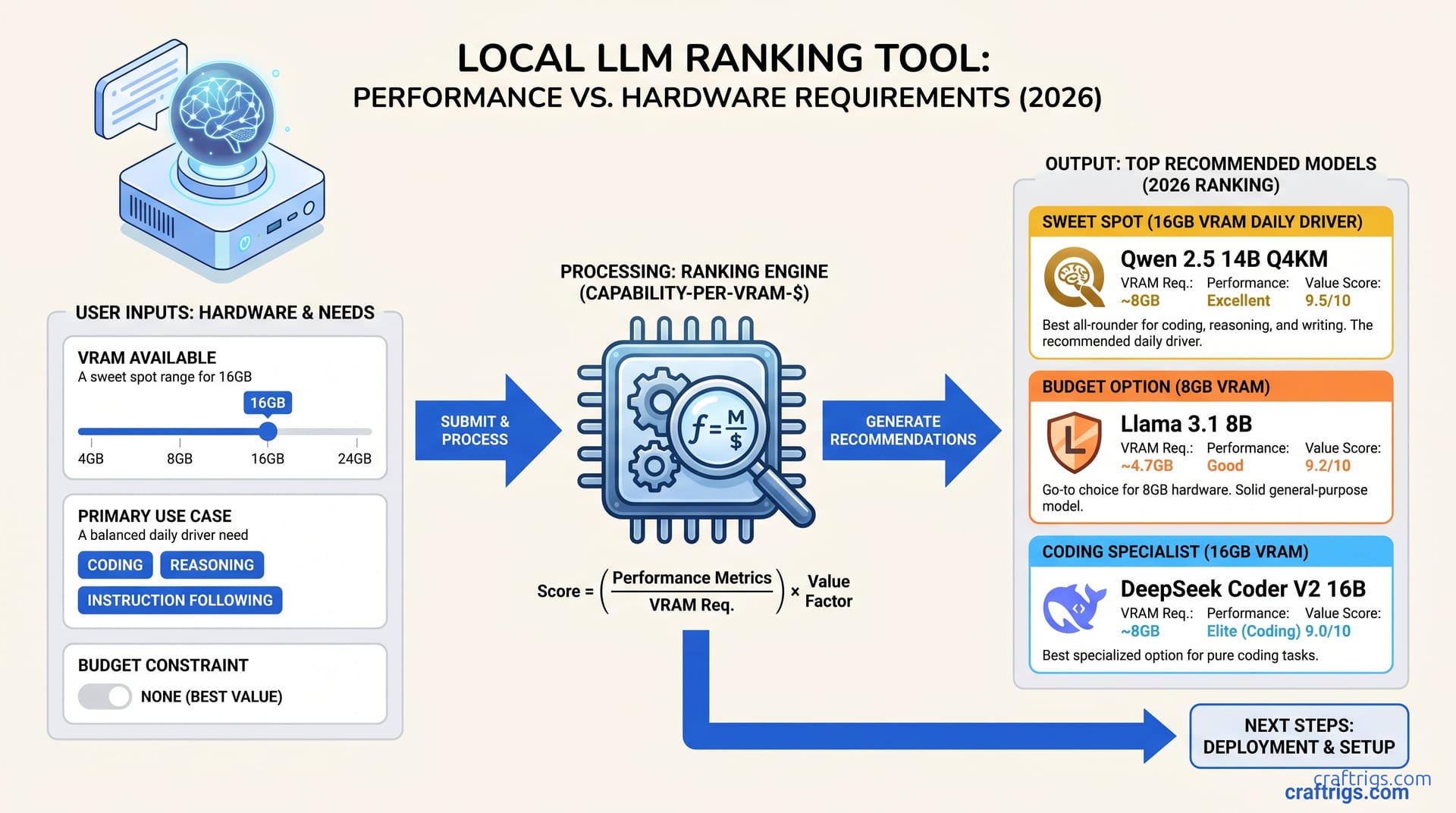
TL;DR: For most people, Qwen 2.5 14B Q4_K_M is the best daily driver — excellent across coding, reasoning, and writing at a size that runs well on 16GB VRAM. For budget hardware with 8GB VRAM, Llama 3.1 8B is the go-to. For coding specifically, DeepSeek Coder V2 16B is the best option. For 30B+ range, Qwen 2.5 32B if you have 24GB VRAM.
The open-source model landscape moves fast. New releases and fine-tunes drop every week. This ranking focuses on what's actually worth running right now for real daily use — not what scored best on a benchmark nobody uses in practice.
Last updated: March 2026.
How This Ranking Works
Models are ranked within VRAM tiers, since your GPU determines which models you can run at all. Within each tier, they're scored on:
- General reasoning and instruction following
- Coding performance (code generation, debugging, explanation)
- Writing quality (fluency, coherence, instruction adherence)
- Context window handling (does it stay coherent in long conversations?)
- Quantization quality (does Q4_K_M still feel usable?)
Benchmarks are referenced but not the deciding factor. What a model scores on MMLU matters less than whether it writes useful code and follows instructions well in practice.
Tier 1: 6–8GB VRAM (RTX 4060, 3060 8GB)
These are the best models for cards with limited VRAM. All run at Q4_K_M within 5–6GB.
#1 — Llama 3.1 8B Instruct (Q4_K_M, ~4.7GB)
Meta's Llama 3.1 8B remains the benchmark for this category. Excellent instruction following, coherent in multi-turn conversations, handles coding basics, and has 128K context window support. It's the most widely tested 8B model which means the most community resources, fine-tunes, and documented setups.
Best for: general assistant tasks, writing, Q&A, light coding
#2 — Qwen 2.5 7B Instruct (Q4_K_M, ~4.4GB)
Qwen 2.5's 7B model punches above its weight class. Strong on reasoning and coding for its size. Better multilingual support than Llama. If you work in languages other than English or do a lot of structured data work, Qwen 2.5 7B may outperform Llama 3.1 8B for your use case.
Best for: multilingual use, structured output, light coding, reasoning tasks
#3 — Phi-4 Mini (Q4_K_M, ~2.5GB)
Microsoft's Phi-4 Mini is remarkably capable for 3.8B parameters. It runs in about 2.5GB VRAM, leaving headroom on even modest cards. Quality on reasoning and coding tasks rivals much larger models. The tradeoff: smaller context handling and occasional odd behavior on creative writing tasks.
Best for: fast inference on constrained hardware, reasoning-heavy tasks, leaving VRAM free for large context
Tier 2: 10–16GB VRAM (RTX 4060 Ti 16GB, RTX 4070 Ti Super, RTX 5070 Ti)
This is the sweet spot for local AI. 16GB VRAM gets you excellent models at comfortable context windows.
#1 — Qwen 2.5 14B Instruct (Q4_K_M, ~9GB)
The best all-around model for 16GB VRAM. Qwen 2.5 14B significantly outperforms Llama 3.1 8B on complex reasoning, code generation, and following nuanced instructions. It handles 128K context well and responds in a way that feels genuinely useful rather than pattern-matched. This is the model most people running 16GB cards should have as their daily driver.
Best for: everything — coding, writing, analysis, research, general assistant work
#2 — DeepSeek Coder V2 16B Instruct (Q4_K_M, ~10GB)
For coding specifically, DeepSeek Coder V2 16B is the best option in this VRAM tier. It outperforms general-purpose models on code generation, debugging, and technical explanation. Slightly weaker on creative writing and general Q&A. If your primary use is code assistance, this is the pick.
Best for: coding, code review, technical documentation, software engineering tasks
#3 — Phi-4 (Q4_K_M, ~8.5GB)
Microsoft's Phi-4 full model (14B) shows strong benchmark performance especially on STEM and reasoning tasks. Good instruction following. Some users find it slightly more "formal" and less flexible on creative tasks. Solid alternative to Qwen 2.5 14B if you do a lot of analytical work.
Best for: STEM reasoning, analysis, structured problem solving
#4 — Gemma 3 12B IT (Q4_K_M, ~7.5GB)
Google's Gemma 3 12B is well-rounded and runs efficiently. Strong on summarization and text analysis. Good multimodal context awareness even in text-only version. Slightly weaker on coding than Qwen 2.5 14B but more consistent on long-document tasks.
Best for: document analysis, summarization, writing assistance
#5 — Mistral Small 3.1 24B (Q4_K_M, ~15GB — tight on 16GB)
Mistral's 24B model just barely fits on 16GB VRAM at Q4_K_M with reduced context. It offers strong general performance and good multilingual capabilities. If you have exactly 16GB, use a 32K or lower context window setting to keep it stable. Worth it if you want the quality step up from 14B without needing 24GB VRAM.
Best for: complex instruction following, multilingual work, stepping up from 14B quality
Tier 3: 20–24GB VRAM (RTX 3090, RTX 4090)
With 24GB VRAM, you can run 30B+ models cleanly at Q4_K_M with full context windows.
#1 — Qwen 2.5 32B Instruct (Q4_K_M, ~19GB)
The best general-purpose model in the 24GB VRAM range. Significantly stronger on complex multi-step reasoning than the 14B version. Excellent code generation. Handles long context well. If you have a 3090 or 4090 and do serious work with your local AI, this is your model.
Best for: complex reasoning, professional coding, research summarization, analysis
#2 — Mistral Large 2 (123B — requires 64GB+ unified memory or 80GB VRAM)
Mistral Large 2 is a 123B parameter model. Even at Q2 quantization it exceeds 30GB and does not fit on a single 24GB consumer GPU. It is only viable on systems with 64GB+ unified memory (Mac Studio M4 Max 64GB, A100 80GB, or multi-GPU setups). Strong on instruction following and business writing. Good multilingual performance. If Qwen 2.5 32B feels too "technically focused" and you have the hardware for it, Mistral Large 2 is a more balanced alternative.
Best for: business writing, multilingual tasks, balanced general assistant work — on 64GB+ hardware only
#3 — Llama 3.3 70B (Q3_K_M only — 24GB is tight)
Meta's Llama 3.3 70B at Q3_K_M fits in approximately 28–30GB — which means it requires CPU offloading on a 24GB card or running on a 32GB card. At Q2 it's possible on 24GB but quality degrades noticeably. If you have 24GB, Qwen 2.5 32B at Q4 is a better experience than Llama 70B at Q2.
Best for: users with 32GB+ VRAM or dual 24GB setups. Don't run at Q2 if you can avoid it.
Specialist Models Worth Knowing
Best embedding model: nomic-embed-text For RAG (retrieval augmented generation) and semantic search. Small footprint, excellent quality. Runs alongside your main model.
Best code generation overall: DeepSeek Coder V2 16B Mentioned in Tier 2, but worth repeating. For serious code work, it outperforms general models at the same size.
Best for long documents: Qwen 2.5 72B or Llama 3.1 70B (if you have 48GB+) The full-size 70B+ models handle extremely long contexts better than 14–32B models. Only relevant if you have the hardware.
Best creative writing: Mistral Small 3.1 24B or fine-tuned Llama variants The community has produced strong creative writing fine-tunes of base Llama models. Check Hugging Face for "creative writing" fine-tunes on the Llama 3.1 base.
How to Download and Run These Models
All models mentioned are available on Hugging Face in GGUF format. The easiest path:
- Install Ollama from ollama.ai
- Run
ollama pull qwen2.5:14b(or whichever model you want) - Ollama handles the download and quantization selection automatically
For manual GGUF downloads from Hugging Face, look for Bartowski's quantized versions — they're consistently high quality and cover every model in this list.