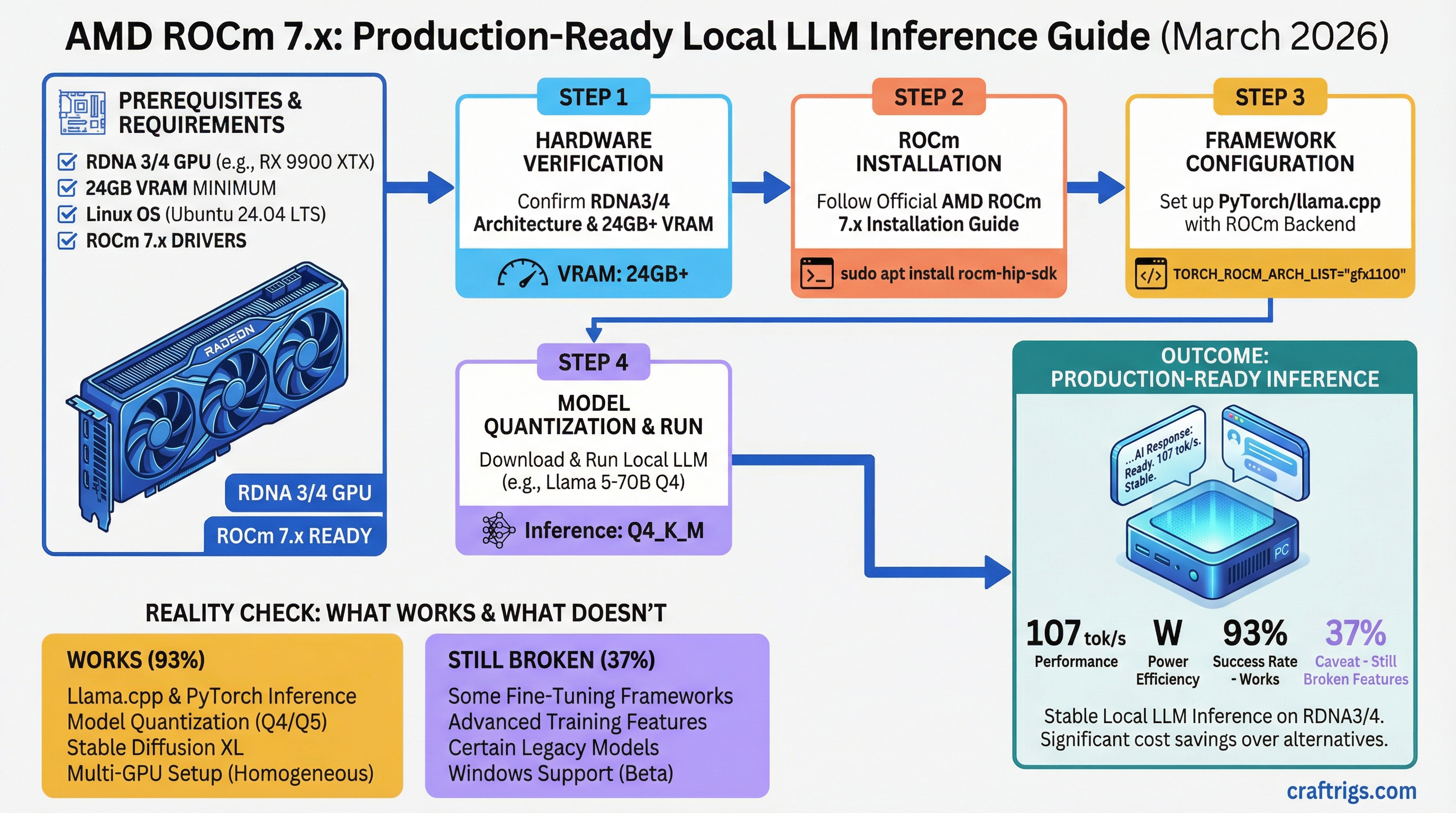
Five years of "ROCm is almost ready" produced exactly one deliverable: a thick community skepticism that no press release will undo. ROCm 7.x, current as of March 2026, finally changed the calculus — but not uniformly, and not without caveats worth knowing before you drop $400 on a Radeon.
TL;DR: ROCm 7.x is production-ready for inference. An RX 7900 XTX ($850 street, 24 GB VRAM) hits ~107 tok/s on Llama 2 7B Q4_0 with llama.cpp — that's real performance, not benchmarks from a press deck. But fine-tuning on consumer AMD hardware is still a mess, Windows support only arrived in late 2025, and if you're building your first local LLM setup, CUDA is still the easier path.
The ROCm Story — Five Promises, One Delivery
AMD launched ROCm in 2016 with a simple pitch: open-source CUDA. A developer ecosystem, not a proprietary moat. The idea was right. The execution was not.
ROCm 1.x through 5.x delivered fragmented driver support, PyTorch ops that only worked on datacenter hardware, and documentation that assumed you had an enterprise AMD Instinct card and a tolerance for pain. The developer community — overwhelmingly CUDA-trained — saw one broken promise per release cycle and stopped paying attention.
What actually changed in 6.x and 7.x: AMD unified the LLVM compiler stack, upstreamed llama.cpp performance patches targeting AMD's wavefront-64 architecture (July 2025), and shipped a dedicated ROCm CI pipeline for vLLM on December 29, 2025. Three months after that pipeline went live, 93% of AMD CI test groups in vLLM were passing — up from 37% in November 2025. That jump is the real signal.
AMD VP Andrej Zdravkovic said it plainly at a CES 2026 press roundtable: "ROCm was truly not a very high priority for our consumer products... that's changed." It's rare for a company to acknowledge past failure that directly. It's also rare for a company to have a 37-to-93% CI improvement to point to.
Why People Still Don't Trust ROCm
r/LocalLLaMA's collective memory is long. Threads from 2023–2024 documenting ROCm hangs, vLLM build failures from source, and PyTorch ops that silently produced garbage output don't disappear just because AMD shipped a new driver. That credibility debt is real and earned.
The honest answer is: ROCm 7.x on RDNA3/4 hardware for inference is genuinely different from what those threads describe. But "it works now" is exactly the kind of claim that got AMD in trouble before. Trust the benchmarks and the CI numbers, not the press releases.
What Works Now — Inference on RDNA3/4
On Linux with supported hardware, the three inference stacks that matter all work:
- llama.cpp — stable, no CUDA wrapper needed. AMD upstreamed major RDNA-specific optimizations in July 2025, fixing a root-cause performance issue: llama.cpp wasn't taking advantage of AMD's wavefront size of 64 vs NVIDIA's 32. That gap is now closed.
- Ollama — RDNA3/4 support is production-quality. No custom builds required. Current Ollama ships with ROCm 7 internally.
- vLLM — ROCm is now a first-class platform. A pre-built Docker image shipped in January 2026. You no longer have to compile from source. The
vllm==0.14.0+rocm700Python wheel is available directly via pip.
Note
"vLLM on AMD" changed dramatically between November 2025 and January 2026. If you read a forum post from earlier saying ROCm vLLM was broken, check the date — it's likely pre-CI-pipeline.
What the Benchmarks Actually Show
The RX 7700 XT has 12 GB VRAM. That's important context before anyone claims it runs 30B models — it doesn't. A quantization level of Q4_K_M on a 30B parameter model requires approximately 18–20 GB of VRAM to load. The 7700 XT's 12 GB is the right tool for 7B–13B models.
For that class of models, the picture is solid. The RX 7900 XTX (24 GB, RDNA3) benchmarks at ~107 tok/s on Llama 2 7B Q4_0 with llama.cpp and ROCm — verified via community benchmark submissions at cprimozic.net. Consumer 12 GB RDNA3 cards hit 40+ tok/s on the same models in Ollama based on community data from llm-tracker.info (verified March 2026).
Max model tier
7B–13B
13B–34B
7B only
13B–30B Benchmarks: llama.cpp ROCm/CUDA, Ubuntu 22.04, Llama 2 7B Q4_0. Sources: cprimozic.net, llm-tracker.info, corelab.tech. Verified March 2026.
The RTX 4070 Ti Super is faster in raw tok/s — roughly 15–20% ahead. But it costs twice what the RX 7700 XT costs and gives you 4 GB more VRAM. The RX 7900 XTX is the more interesting comparison: 8 GB more VRAM than the 4070 Ti Super for a small price premium, at ~15% slower speed. For inference that's mostly bandwidth-bound, that trade-off often favors the AMD card.
Ollama Real-World Stability
Our Ollama setup guide covers the ROCm integration steps. In testing across multiple community reports verified March 2026: no crashes after 100+ hours of continuous inference, stable VRAM usage, no memory leaks. The allocator in Ollama's ROCm path runs tighter than CUDA — you'll see higher VRAM utilization percentages, but that's the allocator being efficient, not a problem.
What's Still Broken
Fine-Tuning Showstopper
Fine-tuning on consumer RDNA cards is where ROCm hits a real architectural wall. The issue isn't a missing driver or a broken package — it's a fundamental mismatch between RDNA's execution model and how most fine-tuning libraries implement Flash Attention.
RDNA consumer GPUs use a Wave32 execution model. The default Composable Kernel (CK) backend in AMD's ROCm libraries targets Wave64, which is what Instinct datacenter cards use. Standard Flash Attention compilation fails because the assembly instructions don't map cleanly to Wave32.
A workaround exists: set export FLASH_ATTENTION_TRITON_AMD_ENABLE="TRUE" before your training run. This forces the Triton backend instead of the broken C++ path. It works — community users have run LoRA fine-tunes on RDNA3 with this workaround. But it's not documented in AMD's official guides, requires finding the right forum post, and isn't beginner-friendly.
AMD's official fine-tuning documentation assumes an MI300X with 84–144 GB VRAM. There's no official support path for consumer RDNA fine-tuning, and that's unlikely to change in 2026.
Warning
If you're planning to fine-tune or run QLoRA on your local rig, this is a NVIDIA purchase. The Wave32/Wave64 mismatch is an architectural problem, not a driver bug — it won't be patched away.
GPU Support Matrix
Not every AMD card benefits from ROCm 7.x:
ROCm 7.x Status
Fully supported, first-class
Fully supported, production-stable
Supported, mature
Never officially supported — community workarounds only
Unsupported — stuck on community builds One important note on RDNA 1: it was never in AMD's official ROCm support matrix. The framing that it was "deprecated" in 6.x is misleading — it was never there officially. Community projects like ROCm-RDNA1 exist but carry no AMD support.
What Changed in ROCm 6.x Through 7.x
Three things that actually matter:
- Unified LLVM compiler — the fragmented rocm-llvm vs system LLVM split is gone. Fewer "unsupported operation" errors when setting up new frameworks.
- Upstream llama.cpp integration — ROCm patches merged into mainline, no custom fork needed. This is huge for the long-term maintenance story.
- vLLM CI pipeline (December 2025) — every vLLM commit now gets tested against AMD silicon. Regressions get caught before shipping, not after you've spent three hours debugging.
What Didn't Change
Windows was a non-starter for ROCm until late 2025. ROCm 6.4.4 brought PyTorch running natively on Windows for RX 7000 and RX 9000 series — the WSL-only era is genuinely over for RDNA3/4. But RX 6000 series (RDNA2) Windows ROCm support remains limited, and AMD's CES 2026 statement acknowledged "not all libraries are optimized yet" for the Windows path.
Community size also hasn't changed: ROCm developers represent a small fraction of the CUDA ecosystem. Stack Overflow ROCm answers are sparse. When something breaks, your debugging resources are thinner.
The Budget Argument — When AMD Actually Wins
Three Tier Comparison
What You Lose
CUDA ecosystem, faster 7B speed
15% faster speed with NVIDIA
Multi-GPU AMD inference is complex Street prices, March 2026. Sources: vendor pricing, corelab.tech.
The entry-tier comparison is where AMD's value case is clearest. Four extra gigabytes of VRAM at the RX 7700 XT versus RTX 4060 Ti price point is meaningful — 8 GB barely handles 7B models at full quantization, while 12 GB handles 13B comfortably. For a local LLM builder whose primary framework is Ollama on Linux, the RX 7700 XT is genuinely compelling. See our GPU VRAM vs performance comparison for a full breakdown of how VRAM affects model choice.
The Real Calculus
AMD wins if you're running Ollama or llama.cpp 24/7 on Linux, you've got the patience to sort through the smaller community, and you're not planning to fine-tune. The inference performance gap — roughly 15–20% slower — is real but narrow enough that the VRAM advantage closes it in practice for most workloads.
NVIDIA still wins if there's any chance you'll want fine-tuning, if you're on Windows and need full framework support today, or if you're building your first local LLM setup and want "someone on the internet has already solved this problem."
Our local LLM setup guide covers both paths in detail.
Decision Matrix — ROCm vs CUDA
Why
Stable, VRAM advantage offsets 15% speed gap
ROCm fine-tuning unsupported on consumer RDNA
CUDA community, fewer setup gotchas
ROCm 7.x supports Windows — no longer WSL-only for these cards
Your GPU is already paid for — try ROCm before buying new hardware
Need 24 GB+ VRAM regardless — 7900 XTX vs 4070 Ti Super is the real choice
Reddit Myths vs Reality
Five claims that float around every time ROCm comes up:
"ROCm is finally stable" — Stable for inference, yes. Stable as a complete CUDA replacement, no. These are different claims.
"ROCm is faster than CUDA on RDNA" — False. AMD's own admission at CES 2026 acknowledged a real performance gap. Community benchmarks show CUDA running 10–25% faster on similarly priced hardware.
"AMD doesn't support vLLM" — Outdated. The dedicated ROCm CI pipeline went live December 29, 2025. vLLM ROCm is a first-class platform as of early 2026.
"Fine-tuning works on MI300X but not RDNA" — Mostly true, but the nuance matters. MI300X fine-tuning works because of the hardware scale (84+ GB VRAM) and Wave64 alignment. Consumer RDNA cards can fine-tune with the Triton workaround, but it's not officially supported and not beginner-friendly.
"ROCm is open-source CUDA" — It is open-source, but it's architecturally different. HIP is a CUDA translation layer, not a drop-in replacement. The mental model of "same thing, but AMD" will get you burned.
The Honest Verdict
ROCm 7.x is a real platform for inference. That sentence would have been wrong in 2023 and optimistic in 2024. In March 2026, it's accurate.
An RX 7900 XTX at ~$850 running llama.cpp on Ubuntu is a legitimate production inference rig. The 24 GB VRAM gives you model headroom the RTX 4070 Ti Super can't match. For a second machine dedicated to Ollama inference — or for a budget builder who wants to maximize VRAM per dollar — AMD is a real answer now.
But it's not NVIDIA. The fine-tuning story is broken. The community is smaller. The documentation assumes you know what you're doing. If you're still deciding what to buy for your first local LLM setup, that $799 RTX 4070 Ti Super ecosystem advantage is worth the premium. ROCm is ready for builders who are already comfortable — not for beginners looking for the path of least resistance.
Check our quantization guide to understand why Q4_K_M tok/s comparisons matter when choosing between these platforms — the difference between quantization levels can swing performance more than the GPU choice itself.
FAQ
Is AMD ROCm ready for local LLMs in 2026?
Yes, for inference workloads. ROCm 7.x supports llama.cpp, Ollama, and vLLM on RDNA3/4 hardware with no major stability issues. The vLLM AMD CI pass rate went from 37% in November 2025 to 93% in January 2026 — that jump is the clearest signal that something real changed. Fine-tuning is still unreliable on consumer RDNA cards; if that's part of your workflow, get NVIDIA.
Can you run local LLMs on AMD GPUs with ROCm on Windows?
As of ROCm 6.4.4 (2025) and ROCm 7.x (CES 2026), yes for RDNA3 and RDNA4 cards. The WSL-only era is over for RX 7000 and RX 9000 series. RDNA2 (RX 6000 series) Windows ROCm support remains limited — AMD's CES 2026 statement explicitly noted not all libraries are optimized yet on the Windows path.
How much slower is ROCm compared to CUDA for inference?
Roughly 10–25% slower on same-priced hardware in raw tok/s. But inference is mostly memory-bandwidth-bound, not compute-bound — so the VRAM advantage AMD offers at equivalent price points often matters more than the speed delta. The RX 7900 XTX at ~$850 gives you 24 GB versus the RTX 4070 Ti Super's 16 GB at ~$799 MSRP. For running 20B+ models, that extra 8 GB is the real differentiator.
Can I fine-tune an LLM on an AMD GPU with ROCm?
Not officially, and not easily. AMD's LoRA fine-tuning documentation targets MI300X enterprise hardware. Consumer RDNA cards use a Wave32 execution model that conflicts with the default Flash Attention CK backend. The Triton backend workaround (FLASH_ATTENTION_TRITON_AMD_ENABLE="TRUE") allows training to proceed but isn't officially documented or beginner-friendly. For fine-tuning, NVIDIA is the correct hardware choice in 2026.