Workflow
Aider + Ollama: Running an AI Pair Programmer Entirely Offline
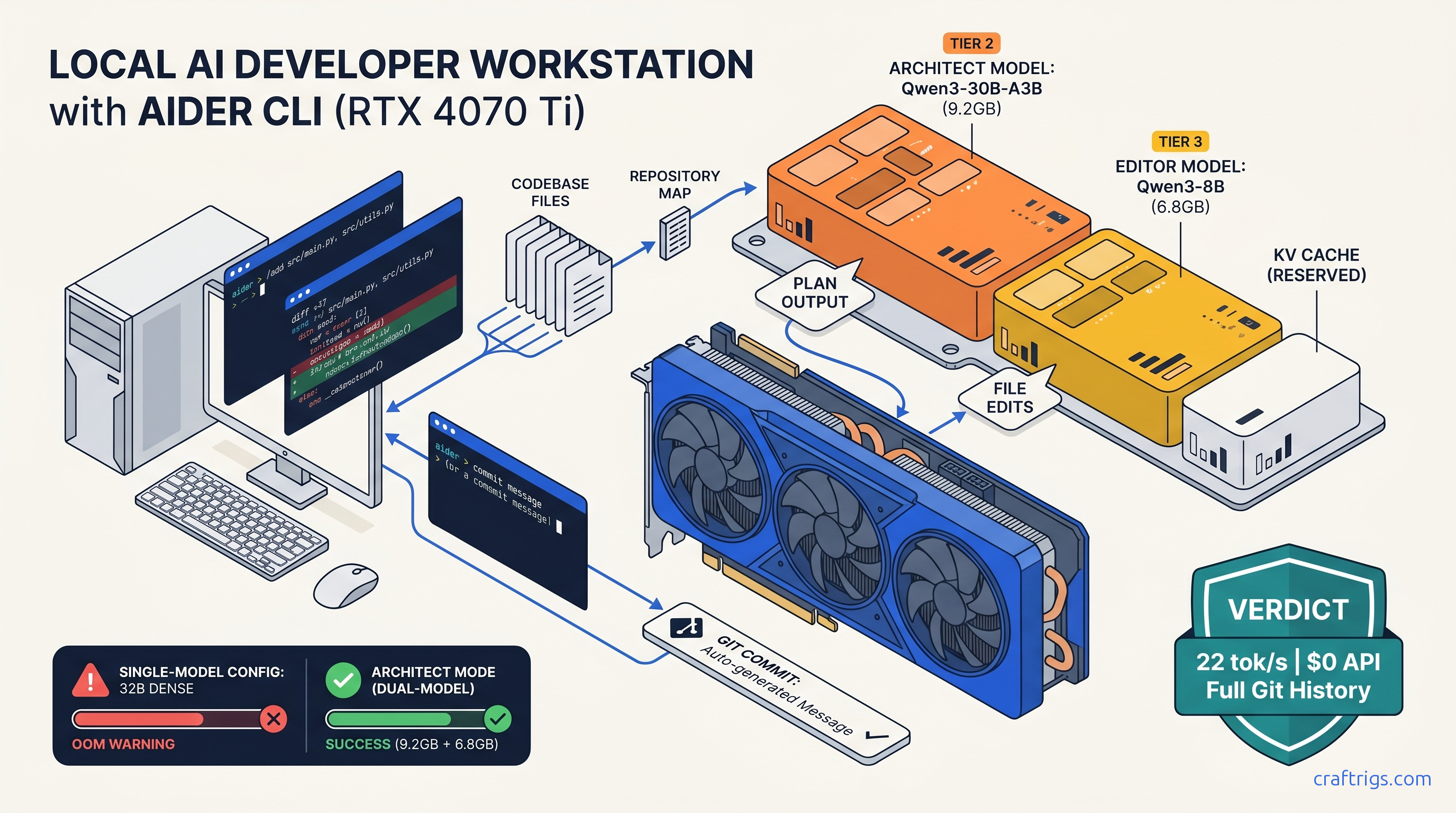
Stop Aider calling OpenAI—lock to local Ollama. 16 GB VRAM runs 30B+8B models at 22 tok/s, but 8 GB cards OOM without architect-only mode.
aiderollamalocal-llm
End-to-end local AI setups that actually work — coding assistants, RAG pipelines, document chat, and automation stacks. Step-by-step, hardware requirements included.
Stop Aider calling OpenAI—lock to local Ollama. 16 GB VRAM runs 30B+8B models at 22 tok/s, but 8 GB cards OOM without architect-only mode.
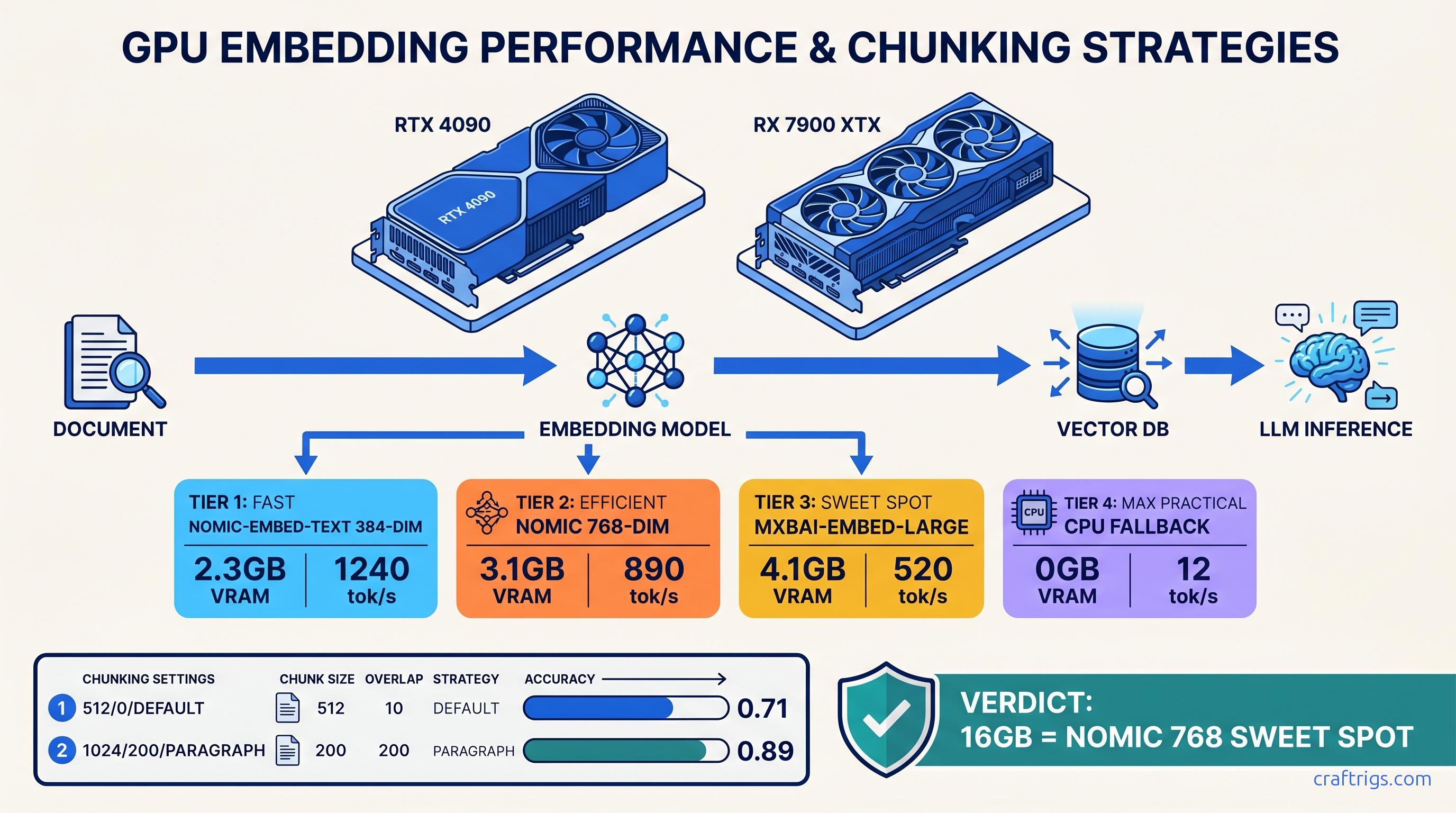
PDF RAG returns garbage? Fix embedding, chunking, GPU passthrough — 0.89 top-5 accuracy possible, but 8 GB cards force CPU fallback.
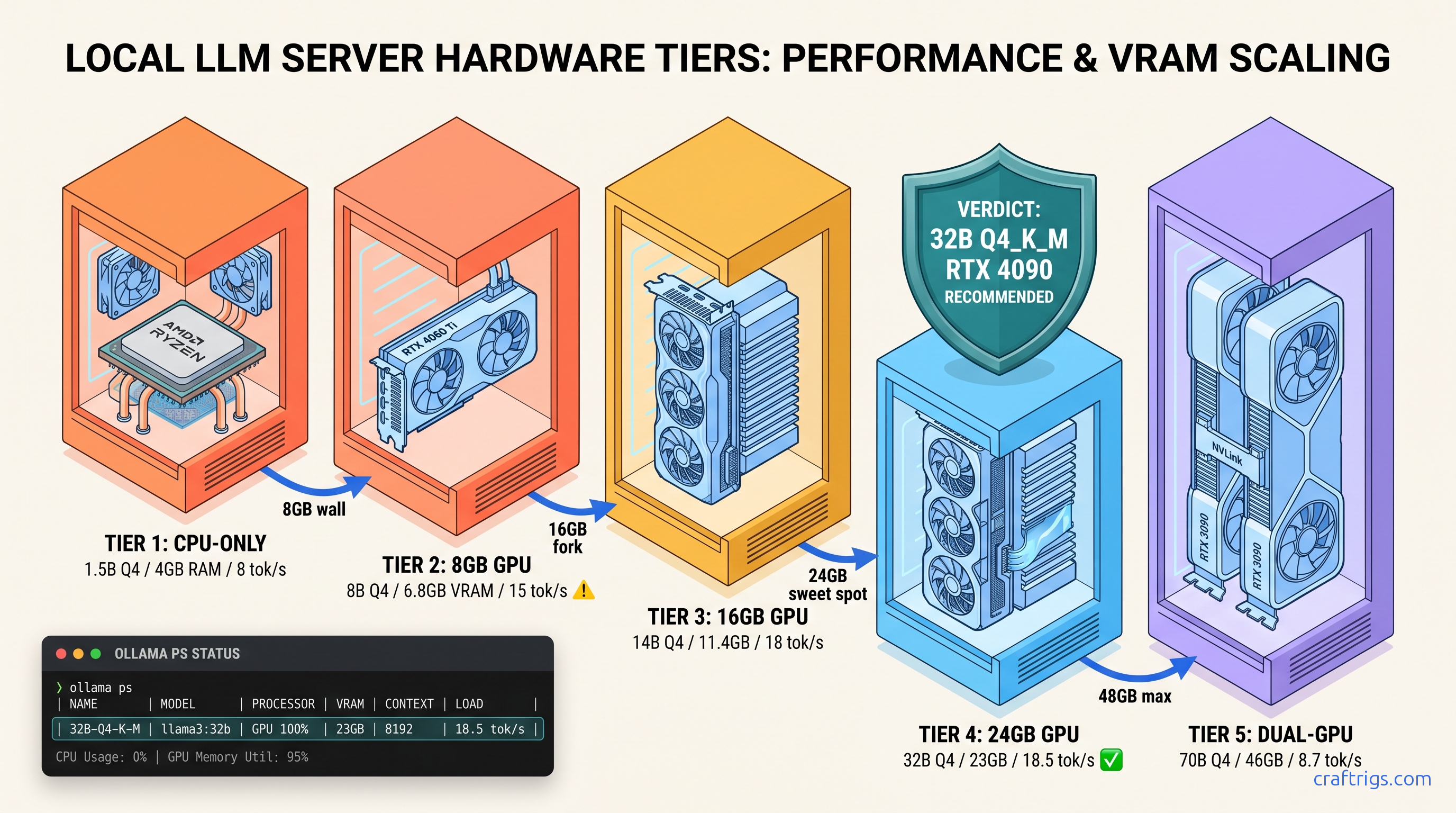
8GB GPUs hit the wall at 14B, 24 GB runs 32B at 18 tok/s — but 70B needs 2 cards or 48 GB unified. Exact VRAM math per quant inside.
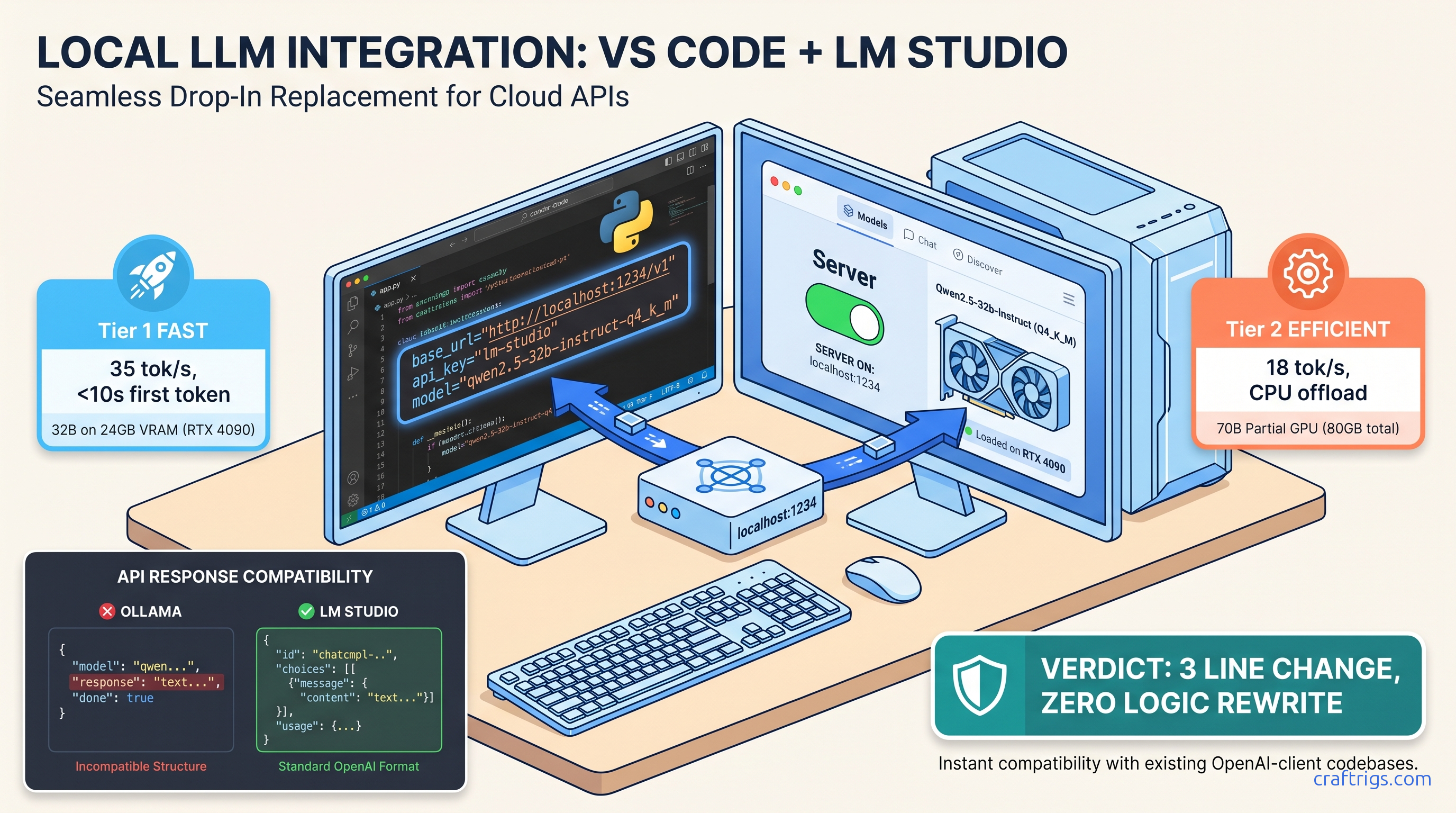
OpenAI SDK fails on local endpoints—fix 3 lines for 35 tok/s inference, but watch the 4K context trap that silent-truncates.
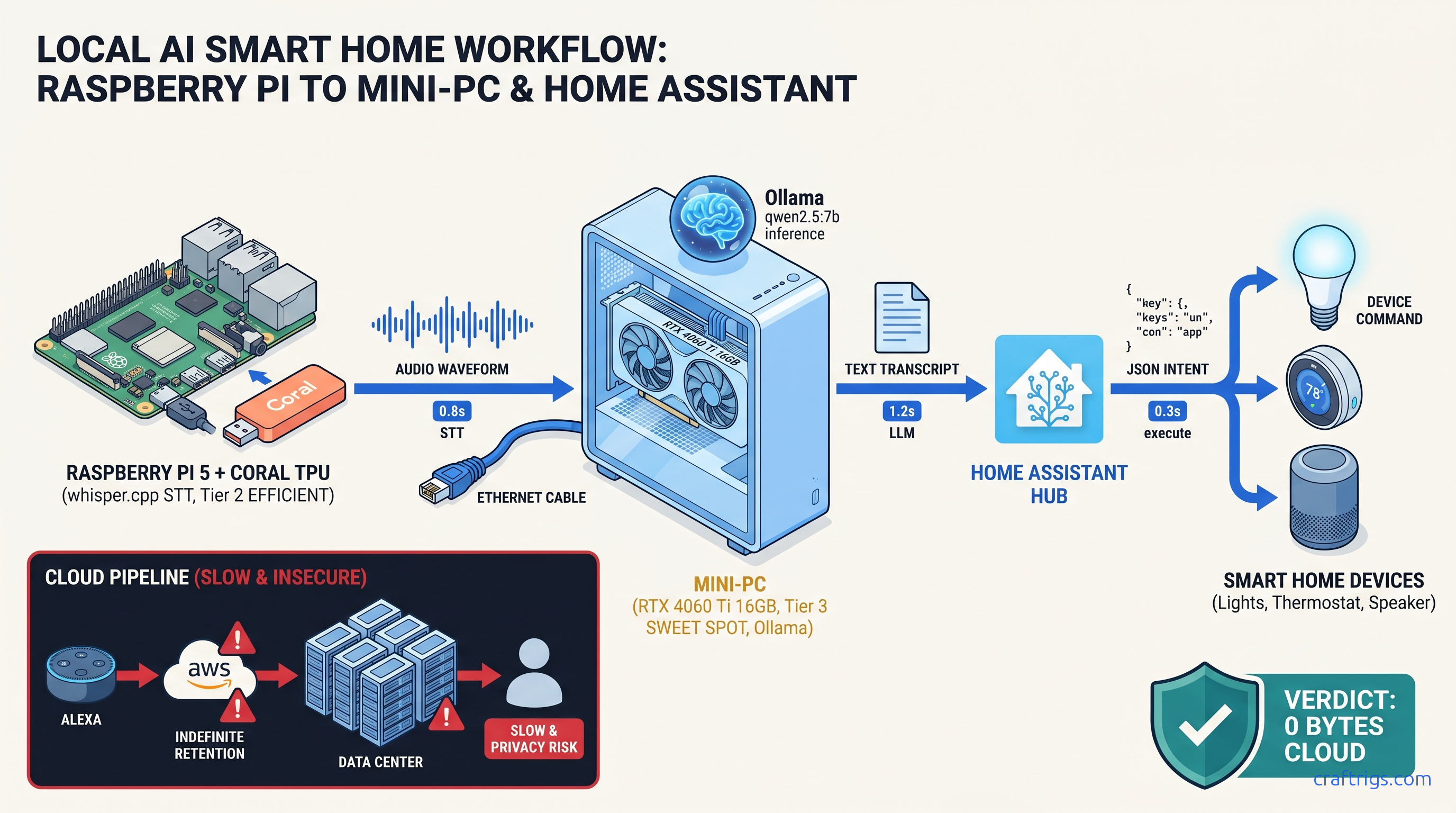
Alexa sends everything to cloud. This Home Assistant + Ollama pipeline runs 100% local — 2.3s response time, but requires 7B model minimum.
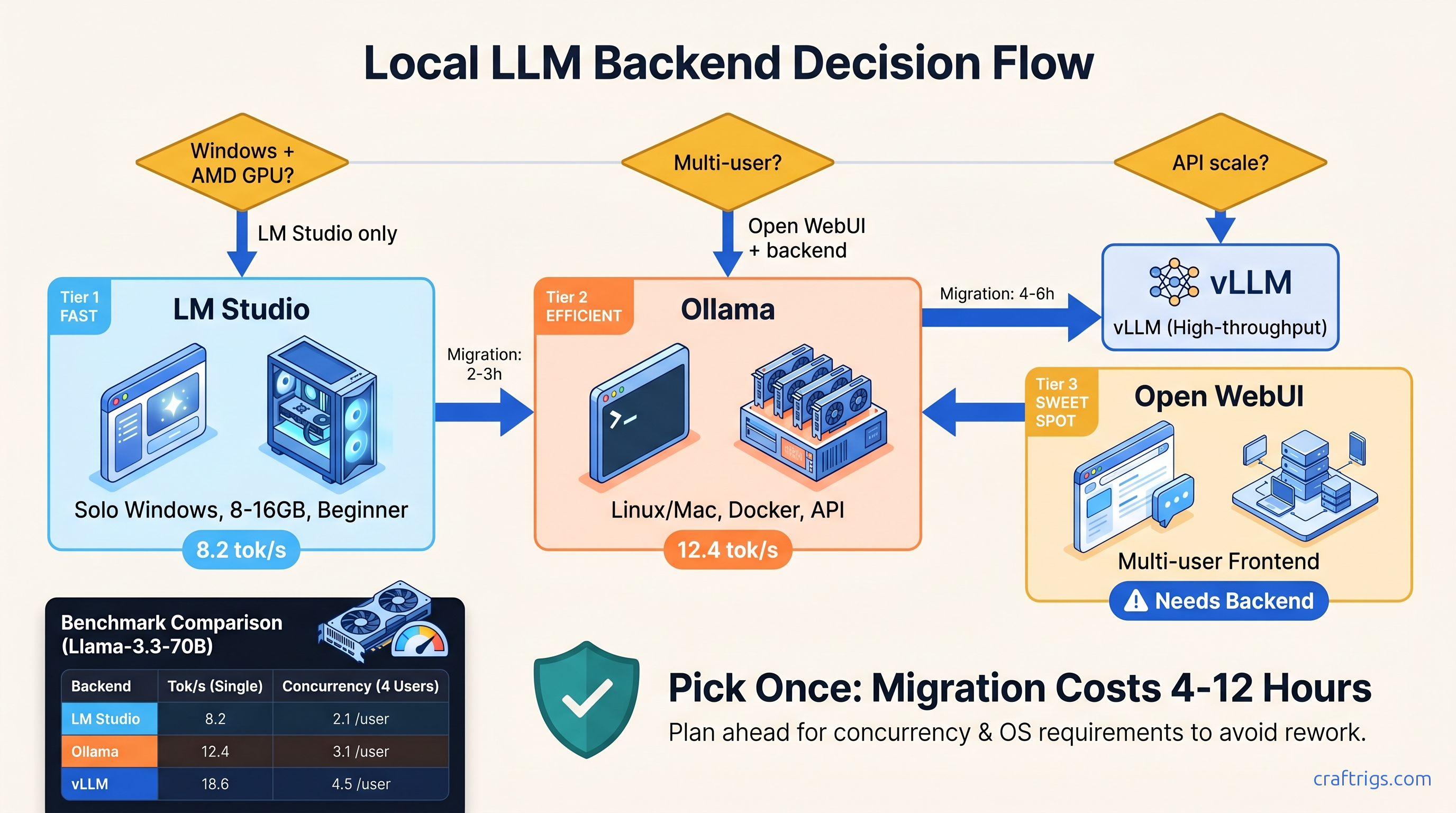
Tried 2 backends? LM Studio wins beginners, Ollama owns Linux, Open WebUI needs a backend — here's the 6-criteria matrix to pick once, skip the rewrite.

Your local agent ignores tools or loops forever? Qwen3 14B runs 28 tok/s with 91% tool success — but only if you pull the right Ollama tag. Here's the fix.
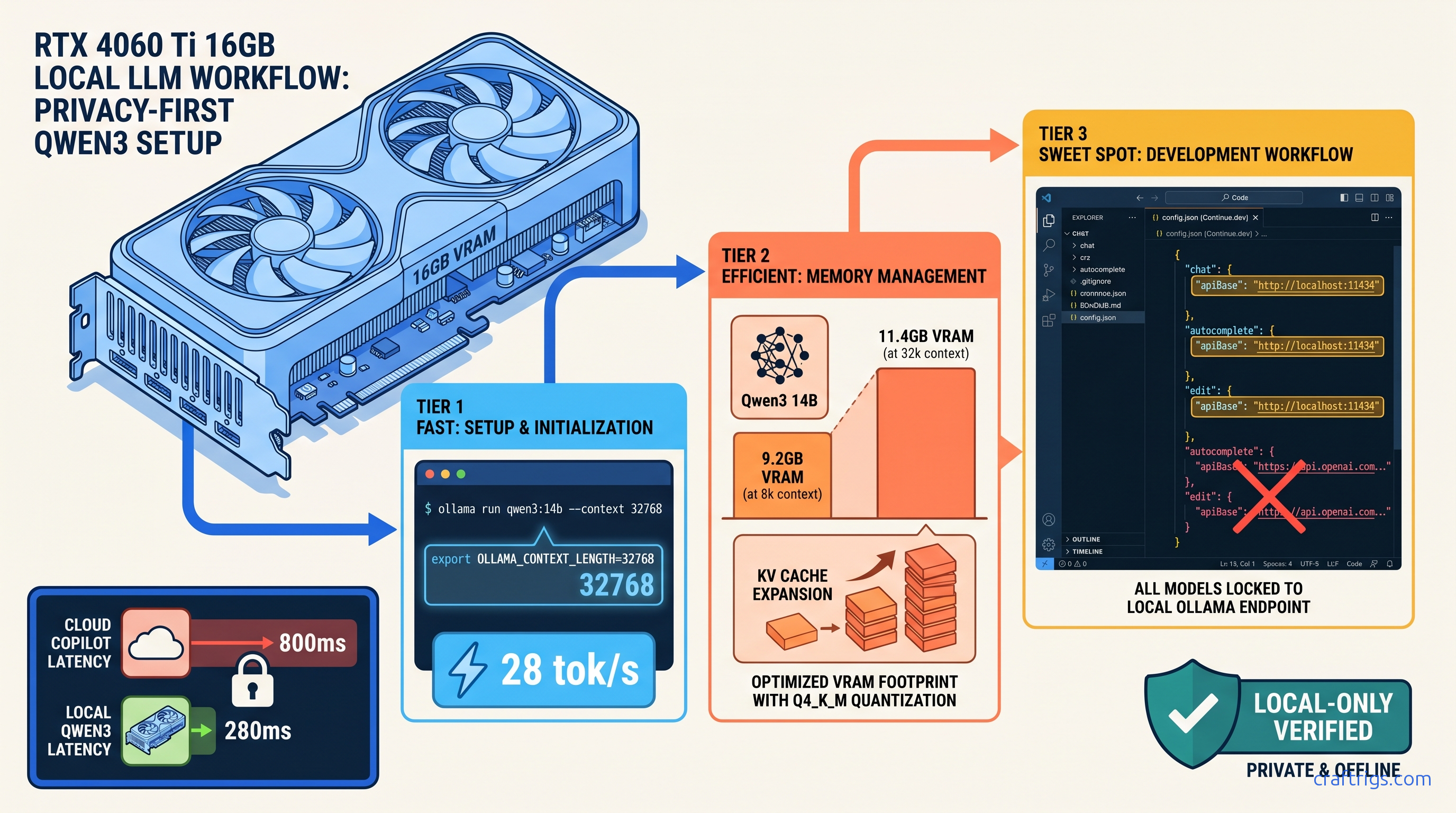
Build a private Copilot in 30 min — Qwen3 14B at 28 tok/s locally with 32k context, but only if you disable Continue.dev's hidden cloud fallback first.
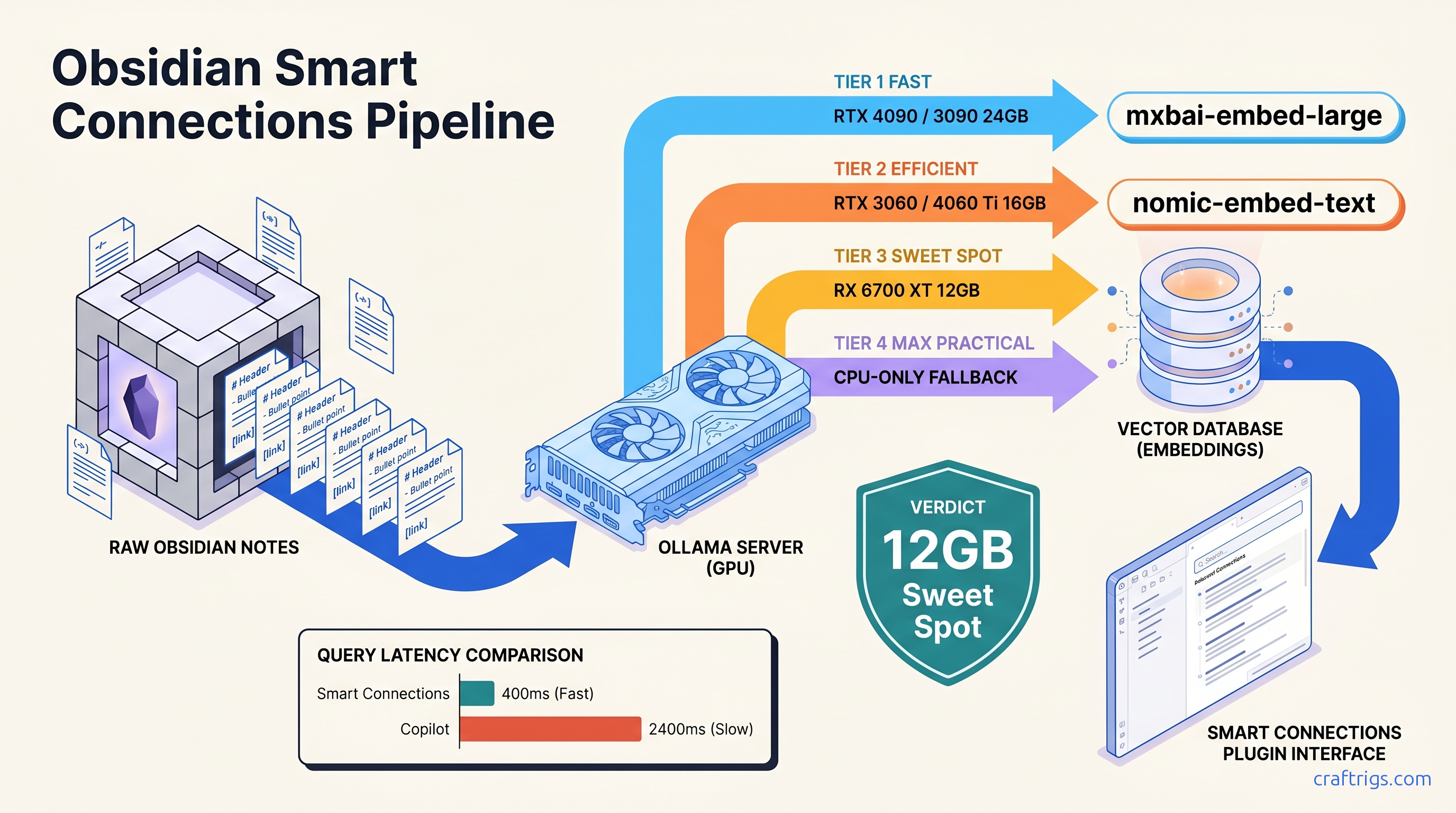
Stop sending notes to OpenAI—build a private Obsidian AI with local embeddings. 10K notes indexed in 90 min on RTX 3060, but 8 GB GPUs hit the wall.

Your local LLM is stuck offline. Add web search with this 3-container stack—2.3 GB RAM, 4.2s latency. Catches: version pins matter, CORS breaks silently.
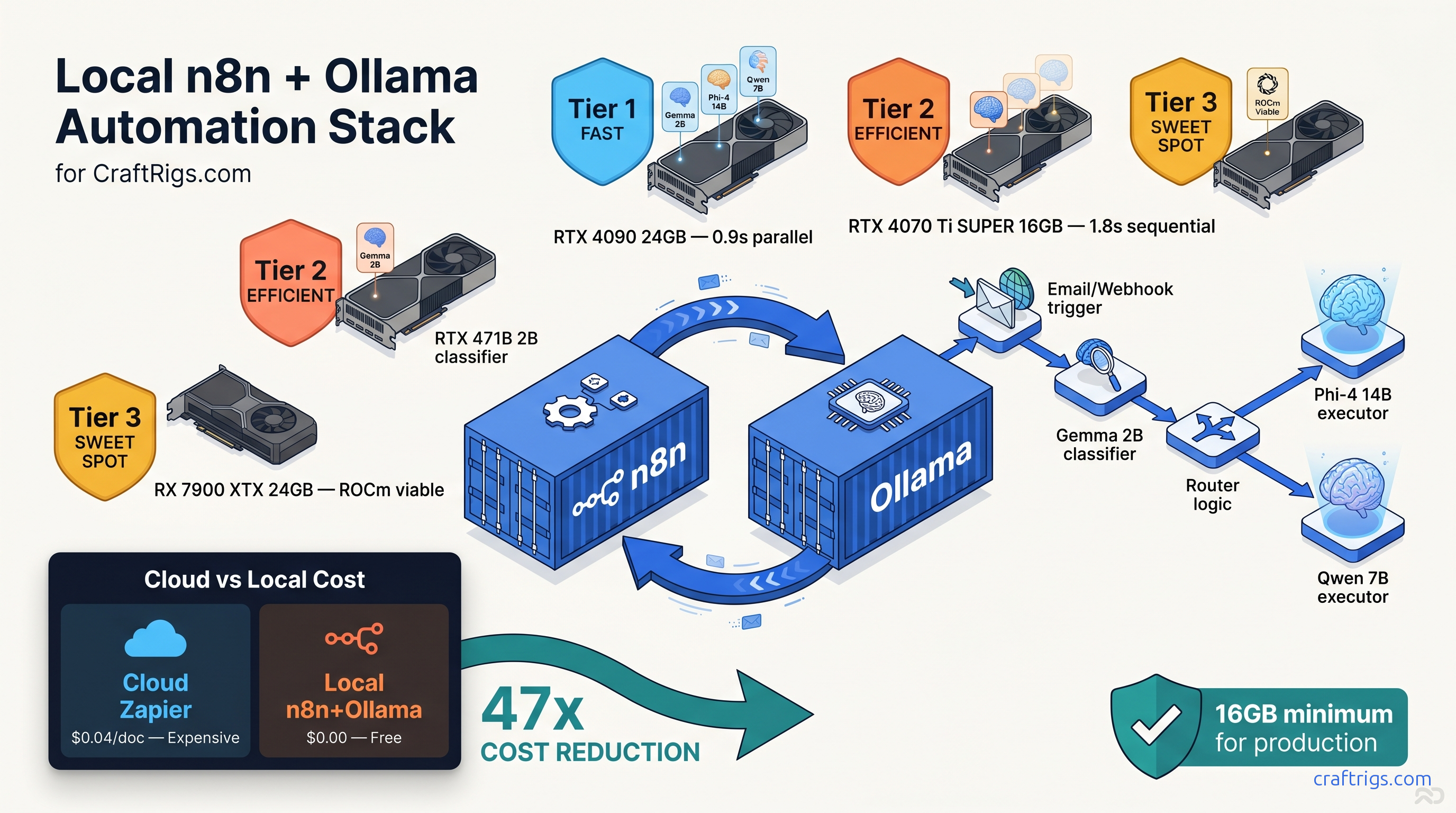
Cloud automation bills stacking up? Build self-hosted n8n + Ollama workflows for $0 per task — but 8 GB GPUs hit the wall at 7B models. Here's the fix.
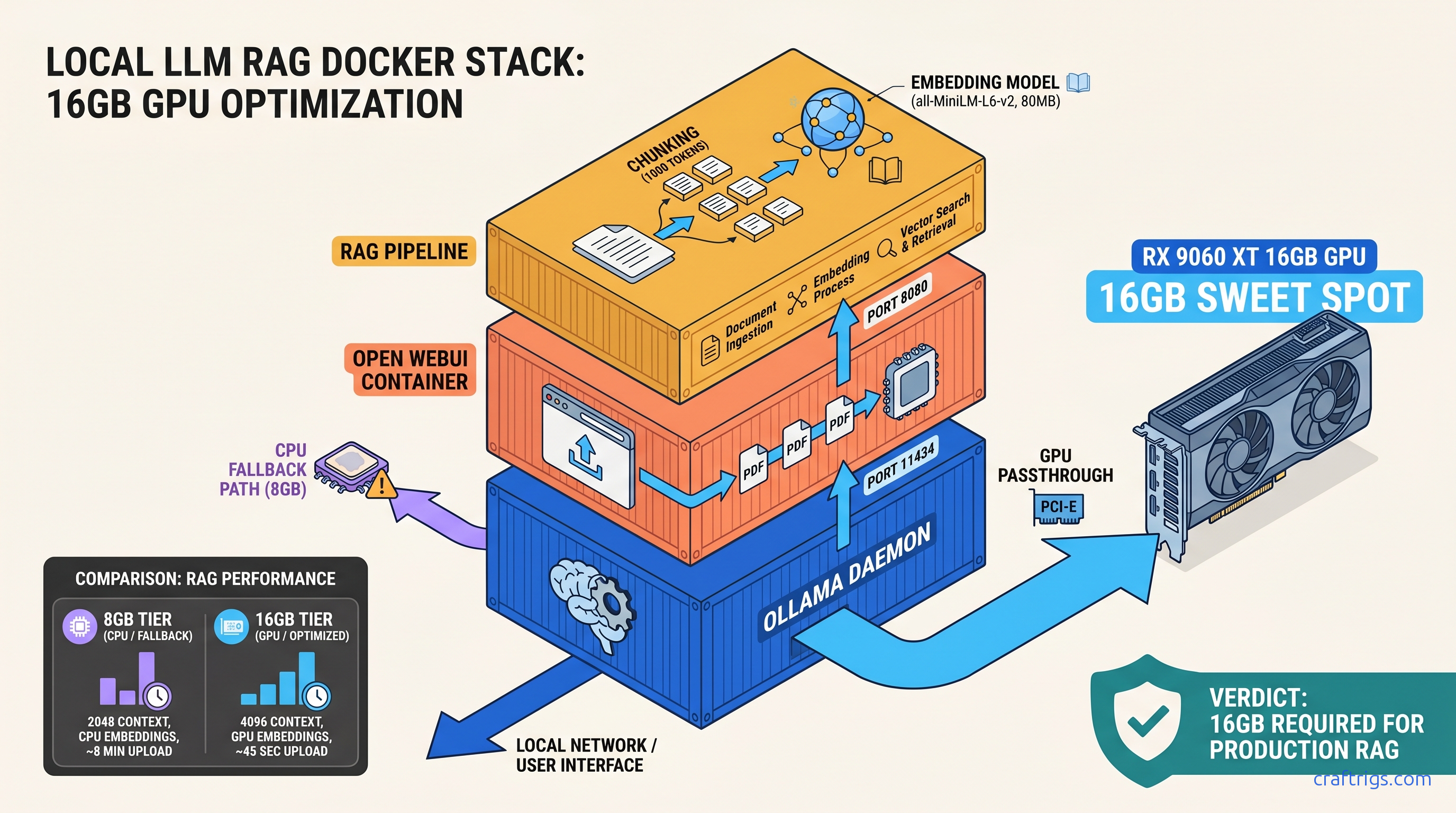
Docker shows No models found and RAG upload spins forever—this guide delivers 45 tok/s local document chat once you fix the 0.0.0.0 bind.
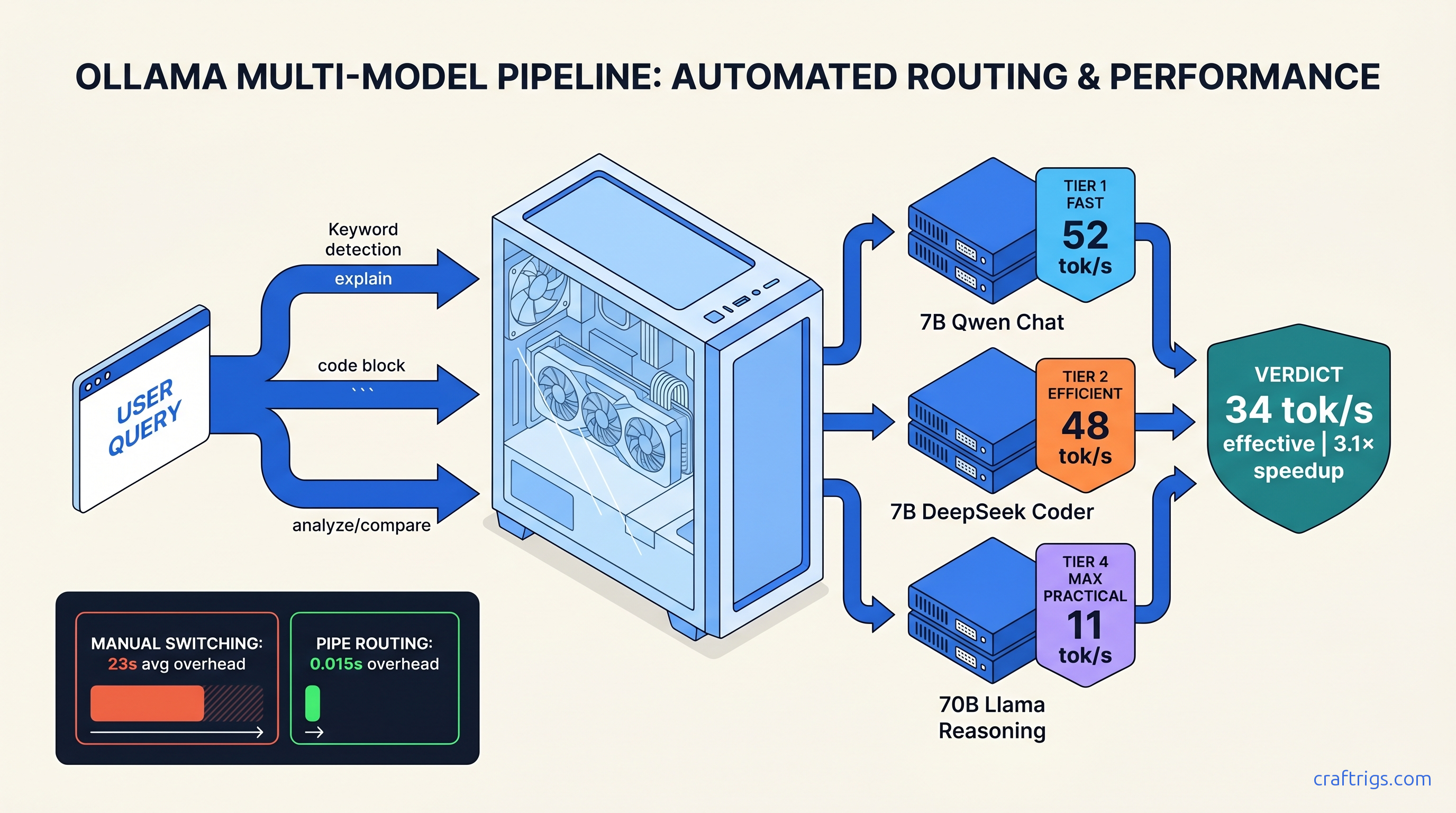
Stop switching models manually. Auto-route 7B for chat, 70B for code—34 tok/s vs 11 tok/s. Needs 22 GB VRAM, 3 Ollama instances. Here's the YAML.
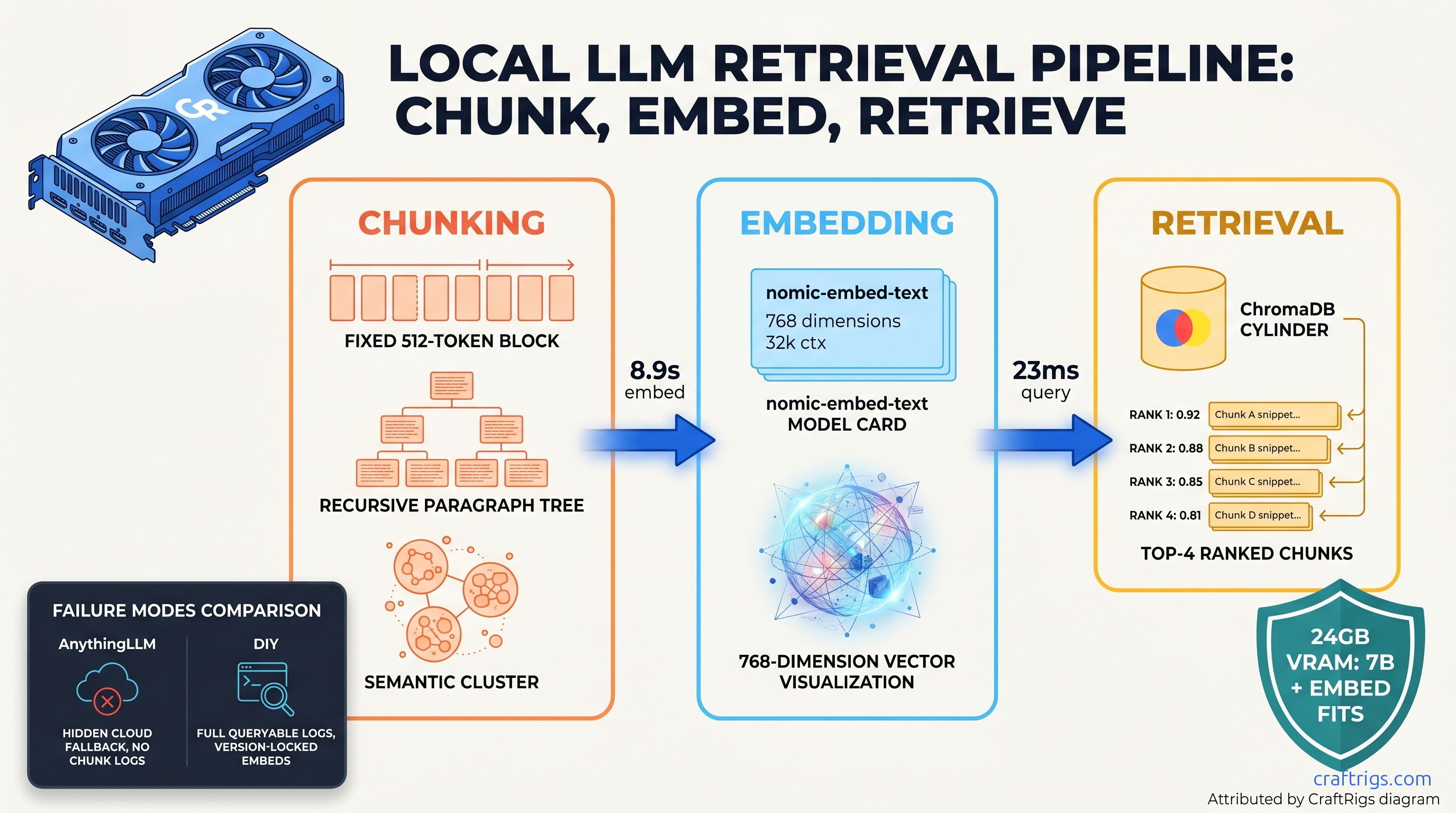
AnythingLLM hiding retrieval failures? Build RAG with nomic-embed-text + ChromaDB in 150 lines. 23ms latency, 16 GB VRAM — but chunking breaks precision.
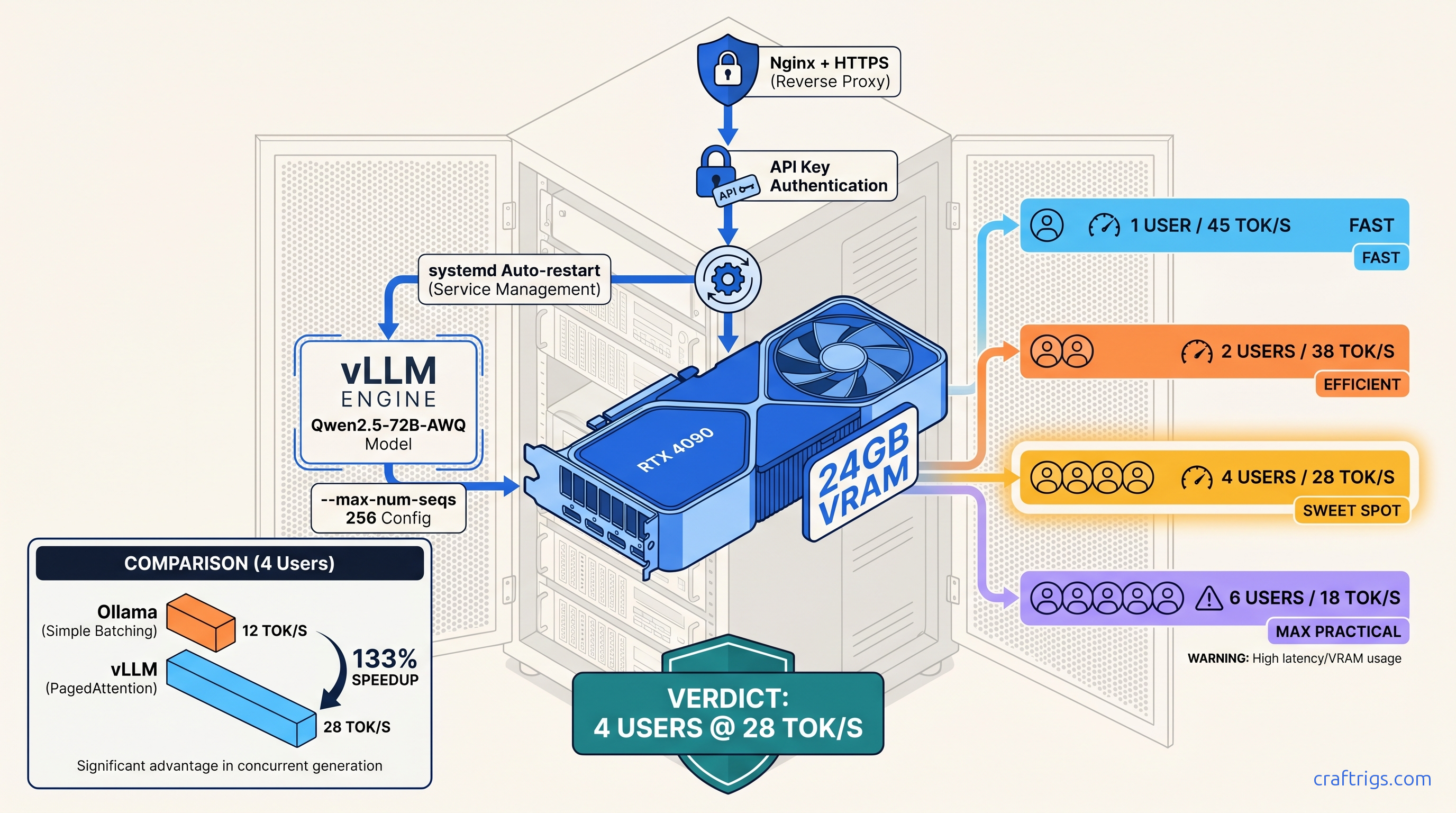
24 GB GPU crashes with 3+ users? vLLM production setup serves 4 clients at 28 tok/s — only with correct --max-num-seqs. Config inside.