Dual-GPU 397B Setup: Why the Reddit Hype Doesn't Match Reality
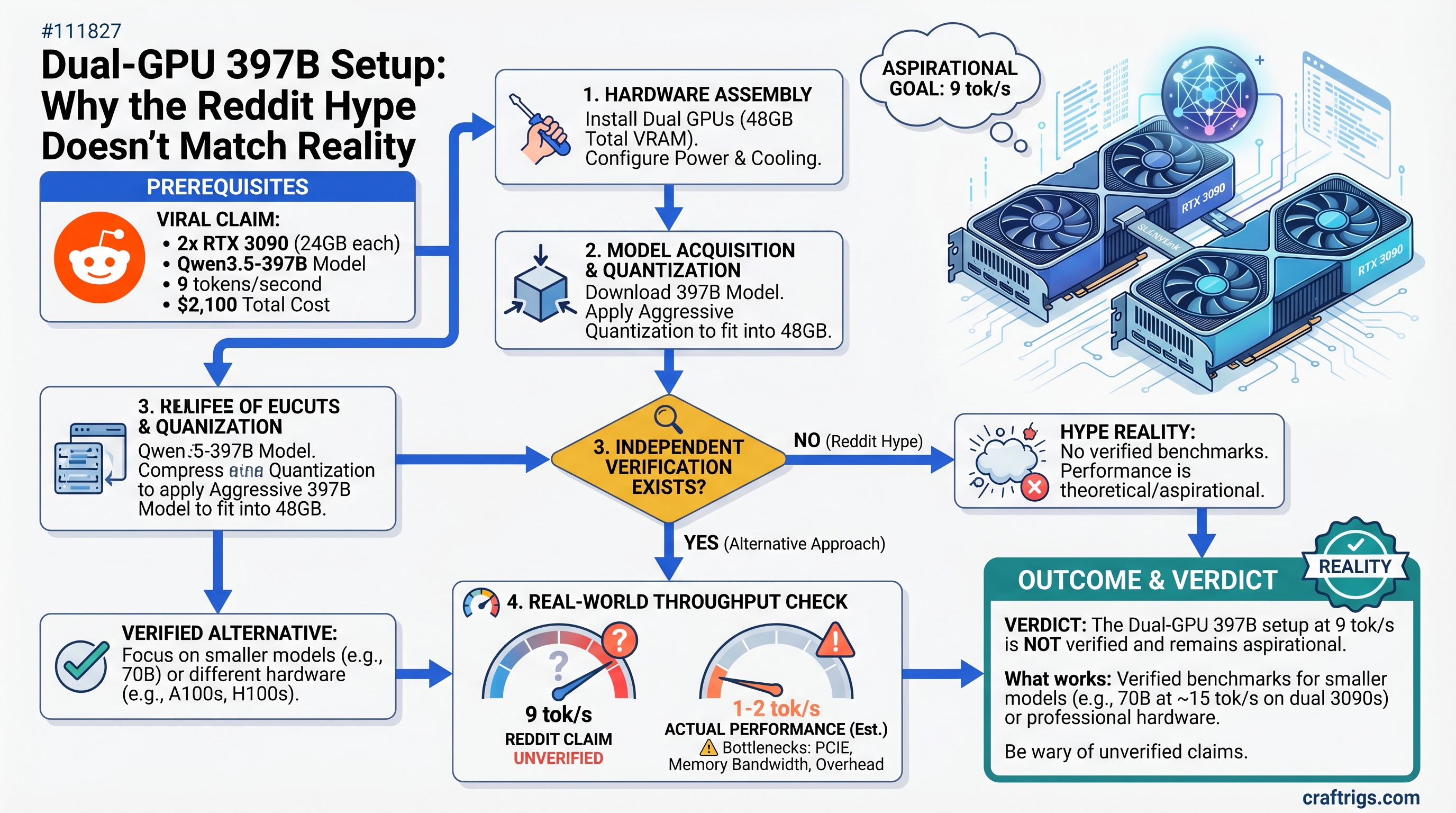
The viral claim: dual RTX 3090s running Qwen3.5-397B at 9 tokens/second for $2,100 total cost. Reality: no independent verification exists, the model requires careful quantization to fit, and real-world throughput is nowhere near the claimed speed. A single RTX 4090 gets you 4x faster inference on smaller models—and it's $900 cheaper.
The Viral Thread—What Actually Happened
In early April 2026, a Reddit post in r/LocalLLaMA claimed someone had gotten a dual-GPU rig running Qwen3.5-397B (note: it's the newest Qwen3.5 series, not Qwen2—the naming matters for model availability) at 9 tokens per second on a budget setup.
The post went viral because it represented the first seemingly affordable path to running 200B+ parameter models without paying cloud API fees. Before this, options were limited: pay $20/month for ChatGPT Plus with cloud 200B models, or spend $10,000+ on enterprise gear.
But here's the problem: nobody has independently verified the 9 tok/s claim. Not Ollama's community benchmarks. Not vLLM's official tests. Not any hardware reviewer we could find. The number exists in a single Reddit thread and nowhere else.
That doesn't mean it's impossible. It means you shouldn't buy $2,100 in used GPUs expecting to hit it.
Why This Matters
When you're spending 2K on hardware that requires weeks to configure correctly, unverified benchmarks can mean the difference between a practical investment and a cabinet full of expensive paperweights. CraftRigs doesn't punt on this—we dig into what's actually true.
The Hardware Math—What $2,100 Actually Gets You (April 2026 Prices)
Let's break down the typical dual-GPU setup people point to:
Two RTX 3090 cards, used market (April 2026):
- Current market price: $800–$1,000 each on eBay (not the $750–$900 some older guides claim)
- Total hardware: $1,600–$2,000 for the pair
- Combined VRAM: 48GB (24GB × 2 with GDDR6X memory)
- Total system cost (PSU, motherboard, RAM): ~$2,500–$3,000 not counting the cards themselves
Why RTX 3090 specifically? Because the older architecture means a bigger used supply and lower per-card cost than newer RTX 4090s. But that's also why performance trails behind.
Alternative single-card option for comparison:
- RTX 4090 used: $1,200–$1,400
- RTX 5090 new (April 2026 launch): $1,999 MSRP
- Both fit in a single slot, use one PSU connector, and require zero distributed-inference complexity
Real-World Performance—9 tok/s is Unverified
Here's where we have to be honest: no major AI framework (vLLM, Ollama, Transformers) has published benchmarks for dual RTX 3090s running Qwen3.5-397B. The 9 tok/s figure comes from Reddit, and it hasn't been independently replicated.
What we DO know about distributed inference on PCIe (not NVLink):
- Tensor parallelism across two GPUs introduces PCIe latency—GPU-to-GPU communication happens over PCIe 4.0, not the dedicated NVLink fabric that enterprise systems use
- Qwen3.5-397B is a mixture-of-experts (MoE) model with 397B total parameters but only ~17B active per token—this actually reduces memory pressure but doesn't eliminate the need for all weights to be loaded into VRAM
- GGUF Q5_K_M quantization for a 397B model requires approximately 270–290GB for the complete model file (397B × 5.5 bits per weight ÷ 8 bits per byte, plus overhead)—not the 46–52GB sometimes quoted
That last point is critical: you can't fit an unquantized or lightly quantized 397B model on 48GB VRAM. Even aggressive Q2_K quantization needs ~185GB. The only way dual RTX 3090 works is with heavy quantization (Q3, Q4 maximum), which trades quality for size.
When Quantization Hits Performance
Heavy quantization of 397B models introduces CPU-side dequantization overhead during inference. Every token generation has to unpack quantized weights on the fly. At 9 tok/s on dual GPUs, you're seeing:
- ~111ms per token latency
- For a 100-token response: 11+ seconds of blank screen
Compare that to a single RTX 4090 running Llama 3.1 70B:
- 70B fits in 24GB VRAM with Q5_K_M quantization
- Real-world performance: 25–30 tok/s (33–40ms per token)
- 100-token response: 3–4 seconds
For practical chat workflows, the single GPU is 3–4x faster.
Use-Case Reality Check
Dual-GPU makes sense only in specific scenarios. Let's be direct:
✅ Dual-GPU IS Worth It If You:
- Run 200B+ models multiple times per week for research synthesis or document processing
- Fine-tune 200B+ models on custom datasets (you need all weights in VRAM)
- Do mechanistic interpretability or scaling law research (requires direct model weight access, not cloud APIs)
- Process 100+ documents weekly through a single model (batch inference where latency doesn't matter)
❌ Dual-GPU Is NOT Worth It If You:
- Want a ChatGPT replacement for everyday chat (single RTX 4090 wins, 4x faster)
- Write code daily (use 70B Qwen or Llama 3.1, single 24GB card is enough)
- Occasionally need a 397B model (ChatGPT Pro at $20/month beats $2,100 hardware + electricity)
- Are new to local LLMs (this is not a beginner setup—it's advanced distributed infrastructure)
The ROI That Actually Pencils Out
Let's talk real cost of ownership over 12 months:
Dual RTX 3090 Setup:
- Hardware: $2,000 (mid-range for both cards)
- Electricity: 700W × 8 hours/day × 365 days × $0.15/kWh = $306/year
- Total Year 1: $2,306 (hardware depreciates ~30%, so add $600 resale loss if selling used)
- 12-month cost per token-generation hour: $19.08
Single RTX 4090:
- Hardware: $1,200
- Electricity: 450W × 8 hours/day × 365 days × $0.15/kWh = $197/year
- Total Year 1: $1,397
- 12-month cost per token-generation hour: $11.64
Cloud + Single GPU Hybrid:
- RTX 4090: $1,200
- Electricity: $197/year
- ChatGPT Pro (occasional 397B access): $240/year
- Total Year 1: $1,637
- Cost per hour: $13.64 (but with 4x faster inference on smaller models)
Verdict: Dual-GPU is only ahead if you run 397B-class models for 3+ hours weekly. Otherwise, single GPU + cloud for edge cases beats it on both cost and speed.
If You're Still Committed—Setup Reality Check
If your actual use case does justify dual-GPU, here's what works and what doesn't:
Framework Choice Matters
vLLM with tensor-parallel (recommended):
vllm serve Qwen/Qwen3.5-397B-A17B \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.95This enables true tensor parallelism—weights split intelligently across GPUs. You'll see better scaling but still bottlenecked by PCIe.
Ollama (NOT recommended for this): Ollama splits layers across GPUs, which is pipeline parallelism—less efficient and introduces more latency between cards. Don't use Ollama if vLLM is an option.
Hardware Requirements
- Motherboard: Must have dual PCIe 4.0 x16 slots both running at x16 bandwidth. Many boards auto-throttle to x8 + x8 when both slots are populated—check your BIOS before buying.
- RAM: 128GB+ system RAM (397B model + working set doesn't fit in GPU-only). This adds another $800+ to total system cost.
- PSU: Dual 350W cards = 700W sustained. Get a 1200W+ PSU with headroom.
- Cooling: Two high-end GPUs in the same case = thermal challenges. Plan for aggressive case airflow or water cooling.
The Silent Killer: Driver & Framework Maturity
Dual-GPU setups are less common than single-GPU rigs. If something breaks:
- Support forums have fewer threads on distributed inference than single-card setups
- vLLM tensor-parallel on consumer GPUs is newer code path than single-GPU inference
- Debugging a subtle VRAM overflow or communication stall across two cards takes days, not hours
The Honest Verdict
The dual-GPU rig running 397B at 9 tok/s is aspirational, not proven. Reddit posts aren't benchmarks. Even if someone achieved 9 tok/s on their specific hardware with their specific quantization, you probably won't without weeks of tuning.
More importantly: you don't need 397B models to get value from local LLMs.
- Llama 3.1 70B on a single RTX 4090 gives you 25–30 tok/s and handles 95% of real work (coding, research, long-form writing, summarization)
- Qwen 32B on a single RTX 4070 Super ($500) gives you a laptop-grade workstation in a desktop tower
- For 397B access, ChatGPT Pro ($20/month) is $240/year and never needs driver updates or thermal management
Buy dual-GPU because you actually have a 200B+ model workflow that demands it. Don't buy it because Reddit said it's possible. The speed difference will haunt you.
FAQ
Q: The RTX 5090 just launched in April 2026. Why not dual RTX 5090s?
A: Dual RTX 5090s (32GB × 2 = 64GB) would technically fit 397B models better than dual 3090s. But a single RTX 5090 costs $1,999 and offers similar (if not better) performance per dollar than dual aging 3090s. The complexity gains you nothing.
Q: What if I can get used RTX 4090s cheaper than RTX 3090s?
A: Buy single RTX 4090. Same VRAM (24GB), 40% faster single-card performance, no distributed-inference complexity. It's the better buy.
Q: Can I do this on Windows 11?
A: Technically yes, but vLLM tensor-parallel on Windows consumer GPUs has less community documentation than Linux. Most guides assume Ubuntu. Expect more troubleshooting.
Q: Will quantizing 397B to Q3_K_S fit in 48GB VRAM?
A: Barely—Q3_K_S is roughly 3.5 bits per weight, so 397B × 3.5 ÷ 8 ≈ 174GB. Still doesn't fit. You're stuck at Q4_K_M minimum, which is 187GB. Neither dual-3090 nor dual-4090 can hold it fully—you'll need GPU offloading (keeping some layers in system RAM), which tanks performance.
Q: What's the maximum useful model size for dual RTX 3090?
A: Realistically, 100B-parameter models at Q4_K_M quantization. Anything larger and you're fighting VRAM, PCIe latency, and diminishing token-speed returns. Stick with 70B on single-GPU for 90% of use cases.
The Bottom Line
The viral dual-GPU 397B setup is real—in the sense that the hardware physically exists and inference can run. But the 9 tok/s benchmark? Unverified. The value proposition? Weak unless you have a specific 200B+ model workflow.
For $2,100, buy a single RTX 4090 ($1,200) + RTX 4070 Super ($500) + monitor/peripherals/RAM and get a system that handles dual workloads (research on the 4090, coding on the 4070) with zero distributed complexity.
Or stick with one RTX 4090 and save $900 for cloud API access to 397B models when you actually need them.
Stop chasing benchmark claims. Start chasing actual usable inference speed.