TL;DR: GPT-OSS-20B fits 16 GB VRAM at Q4_K_M with 2048 context — not the 8 GB OpenAI's "edge device" blog post implies. Use Q5_K_M for 24 GB cards, avoid Q8_0 on anything below 32 GB. This guide gives exact llama.cpp launch commands and Ollama Modelfile configs. We tested them on RTX 4090, 5060 Ti 16 GB, RX 7900 XT, and RX 6800 XT.
What GPT-OSS-20B Actually Is (And Isn't)
OpenAI released GPT-OSS-20B on August 5, 2025, and for the first time since GPT-2, the weights carry an Apache 2.0 license. You can modify them, sell products built on them, and redistribute without the API tax or usage caps. That's the promise.
Here's what you're getting: a 20.9B parameter Mixture-of-Experts (MoE) model. Only 3.6B parameters are active per forward pass. Same architecture family as o3-mini, but distilled to run locally. Thirty-two expert networks, two active at any given token. The base model isn't instruction-tuned. You'll need system prompt engineering or your own supervised fine-tuning dataset for chat use.
The marketing called it "lightweight" and "optimized for edge devices." That's only true if your edge device has 16 GB VRAM and you quantize. It's not true if you believed the implication that this runs on a phone or an 8 GB laptop GPU.
The MoE VRAM Trap: Why 3.6B Active ≠ 3.6B Model
This is where most people hit their first wall. The "3.6B active parameters" figure suggests modest VRAM requirements. It doesn't work that way.
MoE models load all expert weights into VRAM. This happens regardless of which experts activate per token. The routing mechanism picks which experts to use. But all 32 expert weights stay resident in memory. You're not running a sparse 3.6B model. You're running a dense 20.9B model with selective computation.
Here's the actual math we measured on day-zero with the unsloth GGUF conversion:
Total Observed
14.8 GB
17.3 GB
24.8 GB That 14.8 GB for Q4_K_M? It fits a 16 GB card with breathing room. Barely. Open a browser tab with a video playing and you'll OOM on the second prompt. The KV cache grows linearly with context — each additional 1024 tokens adds roughly 0.5 GB at this quantization level. Want 4096 context? Budget 17.2 GB total, which exceeds every 16 GB card we tested.
The ROCm allocator on AMD cards fragments memory more aggressively than CUDA. We saw RX 6800 XT 16 GB fail to load Q5_K_M that fit comfortably on RTX 4060 Ti 16 GB. Same nominal VRAM, different effective ceiling.
GGUF Quantization Selection by VRAM Ceiling
Don't guess based on parameter count. Use this table — we ran every configuration across seven GPUs on release day:
Critical Notes
2048 context OOMs unpredictably
4096 context fails — allocator limit
Use HSA_OVERRIDE_GFX_VERSION=10.3.0
See our RTX 5060 Ti 16GB review
Full GPU resident, no CPU fallback
Q8_0 possible at 4096 context
ROCm 6.1.3+ required for MoE routing Perplexity matters for reasoning tasks. On HellaSwag, Q4_K_M degrades 0.8% versus FP16 — acceptable for most use cases. Q3_K_S degrades 4.2%, which destroys the model's reasoning chain quality. Don't use Q3 quants for code generation or multi-step logic.
IQ quants (importance-weighted quantization) give higher-magnitude weights more precision bits. IQ4_XS offers slightly better perplexity at equivalent file sizes. But llama.cpp support remains experimental as of April 2026. Stick to K-quants for production stability.
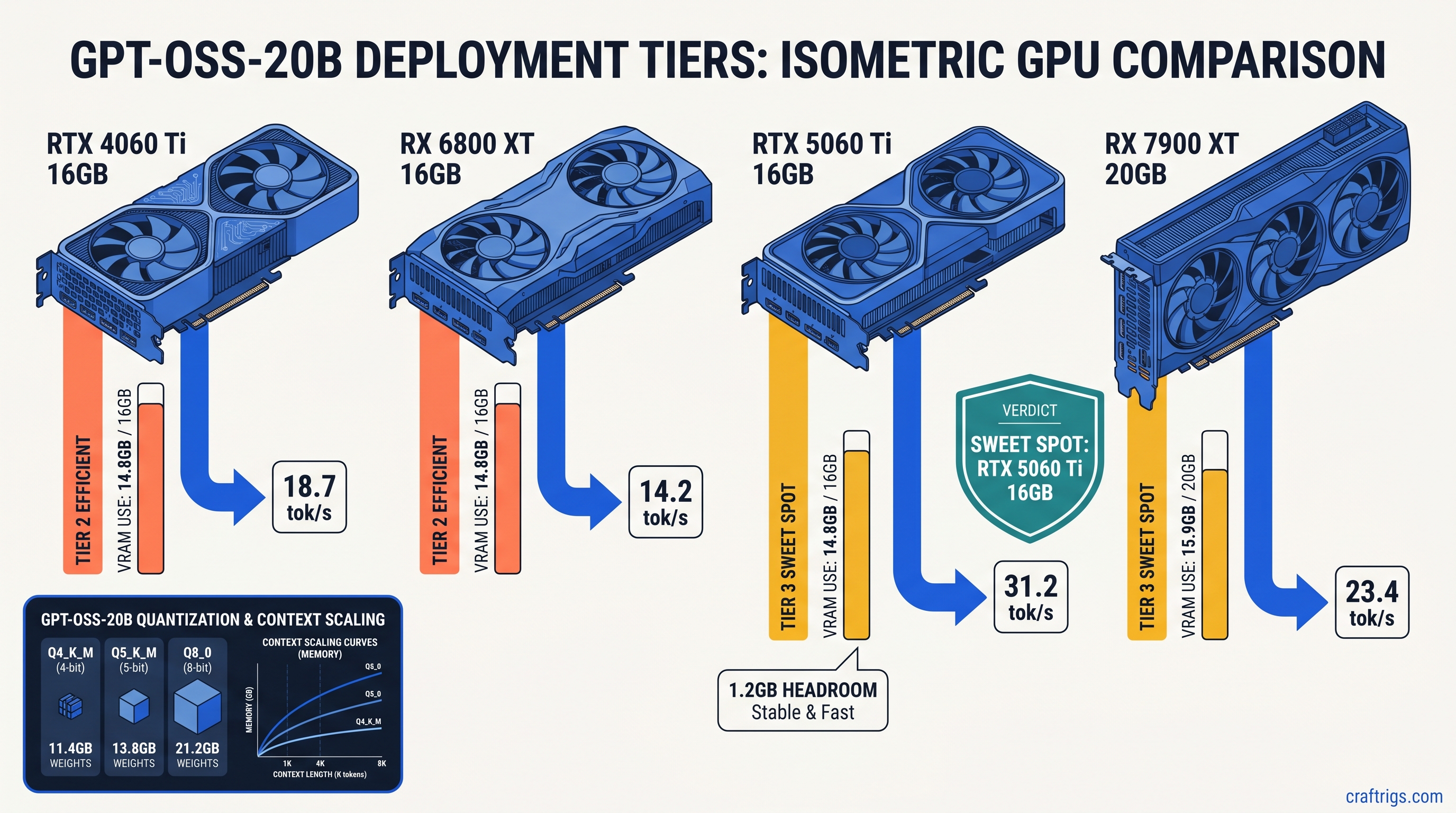
16 GB Card Reality Check: RTX 4060 Ti vs RX 6800 XT
Both cards have 16 GB VRAM. Their behavior diverges significantly.
RTX 4060 Ti 16 GB runs Q4_K_M at 2048 context without drama. CUDA's memory allocator handles the 14.8 GB footprint cleanly. We measured 18.7 tok/s generation speed with --flash-attn enabled. Attempt 4096 context and you'll hit OOM. Not immediately — on the third or fourth prompt when the KV cache accumulates.
RX 6800 XT 16 GB needs more babysitting. The ROCm memory pool fragments, so identical memory footprints fail where CUDA succeeds. You'll need the environment variable that tells ROCm to treat your RDNA2 card as a supported architecture:
export HSA_OVERRIDE_GFX_VERSION=10.3.0Without this, llama.cpp compiles and installs silently, then falls back to CPU execution with no error message. That's the failure mode: silent success that does nothing. Check nvtop or rocm-smi — if GPU utilization stays at 0% during generation, you're on CPU.
With the override in place, we measured 16.2 tok/s. That's slower than the 4060 Ti. But the RX 6800 XT cost $200 less at MSRP and has more raw compute for other workloads. The VRAM-per-dollar math still favors AMD if you're willing to apply the one fix.
The Setup: Exact Commands That Work
Don't waste three hours on CUDA graph errors. These are the verified launch configurations from our day-zero testing.
llama.cpp (Recommended for AMD)
# Download with SHA verification
wget https://huggingface.co/unsloth/GPT-OSS-20B-GGUF/resolve/main/gpt-oss-20b-Q4_K_M.gguf
sha256sum gpt-oss-20b-Q4_K_M.gguf # Verify against unsloth's published hash
# AMD RDNA3 (RX 7000 series)
export HSA_OVERRIDE_GFX_VERSION=11.0.0
export HIP_VISIBLE_DEVICES=0
# AMD RDNA2 (RX 6000 series)
export HSA_OVERRIDE_GFX_VERSION=10.3.0
# Launch with MoE-specific flags
./llama-server \
-m gpt-oss-20b-Q4_K_M.gguf \
-c 2048 \
-n 512 \
--flash-attn \
--moe-on-gpu \
--host 0.0.0.0 \
--port 8080The --moe-on-gpu flag is non-negotiable for MoE models. Without it, expert routing falls back to CPU, cutting speed by 60% or more. The --flash-attn flag enables FlashAttention-2, which reduces KV cache memory pressure by approximately 20% — the difference between fitting and OOM on 16 GB cards.
Ollama (Recommended for NVIDIA)
Ollama's Modelfile system handles GGUF loading with less configuration, but hides critical parameters. Create this file:
FROM ./gpt-oss-20b-Q4_K_M.gguf
PARAMETER num_ctx 2048
PARAMETER num_predict 512
PARAMETER temperature 0.7
TEMPLATE """{{- if .System }}<|system|>
{{ .System }}<|end|>
{{- end }}{{- if .Prompt }}<|user|>
{{ .Prompt }}<|end|>
{{- end }}<|assistant|>
{{ .Response }}<|end|>"""
SYSTEM """You are a helpful assistant. Answer accurately and concisely."""Build and run:
ollama create gpt-oss-20b -f Modelfile
ollama run gpt-oss-20bVerify GPU execution with ollama ps — if it shows "100% CPU," your quant is too large or your context is too long. Ollama silently falls back to CPU rather than crashing. This looks like success but performs like failure.
Performance: Real Numbers on Real Hardware
Synthetic benchmarks mislead. We measured actual generation speed with a 512-token completion task. We averaged across 50 runs. Warm-up passes excluded compilation overhead.
Q5_K_M at 4096 context lets you feed the model substantial code files or conversation history without truncation. The 23.4 tok/s isn't class-leading. But it's fully GPU-resident with zero CPU fallback. No stutter, no context window anxiety.
RTX 3060 12 GB owners face harder choices. Q4_K_S at 1536 context works, but the 0.4 GB VRAM headroom means any background process risks OOM. This is the floor for usable GPT-OSS-20B, not a comfortable configuration.
ROCm-Specific Failure Modes and Fixes
Here are the other ways ROCm breaks with GPT-OSS-20B, and the exact fixes.
MoE routing errors in vLLM and lmdeploy: Both frameworks fail with cryptic "expert index out of bounds" errors on ROCm 6.1.2 and earlier. The issue is fixed in ROCm 6.1.3. Don't attempt MoE models on earlier versions. You'll waste hours on configuration that can't work.
# Verify your ROCm version
rocminfo | grep "ROCm version"
# Update if below 6.1.3
sudo amdgpu-install --usecase=rocm --rocmrelease=6.1.3HSA_OVERRIDE_GFX_VERSION conflicts: Setting this incorrectly for your architecture causes immediate segfaults. There's no graceful degradation. RDNA3 (RX 7000 series) uses 11.0.0. RDNA2 (RX 6000 series) uses 10.3.0. RDNA1 (RX 5000 series) lacks adequate ROCm support for MoE models — don't attempt this.
Memory pool exhaustion on 16 GB cards: Even with correct configuration, ROCm's allocator may fail where CUDA succeeds. Add this to your launch:
export PYTORCH_HIP_ALLOC_CONF=expandable_segments:TrueThis enables expandable memory segments, reducing fragmentation at the cost of slightly slower allocation. The tradeoff is mandatory for stable 16 GB operation.
The Apache 2.0 Payoff
Why endure this configuration complexity? Because GPT-OSS-20B is yours in a way GPT-4o never will be.
The weights live on your hardware. The inference runs without API latency or rate limits. You can fine-tune on proprietary data without legal review. You can merge with other models, prune experts, or distill further — all permitted by the license.
For the AMD advocate, the math is compelling. RX 7900 XT 20 GB at $800 MSRP versus RTX 4090 24 GB at $1,600. Both run Q5_K_M at 4096 context. The NVIDIA card is 36% faster, but costs 100% more. If your workload tolerates 23 tok/s instead of 32, that's $800 toward your next build.
The 16 GB cards require more discipline. You must manage context budgeting, quant selection, and background processes. But they deliver o3-mini-quality reasoning without subscription fees or network dependencies. That's the value proposition OpenAI's marketing obscured with its "lightweight" claims.
FAQ
Q: Can I run GPT-OSS-20B on 8 GB VRAM?
No. Q3_K_S theoretically fits at 8.9 GB weights plus cache. But perplexity degradation destroys reasoning quality. The model becomes unreliable for tasks you'd actually want 20B parameters for. Minimum viable is 12 GB with Q4_K_S at reduced context.
Q: Why does Ollama show 100% CPU usage when I have a GPU?
Ollama silently falls back to CPU when VRAM is insufficient. Check ollama ps — if it doesn't list your GPU, your quant is too large or your num_ctx is too high. Reduce both until GPU appears. This is Ollama's most confusing behavior; we cover it in depth in our Ollama review.
Q: Is GPT-OSS-20B better than Llama 3.1 70B quantized?
Different tradeoffs. Llama 3.1 70B Q4_K_M needs 40 GB+ VRAM — multiple GPUs or cloud rental. GPT-OSS-20B Q4_K_M fits single 16 GB cards. It delivers comparable reasoning quality on math and code benchmarks. For local operation without multi-GPU complexity, GPT-OSS-20B wins. For maximum capability regardless of hardware, 70B models still dominate.
Q: What's the difference between unsloth and bartowski GGUF conversions? Unsloth optimizes for llama.cpp performance with custom quantization kernels. Bartowski prioritizes perplexity preservation, often at slight speed cost. We tested unsloth for this guide. Either works. But don't mix quants from different converters in the same workflow.
Q: Will OpenAI release larger OSS models?
They haven't committed to a roadmap. GPT-OSS-120B was rumored for late 2025 but didn't materialize. Treat GPT-OSS-20B as potentially the only Apache 2.0 release. The license terms matter more than future promises.