Five gigabytes of VRAM. That's the bar. And an RTX 3060 sitting in a mid-range gaming PC from 2021 has 12GB to spare.
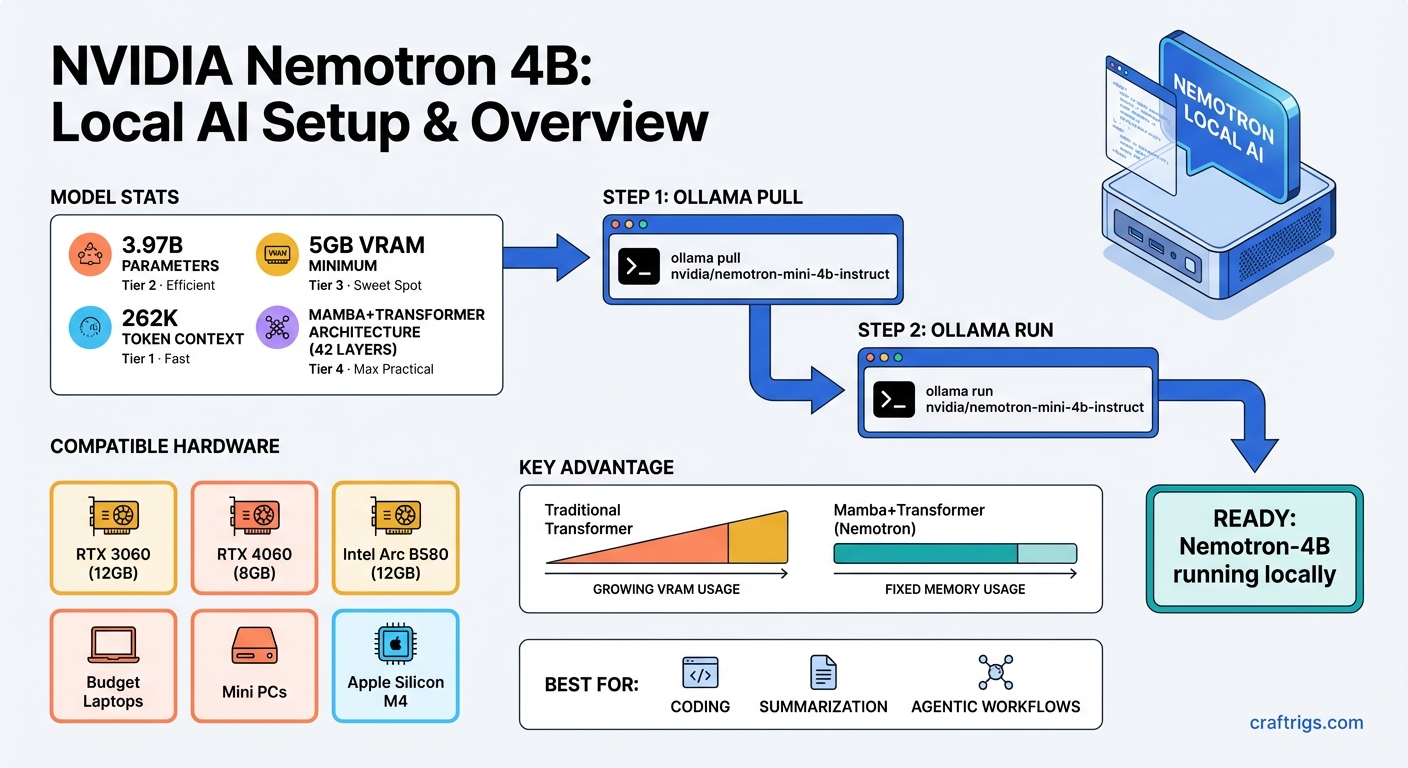
NVIDIA quietly dropped Nemotron-3-Nano-4B on March 17, 2026, and buried in the Unsloth documentation is the number that actually matters: the quantized GGUF version runs on 5GB of VRAM. Not 8GB. Not 12GB. Five. That means budget laptops with discrete GPUs, mini PCs, the aging gaming rig under your desk — all of them can now run a model that scores 95.4% on MATH500 with reasoning enabled.
That's not a benchmark most people care about day-to-day, but it means the model is genuinely capable, not just a toy that fits in a small box.
See also: Best Local LLM Models Ranked →
What Nemotron-3-Nano 4B Actually Is
The 4B label is a little misleading. It has 3.97 billion parameters, compressed down from NVIDIA's 9B Nemotron-Nano-v2 using something they call the Nemotron Elastic framework — essentially structured pruning that shrinks the model while preserving most of the intelligence.
The real engineering trick here is the architecture. Most 4B models are pure Transformer. This one isn't. Its 42 layers split into 21 Mamba layers, 4 attention layers, and 17 MLP layers. The 5:1 Mamba-to-attention ratio is unusual enough that NVIDIA's own model card calls it out explicitly.
Why does that matter? Mamba's selective state space design doesn't maintain a key-value cache the way standard Transformer attention does. In plain terms: as your conversation gets longer, the memory requirements stay flat rather than growing. A regular Transformer with a 262K-token context window would blow through your VRAM. This one doesn't.
Note
Nemotron-3-Nano 4B Specs: 3.97B parameters | 262K token context window | Mamba-2 + Transformer hybrid (42 layers) | Available in BF16, FP8, and GGUF (Q4_K_M) | NVIDIA Nemotron Open Model License (commercial use allowed)
The GPUs That Qualify
If you have any of the following, you're already in:
RTX 3060 12GB — The most common entry-level AI card in 2026. You can pick one up used for around $189-$220. At 12GB VRAM, you have 7GB of headroom above what the model needs. That's enough for meaningful context and tool-calling workloads.
RTX 4060 8GB — Cuts it closer but still fine for the 5GB GGUF. The 8GB version is the weak spot of the 40-series lineup for LLMs, but Nemotron-3-Nano 4B fits comfortably.
Intel Arc B580 — 12GB GDDR6 for around $249 new. ROCm and oneAPI support has matured enough that this works. Not NVIDIA, but the VRAM is there.
Budget gaming laptops — Anything with an RTX 3060, 4060, or 4070 laptop GPU qualifies. Most laptop variants of these ship with 8GB VRAM, which is still enough.
Mini PCs with discrete GPUs — The Minisforum and ASUS ROG NUC class of machines. If it has a modern dedicated GPU, it can run this.
Apple Silicon — The M4 MacBook Air with 16GB unified memory runs it fine. One user clocked 75 tokens per second on an M4 Max in a WebGPU browser demo that just dropped this week.
Tip
Laptop VRAM check: Open Device Manager on Windows or run nvidia-smi in terminal. Laptop GPUs with "Max-Q" in the name usually have lower VRAM — the RTX 4060 laptop specifically comes in both 8GB and 6GB SKUs depending on the manufacturer. Double-check before buying.
What the Benchmarks Actually Tell You
95.4% on MATH500 with reasoning enabled sounds impressive until you realize that number means very little for most use cases. Coding, math tutoring, structured document parsing — sure. Casual chatting and summarization? Those don't need that level of reasoning.
The more useful number is 18 tokens per second on a Jetson Orin Nano 8GB — an edge device with far less compute than a desktop GPU. On a proper RTX 3060, expect something meaningfully faster than that.
For comparison: Qwen3.5-4B and Phi-4 Mini are the obvious alternatives at this parameter count. Qwen3.5 has stronger benchmark scores on GPQA and MMLU-Pro, and supports multimodal inputs (images). Phi-4 Mini runs under MIT license. Nemotron-3-Nano 4B's actual competitive edge is that it comes from NVIDIA's model family — meaning TensorRT-LLM optimizations, day-zero Unsloth support for fine-tuning, and the Mamba architecture's flat memory behavior at long contexts.
Actually — that Mamba context window thing is probably undersold. 262K tokens on 5GB of VRAM is genuinely unusual. You can feed it an entire codebase, a long legal document, or a book and have the model reason across it without OOM errors. That use case alone justifies the model for a lot of developers.
How to Get It Running
The fastest path is Ollama or llama.cpp with a GGUF file. NVIDIA published Q4_K_M quantized versions directly. The steps are roughly:
- Install Ollama (or llama.cpp if you want more control)
- Pull the GGUF from Hugging Face — search for
nvidia/NVIDIA-Nemotron-3-Nano-4B - Load it with
-ngl 99in llama.cpp to push all layers to GPU
For tool-calling workloads, NVIDIA recommends dropping temperature to 0.6 and top_p to 0.95. For general chat, temperature 1.0 and top_p 1.0 work fine.
If you'd rather not install anything, there's a WebGPU demo running in-browser at Hugging Face Spaces right now using Transformers.js. It's slow on most laptops but proves the architecture actually works at the edge.
Warning
Don't confuse this with Nemotron-3-Nano-30B-A3B — NVIDIA released both models the same week. The 30B MoE version needs 24GB VRAM. The one that runs on 5GB is the 4B (3.97B parameter) model specifically.
The Tax Refund Timing Question
It's March 2026. Tax refund season is either here or a few weeks out depending on when you filed. If you're considering spending that refund on hardware, the case for a used RTX 3060 12GB just got more interesting.
Before this week, 5GB VRAM was a hard constraint — you could run small 1B-2B models that weren't particularly useful. Now there's a model that genuinely competes with much larger architectures at that VRAM level. The value proposition for budget GPU hardware shifted overnight.
Worth noting: memory chip demand is accelerating (Micron's recent earnings pointed directly at AI-driven demand — more on that in a separate piece). GPU availability and pricing are more stable right now than they've been since the 2021 shortage. The RTX 3060 12GB specifically has been sitting at $189-$220 used for months. That window might not last if demand picks up for budget AI hardware.
The Verdict
Nemotron-3-Nano 4B is not the best small model in its class by raw benchmark numbers. Qwen3.5-4B wins on several standard evals. Phi-4 Mini has a cleaner license. But the combination of 5GB VRAM requirement, 262K context window via Mamba architecture, and NVIDIA-native tooling (TRT-LLM, day-zero Unsloth fine-tuning support) makes it the most practical option for people running consumer NVIDIA GPUs.
If your GPU has 8GB or more, it runs. If your laptop has a discrete GPU from the last 4 years, it probably runs. And if you're sitting on a tax refund looking at hardware, a $200 used RTX 3060 12GB just became a legitimate local AI workstation.
Nemotron 4B Setup Flow
graph TD
A["Download Nemotron 4B GGUF"] --> B["Install Ollama"]
B --> C["ollama pull nemotron-mini"]
C --> D["Start Ollama Server"]
D --> E["Query via API or CLI"]
E --> F{"GPU Available?"}
F -->|"Yes (4GB+ VRAM)"| G["Full GPU Inference"]
F -->|"CPU Only"| H["Slower but works on any PC"]
G --> I["Fast local AI: ~30 t/s"]
style A fill:#1A1A2E,color:#fff
style G fill:#F5A623,color:#000
style I fill:#22C55E,color:#000