Fix Guide
AMD GPU on Windows with Ollama: Use Vulkan Instead of ROCm
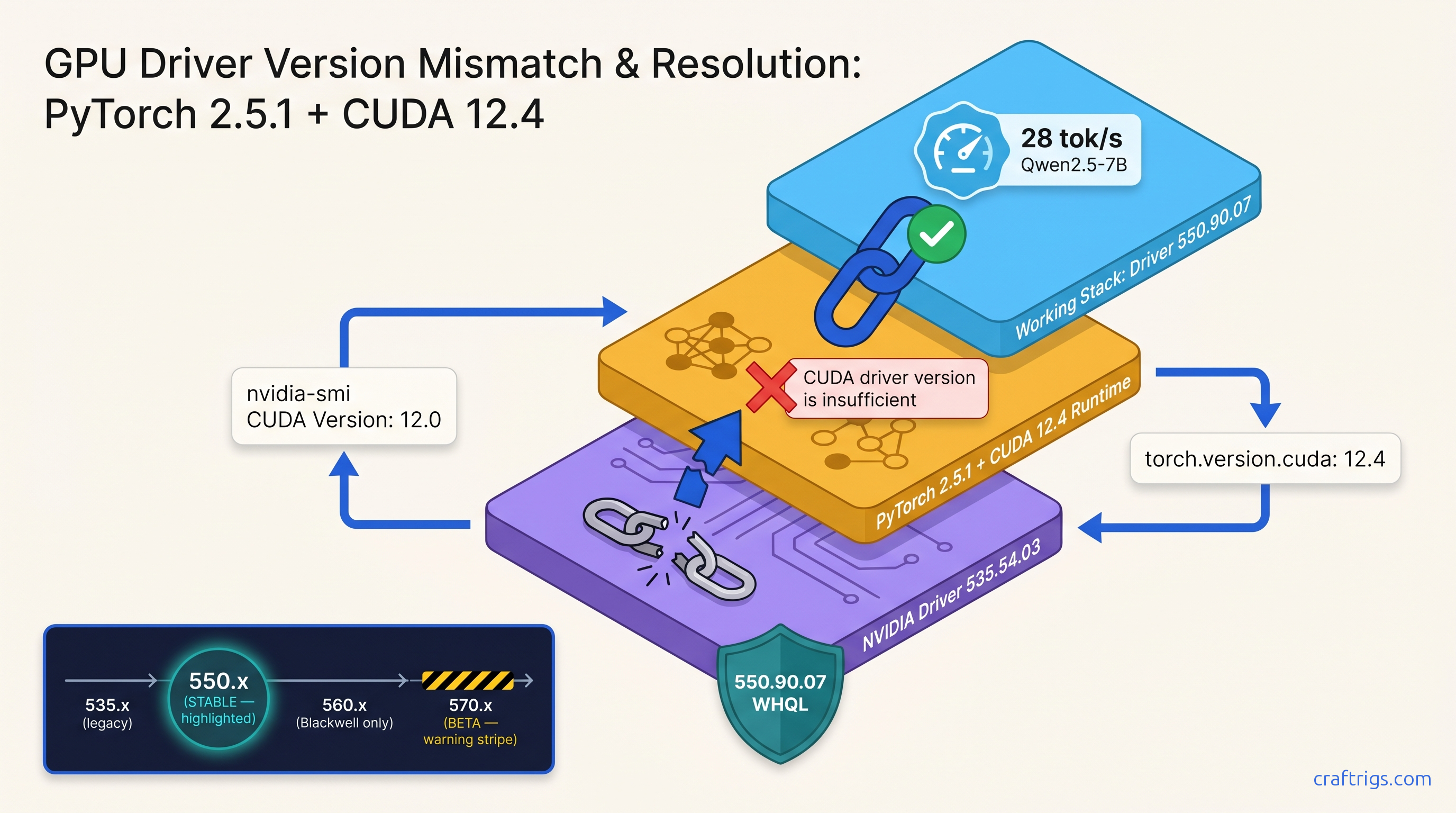
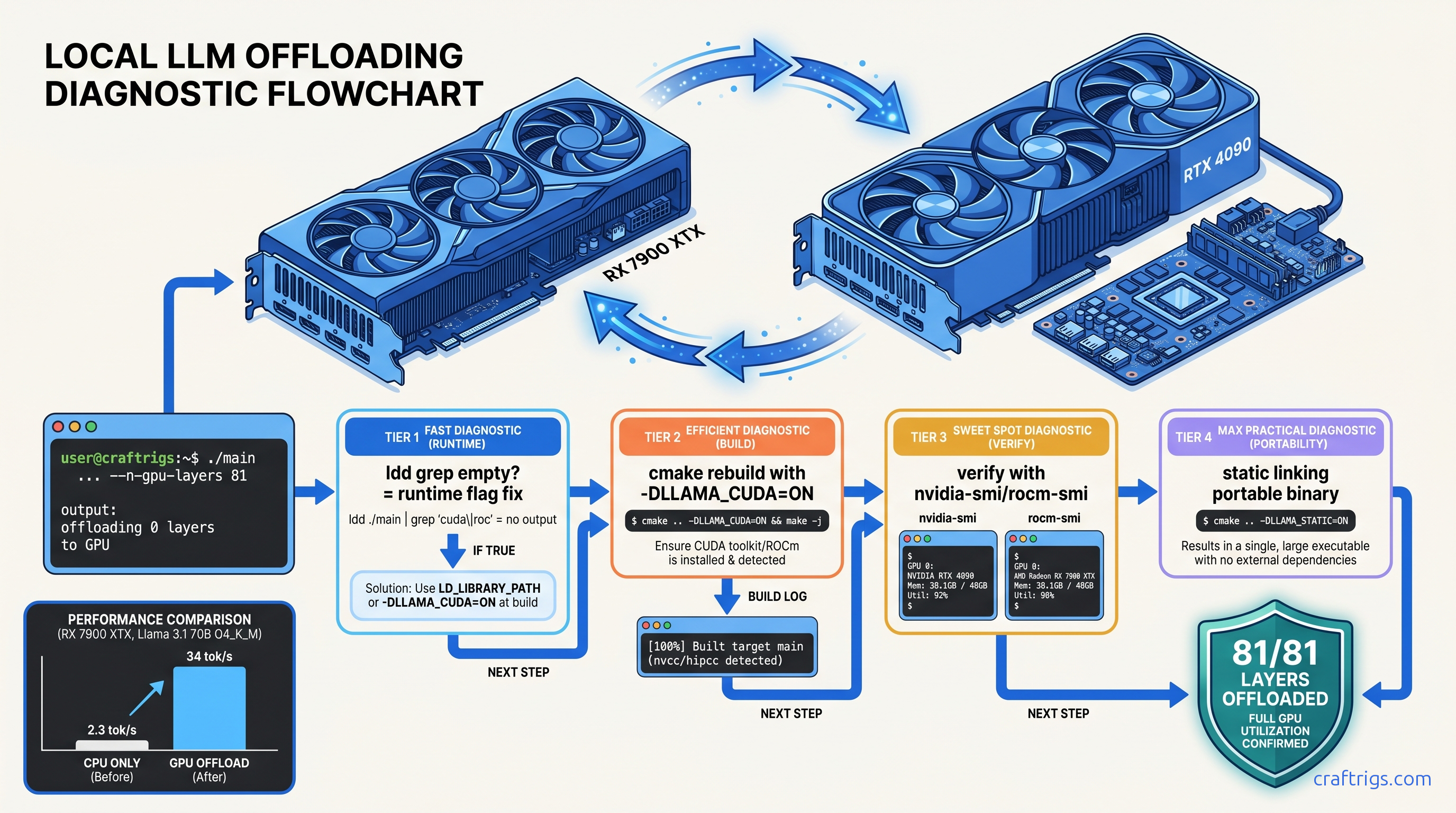
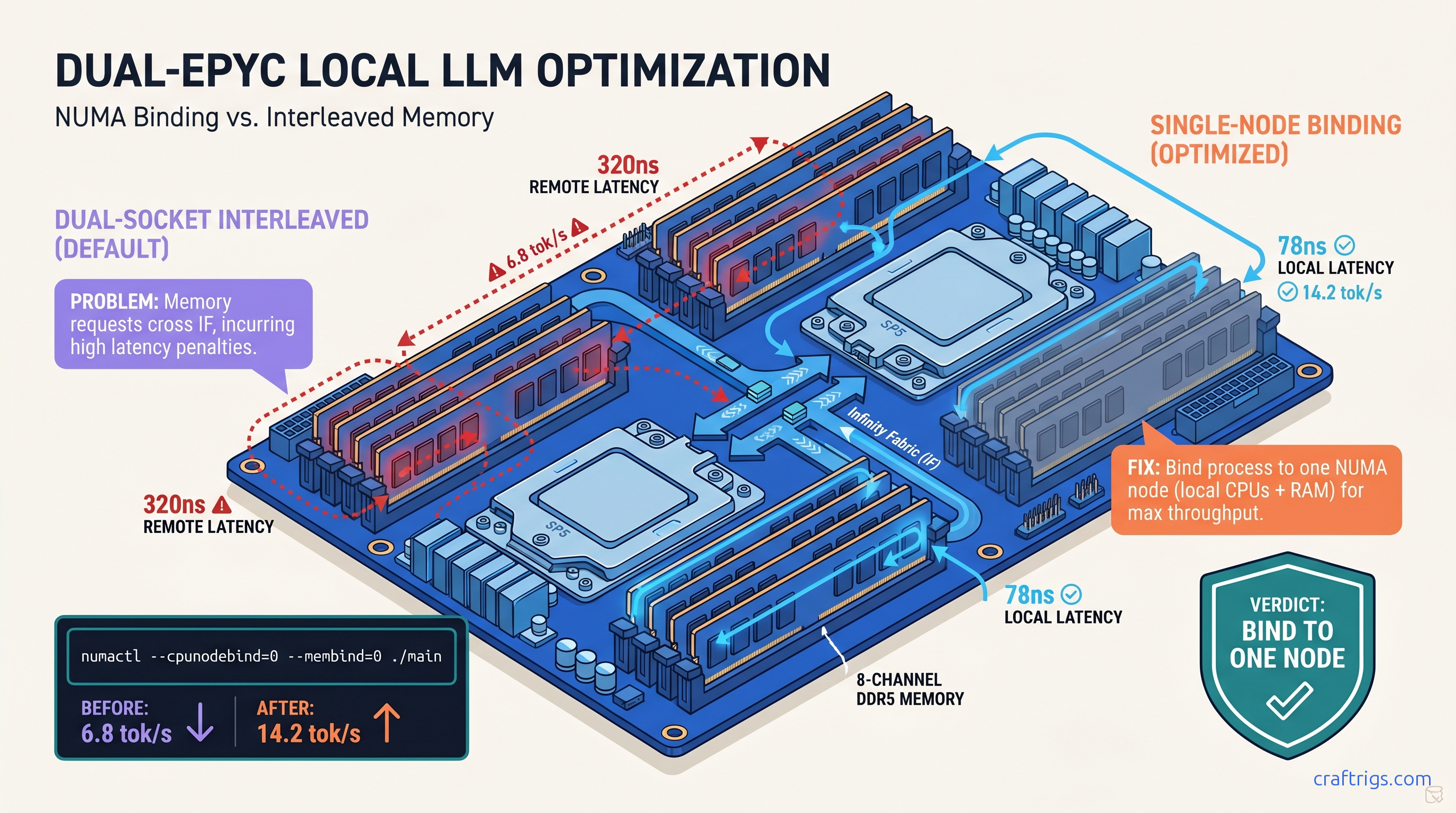
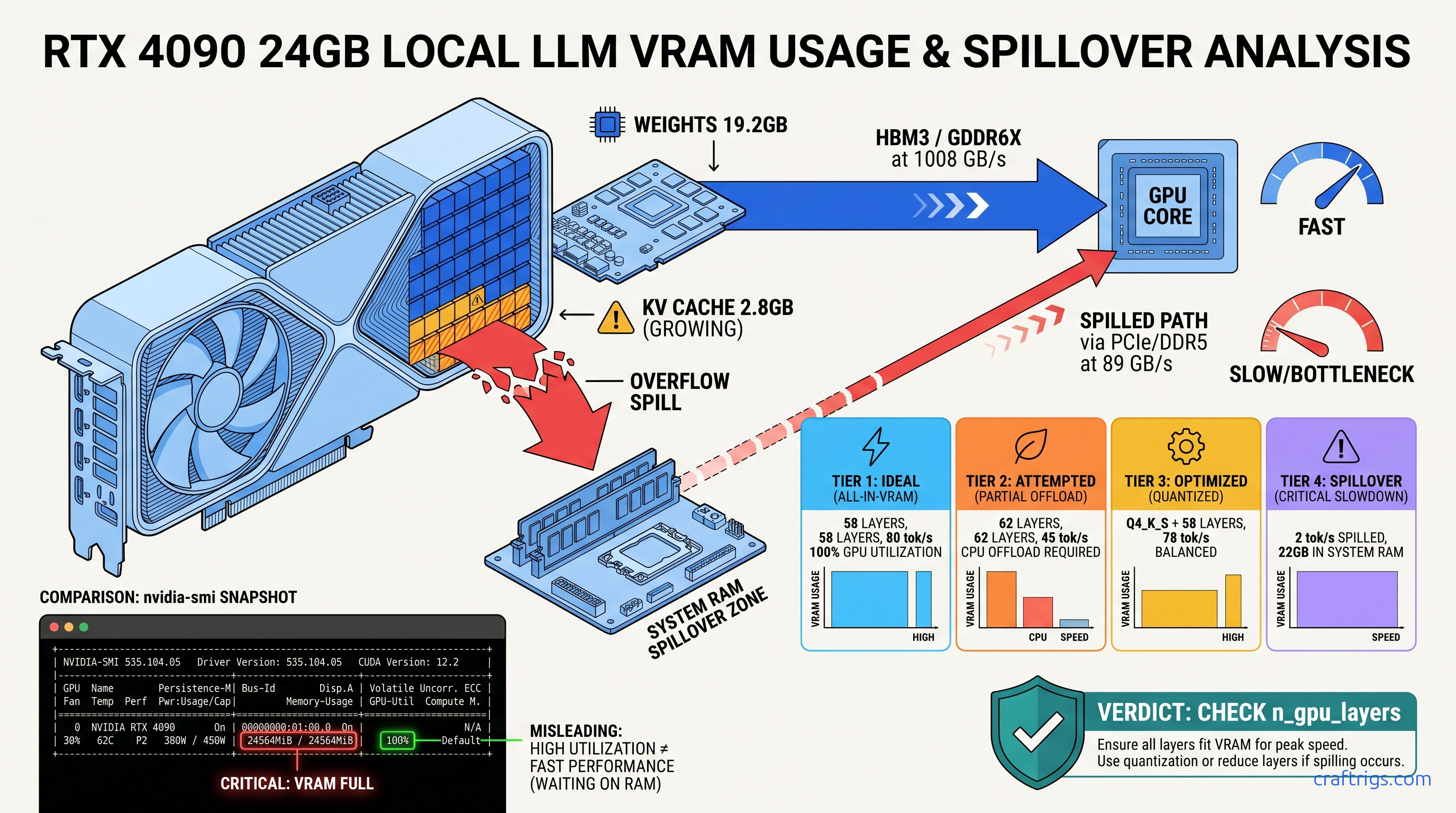
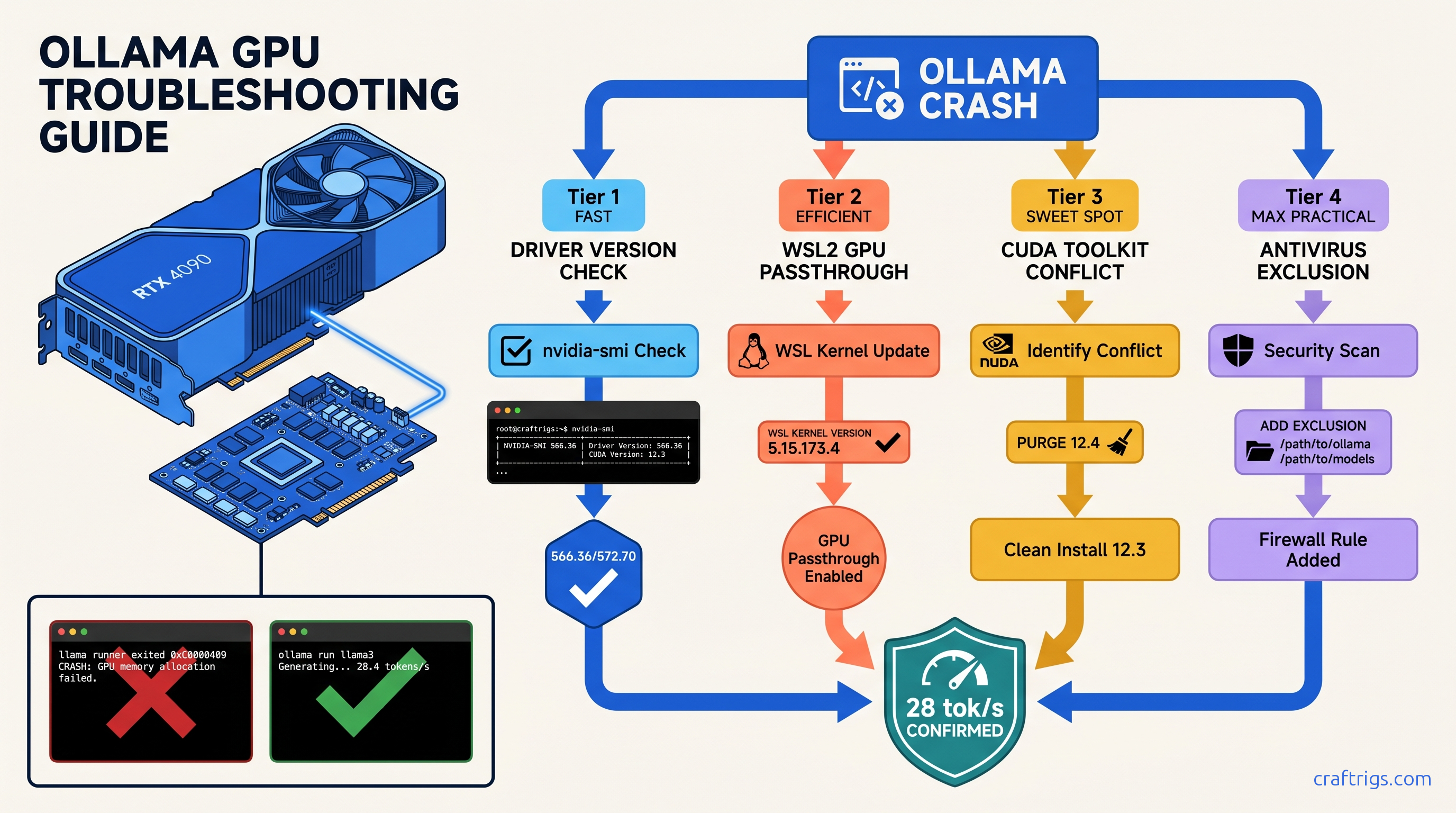
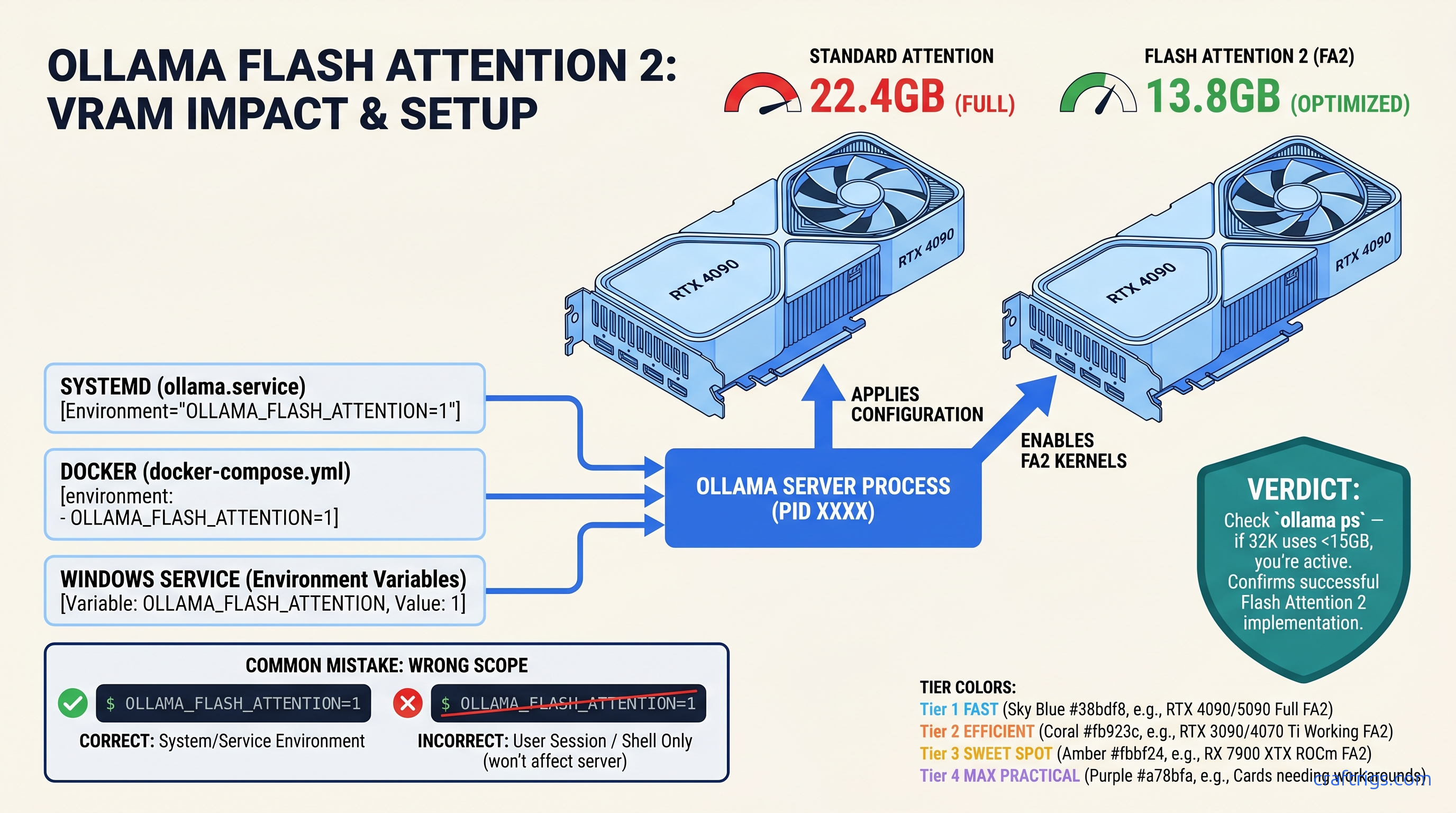
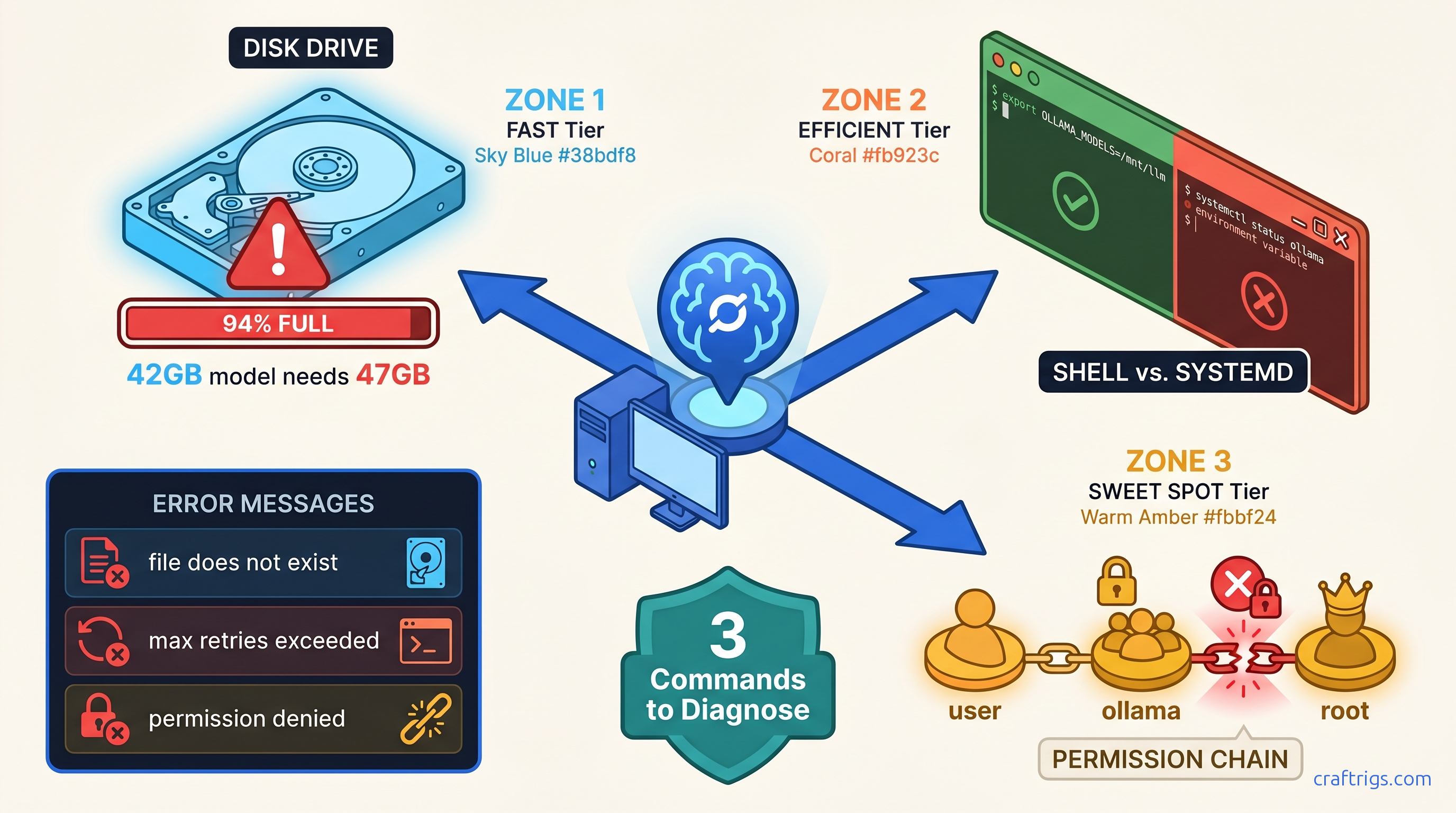
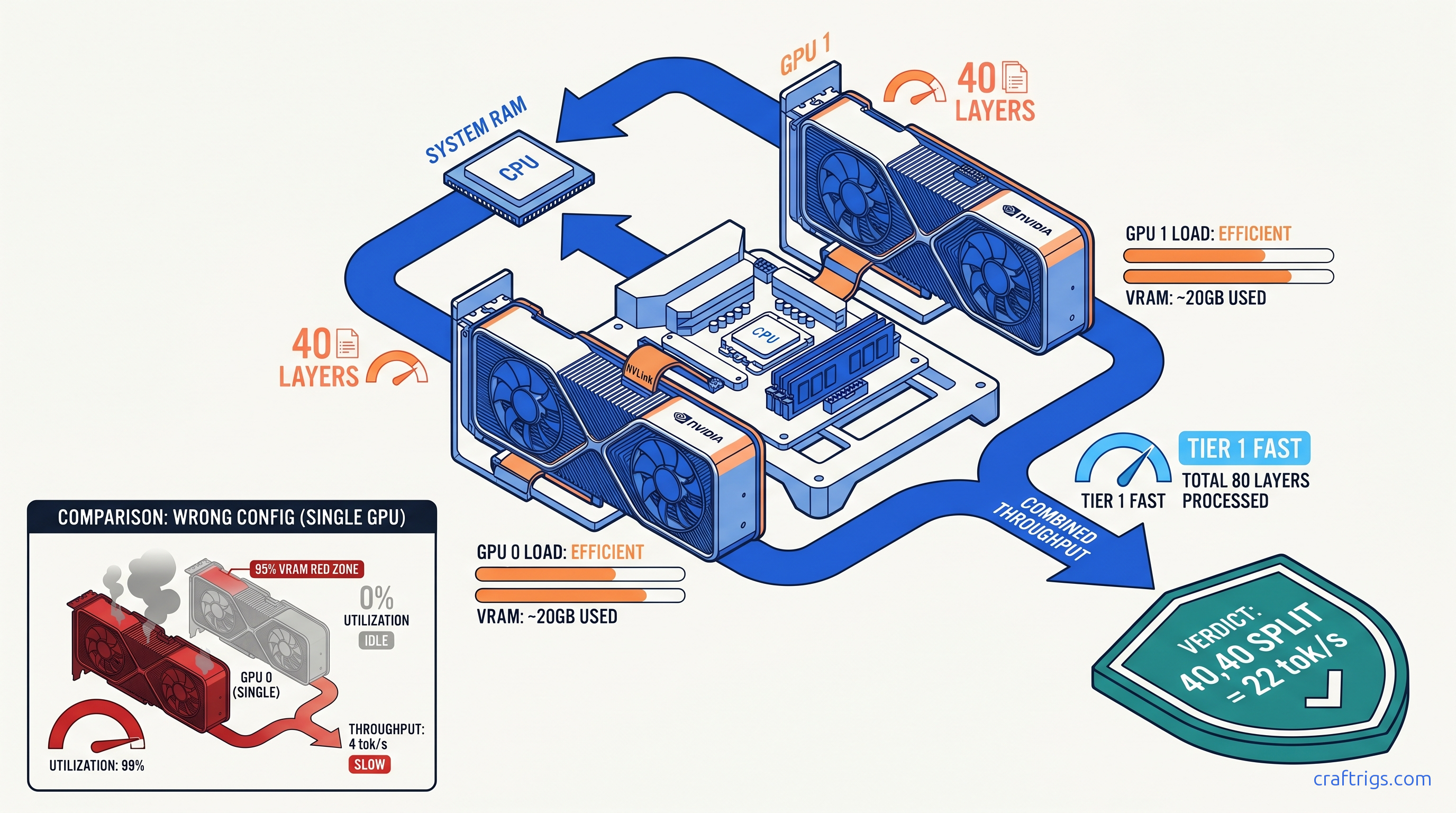
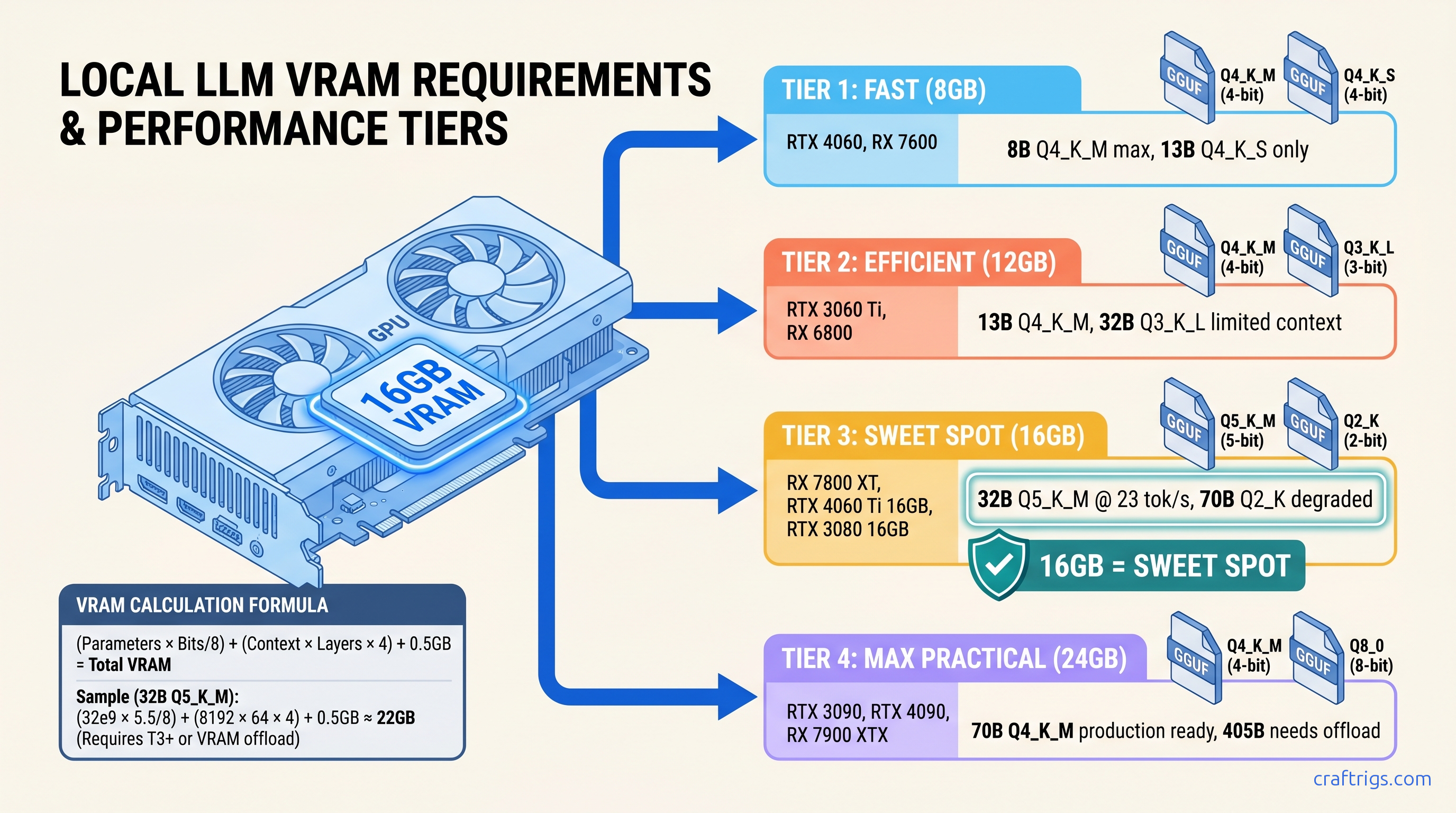
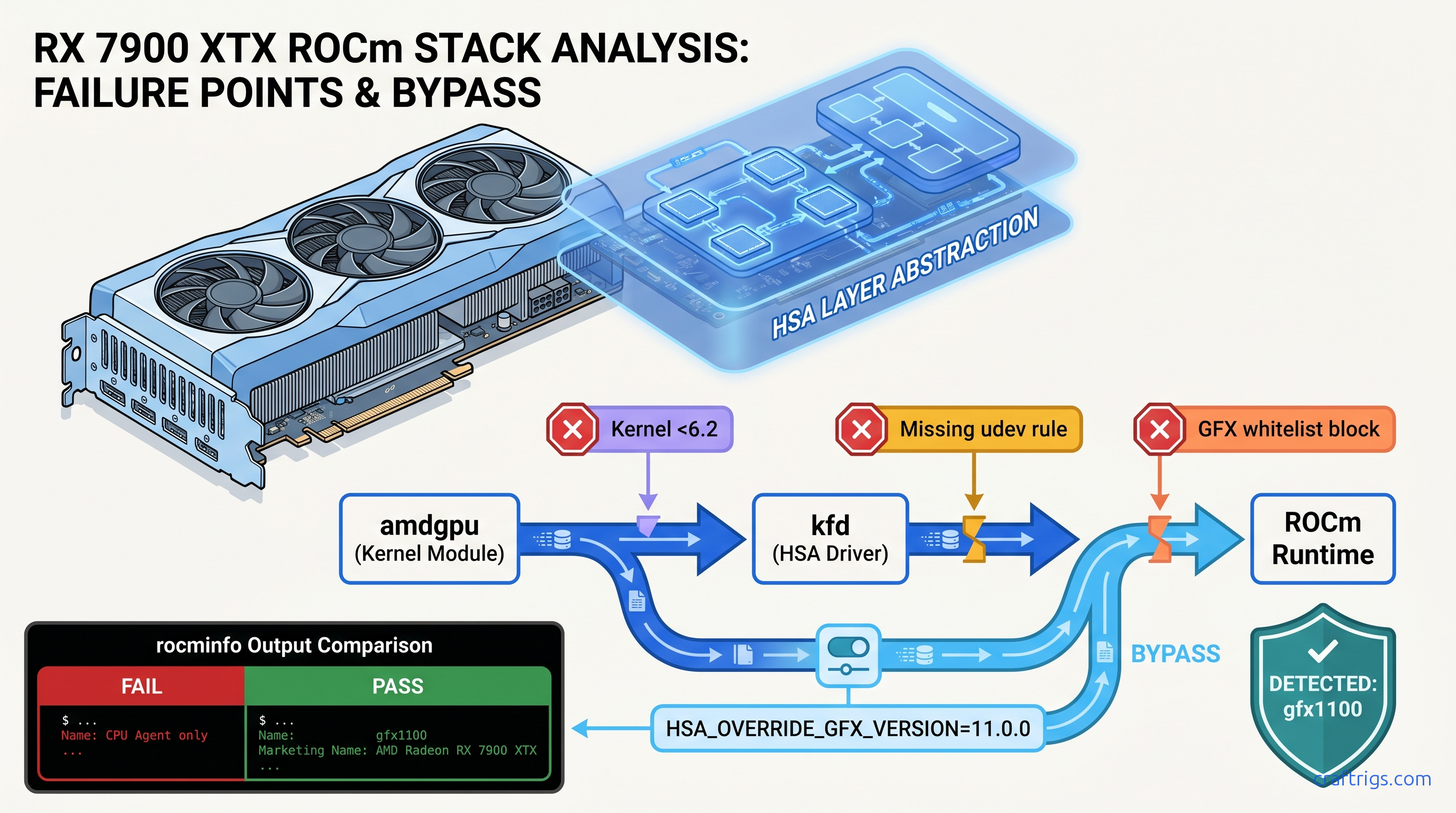
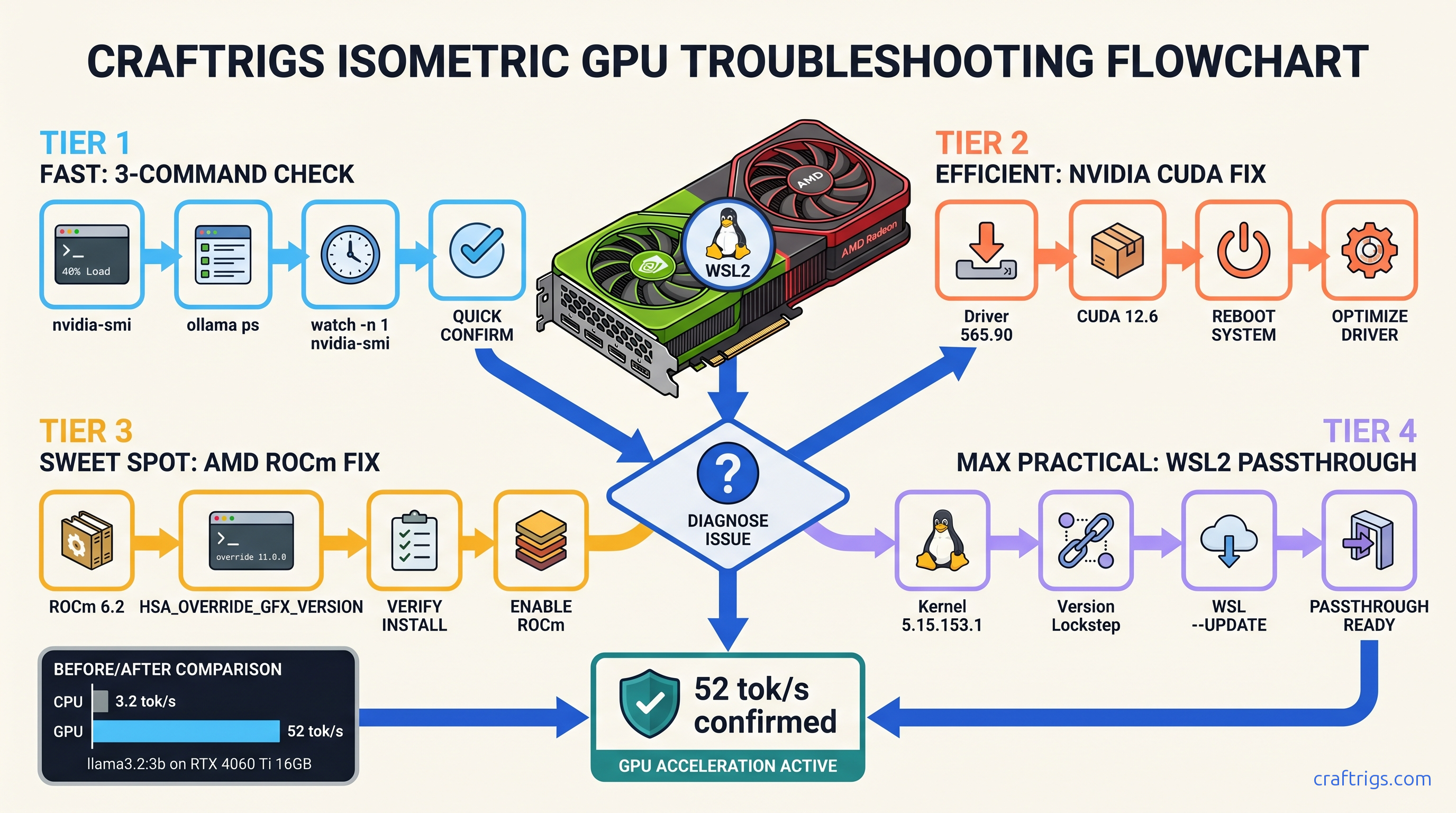
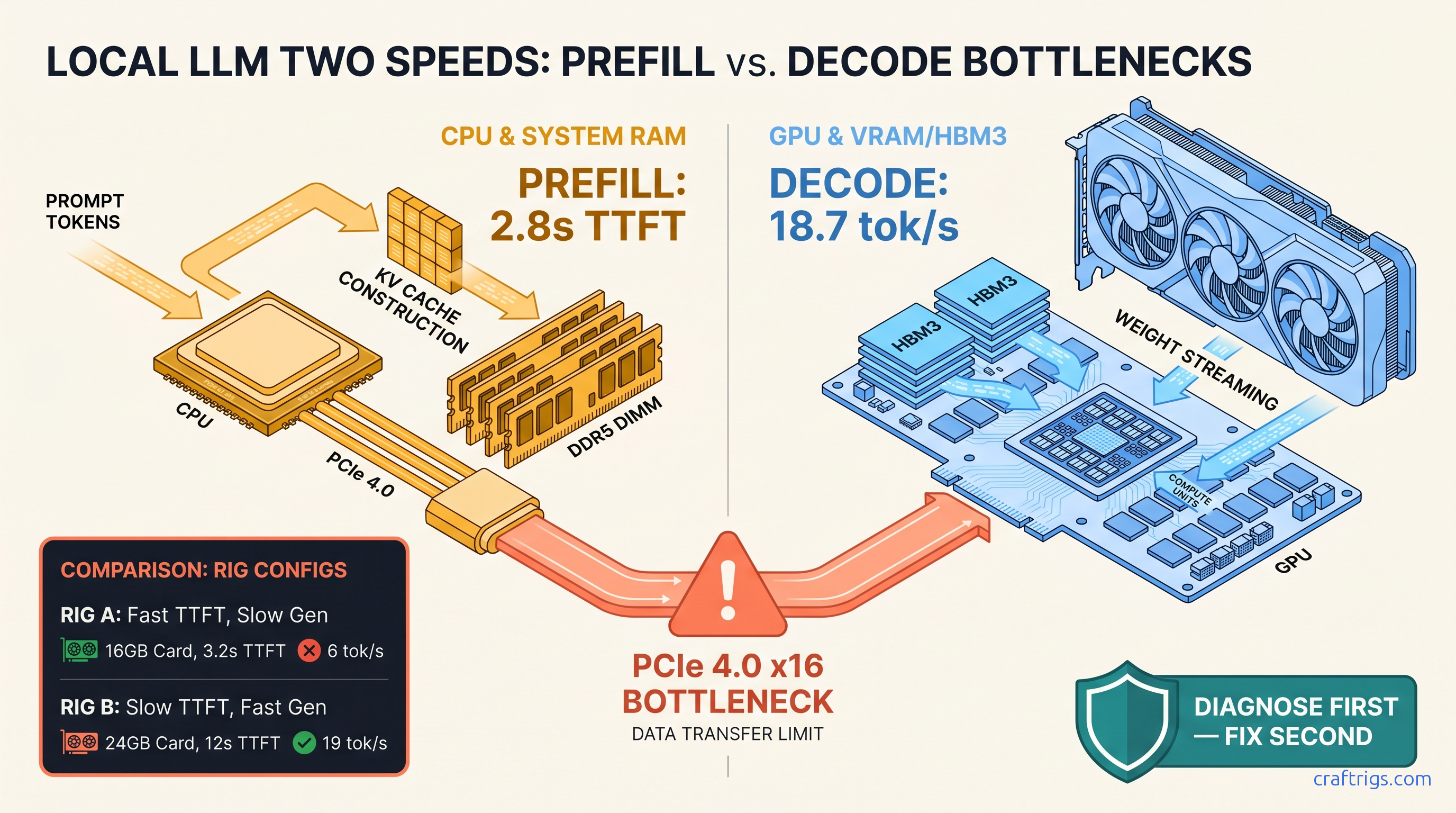
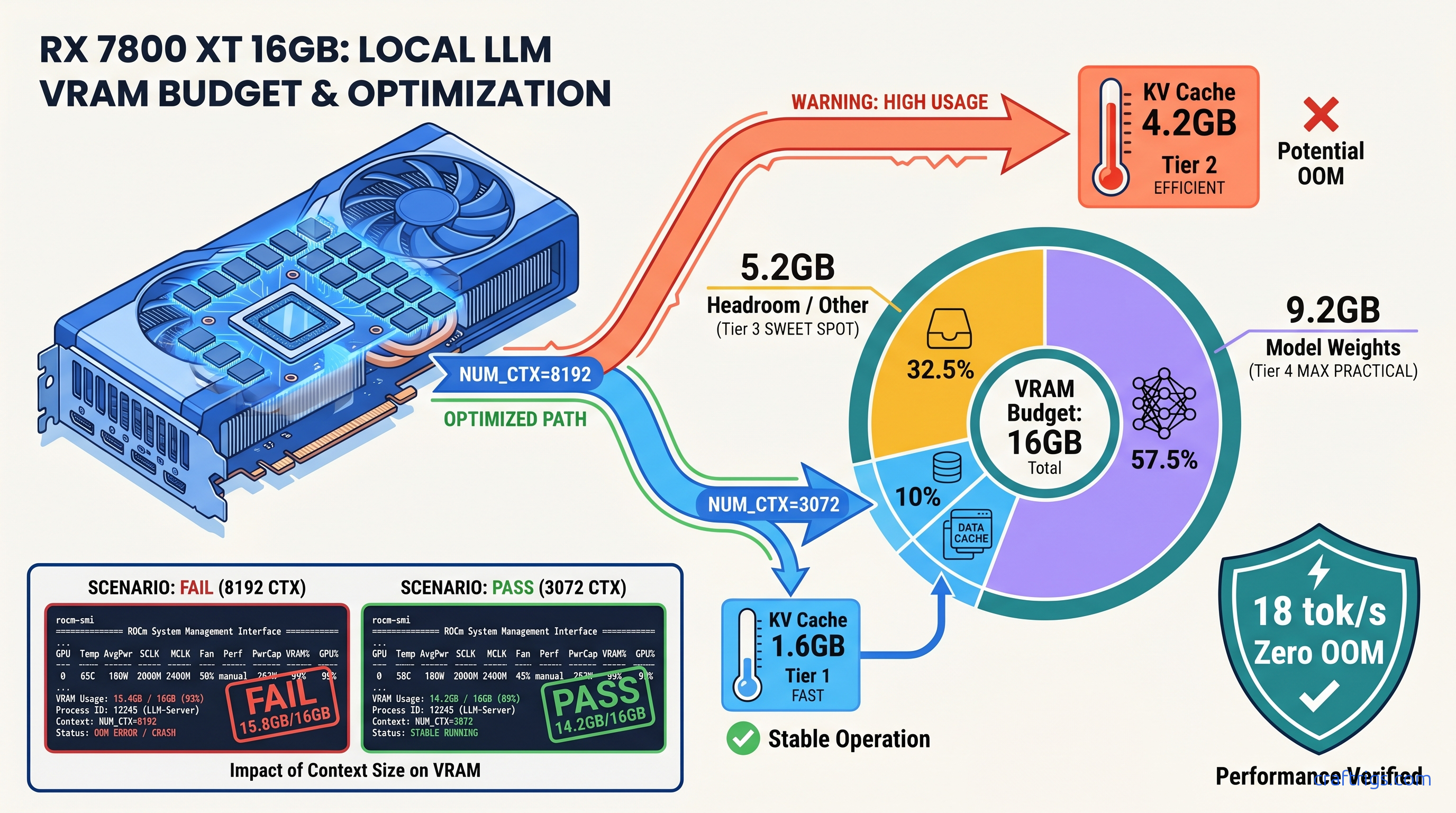
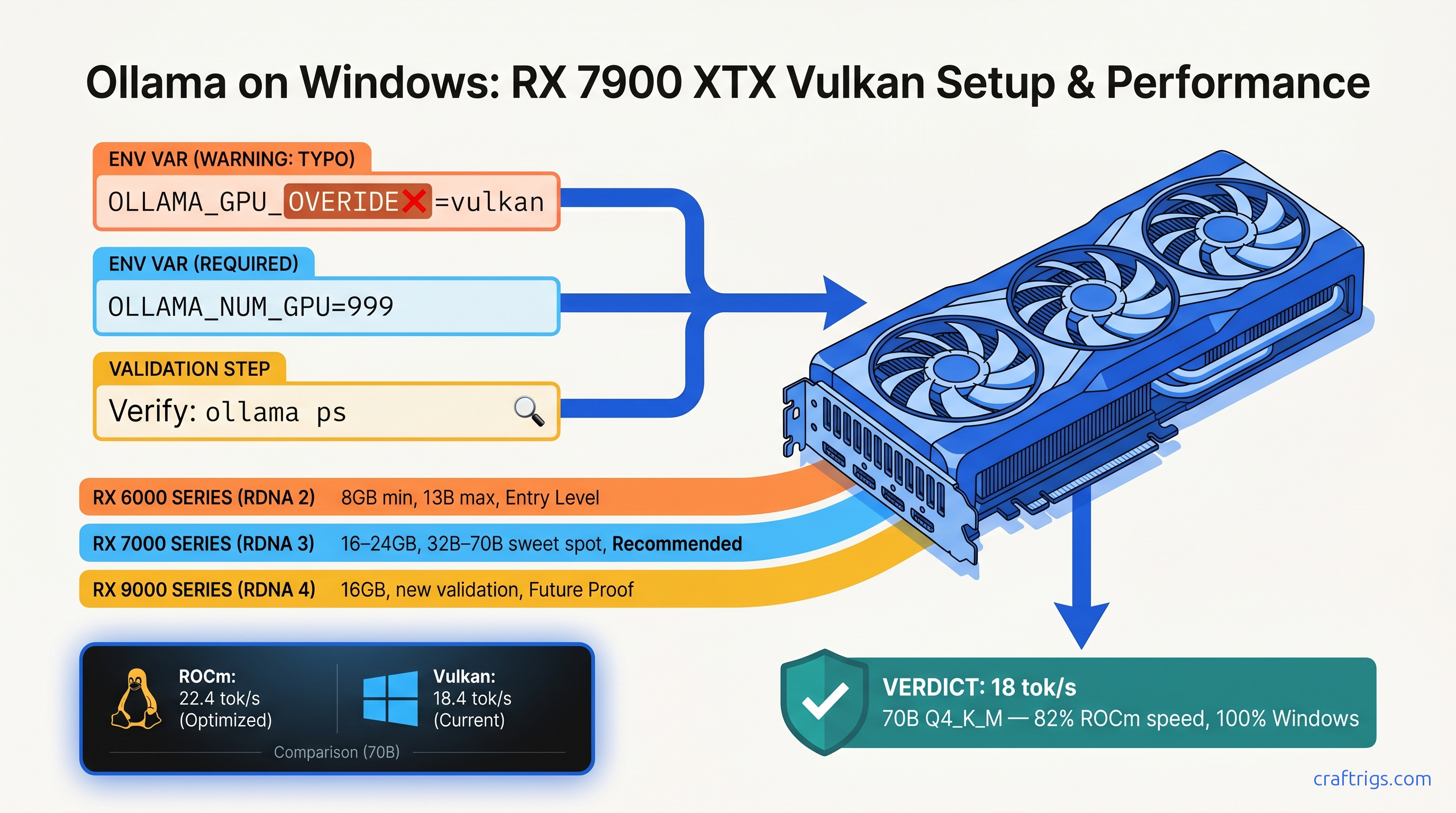
ROCm doesn't run on Windows—your RX 7900 XTX sits idle at 4 tok/s. Force Vulkan backend: 18 tok/s on 70B models. Requires typo env var, Adrenalin 24.12.1+.
ollamaamd gpuvulkan