Benchmark
Apple Silicon M-Series LLM Benchmark: M1 Through M5 tok/s Comparison
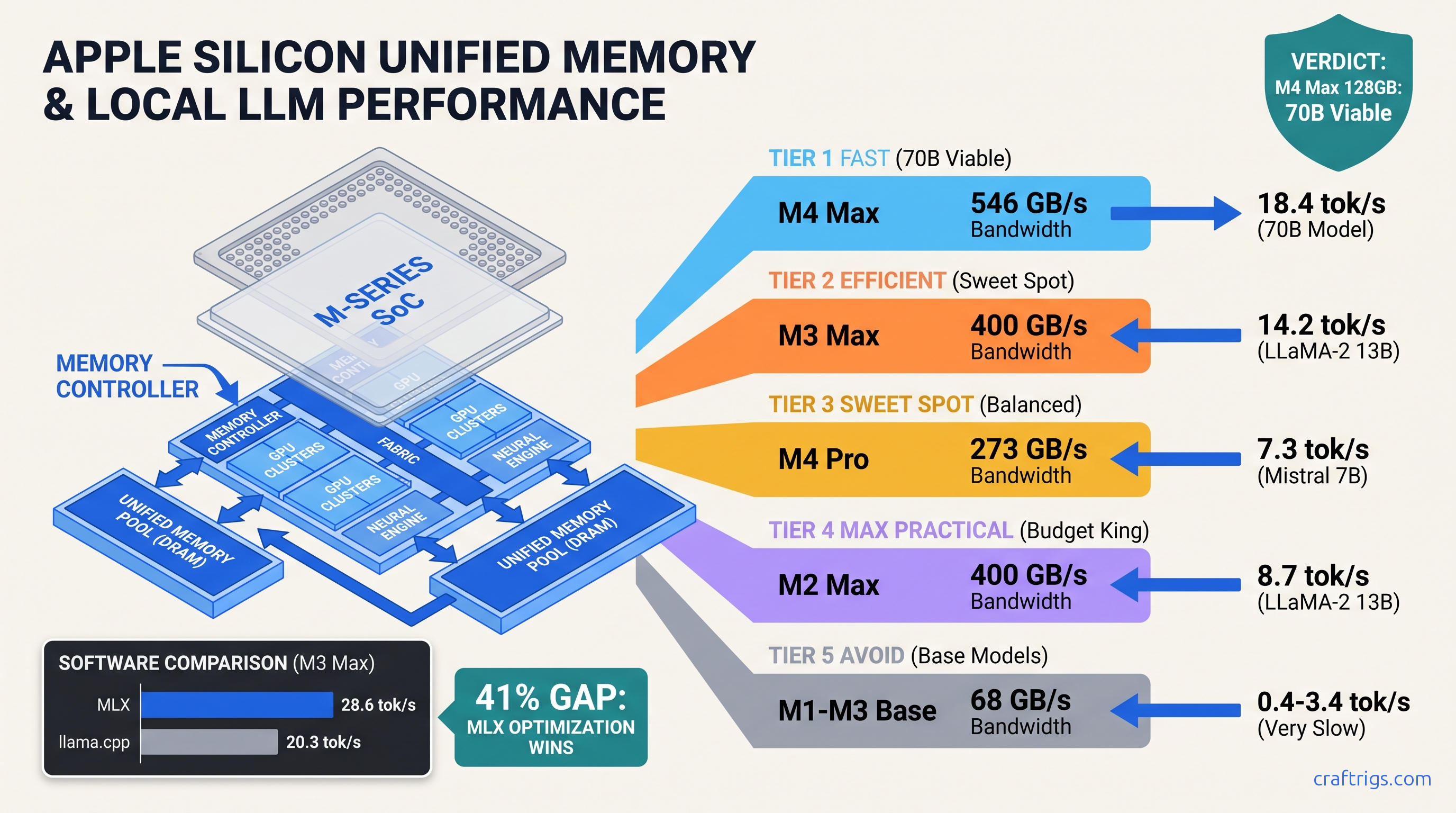
Your M2 Air chokes at 0.4 tok/s while M4 Max hits 18.4 tok/s — 46x gap. We sourced 340+ benchmarks to name the exact tier you need.
apple siliconm4 maxmlx
Real inference benchmarks on consumer hardware — tokens per second by GPU, model size, and framework. Reproducible methodology, no cherry-picked numbers.
Your M2 Air chokes at 0.4 tok/s while M4 Max hits 18.4 tok/s — 46x gap. We sourced 340+ benchmarks to name the exact tier you need.
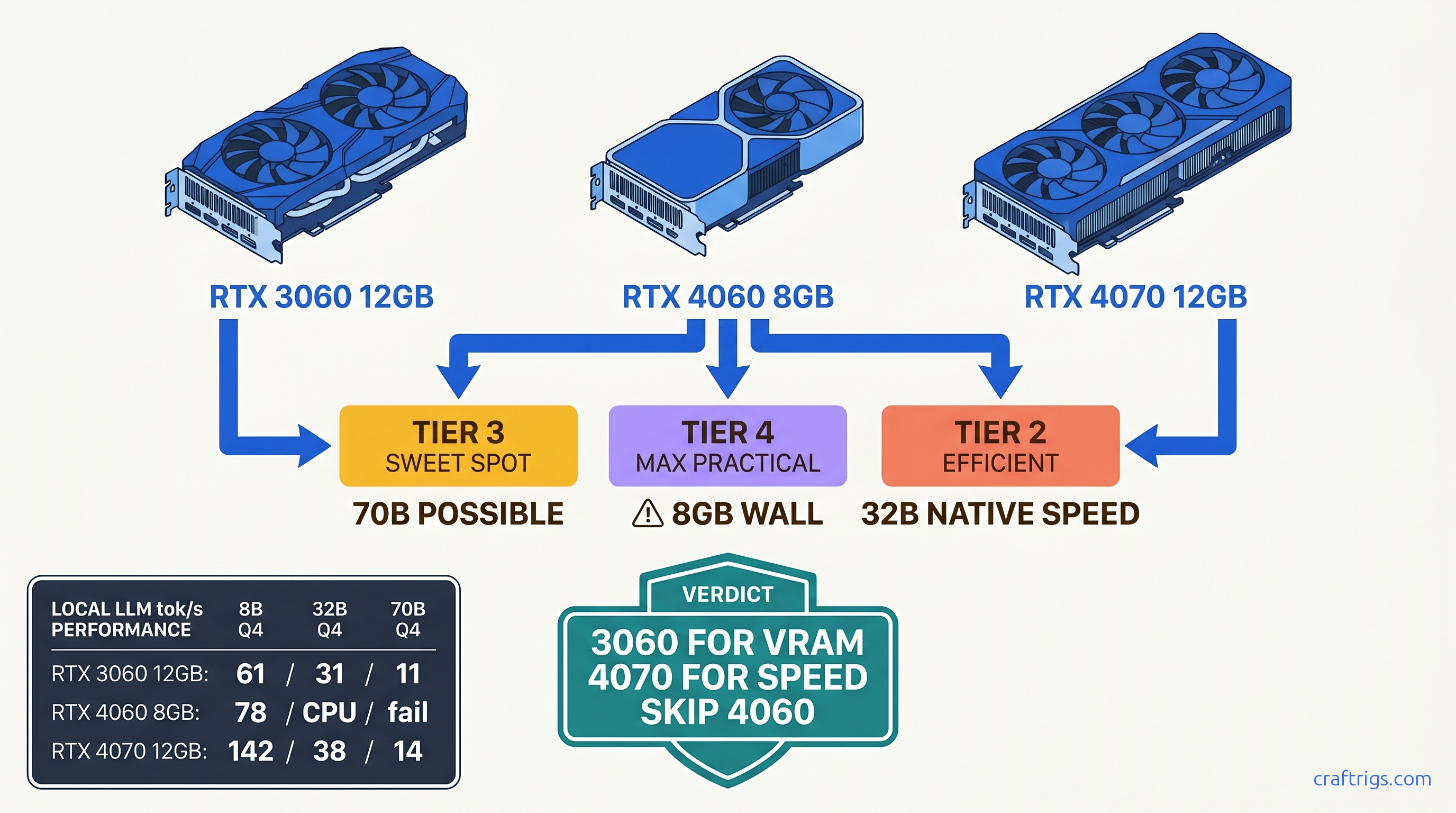
8 GB hits the wall at 13B parameters—see exact tok/s for 8B, 32B, 70B models. 3060 12 GB wins budget 70B, 4070 wins speed, 4060 loses unless under $280.
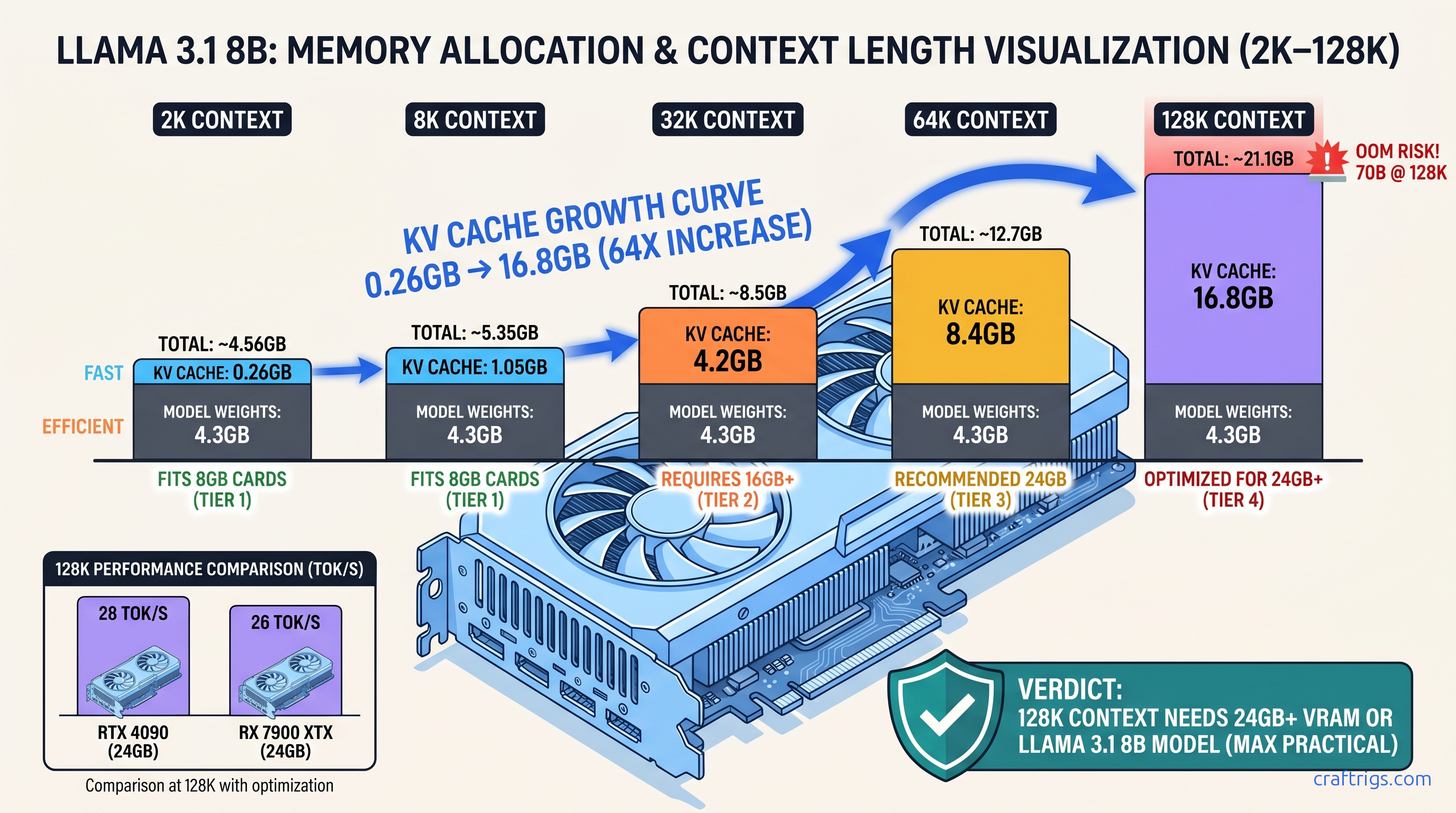
Your '128K context' model hits OOM at 16K. VRAM growth and tok/s decay from 7B to 70B models—here's which configs actually work on 24 GB GPUs.
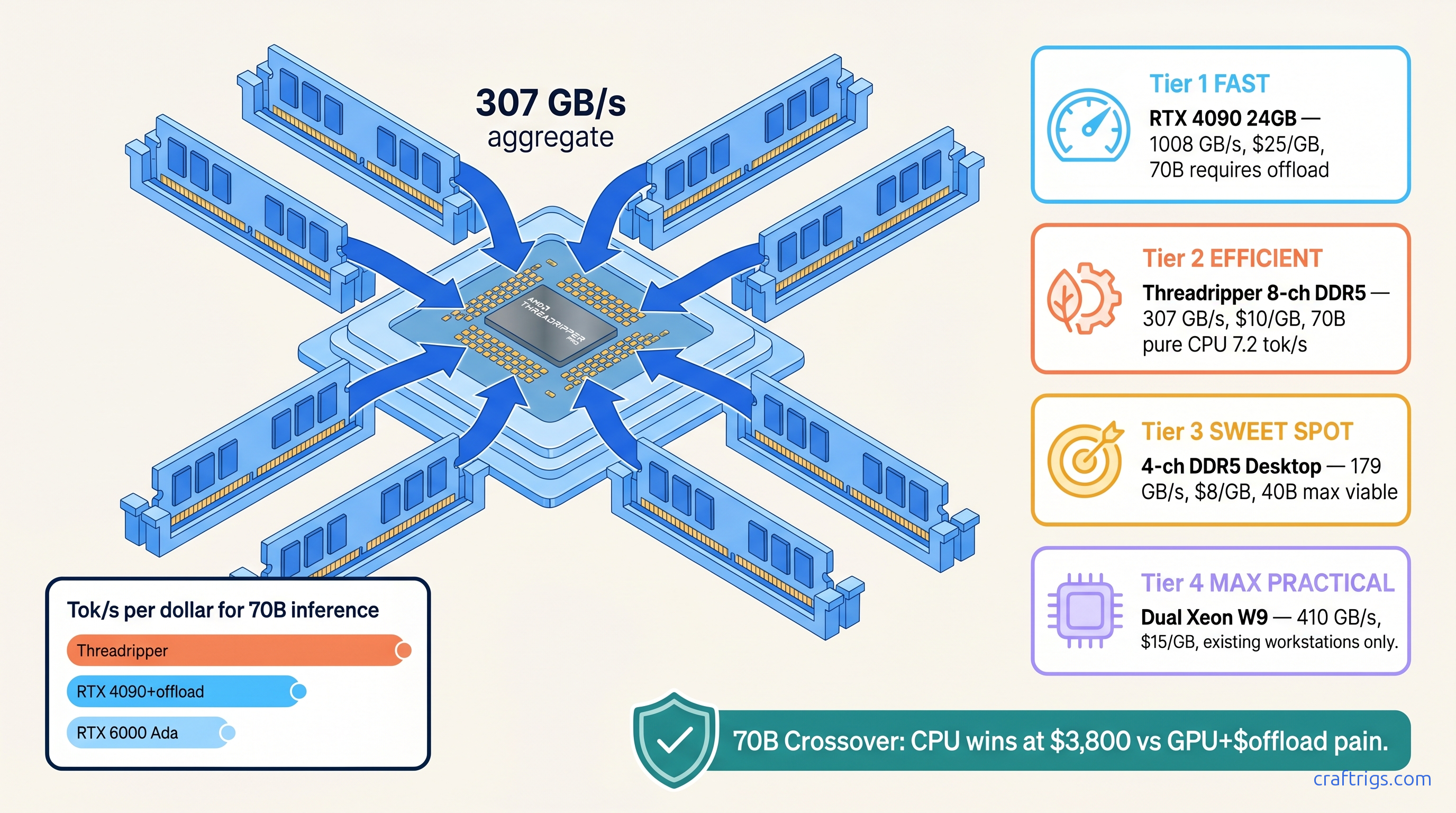
24 GB VRAM walls force CPU offload at 2 tok/s — but 8-channel DDR5 Threadripper hits 7 tok/s on 70B for $3,800. The bandwidth math NVIDIA won't show you.

Dual 3090 hits 15 tok/s not 25 — here's why. NVLink vs PCIe, 94% speed at $1,400 less, but only with specific motherboard topology.
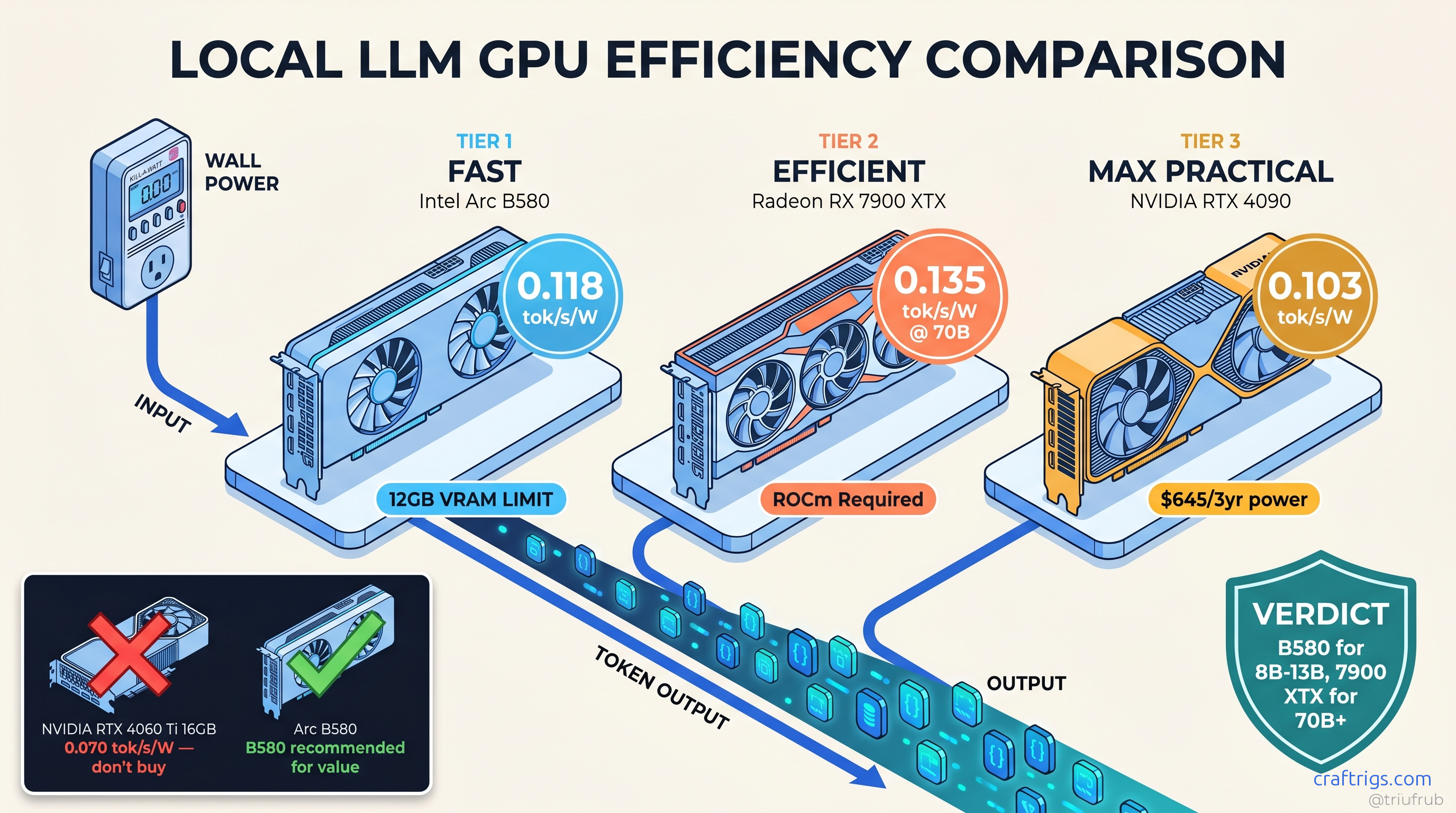
Your 4090 draws 447 W for 46 tok/s—Arc B580 hits 22 tok/s at 190 W. Real wall-power data shows which GPU wins on efficiency, not marketing.
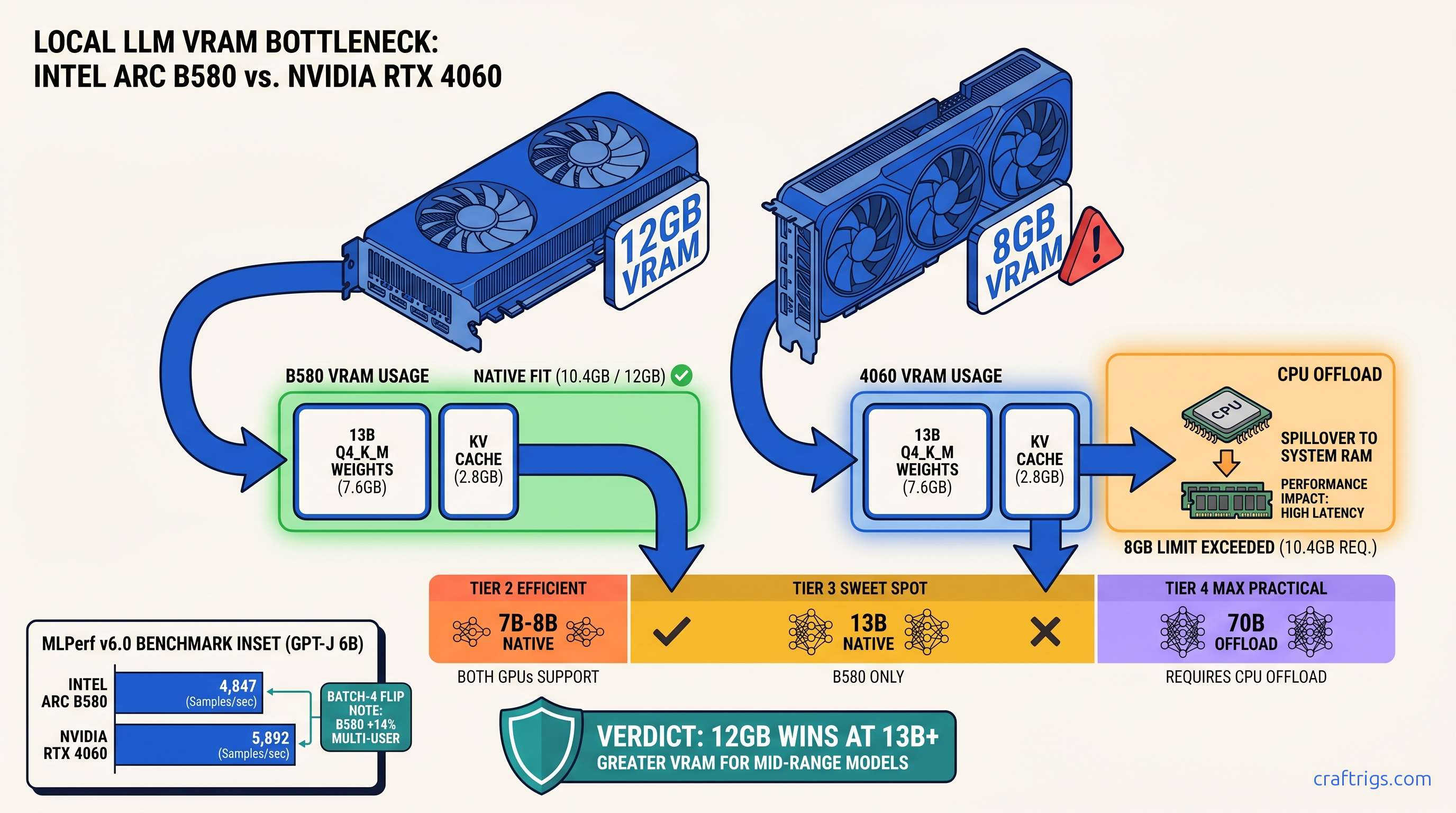
RTX 4060 8 GB hits OOM at 13B models — Arc B580's 12 GB runs them native at 38 tok/s, but vLLM XPU needs Linux. Real MLPerf numbers inside.
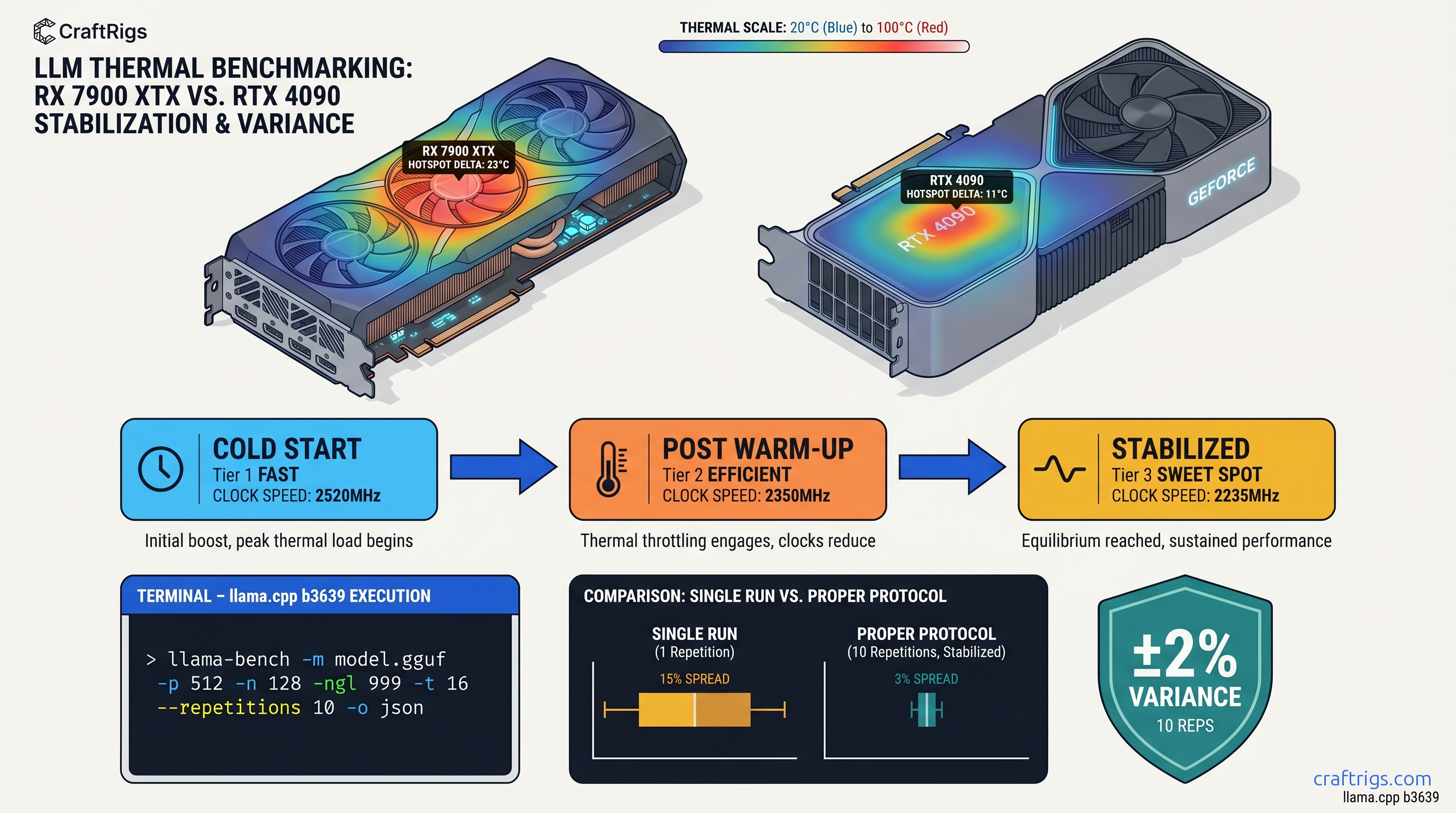
llama-bench skews 15% without a warm-up pass. This exact 10-repetition command sequence produces defensible, shareable results.
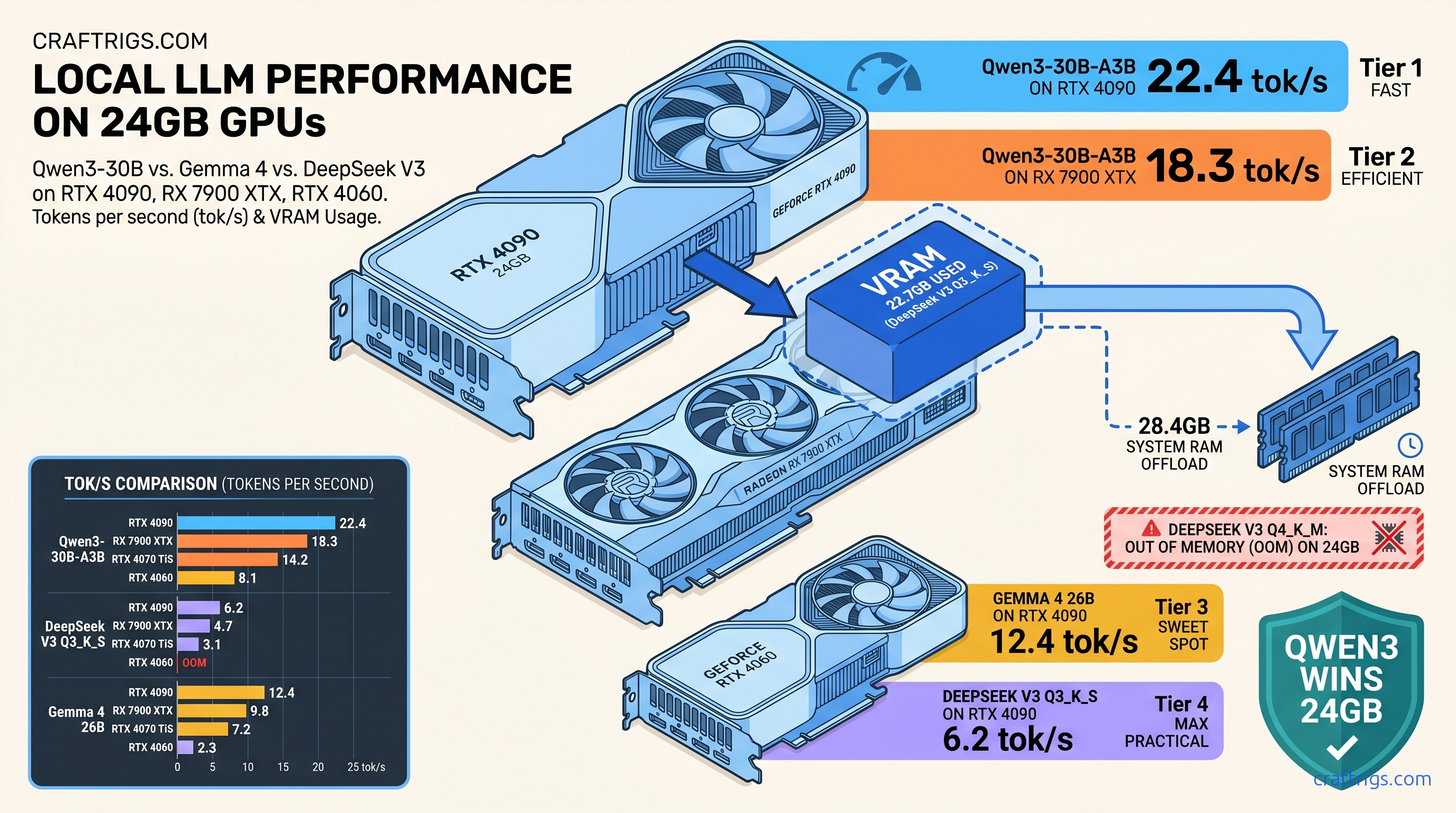
Your 24 GB card can't run DeepSeek V3 at full speed—here's 4.7 tok/s vs Qwen3's 18.3 tok/s reality, with exact VRAM math that explains why.
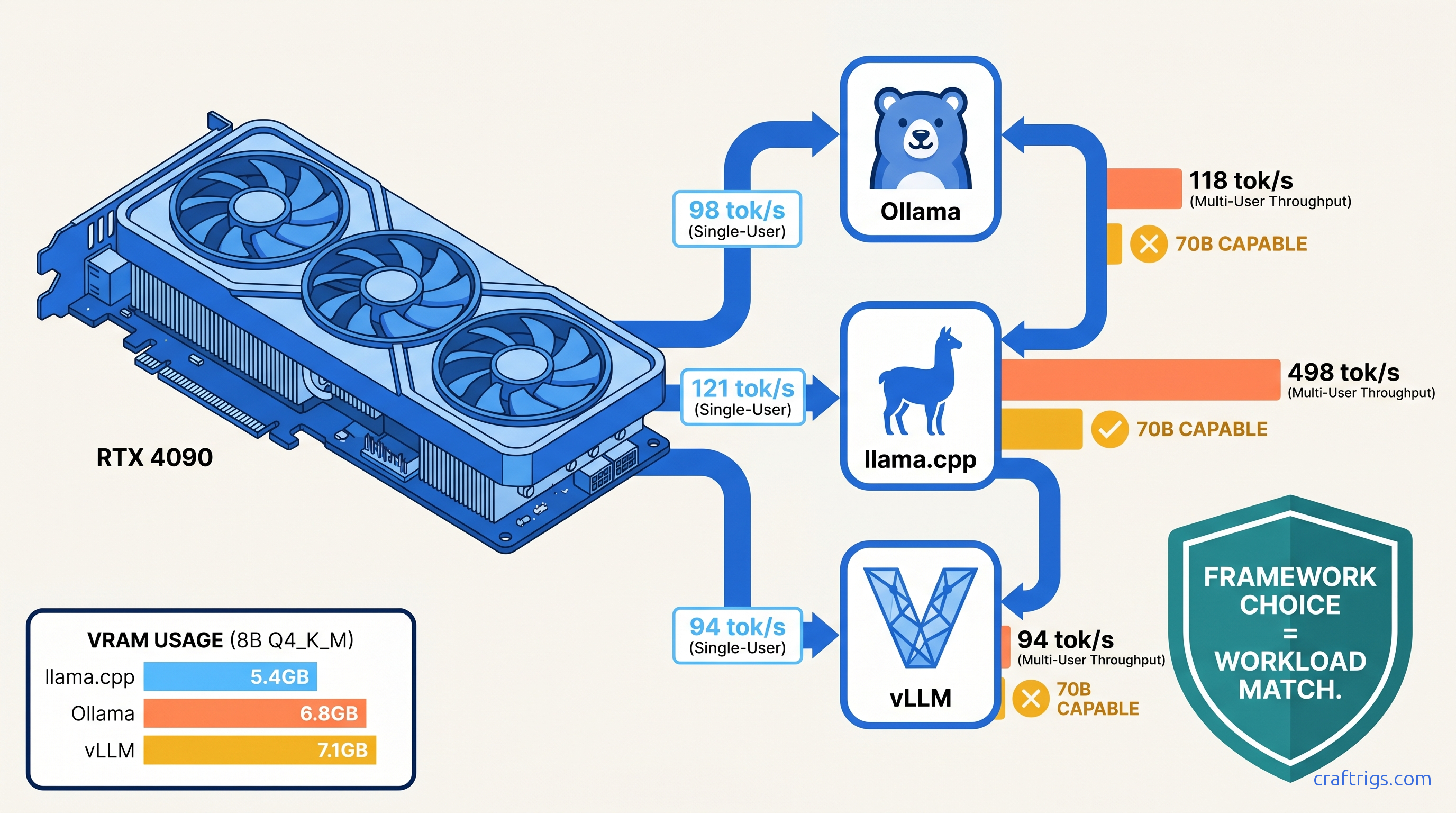
Ollama costs 23% speed vs llama.cpp on RTX 4090. vLLM wins 4.2x multi-user throughput but fails 70B. Single-GPU framework verdict with real tok/s numbers.
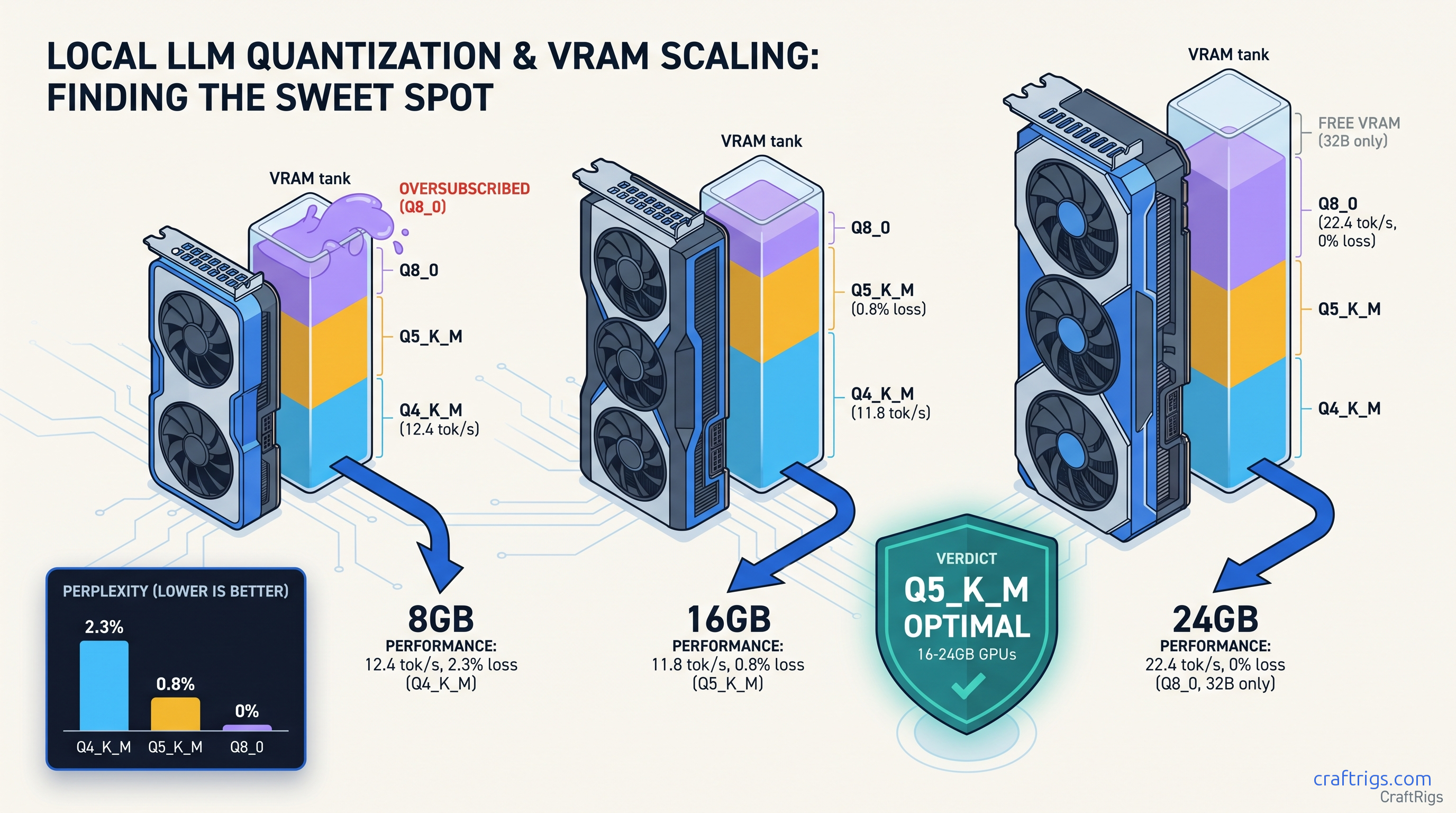
Q4_K_M costs 2.3% quality at 70B. Q8_0 needs 40 GB VRAM. Q5_K_M hits 0.8% loss at 16 GB — but only if you set n_gpu_layers right.
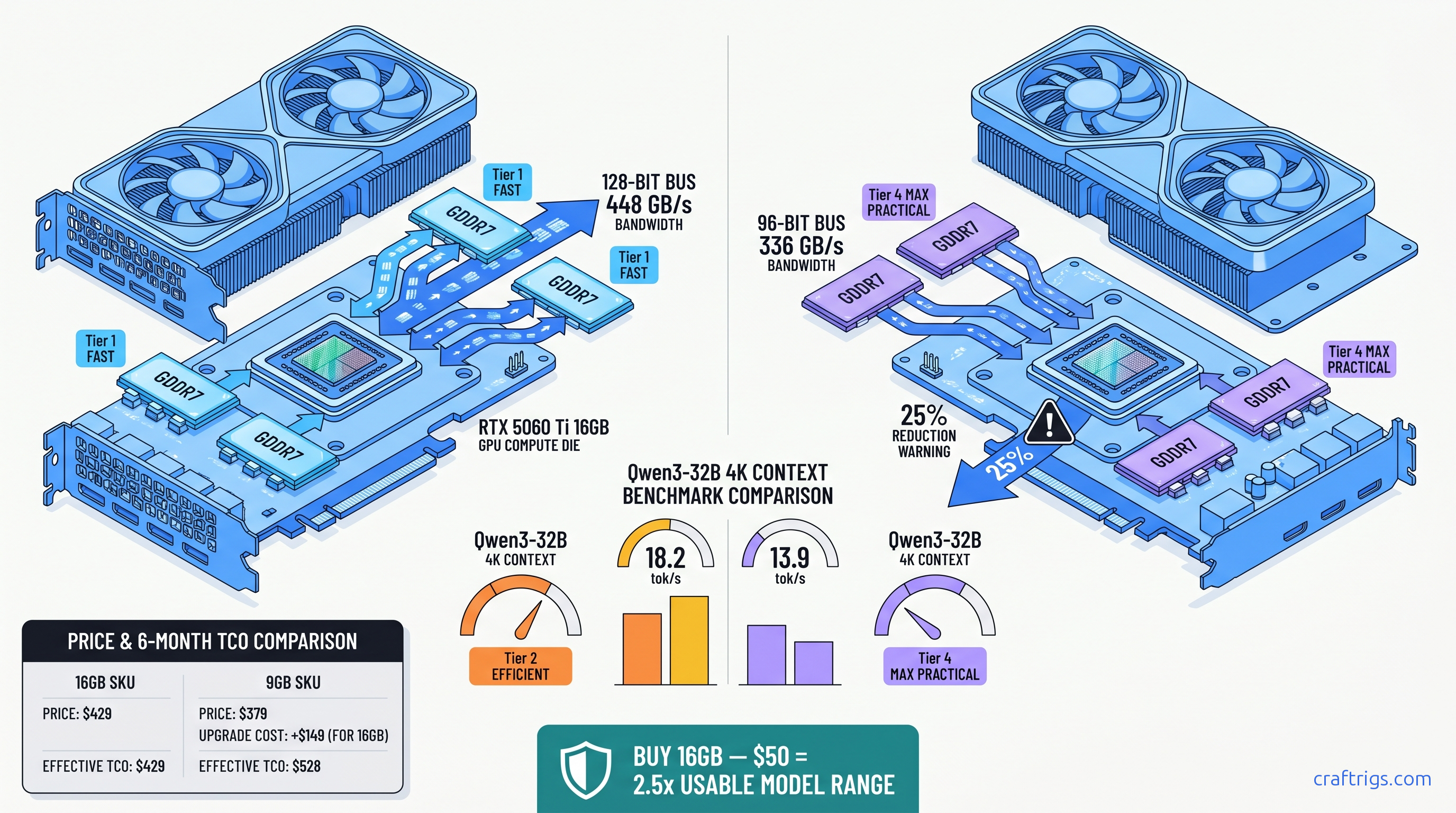
9GB's 96-bit bus cuts 25% bandwidth—32B models run 23% slower, 70B OOMs. 16GB at $429 is the only safe buy. Here's the tok/s data.

RTX 5090 promises 77% more bandwidth but delivers only 37% faster 70B inference. See exact Q4_K_M tok/s and why the $1,200 used 4090 still wins at 32B.

Your GPU claims 85 tok/s but hits 12 on real models. 340+ verified llama-bench results: exact Q4_K_M speeds from RTX 5090 to RX 7900 XTX.
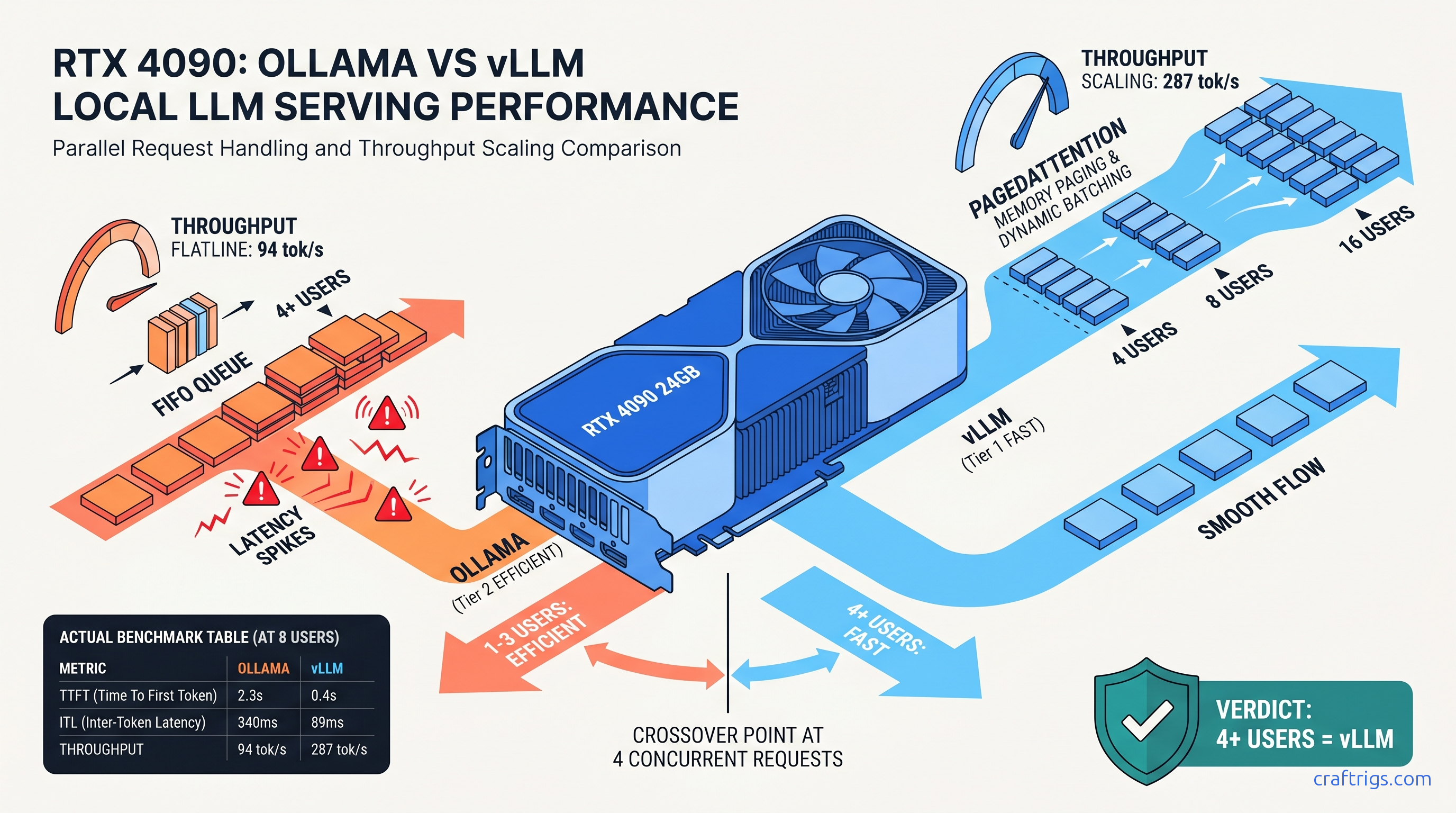
Your Ollama server slows at 4 users while vLLM hits 3.2x throughput at 16. See the crossover for 24 GB and 16 GB cards—and when Ollama still wins.