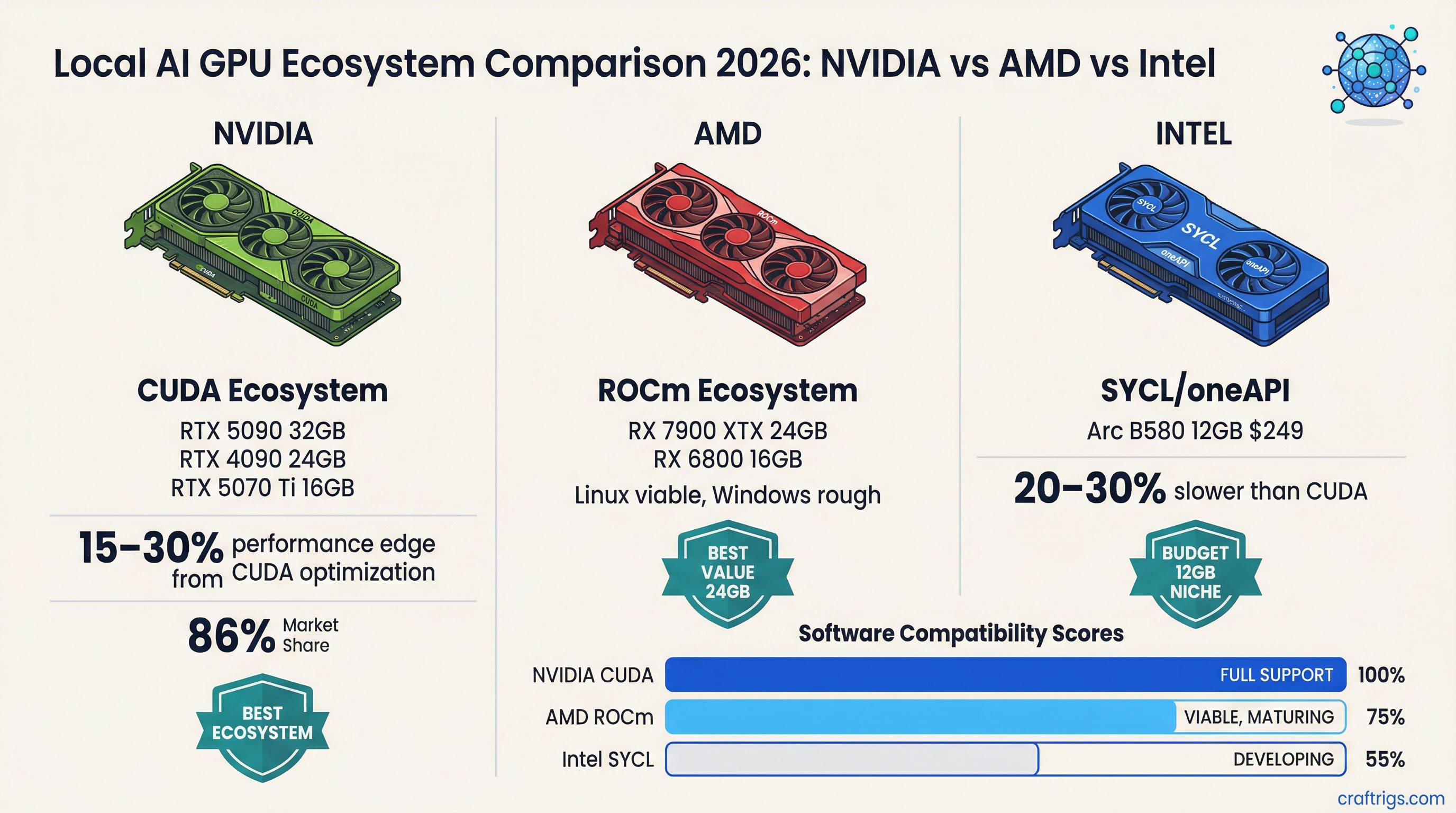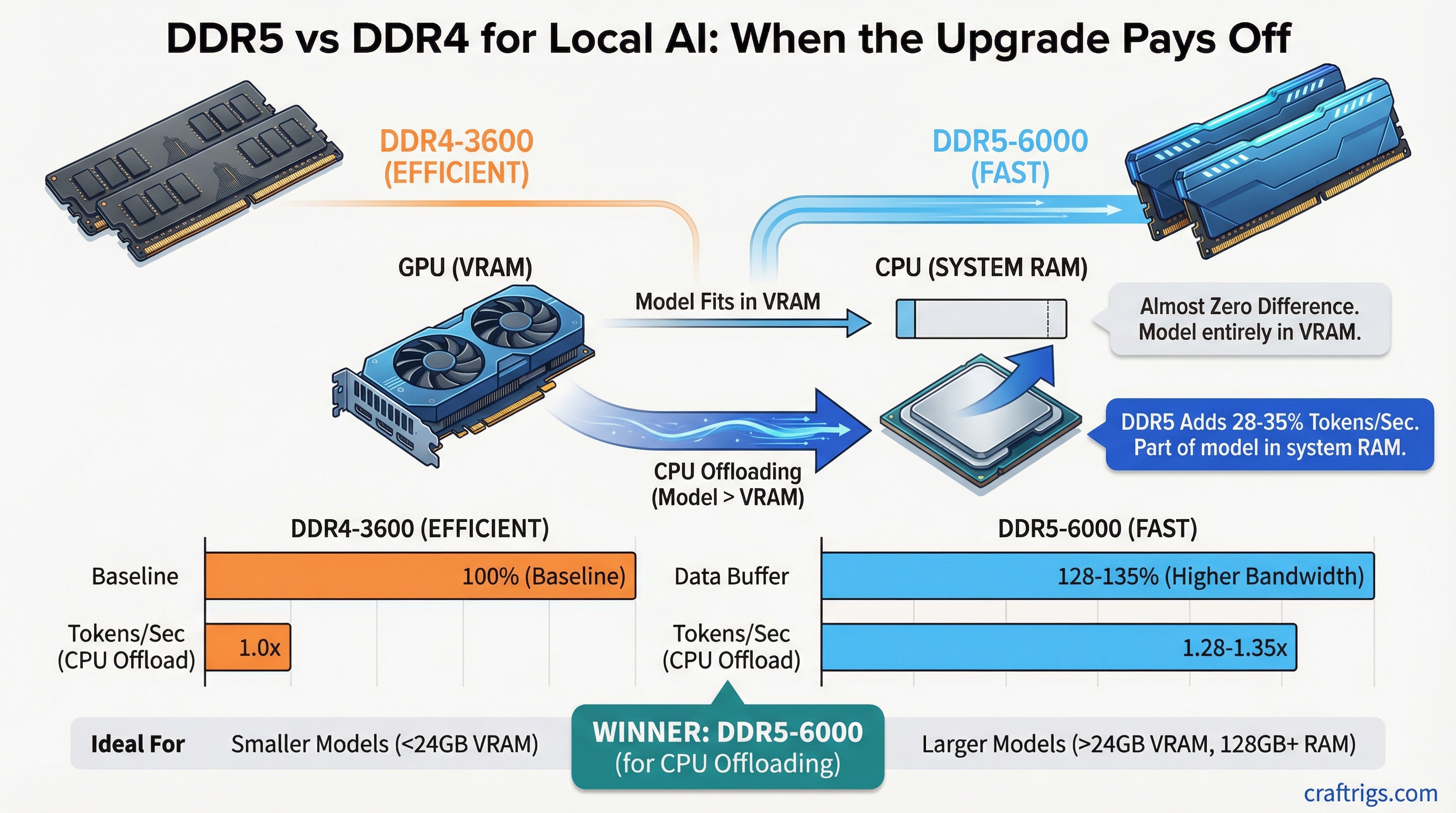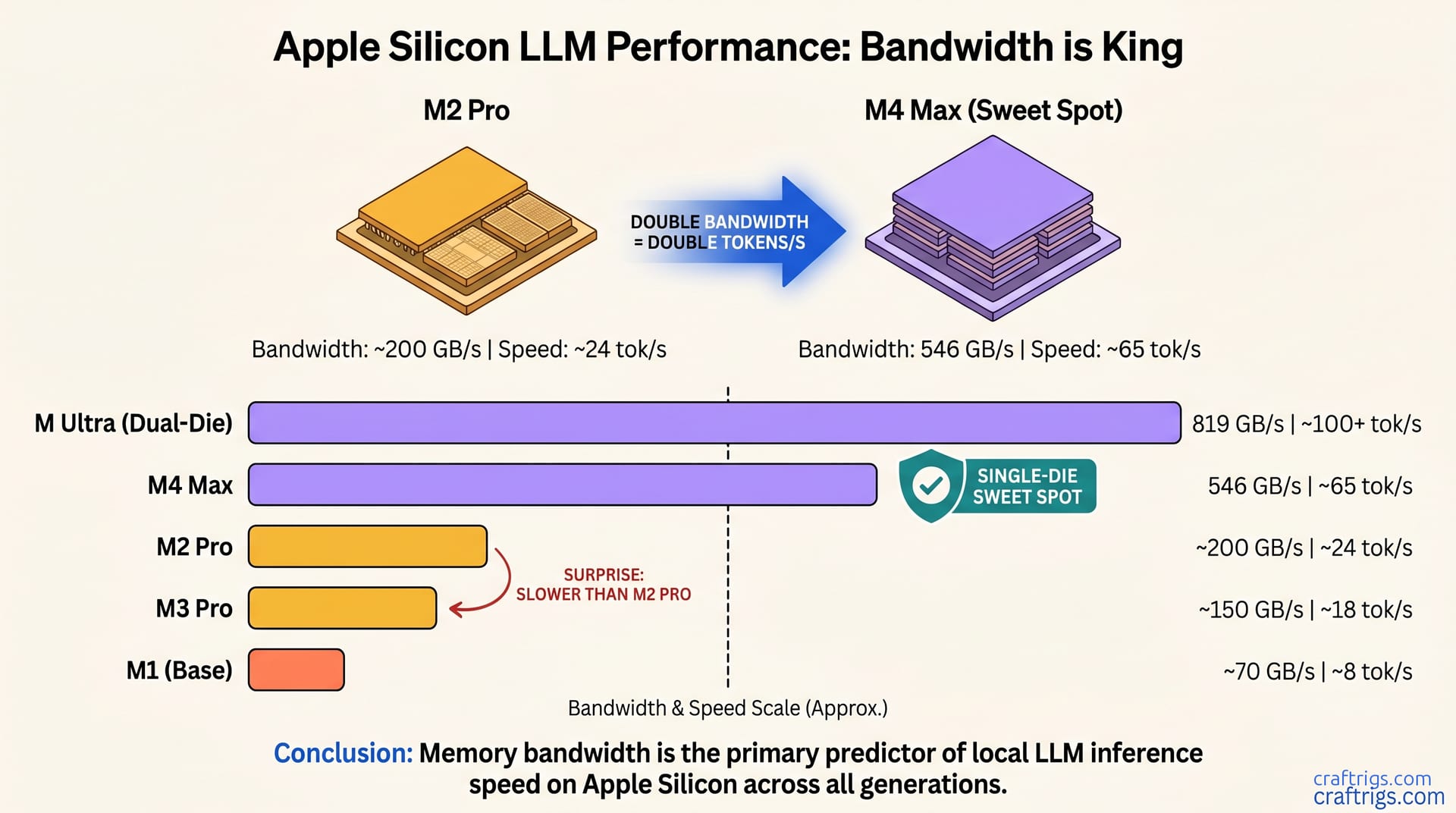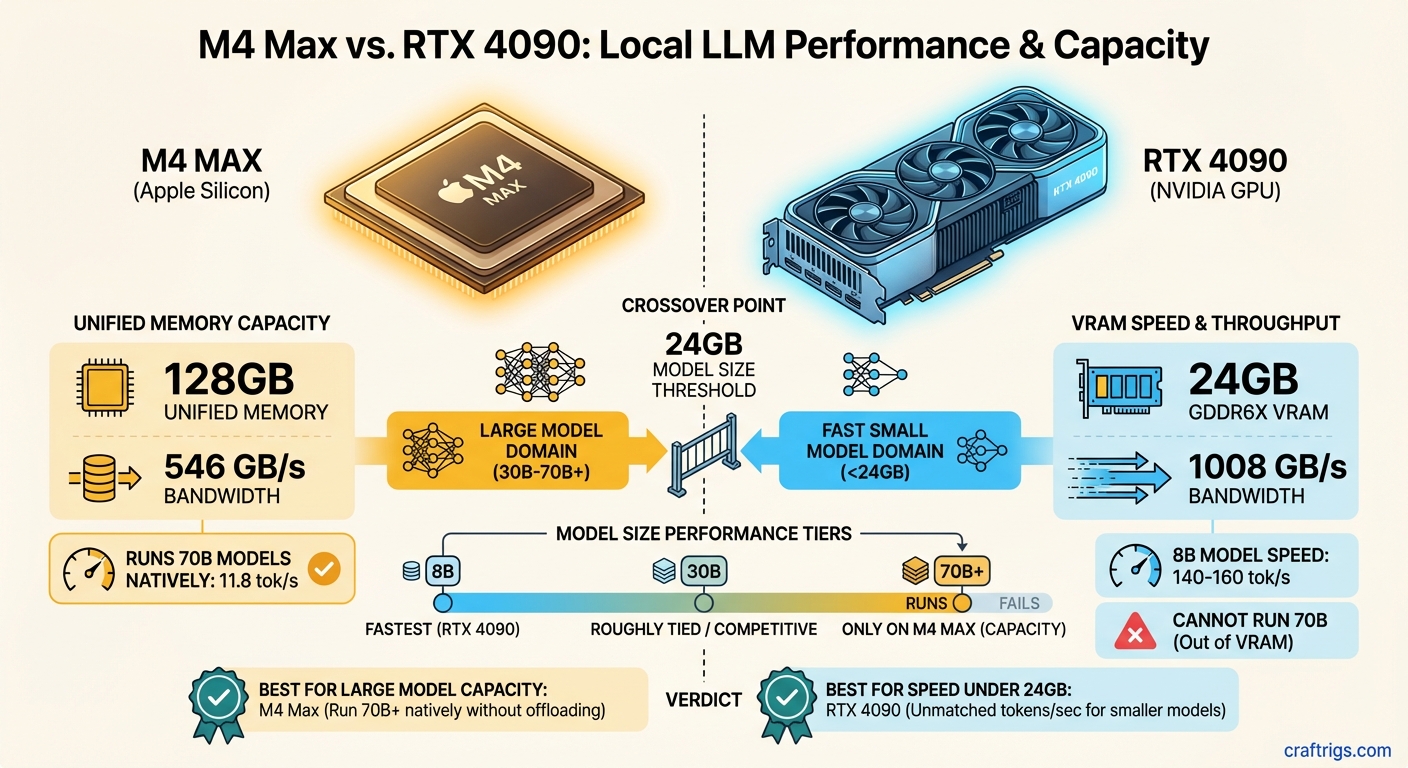
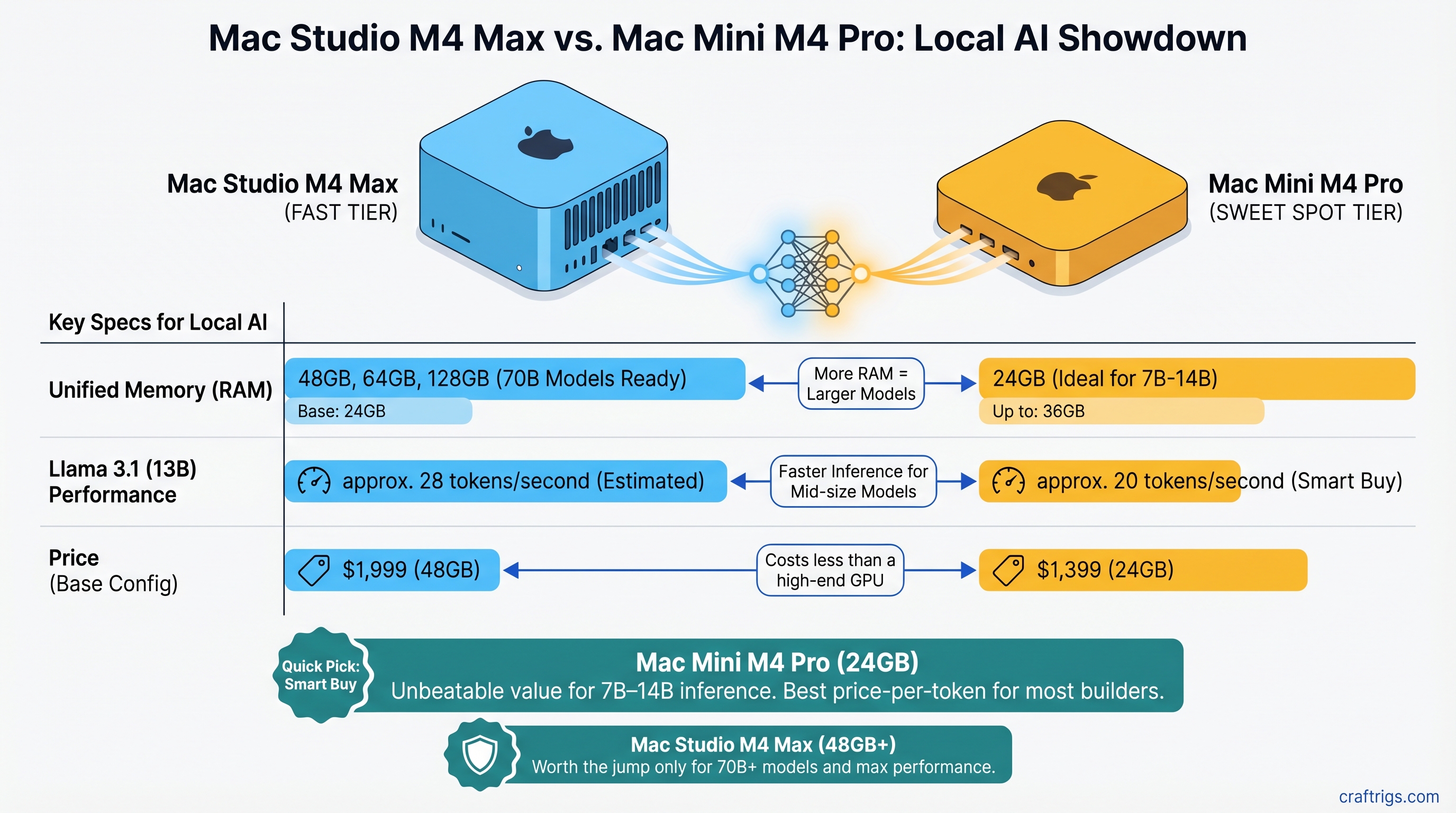
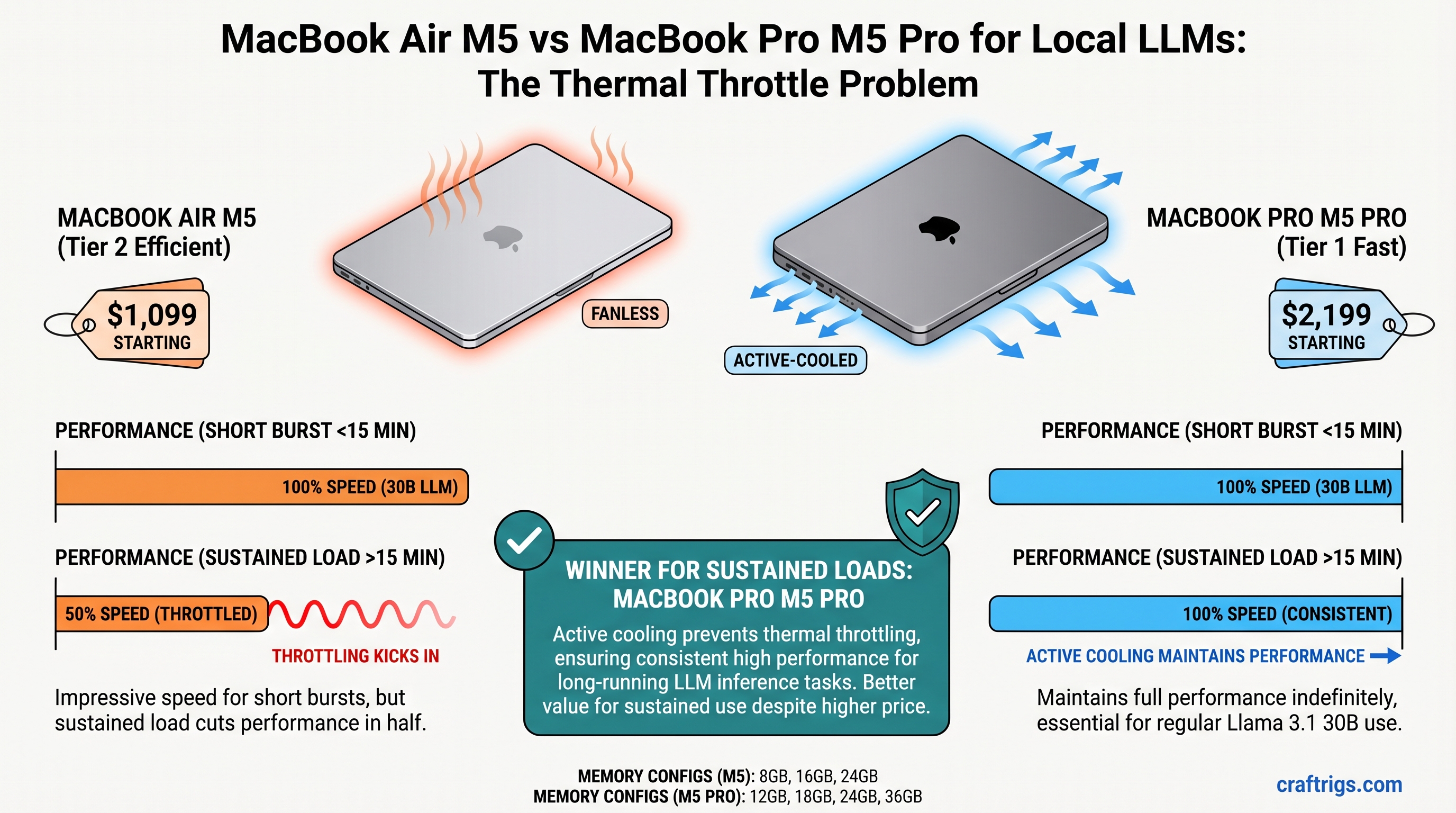
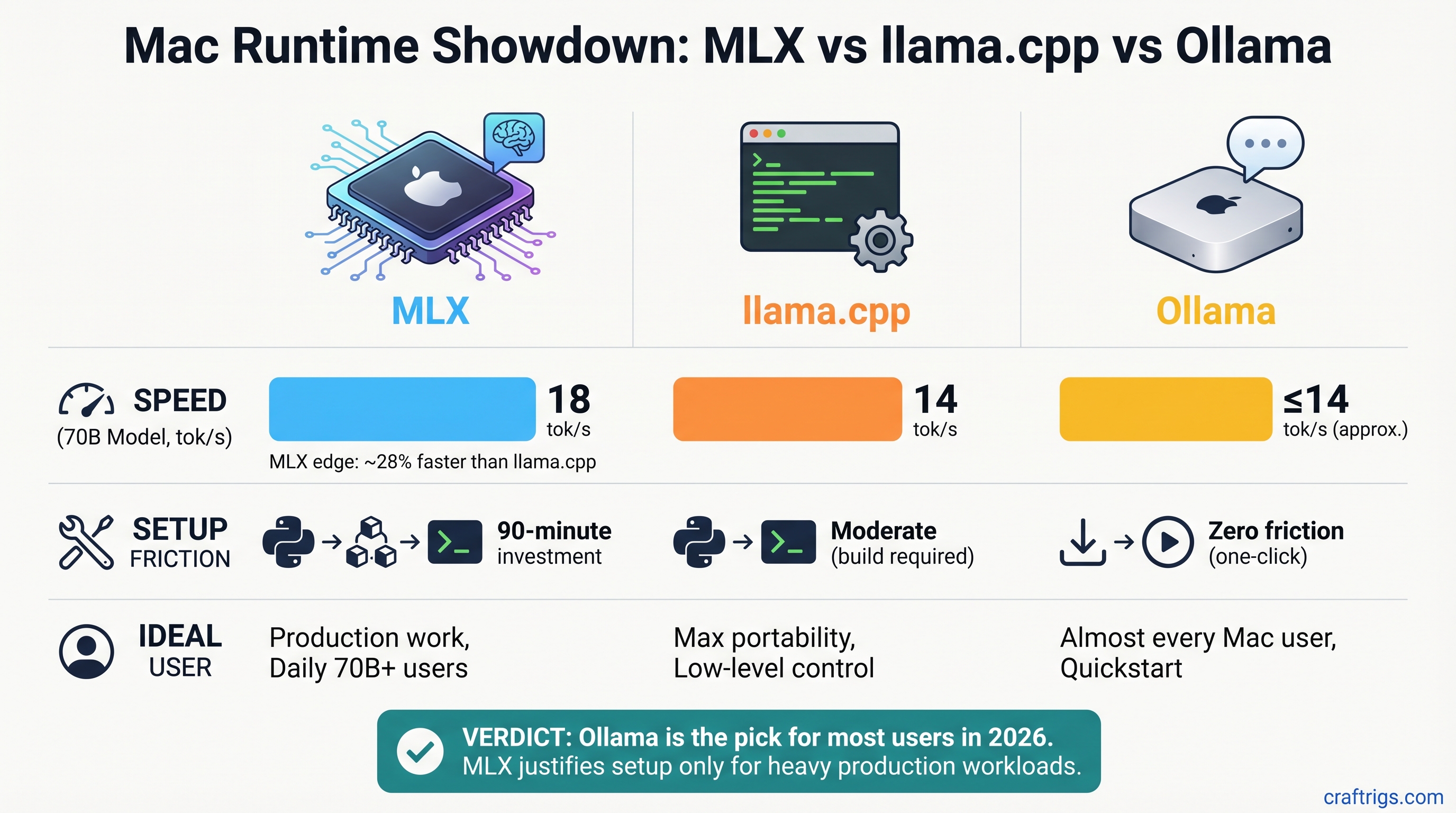
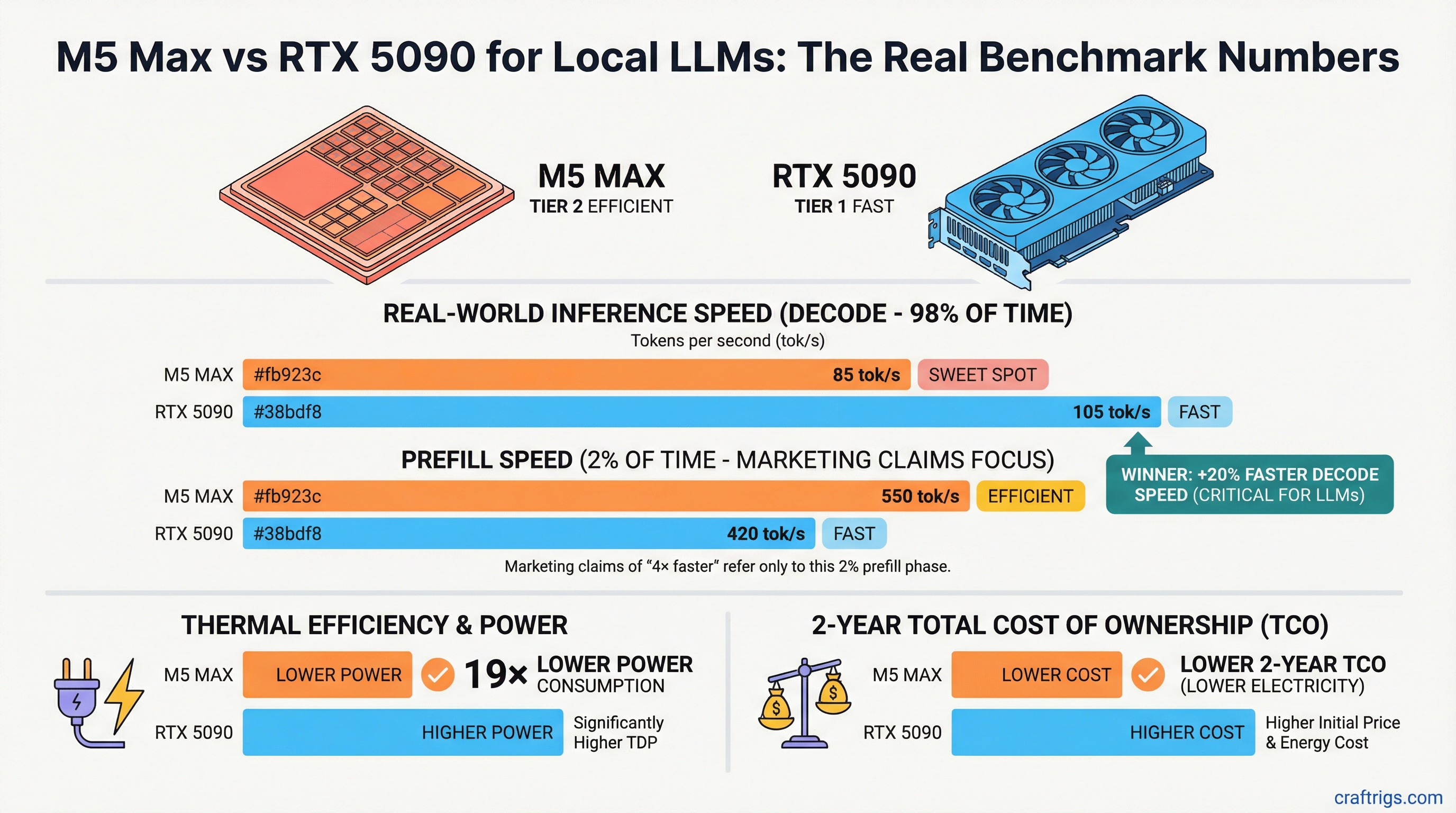
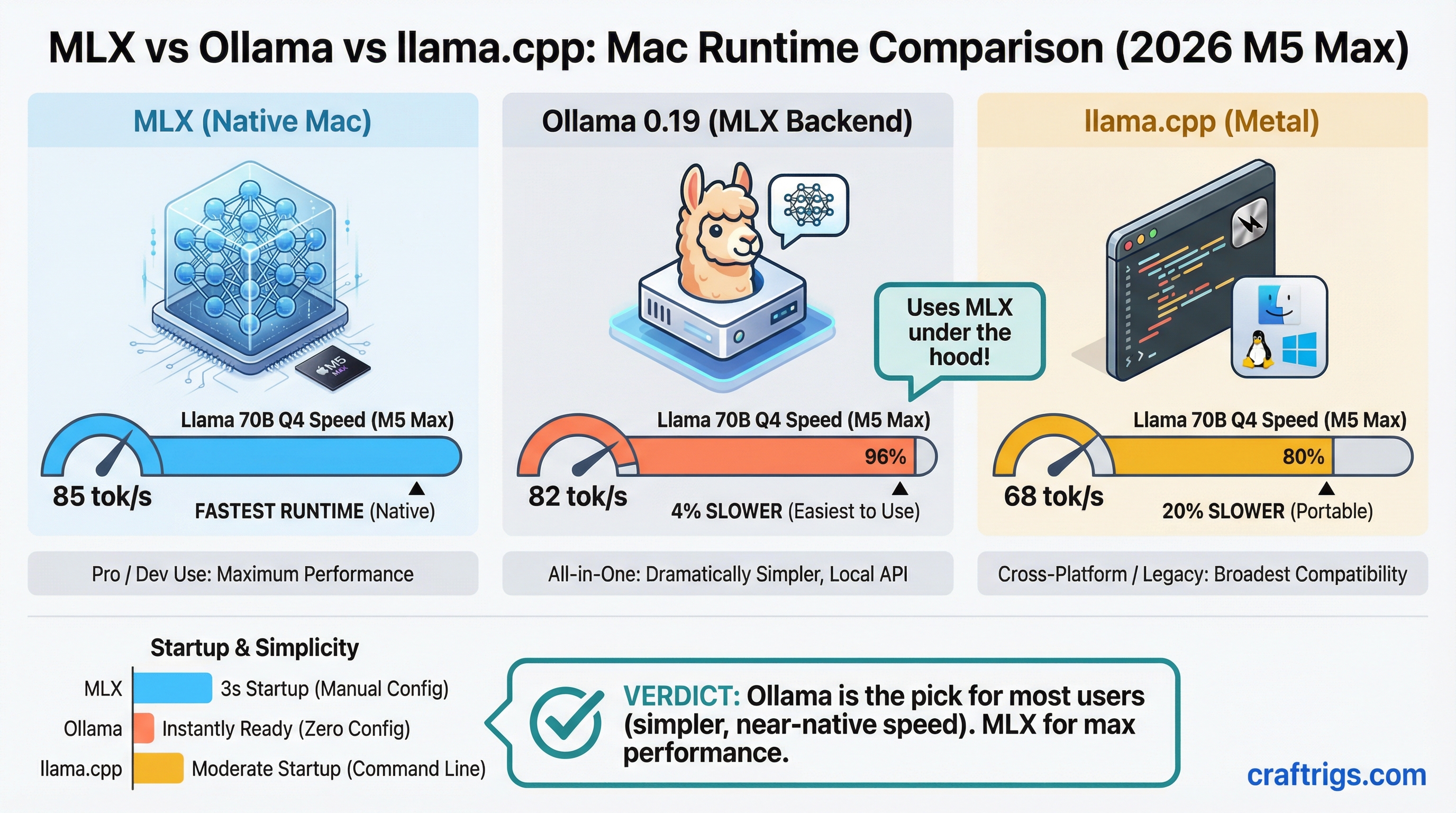
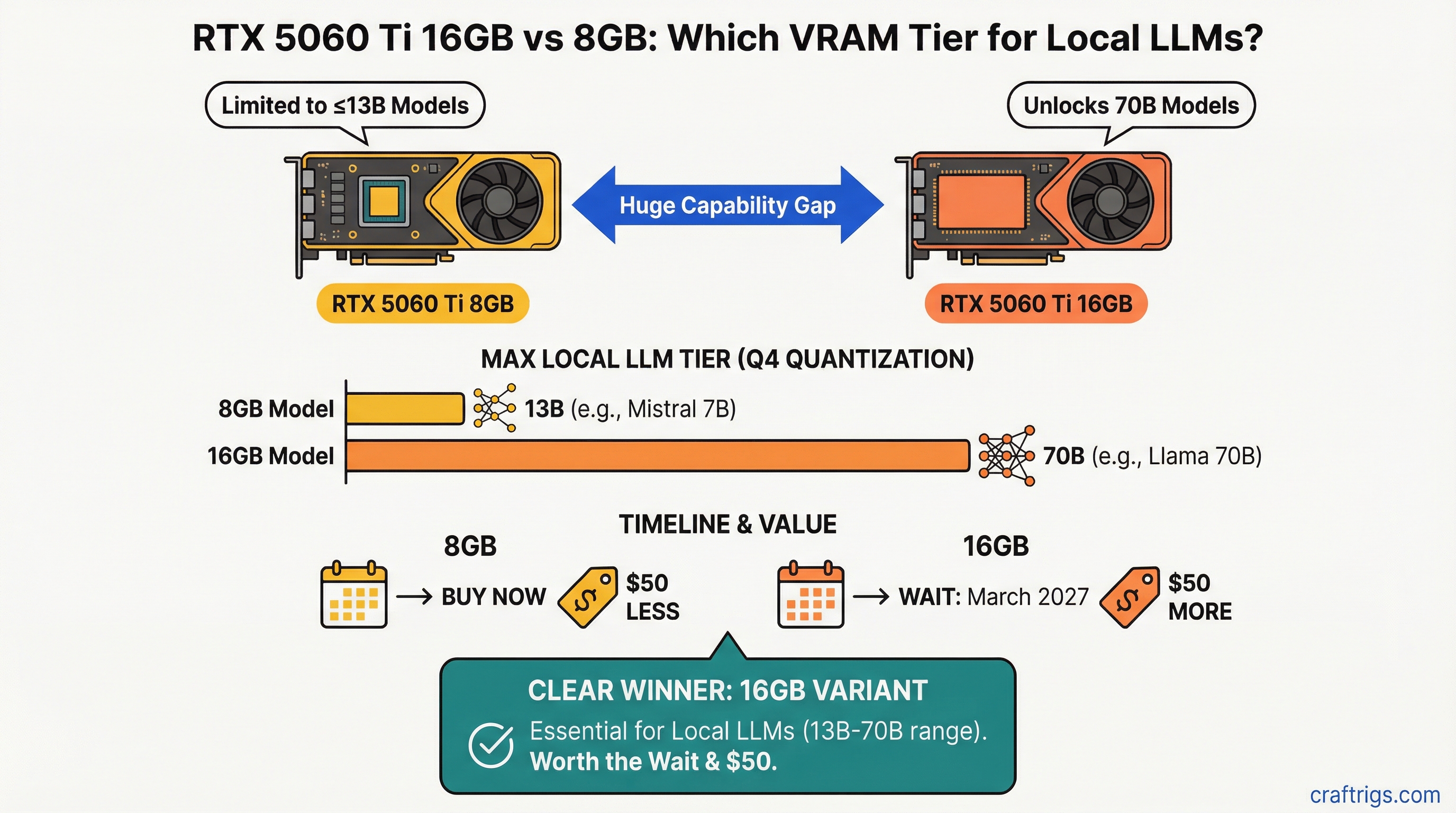
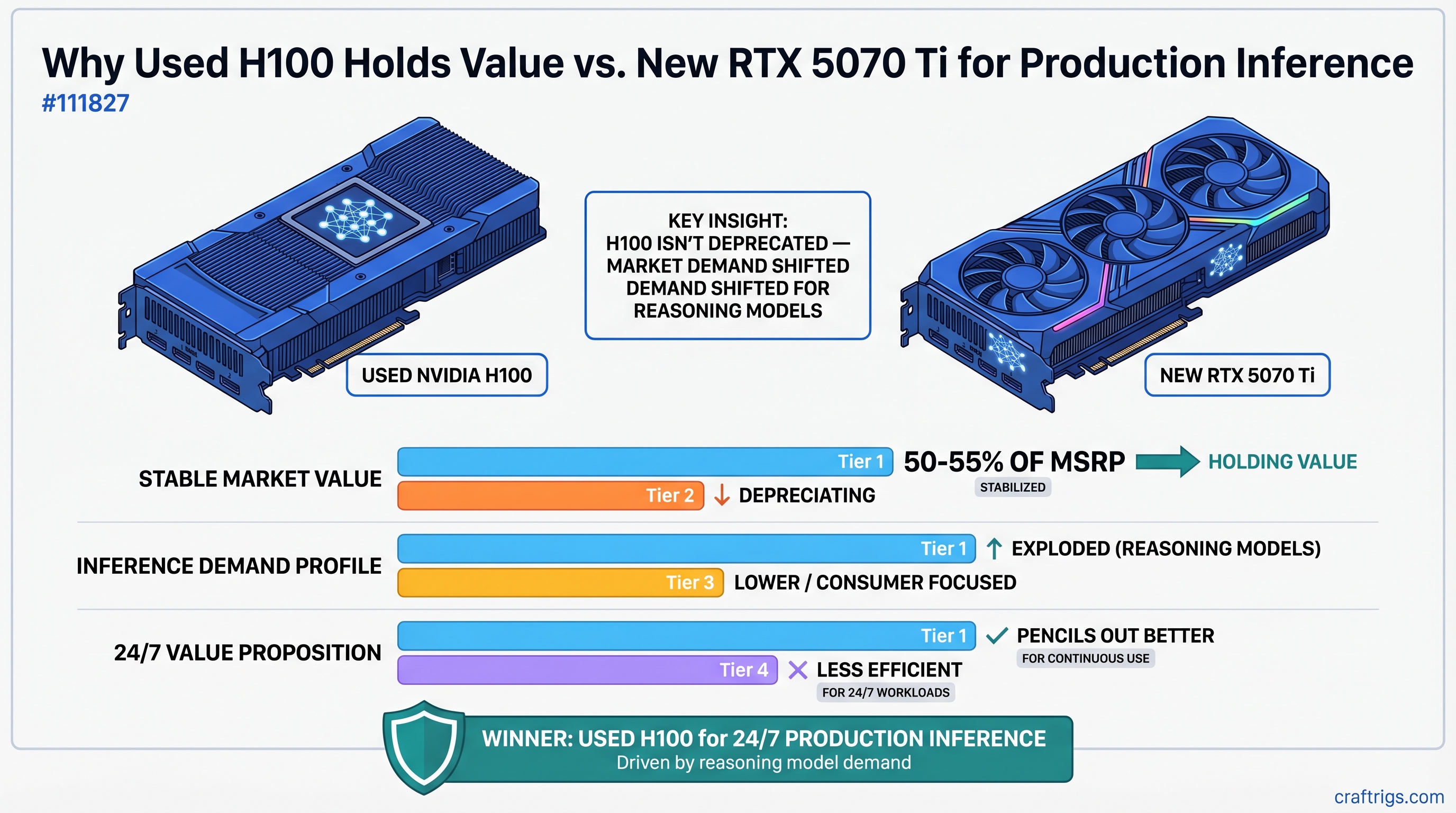
Hardware Comparison
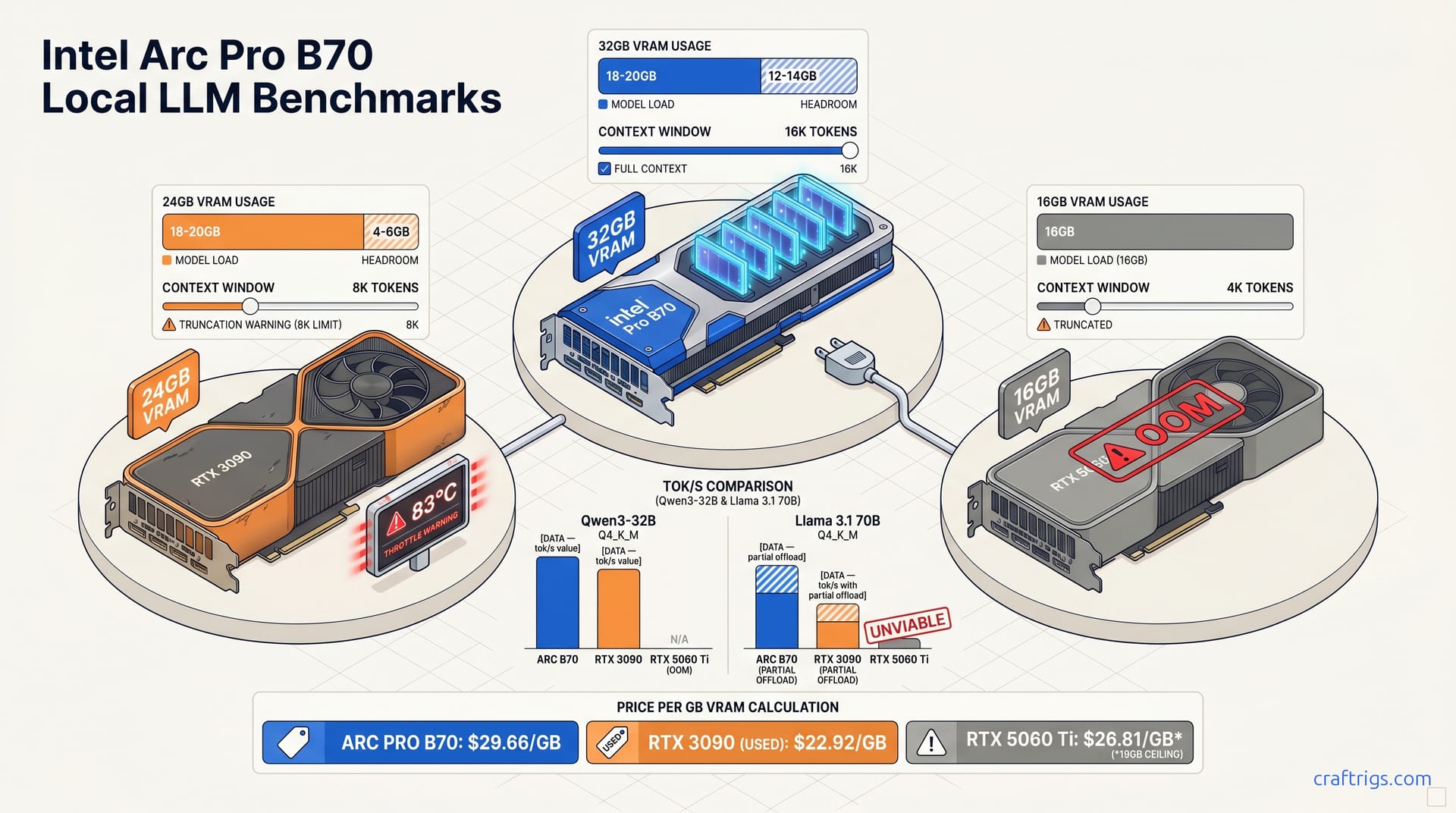
Arc Pro B70 vs RTX 3090: 32GB for $949?
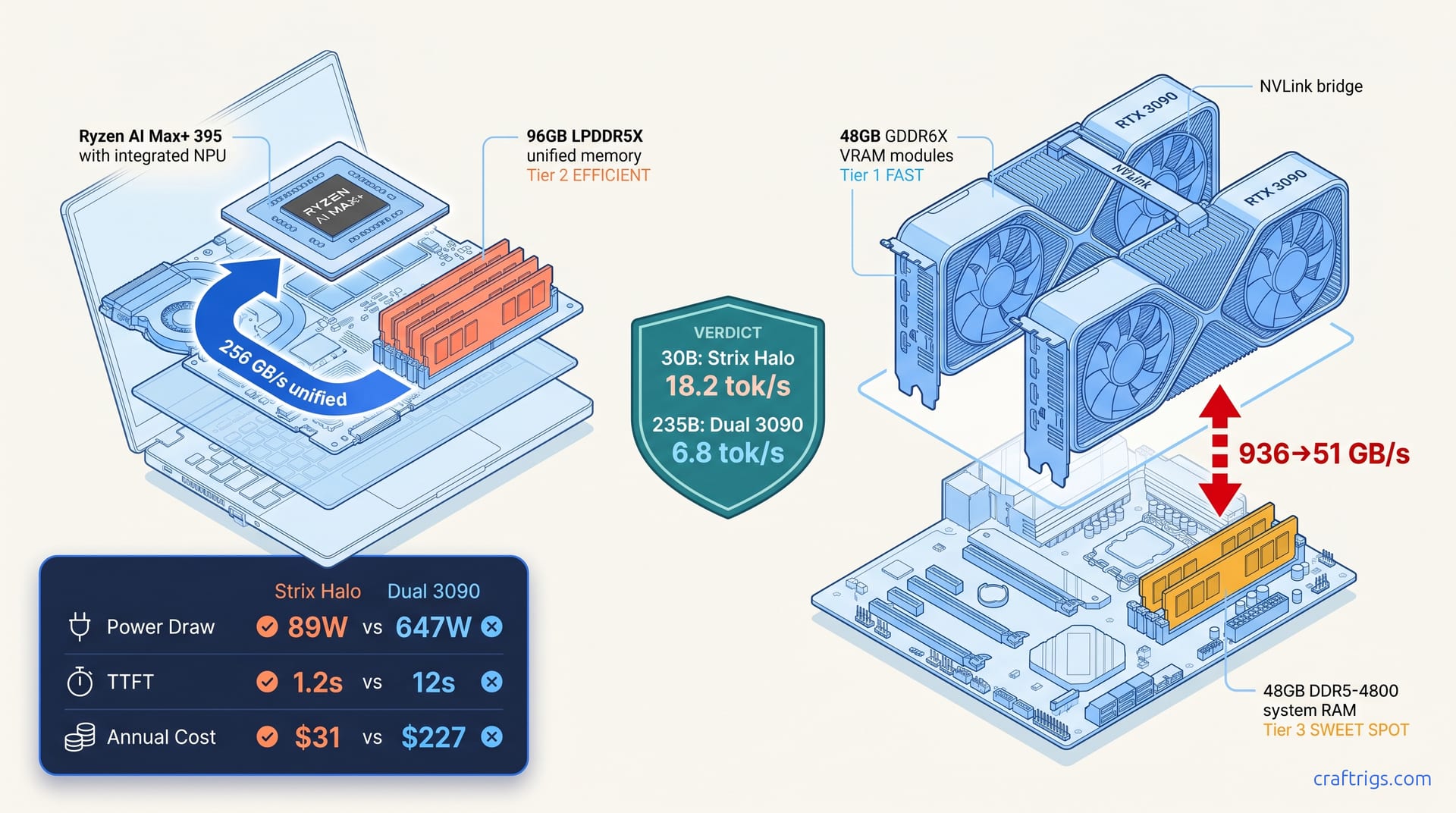
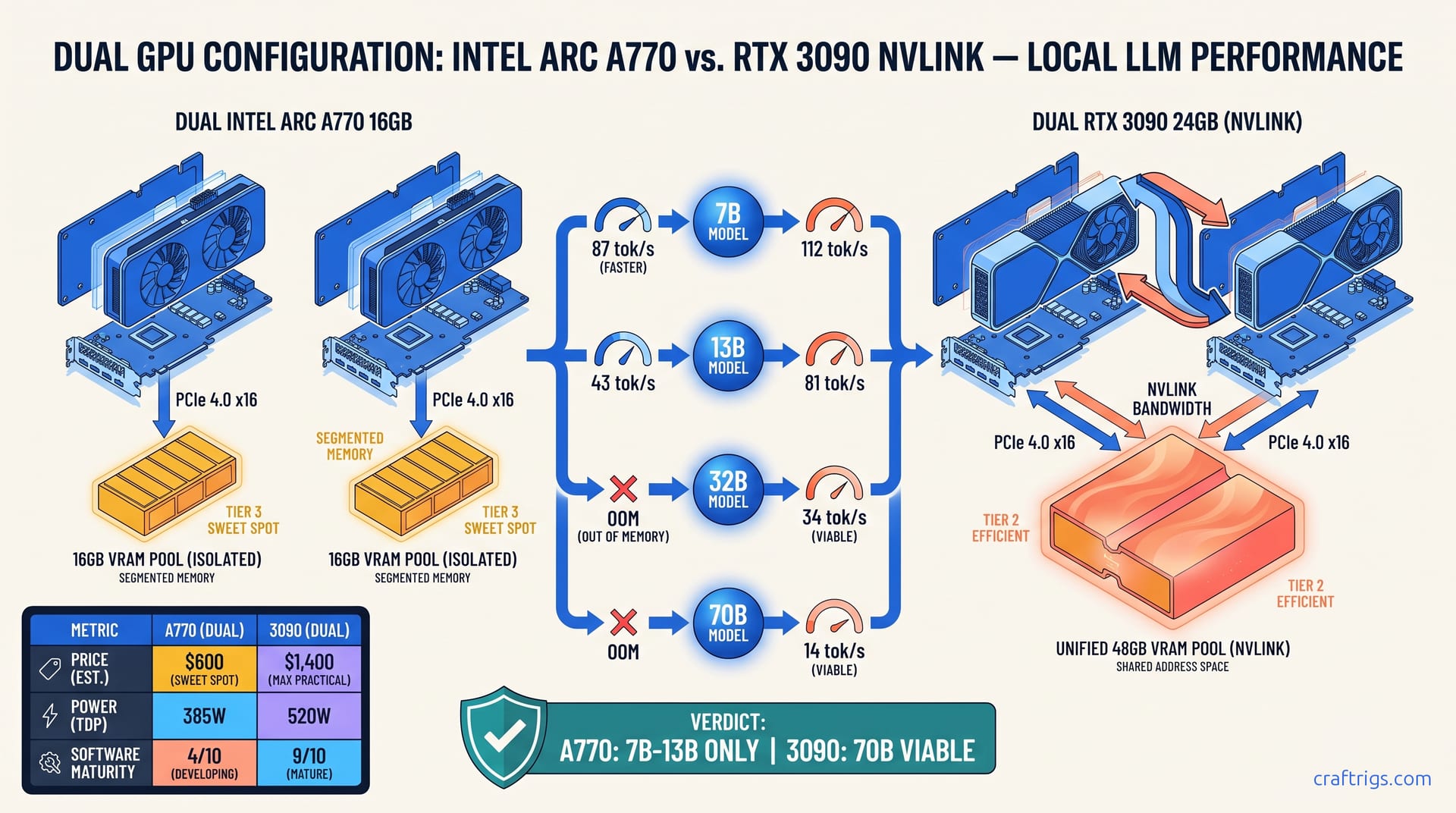
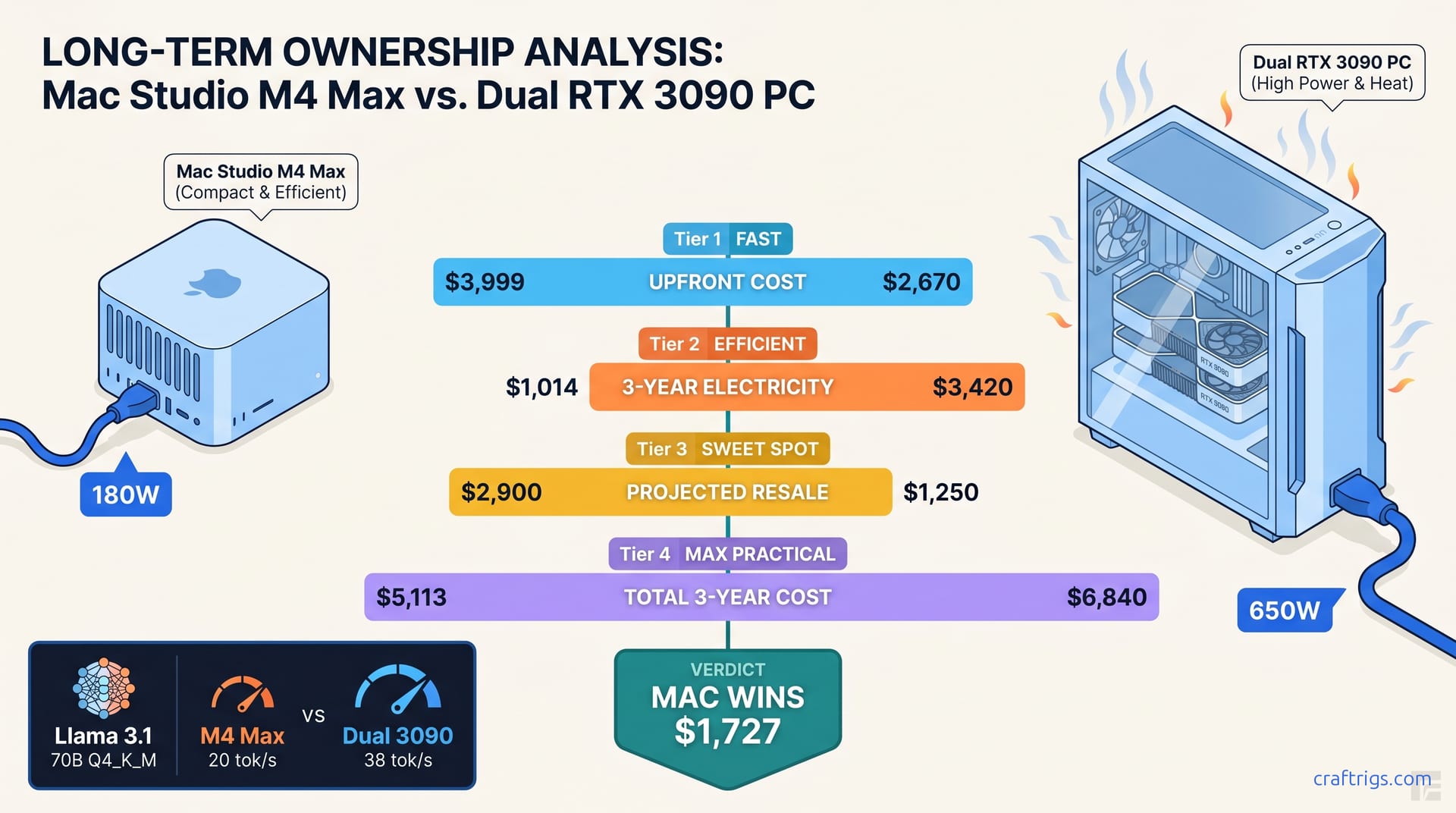
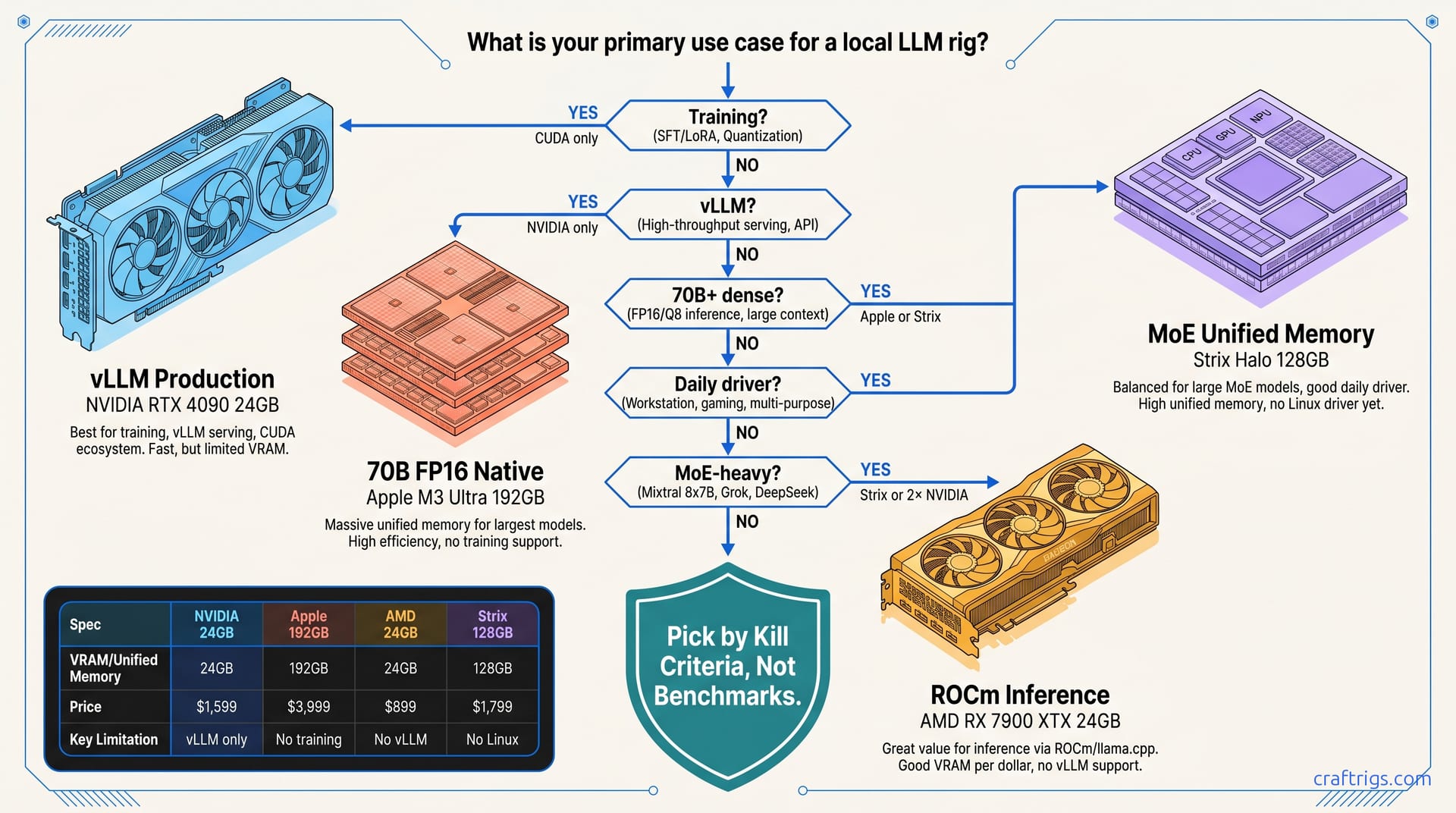
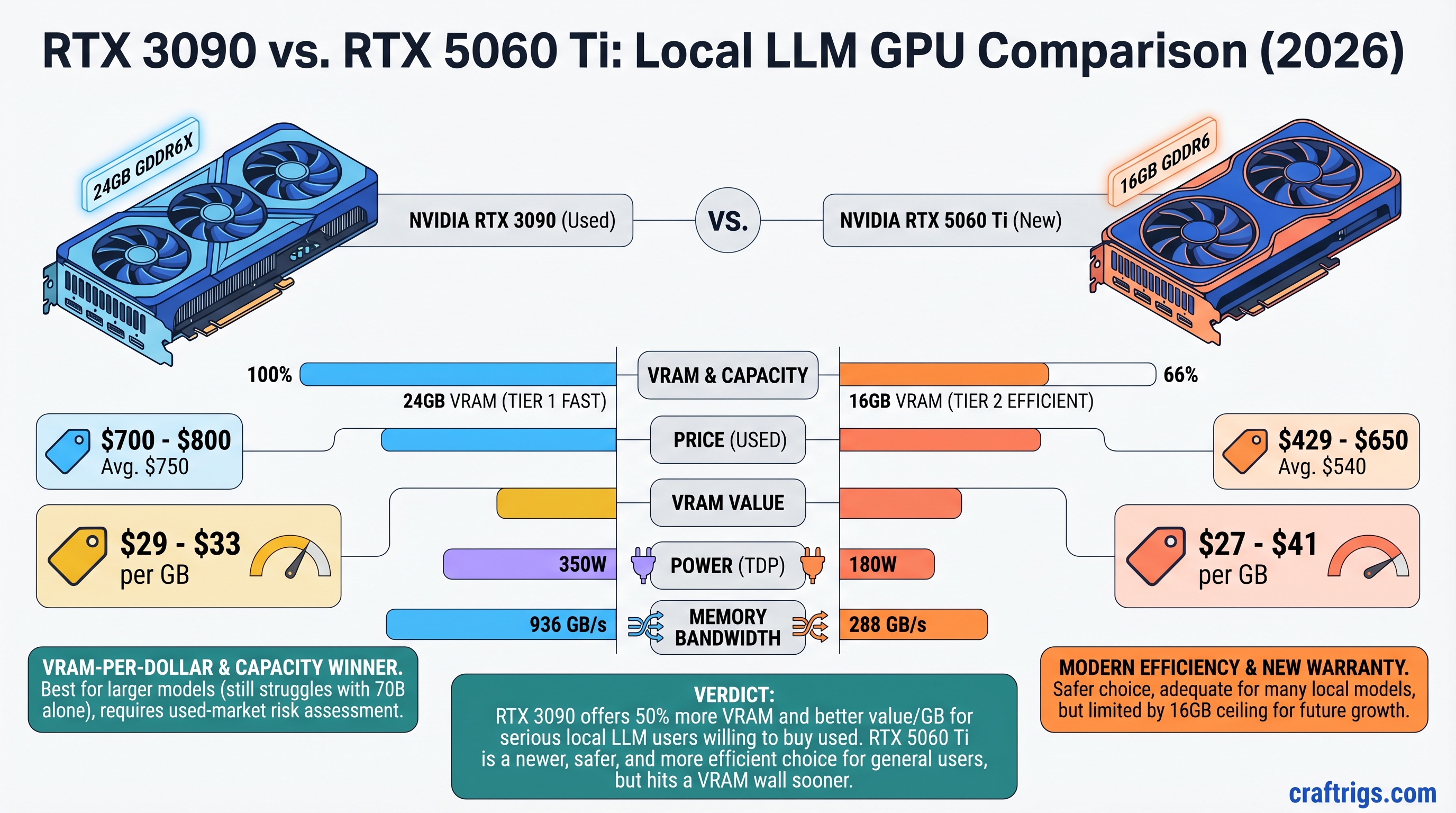
32GB VRAM under $1K sounds perfect for local LLMs—until you benchmark IPEX-LLM against CUDA. Arc Pro B70 tok/s lags RTX 3090 on 70B offload, wins only at 32B context headroom. Buy Intel for the gigabytes, buy used NVIDIA for the speed.
intel-arc-pro-b70-local-llm-benchmarks

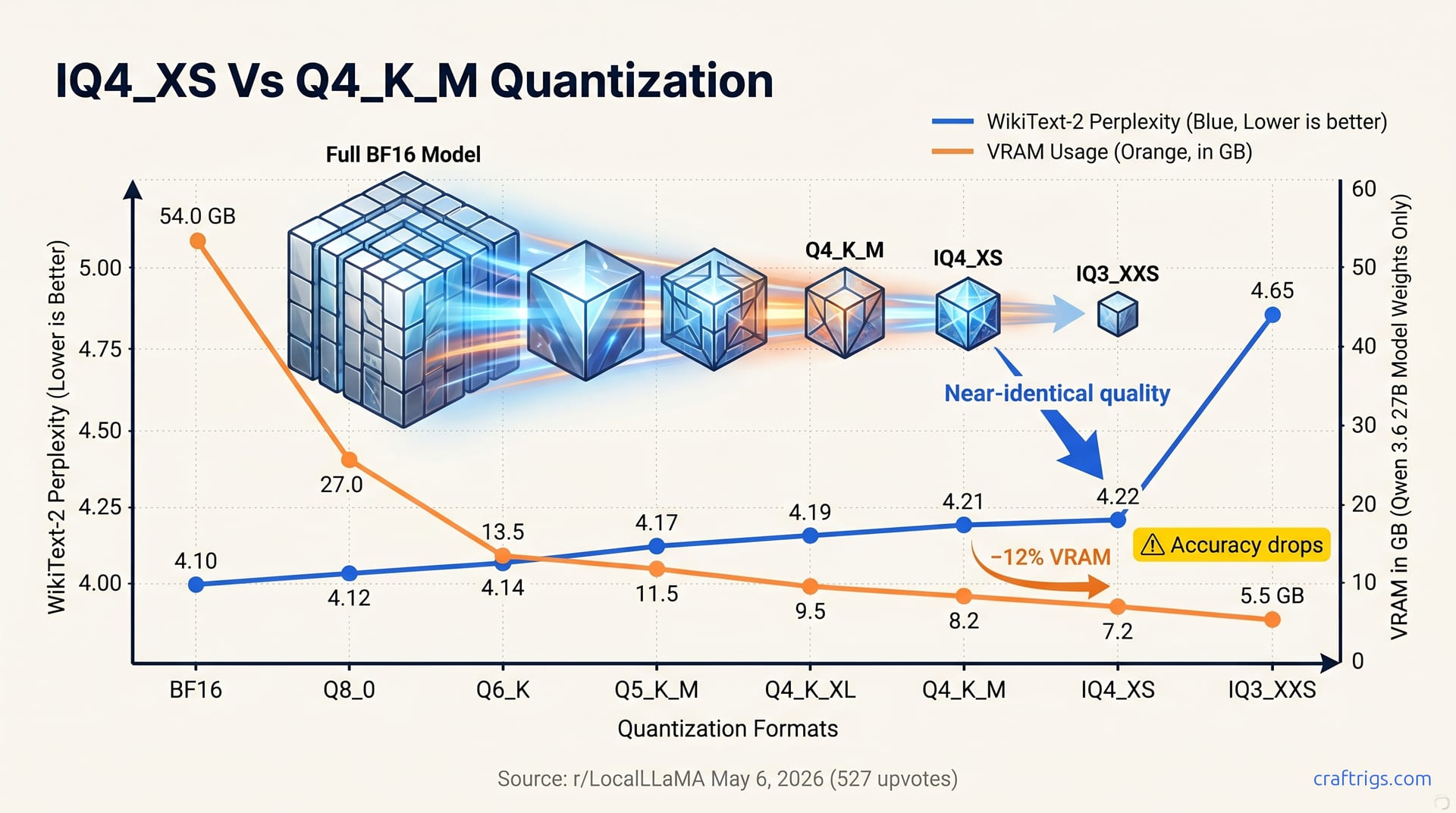
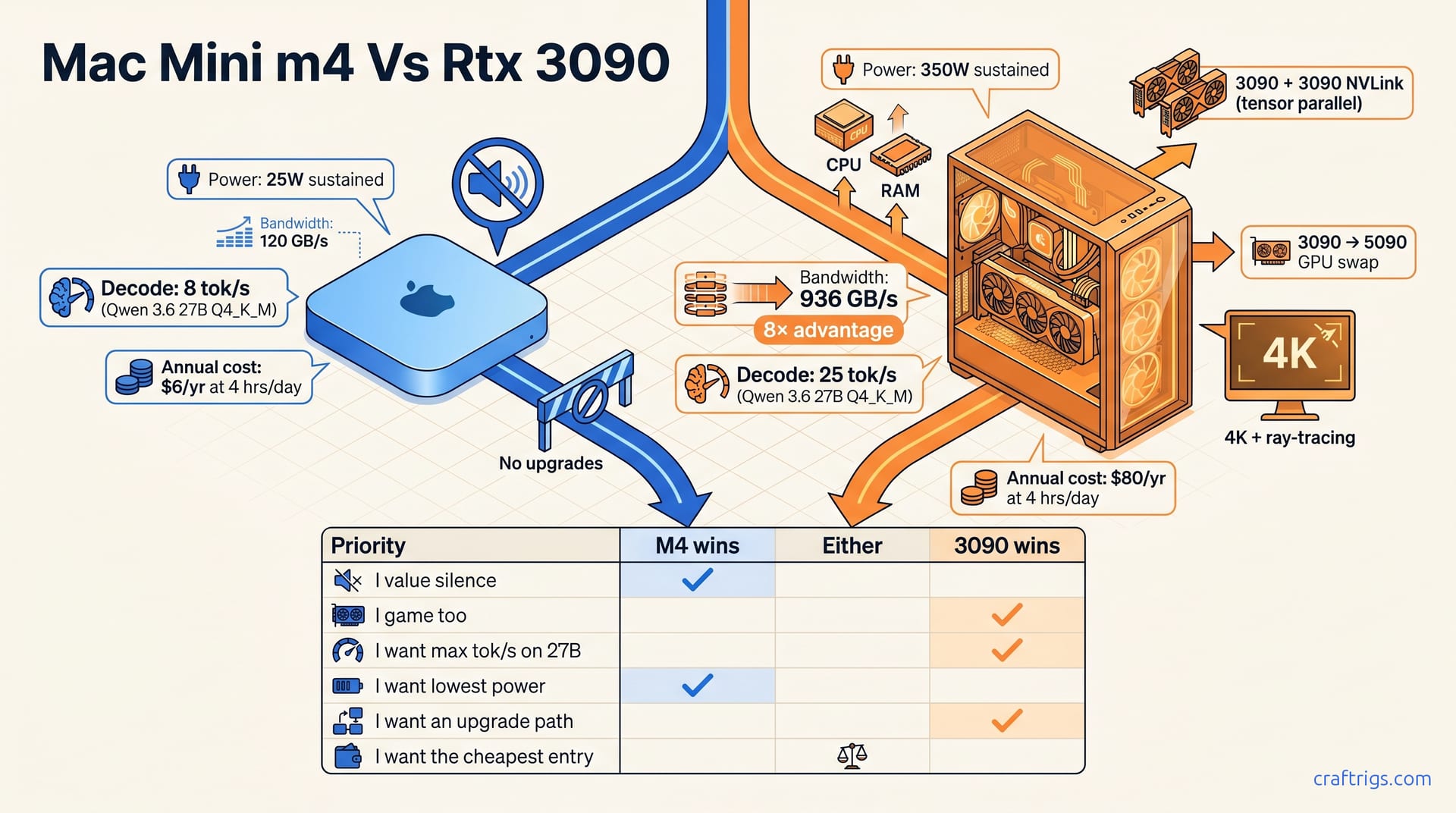
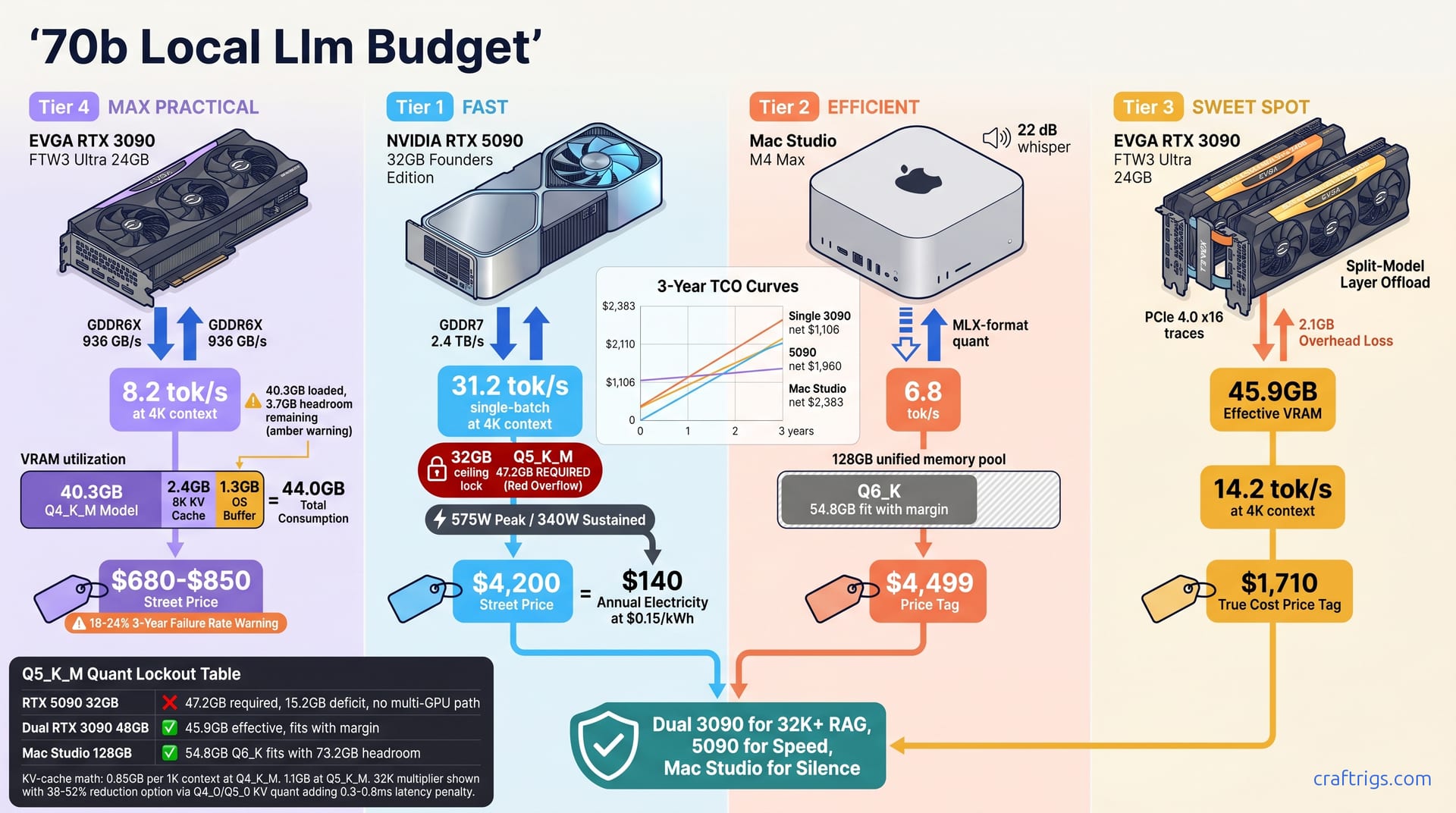
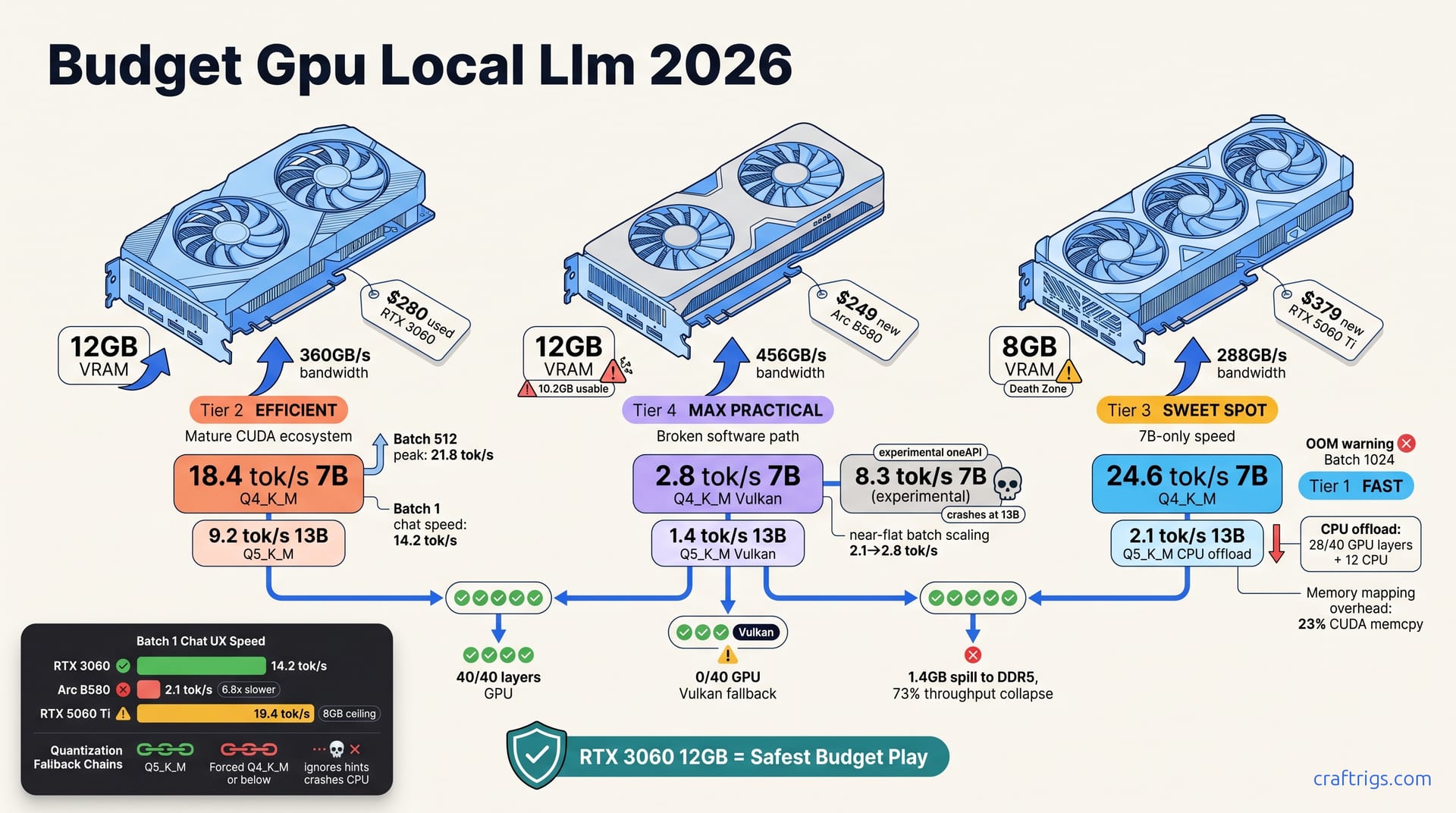
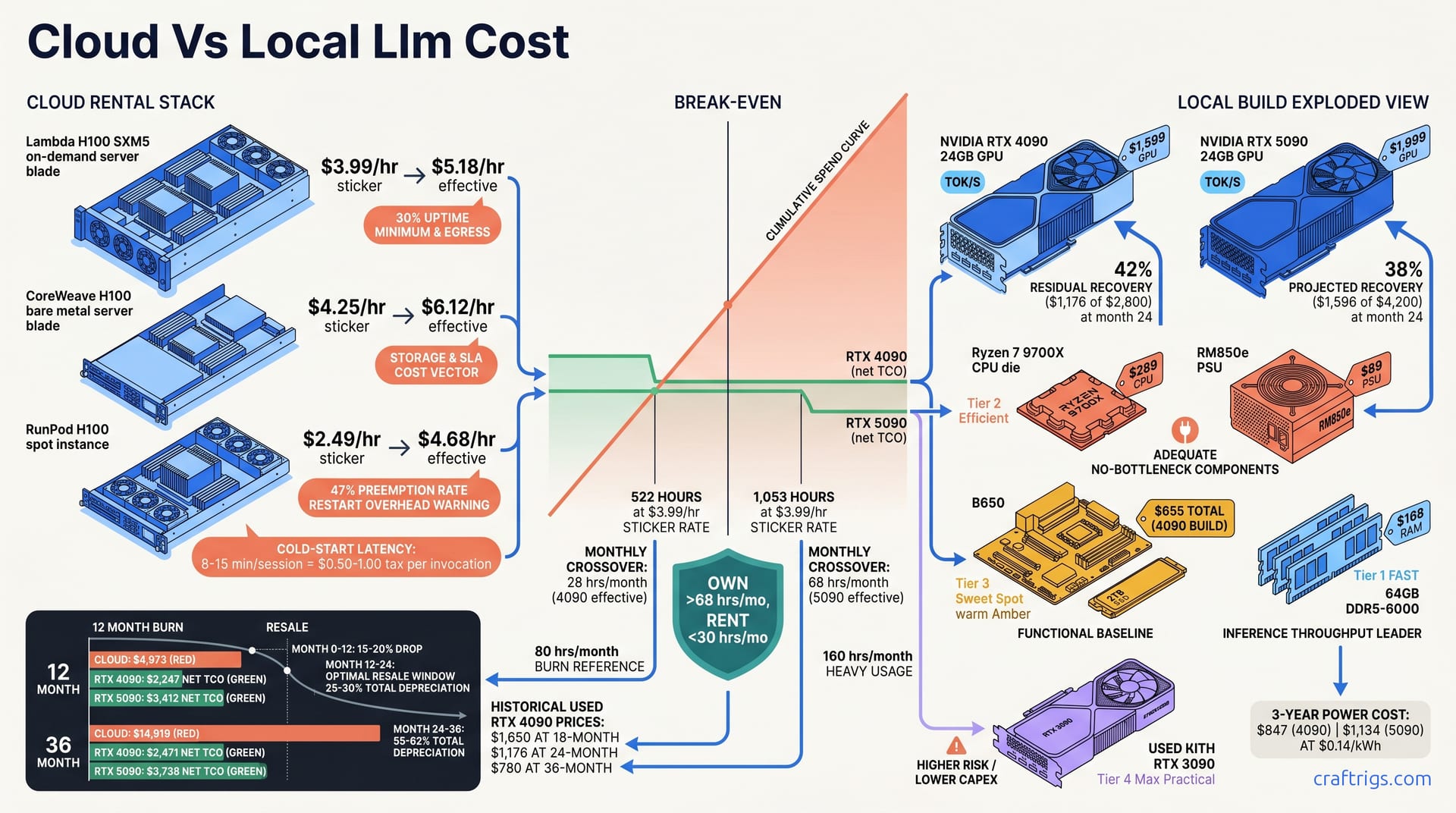
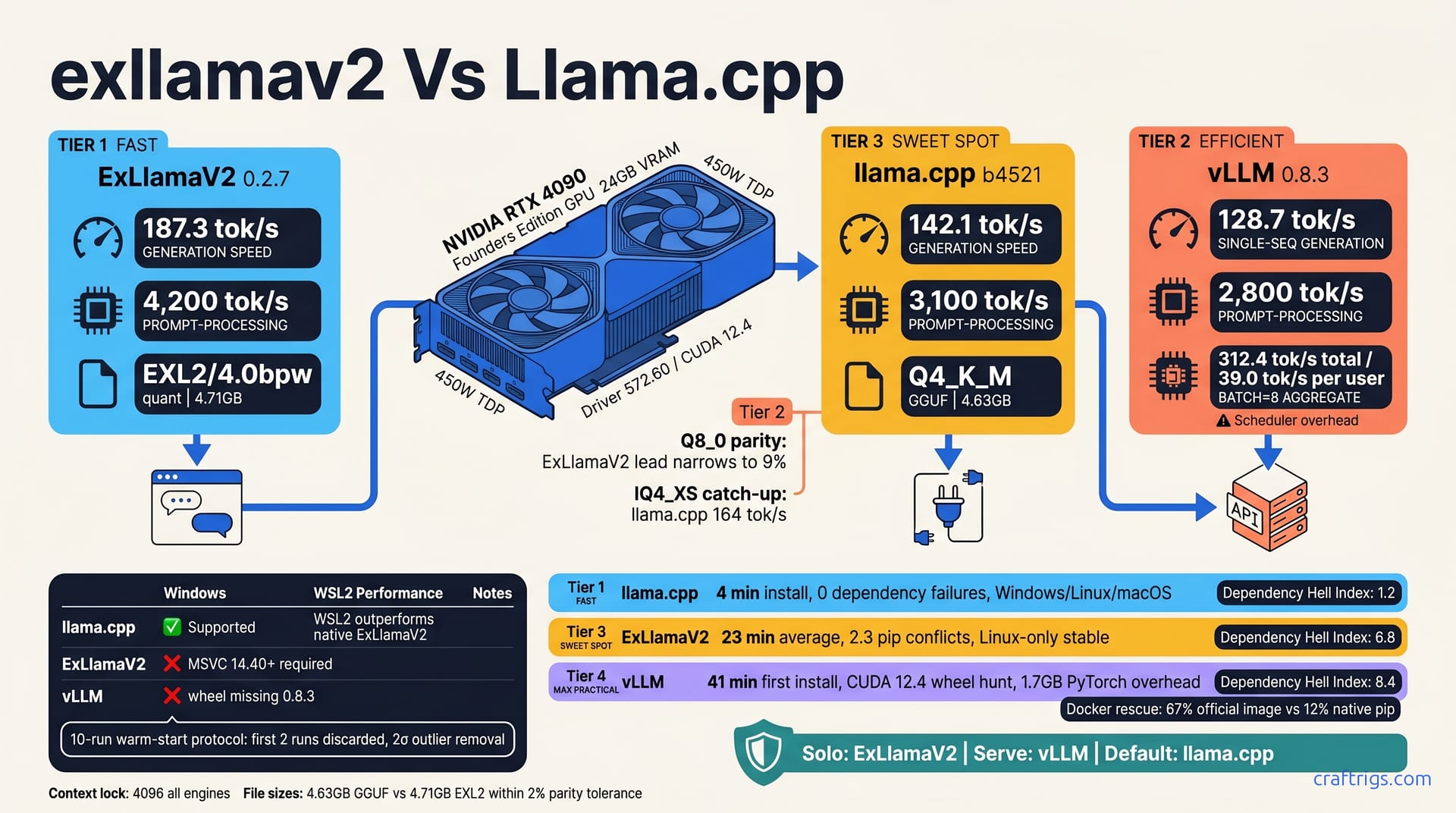
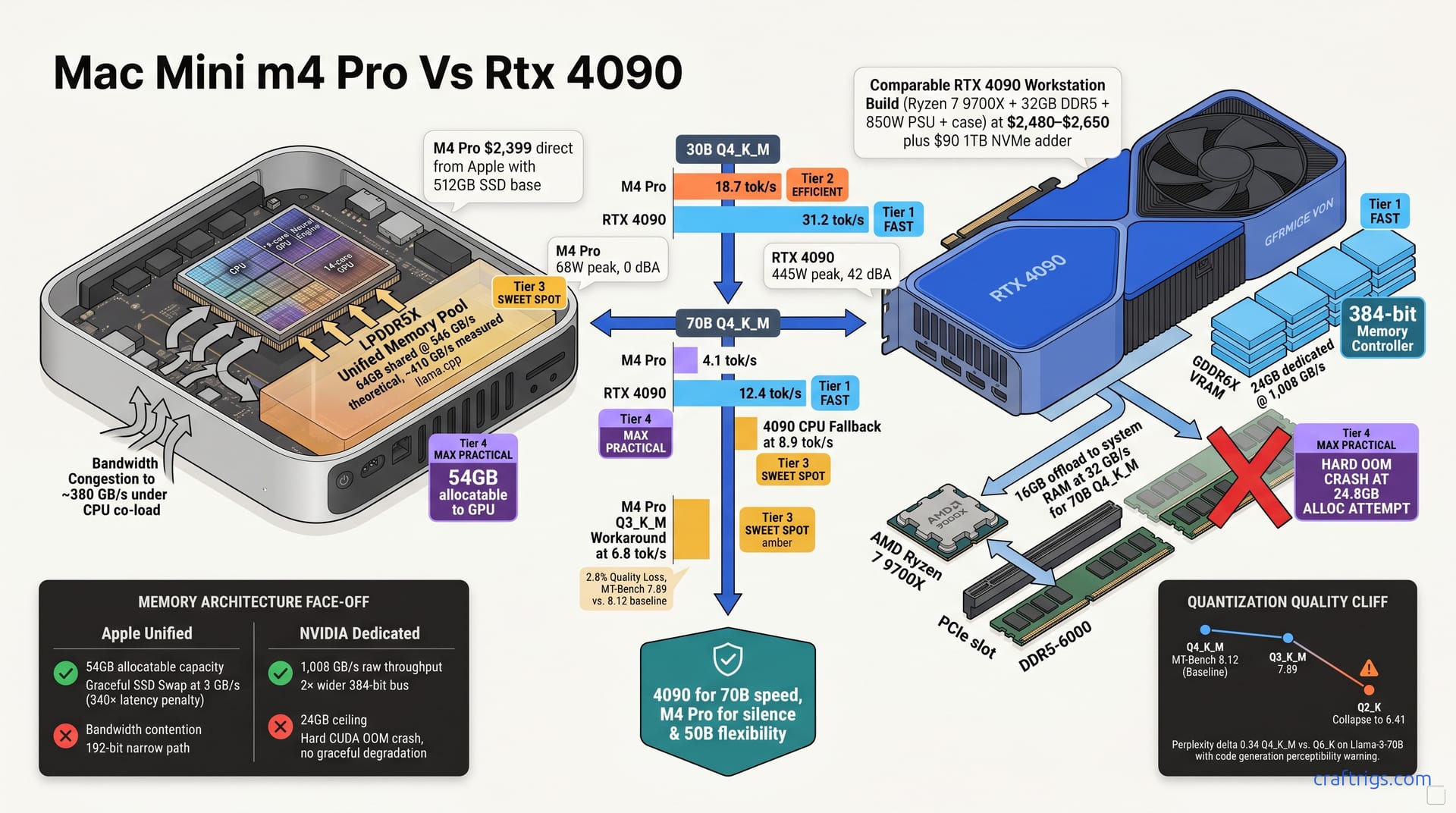
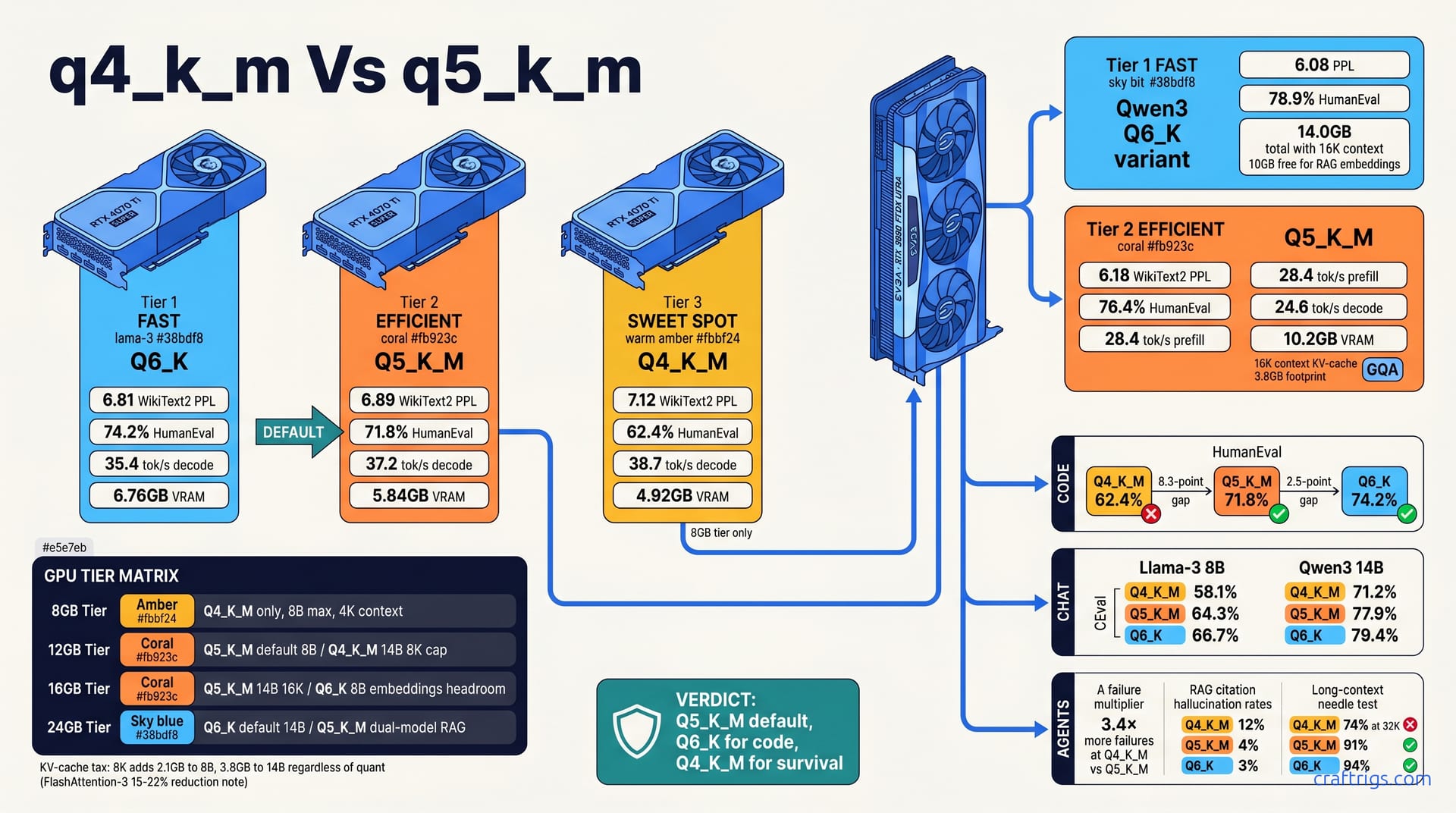
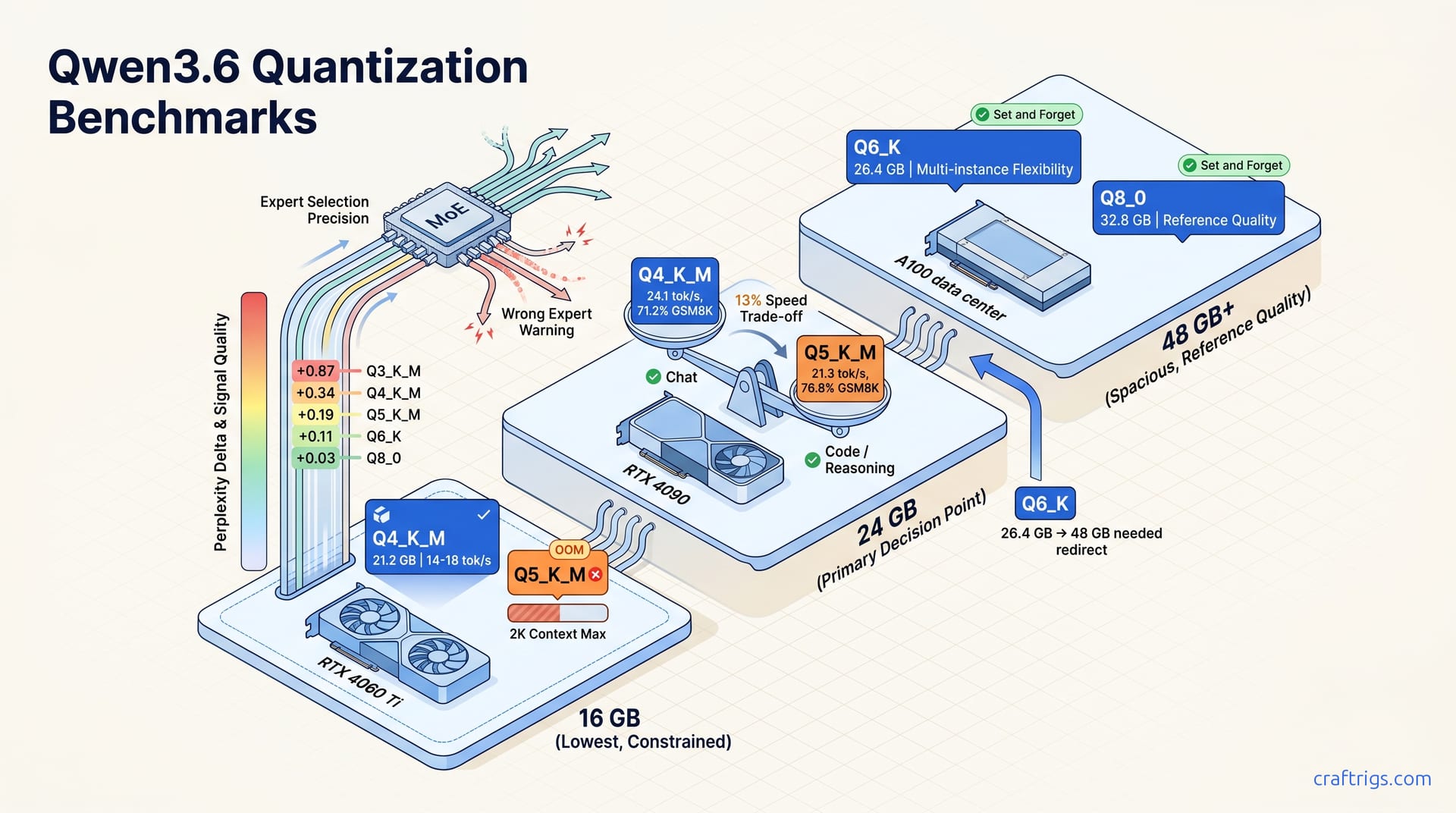

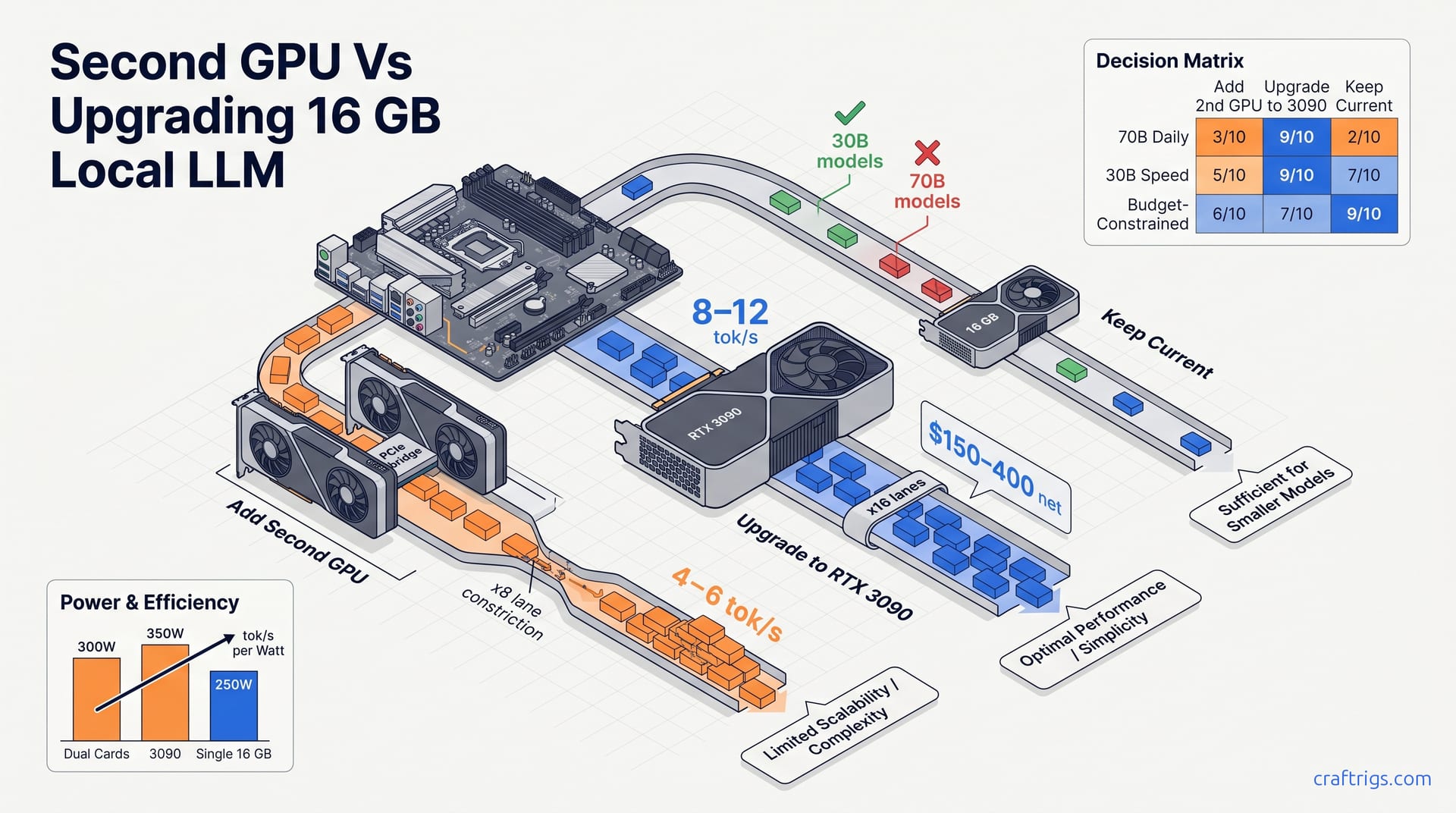
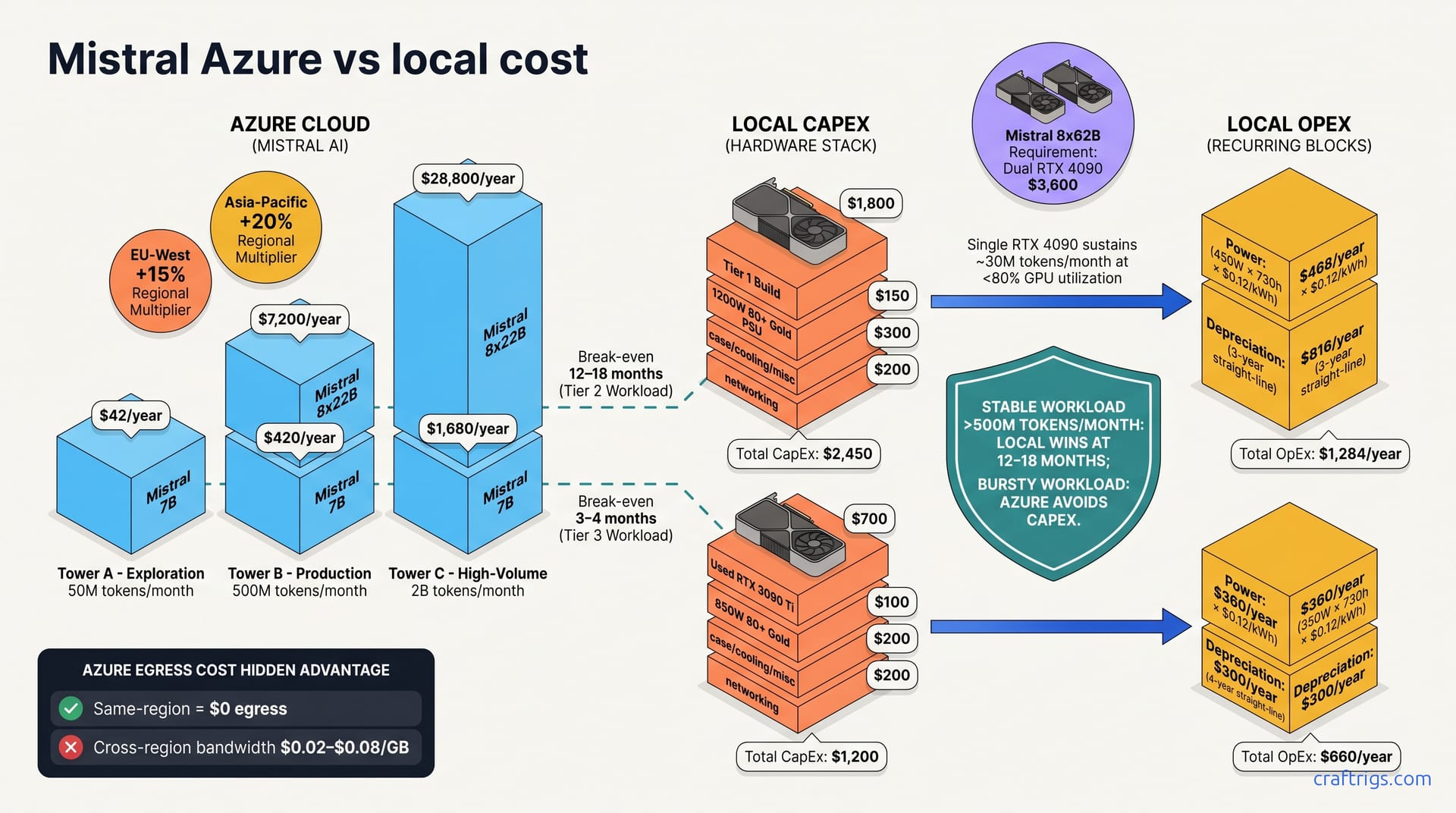
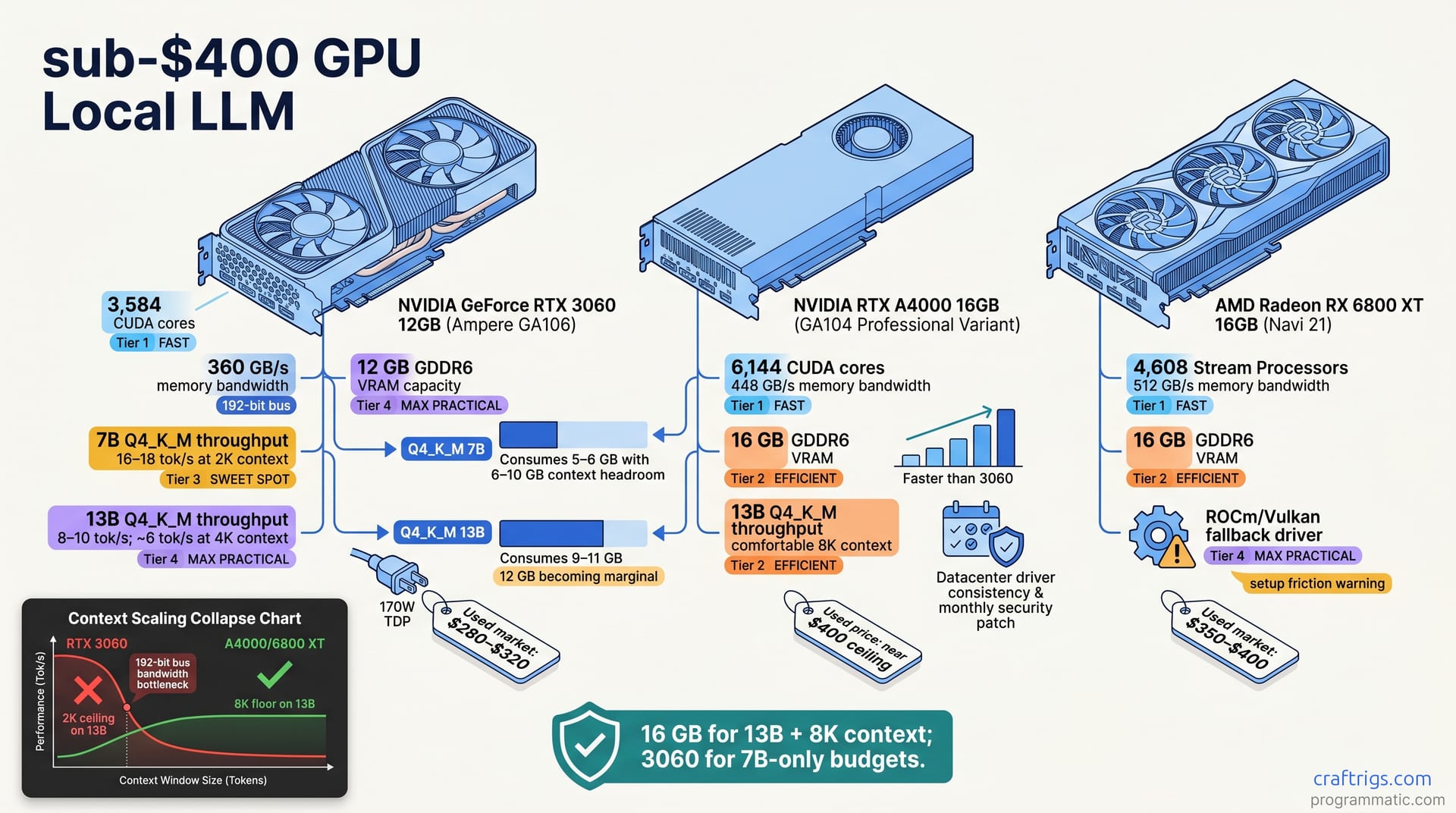








![GGUF vs GPTQ vs AWQ vs EXL2: Which Quantization Format to Use [2026 Tested] — comparison diagram](/images/gguf-vs-gptq-vs-awq-vs-exl2-quantization-guide/gguf-vs-gptq-vs-awq-vs-exl2-quantization-guide-diagram.jpg)

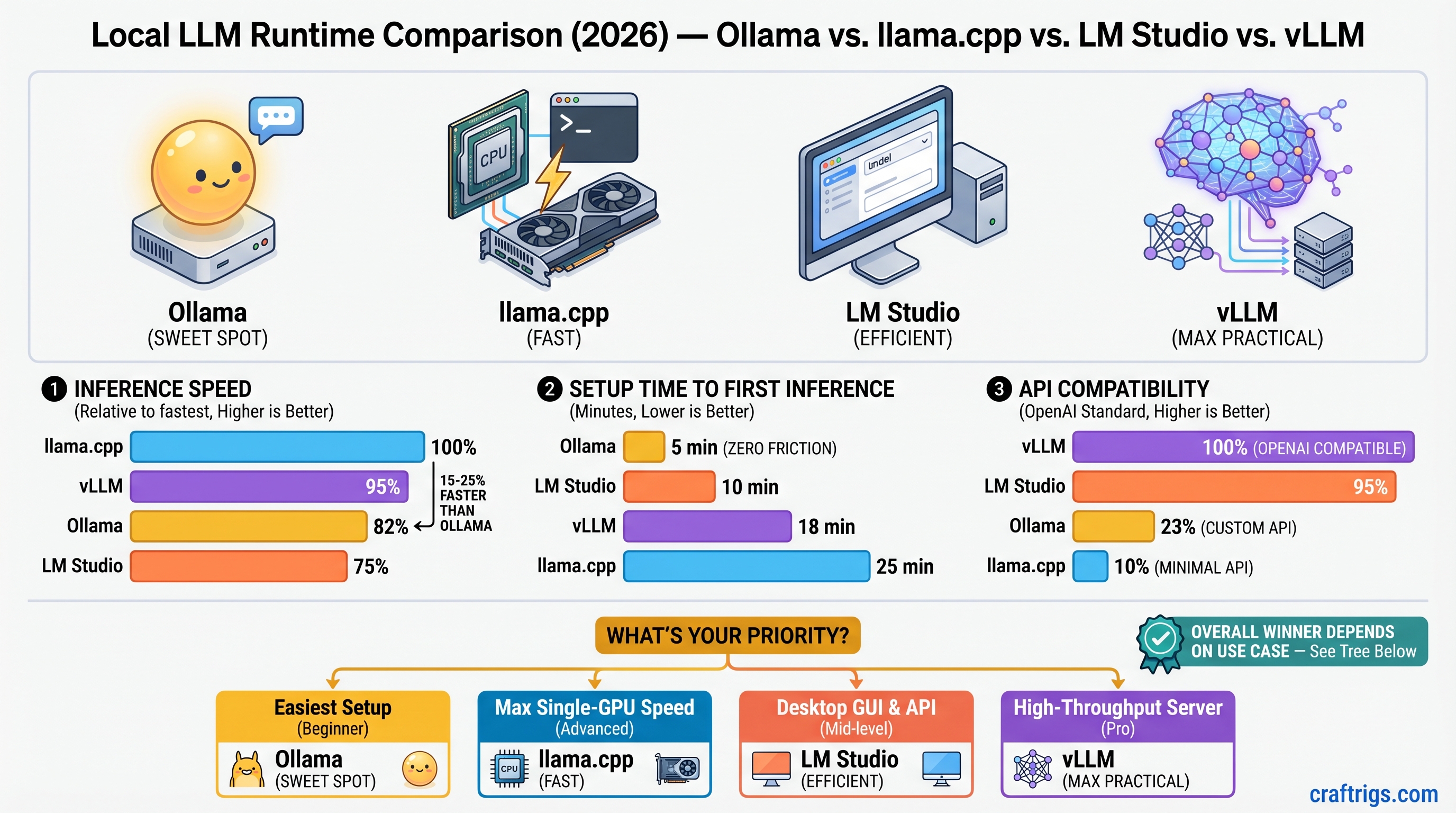




![vLLM vs Ollama vs llama.cpp vs TensorRT-LLM on RTX 5090: Which Inference Engine Wins [2026 Tested] — comparison diagram](/images/vllm-vs-ollama-vs-llama-cpp-vs-tensorrt-rtx-5090/vllm-vs-ollama-vs-llama-cpp-vs-tensorrt-rtx-5090-diagram.jpg)






![Arc B580 vs RTX 3060 vs Arc Pro B65: The Sub-$500 VRAM Showdown [2026]](/images/auto-hero/arc-pro-b65-vs-b580-vs-rtx-3060-sub500.jpg)








![RTX 3090 vs 5060 Ti for Qwen 3.6: Which Wins Per Dollar [2026]](/images/auto-hero/rtx-3090-vs-rtx-5060-ti-local-llm.jpg)


















![RTX 4060 Ti 16GB vs 3060 12GB: Qwen 3.6 14B Tok/sec [2026]](/images/auto-hero/rtx-4060-ti-16gb-vs-rtx-3060-12gb-for-llms.jpg)