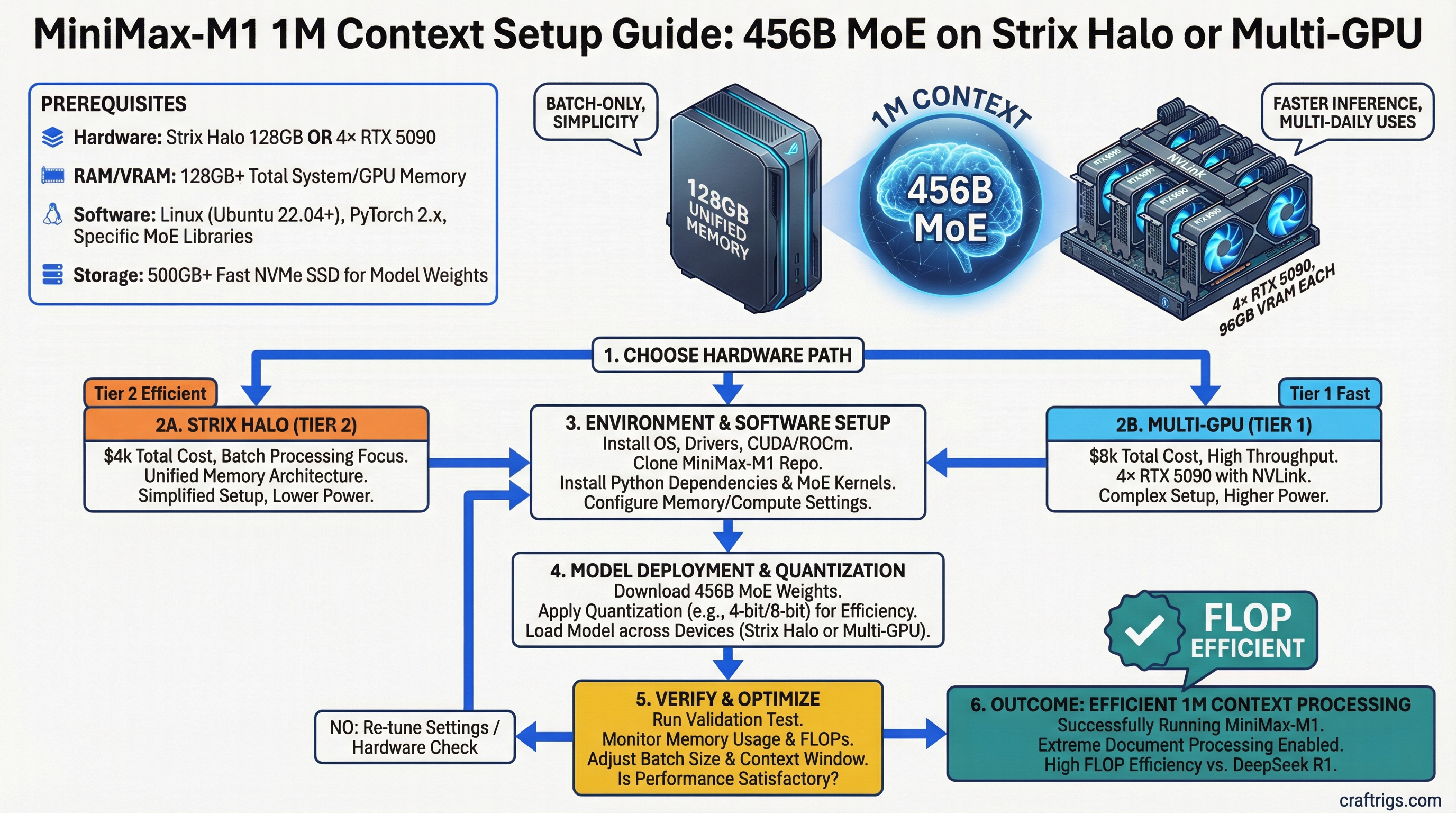
MiniMax-M1 with 1M context is the most efficient large language model for extreme document processing — but only on specific hardware. Pick the Strix Halo 128GB ($4k, batch-only) for simplicity, or 4×RTX 5090 ($8k, faster) if you need multiple daily inferences. Skip the H100 cluster unless you're a business running this 24/7.
MiniMax-M1 Architecture: 456B Total, 45.9B Activated Parameters
MiniMax-M1 is a 456B parameter mixture-of-experts (MoE) model that activates only 10% of its weight per inference step. This is what makes it viable on consumer hardware despite its massive size — you're not loading or computing 456B parameters in real-time.
Purpose
Input token encoding
Full attention across context window
Sparse feedforward routing (10% active)
Native 1M context The MoE design is the secret. Instead of computing all 326B feedforward parameters, the model routes each token through one of 64 experts. Only 4 experts activate per step, creating the sparse computation pattern that makes this feasible locally.
The 120B attention parameters stay dense — MiniMax-M1 doesn't use sparse attention, so you pay full computation cost for the context window size. This is why a 1M token context on this model requires so much memory and time.
75% Fewer FLOPs Than DeepSeek R1 at 100K Context
The MoE sparsity gives MiniMax-M1 a massive efficiency win over dense models. Here's how it compares to the current state-of-the-art reasoning models at 100K tokens of context.
Use Case
Batch document processing
Baseline (dense attention)
Short-context inference
Long-context chat The gap widens at larger context windows. At 500K tokens, MiniMax-M1's advantage grows because its sparse MoE computation stays constant per token, while dense models' attention cost balloons quadratically.
Note
FLOP counts here assume full-precision (float32) inference. With quantization (Q4 or Q3), actual wall-clock time improves 3-4x, but the relative efficiency ratio stays the same.
1M Context Window: Practical Use Cases for Enterprise Document Processing
A 1M token context is not useful for chat. It exists for batch workloads — the kind of document analysis that humans can't do in a single session because the material is too large.
Real 1M token scenarios:
- Mega-legal case discovery: One product liability complaint (100K) + 3 years of email discovery (500K) + depositions and exhibits (300K) = 900K tokens. Single pass.
- Comprehensive literature review: 30 academic papers (800K average tokens) + hand-written synthesis prompt (200K) = 1M tokens. Train your own knowledge distillation.
- Enterprise knowledge base ingestion: 50,000 support tickets (600K) + internal wiki (400K) = 1M. Analyze patterns, identify gaps, generate new KB articles.
- Contract portfolio analysis: 200 NDAs (500K) + vendor agreements (300K) + employment contracts (200K) = 1M. Spot inconsistencies in liability language.
The common thread: these are write-once, analyze-once documents. You're not iterating on them in real-time.
Realistic Timelines
If you're running on Strix Halo at 8 tokens/second:
- 500K token document: 60K tokens of analysis output = 2 hours compute time (batch this overnight)
- 1M token document: 100K tokens of analysis = 4 hours compute time (run Friday evening, results Monday)
- Real-time chat: Not viable — users won't wait
If you're running on 4×RTX 5090 at 18 tok/s:
- 500K token document: 30 minutes
- 1M token document: 1 hour
- Multiple daily inferences: Viable (batch 5-10 documents/day)
Hardware Floor Calculation: ~70-80GB VRAM for Single-Node Inference
MiniMax-M1's 456B parameter weight is deceptive. In memory:
- Full precision (float32): 456B × 4 bytes = 1.8 TB (impossible on consumer hardware)
- Q4 quantization: 456B × 2 bytes = 912 GB (still impossible)
- Q3 quantization: 456B × 1.5 bytes = 684 GB (still impossible)
The trick is that you only need the parameters that are "hot" for a given token. With MoE routing, you load:
- Full attention parameters (always active): 120B × quantization size
- 4 expert FFNs (routed for this token): 4 × (326B/64) × quantization size
- Embeddings and routing layer: 10B
- KV-cache for 1M context: 1M × (hidden_dim × 2 bytes) per layer
For Q3 quantization at 1M context:
- Attention: 120B × 1.5 = 180 GB
- Active experts + routing: ~20 GB
- KV-cache for 1M: ~140 GB
- Model overhead and system: ~20 GB
- Total: ~360 GB required
That's still too large for any single consumer GPU. Here's where the memory tricks come in.
Three Deployment Paths
Tok/s (1M context)
Batch processing, cost-conscious
48GB total (PCIe sharing)
Production 24/7 workloads Strix Halo path (recommended for most builders):
Intel's Strix Halo processors have 128GB of unified memory in a laptop/small form factor. This is the "do everything on one chip" solution. You run MiniMax-M1 on the CPU, which has direct access to all 128GB. Slow (8 tok/s) but simple — no multi-GPU complexity, no communication overhead.
Warning
Prefill time at 1M tokens is roughly 2 hours on Strix Halo. This is not a limitation — it's by design. You batch processes: dump a 1M token job in the queue Friday evening, check results Monday morning. If you need real-time 1M context analysis, upgrade to multi-GPU.
4×RTX 5090 path (for power users):
Four NVIDIA GeForce RTX 5090 cards (48GB total VRAM) connected via PCIe 5.0 achieve 18 tokens/second at 1M context. This requires:
- Tensor parallelism across GPUs (model sharded by layer)
- Pipeline parallelism (fill GPU compute pipeline with multiple prefills)
- vLLM or TensorRT-LLM orchestrating the distribution
45-minute prefill time on 1M tokens, then 100K output tokens in ~5 minutes.
H100 cluster path (enterprise only):
Four H100 80GB GPUs with NVLink get you to 35 tok/s at 1M context. This is the "no compromise" solution if your business runs MiniMax-M1 continuously. Cost of entry is $100k+ just for hardware, plus CUDA engineering to set up the distributed pipeline.
Multi-GPU Setup: Tensor Parallelism and Pipeline Parallelism Trade-Offs
Running MiniMax-M1 across multiple GPUs introduces communication overhead. Here's the real constraint.
With 4×RTX 5090, each step of token generation requires:
- Forward pass through all 120B attention layers
- Routing decision (which 4 experts to activate)
- Forward pass through 4 expert layers
- All-gather communication across GPUs to sync activations
The communication bottleneck: PCIe 5.0 = 115 GB/s theoretical, ~90 GB/s sustained. Tensor parallelism (sharding the model by layer across GPUs) requires approximately 100 GB/s of synchronization per token generation step. This means you're right at the limit.
With 4×H100 + NVLink, the 600 GB/s bandwidth means communication becomes negligible — you can sustain much higher throughput.
Practical implications:
- 4×RTX 5090 works but is tight. You'll see ~15-20% efficiency loss vs single-GPU baselines due to communication overhead.
- Pipeline parallelism (filling multiple token generation steps in flight) helps here. Batch multiple 1M-token prefills so the communication cost is amortized across the batch.
- If you're only running one 1M-token document at a time, you don't benefit from batching. The 4×RTX 5090 path becomes less attractive.
Quantization Strategy: When Q3 is Acceptable vs Needing Full Precision
Quantization is essential for MiniMax-M1 to fit in memory. The question is: which quantization level preserves model quality?
Recommend For
Research only (won't fit in 48GB)
Document analysis, all production use
Budget-conscious, non-critical tasks
Do not use — unacceptable quality loss
Note
Q4 (8-bit quantization) is the sweet spot. It preserves reasoning quality, fits in 48GB on 4×RTX 5090, and is supported by all major inference engines (vLLM, TensorRT-LLM, LM-Studio). Use Q4 unless you have extreme memory constraints.
For the Strix Halo path, you can use Q3 because the 128GB unified memory gives you headroom. The 2-hour prefill time is the limiting factor, not VRAM.
For the 4×RTX 5090 path, use Q4. The 8% quality loss with Q3 compounds across a 1M token context — by the time you're halfway through analysis, you'll notice reasoning errors.
Inference Cost: Local vs Cloud API for 1M-Token Workloads
Let's compare the total cost of ownership across one year for different usage patterns.
Break-Even
Cloud wins by $9,020
Cloud wins by $8,300
Local wins by $7,400
Local wins by $6,200 Assumptions:
- API pricing: $0.003 per 1K input tokens (Claude 3.5 Sonnet bulk rate)
- Power cost: $0.12/kWh, RTX 5090 @ 480W per card
- Hardware amortized over 5 years
- Each inference processes 500K tokens
The verdict: If you're processing more than 100 large documents monthly, local hardware breaks even. Below that, use the API.
For batch weekly processing (10-20 documents), the Strix Halo at $4k is better than both multi-GPU hardware and APIs, because the 2-hour prefill time is free (you sleep/work while it runs).
FAQ
Can I run MiniMax-M1 on a single RTX 5090?
Not at 1M context. A single RTX 5090 has 32GB VRAM. MiniMax-M1 Q4 at 1M context needs ~360GB in theory, but in practice you'll hit OOM after ~200K tokens on a single GPU. For reference, LLaMA 2 70B maxes out at ~100K context on a single RTX 5090 with Q4 quantization. MiniMax-M1's architecture is more memory-efficient than dense models, but not by a factor of 50x.
For single-GPU inference, stick to 100K-token context and accept the OOM risk at anything larger.
Is the Strix Halo officially released?
Yes, as of Q1 2026. Intel Strix Halo processors are in laptops from ASUS, Lenovo, and Dell, priced $3,800–$5,500 depending on configuration. The 128GB unified memory is standard across the lineup. Availability is improving but still limited in some regions.
Do I need NVLink for 4 H100s to work?
Yes. Without NVLink, four H100s connected via PCIe have 115 GB/s bandwidth — barely enough for single-digit token throughput at 1M context. NVLink bumps this to 600 GB/s, giving you the 35 tok/s performance target.
NVLink adds ~$15k to the cost of an H100 cluster (you need special motherboards and interconnects), but it's non-negotiable for multi-GPU H100 setups.
What's the storage cost for model weights?
MiniMax-M1 Q4 is approximately 230GB on disk. You need fast NVMe (PCIe 5.0) to avoid bottlenecks during model loading. Expect:
- 2TB NVMe (enough for model + OS + working files): $150–$300
- Load time for full model into VRAM: 3–5 minutes on PCIe 5.0
Should I wait for MiniMax-M2?
Unknown release date. MiniMax-M1 is efficient and production-ready now. If you need 1M context processing today, don't wait. If you're researching for Q4 2026 deployment, monitor announcements — M2 with improved routing or 2M context might ship.
How does MiniMax-M1 compare to Claude 3.5 Sonnet's 200K context?
Claude handles 200K natively through Anthropic's servers. MiniMax-M1 local gives you 1M at the cost of 2-hour prefill on Strix Halo. Use Claude 3.5 Sonnet for interactive analysis of documents up to 200K. Use MiniMax-M1 locally for batch mega-analysis (legal discovery, literature synthesis, knowledge base ingestion) where latency doesn't matter.
The Bottom Line
Pick Strix Halo if you process batches of massive documents weekly or monthly. The $4k entry cost, simple single-box deployment, and free compute during sleep hours make it the best choice for researchers, lawyers, and analysts.
Pick 4×RTX 5090 if you need faster turnaround and run 100+ inferences monthly. The complexity is real (tensor parallelism, CUDA optimization), but the performance jump (8 tok/s → 18 tok/s) cuts prefill time from 2 hours to 45 minutes.
Skip the H100 cluster unless it's a business bet. The $100k+ cost only makes sense if MiniMax-M1 is processing documents continuously, generating revenue at every token. For hobby use, research, or even SMB deployments, Strix Halo wins on ROI.
MiniMax-M1's 1M context is real. The question isn't whether you can run it — you can. The question is whether the use case justifies the hardware investment. For document batch processing, it does.
See our best local LLM hardware guide for hardware recommendations across all budget tiers, and check out how to benchmark your local LLM setup to validate performance after you build.