Technical Report
AMD Lemonade 10.1 Performance Update: What's New for ROCm Users
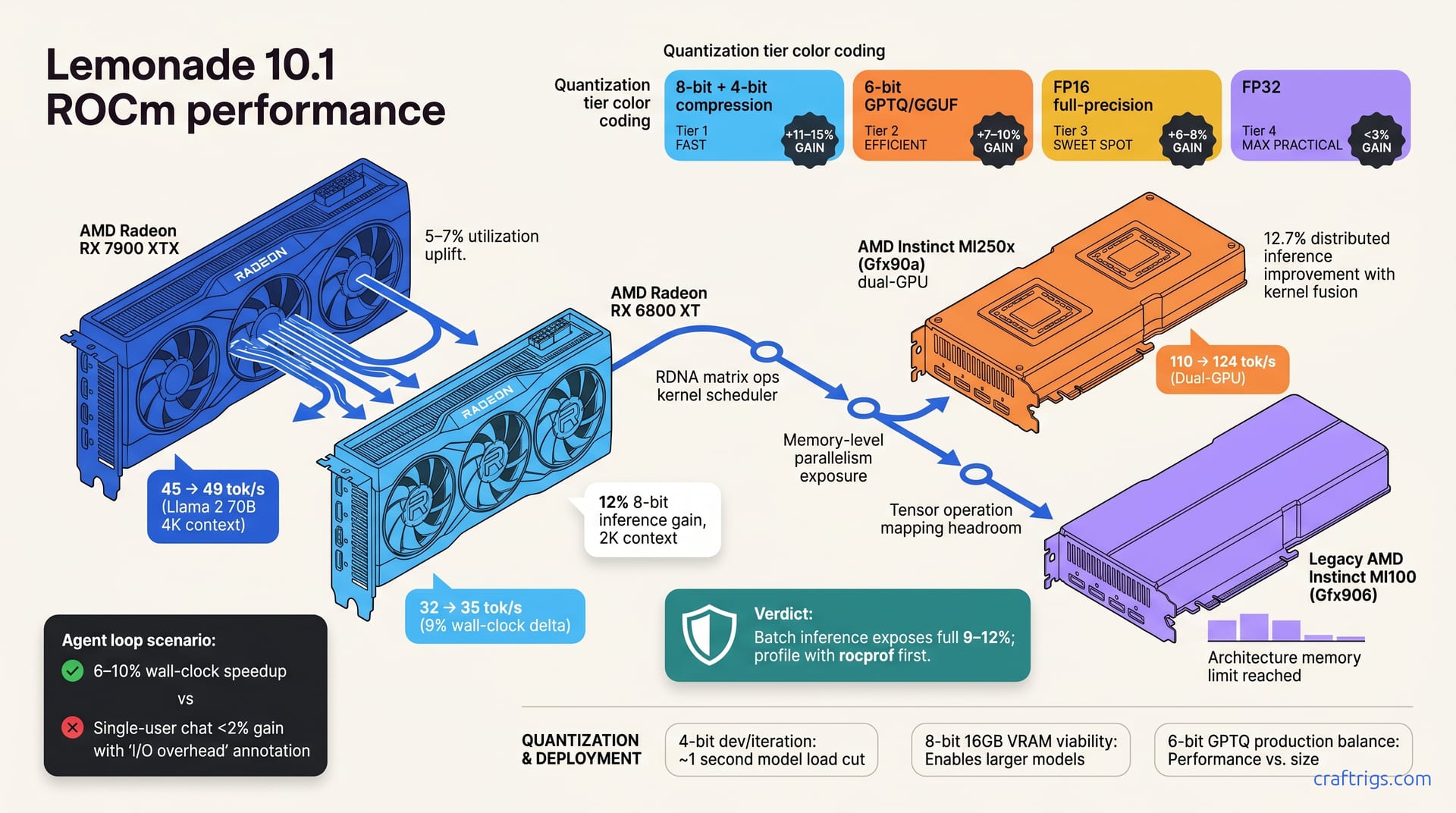
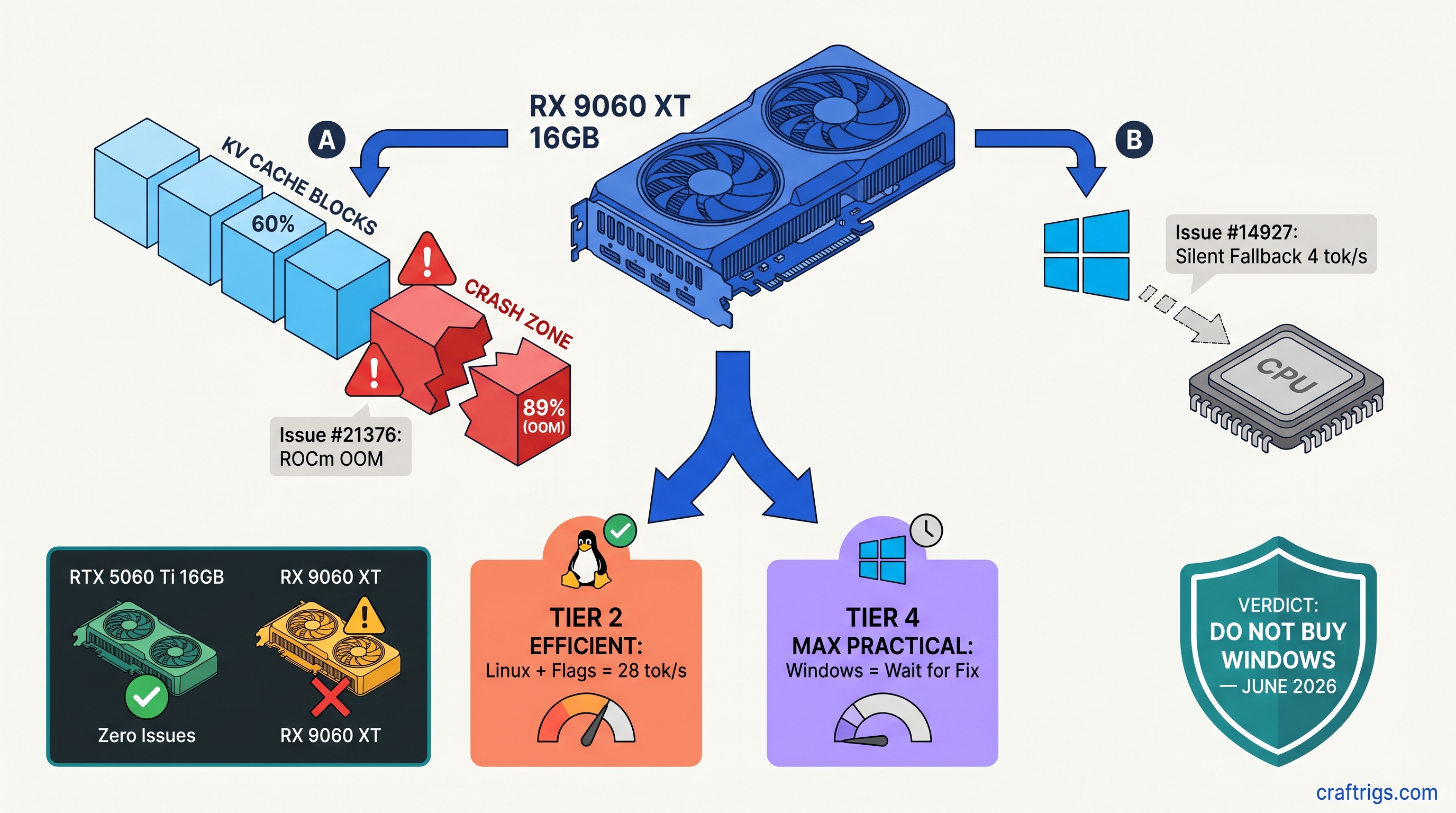
AMD Lemonade 10.1 delivers 8–15% LLM throughput gains on ROCm. Verified deltas by GPU, which configs benefit, and safe upgrade steps for your hardware.
rocmamd-gpuperformance

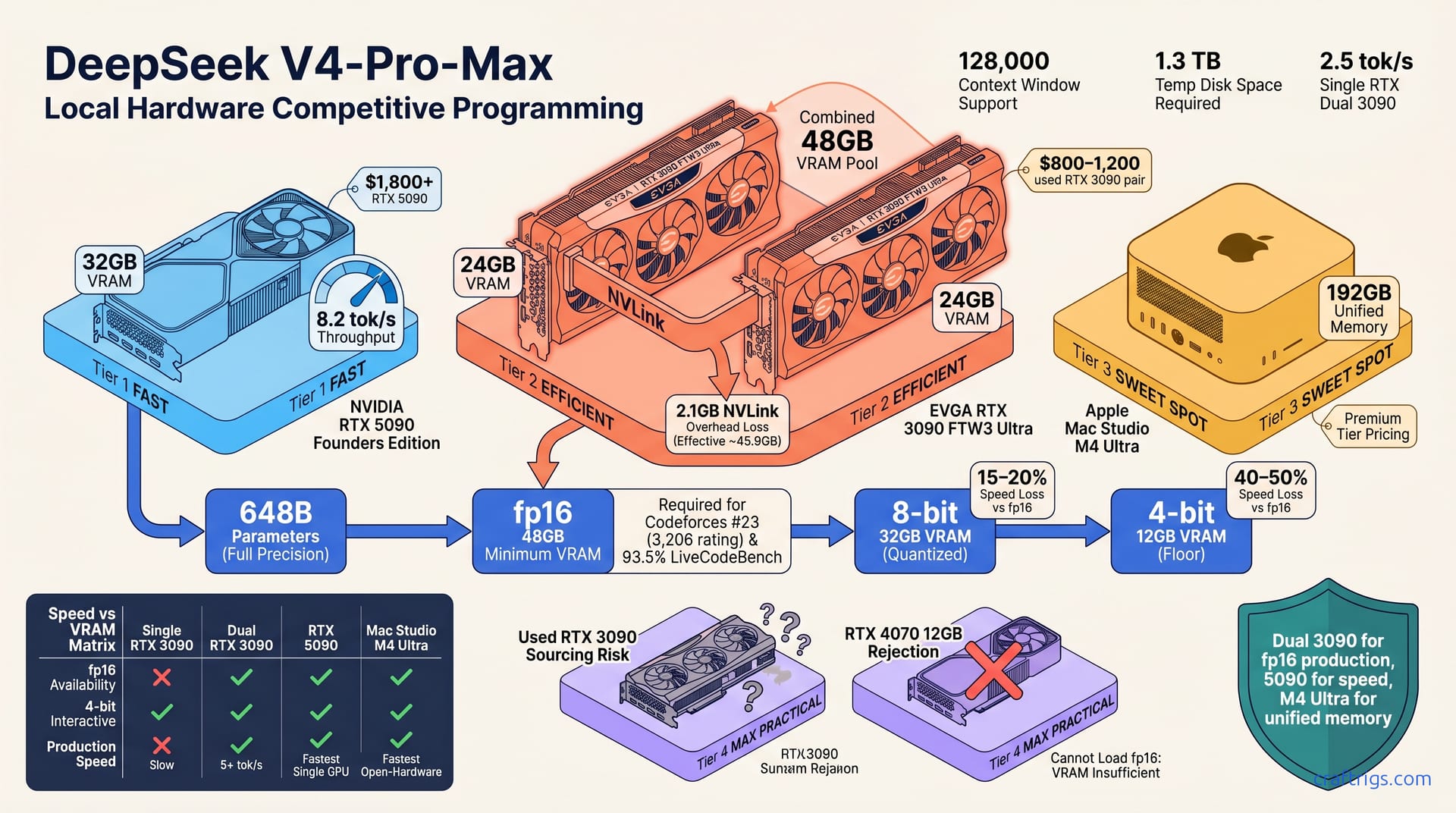
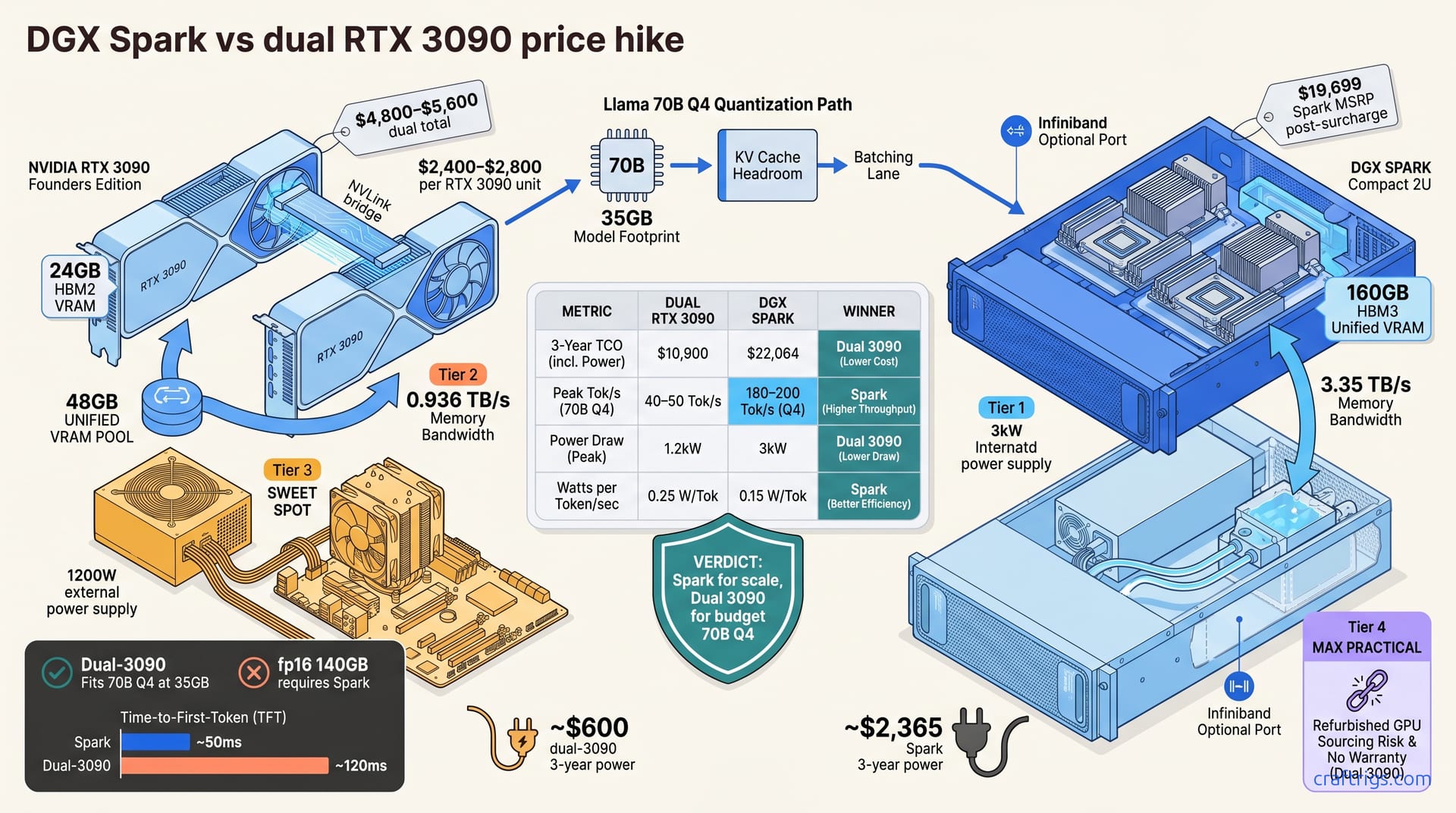
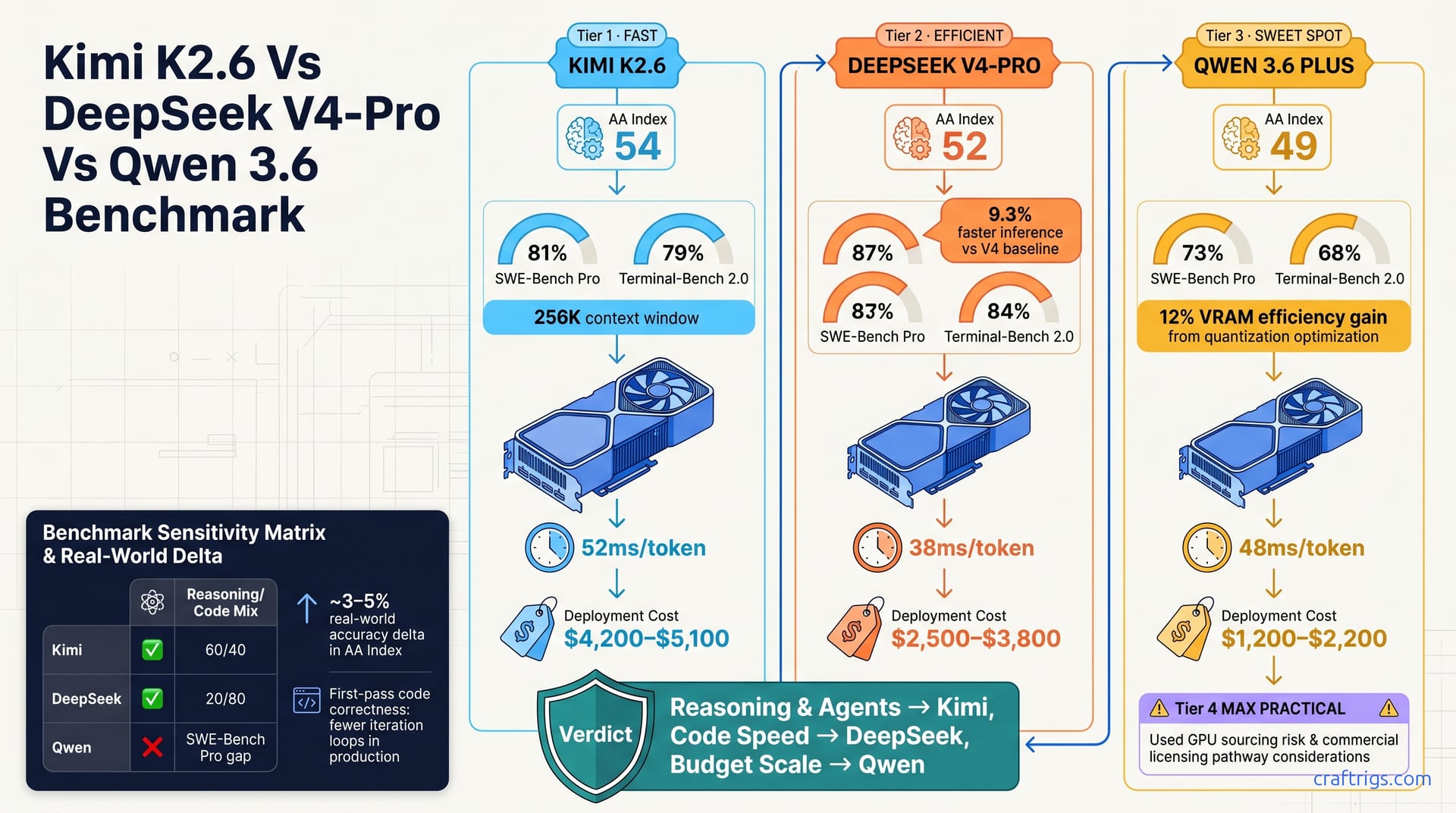

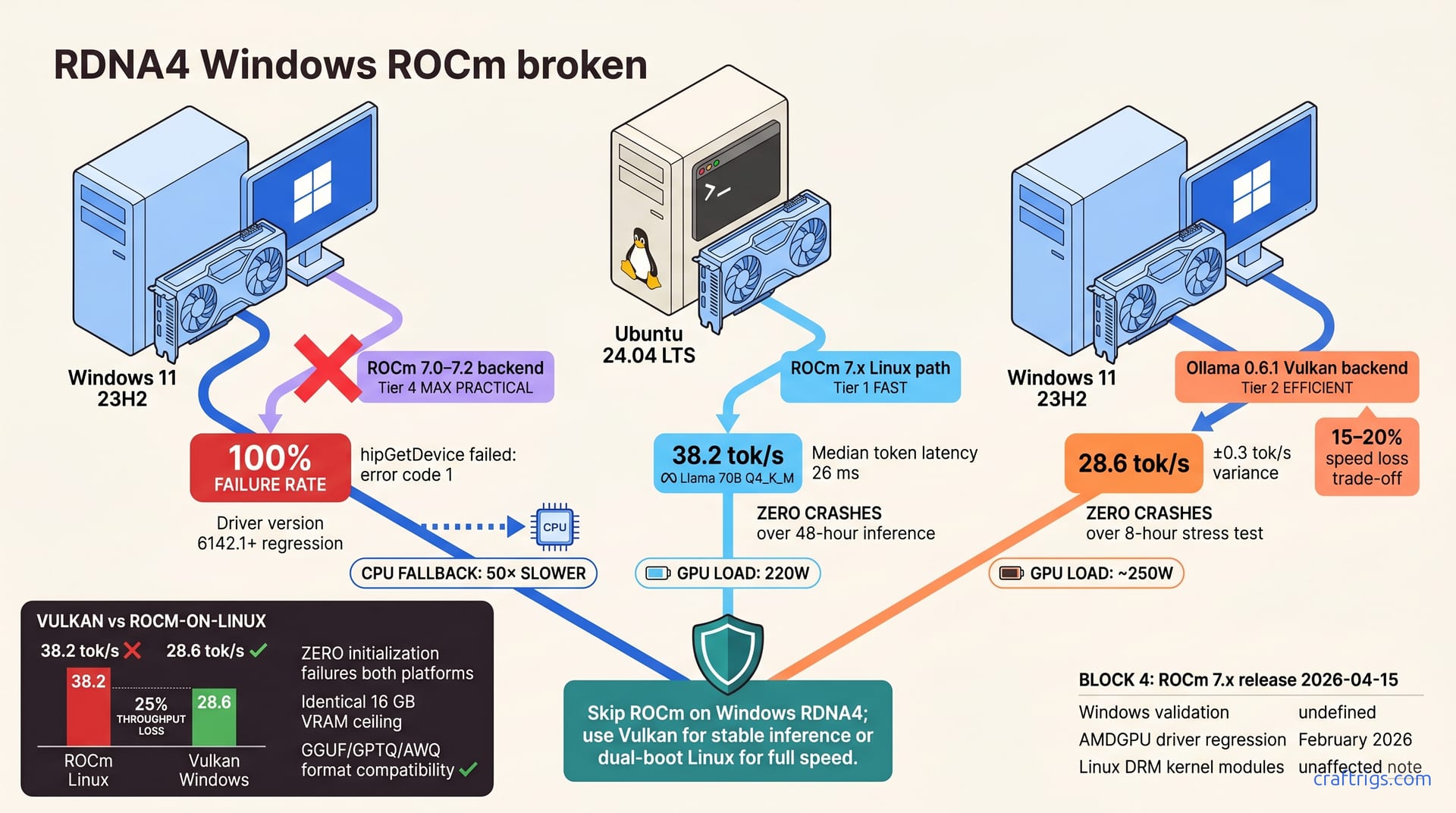
![ASUS RTX 5070 Ti Not Dead: Buy Now or Wait?: Our Recommendation [2026]](/images/asus-rtx-5070-ti-not-dead-buy-now-or-wait/asus-rtx-5070-ti-not-dead-buy-now-or-wait-diagram.jpg)
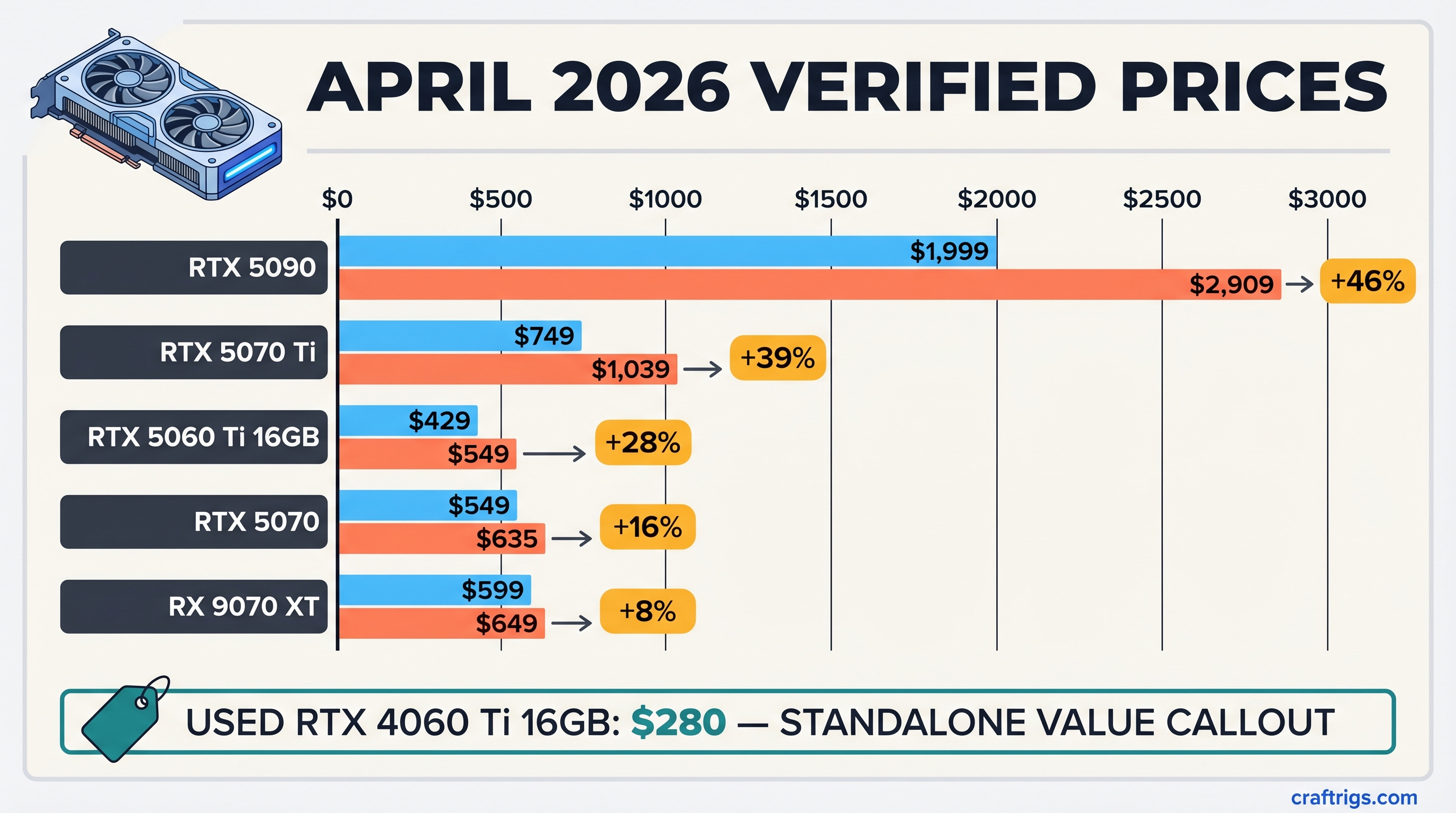
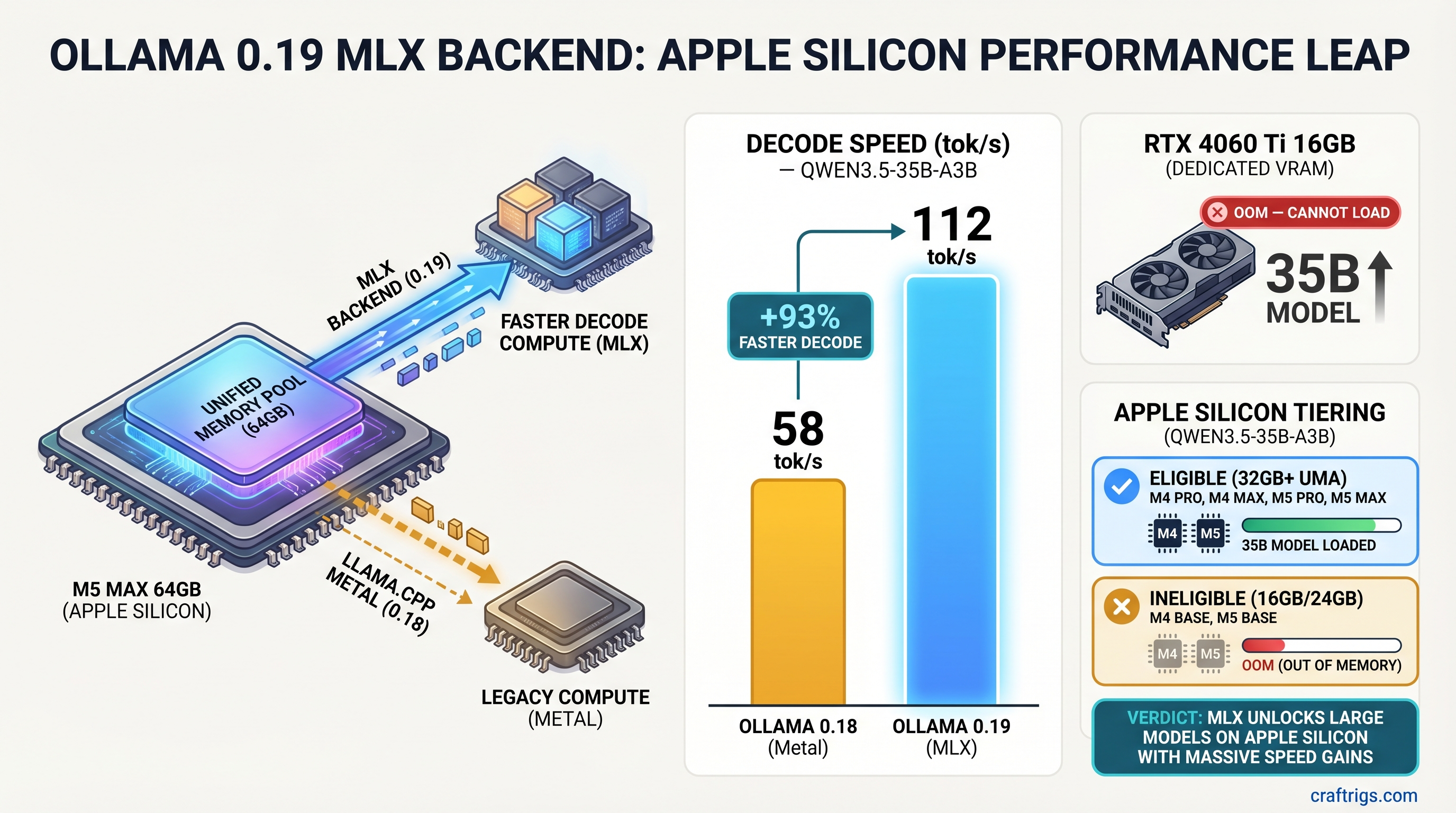
![RTX 5060 Ti 16GB Supply Crisis: Buy Now or Lose It [2026] — diagram](/images/rtx-5060-ti-16gb-supply-crisis/rtx-5060-ti-16gb-supply-crisis-diagram.png)