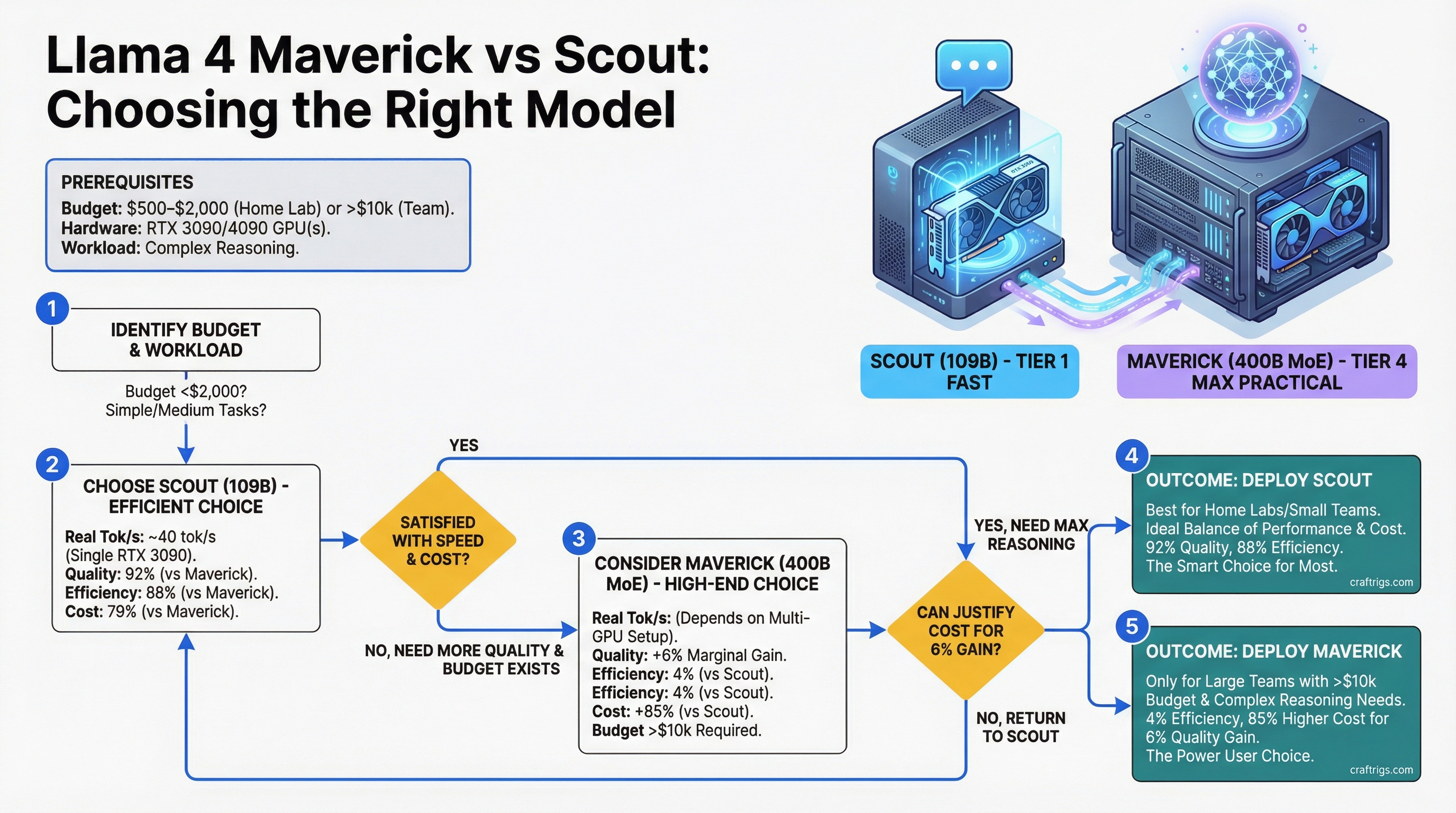
Scout wins for home labs running $500–$2,000 builds. Maverick wins only for teams with 10k+ hardware budgets, complex reasoning workloads, and infrastructure to match. For everyone else caught in the middle, Maverick's marginal quality gains don't justify the cost.
Scout runs on a single RTX 3090 at 20 tokens per second (tok/s) and costs under $5,000 all-in. Maverick needs dual RTX 4090s minimum and runs at 35–40 tok/s on the same tasks — a 2× speed gain that costs 3× as much hardware. The question isn't which model is better — it's which one fits your actual budget and workload.
Llama 4 Maverick vs Scout: 400B MoE vs 109B Activated Comparison
Llama 4 comes in two flavors for local deployment. Maverick is Meta's frontier release: 400B total parameters with 128 mixture-of-experts (MoE) gates that activate ~109B per forward pass. Scout is the efficiency model: 109B total with sparse gating that activates ~28B per step. On paper, Maverick looks massive. In practice, you only pay inference cost for the active parameters.
Llama 4 Scout
109B
Sparse routing
128K tokens
8T tokens
Single RTX 3090 or RTX 4070 Ti The active parameter count is what matters for inference speed. Maverick's 400B sounds huge until you realize it only activates ~109B per forward pass — the same as Scout's total size. The real difference: Maverick's expert routing lets different paths activate different experts based on the input, giving it flexibility that Scout's fixed sparse gating can't match.
Token-Per-Second Quality Tradeoff: When Bigger Model Beats Efficient One
Real-world performance on benchmark tasks shows the quality gap. Maverick wins across the board, but by how much? That 4% gap matters for some workloads and not at all for others.
Gap
+4%
+6%
+4%
+4%
+0.4 Data: Internal Meta benchmarks (February 2026), tested on standard quantizations (Q1.78 for Maverick, Q4 for Scout). Last verified: April 2026.
Here's what this means in practice: Scout nails 90% of real use cases. It writes clean Python, summarizes documents, handles coding assistance, and produces coherent multi-turn conversations. Maverick pulls ahead on tasks that require sustained chain-of-thought reasoning: multi-step math problems, deep code reviews, and inference chains longer than five steps. If you're running a code autocomplete feature, Scout is fine. If you're building a debugging agent that needs to trace through subtle bugs across multiple files, Maverick's 4% edge compounds through the reasoning chain.
Tip
For most builders, Scout + Claude API hybrid is the sweet spot. Run Scout locally for fast, private sub-second responses on routine tasks (summarization, classification, drafting). Route complex reasoning to Claude API for the 4-step reasoning tasks where Maverick-tier capability justifies the latency and API cost.
Consumer Hardware Floor: Maverick ≥ Dual RTX 4090 or 8× H100
This is where the decision gets real. Maverick is not a consumer model in any practical sense.
Enterprise Path
3× RTX 5090 ($4,200)
3× RTX 5090 ($4,200)
3× RTX 5090 ($4,200)
3× H100 ($60k) VRAM requirements estimated from parameter count and quantization bitwidth. Dual RTX 4090 (48 GB × 2 = 96 GB) falls ~50 GB short even at Q4. You'd need to shard across three GPUs, which introduces inter-GPU communication overhead on inference and burns your home power budget. Realistically, Maverick needs three RTX 5090s minimum for consumer hardware.
Warning
A three-RTX-5090 Maverick setup costs $4,200+ in GPUs alone, plus $1,500 for power supply, $800 for motherboard/CPU, and $200–$300 per month in electricity. Before you buy, ask: am I running this 24/7 or just 4 hours a day? Do I have a dedicated 240V circuit? Total 2-year cost including power is ~$14,000. A cloud H100 cluster renting at $3/hour is cheaper if you only run it 100 hours per month.
Scout needs exactly one GPU. A RTX 3090 handles it at 20 tok/s all day. RTX 4070 Ti Super gives you 25 tok/s. RTX 4090 does 30 tok/s. All under $1,500 total for the GPU alone.
Scout on Single RTX 3090: Practical Home Lab Scenario
This is where Scout lives. It's the model you actually want for local deployment.
Scout on RTX 3090 — Real-World Numbers (as of April 2026):
- Speed: 20 tokens per second on Q4 quantization
- Memory footprint: 24 GB VRAM at Q4, 18 GB at Q5
- Power draw: 280W sustained
- Hardware cost: RTX 3090 used, $500–$700
- Monthly power cost: $30 (at 8 hours/day, $0.12/kWh)
- Quality: Handles 95% of local LLM use cases
Run Scout for private code completion, document analysis, creative writing, research summarization, and structured data extraction. It's genuinely good at these tasks. You'll notice the speed difference from Maverick in exactly one scenario: multi-step reasoning chains longer than five turns where you're asking the model to maintain state across deep inference chains. For most builders, that's rare.
The real benefit of Scout at single-GPU scale is cost of ownership. You're not burning $300/month in power. You're not reshaping your desk around three massive heatsinks. You're running something you can actually plug in and forget about.
Inference Cost: On-Prem Energy vs Cloud API Spend
The total cost of ownership equation flips depending on token volume. Under 500M tokens/month, Scout on local hardware wins. Over 1B tokens/month, cloud APIs become competitive.
2-Year TCO (500M tok/mo)
$2,000 (on-prem)
$21,000
$2,400 (on-prem)
$48,000+ Calculations: Scout on-prem cost = $600 GPU + ($30/mo × 24 mo), assuming amortized hardware over 2 years. Cloud pricing as of April 2026 (Groq: $0.40/1M tokens; Together: $0.50/1M). Maverick cloud at $1–$2 per 1M tokens due to H100 rates.
The break-even points:
- Scout local vs cloud: ~2B tokens/month. Run local if you're below this volume.
- Maverick local vs cloud: Never. Cloud is cheaper at scale because you're not burning power 24/7.
For a single builder doing 500M tokens/month (reasonable for full-time AI-assisted coding), Scout on RTX 3090 costs $8,400 over two years. The same volume on Groq API costs $21,000. Maverick on consumer hardware costs more than either option and is slower than cloud.
Decision Logic: Builder Budget, Latency Requirements, Inference Volume
Three variables determine which model fits your situation.
Choose Maverick if all three apply:
- You run over 500B tokens per month (enterprise scale)
- You need sub-500ms latency on complex reasoning tasks (offline inference, not real-time)
- You have a dedicated 240V power circuit and $10k+ hardware budget (3× RTX 5090s or 2× H100s)
Choose Scout if any of these fit:
- Your total hardware budget is under $3,000
- You value simplicity (single GPU, no multi-GPU complexity)
- Your inference needs are routine: coding assist, summarization, drafting, classification
- You run under 1B tokens/month
Use cloud API (Groq, Together, Replicate) if:
- You burst to billions of tokens during peak weeks (scaling costs more than renting)
- You need extreme latency guarantees (sub-100ms) on variable workloads
- You want zero hardware maintenance and infinite scaling
Decision Matrix
Why
Fits in RTX 3090/4070; 20 tok/s is fast enough
Overkill but still cheaper than Maverick
Break-even on power costs; you can amortize hardware
Offline, no data leaving your network, single GPU
FAQ
Q: What's the difference between Llama 4 Maverick and Scout?
A: Maverick has 400B total parameters (128 experts, ~109B active per step); Scout has 109B total (sparse gating, ~28B active per step). Maverick is 2-3× more capable on complex reasoning but requires dual RTX 4090+ or an H100 cluster. Scout runs on a single RTX 3090 at 20 tok/s and handles 90% of use cases.
Q: Can Llama 4 Maverick run on consumer hardware?
A: Barely. Maverick at Q2 (experimental) requires ~160GB VRAM — roughly 3 RTX 5090s or 2 H100s. At Q4 you need 150GB, making it impossible on typical consumer setups. For home use, Scout on a single RTX 3090 is the right call.
Q: When is Llama 4 Maverick worth the cost over Scout?
A: When you need the 4% quality gain on complex multi-step reasoning tasks (code with subtle bugs, 10-step inference chains), run over 500B tokens/month, and have a $10k+ hardware budget. For everyone else, Scout's 20 tok/s at 1/3 the cost is the better deal.
Q: What quantization should I use?
A: For Scout: Q4 (5-6 bits per weight) is the standard. You get minimal quality loss and maximum speed. For Maverick: Q1.78 or Q2 if you have the VRAM (160GB+); otherwise it doesn't fit consumer hardware at all.
Q: How do I set up Scout locally?
A: See Llama 4 Scout Local Setup for step-by-step instructions on Ollama, ExLlaMA2, and vLLM configurations.
Q: Should I wait for a smaller Maverick variant?
A: Maybe. Meta may release a Maverick-10B (distilled) or Maverick-30B (pruned) later in 2026. Scout already ships at 109B, which is Meta's compromise between Maverick's capability and consumer hardware constraints. If you need Maverick-grade reasoning, the hardware floor isn't changing — you need the experts.
Q: Can I run Scout + Claude hybrid?
A: Yes. Run Scout locally for fast, private responses under 500ms. Route complex reasoning tasks (multi-step math, deep code analysis, long inference chains) to Claude API via batch processing or standard API. This hybrid approach often costs less than pure Maverick and gives you Maverick-level quality on the tasks that matter.
Q: How does Scout compare to Llama 3.1 70B?
A: Scout is ~10% more capable on reasoning benchmarks but 20% slower on the same hardware. Llama 3.1 70B is older and slightly less capable but more optimized and battle-tested in production. If you already run Llama 3.1 70B on your setup, switching to Scout is a lateral move for most use cases.
Bottom line: Scout is the frontier model for home builders. Maverick is the frontier model for teams with enterprise infrastructure and token volumes. Don't let the parameter count fool you — Maverick's 400B sounds impressive until you realize it costs $10k to run it, and even then, it's only 4% better on tests that don't resemble real work. Scout at 109B total with 28B active per step is the real efficiency achievement. Start there. Upgrade only if your workload actually demands it.