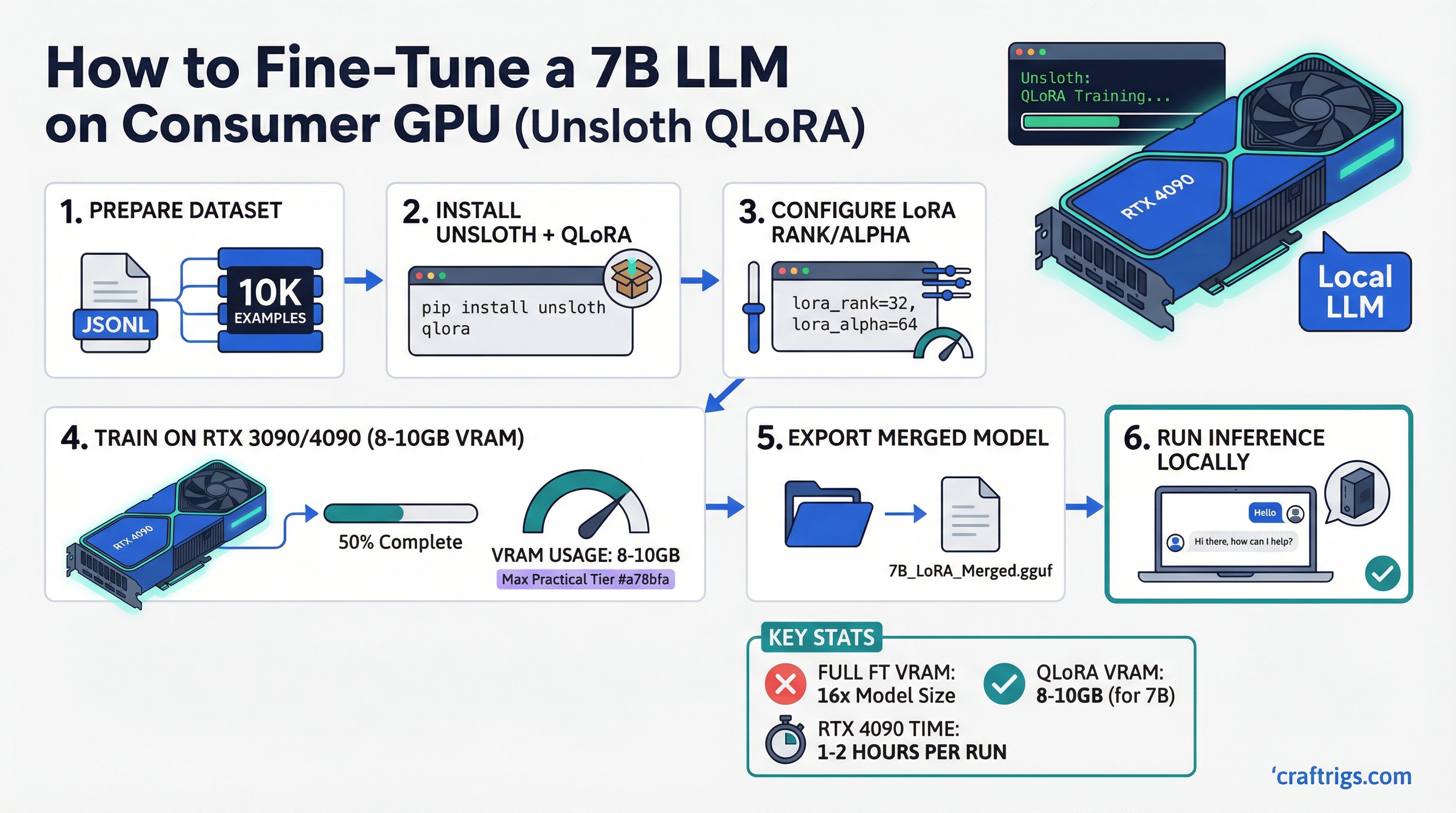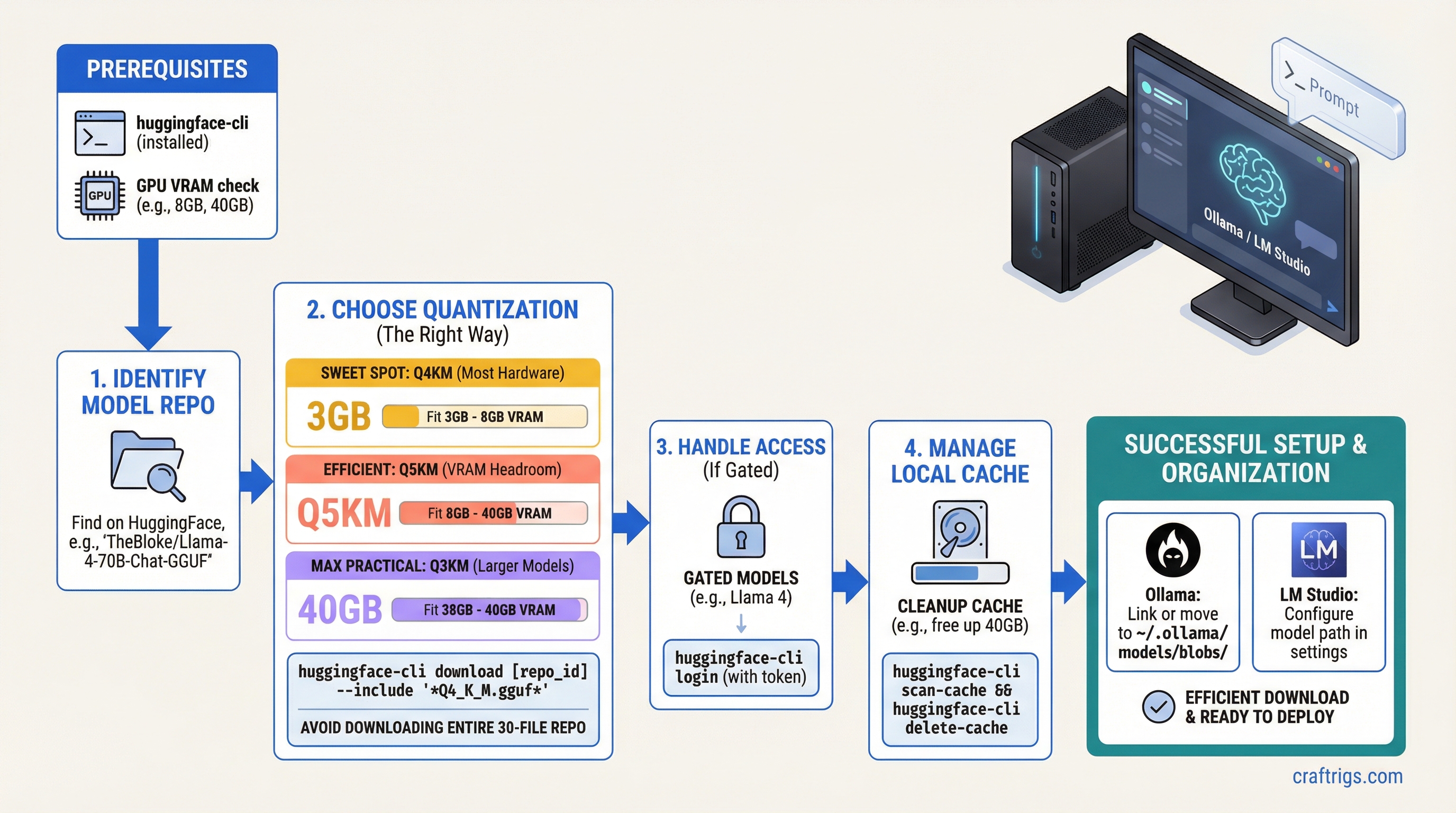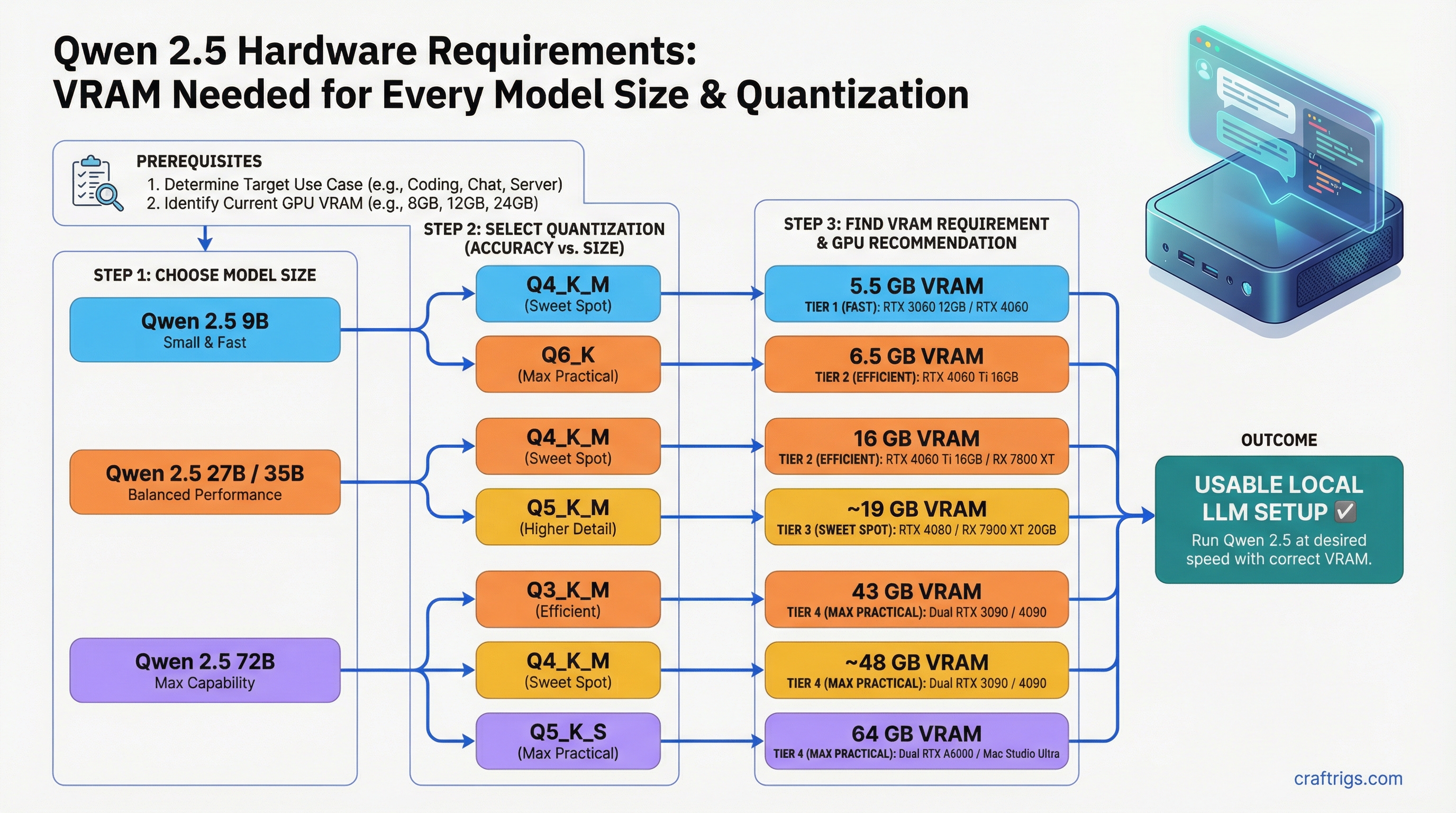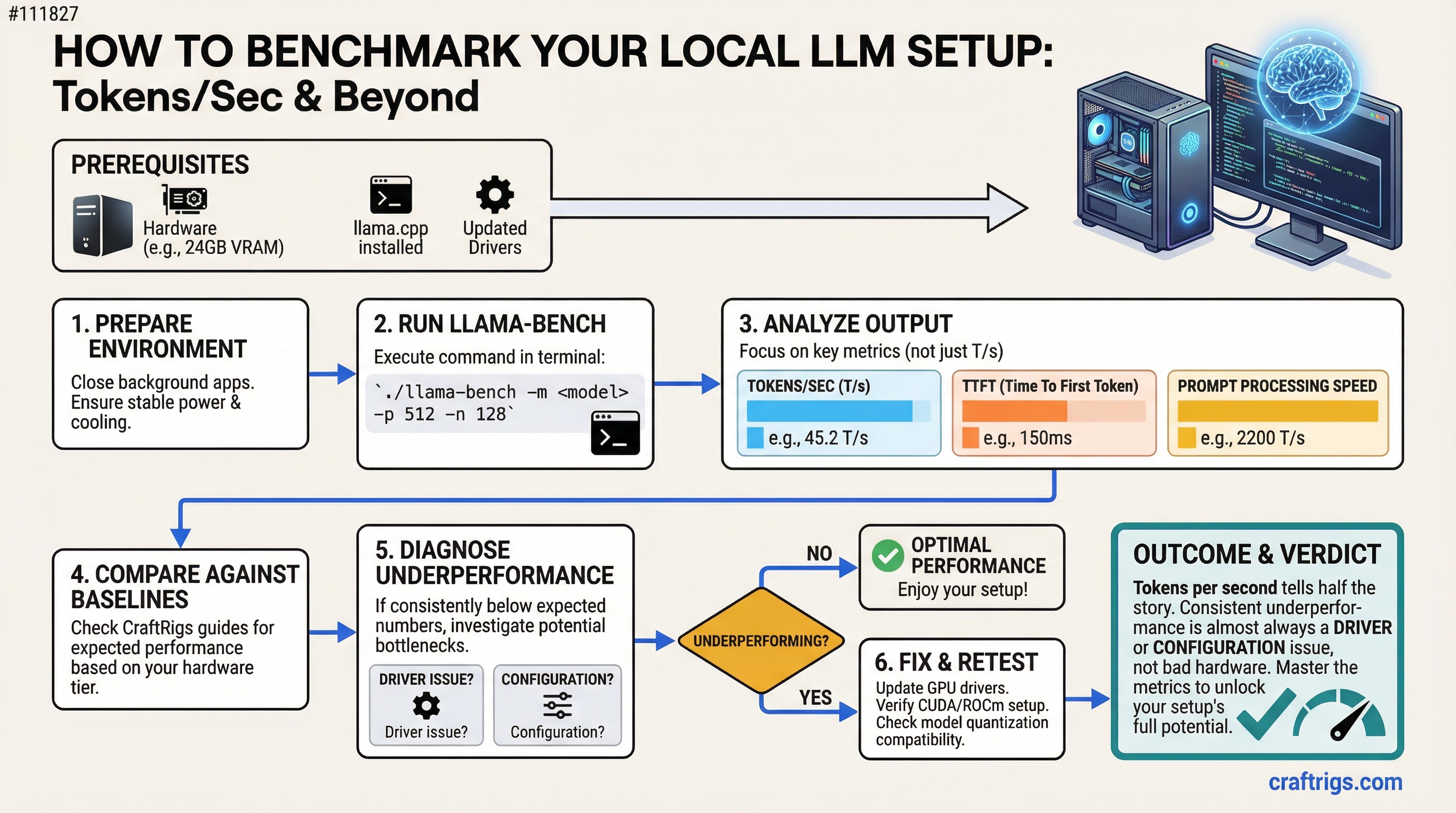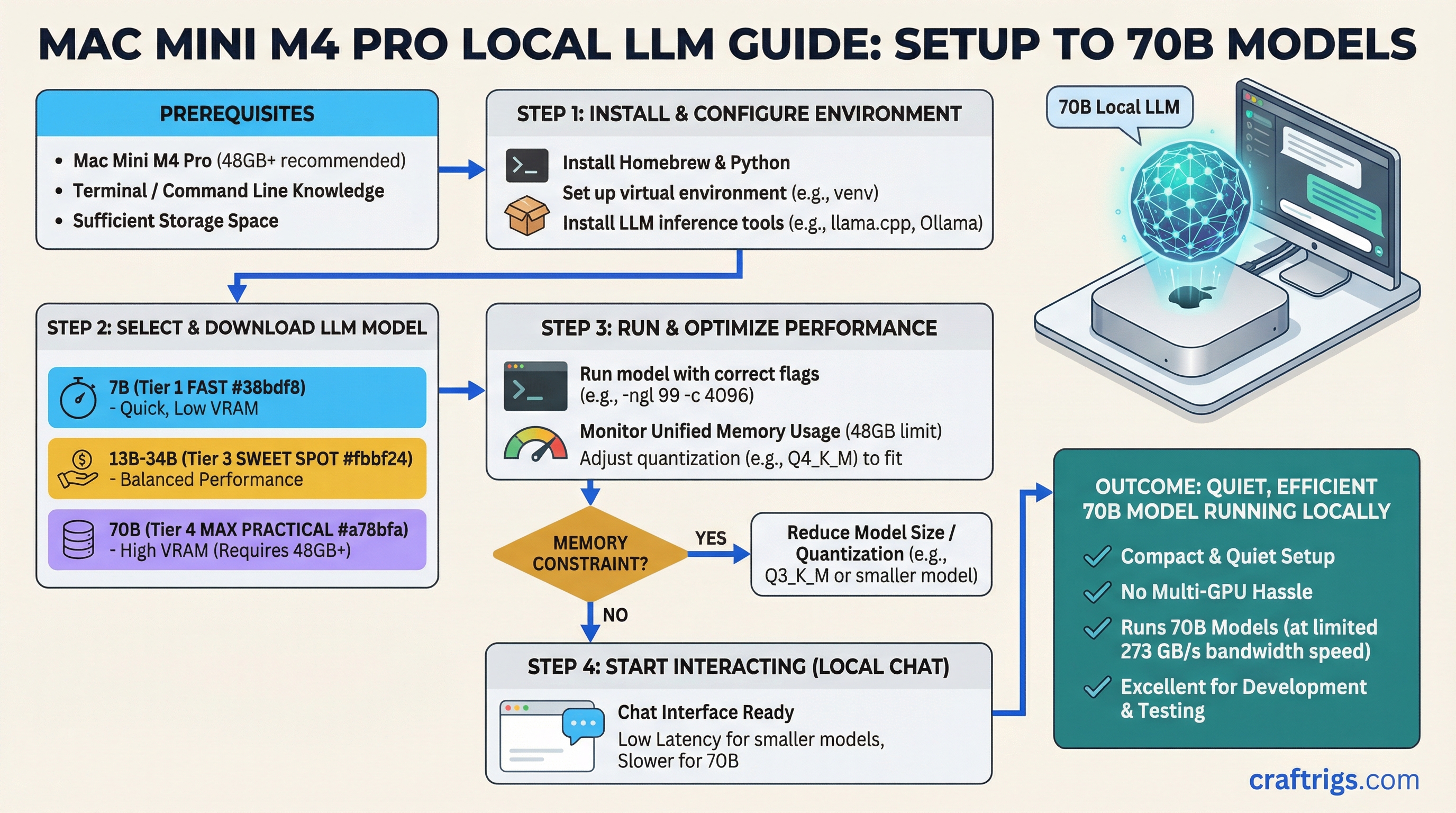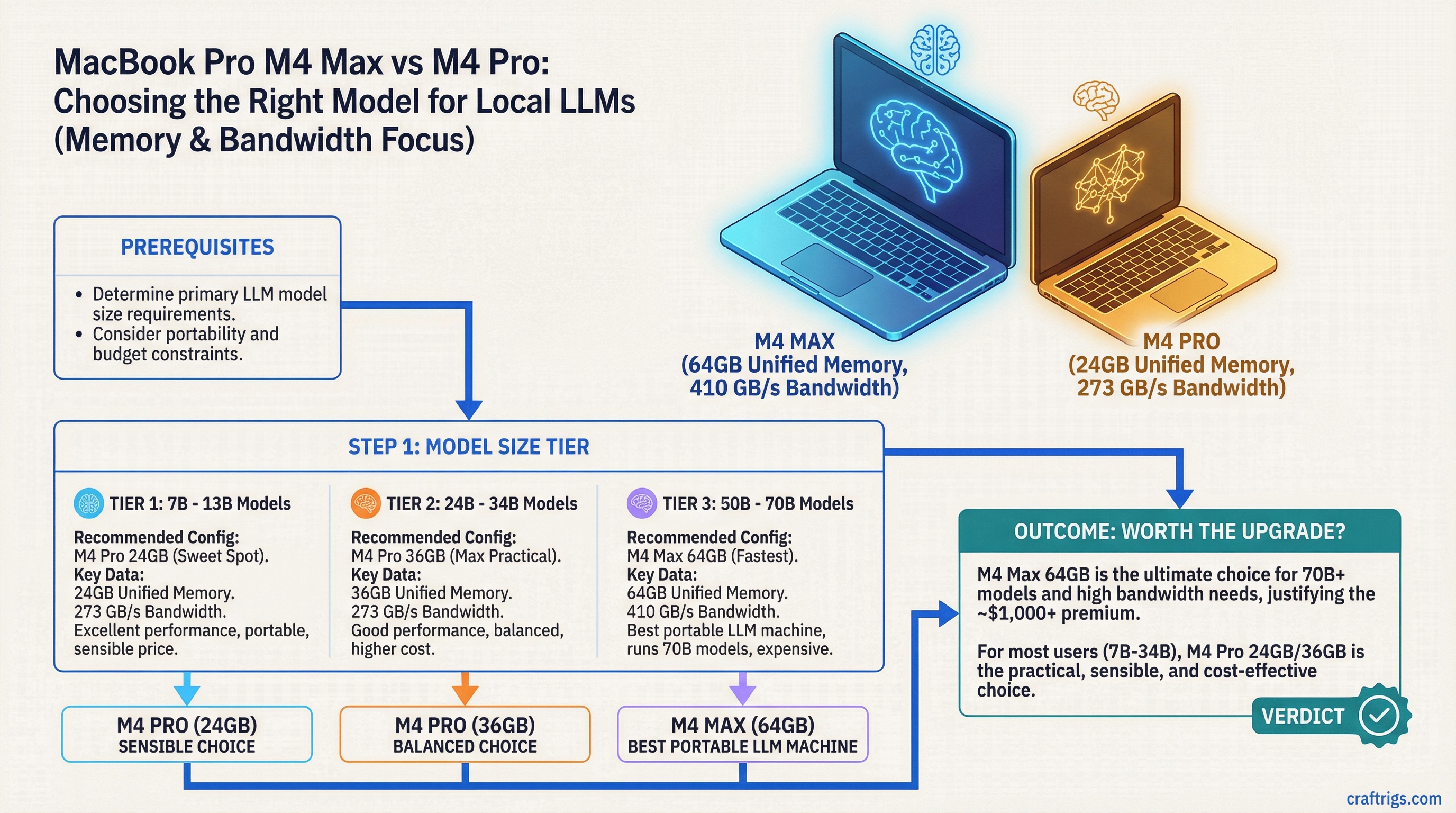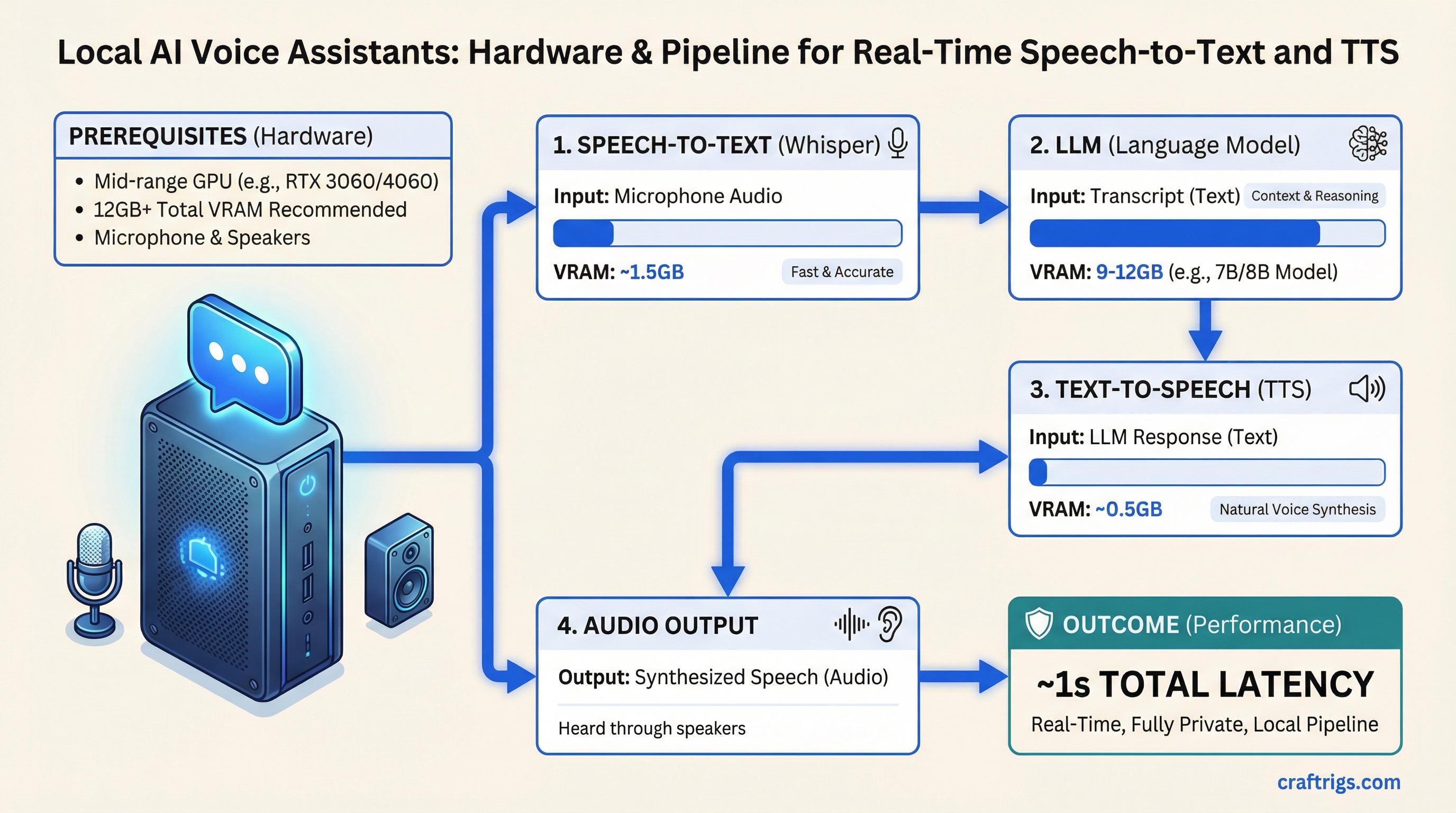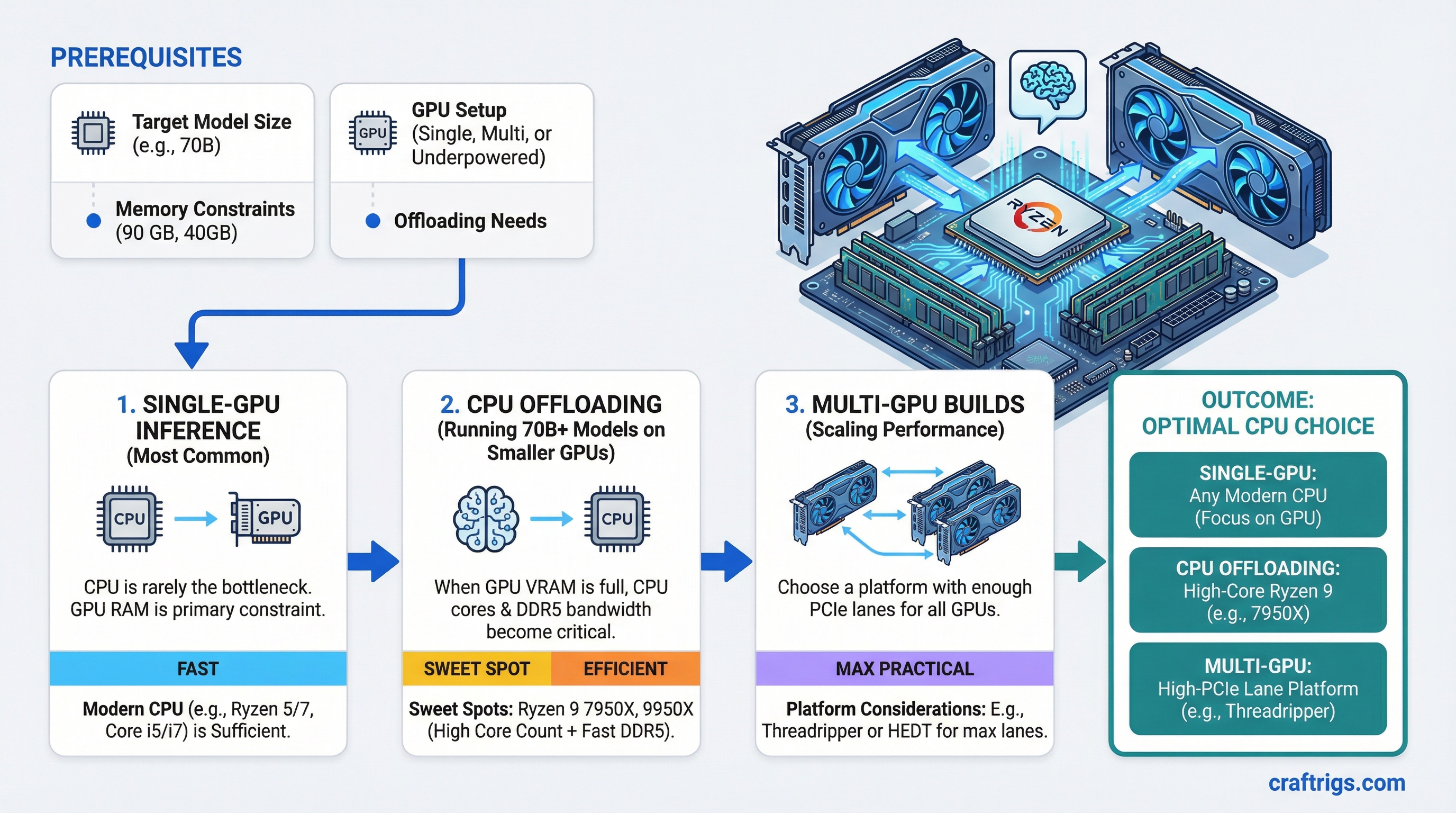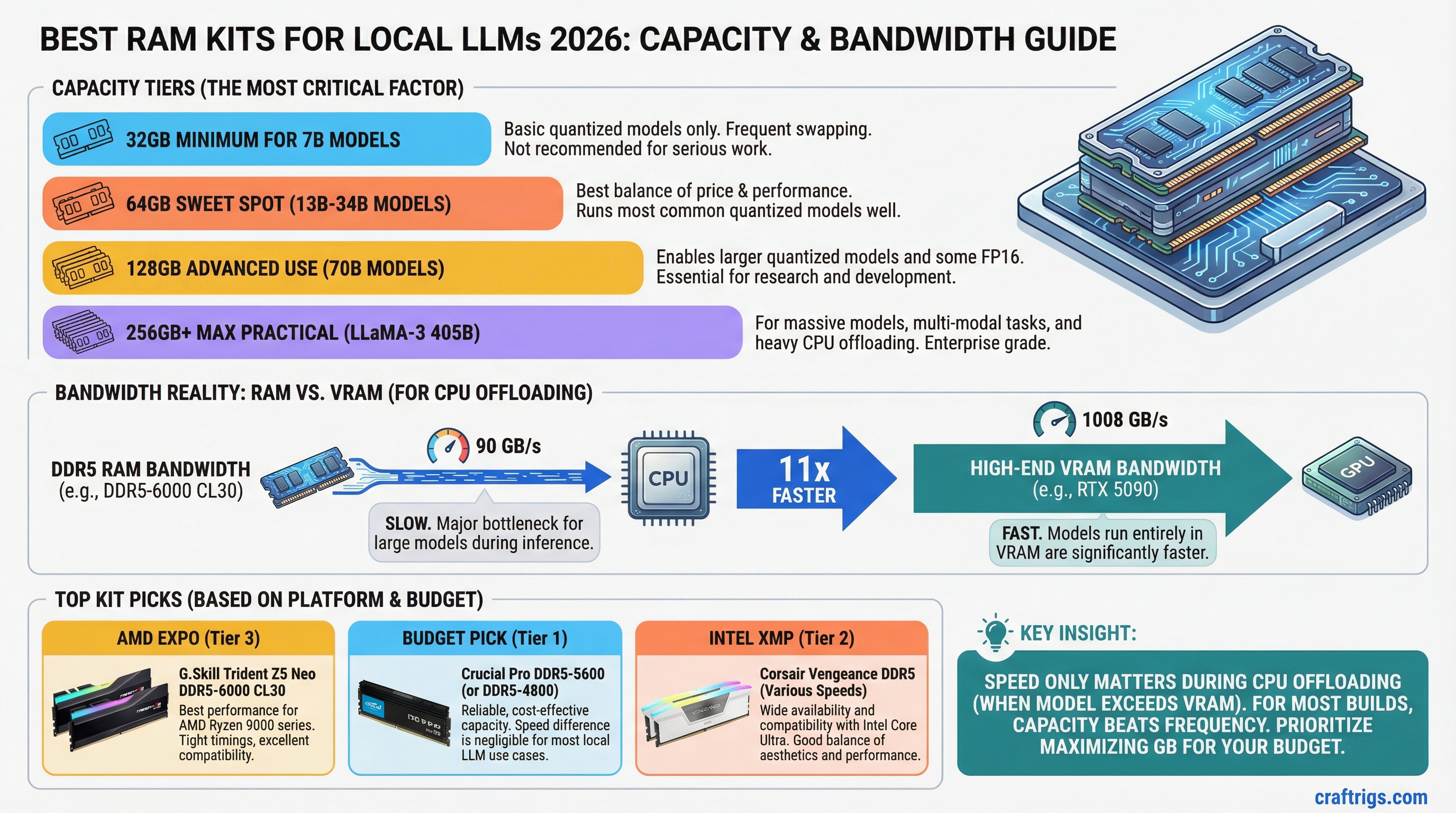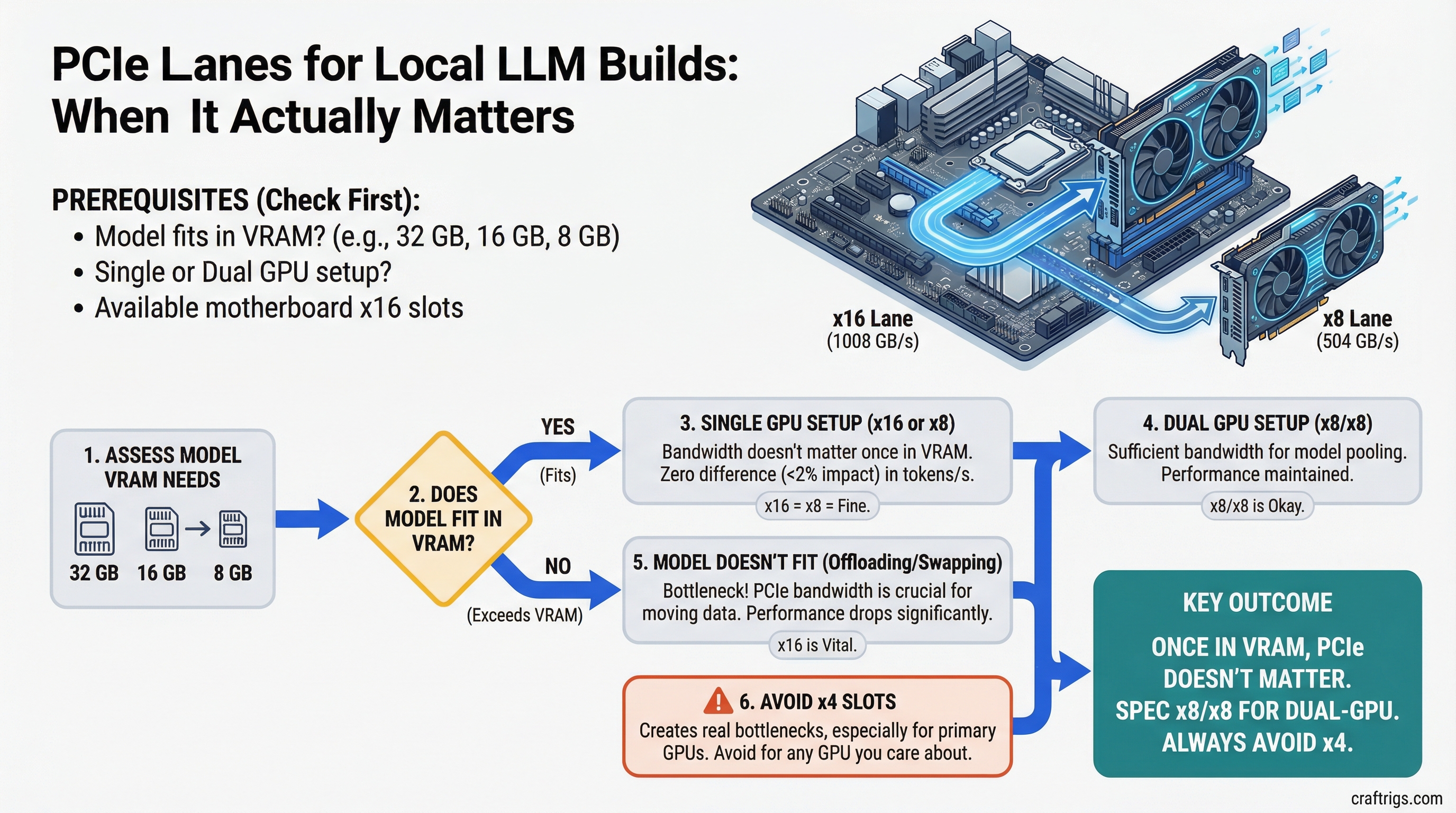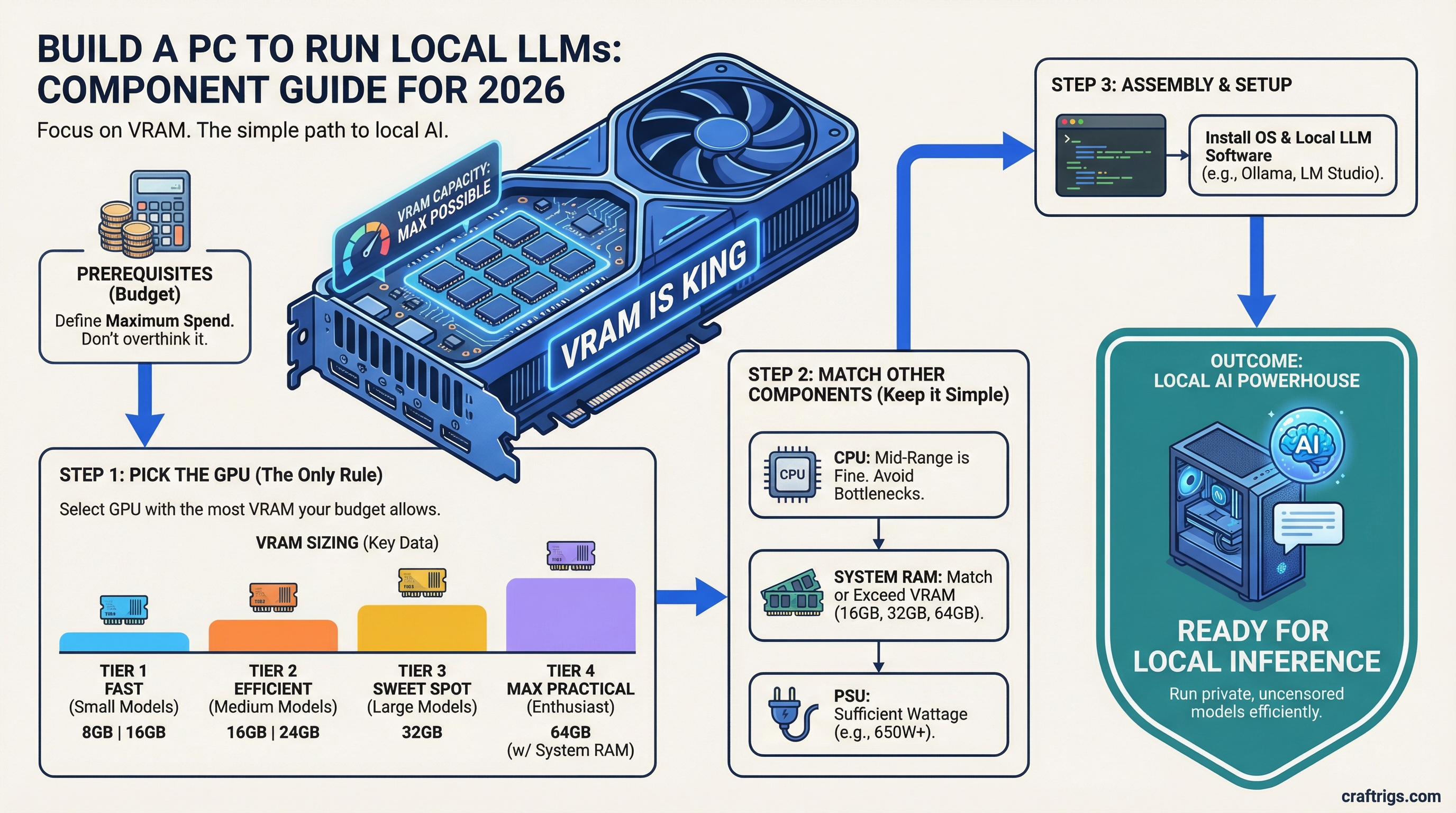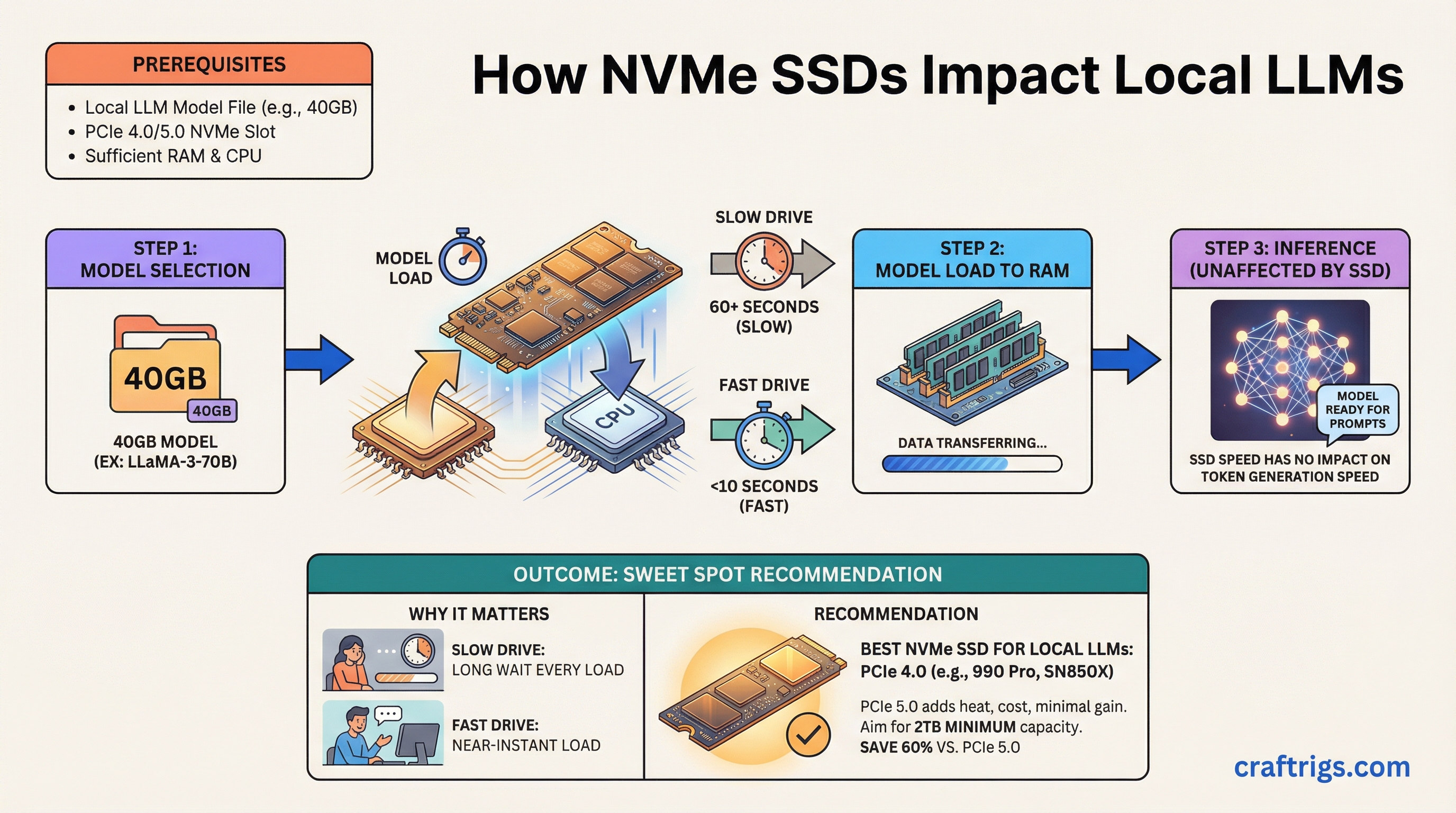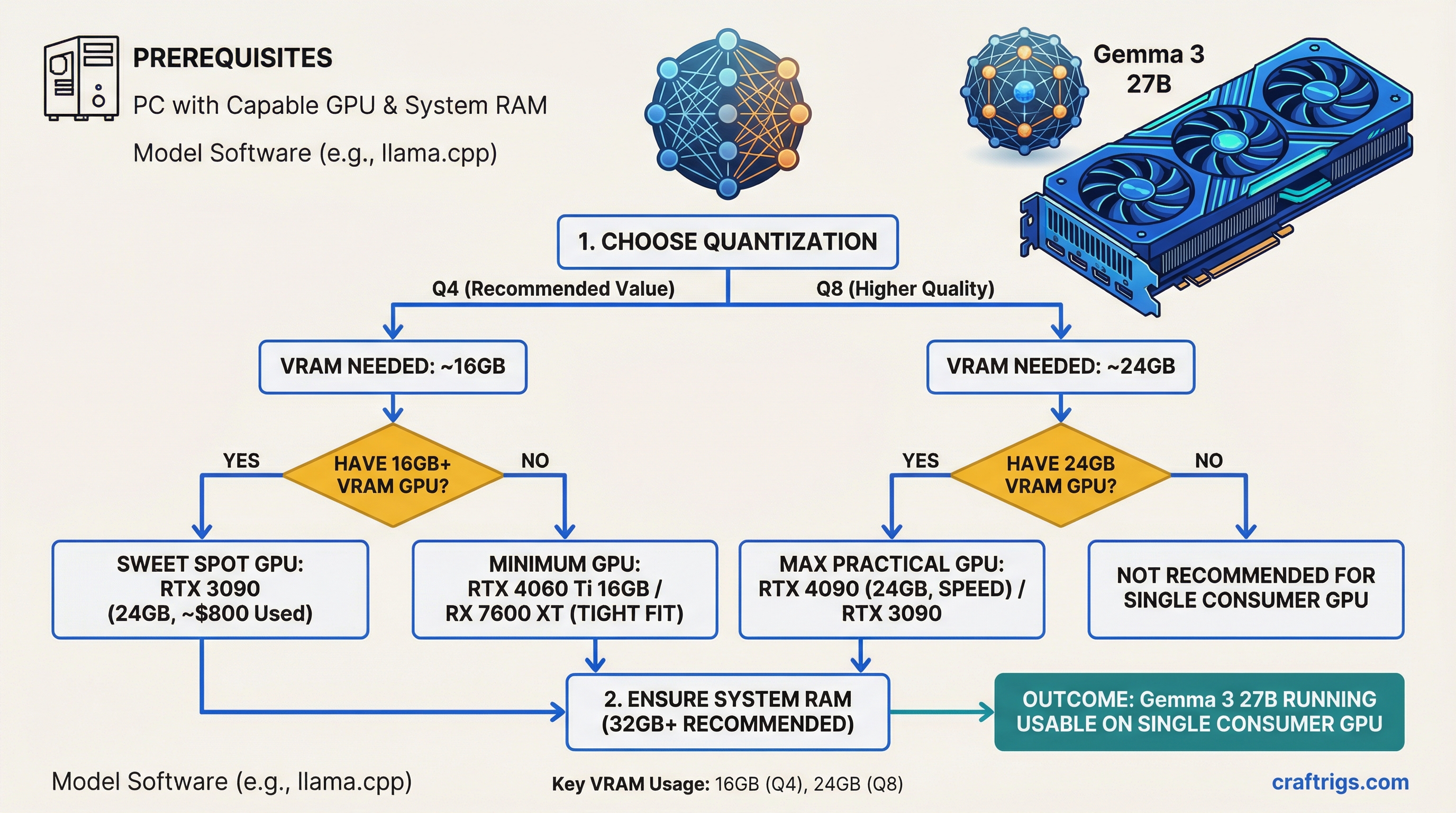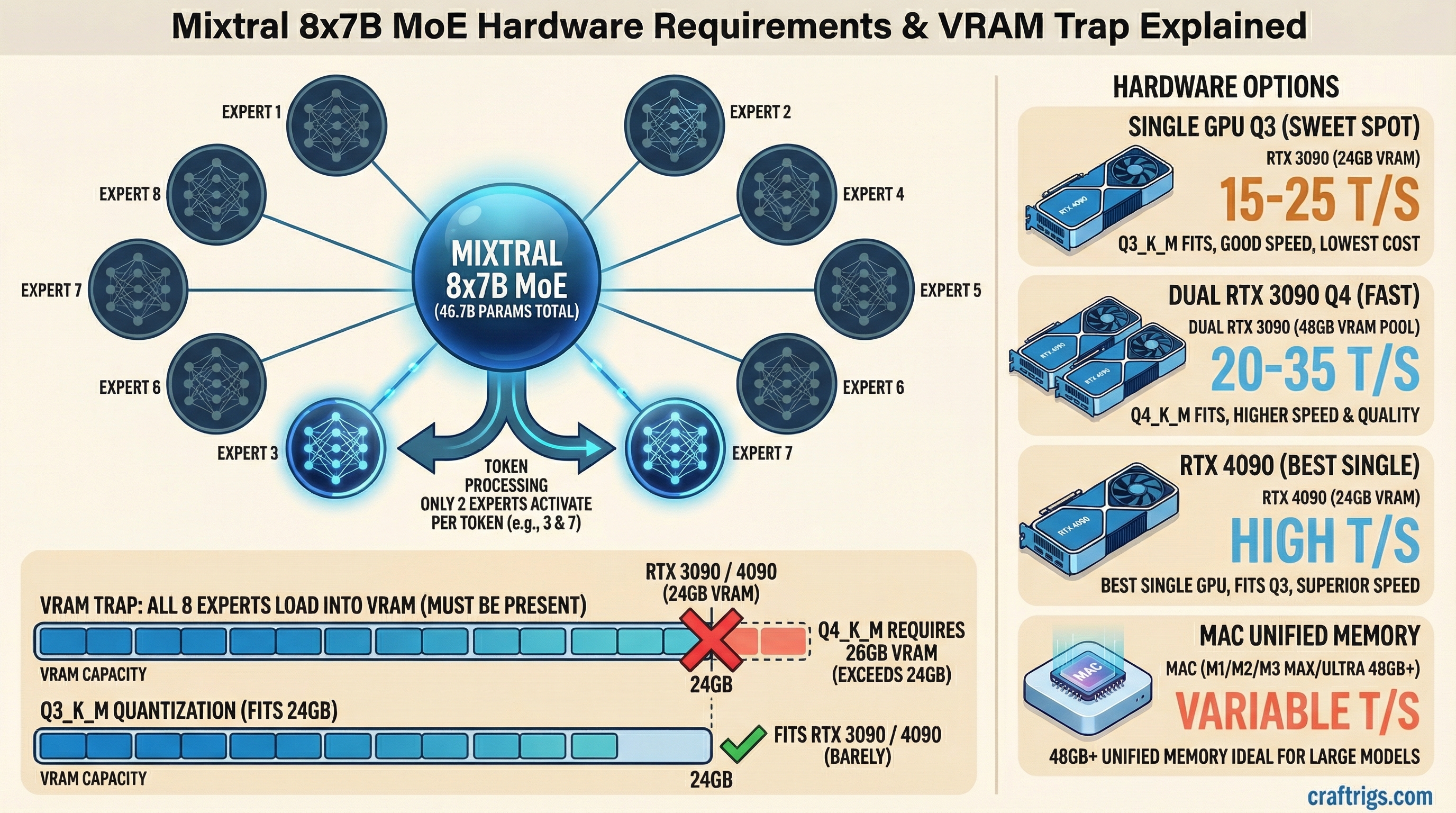
Architecture Guide
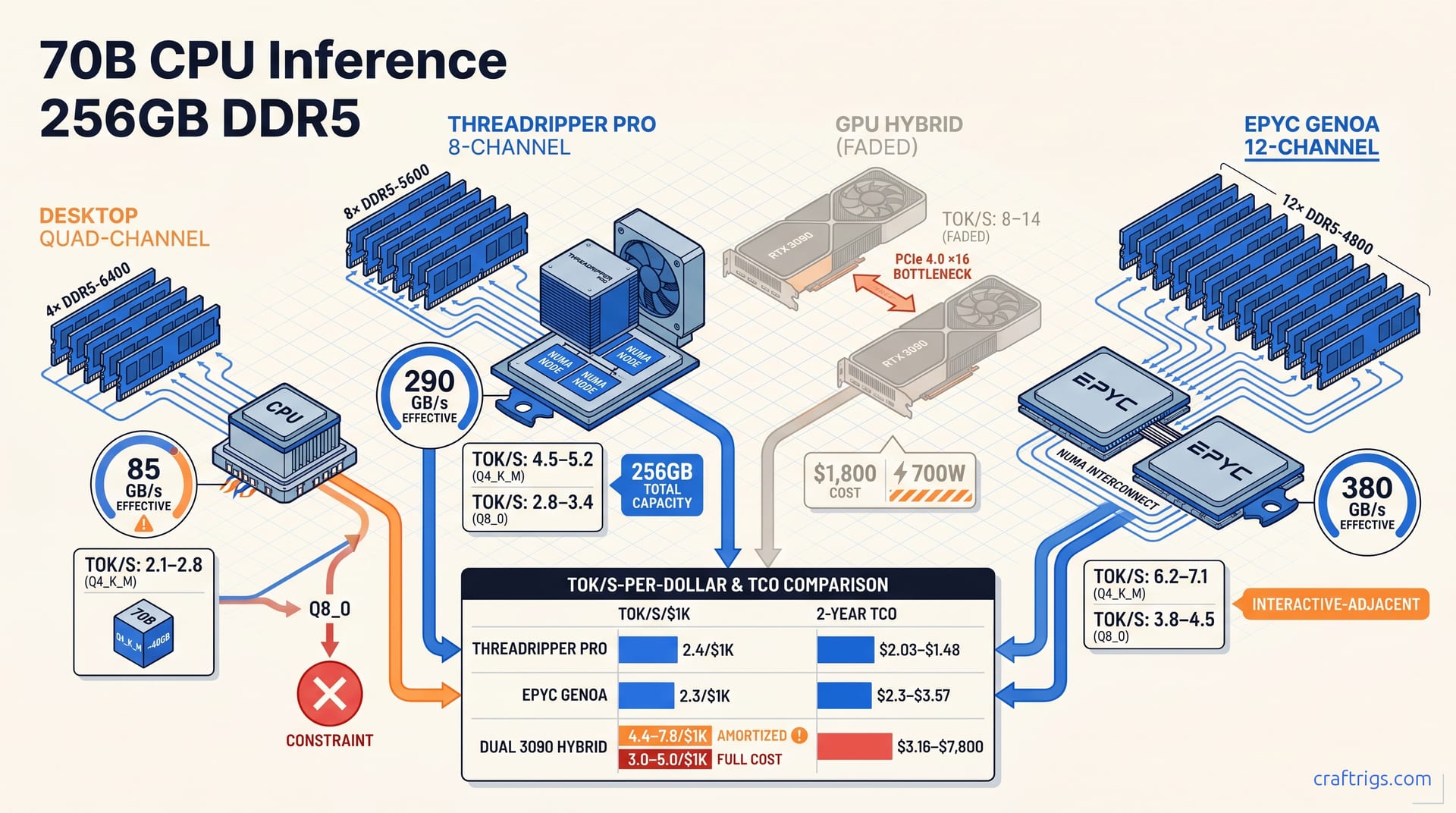
70B CPU Inference: 2–7 tok/s Without Buying GPUs
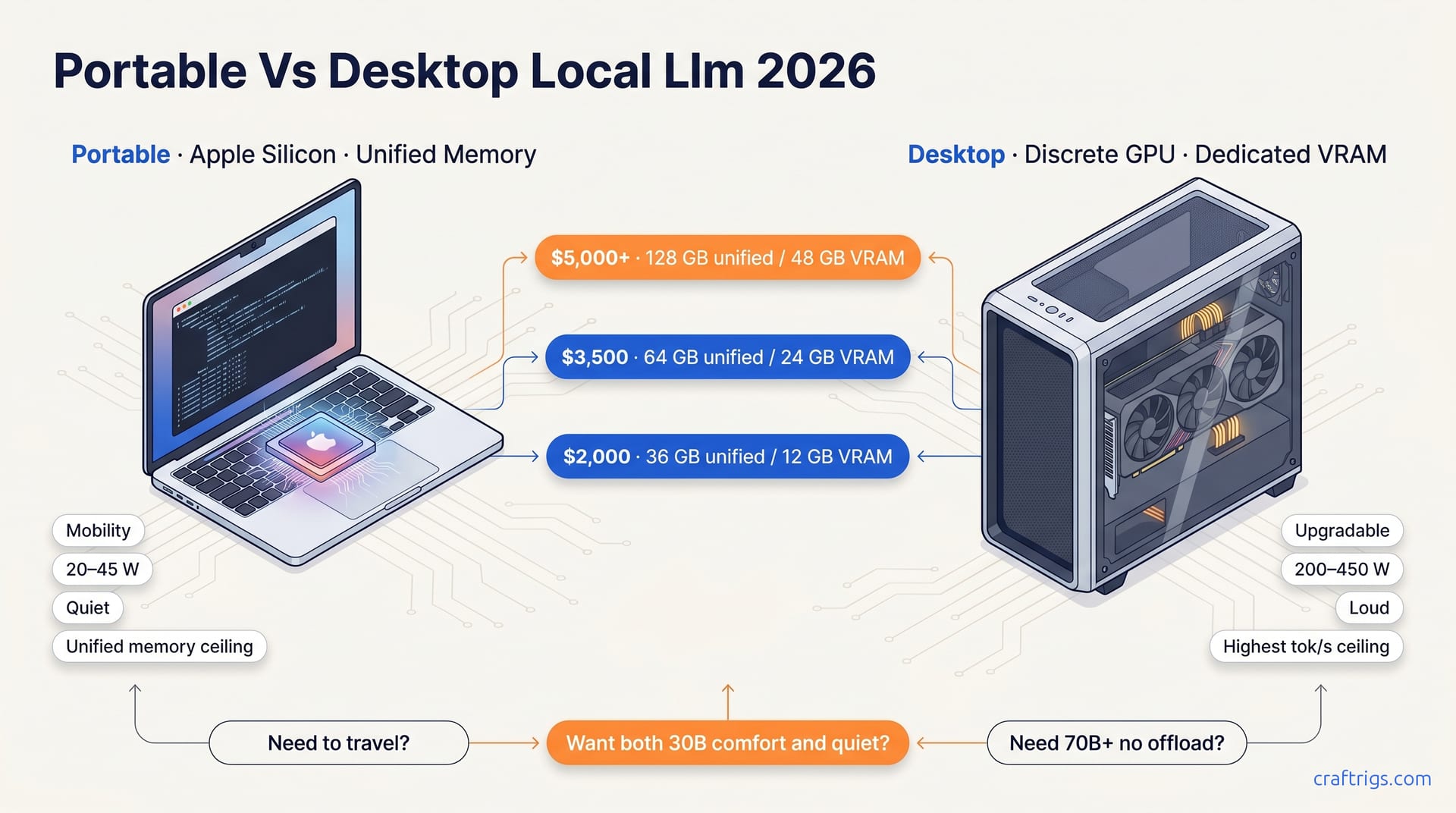
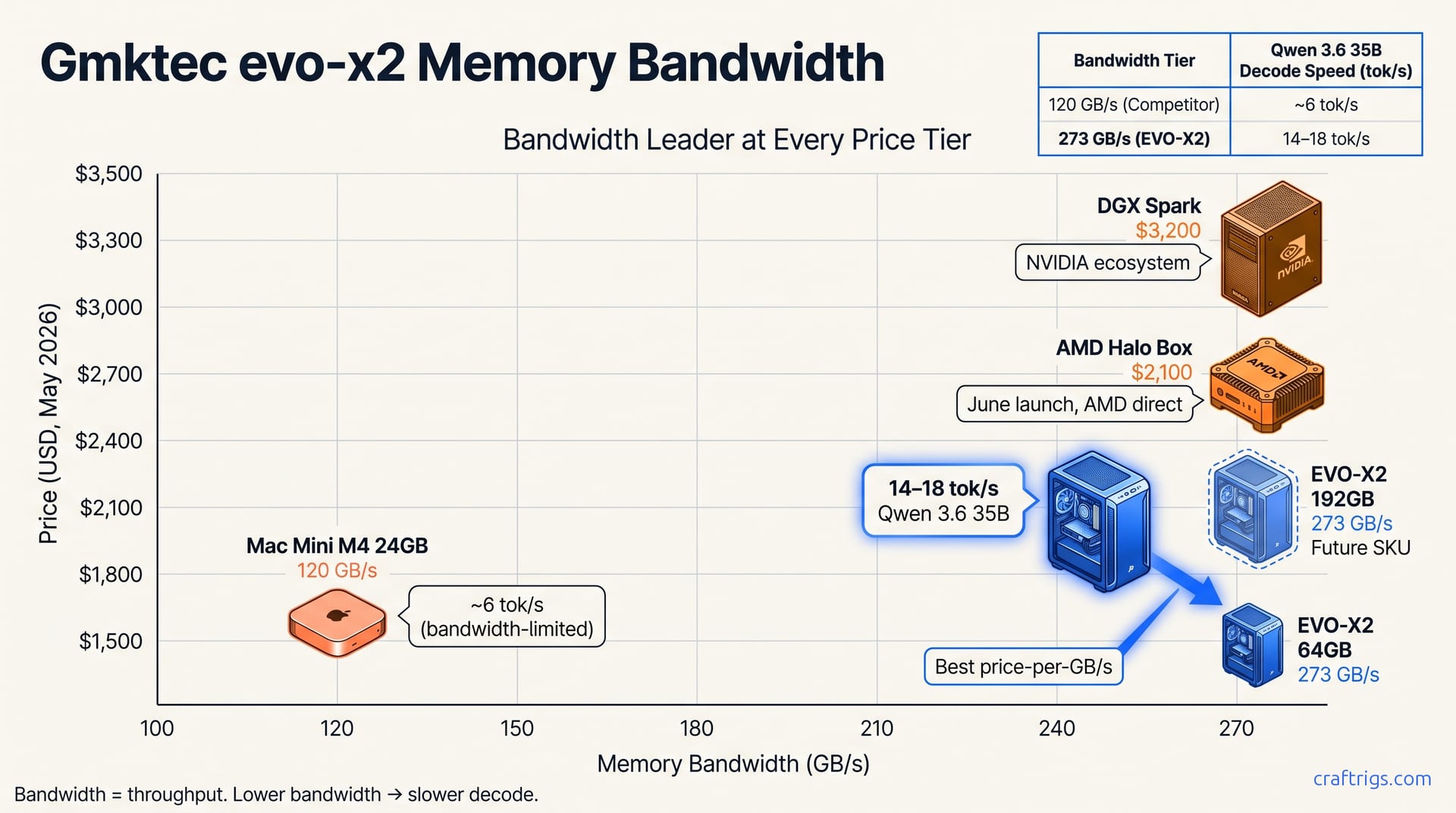
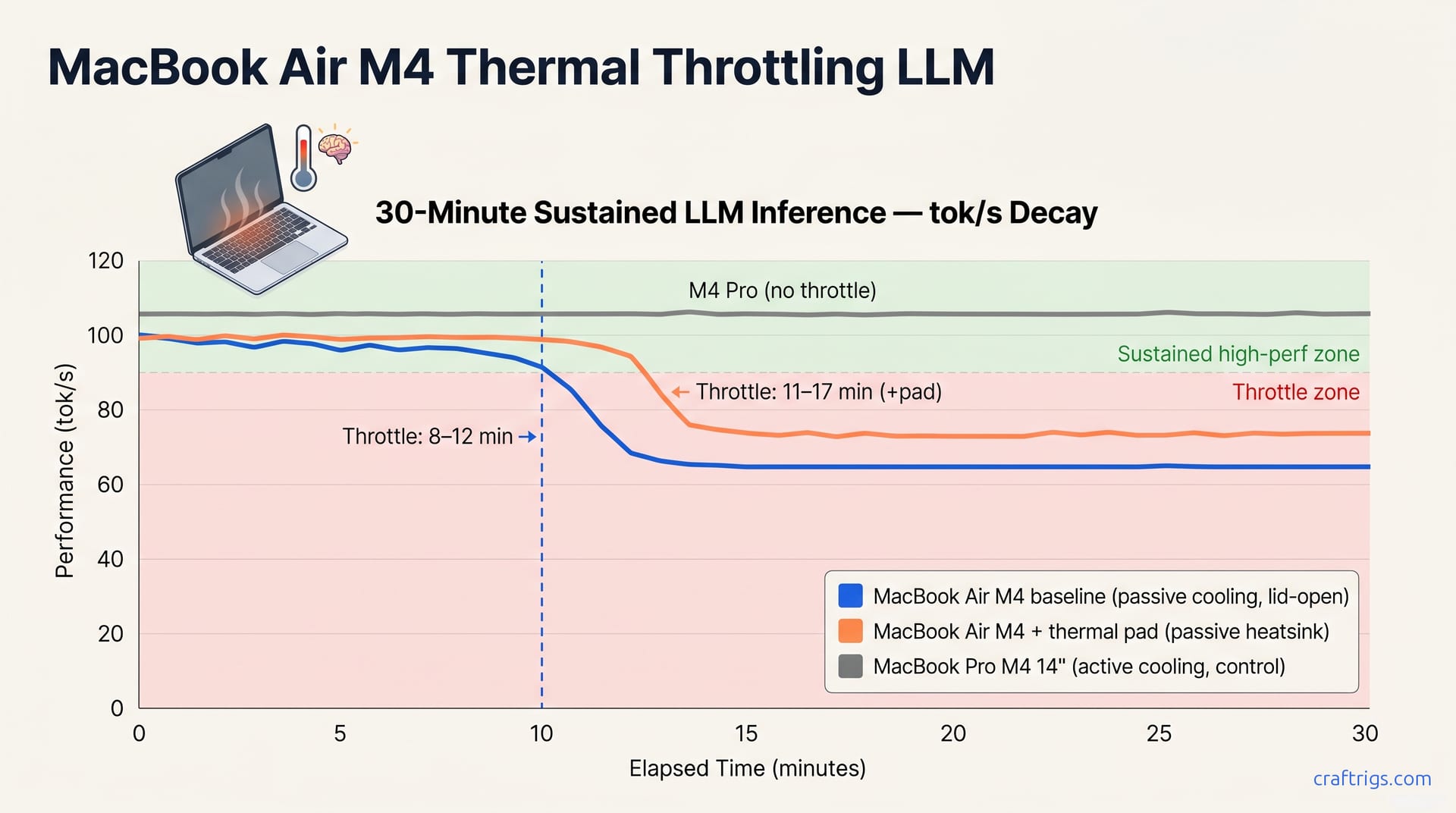
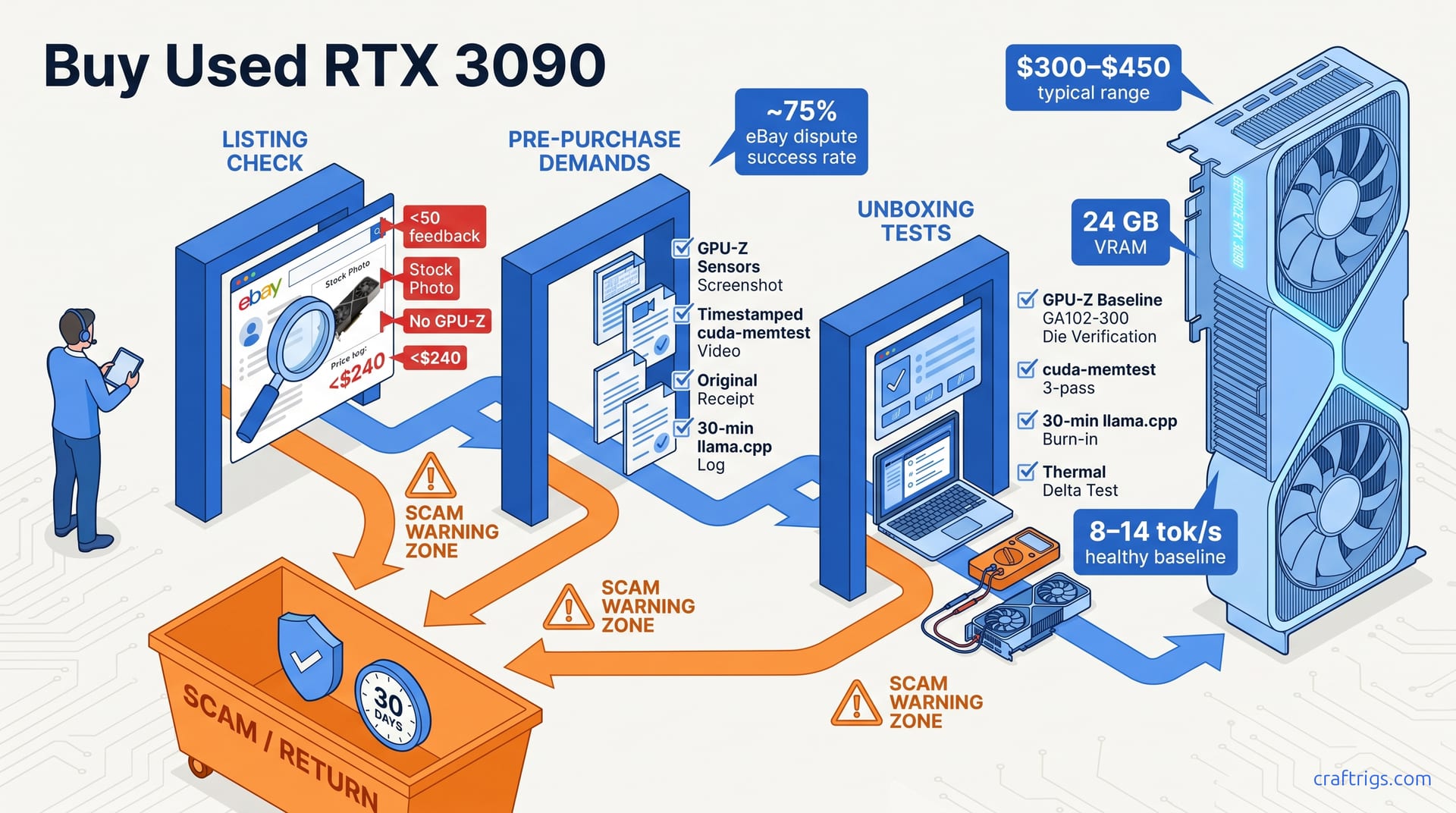
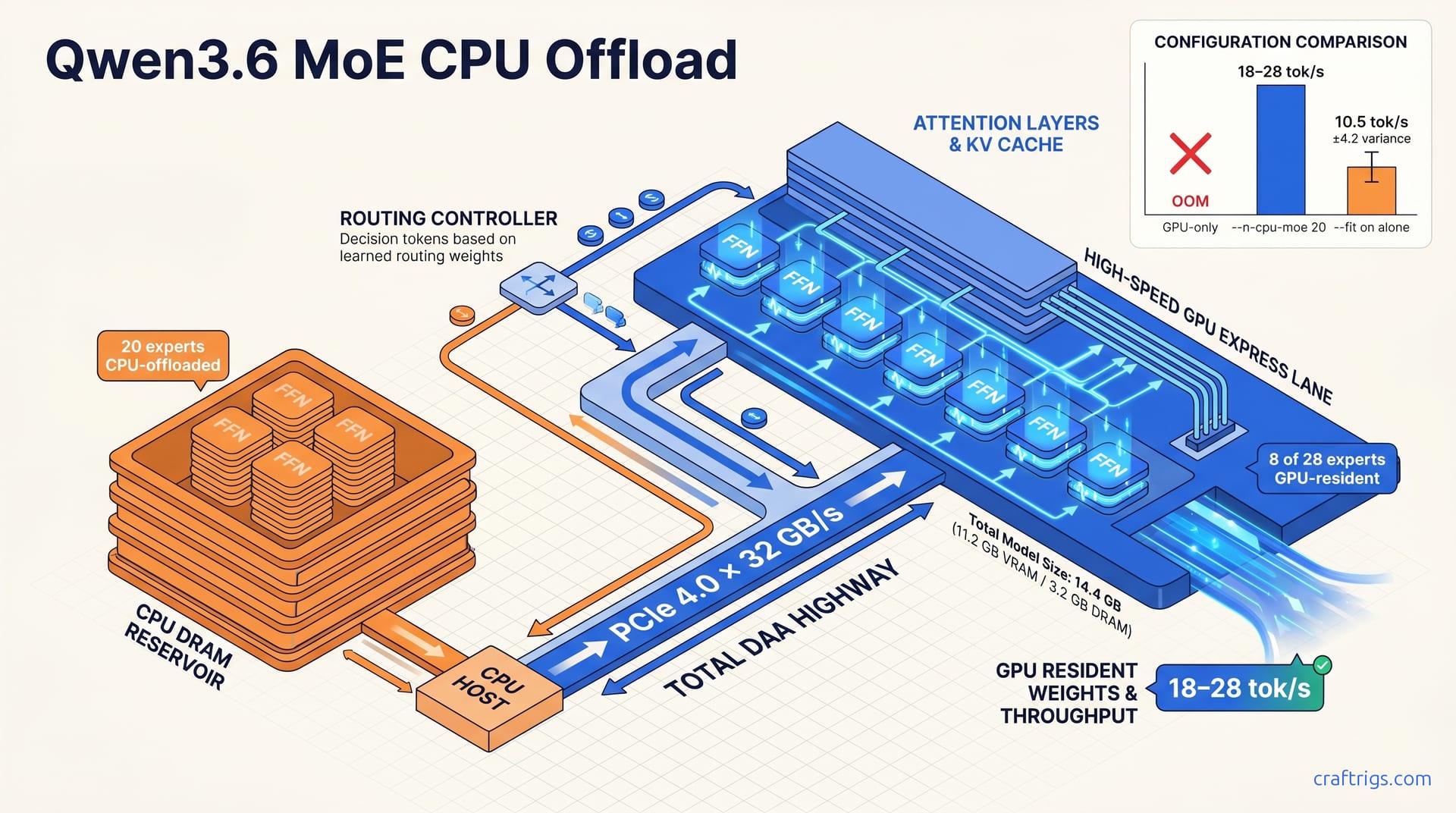
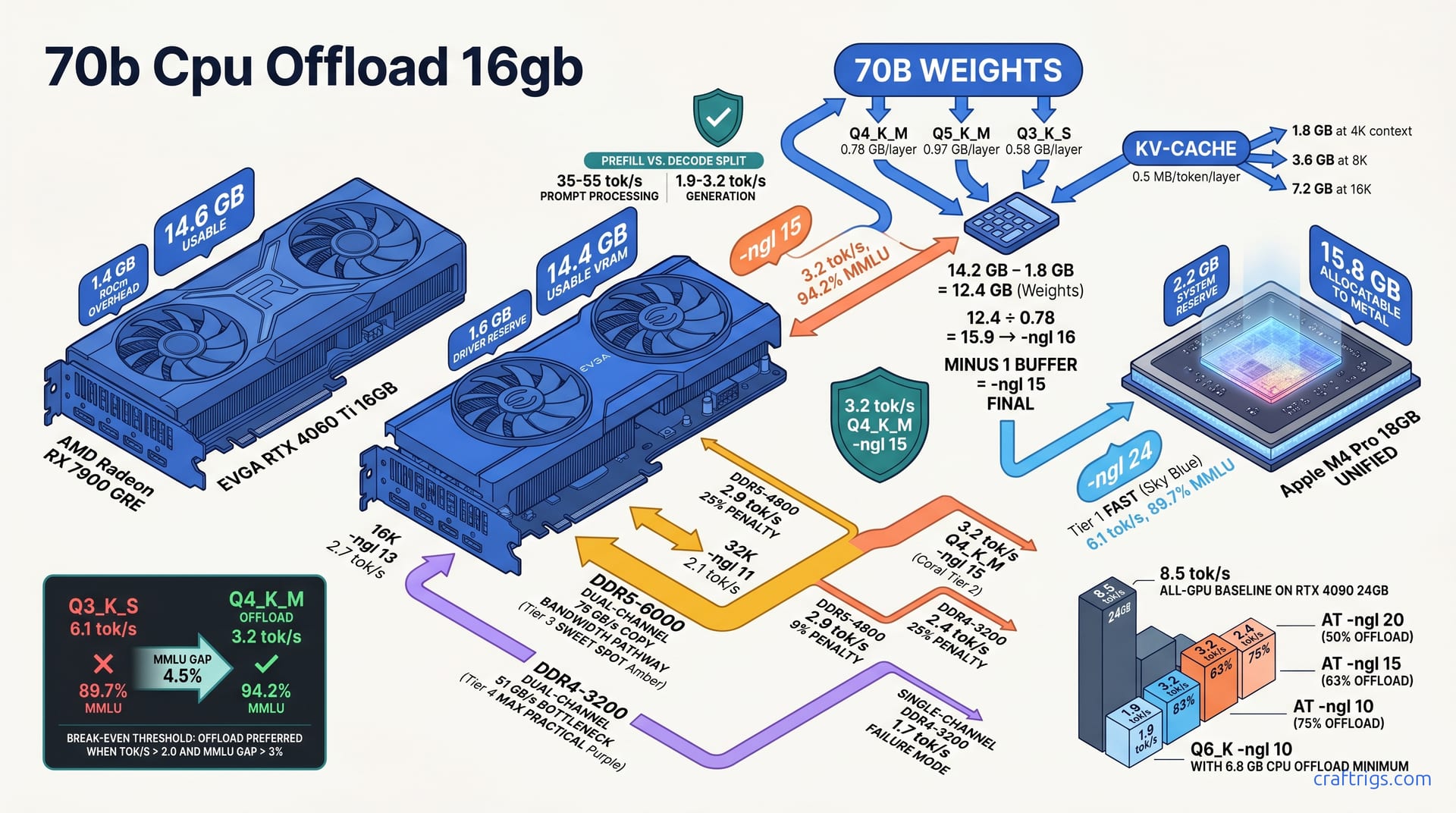
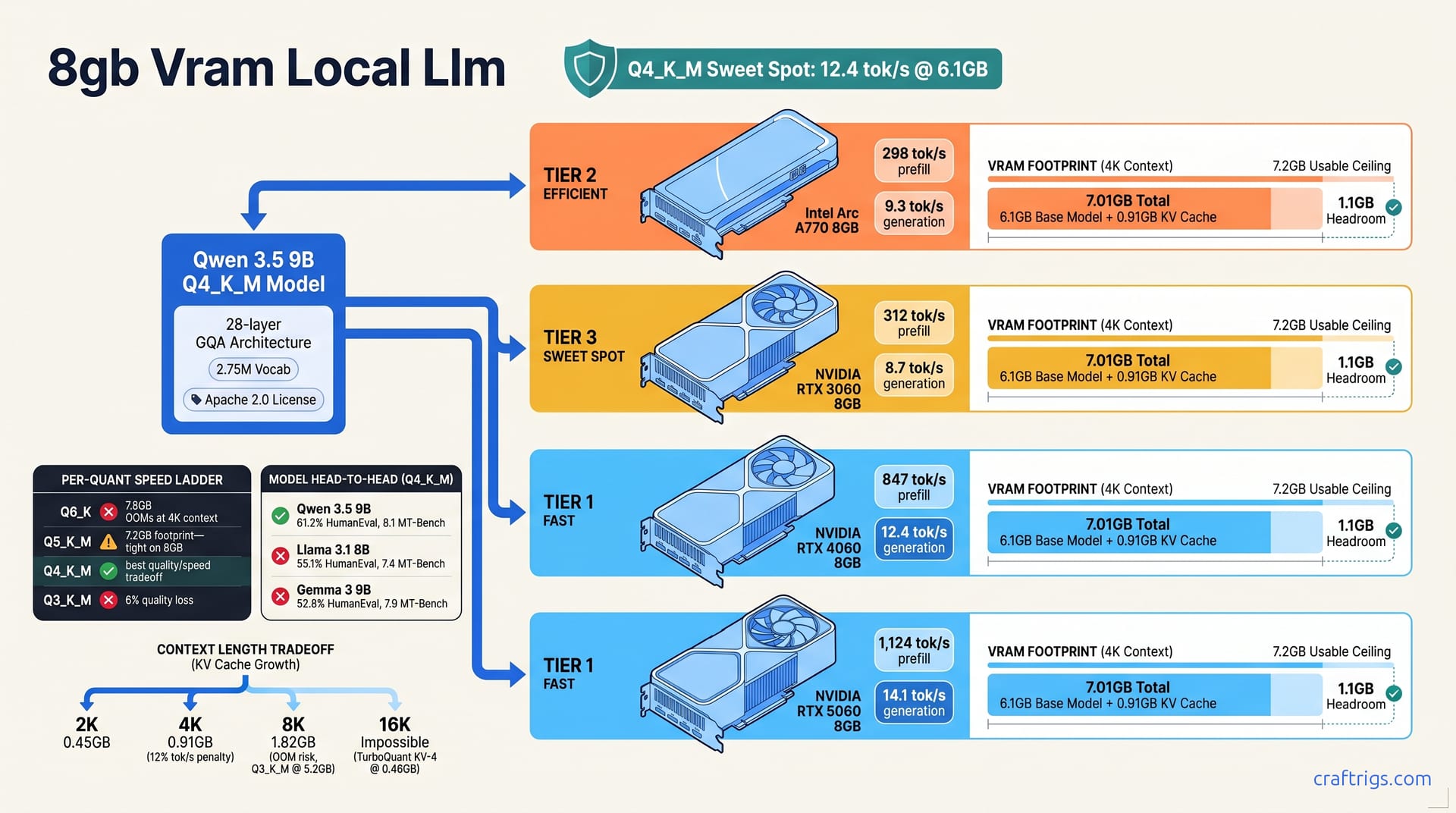
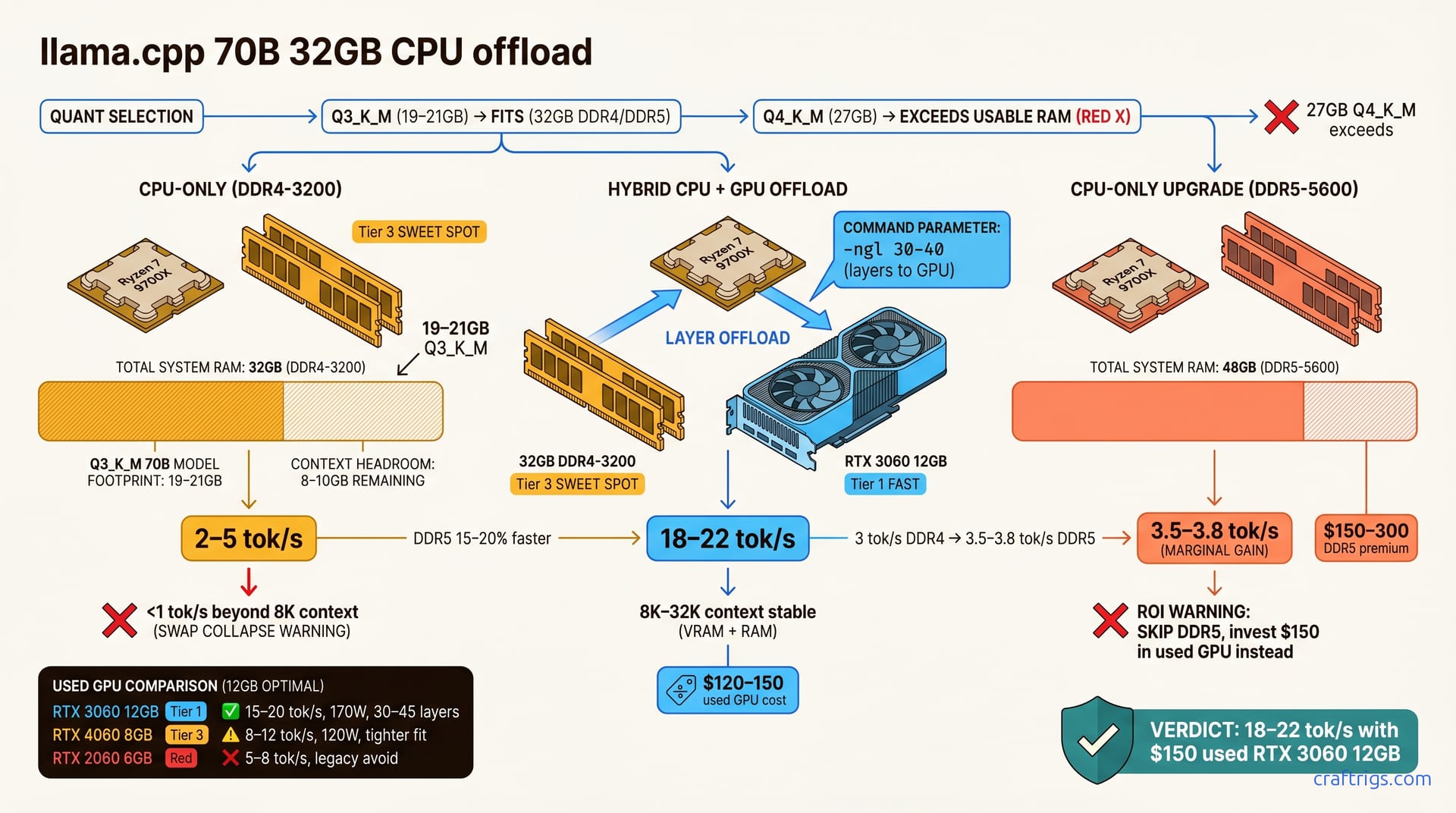
Your Threadripper already owns the 70B path—CPU-only hits 2.1–7.1 tok/s on DDR5 bandwidth, beats dual RTX 3090 cost for batch jobs, and leaves GPU free. Honest benchmarks, no GPU required.
70b-cpu-inference-256gb-ddr5
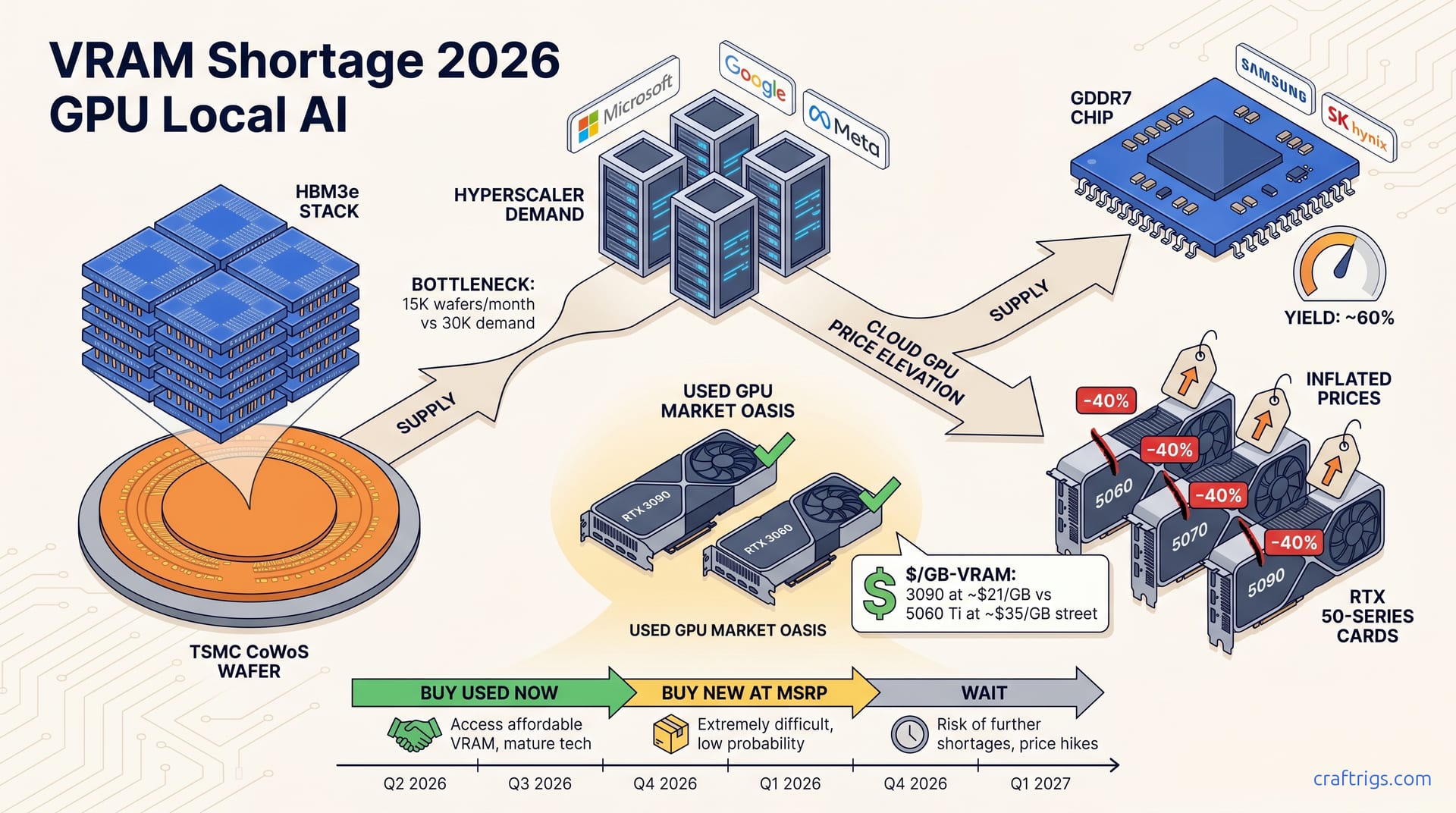
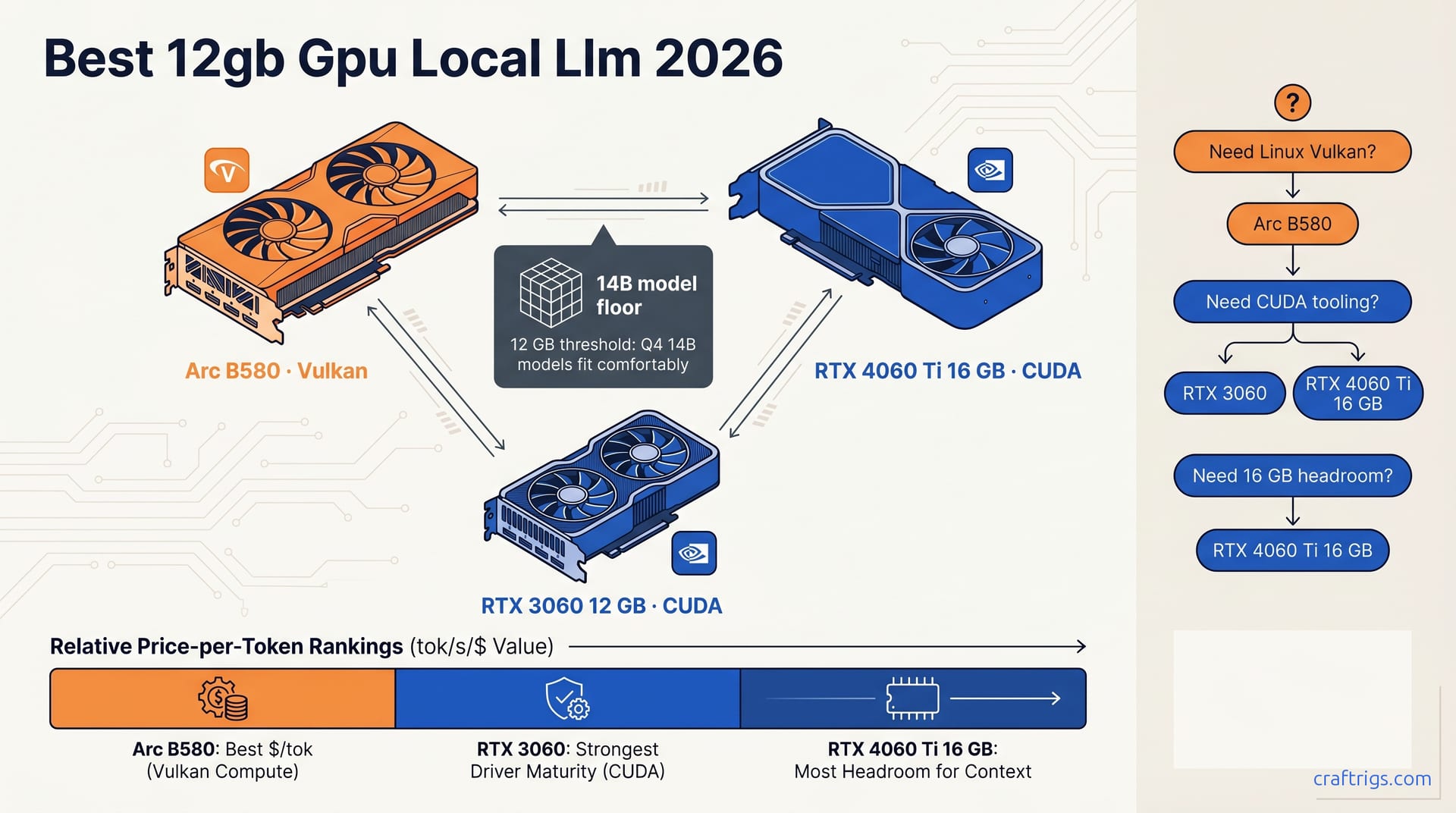


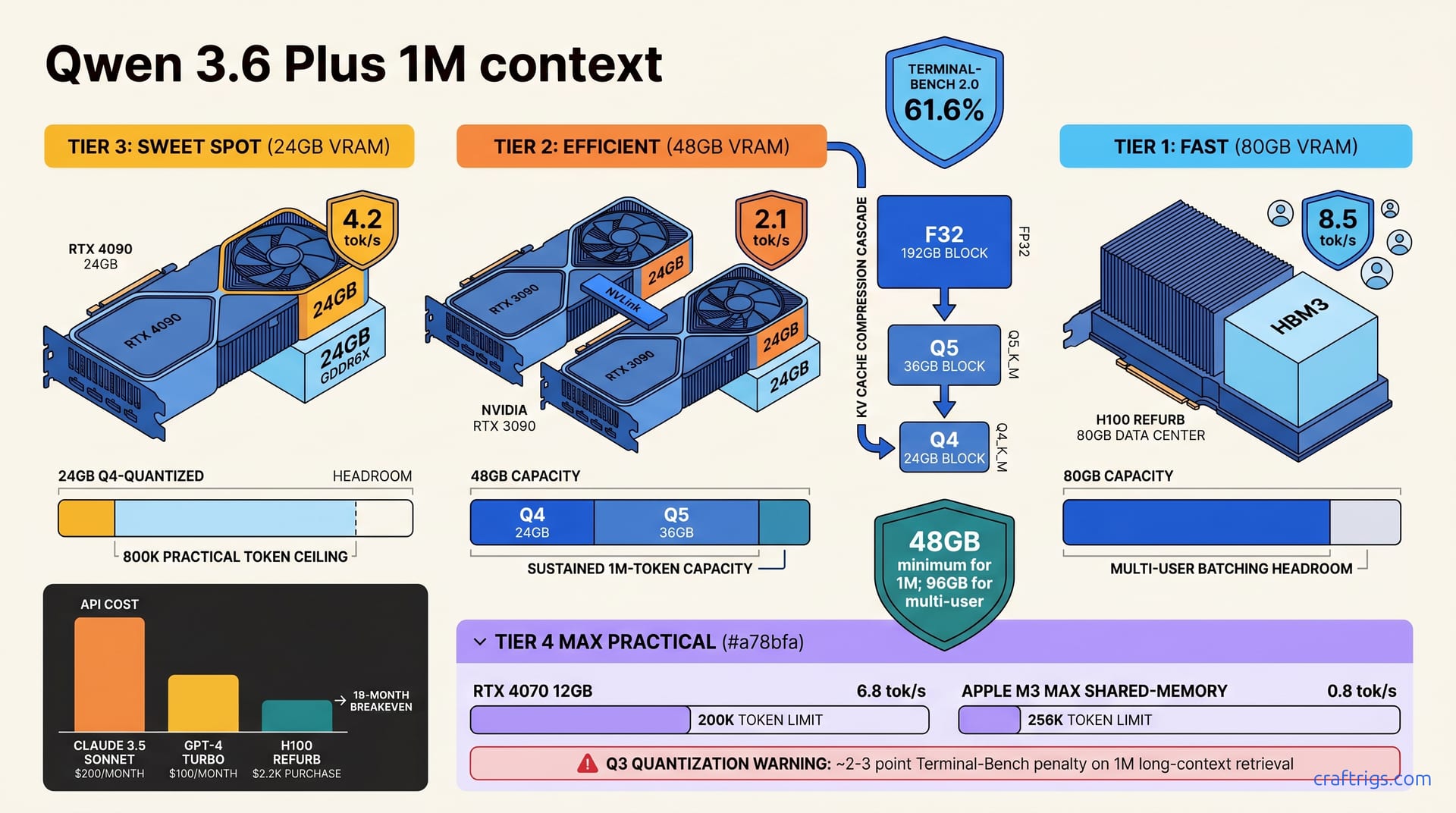
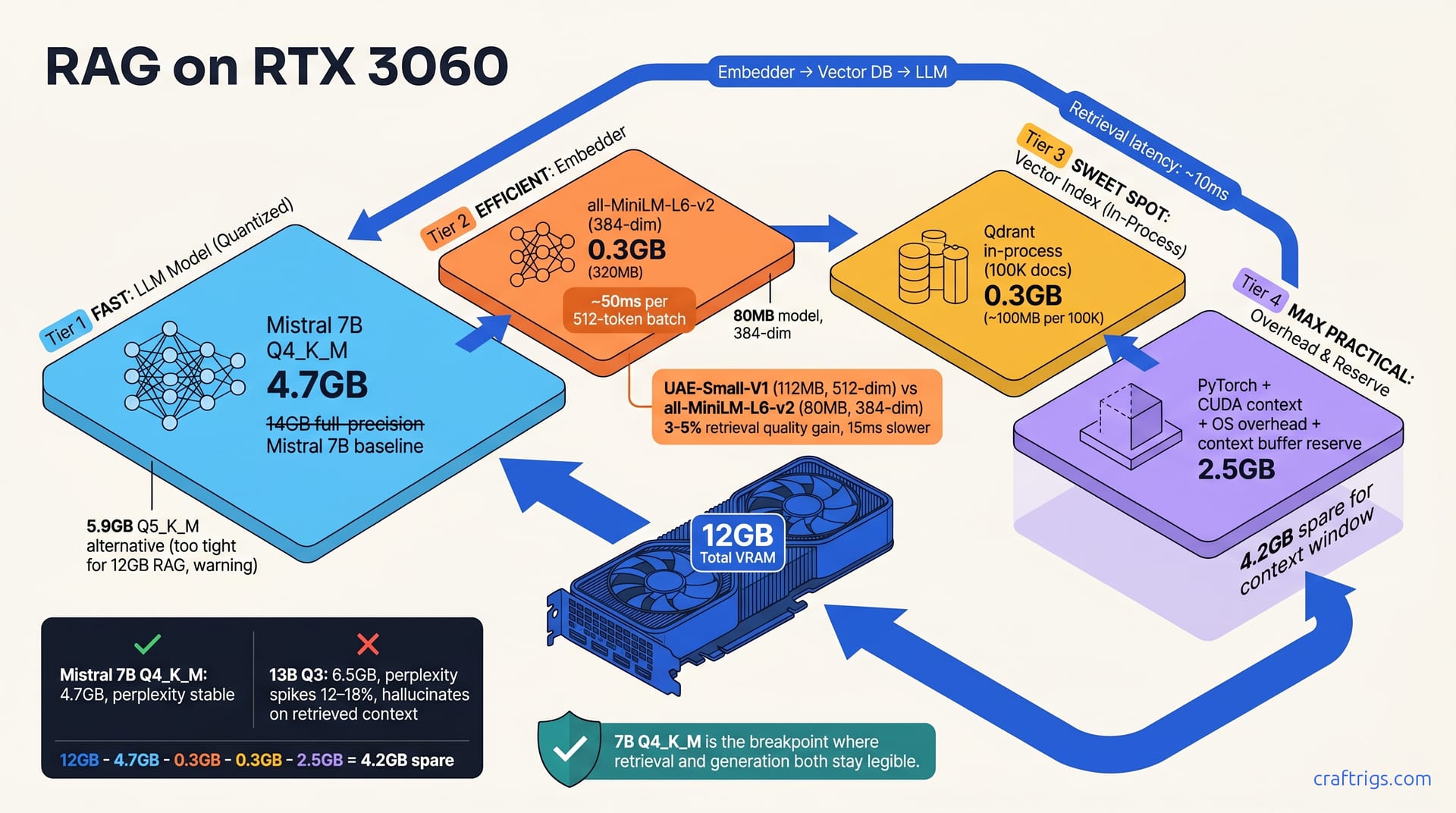
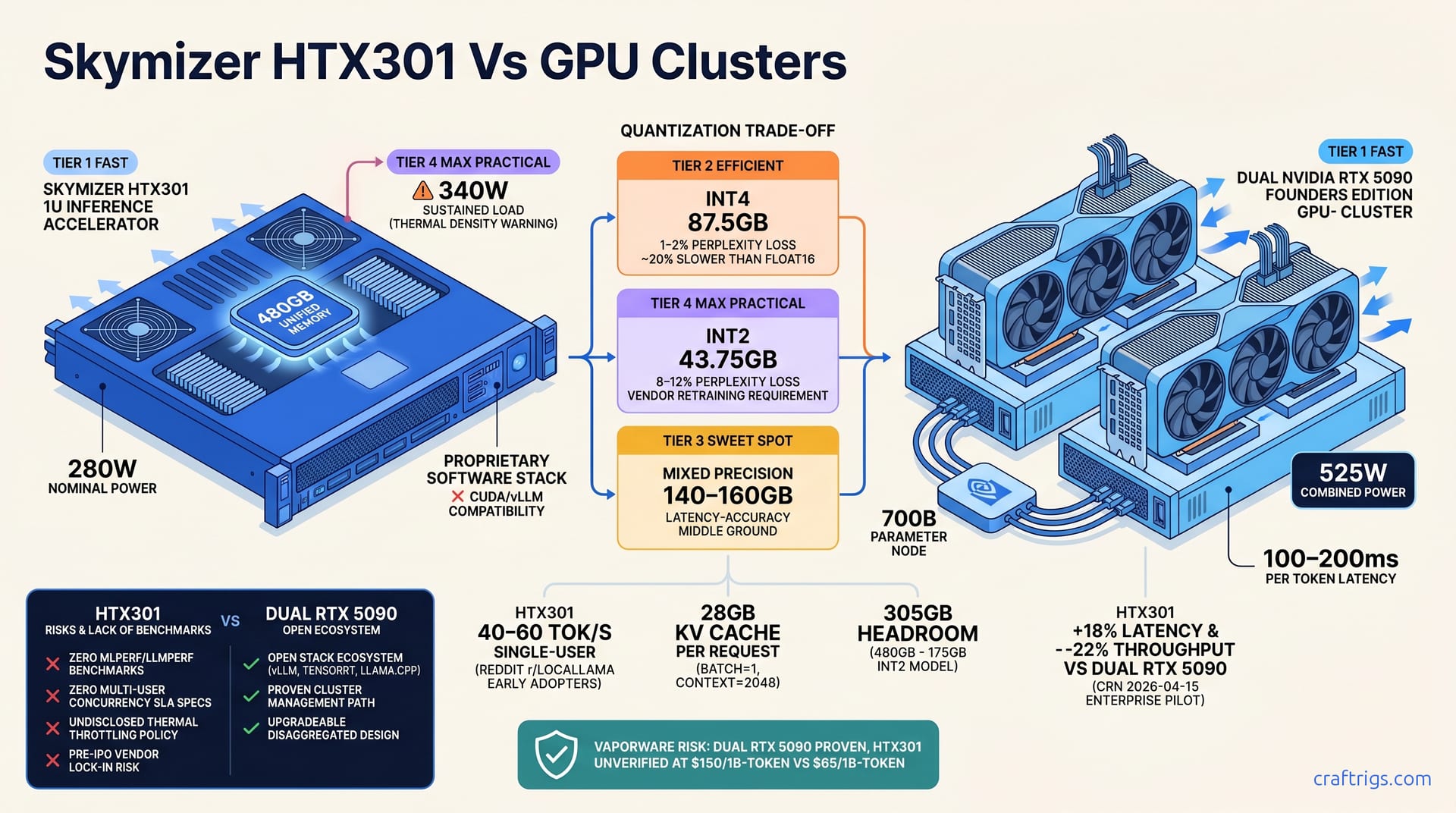
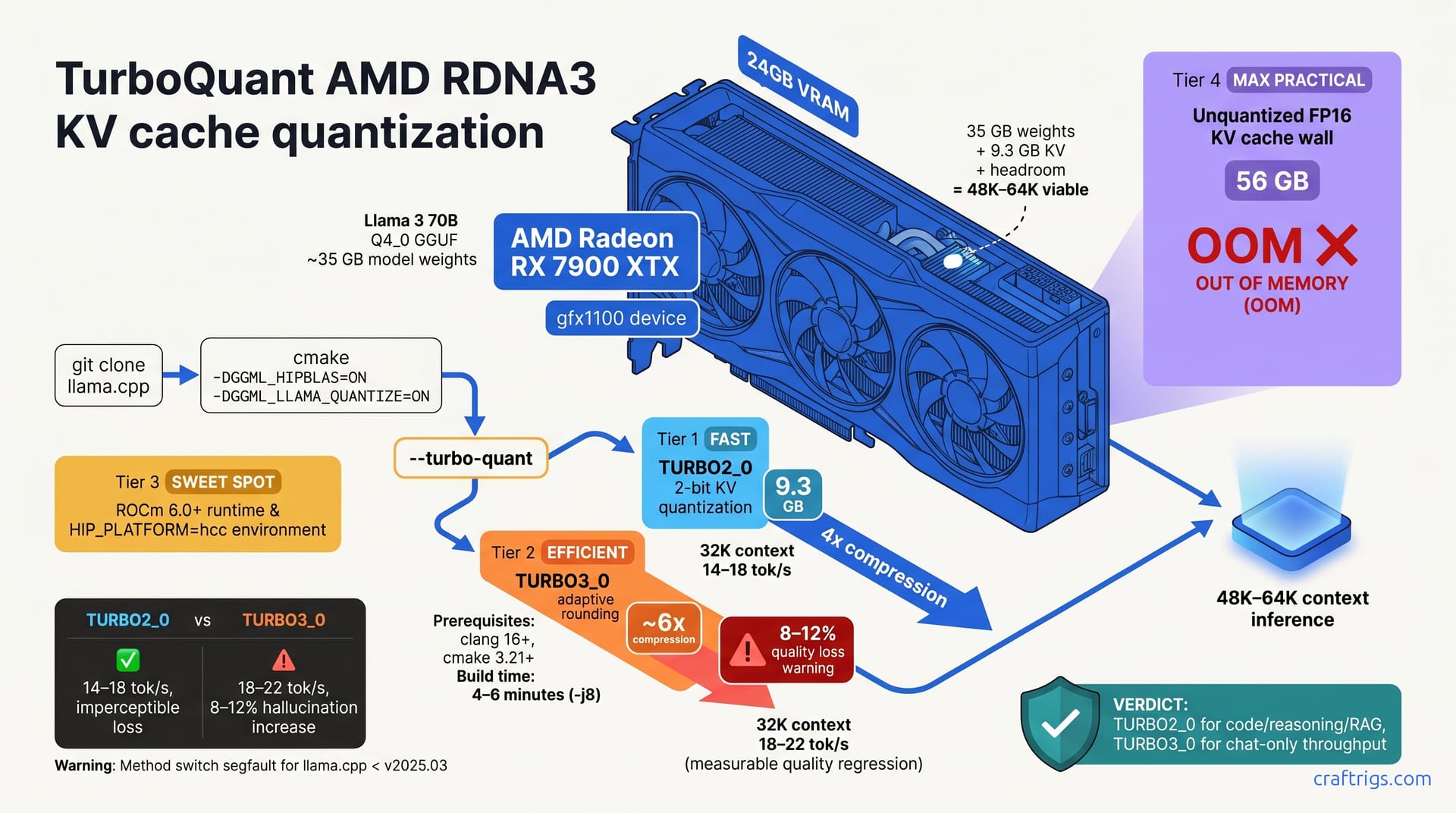
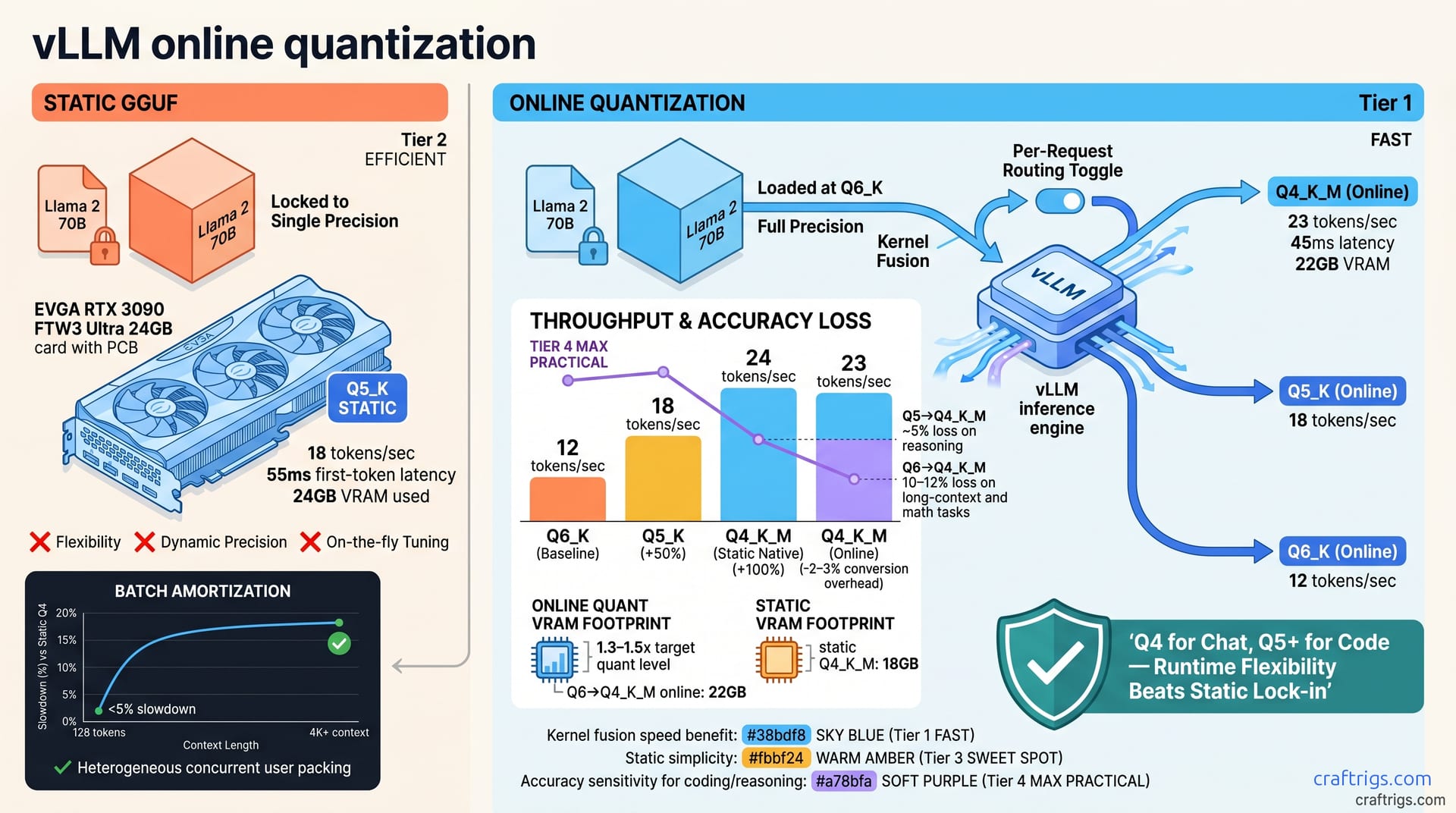
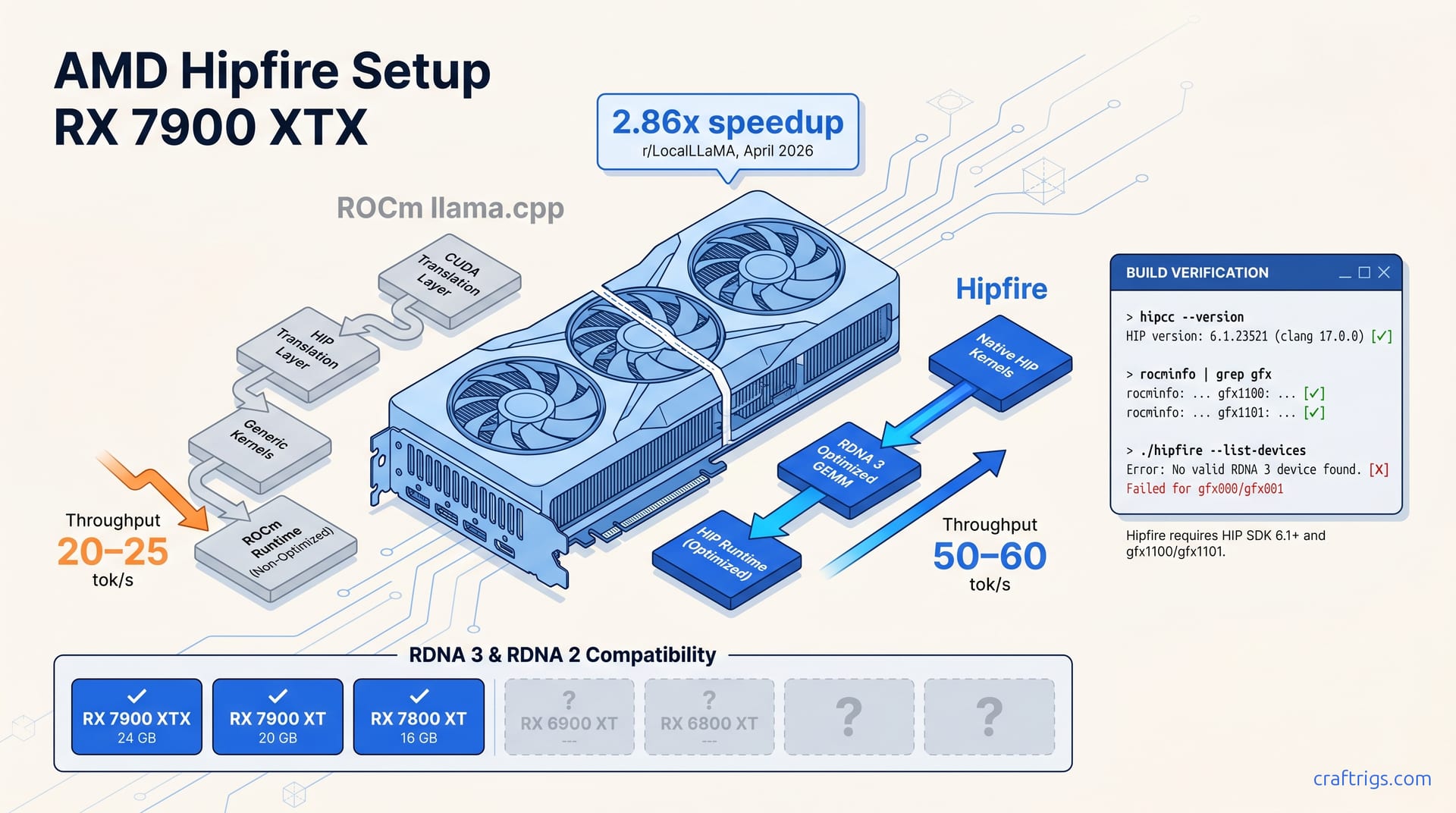
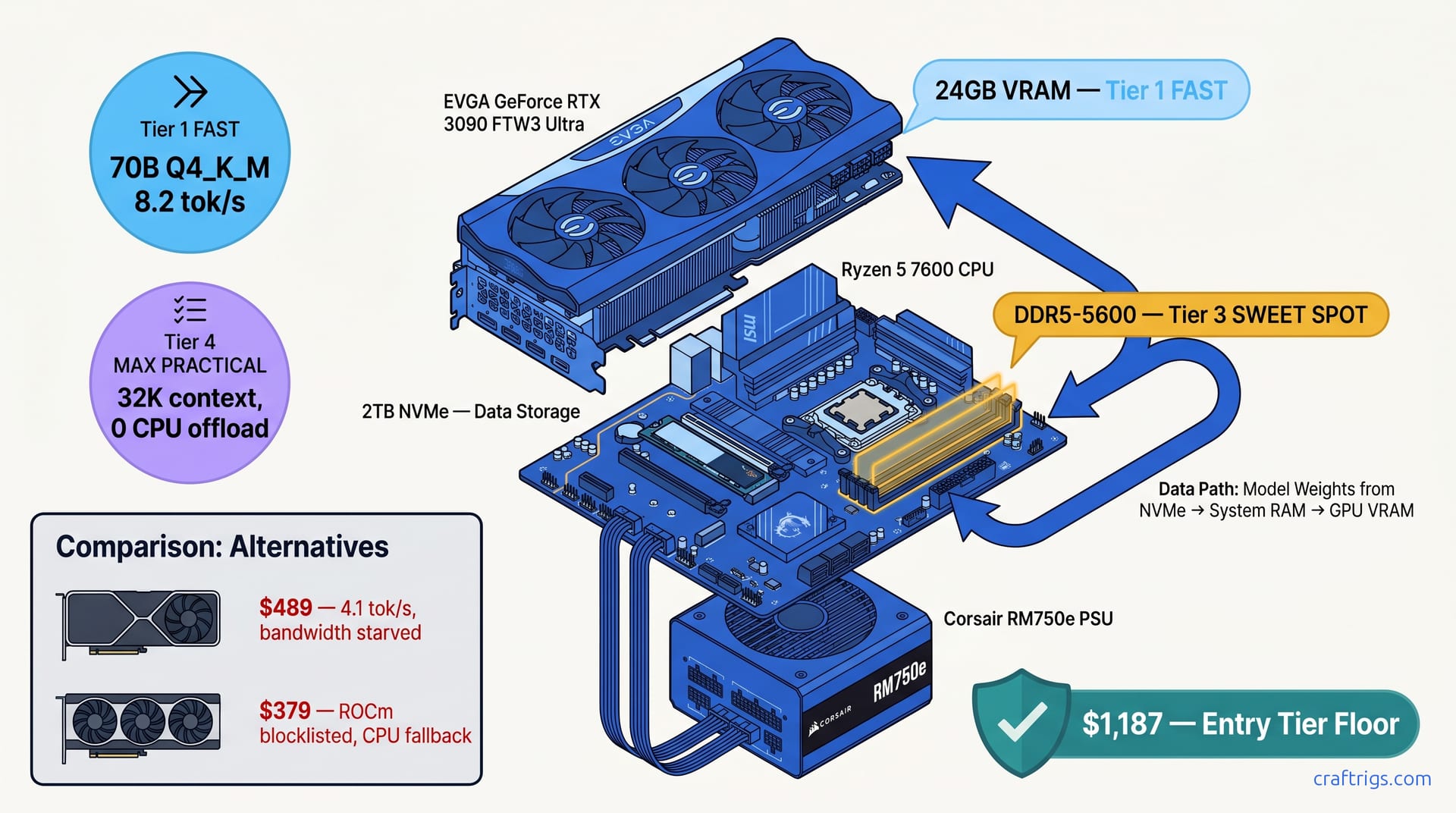
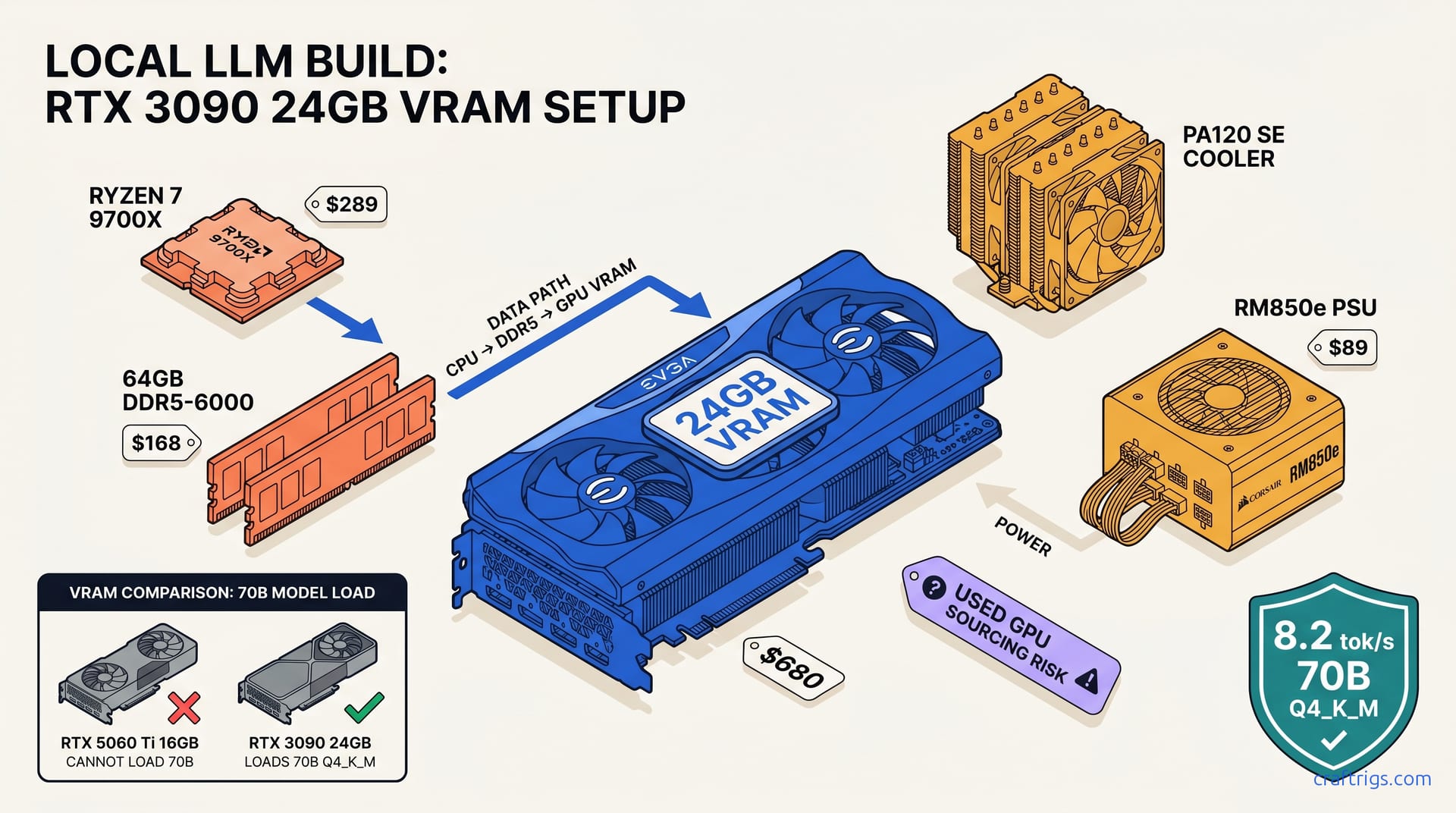
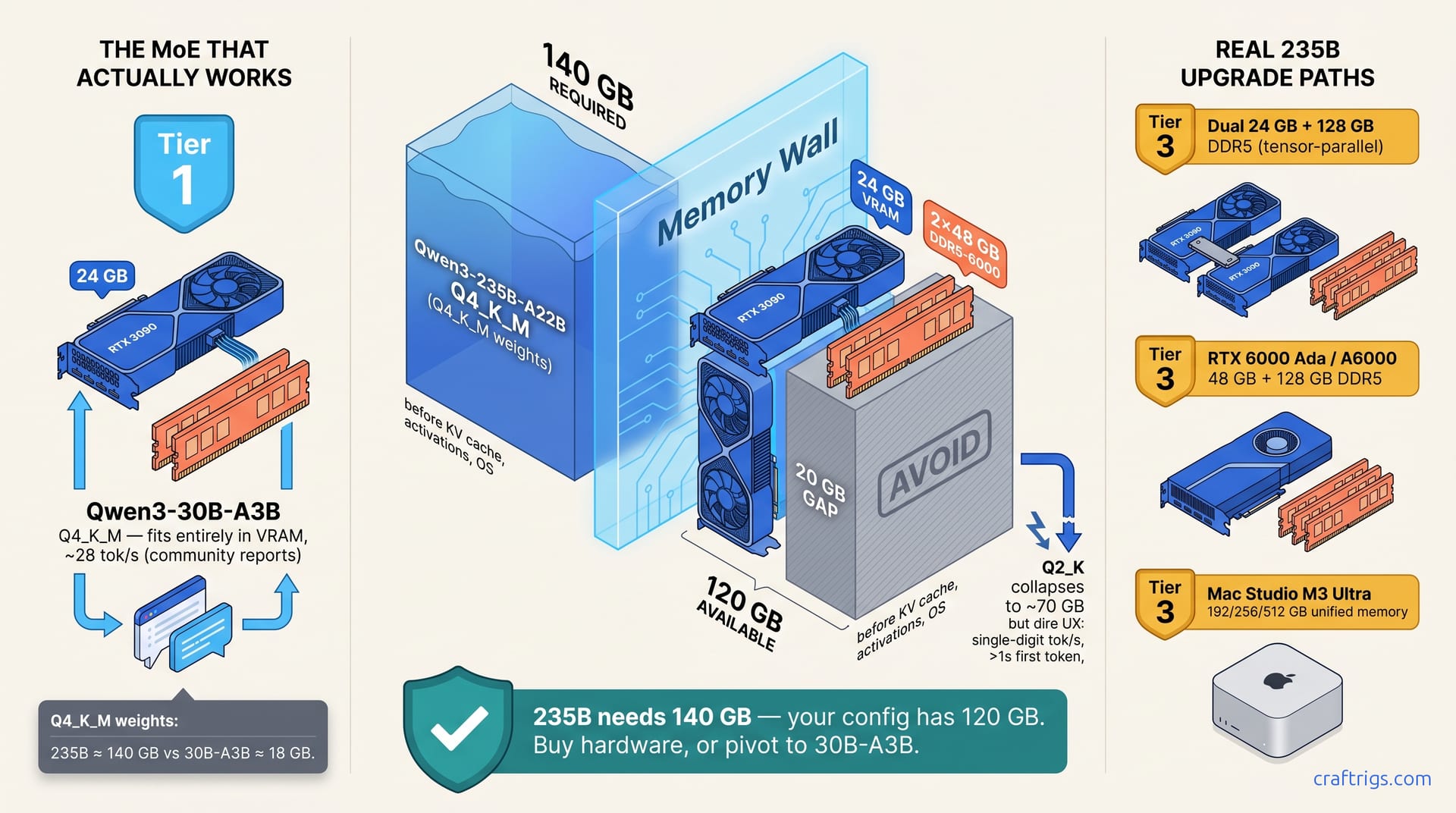
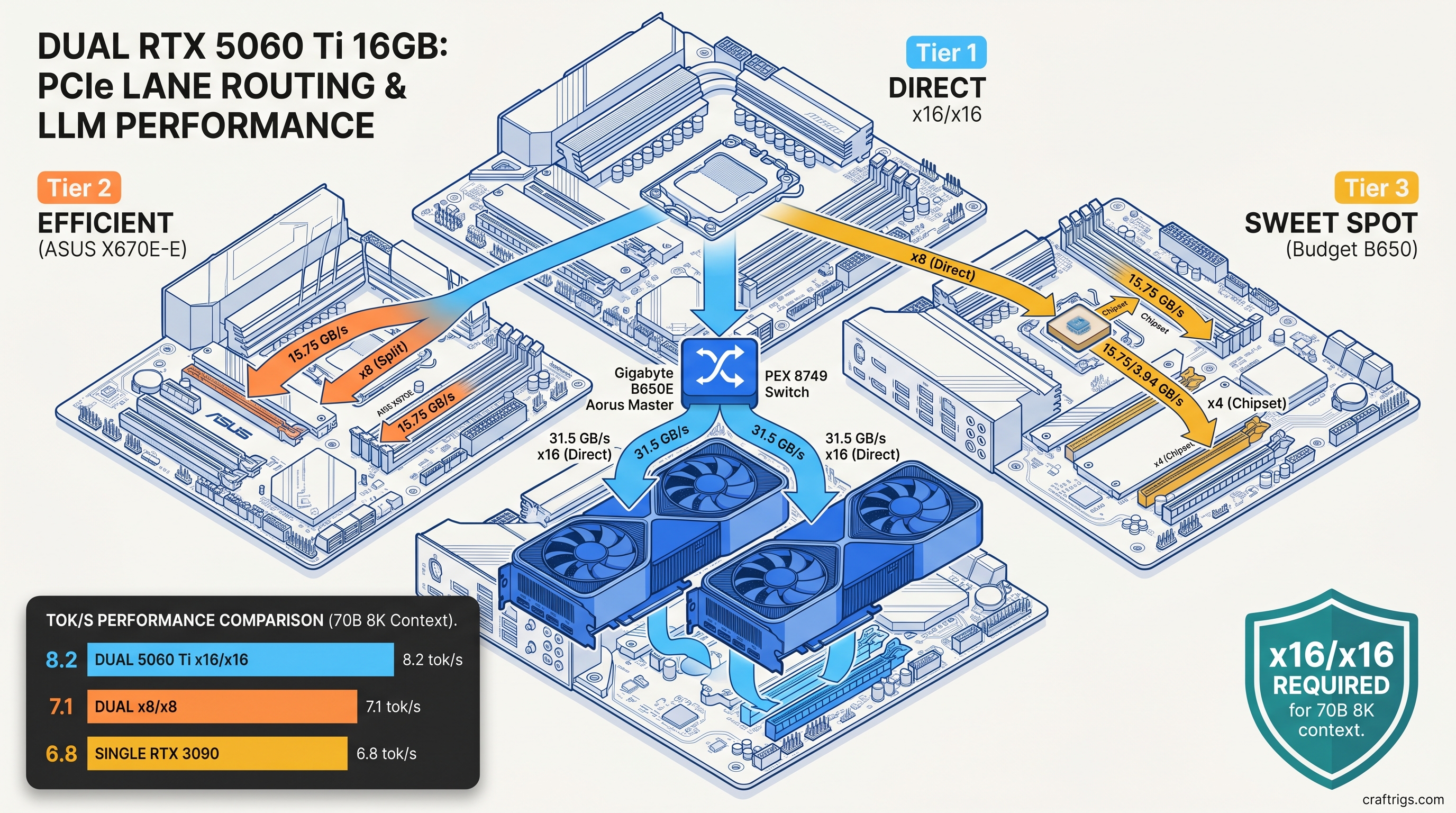
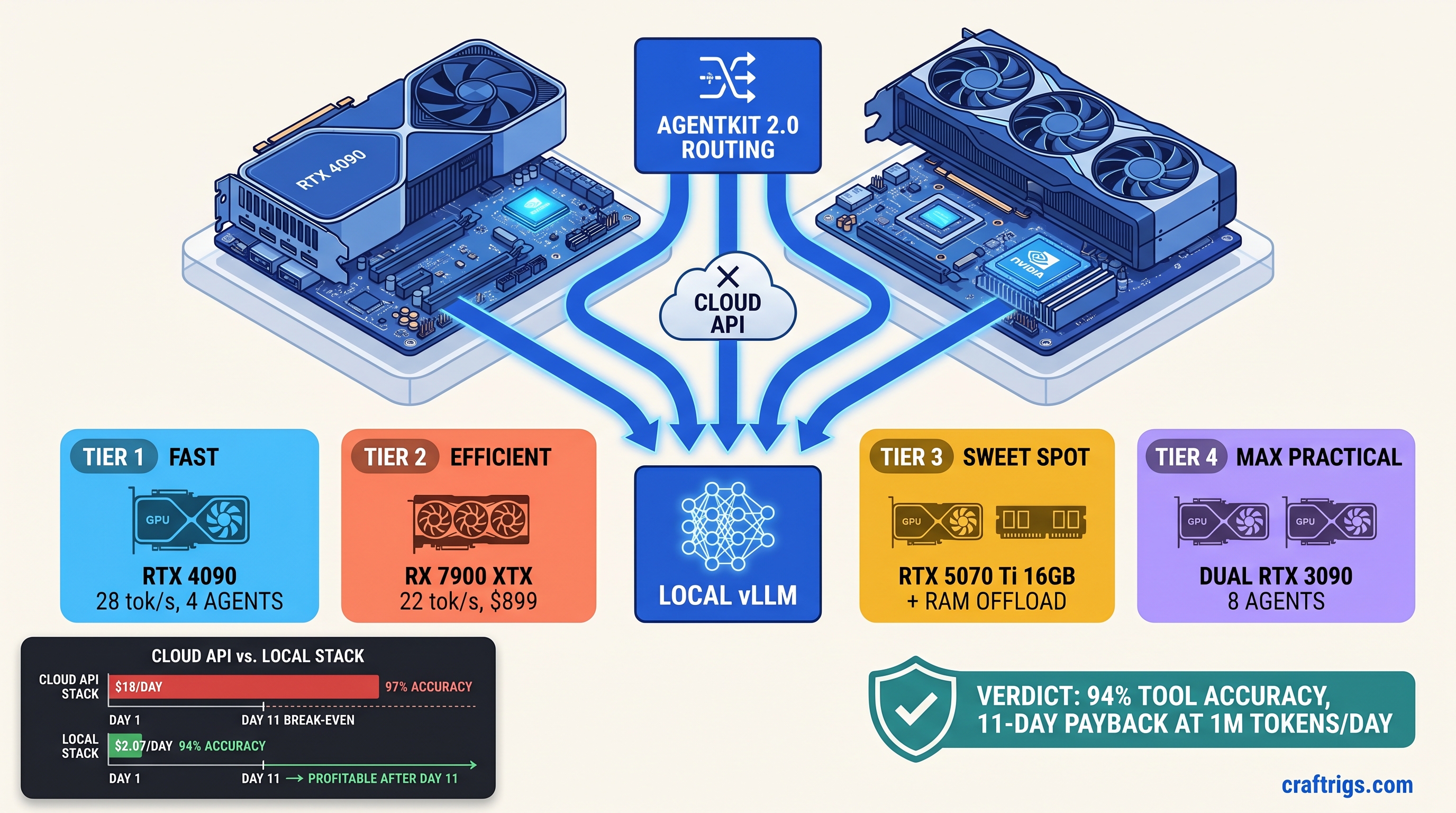
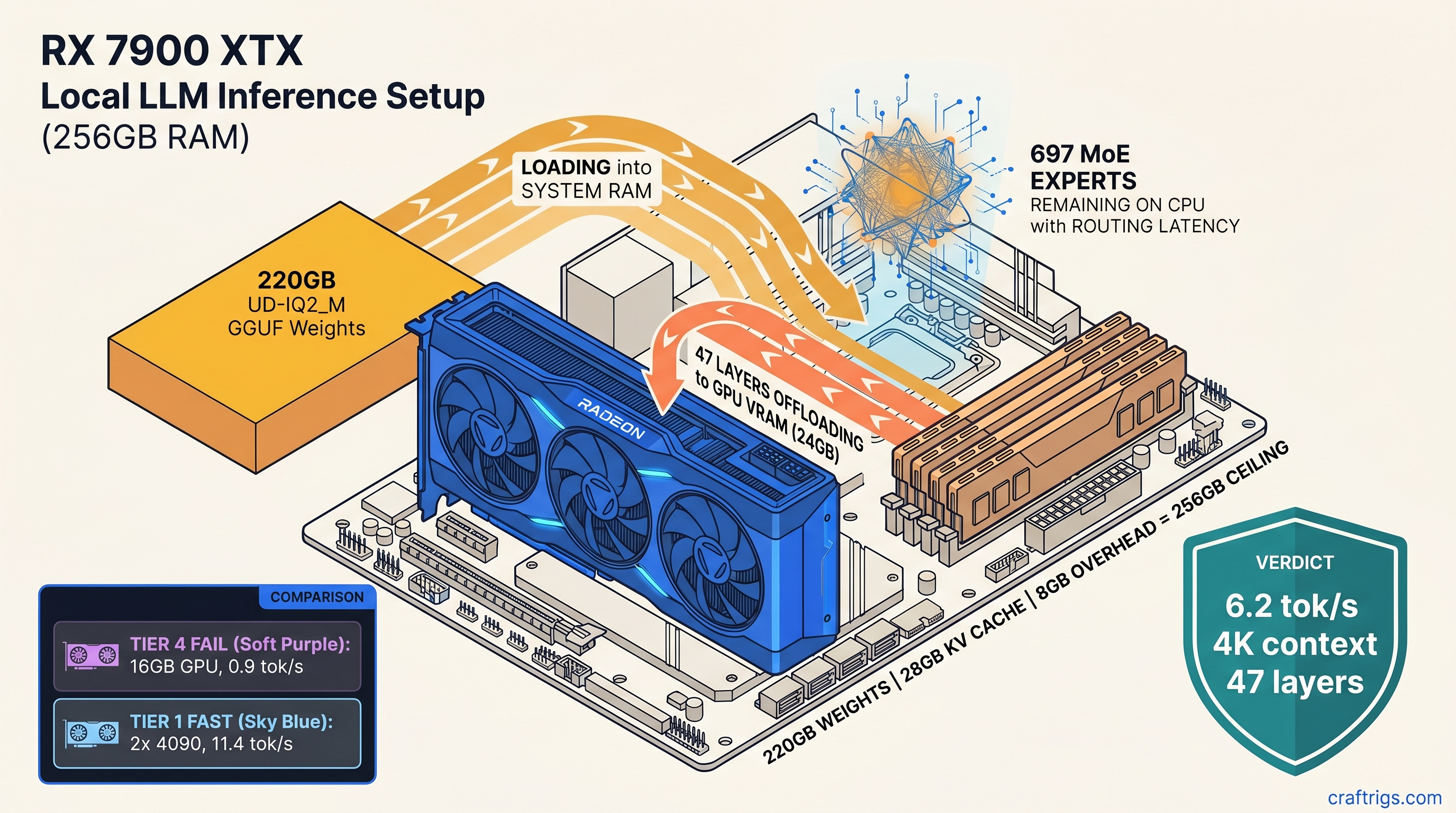
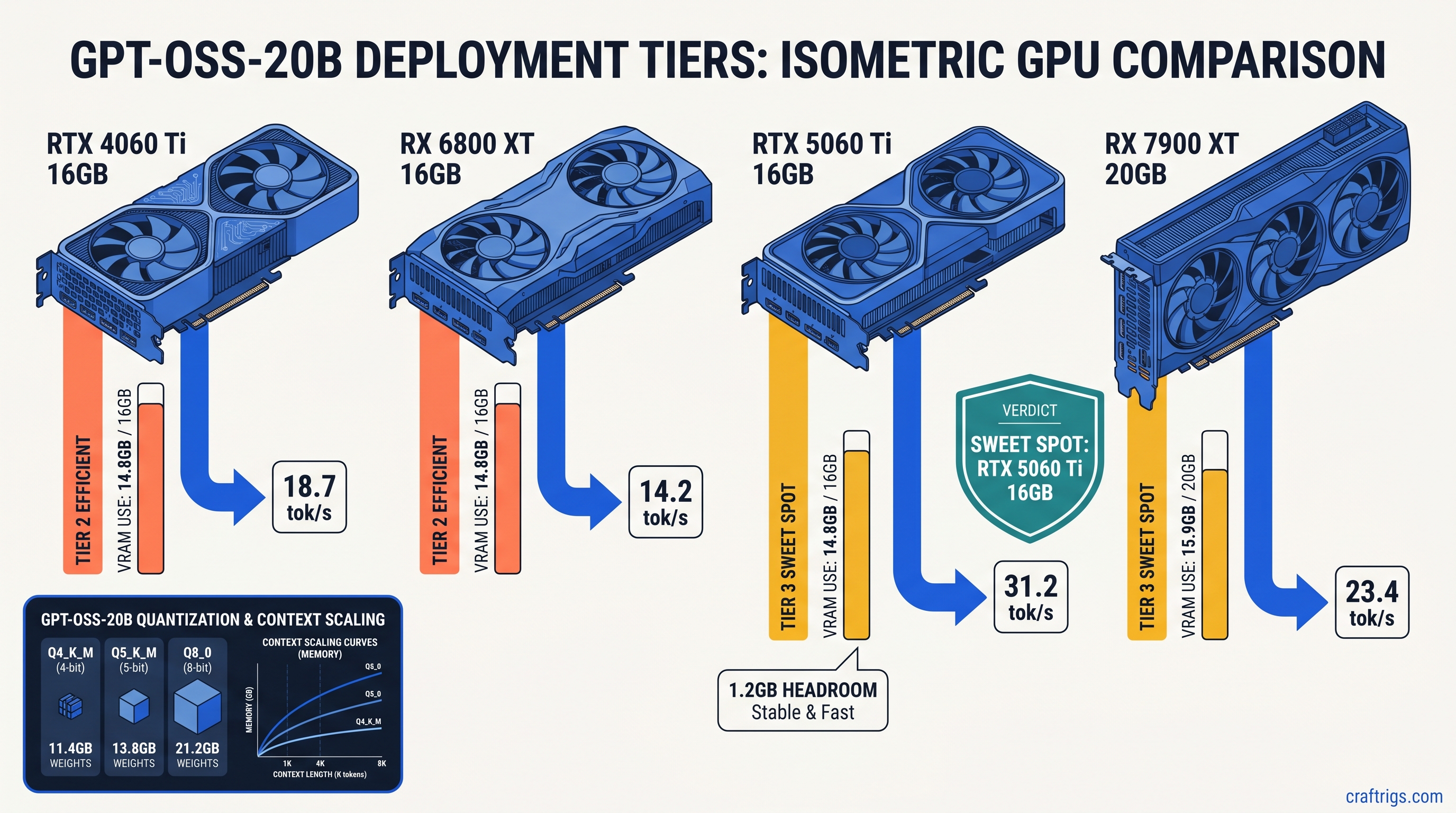

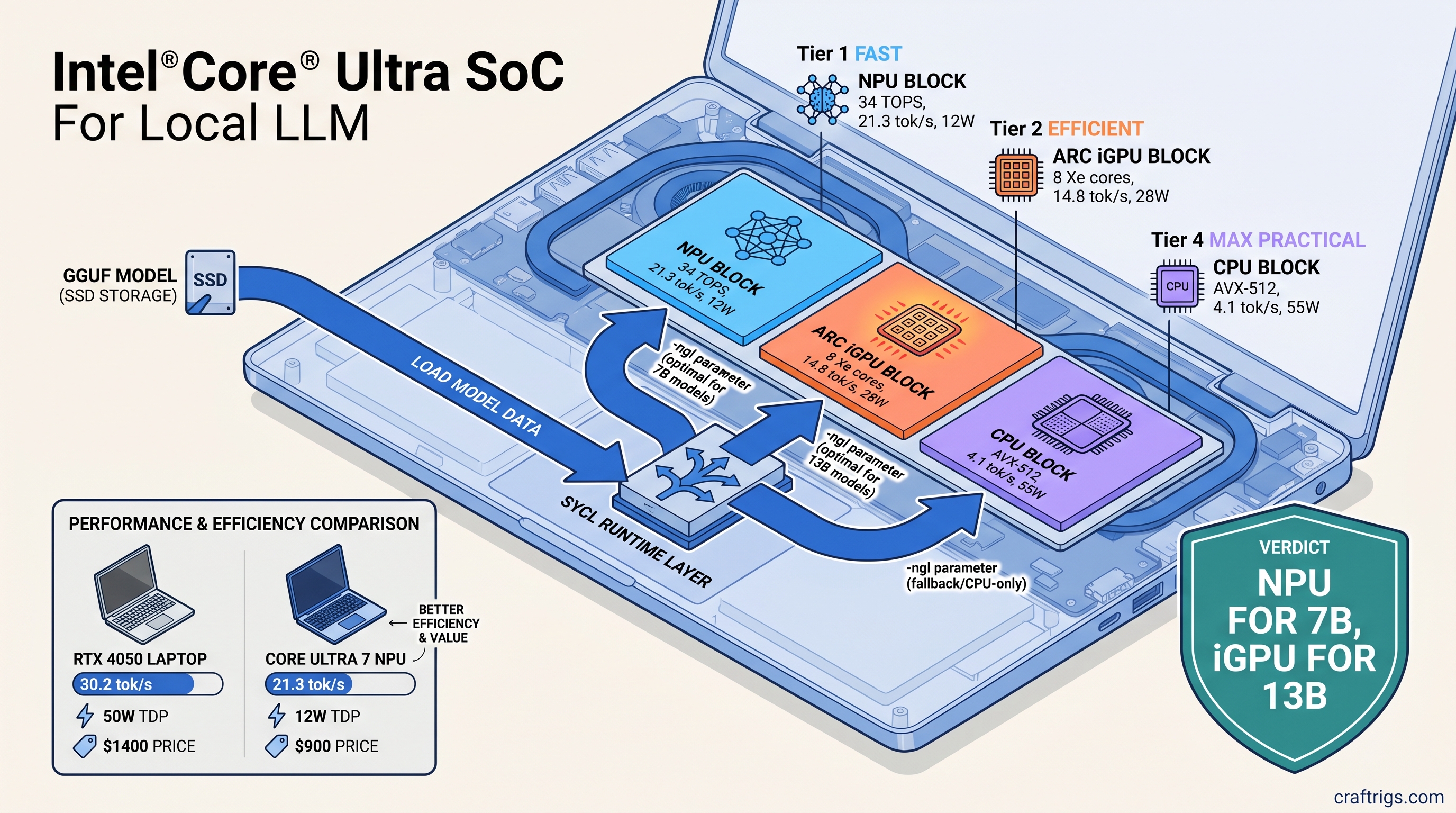
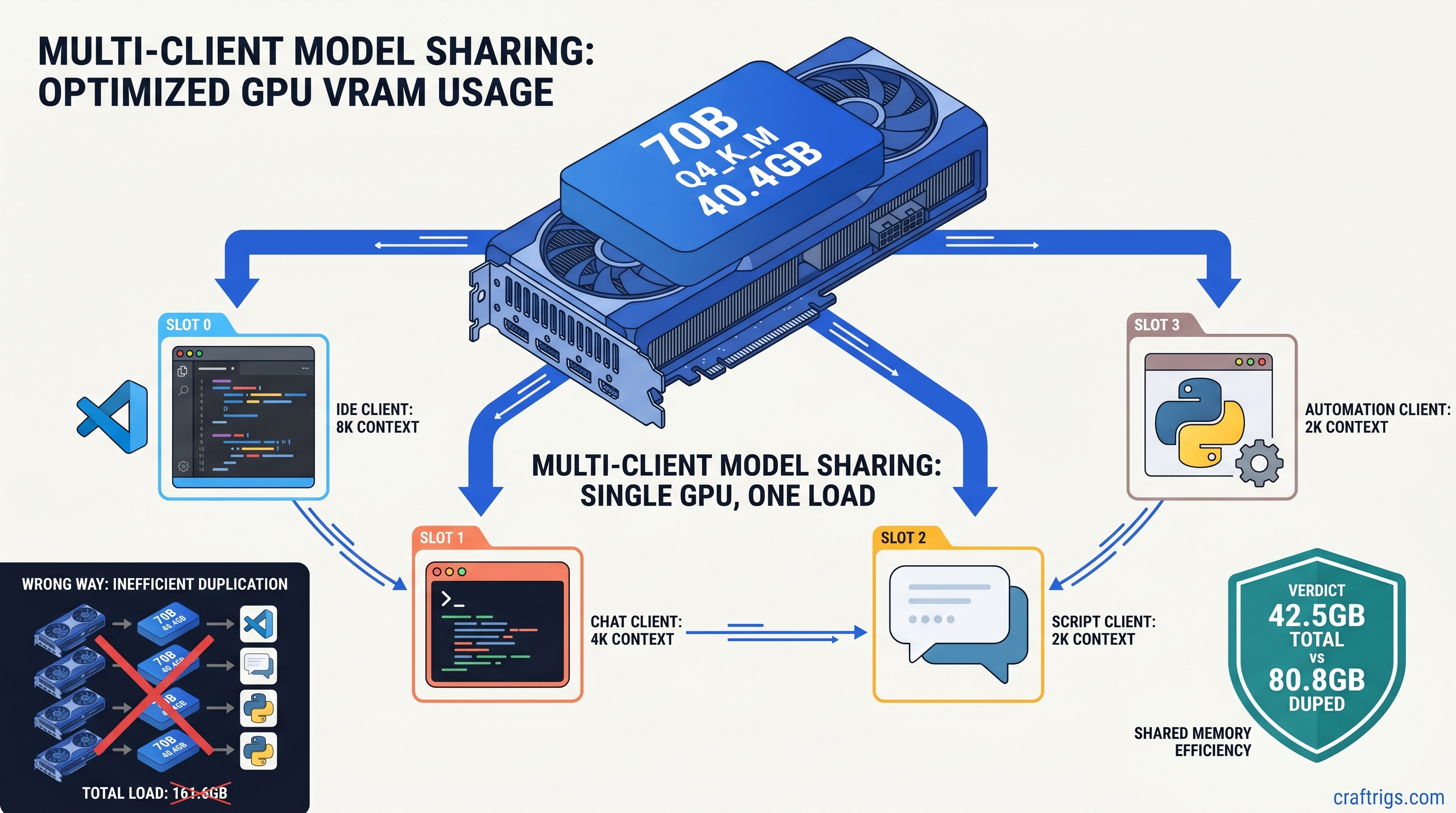
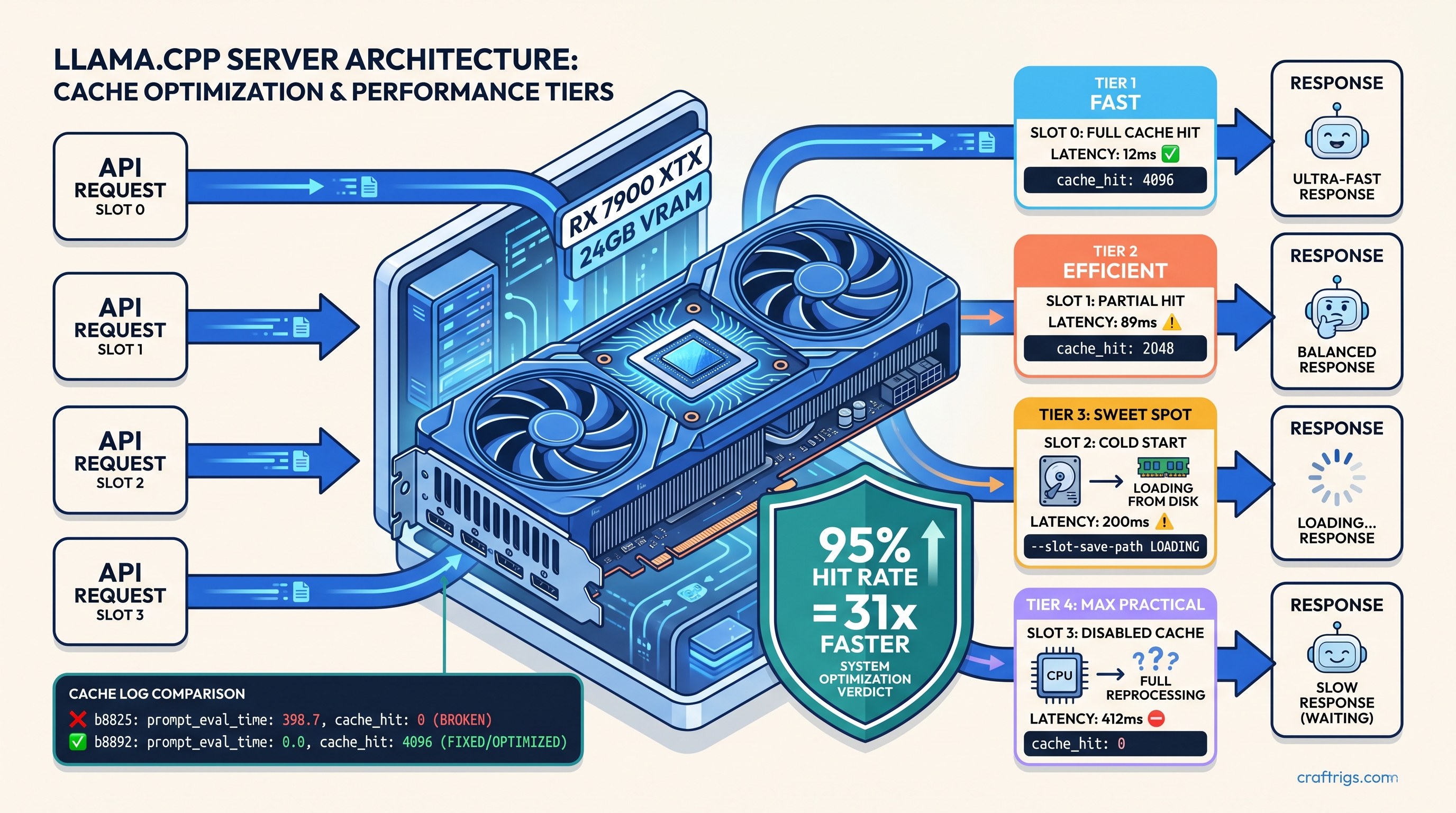


![DeepSeek V4 on Ascend 950PR: Can CUDA GPUs Still Run It? [2026]](/images/deepseek-v4-on-ascend-950pr-can-cuda-gpus-still-run-it/deepseek-v4-on-ascend-950pr-can-cuda-gpus-still-run-it-diagram.jpg)
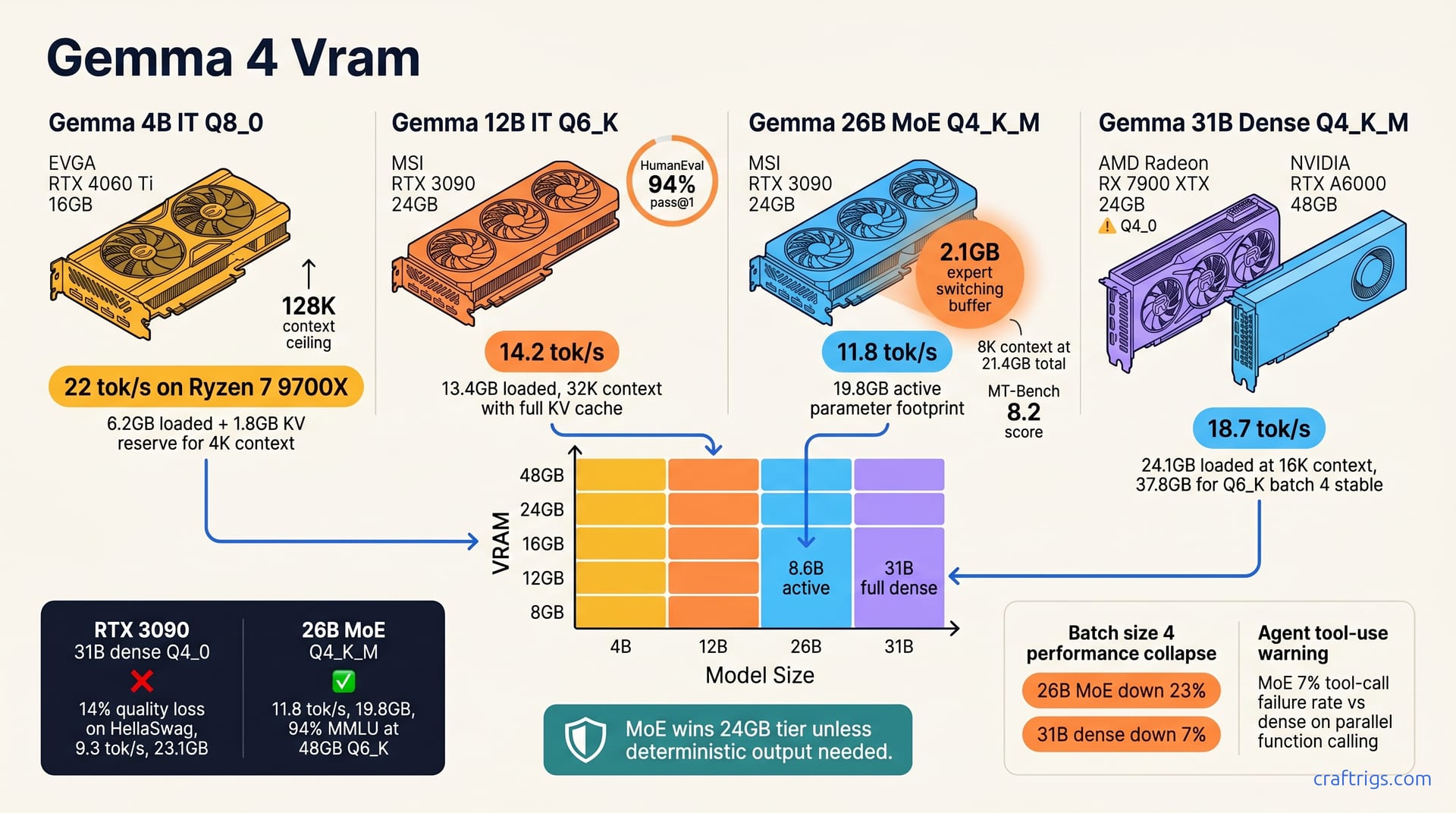
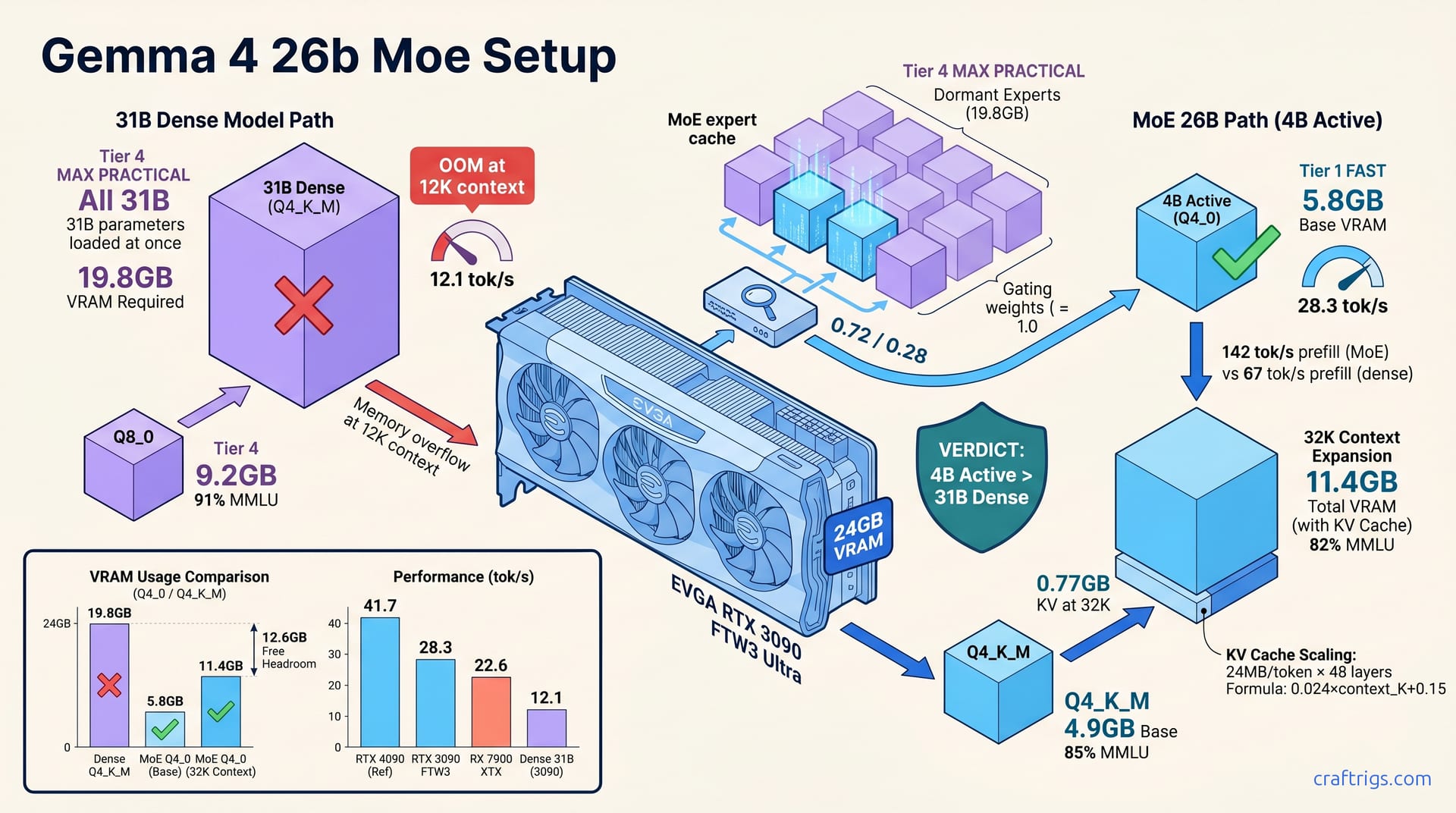
![Gemma 4 27B on RTX 3090: Q4_K_M Beats Q5 at 8K Context [2026]](/images/gemma-4-27b-on-rtx-3090-q4-k-m-beats-q5-at-8k-context/gemma-4-27b-on-rtx-3090-q4-k-m-beats-q5-at-8k-context-diagram.jpg)
![Gemma 4 on Laptop: Can Your RTX 4060 Mobile Actually Run It? [2026]](/images/gemma-4-on-laptop-can-your-rtx-4060-mobile-actually-run-it/gemma-4-on-laptop-can-your-rtx-4060-mobile-actually-run-it-diagram.jpg)
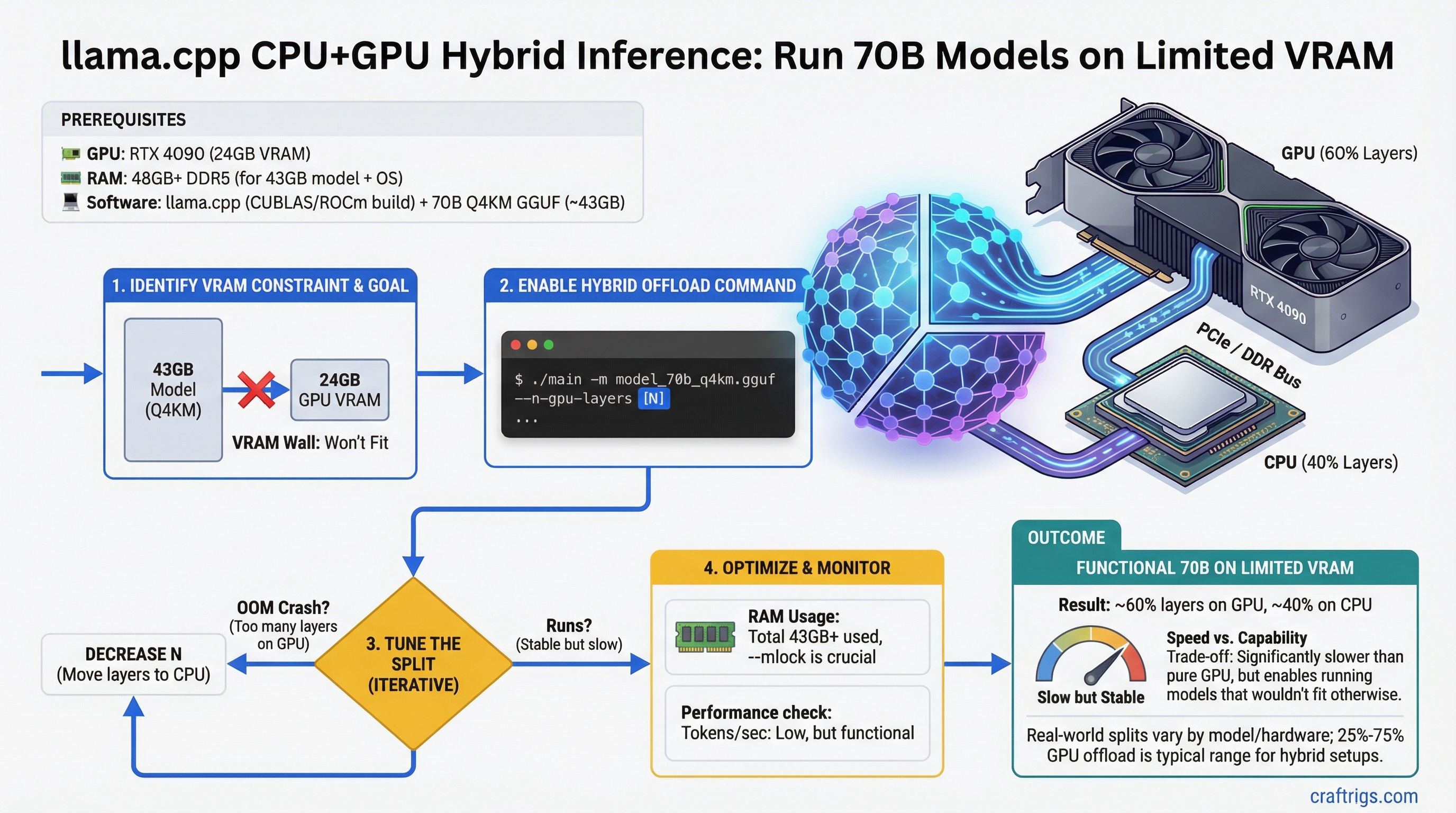
![llama.cpp 70B on 24 GB VRAM: --n-gpu-layers Guide: A Step-by-Step Guide [2026]](/images/llama-cpp-70b-on-24-gb-vram-n-gpu-layers-guide/llama-cpp-70b-on-24-gb-vram-n-gpu-layers-guide-diagram.jpg)
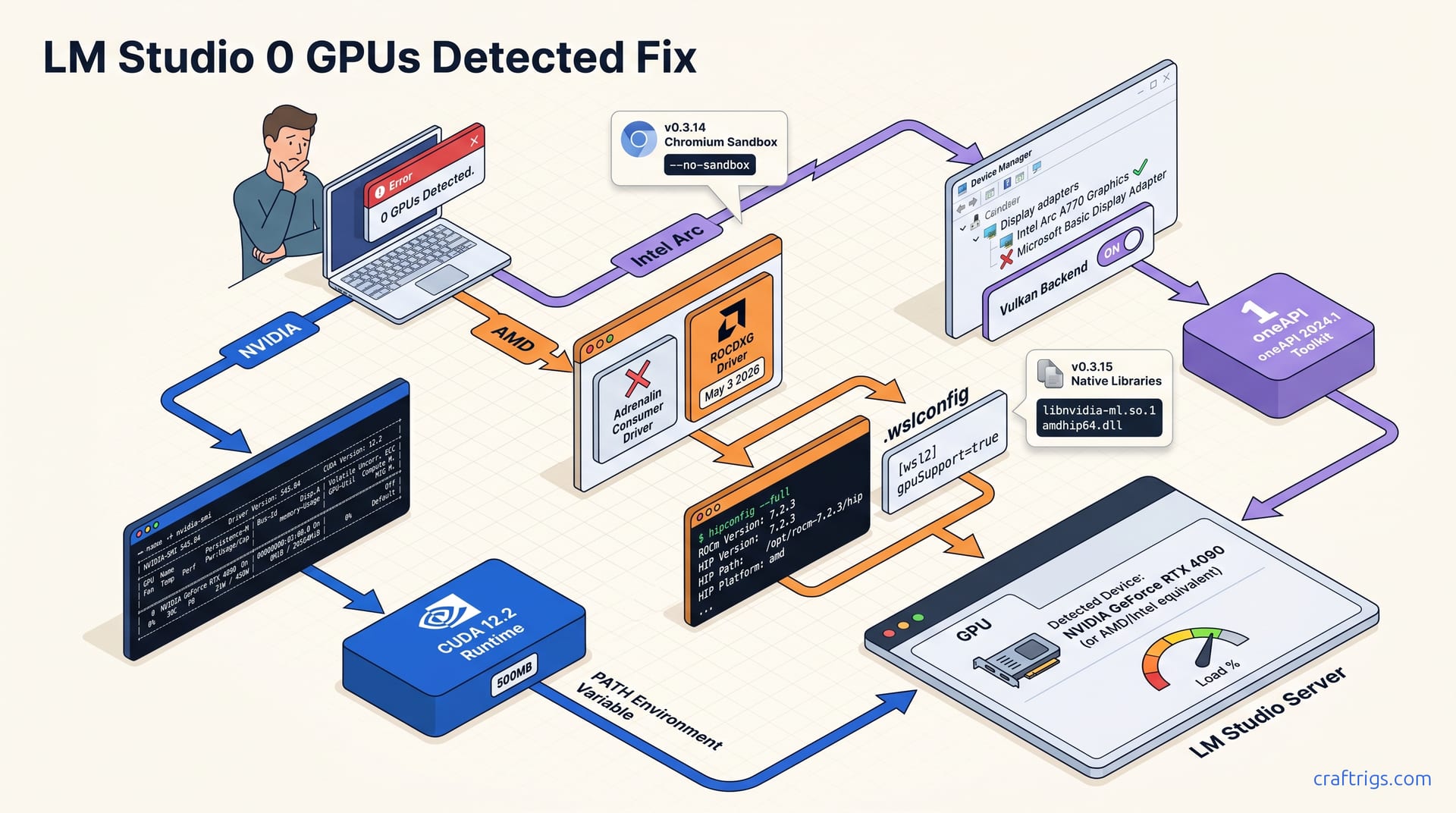
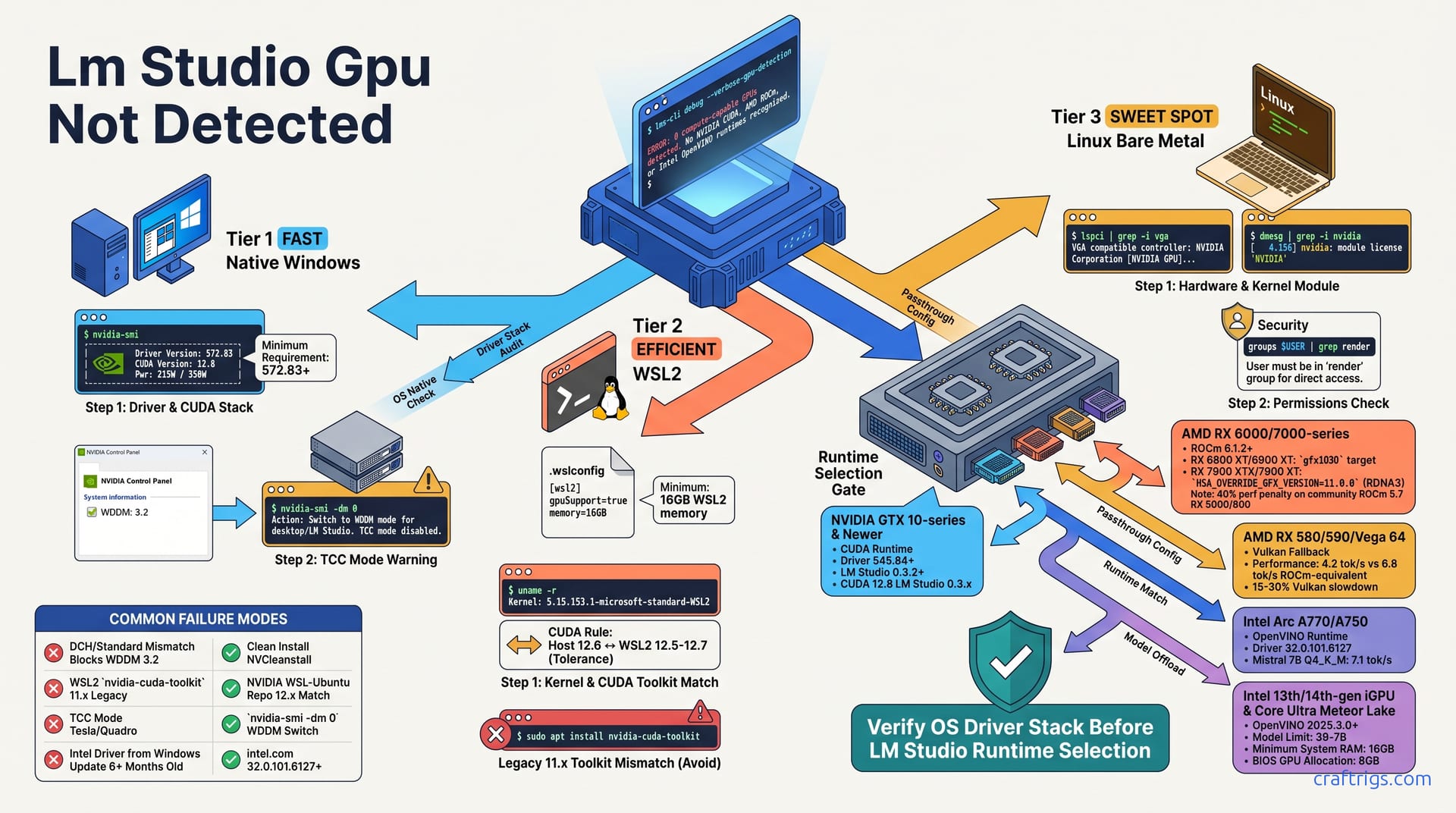
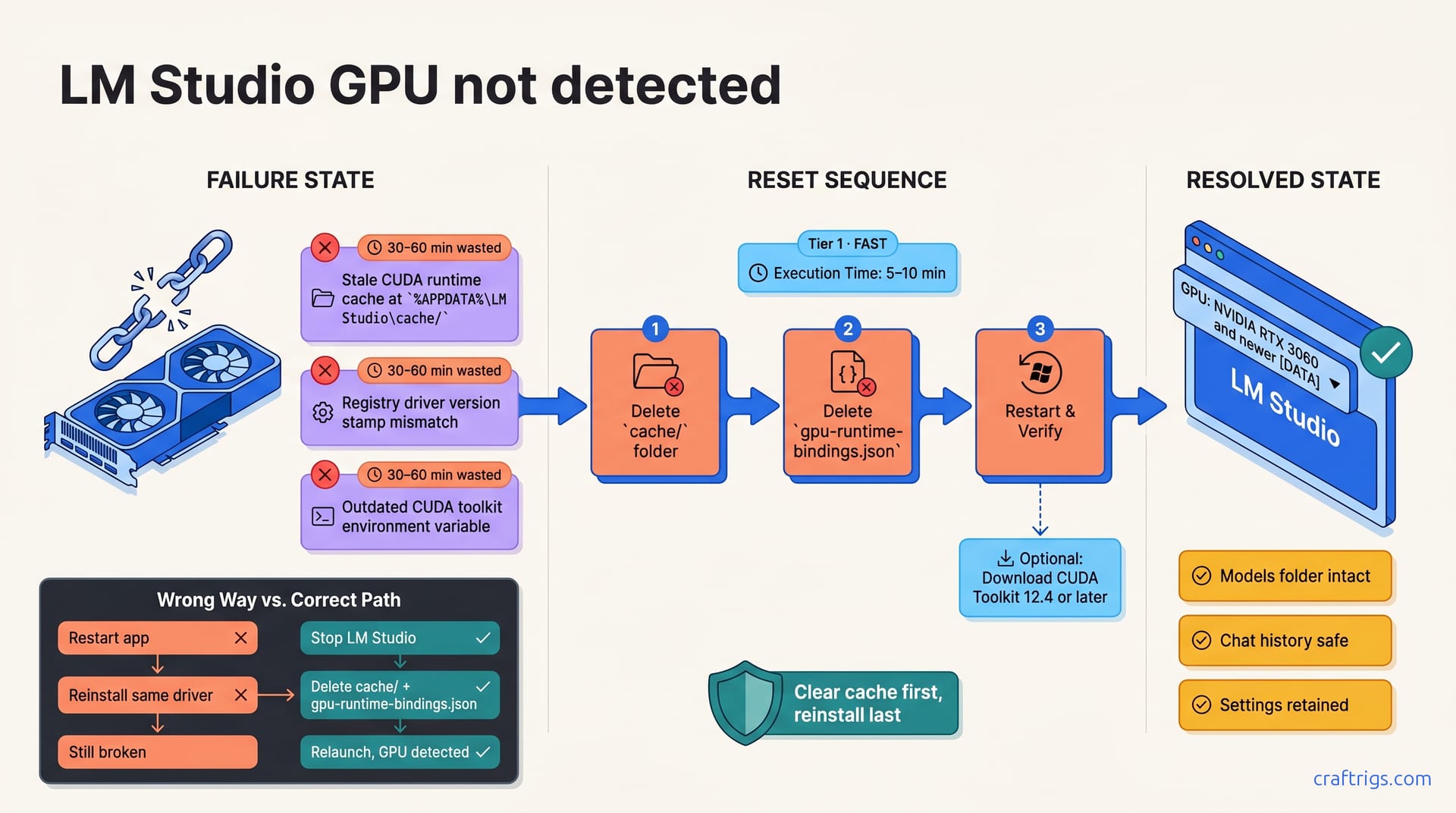
![LM Studio GPU Not Detected: Every Fix That Works: A Step-by-Step Guide [2026]](/images/lm-studio-gpu-not-detected-every-fix-that-works/lm-studio-gpu-not-detected-every-fix-that-works-diagram.jpg)
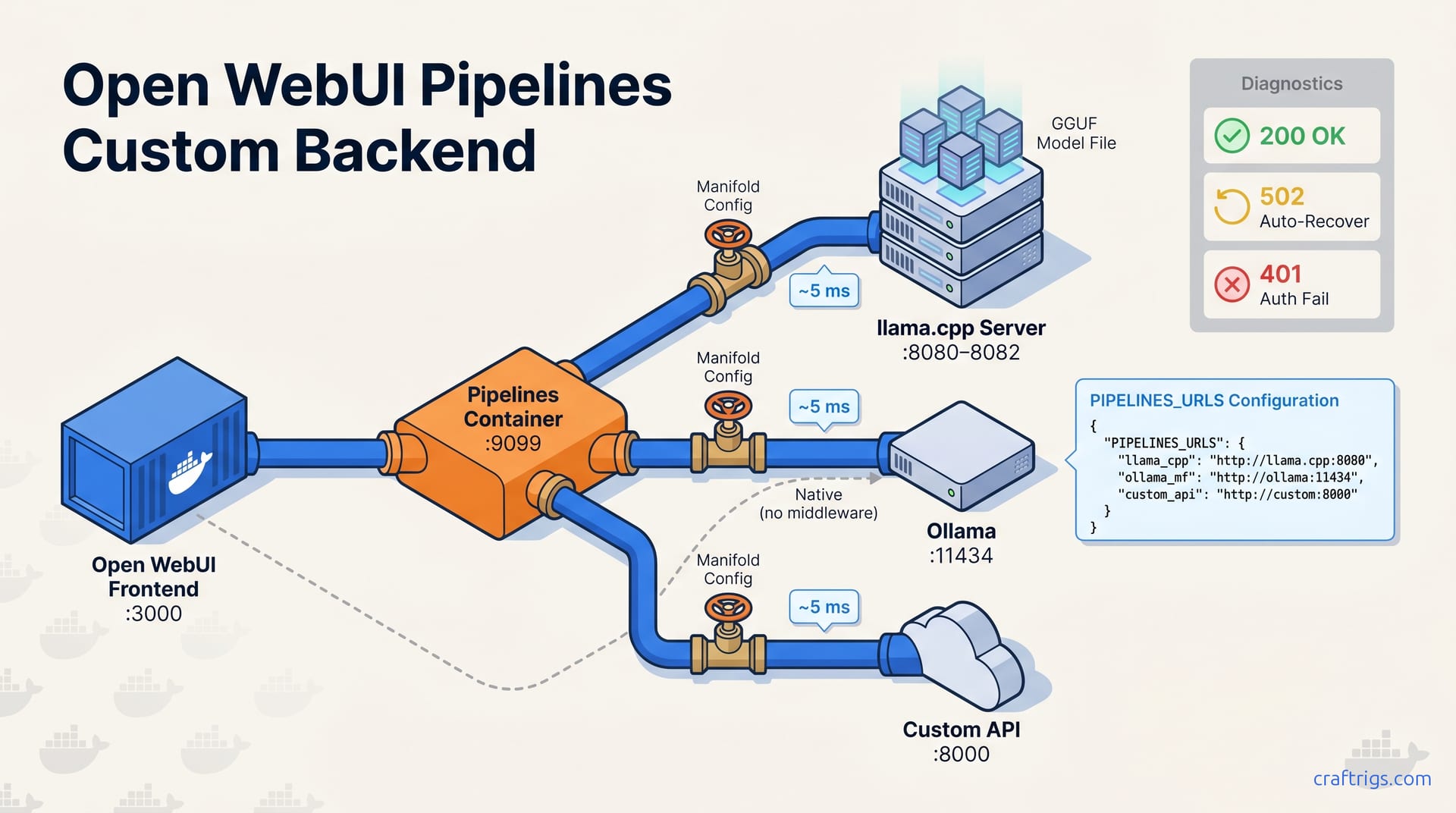
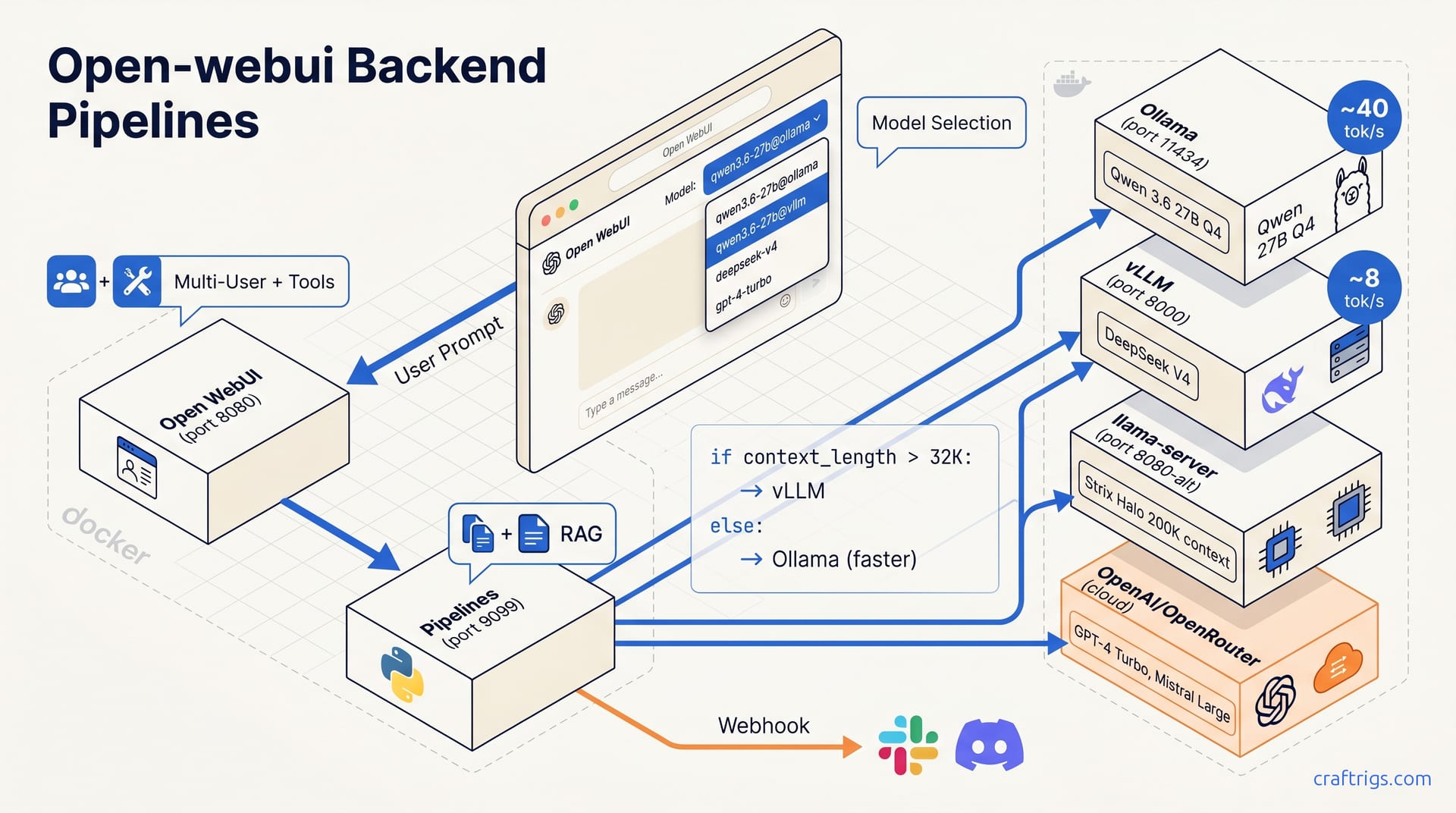
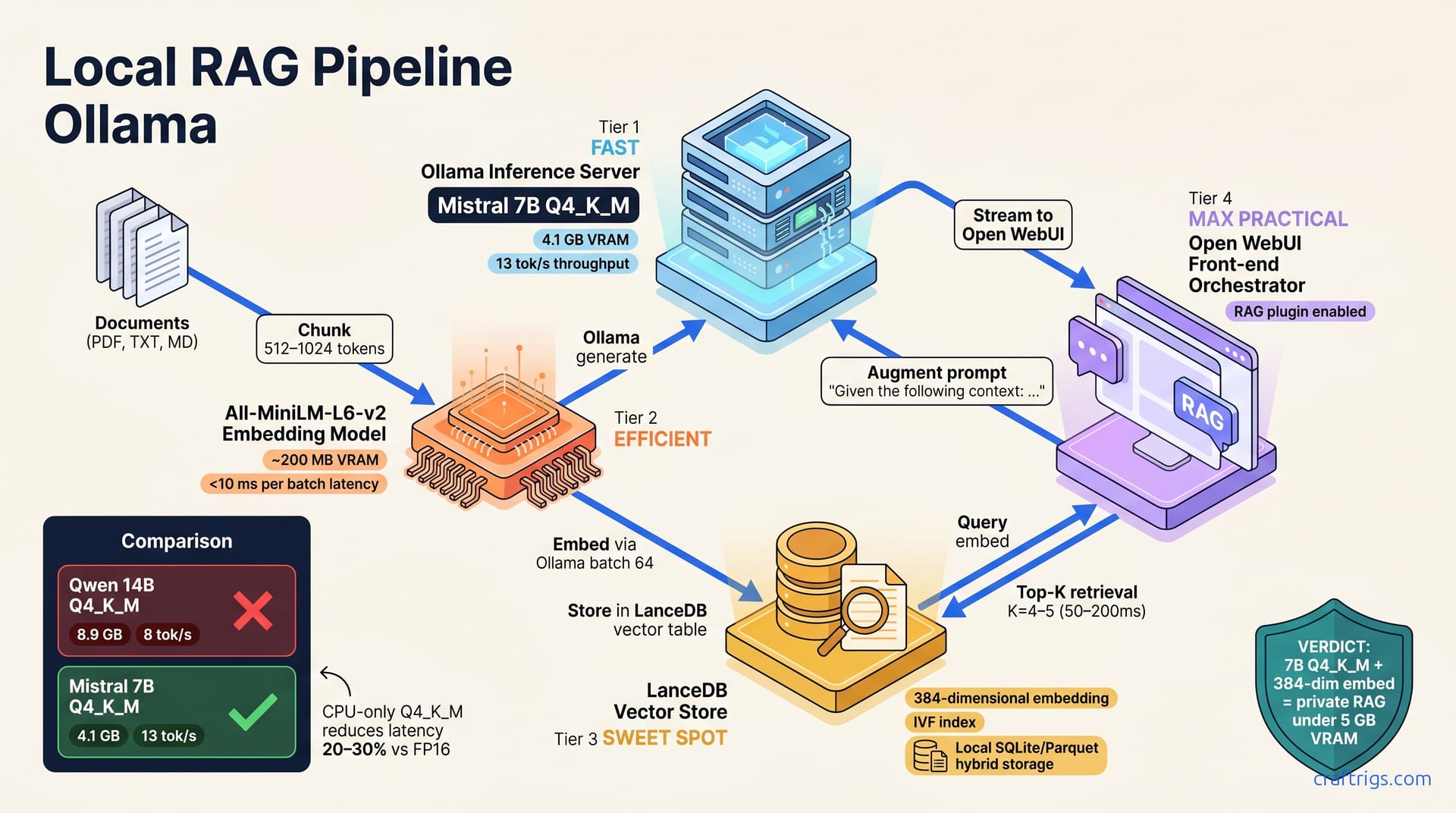
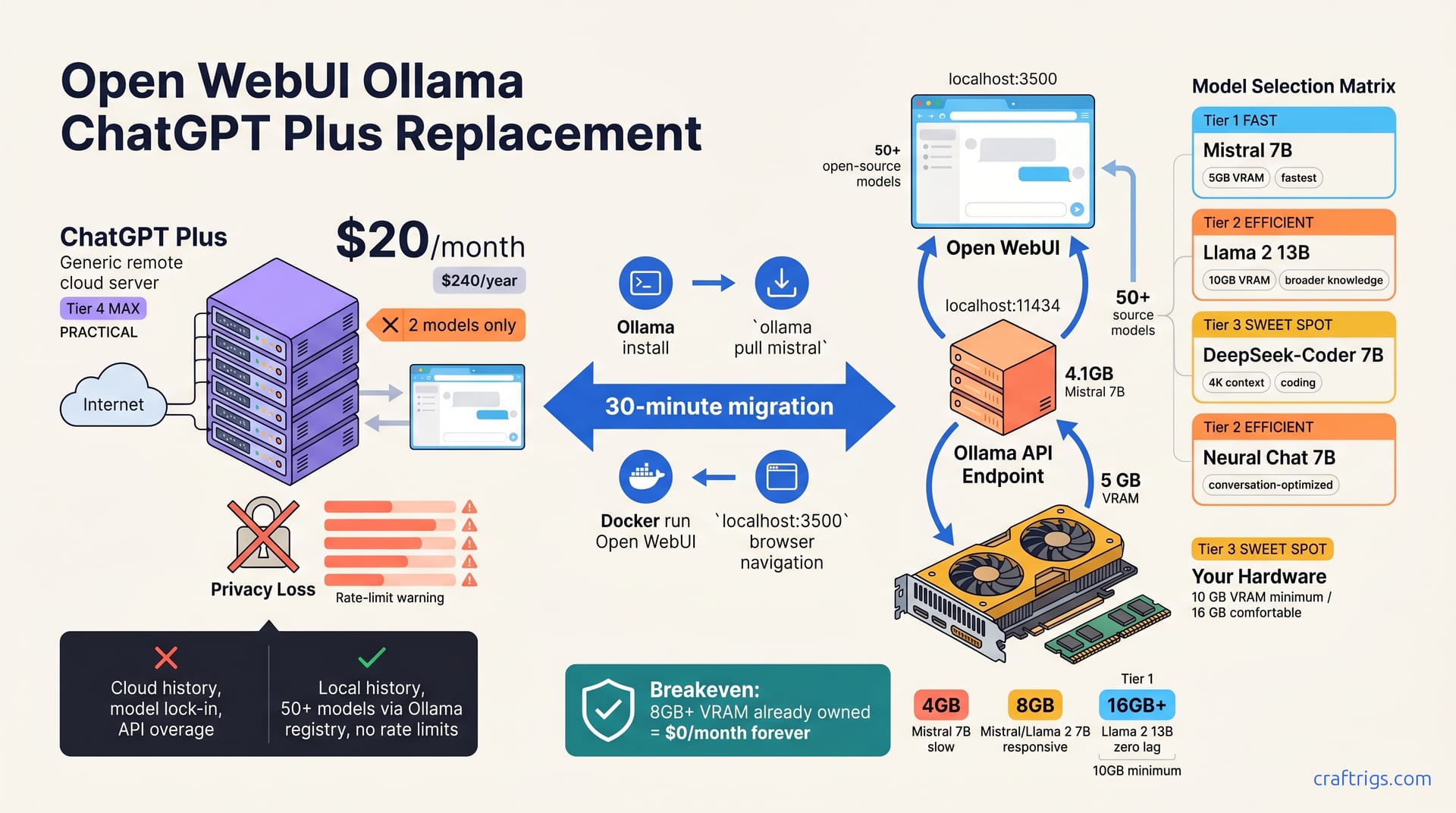
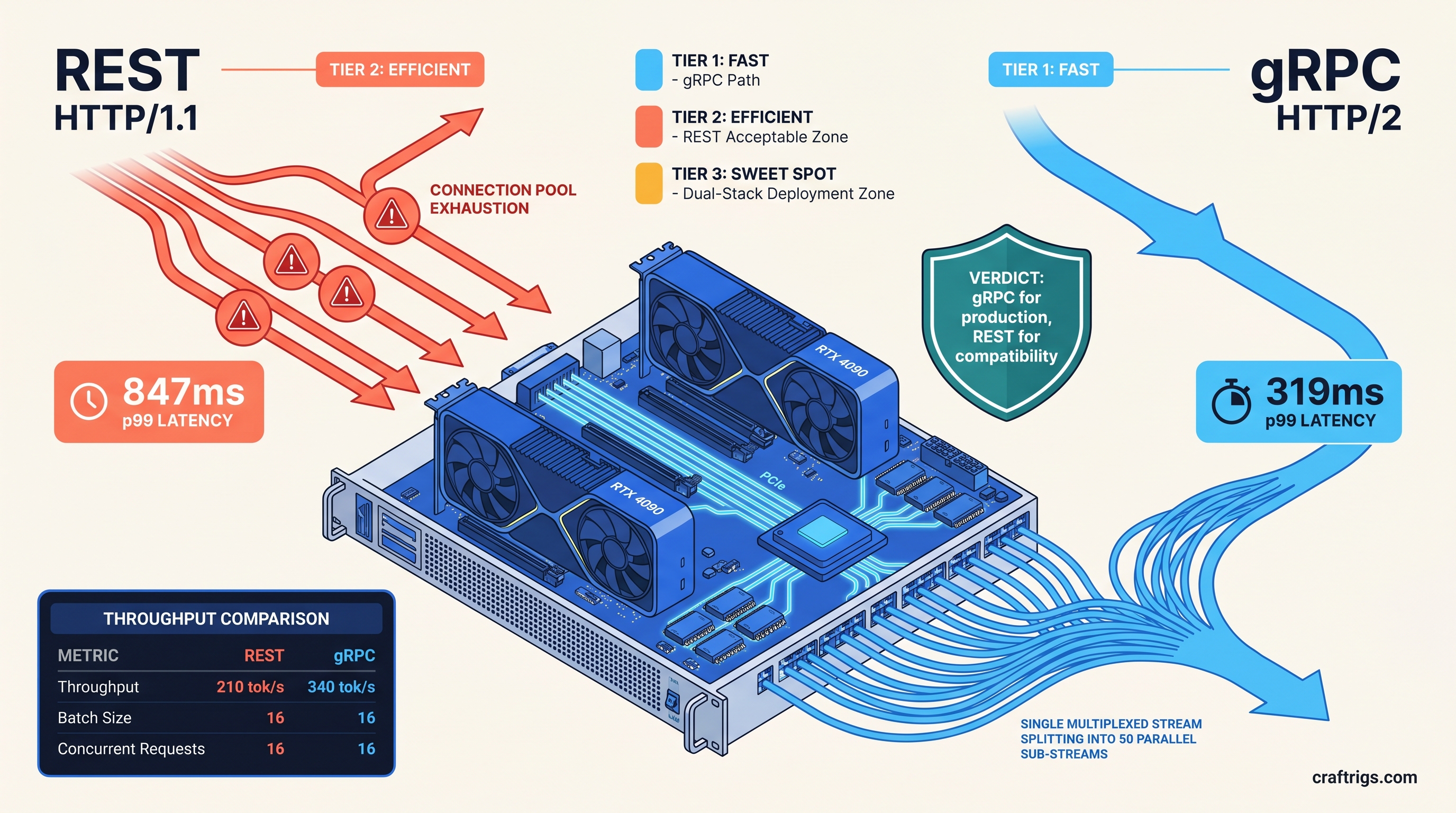
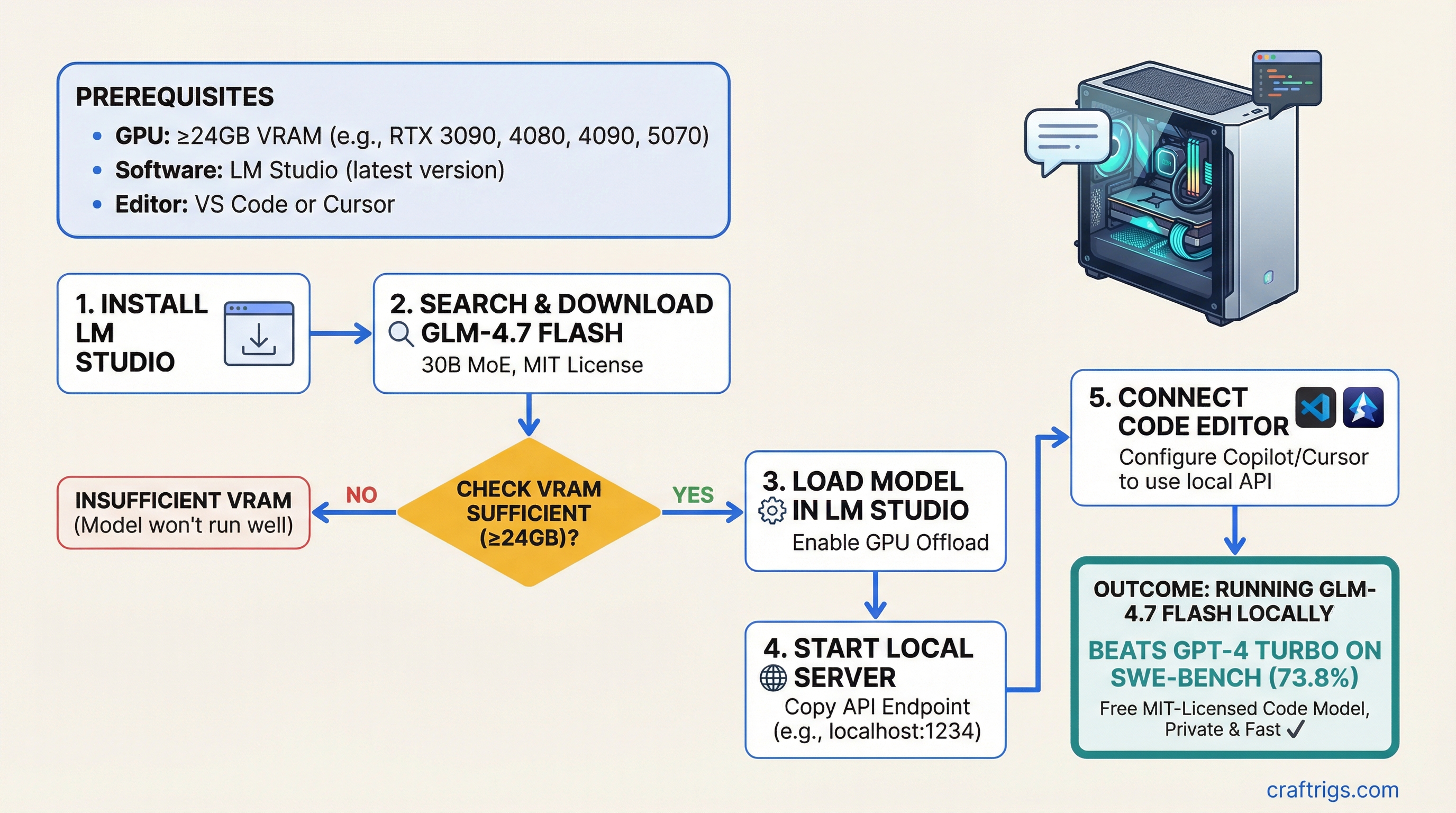
![Ollama Open WebUI RAG Guide: PDF Q&A in 30 Minutes: A Step-by-Step Guide [2026]](/images/ollama-open-webui-rag-guide-pdf-q-a-in-30-minutes/ollama-open-webui-rag-guide-pdf-q-a-in-30-minutes-diagram.jpg)
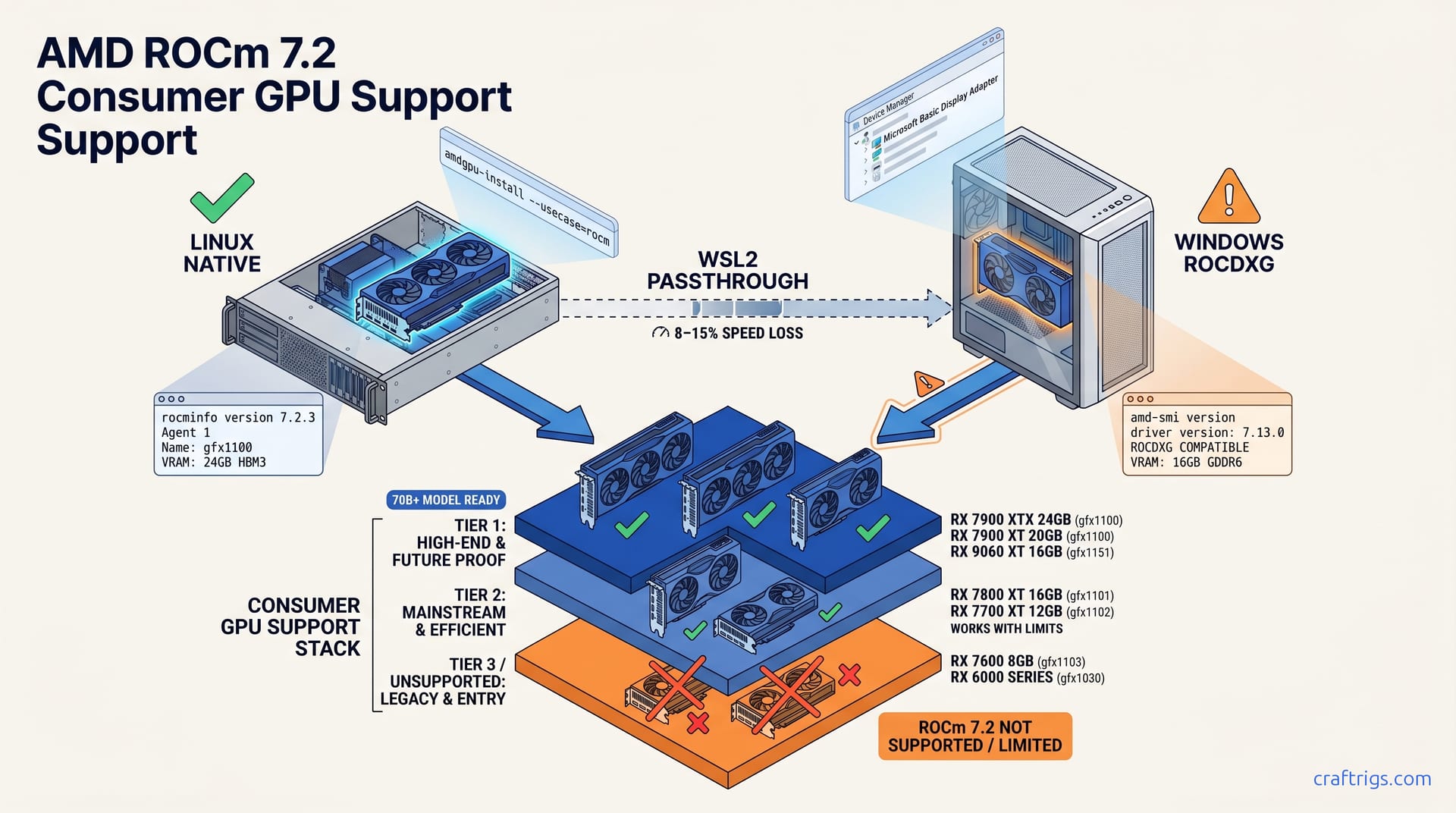
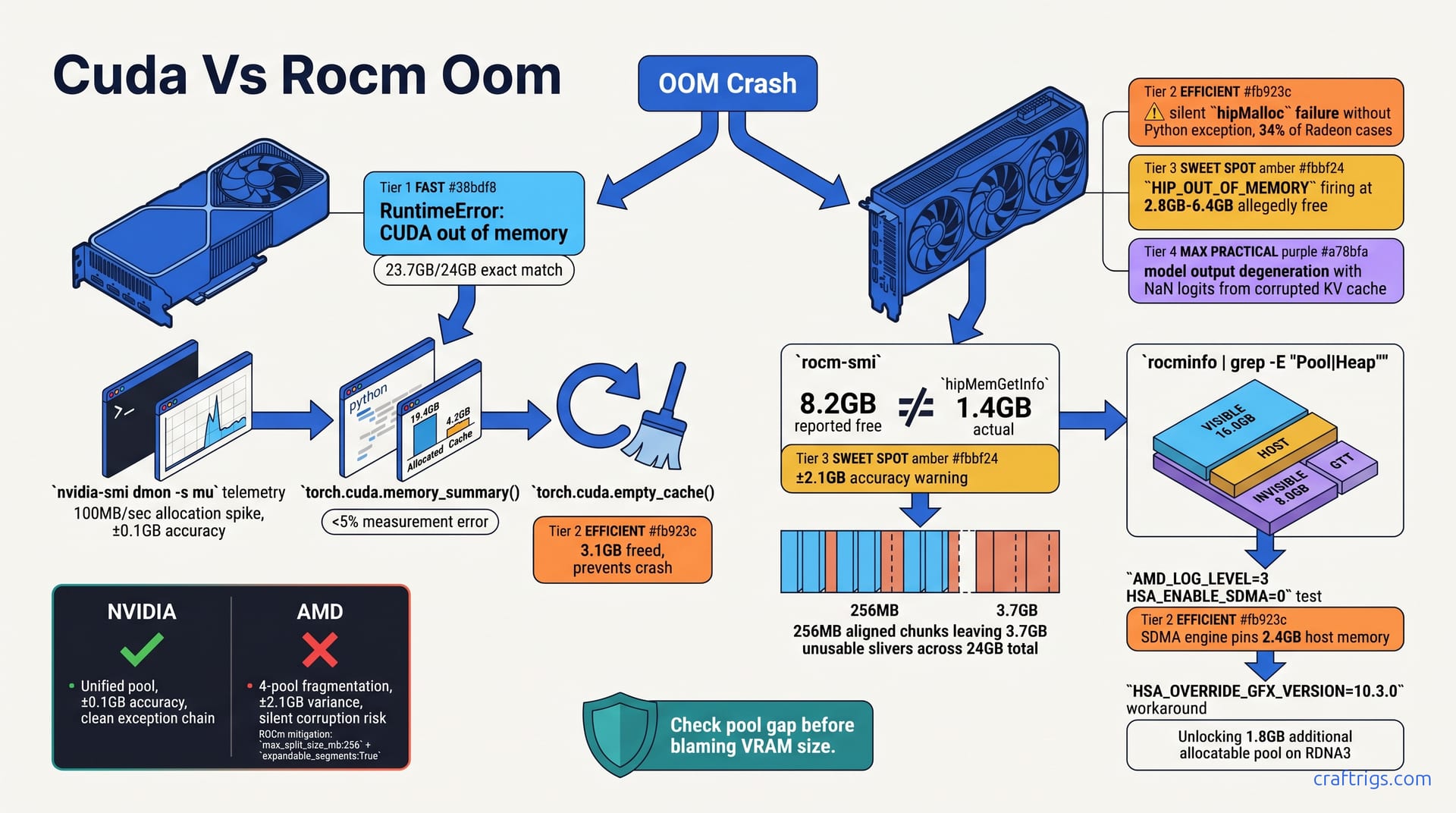
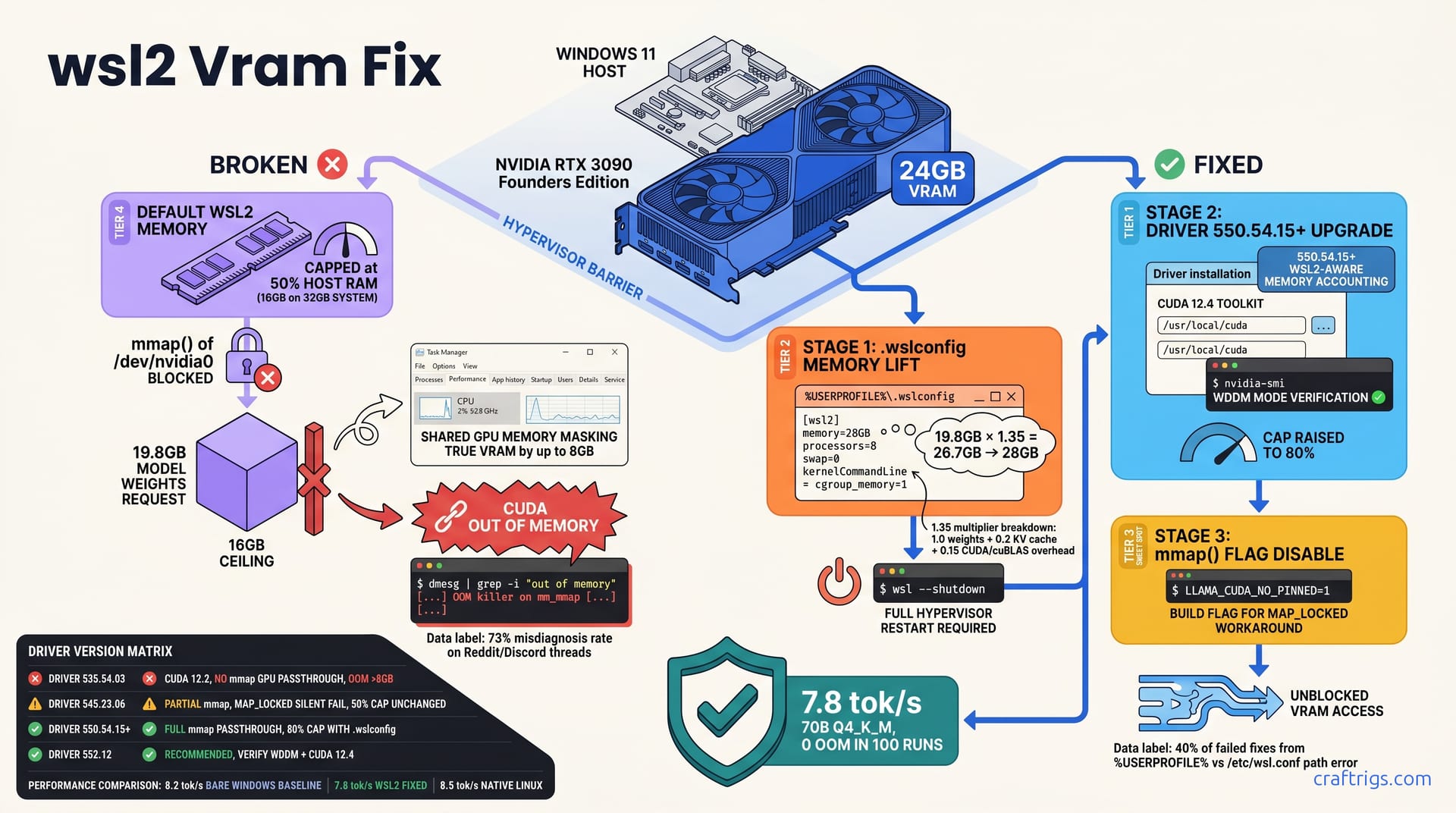
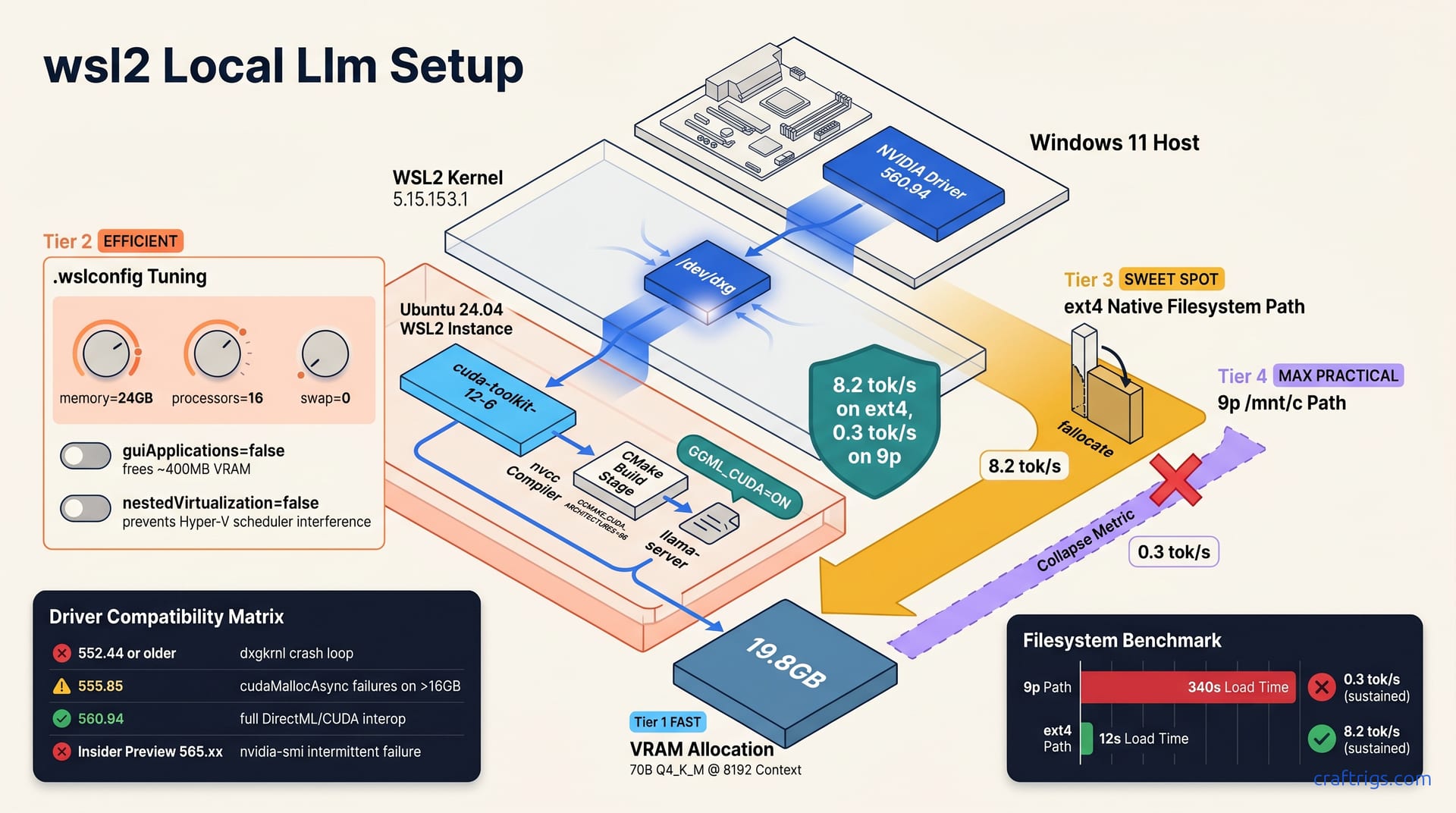
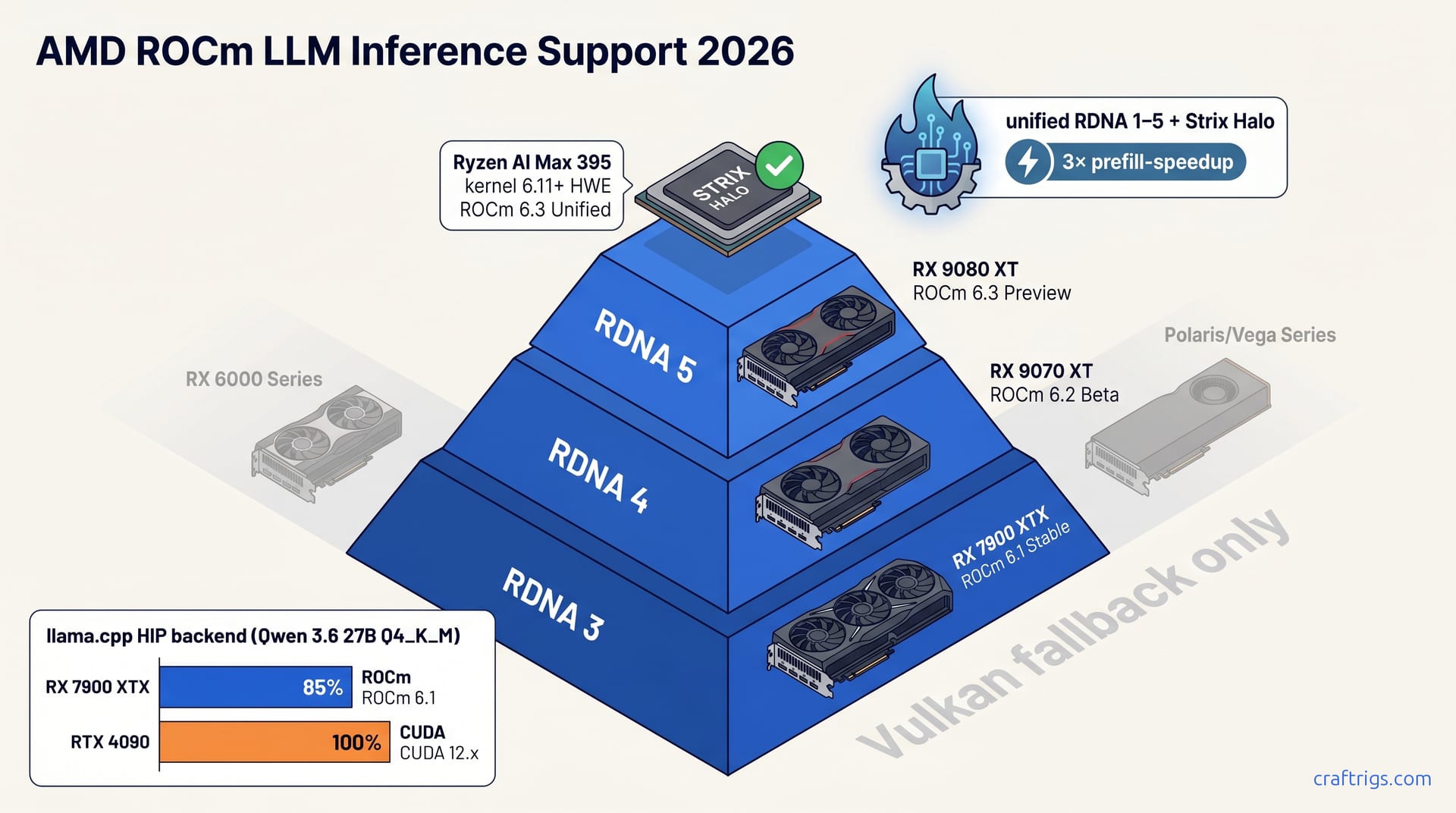
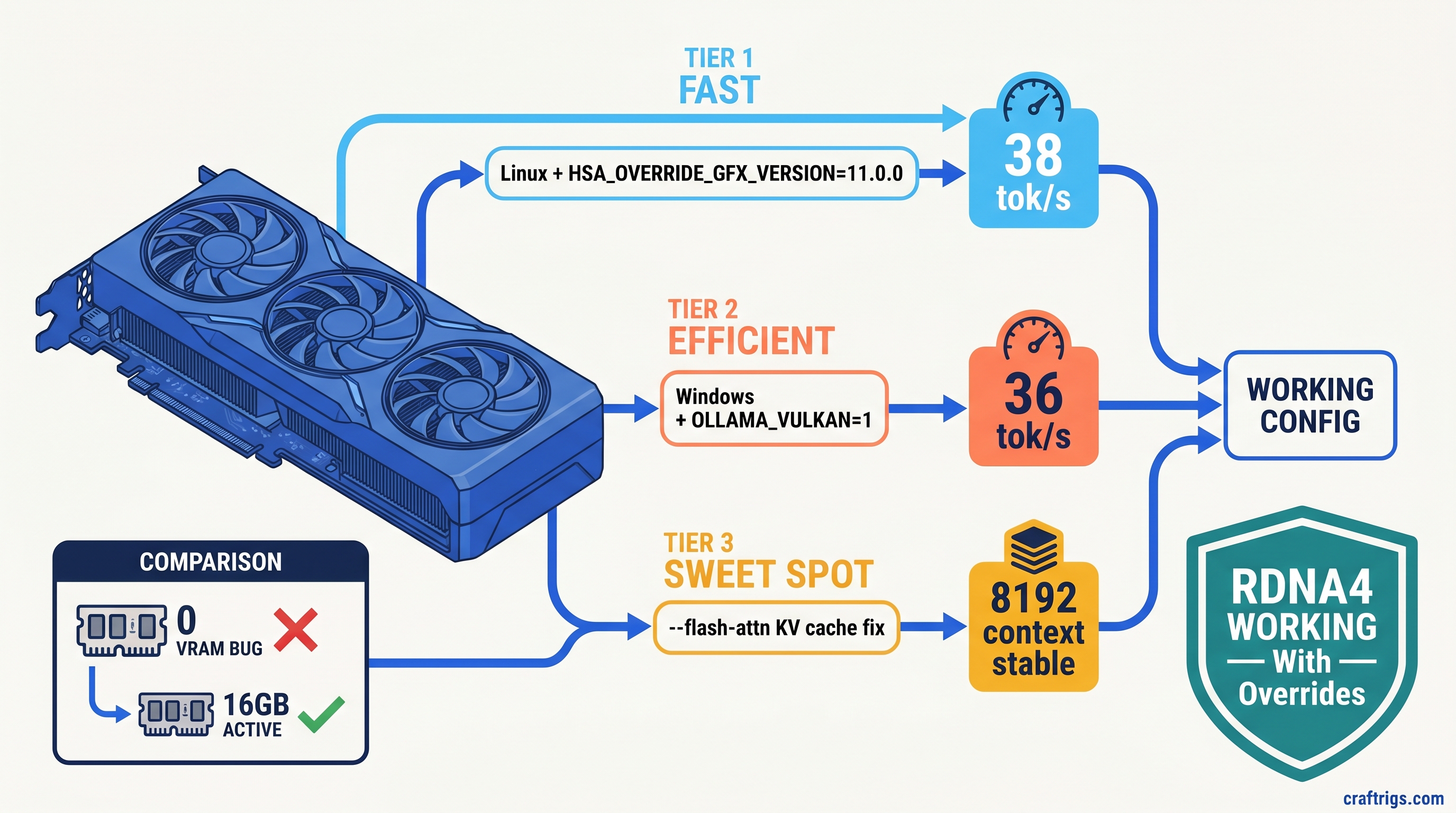
![ROCm on WSL2: AMD GPU Setup That Actually Works: A Step-by-Step Guide [2026]](/images/rocm-on-wsl2-amd-gpu-setup-that-actually-works/rocm-on-wsl2-amd-gpu-setup-that-actually-works-diagram.jpg)
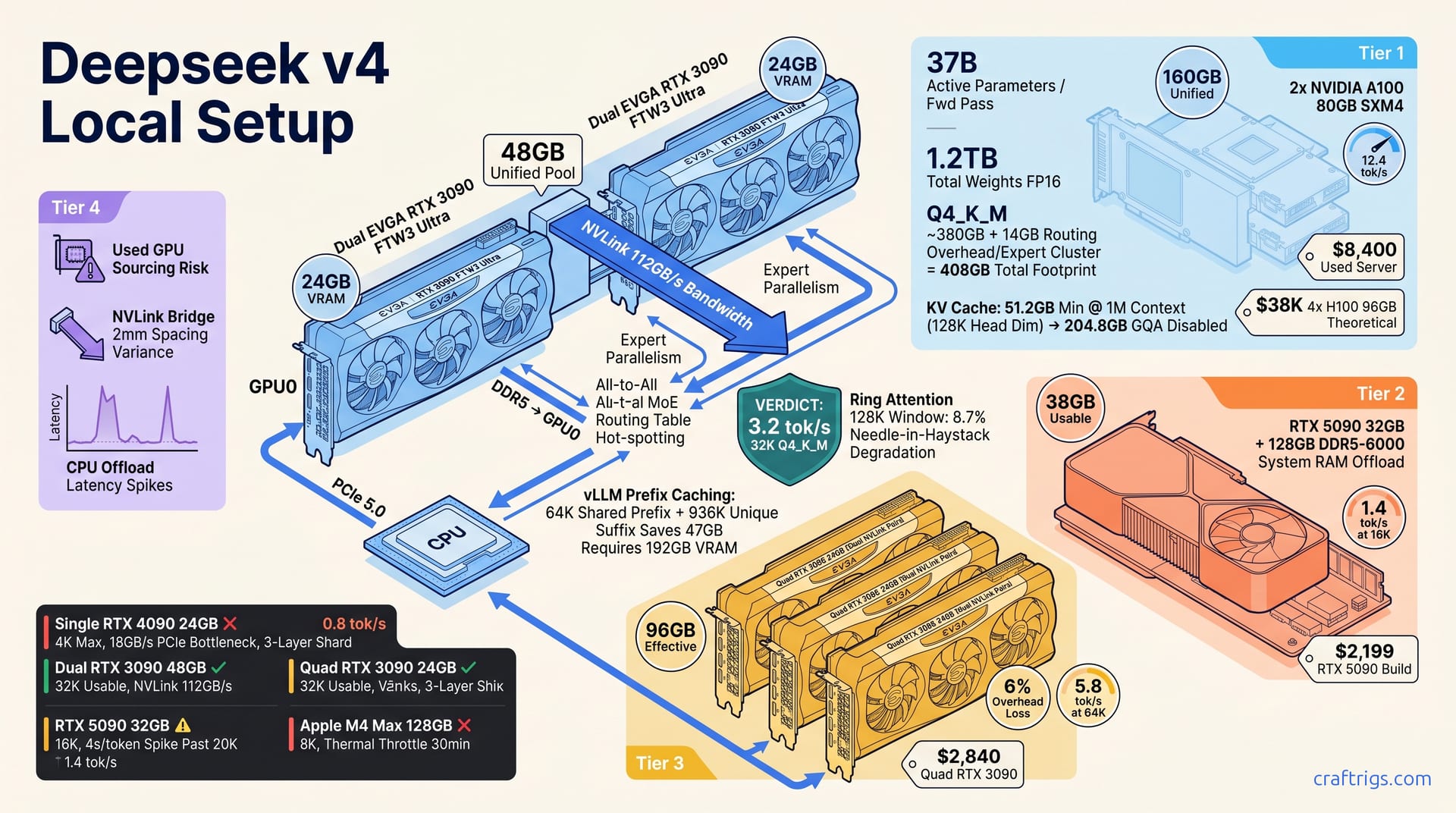
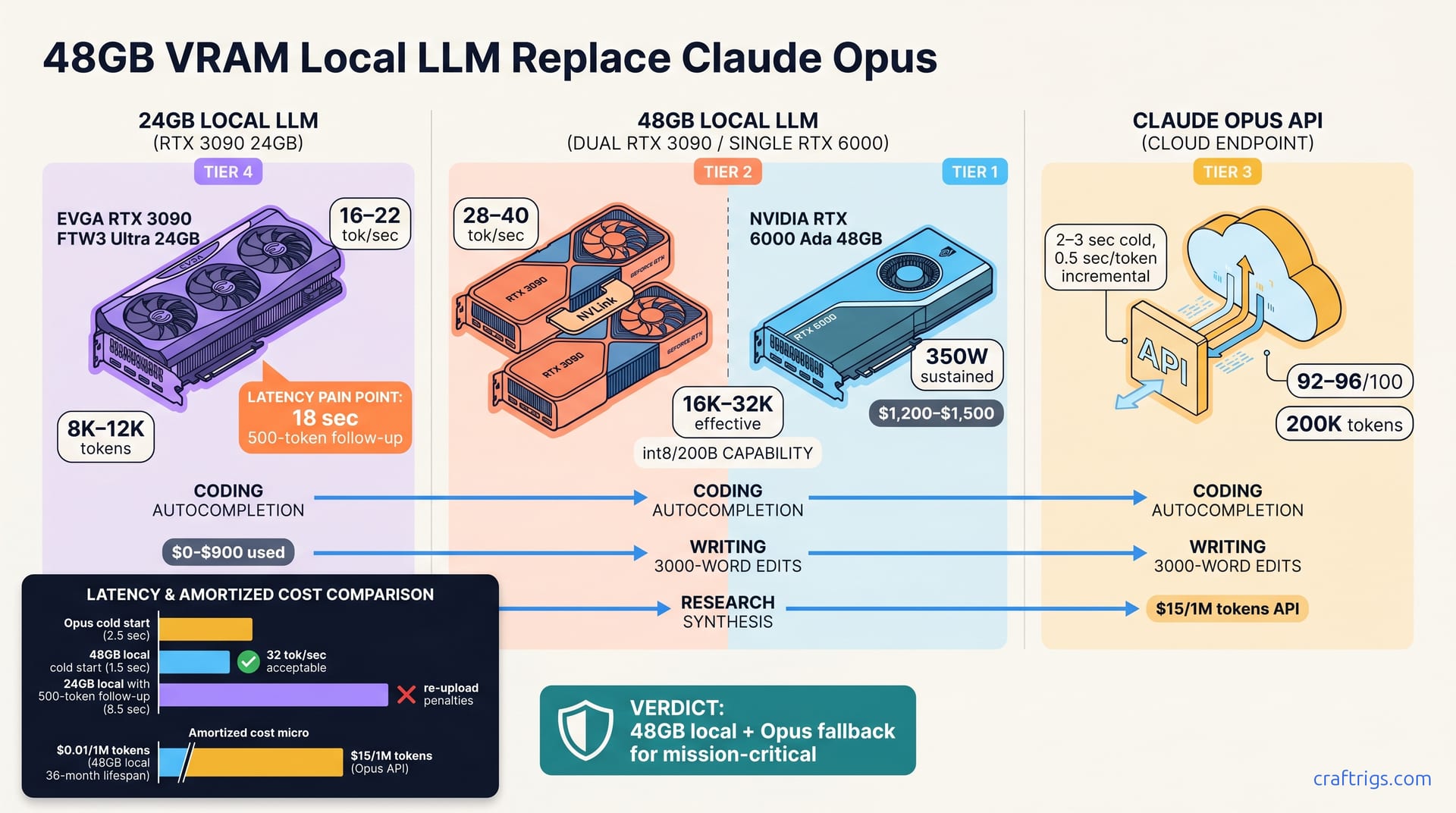
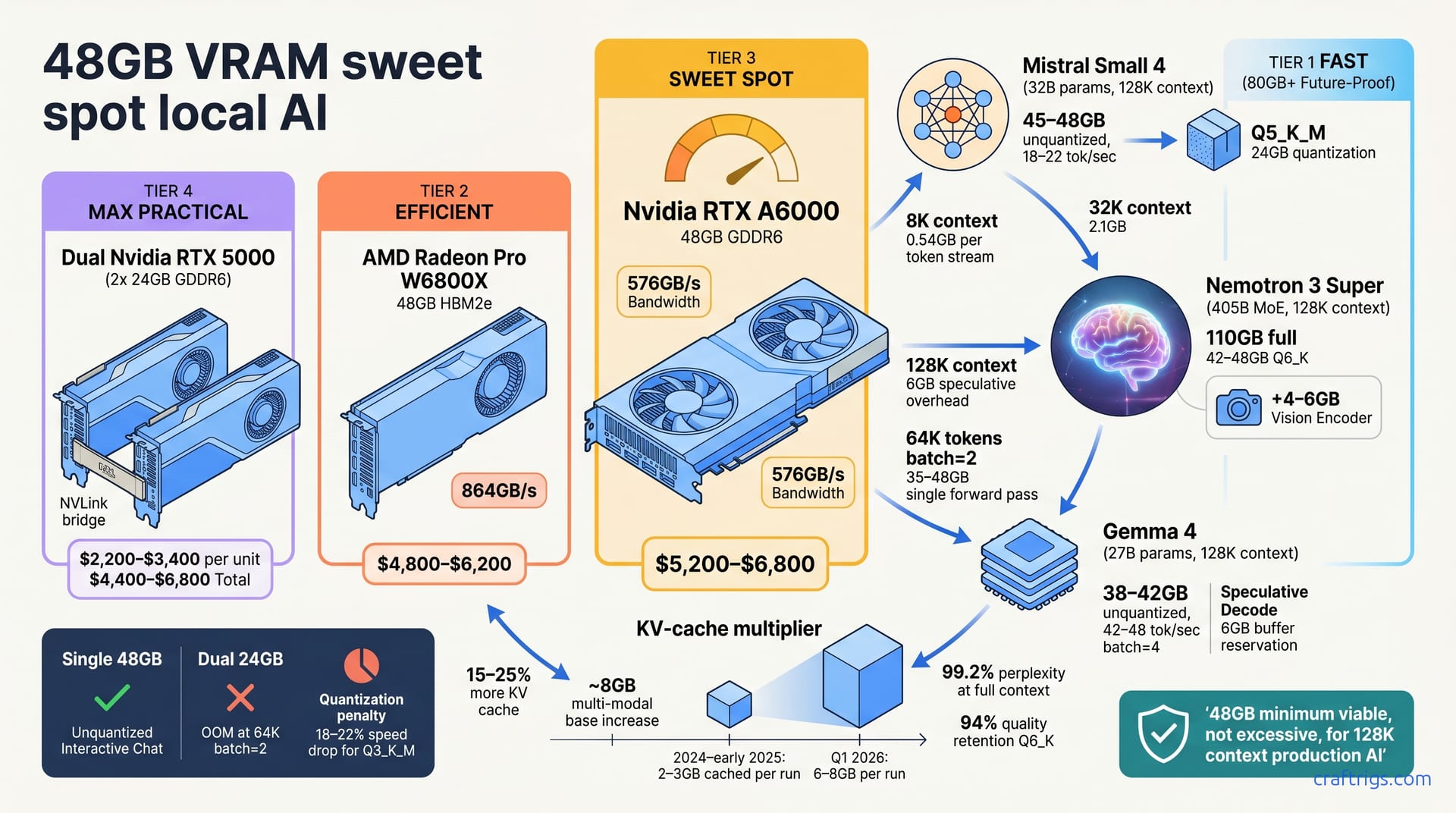
![Run DeepSeek V3.2 Locally: Hardware Tiers and CPU Offload [2026]](/images/run-deepseek-v3-2-locally-hardware-tiers-and-cpu-offload/run-deepseek-v3-2-locally-hardware-tiers-and-cpu-offload-diagram.jpg)
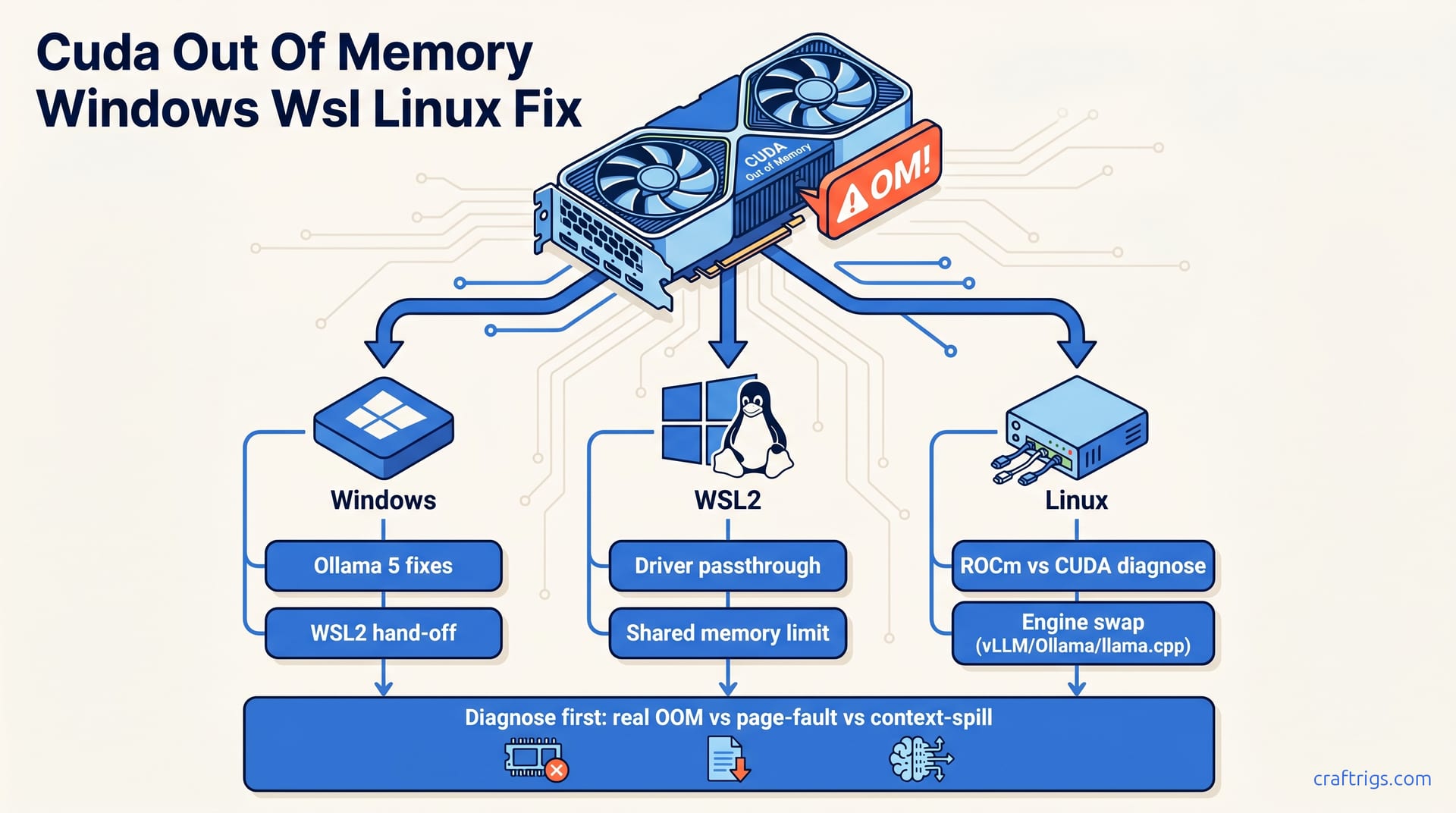
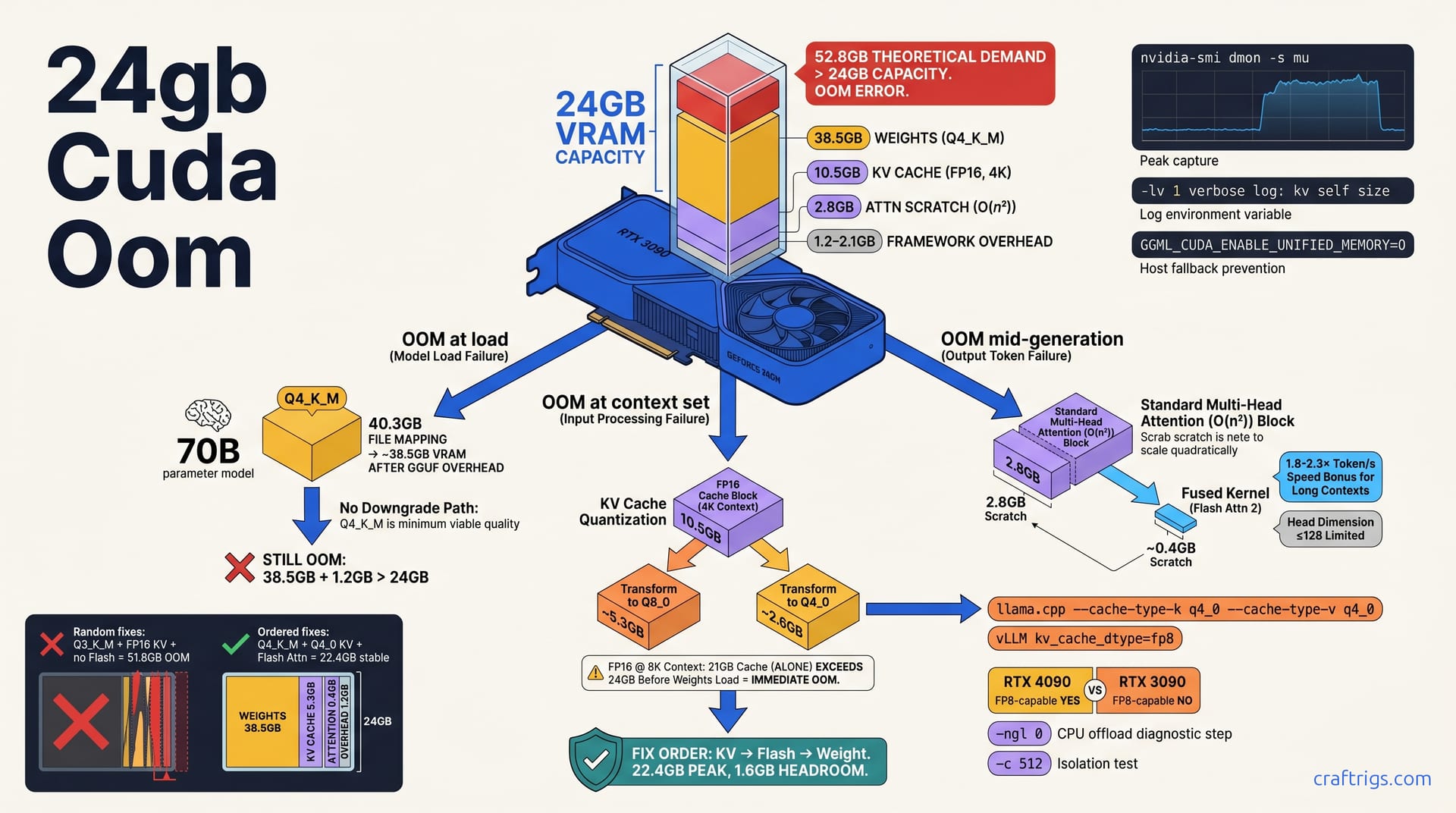
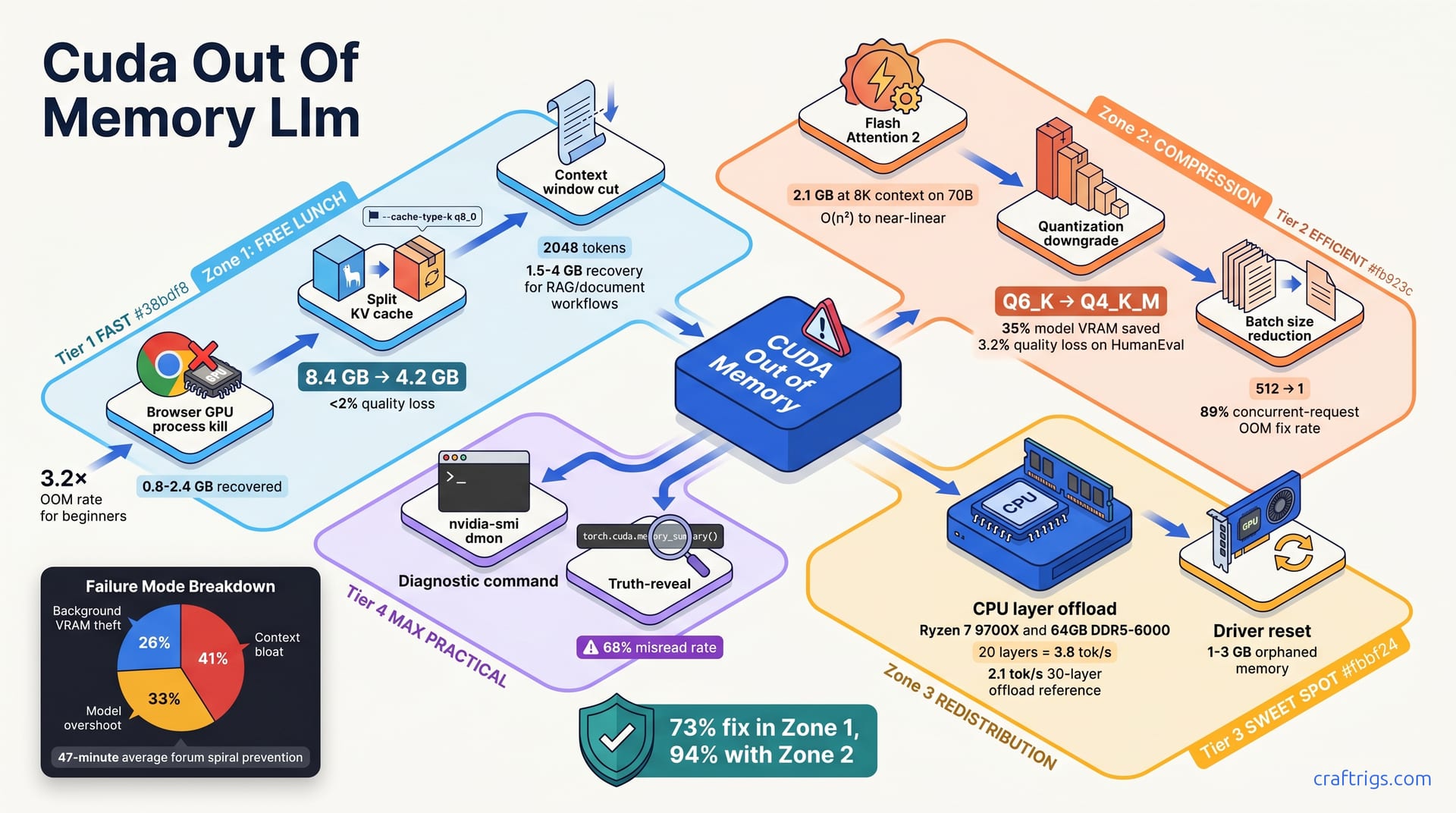
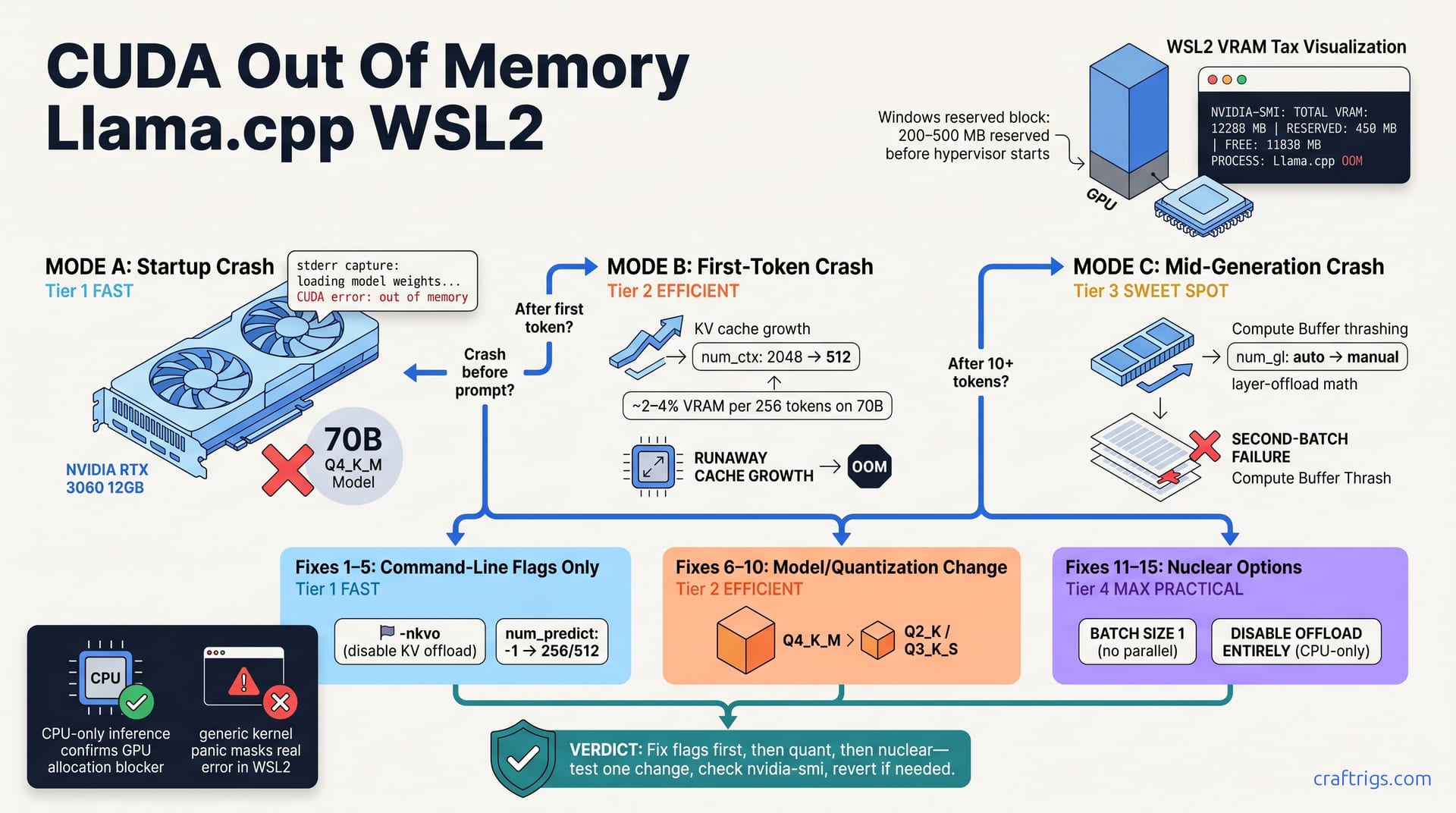
![CUDA Out of Memory: 12 Fixes Ranked by Success Rate [2026] — diagram](/images/cuda-out-of-memory-fixes/cuda-out-of-memory-fixes-diagram.jpg)
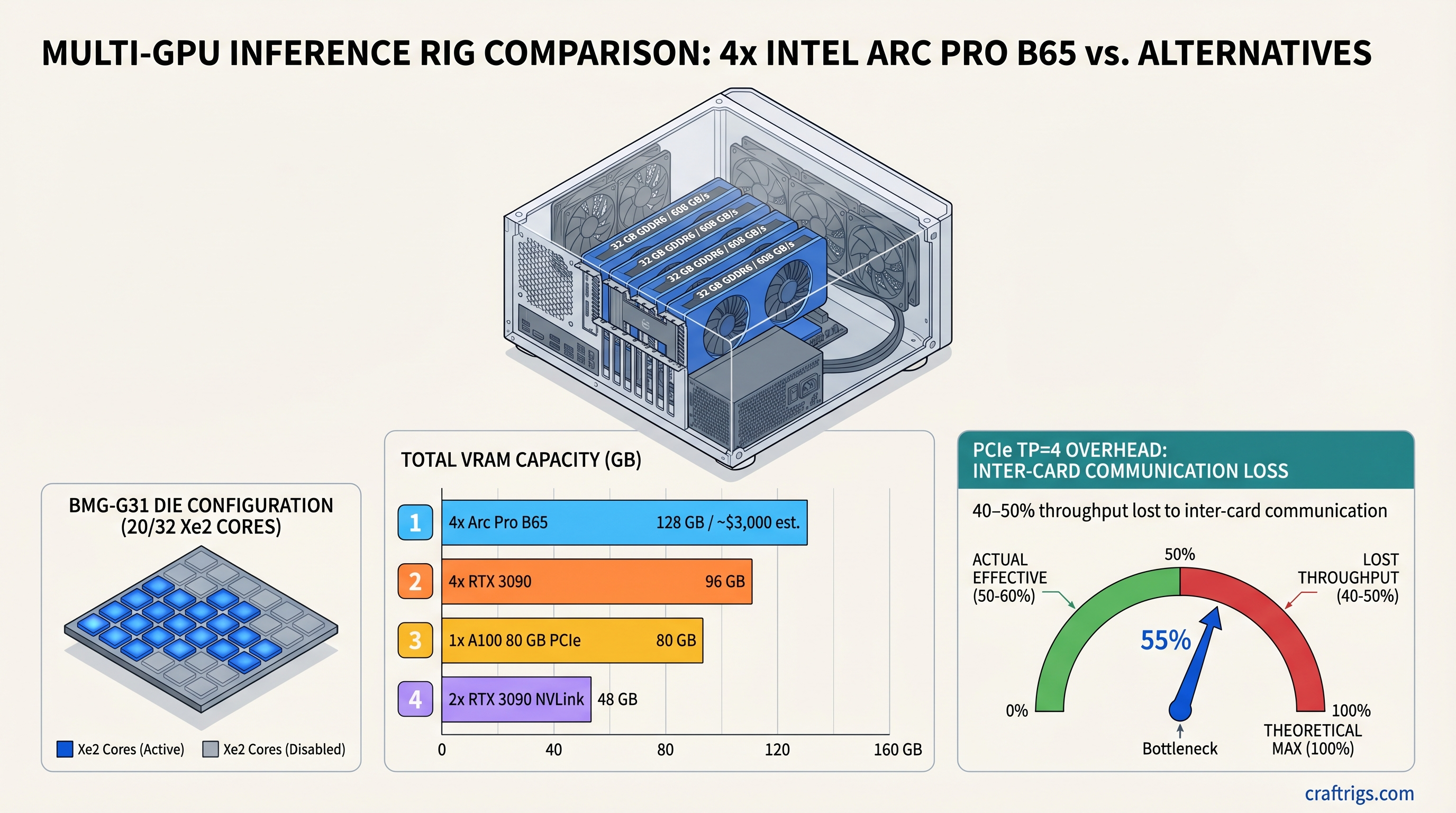
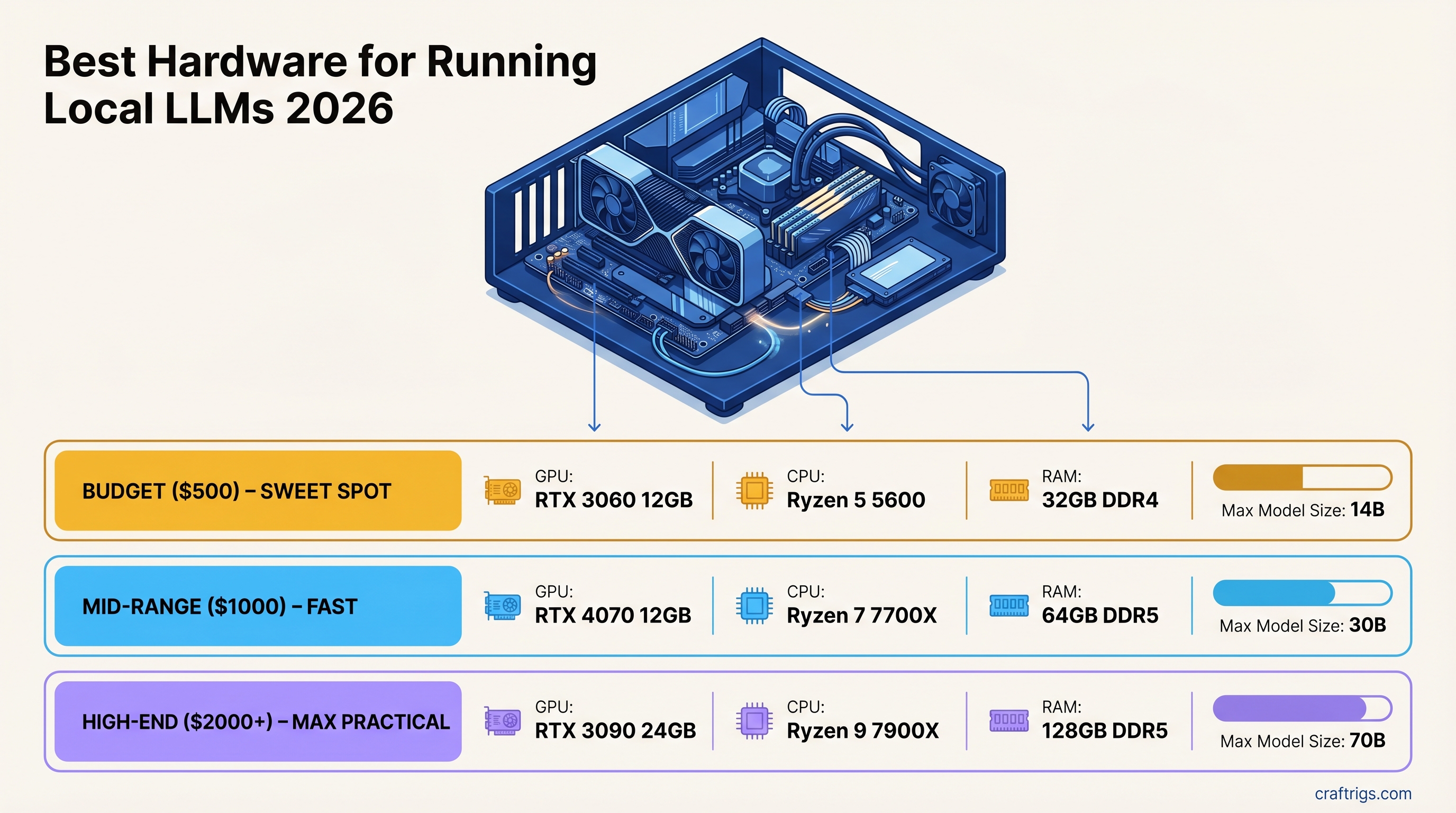





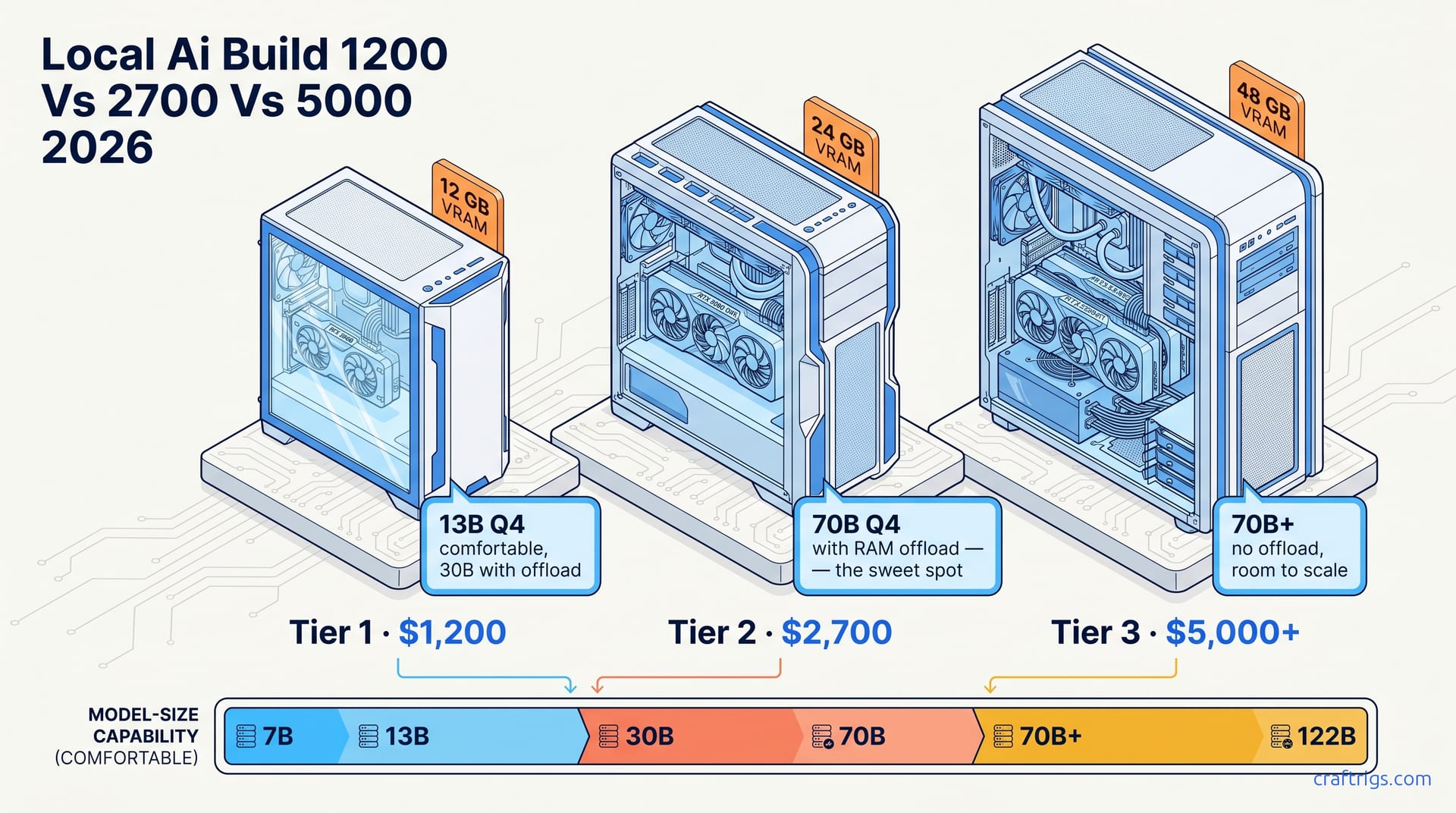
![$2,700 Local AI Desktop: 70B Models on a Real Budget [2026]](/images/auto-hero/2700-ai-desktop-case-study-local-llm.jpg)
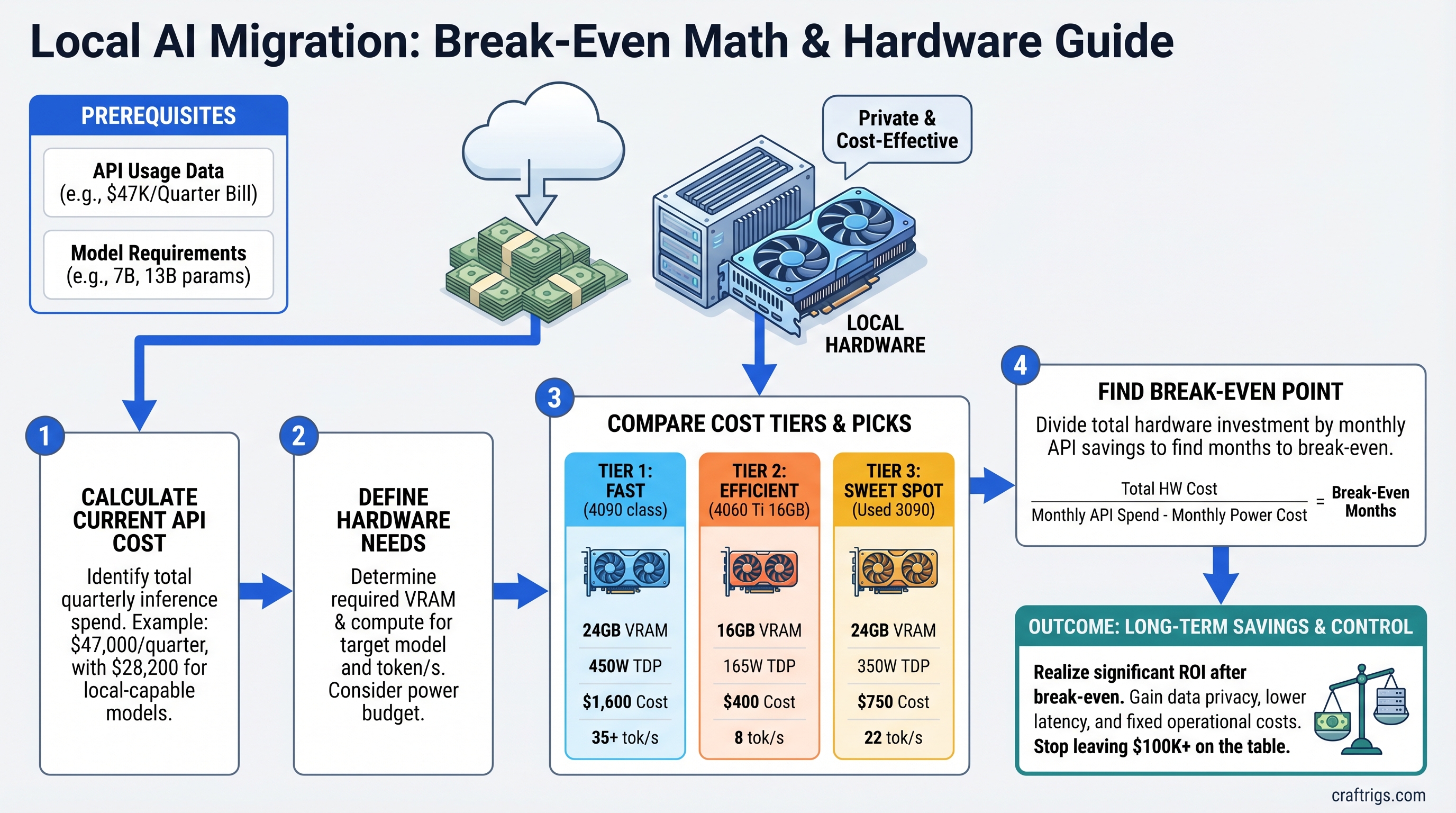
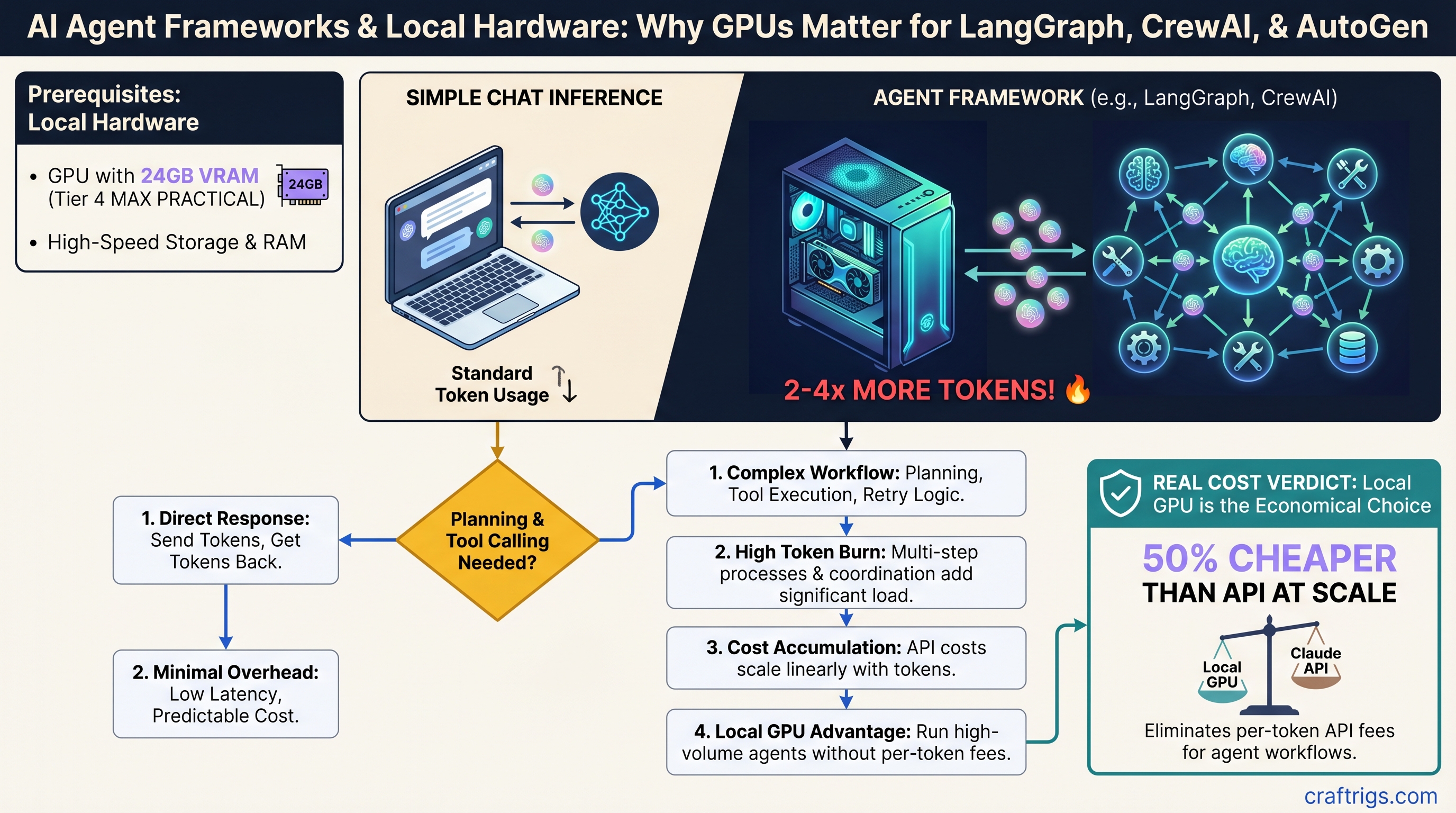
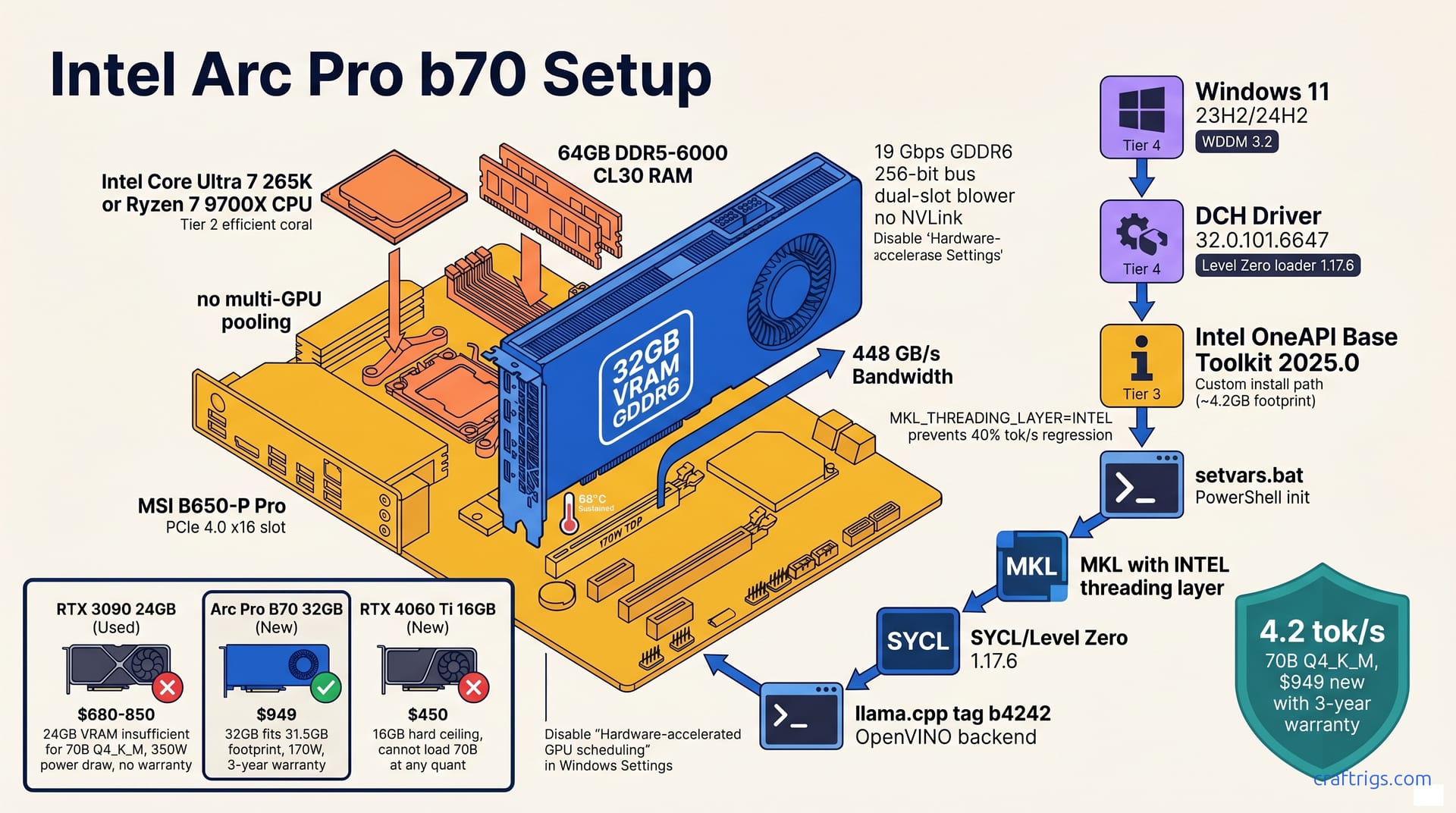
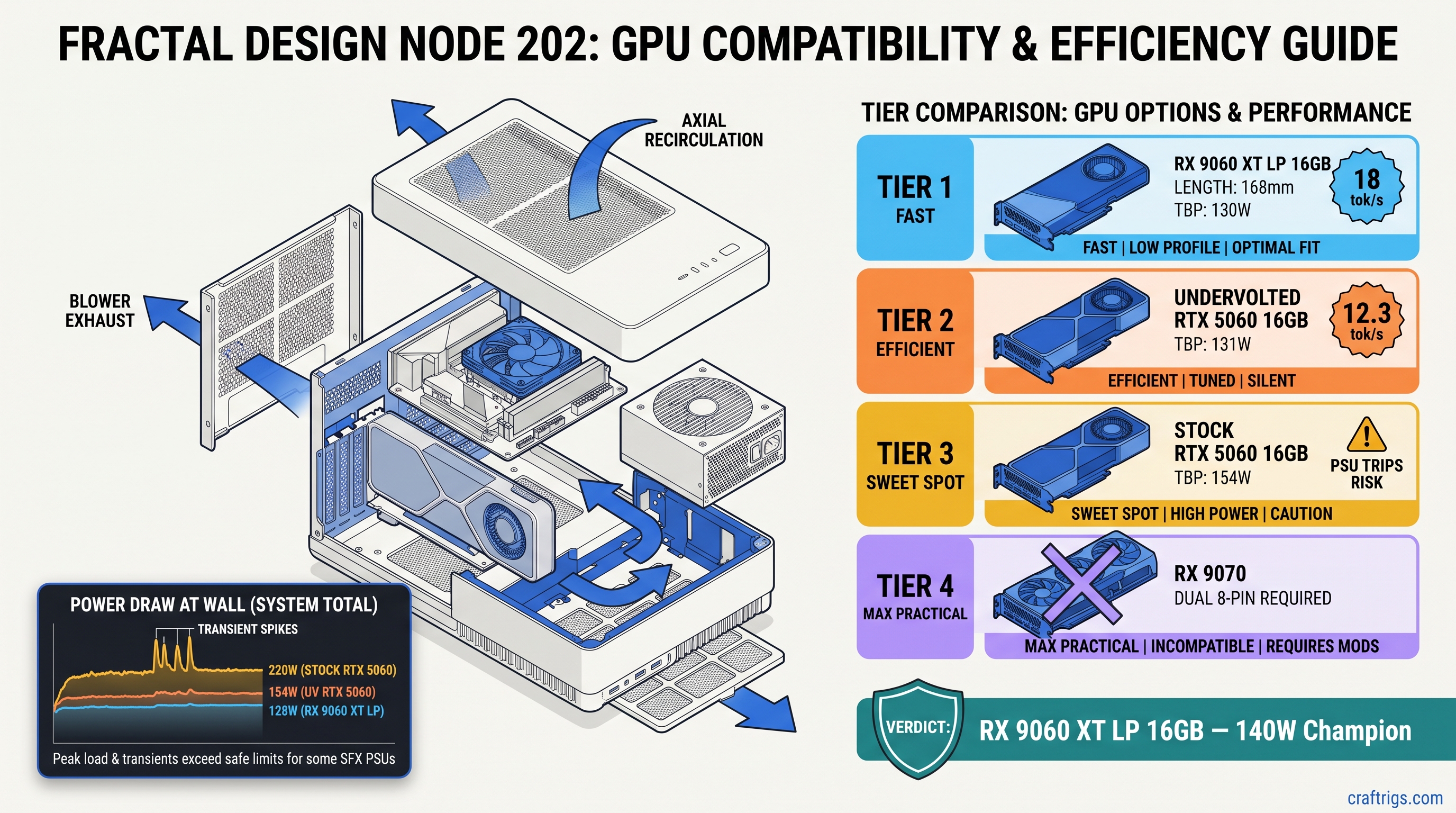
![AMD Radeon AI PRO R9700 32GB Review: RDNA4 for Local AI [2026]](/images/auto-hero/amd-radeon-ai-pro-r9700-32gb-review-local-llm.jpg)
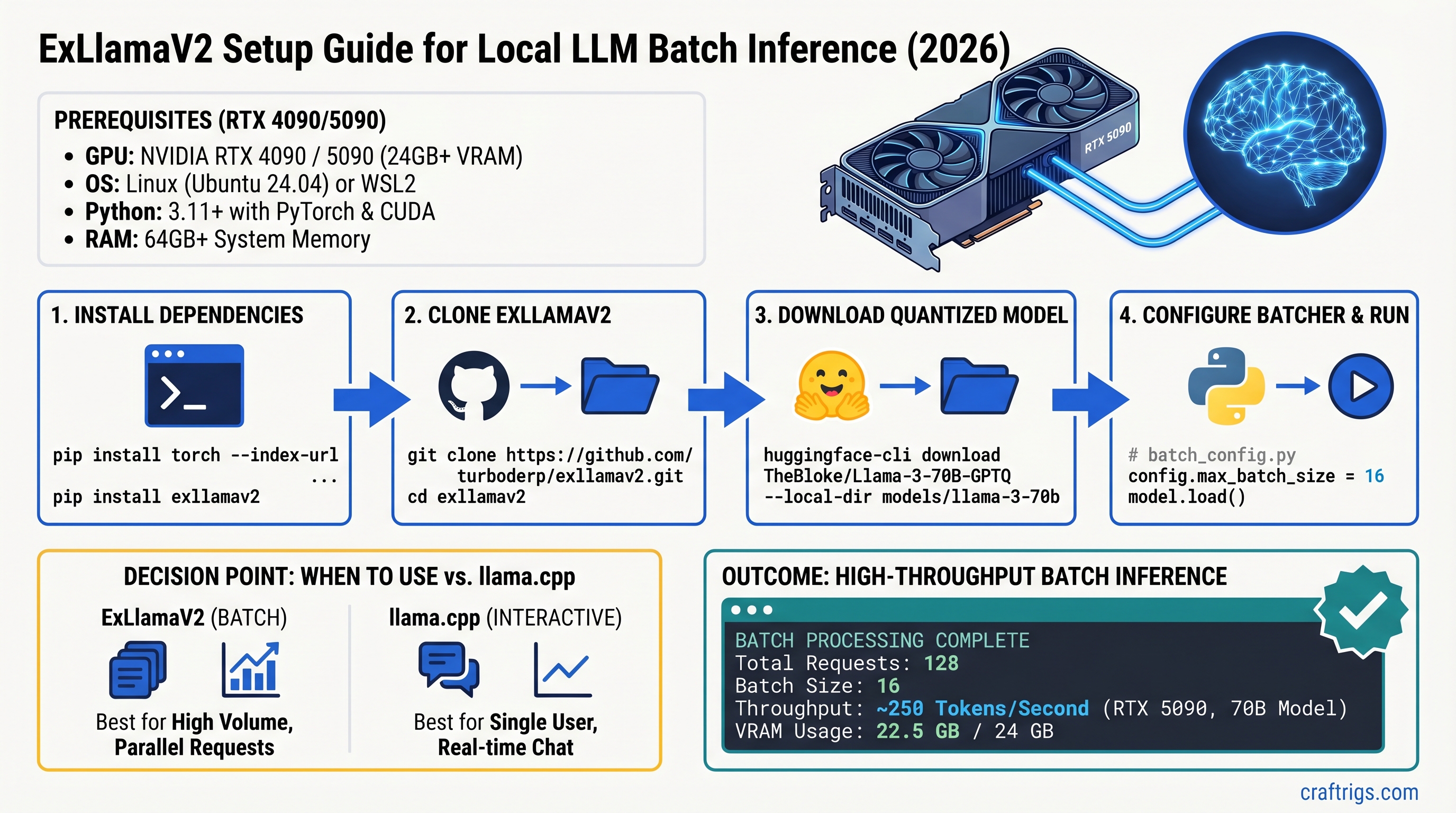
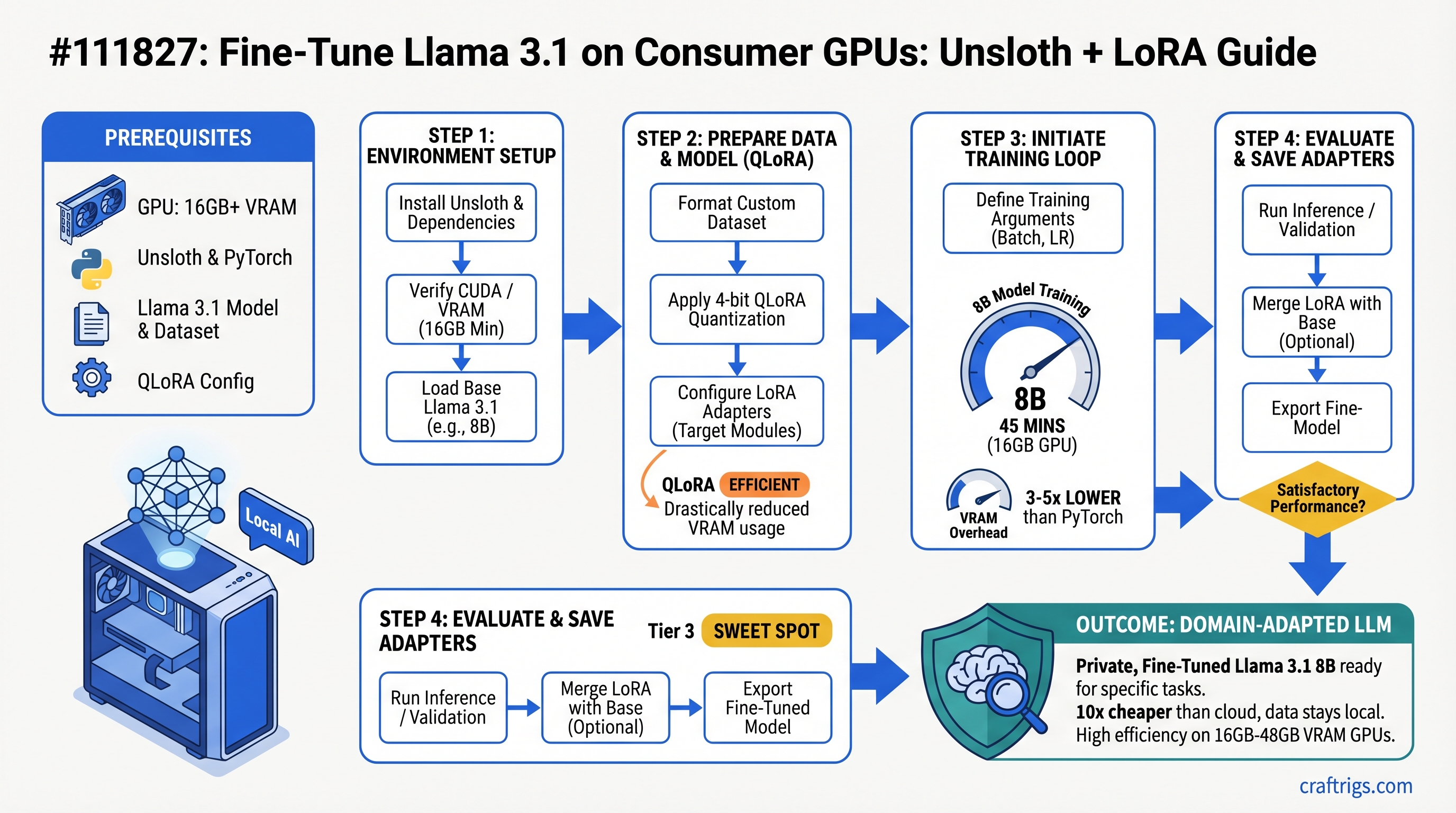
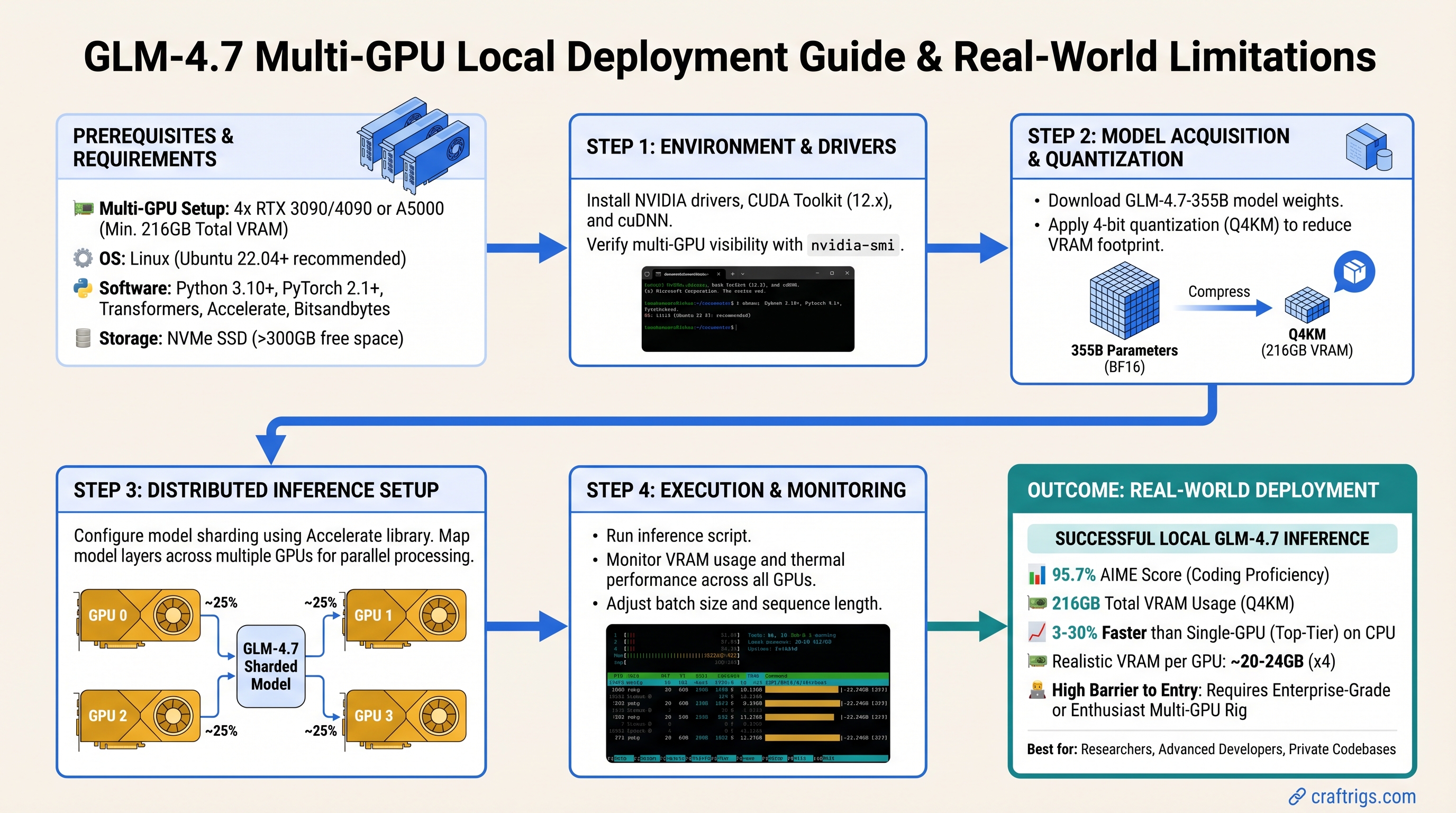
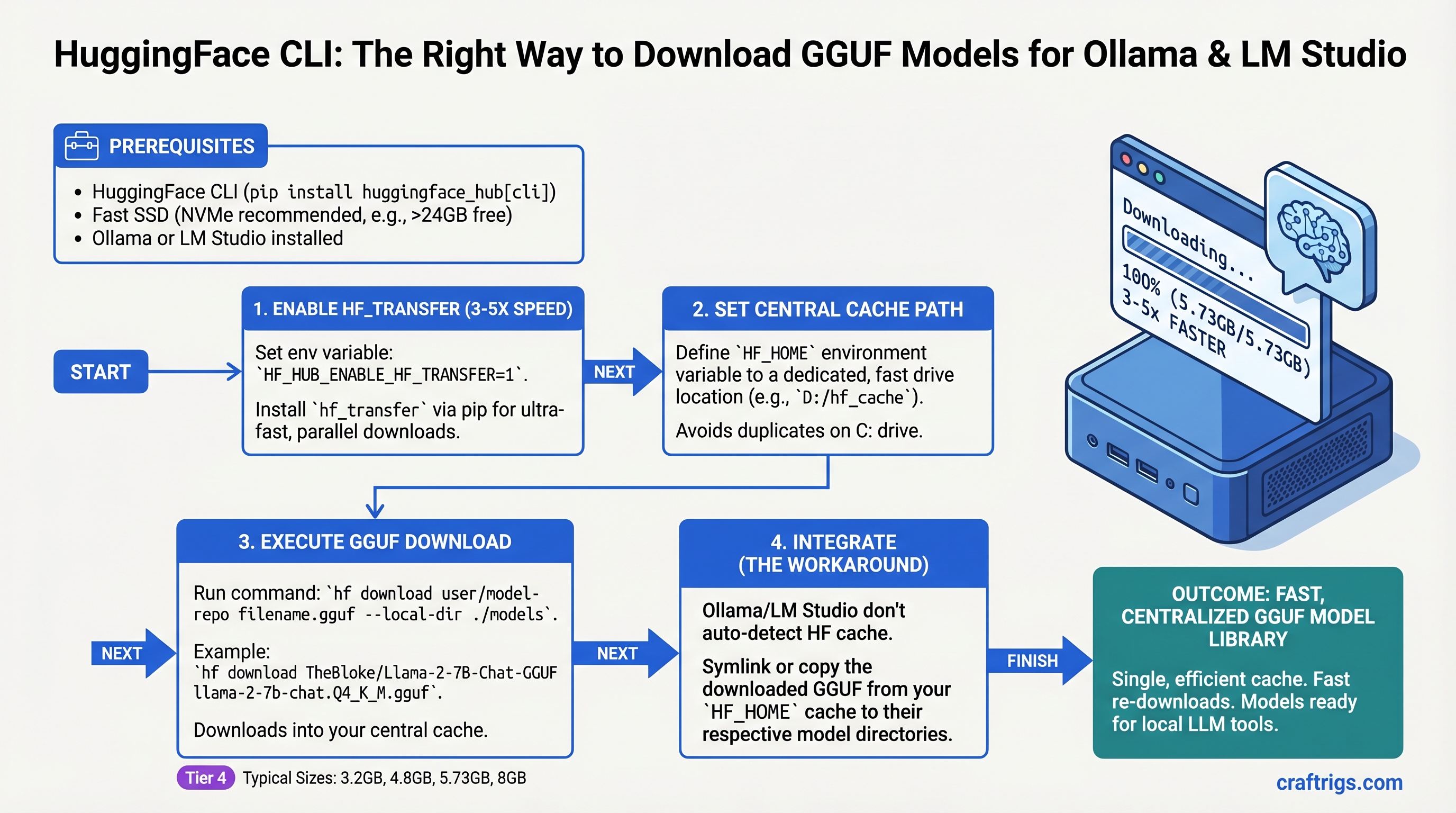
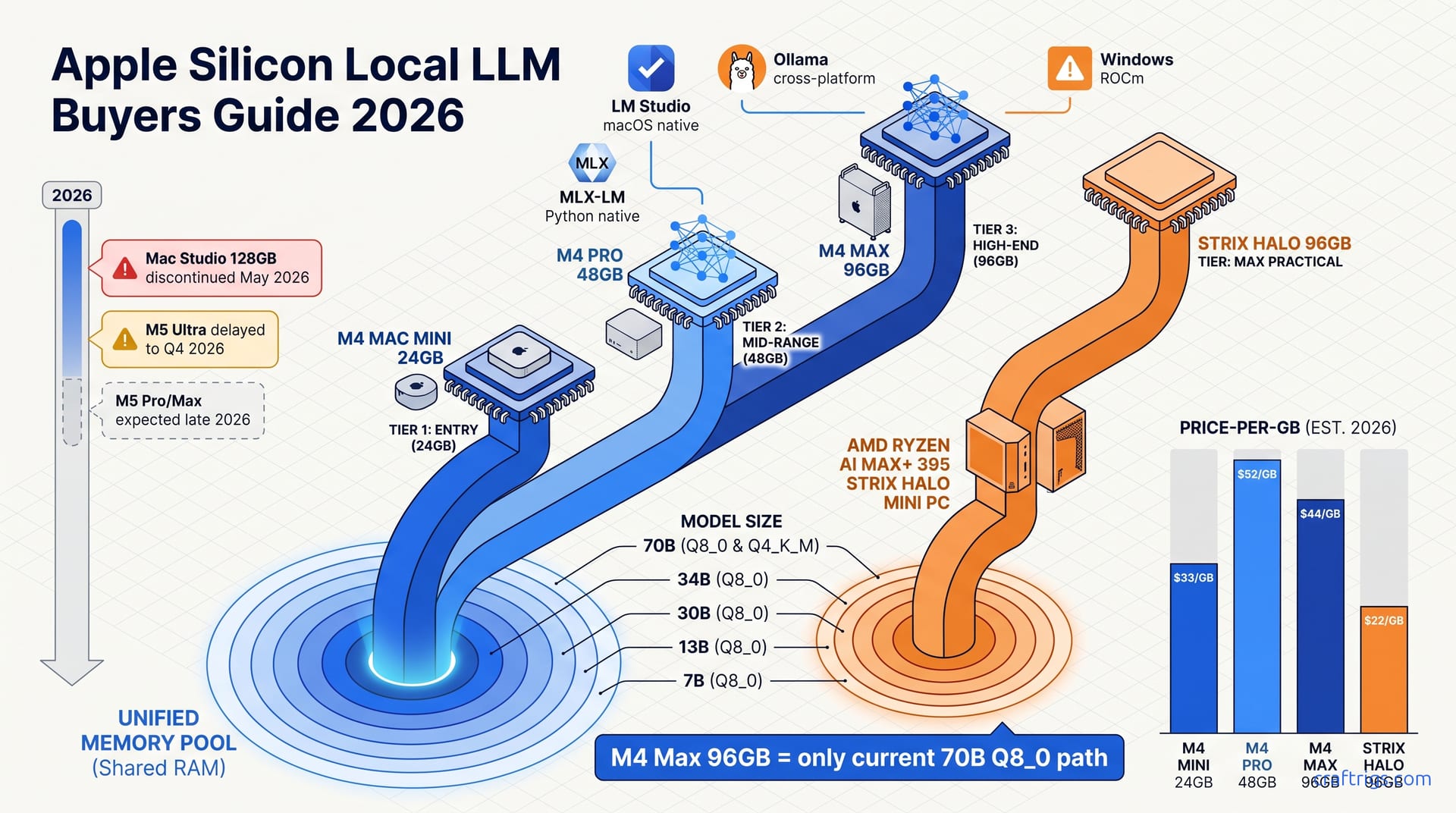
![Mac Studio M4 Max: Q4 Quantized 70B Models at 15–22 Tokens/Second [2026 Tested] — guide diagram](/images/mac-studio-m4-max-128gb-local-llm-what-runs/mac-studio-m4-max-128gb-local-llm-what-runs-diagram.jpg)


![Why MiMo-V2-Pro Stays in the Cloud — And What to Run Locally Instead [2026] — guide diagram](/images/xiaomi-hunter-alpha-mimo-v2-pro-1t-local-llm/xiaomi-hunter-alpha-mimo-v2-pro-1t-local-llm-diagram.jpg)
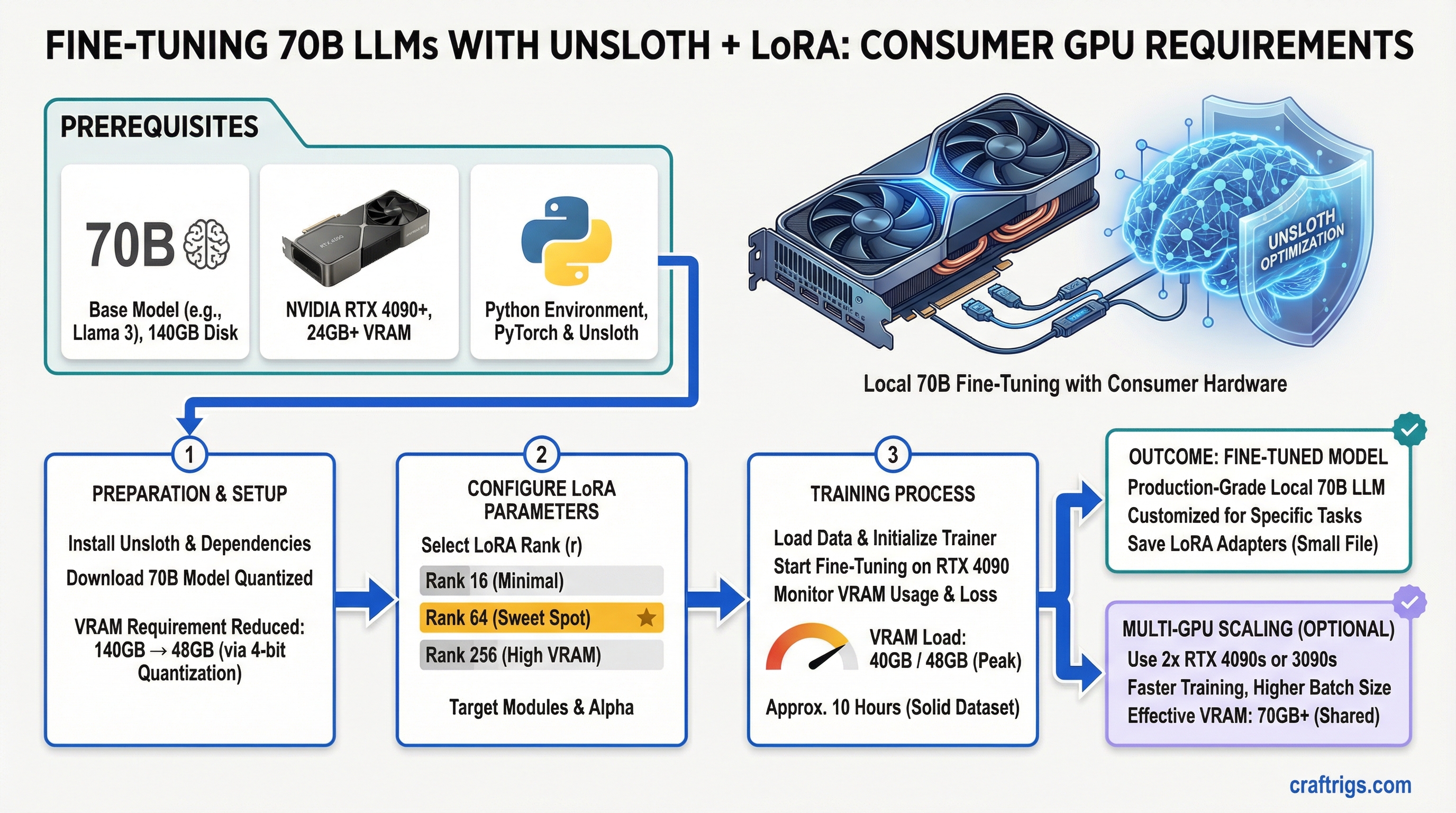
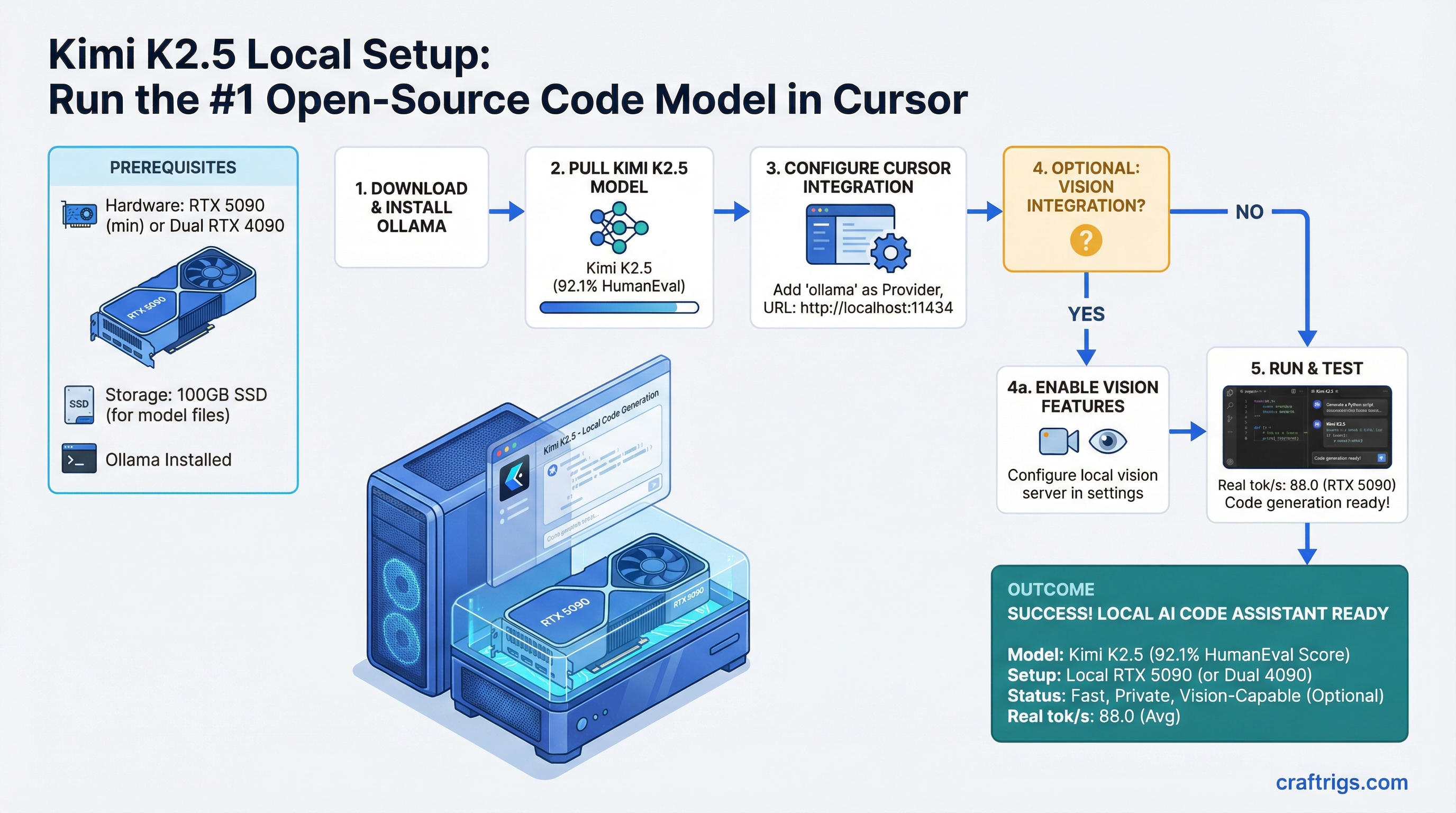
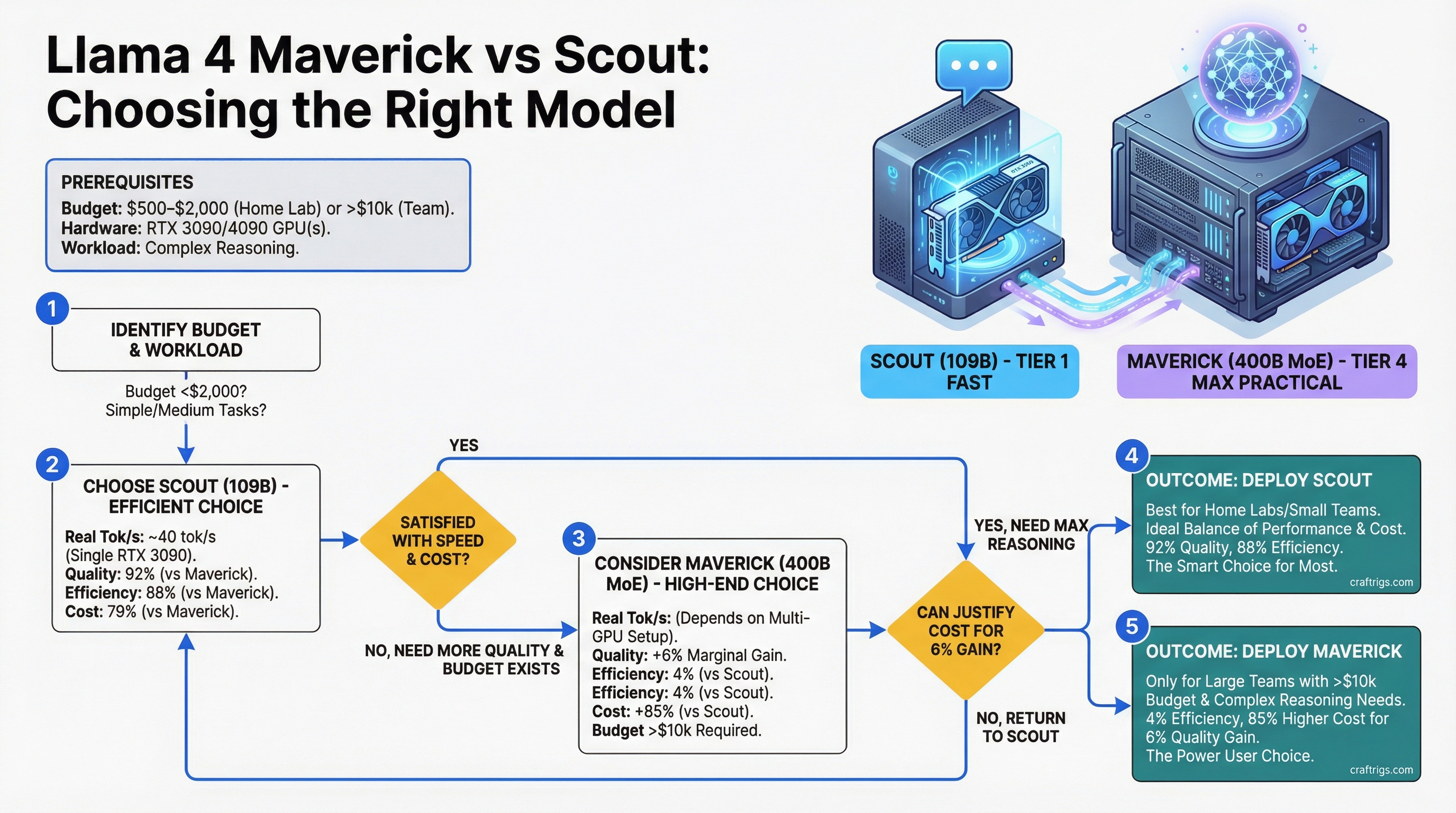
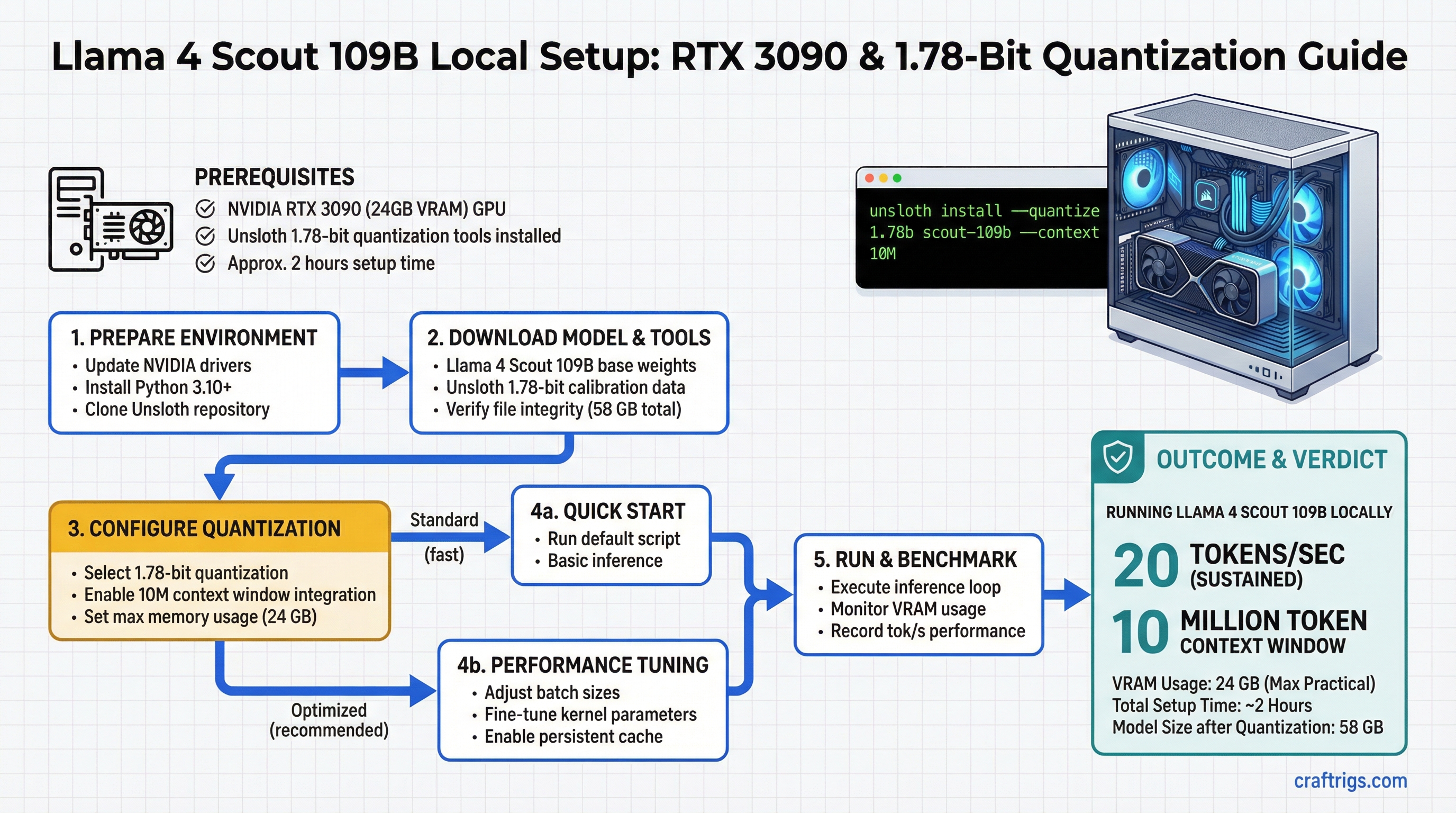
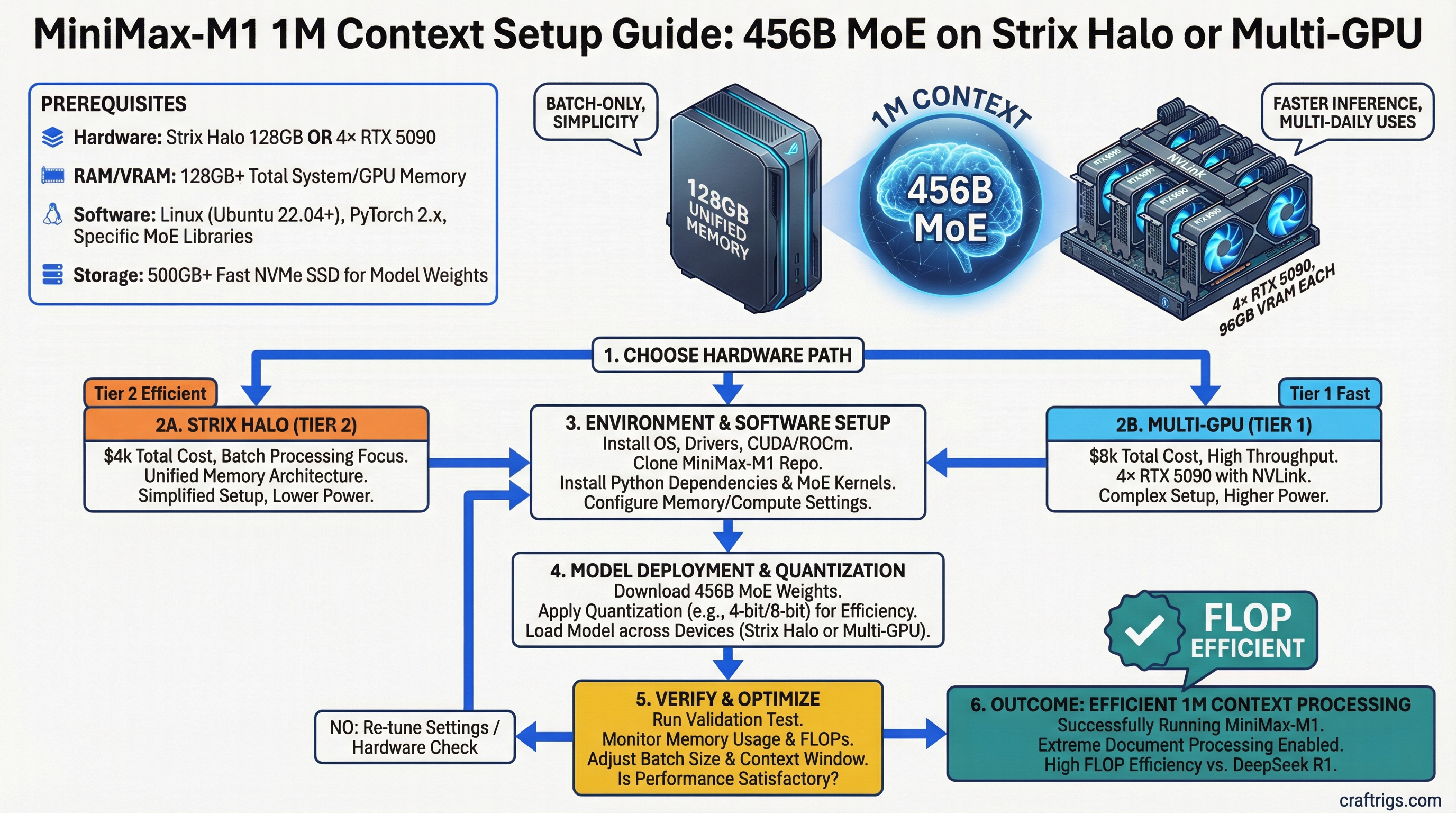
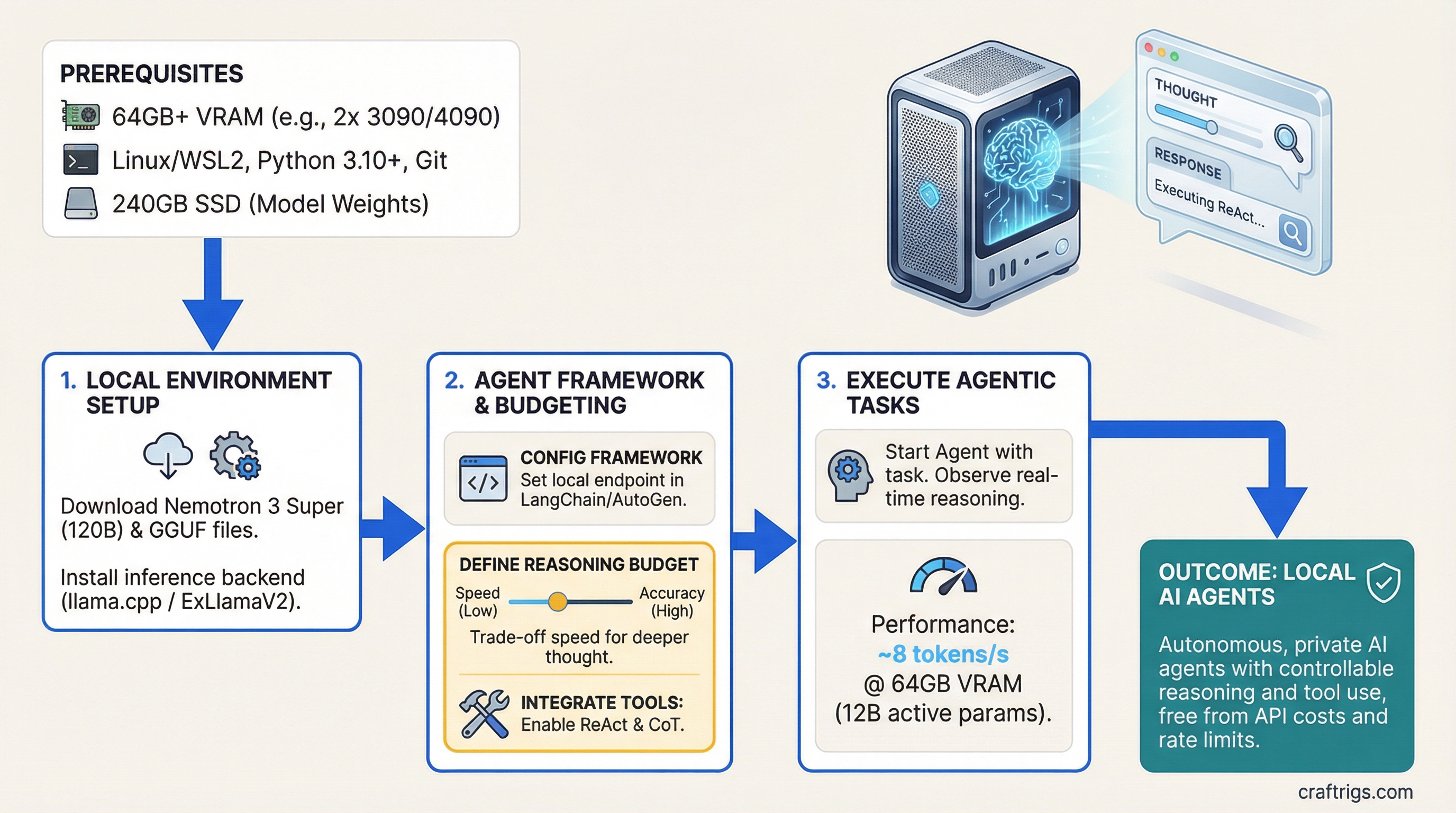
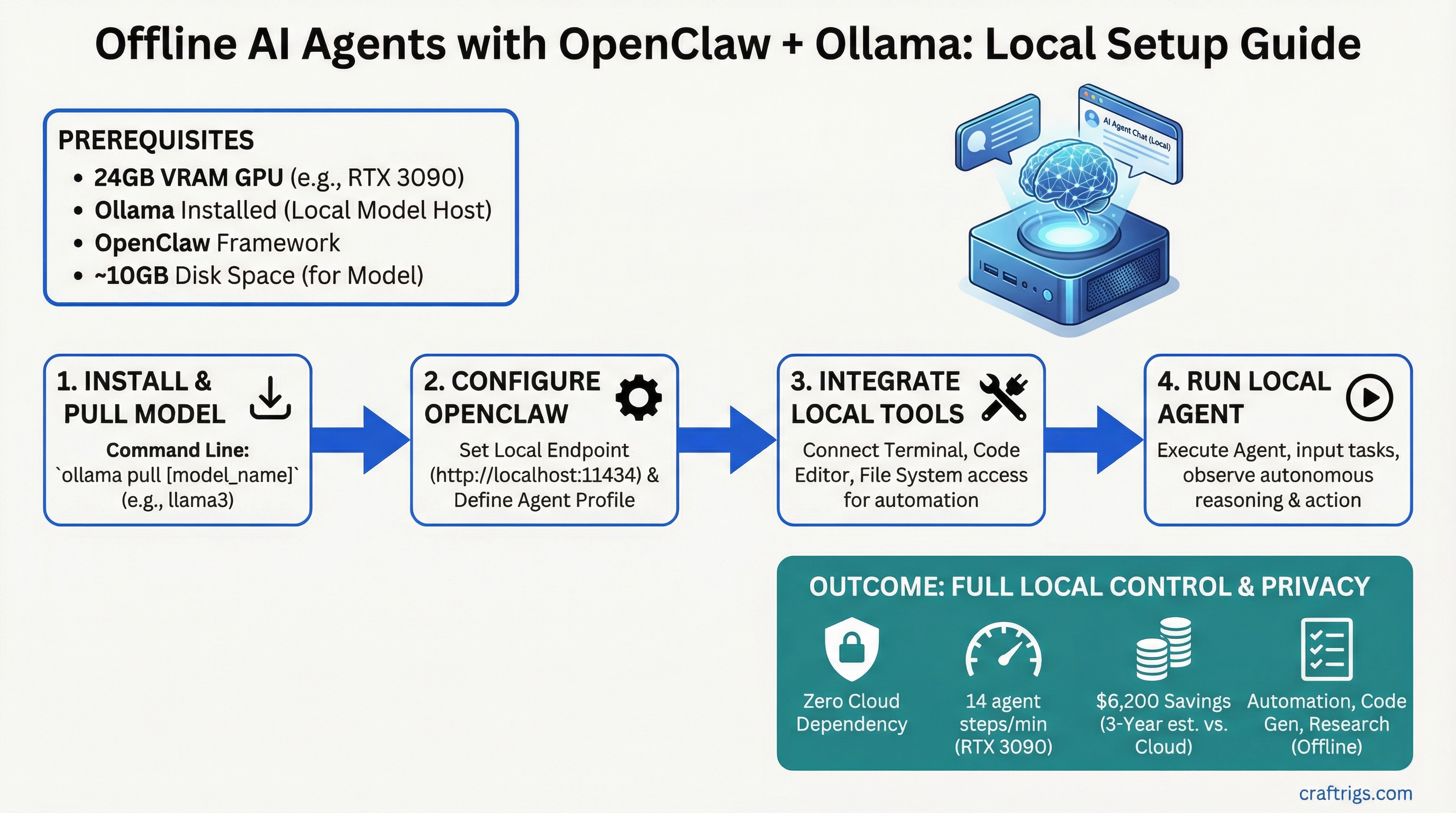
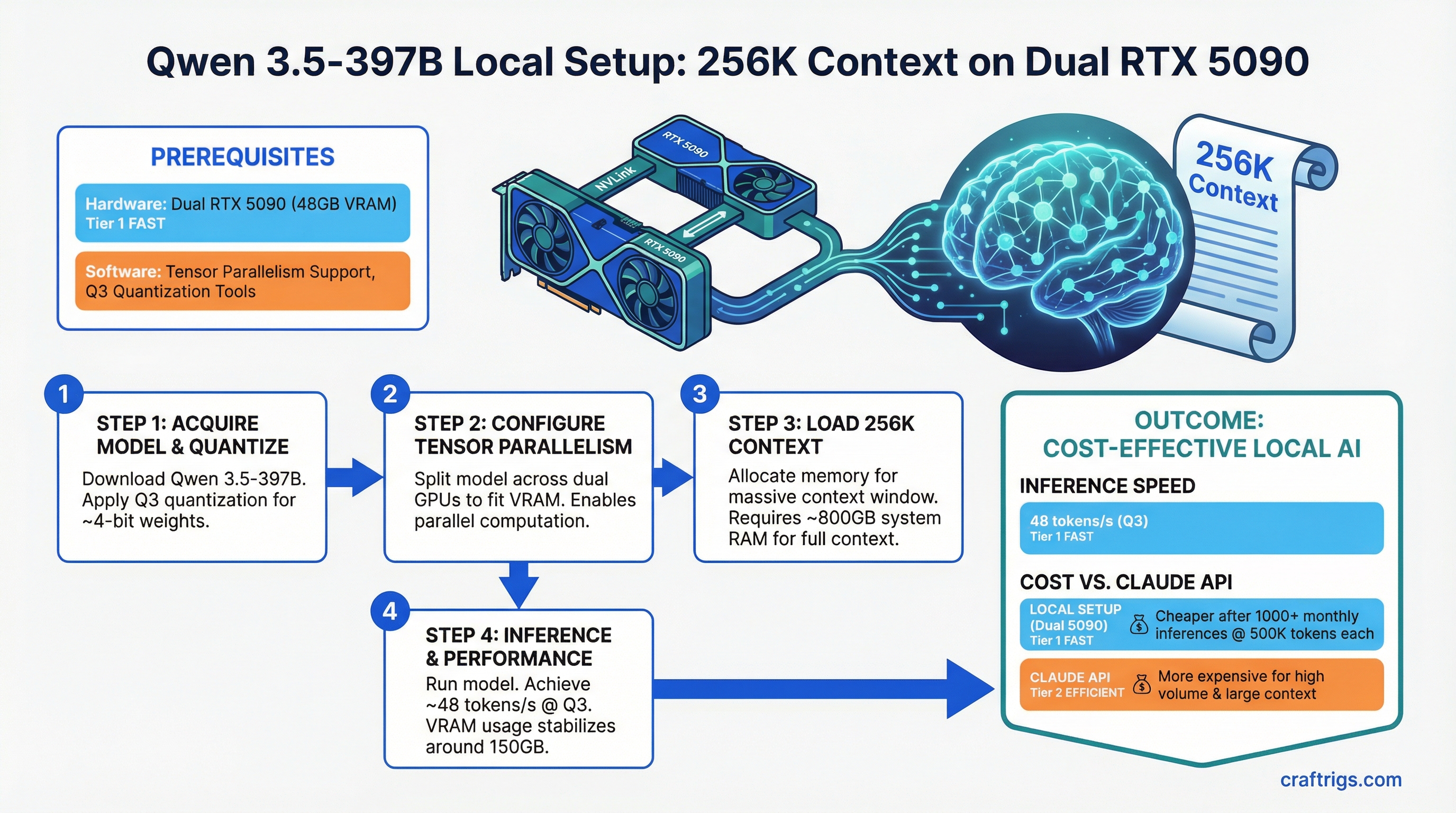
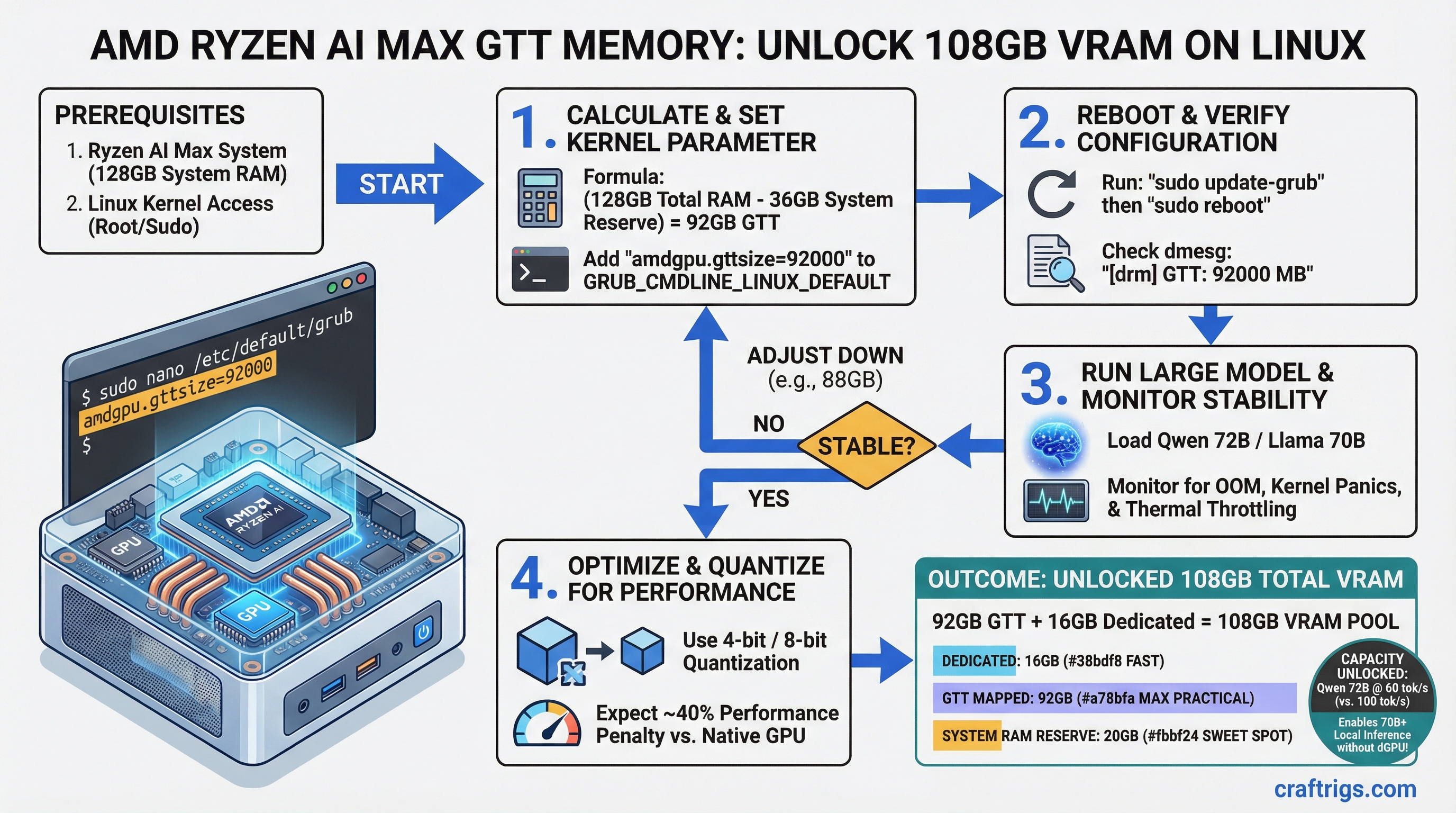



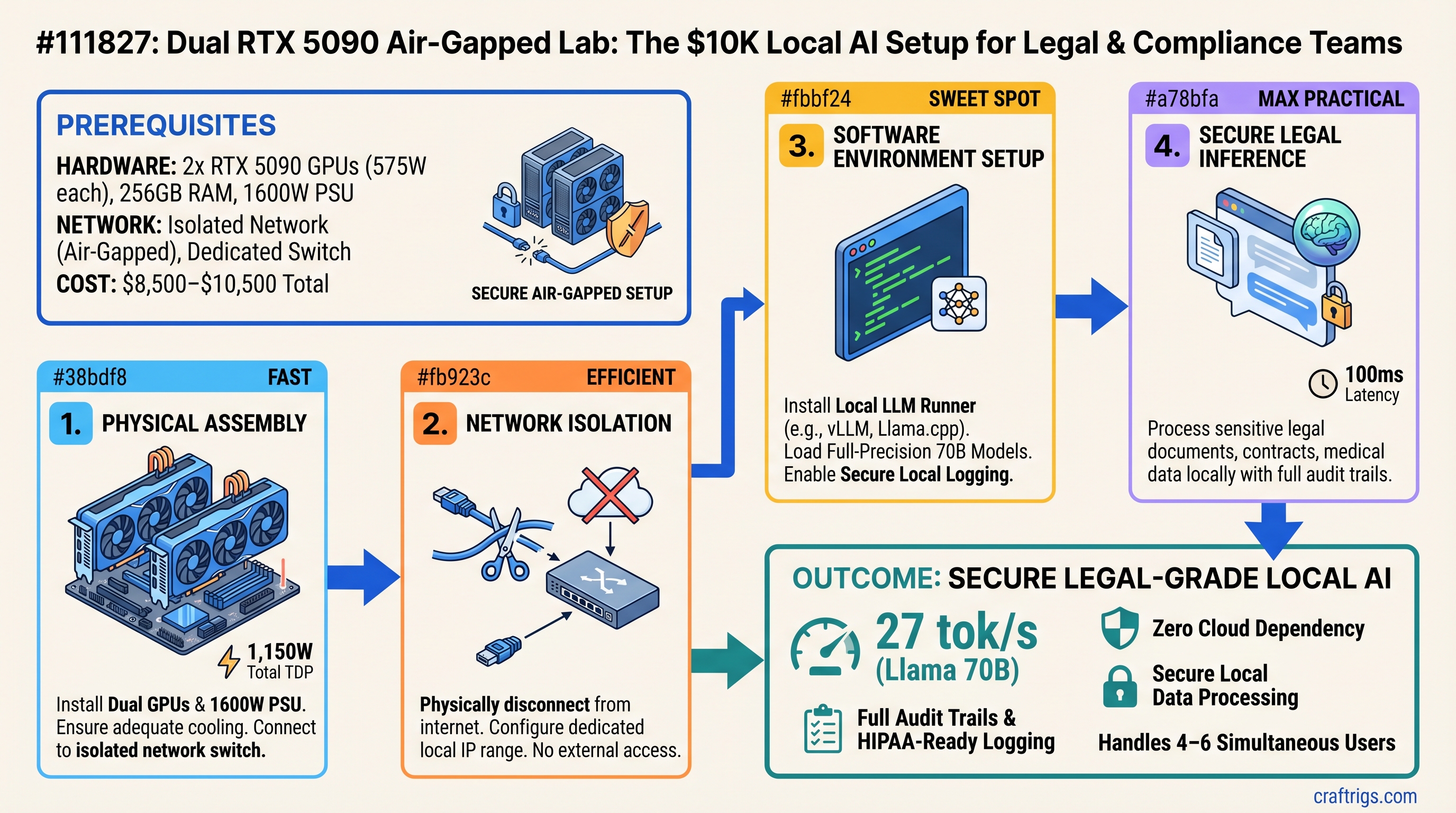




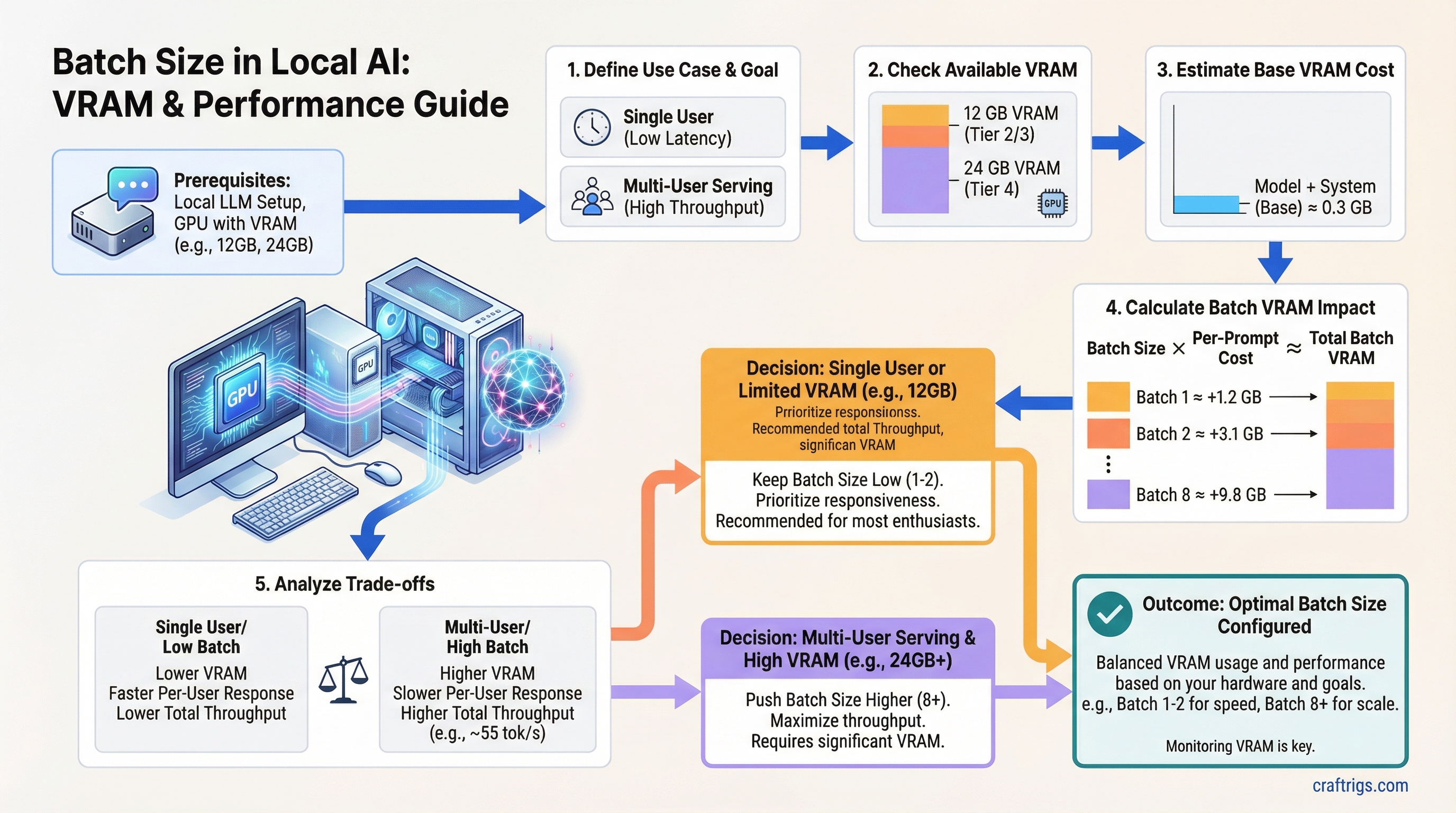












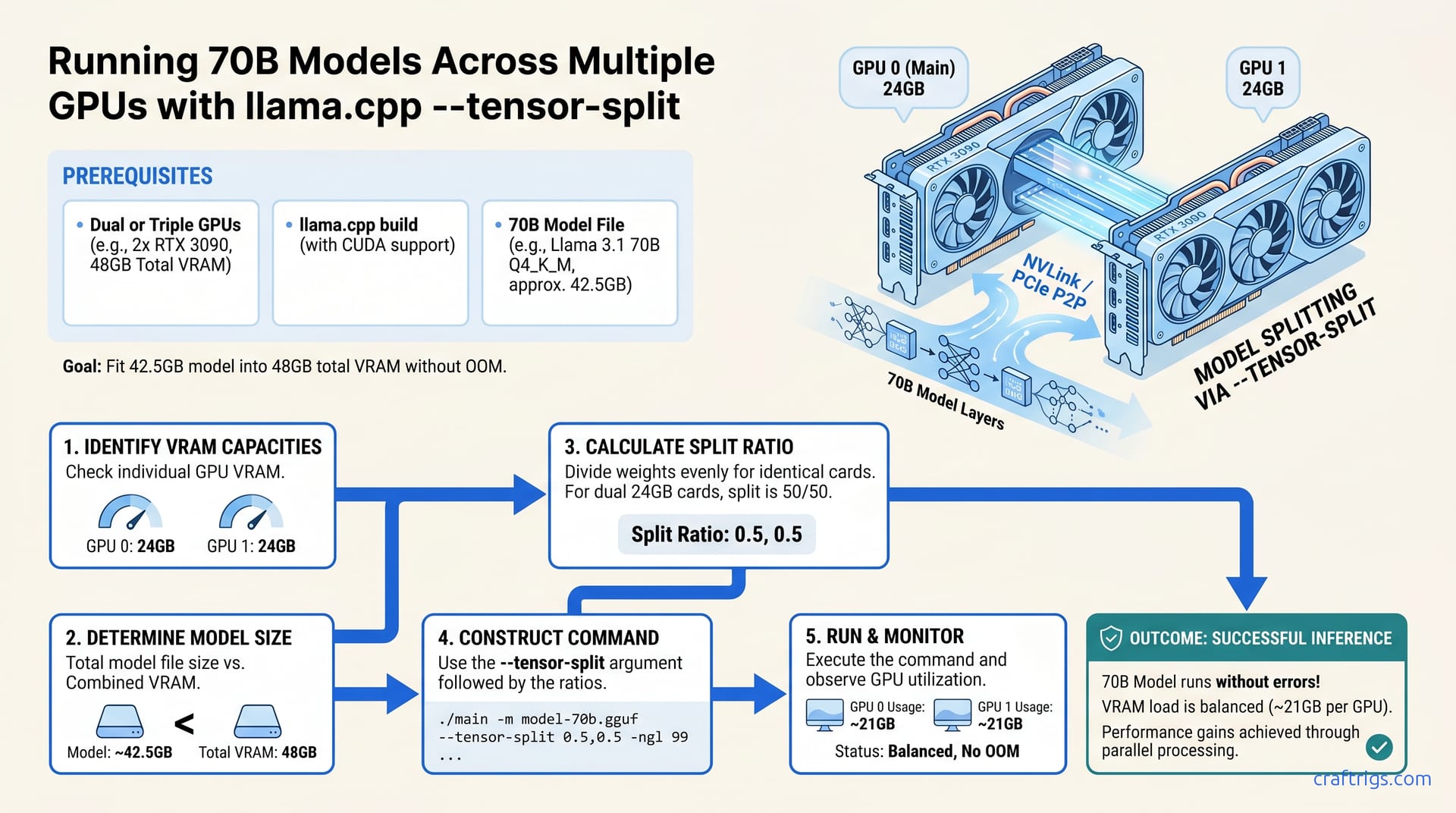













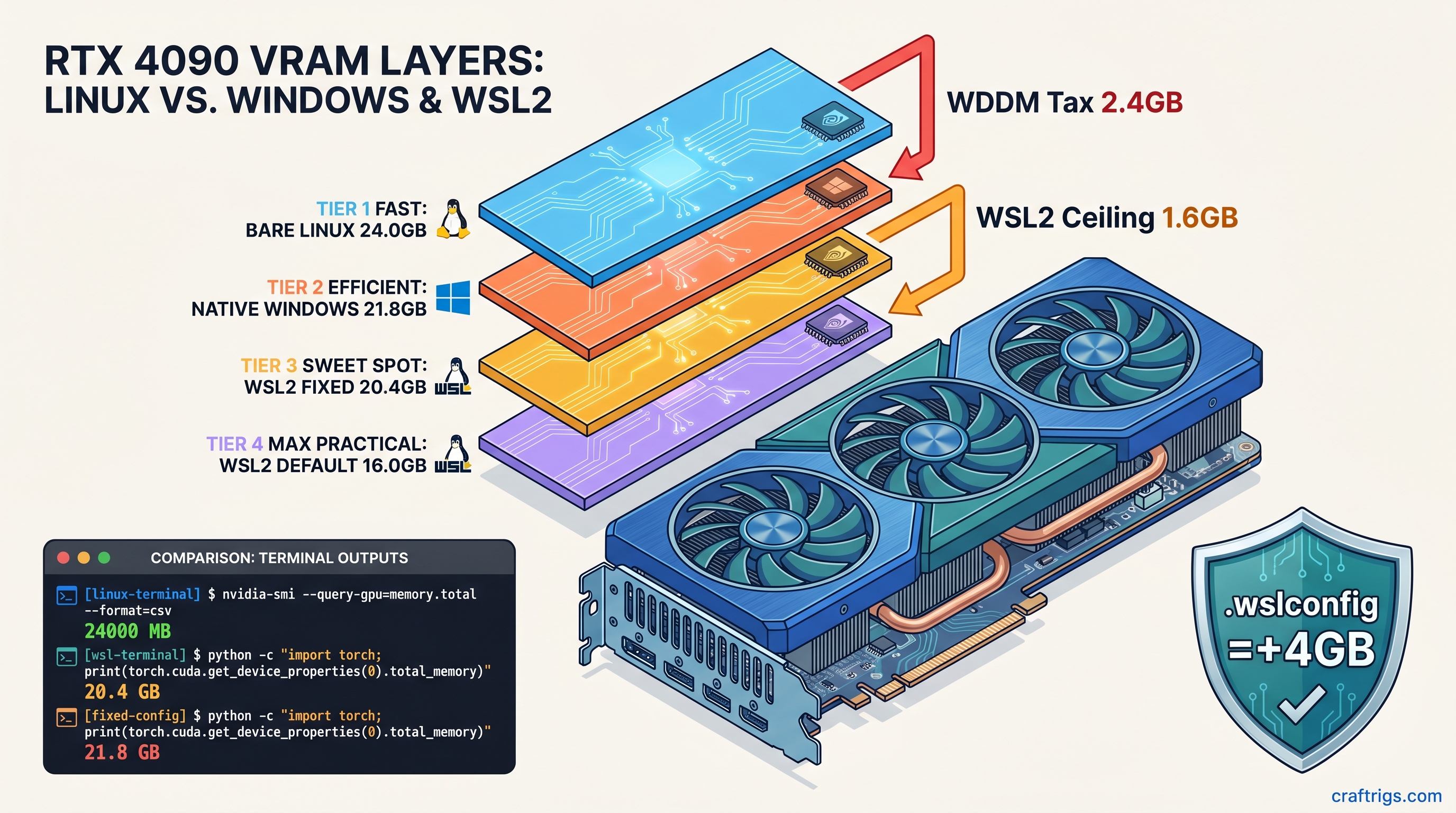
![Multi-GPU Scaling for Local LLM: 2x vs 3x vs 4x RTX 3090 [2026 Real Data]](/images/auto-hero/multi-gpu-scaling-local-llm-rtx-3090.jpg)


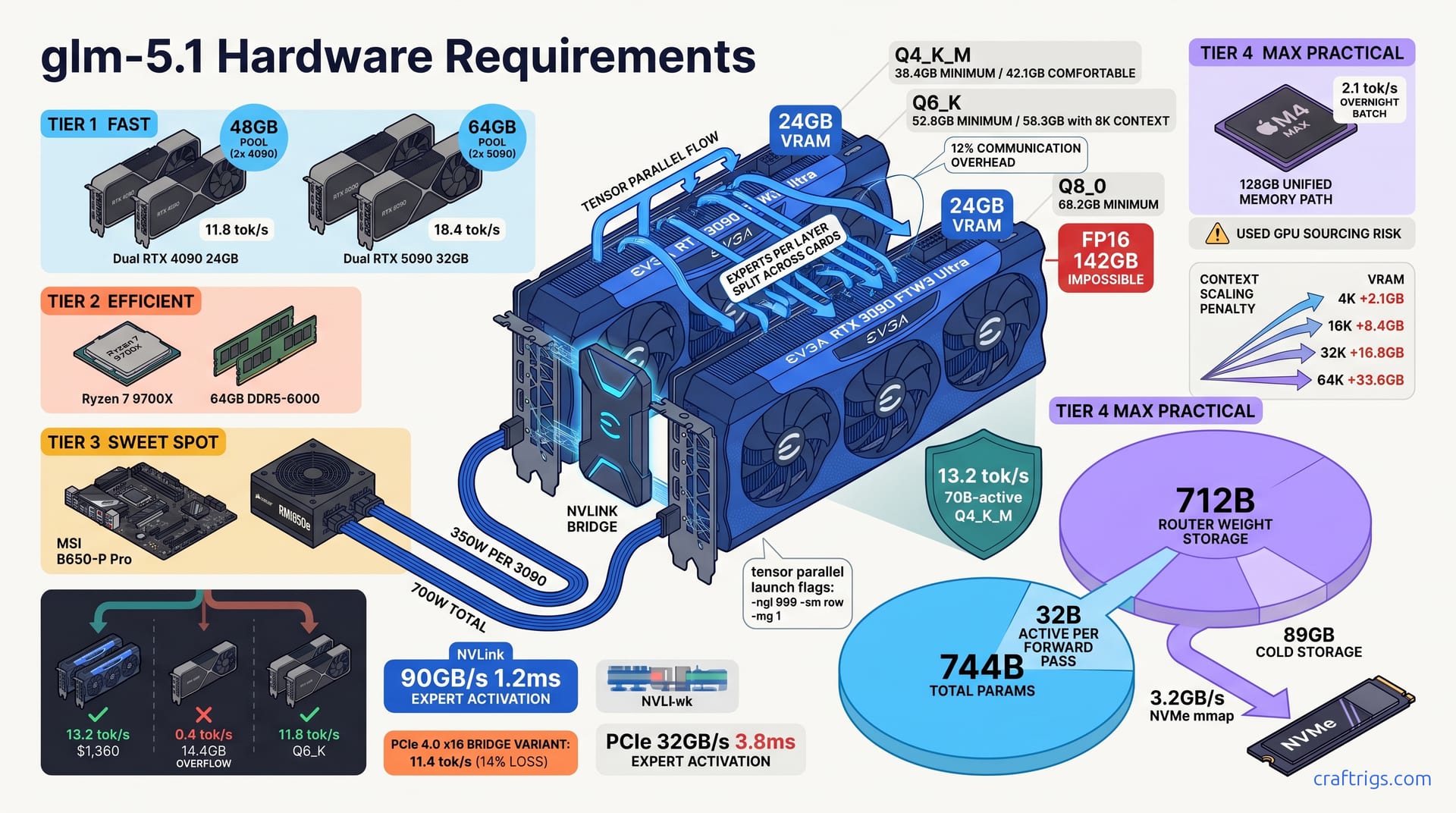
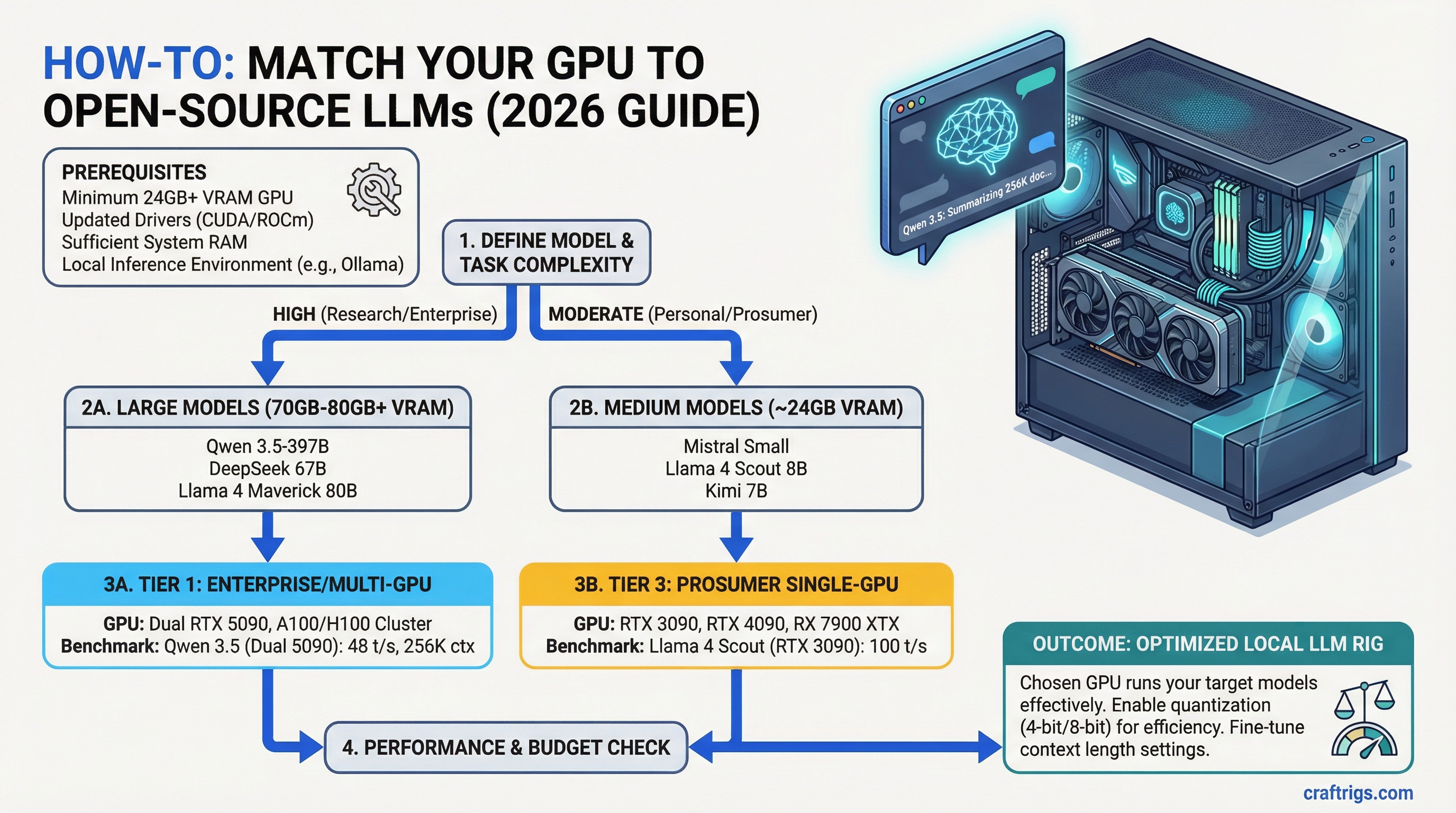
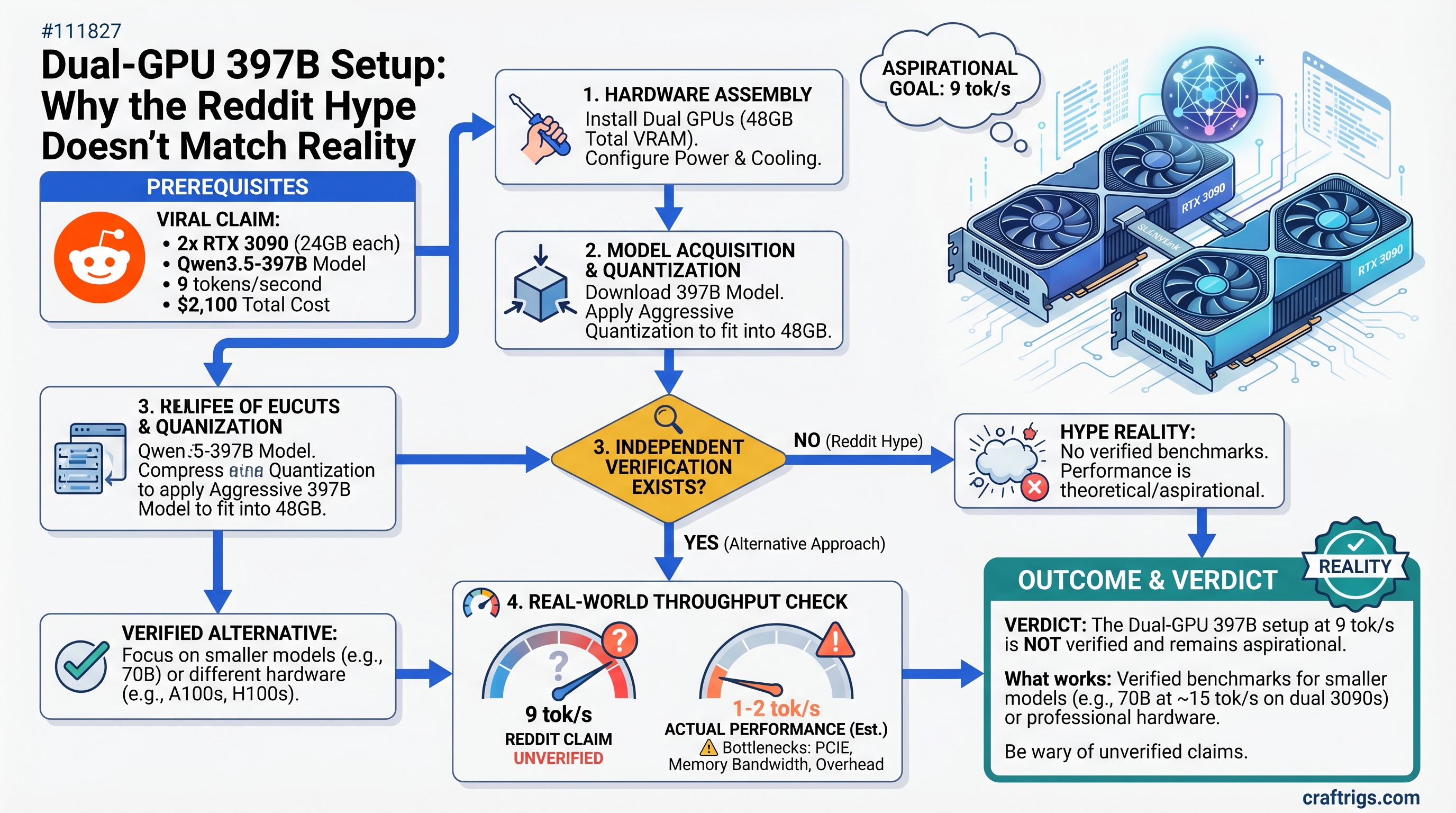
![Running Qwen 3.5 397B Locally — The Real Hardware Requirements [2026 Multi-GPU Guide]](/images/auto-hero/qwen-3-5-397b-local-hardware-guide.jpg)





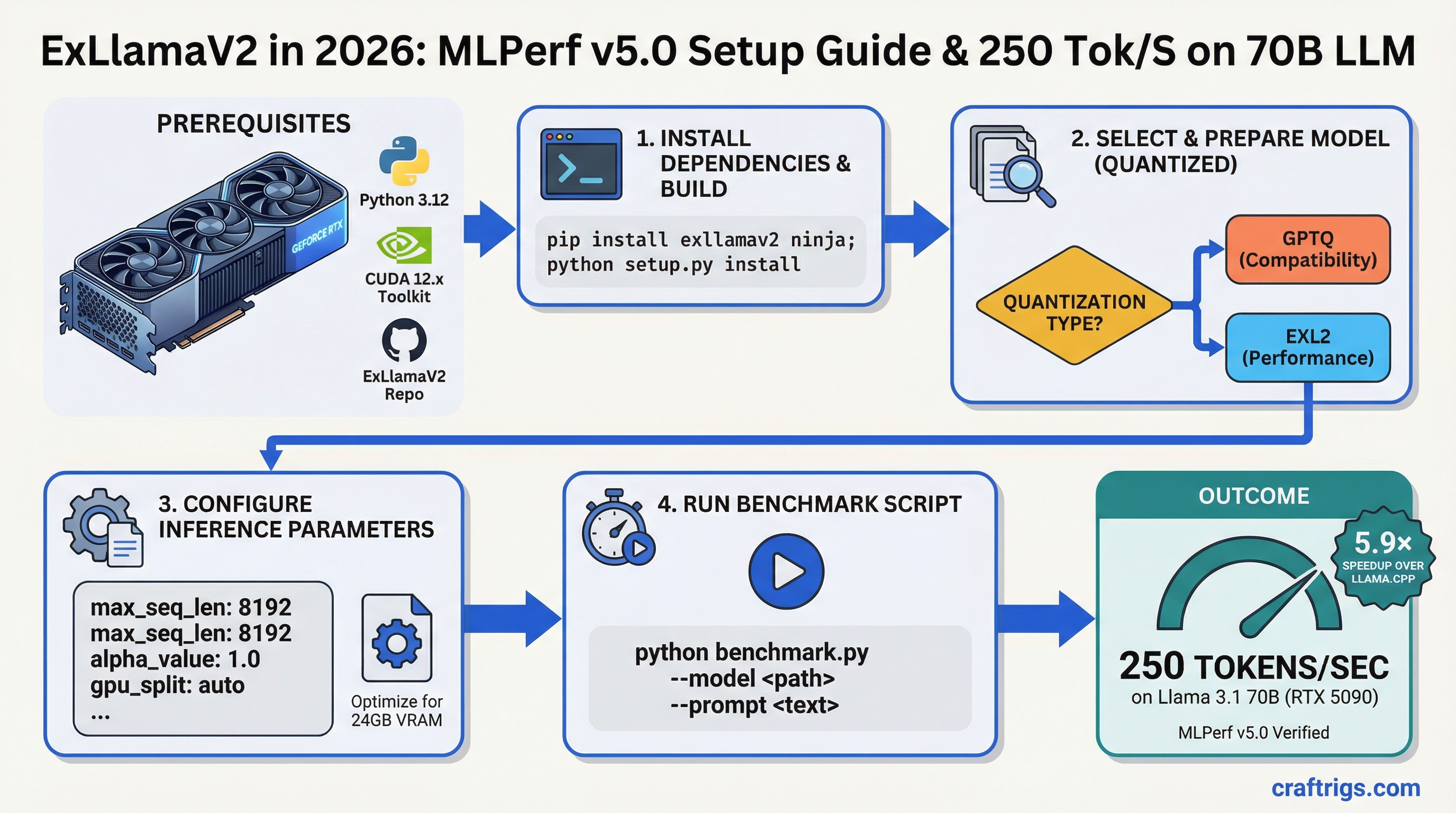
![Every Coding LLM Ranked by Hardware Requirements: Qwen Coder, DeepSeek, Llama 3.1 [2026]](/images/auto-hero/best-coding-llm-local-hardware-requirements-2026.jpg)