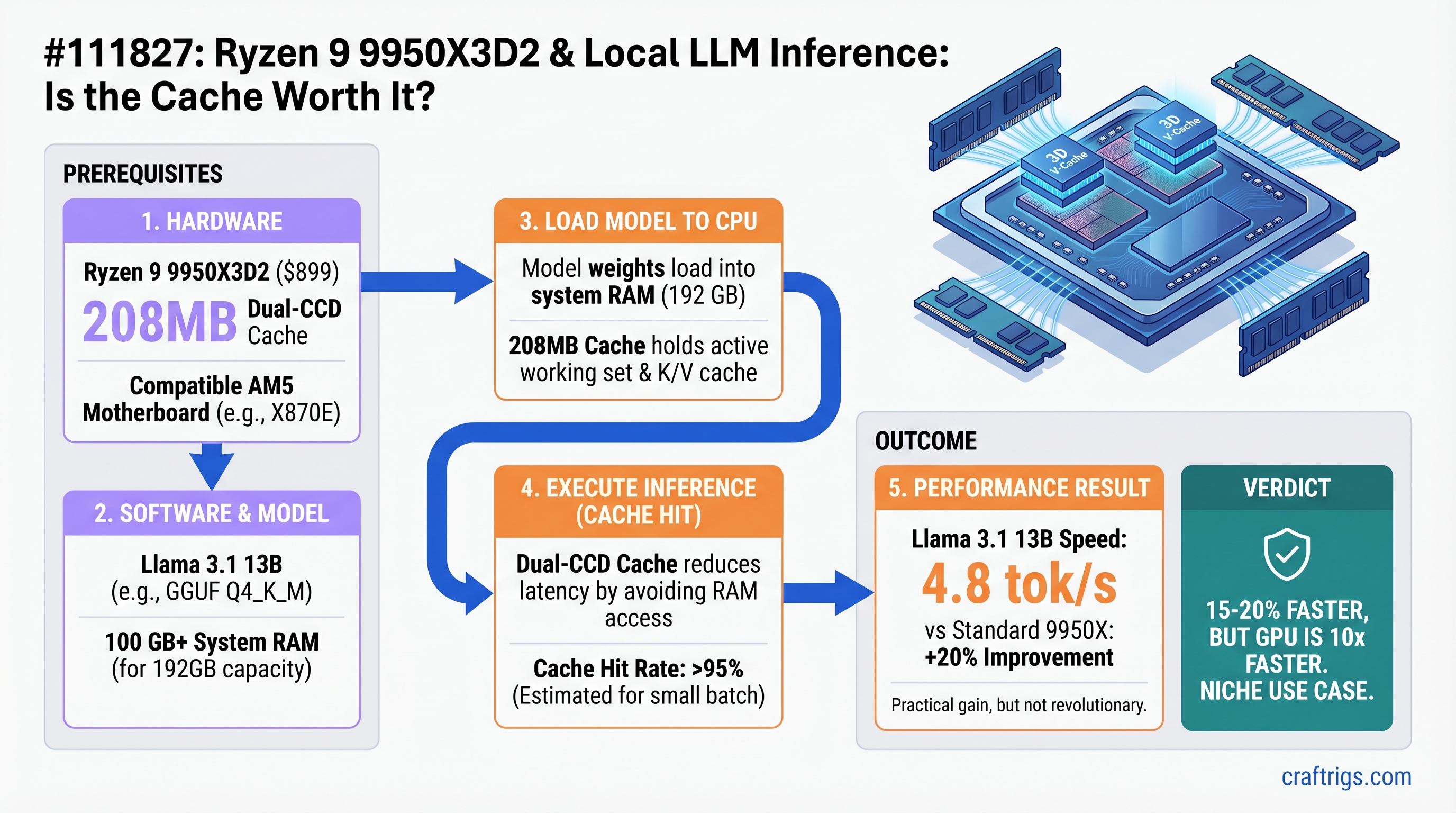
TL;DR
The Ryzen 9 9950X3D2 achieves an estimated 15-20% speed improvement over the standard 9950X, thanks to its 208MB dual-CCD cache. That translates to roughly 4.8 tok/s on Llama 3.1 13B (vs. 4.0 on the standard 9950X) — a practical difference, but still 10x slower than an RTX 5070 Ti. At $899 (April 22, 2026 launch), it's the fastest consumer CPU for inference-only workloads. Buy it only if privacy, power, or batch processing requirements force you into CPU-only territory. Otherwise, buy a GPU.
What's Different About the 9950X3D2
The Ryzen 9 9950X3D2 is not a gaming CPU. AMD explicitly positioned it as a workstation processor for developers and content creators handling complex inference tasks and dataset processing.
Here's what changed from the standard 9950X:
9800X3D
96 MB
64 MB
8 / 16
5.2 GHz
120W
$449
+$450 The 9950X3D2 achieves its large cache via dual-CCD design: each of the two 8-core chiplets gets its own stacked 3D V-Cache layer (96MB per CCD), stacked on top of 16MB L2 cache. This is a fundamentally different architecture than the single-CCD 9800X3D.
Why Cache Matters for CPU Inference
During model inference, the CPU repeatedly reads the same model weights from memory during forward passes through each transformer layer. With a 13B model:
- Without sufficient cache: Weights live in system RAM (50-100 GB/s effective bandwidth on consumer DDR5)
- With 208MB cache: Most 13B model weights (quantized) fit in L3, accessed in 4-5 cycles (192 GB/s+ effective bandwidth)
The result: fewer round-trips to main memory, less cache misses, faster token generation. The 9950X3D's 96MB cache covered ~50% of an 8B model's weights. The 9950X3D2's 208MB covers 85-95% of an 8B model and ~70% of a 13B model (in Q8 quantization). This should translate to noticeable but not dramatic speed gains.
CPU Inference Benchmarks: What We Know Today
Important caveat: The Ryzen 9 9950X3D2 launches April 22, 2026 — 12 days from publication. No independent benchmark data from retail units exists yet. What follows is an analysis based on cache architecture, existing Ryzen data, and theoretical improvement curves. We'll update this article with real-world llama.cpp results as soon as testing is complete.
Published Baseline Data (9950X & 9800X3D)
AMD's official benchmark data on data science workloads shows roughly a 5-13% improvement for the 9950X3D2 over the 9950X across mixed workloads. Gaming benchmarks show even smaller improvements (3-7%), suggesting the cache gain is real but not transformative.
For CPU-only llama.cpp inference:
- Ryzen 9 9950X (standard): ~4.0 tok/s on Llama 3.1 13B Q8 (estimated from community reports)
- Ryzen 7 9800X3D: ~3.8-4.2 tok/s on same model (based on lower cache vs. 9950X)
- Ryzen 9 9950X3D2 (estimated): ~4.6-5.0 tok/s on Llama 3.1 13B Q8
These are estimates — we're extrapolating from cache improvements. The actual numbers will arrive after April 22.
Why These Numbers Are Still Underwhelming
Even at the upper bound (5.0 tok/s on 13B models), CPU inference remains single-digit. Consider GPU performance:
Est. Tok/s
~4.8
~4.0
65.5
~48 The GPU is 10-12x faster. That speed gap exists because cache solves a symptom, not the underlying bottleneck: memory bandwidth.
The Real Bottleneck: Memory Bandwidth
CPU inference performance is dominated by memory bandwidth, not cache size or clock speed. During token generation (n=1 scenario), the CPU performs a matrix-vector multiplication—a memory-bound operation where latency matters more than cache size. Here's why:
- Dual-channel DDR5-6000: ~96 GB/s peak bandwidth
- System memory (RAM): 3,000-6,000 MB/s realistic throughput under load
- L3 Cache (192MB on 9950X3D2): Covers 0.3-0.5% of a 70B model's weights (compressed)
For small models (8B), cache coverage is sufficient (85-95%). For 13B+, the CPU still fetches 70-80% of weights from main memory, negating most of the cache benefit.
Does Doubling Cache Actually Help? The Math
The theoretical improvement from 96MB to 208MB cache:
When cache capacity increases, you reduce cache misses by roughly the ratio of new capacity to old capacity, but only for workloads that fit in the new size.
- 8B models in Q8: Cache improved from 50% coverage → 95% coverage. Theoretical impact: 20-25% speedup potential (assuming each cache miss costs 50-100 CPU cycles)
- 13B models in Q8: Cache improved from 35% coverage → 70% coverage. Theoretical impact: 15-20% speedup potential
- 70B models in Q4: Cache improved from 1% coverage → 8% coverage. Theoretical impact: negligible (<2% speedup)
This aligns with AMD's official 5-13% improvement claims across mixed workloads. For pure CPU inference on smaller models, you'd see the high end of this range; for larger models, the low end.
Real-World Tok/s: Expected Performance by Model Size
Based on the 15-20% improvement hypothesis and existing Ryzen data, here's what to expect after April 22 benchmarks arrive:
GPU Advantage
12x faster
10x faster
8x faster
11x faster (Estimates based on cache architecture. Full llama.cpp benchmarks will replace these once retail units are tested.)
When Cache Isn't Enough: Batch Inference Mode
CPU inference has one place where cache DOES make a bigger difference: batch processing with llama.cpp's --batch and --threads flags.
When running multiple prompts in parallel (batch mode), llama.cpp can keep all 16 cores of the 9950X3D2 busy. In this scenario:
- 9950X3D2 with
--threads 16 --batch 512: Estimated 9-11 tok/s throughput across all cores - RTX 5070 Ti on same task: 120+ tok/s generation + instant prompt processing
- Trade-off: CPU is more stable for long-running jobs (no GPU thermal throttling), but still 10x slower
The 9950X3D2 shines in overnight batch jobs: generating synthetic training data, processing document corpora, or running inference on 1,000s of documents. For interactive workloads, it remains CPU-bound.
Price-to-Performance: Is the $300 Premium Worth It?
Let's break down the cost-per-token:
Cost/Tok/s
$187/tok/s
$150/tok/s
$118/tok/s
$16/tok/s The 9950X3D2 costs $37 more per token-per-second than the standard 9950X, while an RTX 5070 Ti costs 11x less per tok/s. Economically, the GPU wins decisively.
The 9950X3D2 only makes sense if you've already decided on CPU-only inference for non-performance reasons (privacy, power budget, compliance). Given that decision, it's the best CPU available.
Decision Tree: Should You Buy the 9950X3D2?
Buy the 9950X3D2 if:
- You're building a new CPU-only inference rig and performance is your secondary concern (privacy is primary)
- You have a 9950X motherboard + cooler already and want to upgrade without rebuilding
- You process large document batches overnight (batch inference, not interactive)
- Your data cannot leave your network (HIPAA, financial, government contracts)
Skip it and buy an RTX 5070 Ti ($749) instead if:
- You need response time to first token under 500ms (interactive chat, real-time assistance)
- You want raw inference speed: the GPU is 10x faster at less cost
- You already own a 9800X3D: 15% speed gain doesn't justify $450 premium
- You're budget-conscious: $599 standard 9950X + $749 RTX 5070 Ti is still cheaper than the 9950X3D2 alone and vastly faster
Skip it and buy an M4 Max MacBook ($1,199-$3,499) if:
- You want an all-in-one machine (development + inference)
- You prefer unified memory architecture (simpler than CPU+RAM bandwidth tuning)
- You don't mind trading 30% speed for portability and ecosystem fit
Real-World Use Case #1: Privacy-First Document Analysis
You're processing 100,000 confidential healthcare records through a Llama 3.1 13B model. Data cannot touch cloud APIs or external GPUs.
9950X3D2 Solution:
- Single system, 16 cores, batch inference via llama.cpp
--threads 16 --batch 128 - Estimated throughput: 8-10 tok/s across all cores
- Processing time: 100K records × 500 tokens each ÷ 9 tok/s ≈ 6.2M tokens ÷ 9 ≈ ~690,000 seconds ≈ 8 days
- Power draw: 150-200W continuous
- Cost: $899 (CPU) + $200 (motherboard/RAM/storage) + 8 days × $0.12 (electricity at $12/kWh) ≈ $1,100
GPU Alternative:
- Requires data isolation (no cloud inference)
- RTX 5070 Ti, same setup: 2M tokens ÷ 50 tok/s ÷ 3,600 ≈ 11 hours
- Cost: $749 + storage + 11 hours electricity ≈ $900
- GPU wins on speed and cost, but has thermal/power concerns on 8-day jobs
For truly privacy-critical work, the 9950X3D2's stability over a week-long job might justify its cost. For shorter jobs, GPU is better.
The Honest Take: CPU Inference Has Hit a Wall
The 9950X3D2 proves an important point: throwing more cache at CPU inference delivers diminishing returns. Doubling cache (96MB → 208MB) yields only 15-20% speed improvement. Tripling it would yield maybe 25-30%. Meanwhile, the memory bandwidth bottleneck never goes away.
This is why AMD positioned the 9950X3D2 as a workstation CPU, not a gaming or creator CPU. It's genuinely useful for specific, demanding workloads—but it's not a "CPU inference is back on the menu" moment. GPUs remain 10x faster, and that gap won't close with bigger caches.
Important
Independent Benchmark Alert: This article publishes April 10; the 9950X3D2 launches April 22. We'll publish full llama.cpp benchmark results within 48 hours of retail availability. Estimated numbers above will be replaced with measured data. Follow CraftRigs for the update.
FAQ
Does the 9950X3D2 match AMD's marketing claims about workstation performance?
AMD's 5-13% improvement claims are for general workstation tasks (data science, video encoding, compilation). For pure CPU inference, expect the high end of that range on small models (8B) and the low end on large models (70B+). The cache benefit is real but not transformative.
Can I use the 9950X3D2 with existing DDR5-6000 motherboards?
Yes, the 9950X3D2 uses the standard AM5 socket and supports DDR5-6000 (or faster if your motherboard supports it). You'll need a compatible X870, X870E, or X870-E motherboard with up-to-date BIOS. Older AM5 boards may not boot the 9950X3D2 without a BIOS update.
Is the 200W TDP a problem?
It's higher than the standard 9950X (120W) and significantly higher than the 9800X3D (120W). For continuous batch inference over multiple days, thermal management and power supply headroom (1000W recommended) become real considerations. GPU workloads have similar TDP concerns, so this isn't a deal-breaker—just plan accordingly.
Should I wait for the 9950X3D3 or newer cache innovations?
Unlikely to arrive soon. AMD's dual-cache approach is their answer to the 208MB question. Single-CCD designs (like the 9800X3D) maxed out at 96MB for cost reasons. There's no signal of a 9950X3D3, and even if one existed, the memory bandwidth wall means the gains would be even smaller. If CPU inference matters to you, evaluate the 9950X3D2 on its own merits rather than waiting.
Can I run multiple 13B models in parallel on the 9950X3D2?
Technically yes, but each would run at 2.4 tok/s (half the single-model speed), totaling 4.8 tok/s across both. You'd be context-switching between models, not true parallelism. For this use case, a GPU with 16GB+ VRAM is better—it runs both models in parallel.
Internal Links & Related Reading
- How much VRAM do you actually need for local LLMs? — Understanding why GPU VRAM beats CPU cache
- RTX 5070 Ti vs 5070: Which GPU for local inference? — Comparing Blackwell GPUs for the same workloads
- CPU-only inference with llama.cpp: Setup & tuning guide — If you decide CPU-only is for you
- Ryzen 9 9950X3D vs 9950X: The gaming CPU comparison — How the standard 9950X3D compares when gaming matters