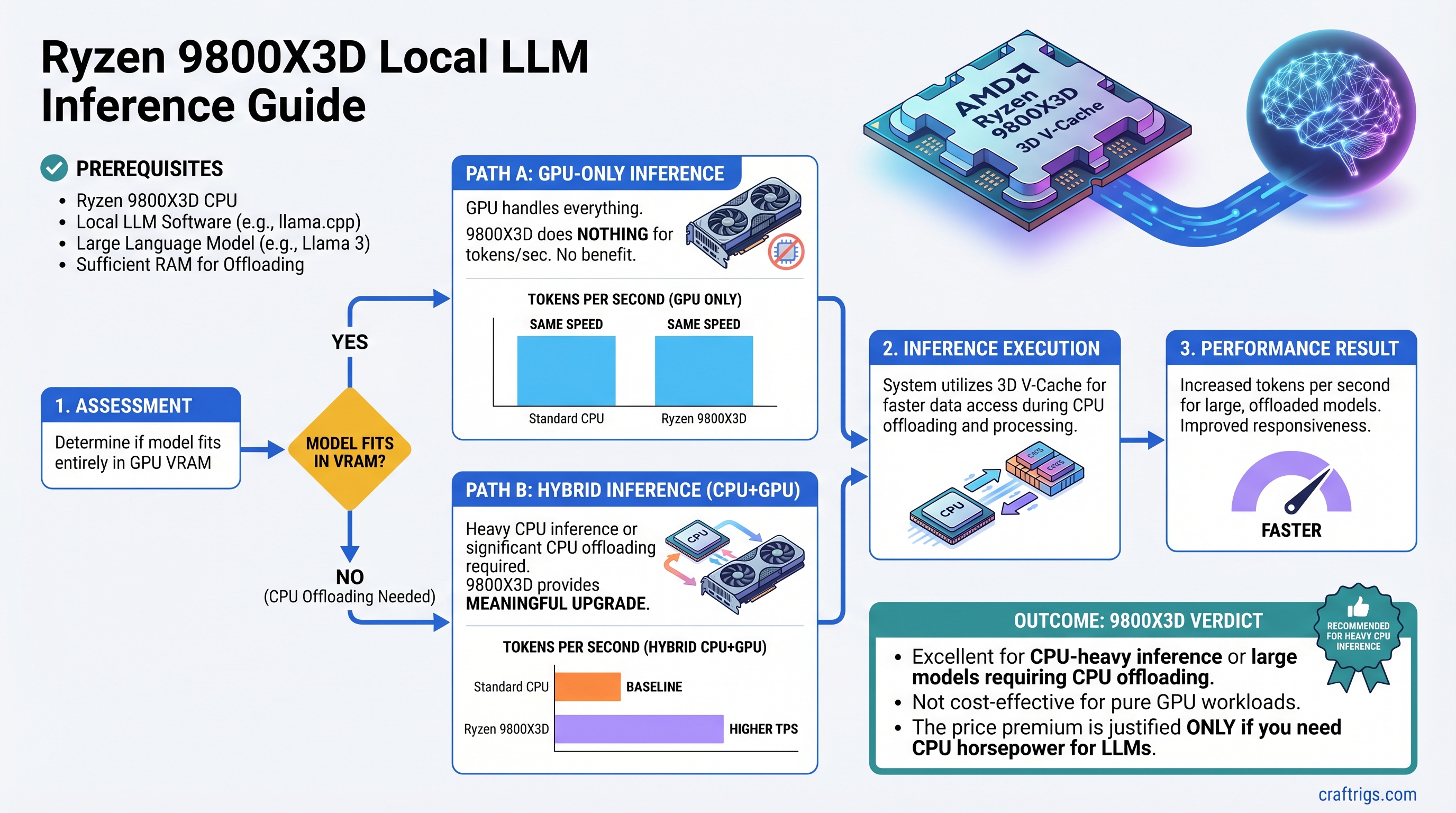
TL;DR: The Ryzen 9800X3D's 3D V-Cache is a meaningful upgrade if you do heavy CPU inference or significant CPU offloading. If your model fits in VRAM and your GPU handles everything, the 9800X3D does nothing for your tokens per second — and the price premium doesn't pay off.
What 3D V-Cache Actually Is
3D V-Cache is AMD's branding for stacked L3 cache. They take standard SRAM cache dies and physically bond them on top of the CPU's compute chiplets. This stacking dramatically increases the total L3 cache without requiring a larger die footprint.
The Ryzen 9800X3D has 96MB of L3 cache. The standard Ryzen 9700X has 32MB. That's 3x more cache available to the CPU cores.
Cache matters because accessing data from cache is much faster than going out to system RAM. L3 cache latency is measured in nanoseconds. DRAM latency is in the range of 60–80 nanoseconds — slower by an order of magnitude. When your CPU is doing work that needs data repeatedly, more cache means fewer expensive RAM trips.
The question for local LLMs is whether the workload benefits from that cache or not.
Why Cache Matters for CPU Inference
During CPU offloading or pure CPU inference, each model layer's weights need to flow through the CPU to do the matrix math. The core operation — matrix-vector multiplication — reads the weight matrix repeatedly across different steps.
With a small enough layer, if the weights fit in L3 cache, the CPU can pull them from cache instead of RAM on repeated access. This is where 3D V-Cache helps: it allows more of the model's weights to stay resident in cache between operations, reducing the number of trips to DRAM.
The KV cache is also relevant here. As context length grows, the KV cache occupies memory. For CPU-side inference, a larger L3 cache can hold more of this working set, reducing latency per token.
Real-world benchmarks on llama.cpp CPU inference show the 9800X3D is consistently 20–40% faster than the standard 9700X at the same clock speeds on CPU-bound inference tasks. For heavier models or longer contexts, the gap can be larger. That's a meaningful difference if CPU inference is your primary workload.
How It Performs on CPU-Offloaded Inference
This is the most relevant scenario for most local LLM users who have a mid-range GPU and are offloading some layers.
When you're offloading 20–40% of a model's layers to the CPU, the CPU side of the inference becomes the bottleneck. The GPU blazes through its layers in milliseconds. The CPU grinds through its layers using RAM bandwidth. The total speed is determined by the slower component.
The 9800X3D doesn't change RAM bandwidth — that's fixed by your memory kit. But it reduces the number of RAM accesses by keeping more data in cache. On a 30B model with significant offloading, expect a 15–30% improvement in CPU-side layer throughput versus a standard 9700X.
Whether that translates into noticeable overall improvement depends on the split. If 80% of layers are on the GPU and 20% are on the CPU, the CPU side contributes only part of the total inference time. The 9800X3D's benefit is real but partially diluted by the fact that the GPU is doing most of the work.
If you're doing 50/50 splits or heavier CPU loads, the improvement is more felt.
Who Should Care About This
The 9800X3D is worth considering if:
- You run models primarily on CPU — no discrete GPU, or a very weak one.
- You have a GPU with 12–16GB VRAM and regularly offload layers for larger models.
- You run models at long context windows where the KV cache grows large enough to stress the CPU.
- You're building a dedicated inference server and CPU performance is part of the spec.
Note
If you're between the 9800X3D and a GPU upgrade with the same budget, the GPU upgrade almost always wins. A jump from 12GB to 24GB VRAM eliminates offloading entirely for most mid-size models. Eliminating offloading beats optimizing offloading by a large margin.
Who Should Not Care
If your model fits entirely in VRAM and your GPU runs inference without any CPU help, the 9800X3D does nothing for your performance. Zero. The CPU isn't involved in the inference path at all — it's just sitting there scheduling tasks and handling the OS.
This covers a large percentage of local LLM users:
- 7B and 13B models running on an RTX 4090 (24GB VRAM): fully in VRAM.
- 30B models in Q4 quantization on dual RTX 3090s (48GB combined VRAM): fully in VRAM.
- Apple Silicon users: the CPU and GPU share unified memory — V-Cache doesn't apply here.
If you're primarily GPU-bound, the extra $100–150 premium on the 9800X3D over the 9700X is wasted.
The Price Premium Analysis
The Ryzen 9800X3D typically costs $450–500. The Ryzen 9700X is $300–350. The premium is roughly $150.
For gaming, the 9800X3D premium is clearly justified — many gaming workloads are cache-sensitive and the performance gains are well-documented.
For local LLMs, it's conditional. If you're a heavy CPU-offload user, 15–30% faster inference for $150 is reasonable. If you're a pure GPU inference user, you should spend that $150 on RAM, storage, or put it toward the next GPU upgrade.
Tip
If you already have a 9700X or 9600X and are thinking about upgrading to a 9800X3D specifically for LLM performance, reconsider. The upgrade cost plus reselling your current chip rarely makes sense compared to waiting for the next GPU tier drop or buying more VRAM.
Comparison vs Standard Ryzen 9000 Series
For CPU inference tasks specifically:
- 9800X3D is the fastest consumer CPU for CPU-bound LLM workloads.
- 9700X is a solid runner-up — the cache reduction costs you speed, but it's cheaper.
- 9900X and 9950X have more cores but standard cache — they don't beat the 9800X3D on single-threaded inference, though more cores help with parallelism on batched requests.
- Intel Core Ultra 200 series: competitive on single-thread performance but lacks the V-Cache advantage for cache-sensitive workloads.
For tasks where cache matters, AMD's 3D V-Cache architecture is the clear choice in the consumer CPU space. No Intel product currently competes with it for this specific use case.
The Bottom Line
The 9800X3D is a real performance win for CPU-side inference. The V-Cache advantage is legitimate, not marketing. But it only matters if the CPU is actually doing inference work.
Check your current setup: if you're running --n-gpu-layers 999 and your model fits in VRAM, your CPU is barely involved. The 9800X3D does nothing for you there. If you're regularly seeing CPU layers in your llama.cpp output and your tokens per second are bottlenecked on the CPU side, the 9800X3D is one of the most targeted hardware upgrades you can make.