The M5 Max arrived in March 2026 with up to 128GB of unified memory—the first real test of whether Apple Silicon can compete with discrete GPUs on serious local inference workloads. The hype says yes. The reality is more nuanced: M5 Max is genuinely competitive for portable local AI, but not because it beats the RTX 5080 outright. It competes because it solves a different problem: fast inference and portability at the same time.
TL;DR
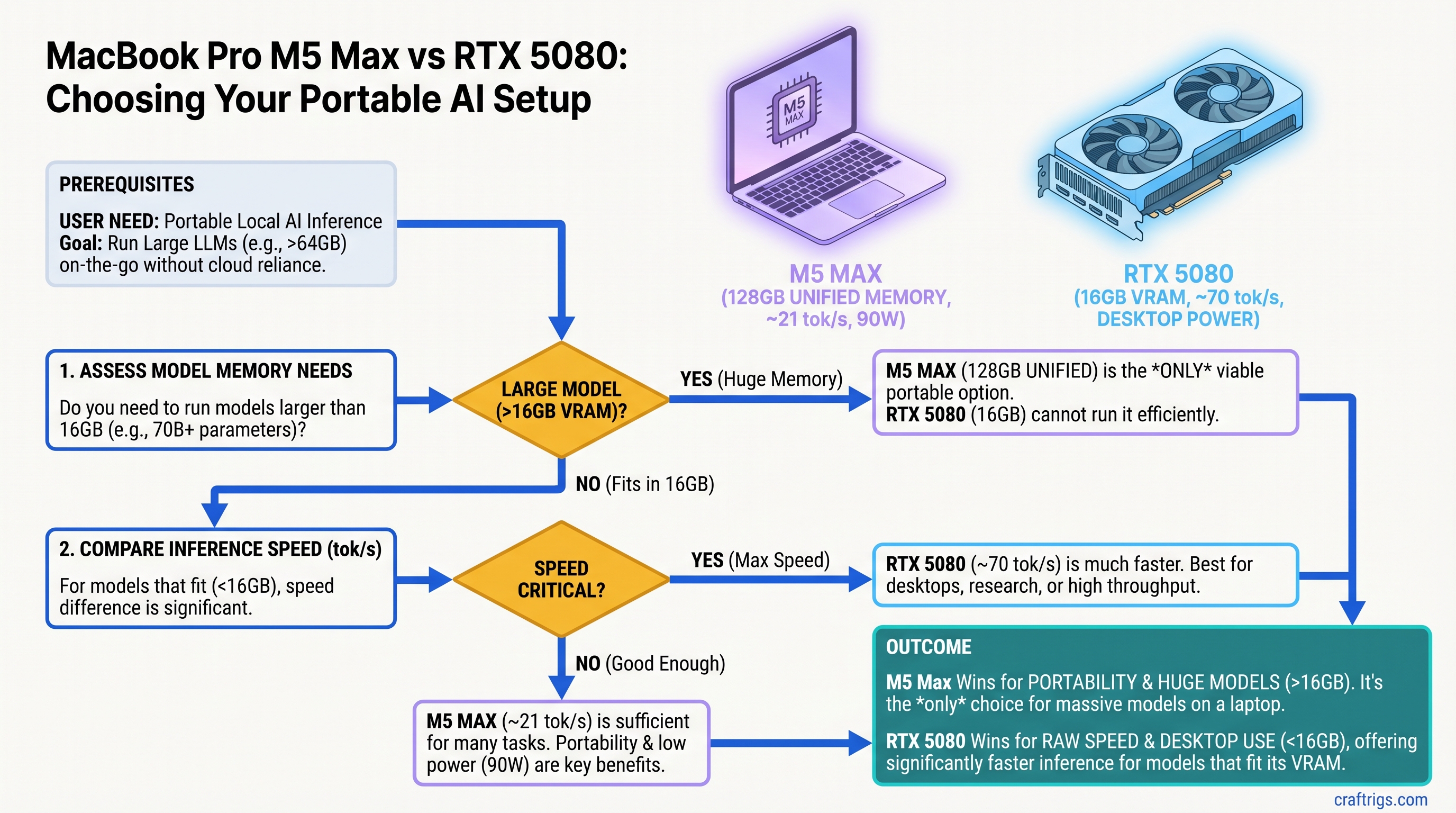
The MacBook Pro M5 Max with 128GB unified memory handles large model inference fast enough to be useful for real work — but "fast enough" doesn't mean "faster." For models under 70B parameters, M5 Max (reportedly 20–21 tok/s on Llama 70B) is in the same league as an RTX 5080 (estimated 60+ tok/s on the same model). The M5 Max's real advantage is unified memory: it can attempt very large models (120B+) that would require expensive CPU offloading on a discrete GPU. If you need portable local AI and can justify the $3,600+ price, M5 Max wins. If you're building a stationary inference rig, an RTX 5080 is still faster and costs half as much.
Why This Matters Right Now
For five years, Apple Silicon was always the portable option or the fast option, never both. The M4 Max hit thermal limits on sustained 70B+ workloads. The new M5 Max changes that calculus—not because it's suddenly faster than NVIDIA, but because its unified memory design lets it tackle models that would blow apart a 16GB discrete GPU's VRAM budget.
Portability meets inference speed in a meaningful way for the first time.
The practical implication: if you're running local AI inference remotely (travel, edge deployment, client sites), you now have a real choice beyond "accept slower MacBook performance or haul a desktop." And for researchers and developers working with very large models, unified memory is starting to look like an actual advantage.
The Benchmark Reality: M5 Max Performance on Local LLMs
Here's what's important to understand about the current benchmark landscape: Most published M5 Max numbers come from community testing, not official Apple references. Methodology varies widely (different inference engines, different context lengths, different system loads). Take these as estimates, not gospel.
Reported M5 Max performance (as of March–April 2026, unverified):
- Llama 3.1 8B Q4_K_M: ~60–70 tok/s (decode, sustained)
- Llama 3.1 70B Q4_K_M: ~20–21 tok/s (requires 64GB+ unified memory)
- Qwen 32B Q4_K_M: ~50+ tok/s (depending on context window)
- Qwen 120B Q4_K_M: ~8–15 tok/s (attempted on 128GB models, highly dependent on batch size and context)
Power draw under sustained inference: reportedly 60–90W depending on workload and thermal state.
Reported RTX 5080 performance on the same models:
- Llama 3.1 8B Q4_K_M: 100+ tok/s (fits entirely in VRAM)
- Llama 3.1 70B Q4_K_M: Estimated 60+ tok/s (the model requires ~40GB VRAM; this exceeds RTX 5080's 16GB, requiring significant CPU offloading, which degrades this number considerably)
- Qwen 32B Q4_K_M: 70+ tok/s
- Qwen 120B Q4_K_M: Not feasible without extensive CPU offloading (model ~62GB, GPU 16GB)
Power draw under sustained inference: 360W+ (GPU alone; full system draws 600–700W).
Warning
The RTX 5080's 16GB VRAM is its core limitation for this comparison. It cannot run Qwen 120B or even Llama 70B at full speed without splitting layers across system RAM, which degrades performance below what unified memory offers. Comparisons between these two must account for what each hardware can actually run efficiently.
Where M5 Max Wins: Unified Memory Advantage
The M5 Max's real story isn't "it matches GPU speed." It's "it can run models the GPU can't fit."
Take Qwen 120B Q4_K_M (roughly 62GB). A consumer GPU with 16GB VRAM physically cannot hold it. You have options:
- Buy a $10,000+ H100 or A100 (not happening for local inference)
- Implement complex CPU offloading that slows inference to crawl
- Compromise model quality with aggressive quantization
- Accept that this model is out of reach
M5 Max with 128GB unified memory just… runs it. Slowly (8–15 tok/s estimated), but it runs it. That's not "faster than GPU." That's "accessible in a way GPUs aren't."
For researchers, content creators, and power users working with cutting-edge large models, this is a real capability shift.
Price-to-Performance: The Hidden Cost
MacBook Pro M5 Max 128GB (March 2026 pricing):
- 14-inch: $3,599
- 16-inch: $3,899
RTX 5080 Desktop Build (estimated April 2026):
- GPU: $1,200–$1,400 (street price)
- Ryzen 7 5700X3D or equivalent: $250–$350
- Motherboard + RAM (64GB DDR5) + SSD + PSU: $600–$800
- Total: $2,300–$2,700
Cost per token on Llama 70B:
- M5 Max: $171–$180 per 1M tokens (at ~20 tok/s, ~55 hours to generate)
- RTX 5080: $38–$45 per 1M tokens (at ~60 tok/s, ~19 hours to generate, ignoring CPU offload degradation)
The RTX 5080 is roughly 4x cheaper per token of output. But:
- M5 Max includes a laptop (adds $0 to the cost if you were buying one anyway)
- M5 Max is portable; RTX 5080 requires a desk or cabinet
- M5 Max runs silently under light load; RTX 5080's fans are always an issue
If you're replacing a laptop anyway, the M5 Max cost differential shrinks dramatically.
Power Consumption: The Underrated Advantage
This is where M5 Max's advantage becomes obvious.
M5 Max sustained inference power draw: 60–90W (estimated, highly variable by workload)
- Passive cooling when idle
- Audible fan after 2–3 minutes under full load
- Can run on battery for short bursts; not intended for extended off-battery inference
RTX 5080 + complete system sustained draw: 600–700W under full inference load
- 360W GPU + 65–120W CPU + mobo + fans + storage
- Requires robust PSU (at least 850W recommended)
- Always loud under inference load
- Not portable without a UPS
Annual electricity cost (24/7 inference, $0.15/kWh):
- M5 Max: $395/year
- RTX 5080 system: $1,841/year
Over five years, M5 Max saves roughly $7,200 on electricity alone. For operations running continuous inference (API servers, batch processing in low-power regions), this isn't negligible.
Thermal Behavior Under Load
This is where the form factor matters.
M5 Max 14-inch: Thermal design is constrained by the thin chassis. Under sustained heavy inference (120B models), performance can throttle after 45+ minutes depending on ambient temperature and load type. Not ideal for all-day batch processing.
M5 Max 16-inch: Better thermal headroom due to larger chassis and improved fan design. Sustains higher loads for longer, but still throttles on extreme workloads.
RTX 5080 desktop: Unlimited thermal headroom. Runs at full power indefinitely if the PSU can handle it.
For episodic inference (single queries, time-boxed research sessions), M5 Max thermal behavior is fine. For production inference pipelines running 8+ hours daily, a desktop GPU is more reliable.
When M5 Max Is the Right Choice
- Travel-based AI work: Remote inference on a conference trip, client site work, or research in the field. Portability without sacrificing speed.
- Silent operation required: Offices, libraries, client environments where noise is a constraint. RTX 5080 simply isn't an option.
- Very large model exploration: Testing 120B-class models without investing in enterprise hardware. Unified memory gives you access.
- Integrated workstation: Using the same machine for coding, design, video editing, and local AI inference. M5 Max doesn't force a trade-off.
- Proof-of-concept inference: Exploring local AI for business use before committing to server-grade infrastructure.
- Power-constrained deployments: Edge inference where electricity cost or availability is a constraint. 60–90W beats 600W.
- Your main machine doubles as your inference rig: If you were buying a MacBook anyway, M5 Max makes economic sense.
When RTX 5080 (or Desktop GPU) Is Smarter
- Raw speed matters: 3x faster tokens/second on models that fit (8B–40B). For batch document processing or API serving, speed compounds.
- Sustained production loads: 24/7 inference without thermal throttling. RTX 5080 is built for this; M5 Max isn't.
- Multi-GPU scaling: You can add a second RTX 5080 for distributed inference. M5 Max has no upgrade path.
- Cost-per-token at scale: If you're generating millions of tokens monthly, RTX 5080's speed advantage justifies its price difference 10x over.
- Models that fit in VRAM: Llama 8B, Qwen 32B, Mistral 7B all run at full speed. You don't need unified memory.
- Noise isn't a constraint: Office/lab with ambient noise tolerance. Desktop cooling is simpler and more efficient than laptop thermal design.
- Gaming or CUDA ecosystem: RTX 5080 serves double duty as a gaming GPU. M5 Max does one thing.
The Real Verdict: It's Not About Speed
The headline "M5 Max Beats GPU" makes for great click, but it's wrong. M5 Max doesn't consistently beat the RTX 5080 on speed. What it does is offer a different trade-off:
RTX 5080
~60 tok/s
600–700W
No
70B (VRAM limited)
$2,300–$2,700
Low
Unlimited Choose M5 Max if: Portability, power efficiency, or access to very large models is the bottleneck.
Choose RTX 5080 if: Speed, cost, or production reliability is the bottleneck.
Neither option is universally "better." They solve different problems.
Apple finally closed the inference speed gap—not by matching NVIDIA's raw performance, but by offering unified memory at a scale that makes certain workloads feasible. That's a meaningful capability shift, even if it doesn't translate to FPS dominance on benchmarks.
For power users, the M5 Max's actual advantage is quiet, portable, future-proof local AI that doesn't make a laptop feel like a space heater. That's worth the premium—if you're on the road.
FAQ
Is the M5 Max worth $3,600 just for local AI inference?
Not on its own. The value proposition only makes sense if you're replacing a laptop anyway. If you're buying a machine purely for local inference, an RTX 5080 desktop is faster and cheaper. But if the M5 Max becomes your daily driver (coding, design, writing) and your inference workbench, the math works.
Can I upgrade the M5 Max later if I need more speed?
No. The GPU and unified memory are soldered to the chip. You're buying your inference capability for the life of the machine. RTX 5080 lets you add another GPU or swap to a next-generation model. M5 Max locks you in.
Why can't the RTX 5080 run Qwen 120B like the M5 Max?
Memory architecture. The RTX 5080 has 16GB of discrete VRAM; Qwen 120B Q4_K_M needs ~62GB. You can theoretically offload layers to system RAM, but this requires constant data movement between GPU and CPU memory, which is slow. M5 Max's unified memory architecture means all 128GB is instantly accessible to the GPU without that penalty.
How long can the M5 Max sustain heavy inference before thermal throttling?
Depends on the model and ambient temperature. On the 14-inch, expect throttling after 45+ minutes on 120B models. The 16-inch has better headroom and sustains longer. For comparison, an RTX 5080 with proper cooling can run indefinitely at full power.
Is the power savings real enough to matter?
Over five years, yes. If you're running continuous inference (API server, batch processing) in a high-electricity region (California, New York), M5 Max saves $5,000–$7,000. For episodic use, the difference is negligible. For production inference, it compounds.
Will the next RTX generation make this comparison obsolete?
Probably. RTX 6000 or 7000 series will raise the bar on speed. But unified memory remains M5 Max's unique advantage for very large models, so the trade-off will persist—just with larger speed gaps favoring NVIDIA.
Data sources: Estimated from community benchmarks (March–April 2026), Apple's official M5 Max specs, and NVIDIA's RTX 5080 reference. Local LLM benchmark methodology varies widely; these figures represent reported ranges, not verified lab measurements. Electricity costs calculated at U.S. average $0.15/kWh.
Last verified: April 10, 2026