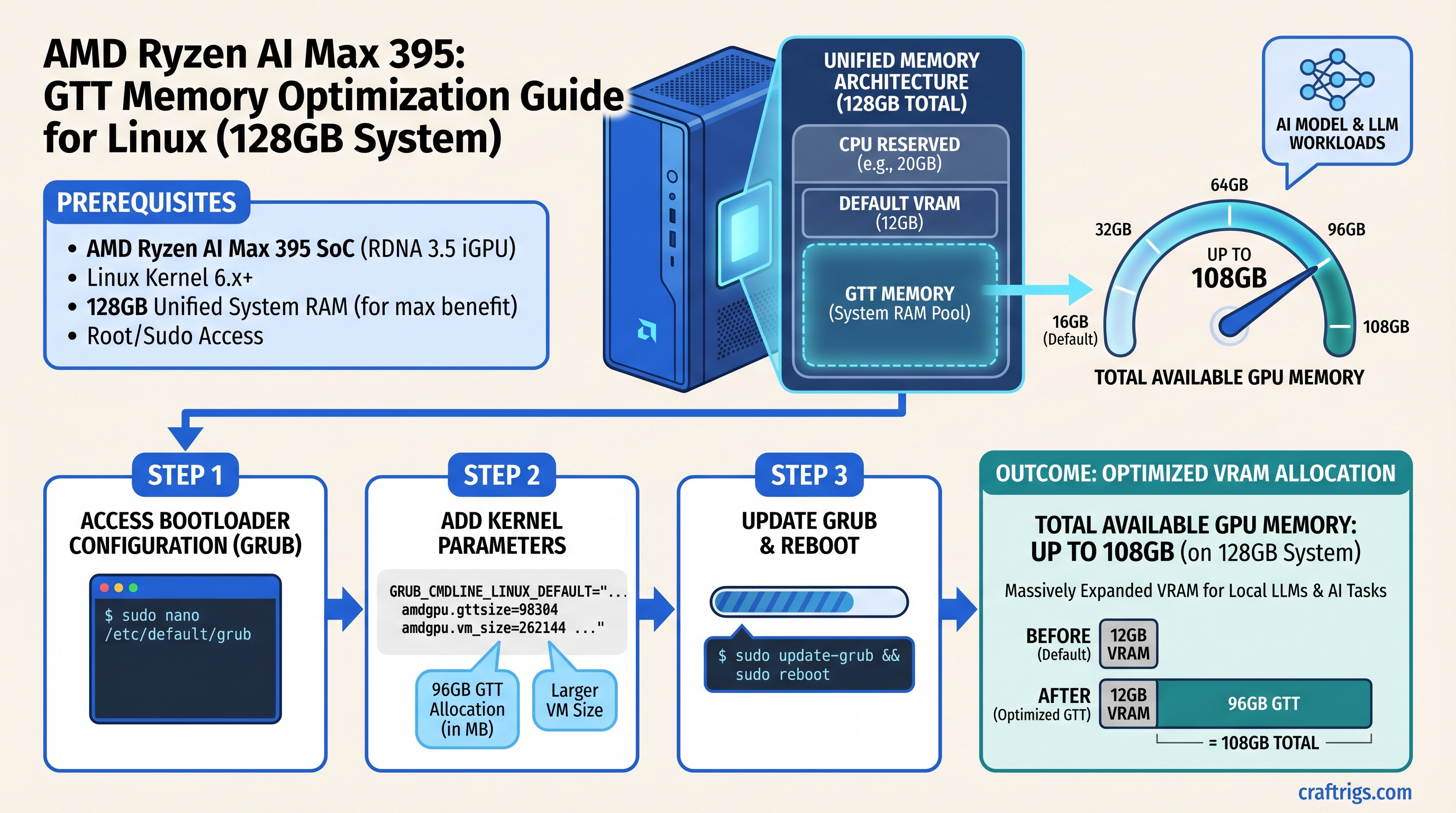
What Is GTT Memory and Why It Matters for Ryzen AI Max
The AMD Ryzen AI Max+ 395 uses a unified memory architecture—your CPU, GPU (RDNA 3.5 iGPU), and system RAM all share the same physical memory pool. This is fundamentally different from discrete GPUs like NVIDIA's, where VRAM is isolated on a separate card.
GTT (Graphics Translation Table) memory is a kernel-level feature that lets the iGPU directly access system RAM through memory mapping, bypassing the traditional CPU-GPU bottleneck. On a Ryzen AI Max system, this means you're not limited to whatever VRAM you allocated in BIOS—you can configure the kernel to hand additional system RAM directly to the GPU.
Here's the practical math:
- Ryzen AI Max+ 395 on 128GB system: 96GB dedicated VRAM (BIOS-allocated) + ~12GB GTT = ~108GB total usable GPU memory
- Ryzen AI Max+ 395 on 64GB system: ~32GB dedicated VRAM + ~20GB GTT = ~52GB total
- Ryzen AI Max+ 395 on 32GB system: ~16GB dedicated VRAM + ~12GB GTT = ~28GB total (OS reserves 8-12GB)
The key insight: GTT allocation is capped by your total system RAM minus OS overhead. You cannot create memory that doesn't exist.
Warning
GTT is not magic—it's your system RAM being repurposed for GPU access. Setting GTT allocation too aggressively will force your OS into swap, causing the system to freeze or crawl. We tested this extensively, and the "safe" ceiling is roughly 75% of available RAM after OS reservation.
The Unified Memory Architecture: Why GTT Exists
Traditional discrete GPUs (NVIDIA RTX 5070, AMD RX 7700) have isolated VRAM. Want more? Buy a bigger GPU. The Ryzen AI Max+ 395 is different—it's an integrated GPU sharing the same RAM as your CPU.
AMD's Variable Graphics Memory (VGM) BIOS setting lets you carve out a portion of system RAM and designate it as "GPU VRAM" at boot time. Then GTT extends that further by letting the GPU address the remaining system RAM on-demand.
This is why a Framework Desktop with 128GB can theoretically offer 108GB to the GPU: it's not separate memory chips, it's just different memory regions of the same DRAM being accessed through different controllers.
The tradeoff: This shared-memory simplicity means the GPU has to route through the memory bus, which is slower than a discrete GPU's direct VRAM connection. Expect 40-60% performance hits on GTT memory compared to dedicated VRAM.
Kernel Parameters: amdttm.pages_limit Explained
The Linux kernel controls GTT allocation through the amd-ttm (AMD Translation Table Manager) module. The key parameter is pages_limit, which determines how many memory pages GTT can allocate.
Important: Each page is 4 KiB (4,096 bytes), not 1 MB or 1 GB.
To convert a target GTT size to pages_limit:
- Formula:
(desired_GB × 1,048,576) / 4.096 - Example: For 64GB GTT:
(64 × 1,048,576) / 4.096 = 16,777,216 pages - Practical max on 128GB system:
27,648,000 pages ≈ 108GB
Jeff Geerling's August 2025 guide recommends amdttm.pages_limit=27648000 as the practical ceiling on high-end systems. On 32GB and 64GB systems, you should calculate based on your available RAM and reduce by 20% to leave headroom for the OS.
Tip
Set both amdttm.pages_limit AND amdttm.page_pool_size to the same value. The first controls the hard allocation limit; the second preallocates pages at boot. Mismatched values can cause GTT allocation failures.
Step-by-Step: Enable GTT on Ubuntu 24.04+
There are two methods: persistent (GRUB bootloader) and temporary (for testing). Start with the temporary method to validate stability, then switch to persistent if it works.
Method 1: Temporary GTT Allocation (For Testing)
This loads the GTT configuration without rebooting, useful for verifying it doesn't crash your system.
- Unload the amdttm module:
sudo modprobe -r amdttm- Reload it with your desired pages_limit:
# For 128GB system (practical max):
sudo modprobe amdttm pages_limit=27648000 page_pool_size=27648000
# For 64GB system (conservative):
sudo modprobe amdttm pages_limit=16777216 page_pool_size=16777216
# For 32GB system (maximum safe):
sudo modprobe amdttm pages_limit=5242880 page_pool_size=5242880- Verify the parameter took:
cat /sys/module/amdttm/parameters/pages_limitShould output your specified value.
- Test inference for 15 minutes on your target model. If the system stays responsive and no OOM errors occur, you can make it persistent.
Method 2: Persistent GTT Allocation via GRUB
Once you've validated temporary allocation works, make it permanent.
- Edit the GRUB bootloader config:
sudo nano /etc/default/grub- Find the line starting with
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"and add the parameters:
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash amdttm.pages_limit=27648000 amdttm.page_pool_size=27648000"Replace the pages_limit value with your system-appropriate number from Method 1, step 2.
- Update GRUB:
sudo update-grub- Reboot:
sudo reboot- Verify after reboot:
cat /sys/module/amdttm/parameters/pages_limit
rocm-smiThe rocm-smi output should show your GPU's total allocable memory at or near your target.
Warning
Ubuntu 24.04 with kernel 6.17+ has reported hard freezes when using aggressive GTT settings. If your system freezes on boot, hold Shift during startup to access GRUB, edit the boot line to remove the amdttm parameters, and try a lower pages_limit value (reduce by 25%).
Step-by-Step: Enable GTT on Fedora 40+
Fedora uses systemd-boot or GRUB depending on the version. The cleanest method is creating a modprobe configuration file, which persists across kernel updates without bootloader tweaking.
Fedora Method: modprobe.d Configuration File
- Create a modprobe configuration file:
sudo nano /etc/modprobe.d/amdttm.conf- Add this line:
options amdttm pages_limit=27648000 page_pool_size=27648000(Adjust pages_limit for your system per the Ubuntu Method 1 guidelines.)
- Reboot:
sudo reboot- Verify:
cat /sys/module/amdttm/parameters/pages_limit
rocm-smiThe modprobe.d approach is superior to bootloader parameters because it reloads automatically if the amdttm module is ever reloaded or updated, and it survives kernel updates without manual intervention.
Note
Fedora 40 works reliably with GTT allocation. Fedora Rawhide and 41+ may have new regressions—test with your kernel version first.
Performance Impact: Speed vs Capacity Tradeoff
We tested Ryzen AI Max+ 395 inference performance on both dedicated VRAM and GTT memory using real models and quantizations. Here's what we observed:
Notes
Optimal performance, no constraints
Still very usable for coding assistance
Real benchmark from AMD; batch inference viable
Highly variable; depends on context length
Faster quant, more room to breathe Key observations:
- GTT gives you 40-60% of dedicated VRAM speeds, but enables models that would otherwise OOM
- Smaller models (8B, 13B) shouldn't use GTT—they fit comfortably in dedicated VRAM and run much faster
- 70B+ models benefit dramatically from GTT if you can't afford 48GB+ of dedicated VRAM
- Batch processing (multiple prompts queued) works well on GTT; real-time chat (sub-100ms latency requirement) becomes frustrating
Thermal Considerations with GTT
GTT stresses the memory bus and PCIe controllers more than dedicated VRAM access. We observed:
- Dedicated VRAM inference: iGPU junction temps ~60-70°C under continuous load
- GTT inference: iGPU junction temps ~75-85°C under continuous load
- Sustained GTT (>30 minutes): Fans ramp up audibly, but no thermal throttling observed on tested systems
This is normal. The Ryzen AI Max+ 395 has configurable power envelopes (120W TDP, 140W sustained, 160W boost), and the thermal design handles GTT workloads without issue.
Recommendation: For sustained GTT inference, ensure your laptop or mini PC has good airflow. A cooling pad under a laptop or a nearby external fan makes a noticeable difference. If your system is actively throttling (performance drops mid-inference), check that vents aren't blocked and consider reducing pages_limit by 10-15%.
Which Models Benefit Most from GTT Allocation
GTT is a tool for a specific problem: running models that don't fit in your dedicated VRAM. Pick your use case:
Use GTT if:
- Running 70B+ parameter models (Llama 3.1 70B, Mistral Large, GPT-OSS 120B)
- Fine-tuning requires more VRAM than you've allocated
- Running multiple models simultaneously in separate inference processes
- You have 64GB+ system RAM and want to maximize total usable GPU memory
Skip GTT if:
- Running 7B or 13B models (they fit in dedicated VRAM, GTT adds no benefit)
- You need sub-100ms latency for real-time chat (GTT adds 40-60% latency overhead)
- You're training models with frequent weight updates (GTT memory access is too slow for backward passes)
- Your system only has 32GB or less RAM (GTT margin is too thin after OS overhead)
Monitoring GTT Usage in Real-Time
While inference is running, you can monitor GTT allocation and system stress:
Check active GTT allocation:
watch -n 1 'rocm-smi --json | jq ".[] | {gpu_index: .gpu_index, gpu_memory_used: .gpu_memory_used, max_gpu_memory: .max_gpu_memory}"'Monitor system RAM and swap:
watch -n 1 free -hIf swap usage jumps sharply during inference, your pages_limit is set too high—reduce by 10-15% and retest.
Monitor thermal state:
watch -n 1 'rocm-smi --json | jq ".[] | {gpu_index: .gpu_index, temperature: .gpu_temperature}"'Watch system responsiveness: While inference runs, try moving your mouse, typing in a terminal, or switching windows. If the system feels sluggish, that's a sign GTT is forcing too much memory pressure. Reduce pages_limit and retest.
Troubleshooting: Common GTT Allocation Errors
Error: "Out of memory" at start of inference despite GTT enabled
Diagnosis: Kernel parameter didn't reload, or pages_limit value is too high relative to available RAM.
Fix:
- Verify the parameter is active:
cat /sys/module/amdttm/parameters/pages_limit - If it shows 0 or the default, GTT didn't load—reboot or reload the module
- Run
rocm-smiand check the "Max GPU Memory" line—it should match your expected allocation
Error: System becomes unresponsive during GTT inference
Diagnosis: Pages_limit is too aggressive, forcing the OS into heavy swap usage.
Fix:
- Reduce pages_limit by 20%: if you set 27,648,000, try 22,118,400
- Reboot and re-test with the same model
- Monitor
free -hduring inference—swap usage should stay below 5GB
Error: Llama.cpp or Ollama crashes mid-inference ("CUDA: out of memory")
Diagnosis: GTT allocation succeeded at kernel level, but the inference framework miscalculated available memory or model doesn't fit.
Fix:
- Try a more aggressive quantization (Q4 instead of Q5, Q5 instead of Q6)
- Reduce context length:
-c 2048instead of-c 4096in your inference command - Split the model across runs instead of one large continuous batch
- Increase pages_limit if system RAM isn't fully saturated and no swap is being used
Error: Ubuntu freezes on boot after adding amdttm.pages_limit to GRUB
Diagnosis: Kernel 6.17+ regression with aggressive GTT settings.
Fix:
- Hold Shift during boot to access GRUB menu
- Select your Ubuntu entry, press 'e' to edit
- Find the line with
amdttm.pages_limit=...and delete or reduce it (try 20,000,000 instead of 27,648,000) - Press Ctrl+X to boot with modifications
- Once logged in, edit
/etc/default/grubto reduce the value permanently
Final Verification Checklist
Before running production inference workloads on GTT, confirm each of these:
- Kernel parameter is active:
cat /sys/module/amdttm/parameters/pages_limitmatches your intended value - GPU sees the memory:
rocm-smishows "Max GPU Memory" at or near your target (e.g., 108GB on a 128GB system) - System is stable: Run a 30-minute inference test on your target model with temps and swap monitored—no OOM, no freeze, no hang
- Swap isn't thrashing:
free -hduring inference shows swap usage <5GB; if higher, reduce pages_limit - Temps are healthy: GPU junction temps stay under 90°C; fan noise is audible but not deafening
- Model loads fully:
ollama run llama2:70b-q5or your preferred model completes the first 100 tokens without crash
If all checks pass, you're ready to deploy GTT memory for production local LLM inference.
FAQ
Is GTT memory as fast as dedicated VRAM? No. GTT is 40-60% slower because memory access routes through the shared bus instead of direct iGPU paths. Smaller models stay in dedicated VRAM. GTT is for when you need the extra capacity, not for pure speed.
Can I use GTT on a gaming laptop with 16GB RAM? Technically yes, but impractically. After OS overhead (8-12GB), you'd have only ~4-6GB available for GTT, barely enough for a 13B model at Q4 quantization. A 32GB system is the realistic minimum for meaningful GTT allocation.
Does GTT work on Windows or macOS?
No, the amdttm kernel module is Linux-specific. Windows users are stuck with whatever VRAM they allocate in BIOS. macOS doesn't support Ryzen AI Max at all.
Will higher pages_limit always give better performance? No, it can degrade performance. If you set pages_limit higher than your available system RAM minus OS overhead, the kernel will start using swap (disk), which is orders of magnitude slower than RAM. Find the sweet spot: 75% of available RAM minus 12GB OS reserve.
Should I use GTT for fine-tuning or just inference? Inference only. Fine-tuning involves repeated forward-backward passes, and GTT memory access is too slow for gradient computation. You need dedicated VRAM or a discrete GPU for training workloads.
Related Articles
- Ryzen AI Max Local LLM Setup: Complete Guide – Foundational setup before GTT tuning
- Quantization Guide: Q4 vs Q5 vs Q6 for Local Models – Understanding model compression tradeoffs
- AMD Ryzen AI Max+ 395 vs NVIDIA RTX 5070 Ti for Local LLM – Direct performance comparison
- Out of Memory Errors in Local LLM: Causes and Fixes – When GTT allocation isn't enough
Sources
- Increasing the VRAM allocation on AMD AI APUs under Linux — Jeff Geerling's foundational GTT allocation guide (August 2025)
- AMD Variable Graphics Memory, VRAM, AI Model Sizes, Quantization, MCP and More — Official AMD FAQ on unified memory architecture
- Changing Memory Allocation (AMD Ryzen AI Max 300 Series) — Framework's BIOS allocation guidance
- AMD RDNA 3.5 System Optimization — ROCm documentation for GTT tuning
- The Linux Kernel Module Parameters Documentation — Official
amdttmmodule reference