Hardware Review
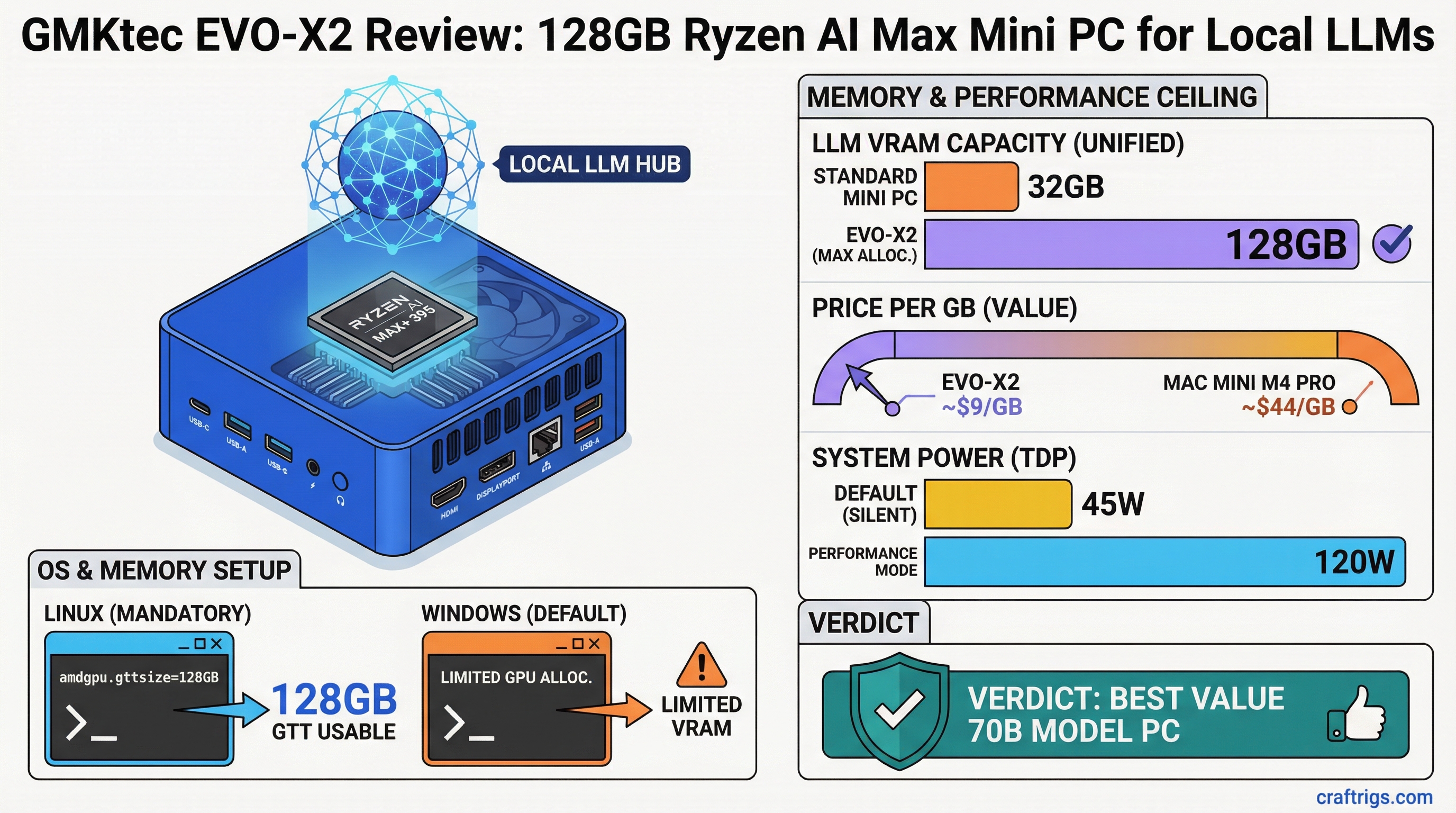
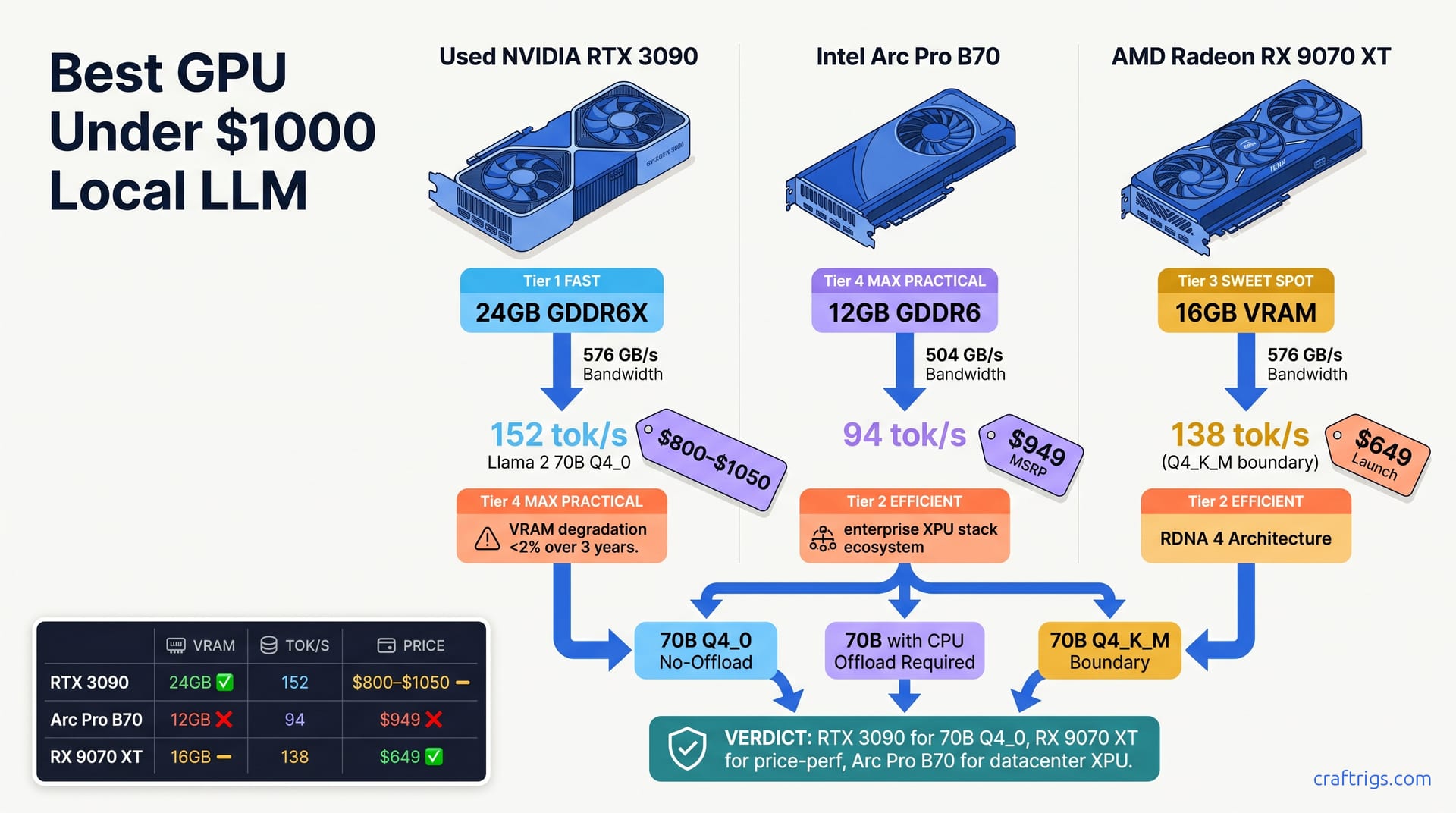
GPU Under $1000: RTX 3090 vs Arc Pro B70 vs RX 9070 XT for Local LLMs
RTX 3090 used, Arc Pro B70 ($949), and RX 9070 XT ($649) compared: real tok/s benchmarks, cost-per-token math, and ecosystem support for local LLM inference.
best-gpu-under-1000rtx-3090-localrx-9070-xt-benchmark
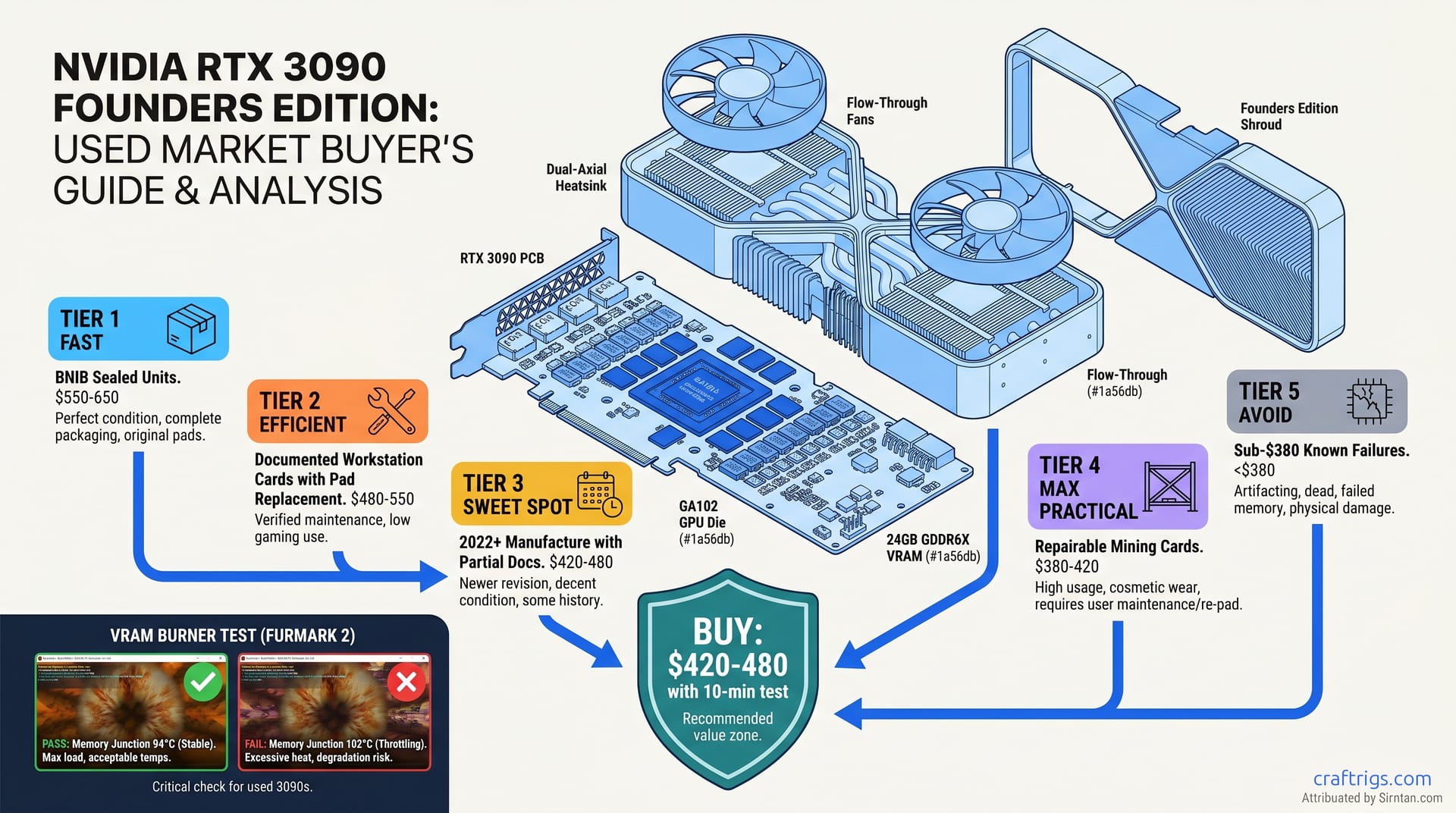
![RTX 5060 Ti 16GB LLM Verdict: What April 16 Reviews Tell Local AI Users [2026]](/images/rtx-5060-ti-16gb-llm-verdict-what-april-16-reviews-tell-local-ai-users/rtx-5060-ti-16gb-llm-verdict-what-april-16-reviews-tell-local-ai-users-diagram.jpg)
![RTX 5060 Ti 16GB Local LLM Review: Real Inference Results [2026] — diagram](/images/rtx-5060-ti-16gb-local-llm-review/rtx-5060-ti-16gb-local-llm-review-diagram.jpg)

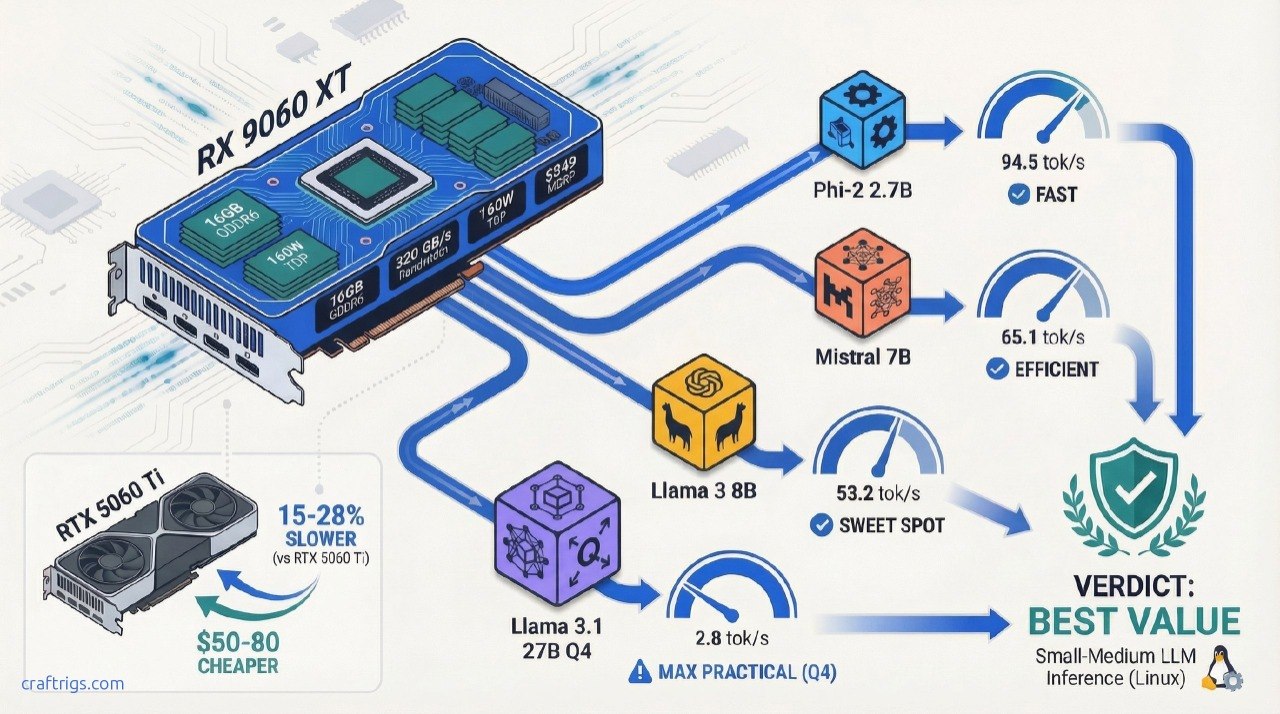








![GMKtec EVO X2 Review: 96GB Unified Memory for Local LLMs [Honest Verdict]](/images/auto-hero/gmktec-evo-x2-review-local-llm.jpg)
![Intel Arc B580 12GB Local LLM Review: Budget GPU, Real Performance [2026]](/images/auto-hero/intel-arc-b580-review-local-llm.jpg)



![LM Studio Review: Best GUI for Local LLMs in 2026 [Tested]](/images/auto-hero/lm-studio-review-2026.jpg)







![RTX 5060 Ti 16GB Review: Best Budget LLM GPU at $429 [2026]](/images/auto-hero/rtx-5060-ti-16gb-review-local-llm.jpg)


![RTX 5070 Ti Review: The 16GB GPU That Finally Closes the VRAM Gap [2026 Tested]](/images/auto-hero/rtx-5070-ti-review-local-llm.jpg)