You need 40–80GB of VRAM for real 70B model work. That's the ceiling everyone hits. Consumer GPUs top out at 24GB (RTX 3090) or 16GB (RTX 5070 Ti). Used A100 80GB units haven't dropped below $4,800 on the secondary market the way everyone was hoping they would. Dual RTX 3090 NVLink setups give you 48GB — barely enough for 70B at Q4, nothing more. Everyone watching this space has been waiting for a break in the math.
The Intel Arc Pro B65 might be it. Maybe.
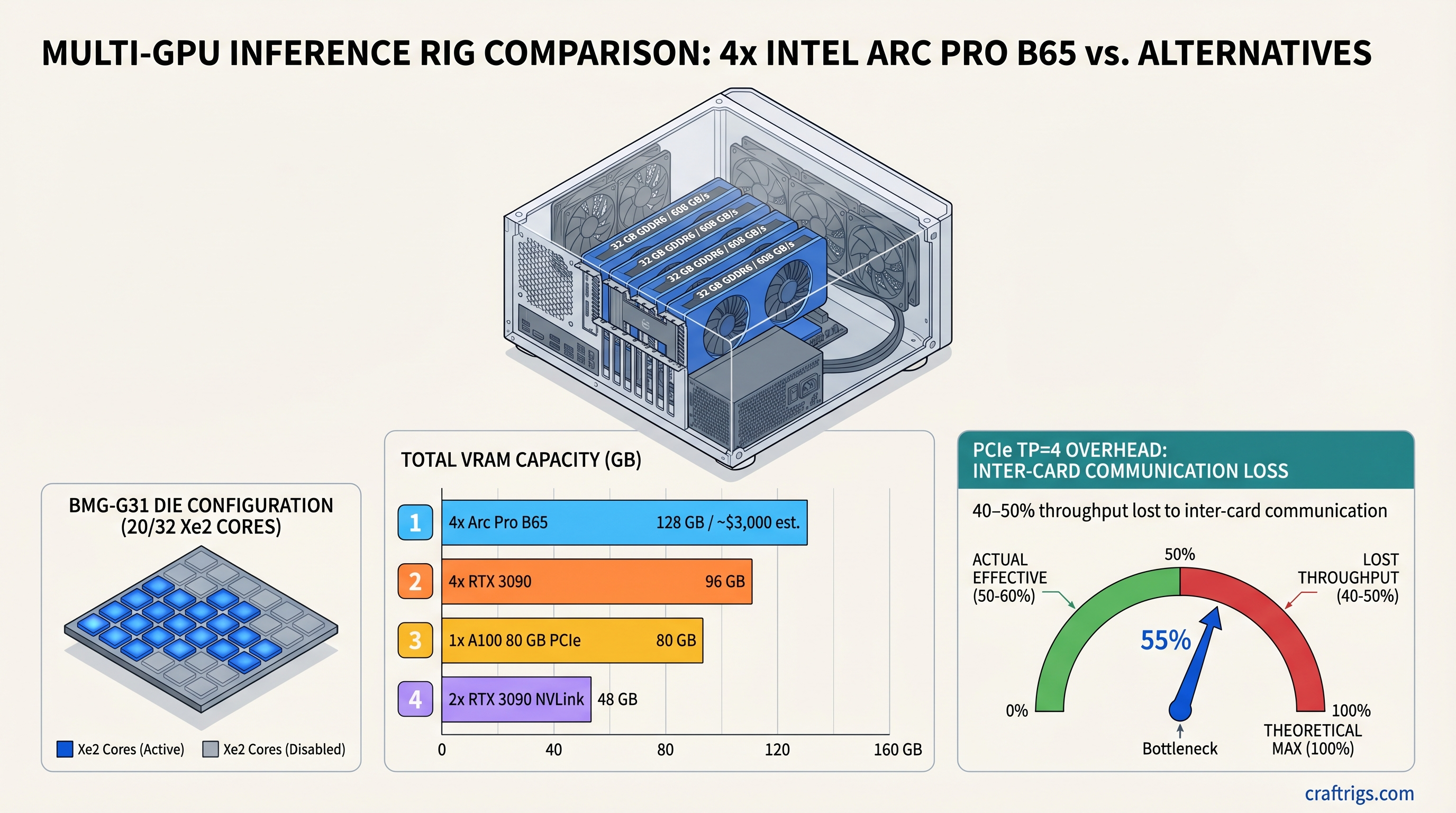
TL;DR: The Intel Arc Pro B65 delivers 32GB GDDR6 per card — identical memory specs to the $949 B70 — on a lower-compute die positioned below $949. Four cards reach 128GB VRAM via Intel's XPU tensor parallelism stack, enough for 70B models at Q8_0 or 120B-class models at Q4. Intel's vLLM XPU backend is actively maintained and production-usable in April 2026. The real constraints: B65 street pricing isn't confirmed yet (the "4x = $1,600" figure circulating online is unverified; industry expects $700–800 per card, putting a 4-card rig at ~$3,000), PCIe-based tensor parallelism loses 40–50% of theoretical throughput to inter-card communication overhead, and OneAPI has real gaps versus CUDA for fine-tuning workflows. If you need 128GB and can tolerate software roughness, this is worth a hard look. If you need the rig running today, two used RTX 3090s with NVLink is still the more reliable path to 70B inference.
Intel Arc Pro B65 32GB — Full Specs and What Intel Actually Shipped
The B65 isn't a new chip. It's the same BMG-G31 silicon that powers the B70, with 12 of 32 Xe2 cores disabled and the clock dropped from 2,800 MHz to 2,400 MHz. Intel left the memory configuration completely intact. Both cards ship 32GB GDDR6 on a 256-bit bus at 19 Gbps — meaning identical 608 GB/s memory bandwidth regardless of which card you buy.
This decision matters enormously for quantization-driven LLM inference workloads, where the memory subsystem is almost always the bottleneck, not raw compute. Losing 37% of the Xe2 cores hurts rendering and model training. For inference on models in the 7B–70B range, where you're constantly streaming weights from VRAM at near-saturation bandwidth, the compute reduction is genuinely less punishing.
Spec Sheet — VRAM, Bandwidth, TDP, and Architecture
Intel Arc Pro B70
32
256
367
32 GB GDDR6
256-bit
608 GB/s
2,800 MHz
~300W
PCIe 5.0 x16 Specs from Intel product specifications page, verified April 2026.
B65 Pricing and Availability as of April 2026
Intel positioned the B65 as AIB-only — no Intel-branded card. Partners confirmed include ASRock (passive and Creator variants), Sparkle (passive and blower), and Gunnir. Availability landed mid-April 2026 per Intel's original roadmap.
Intel published no MSRP for the B65. Based on the B60's ~$660 street price and the B70's confirmed $949, AIB partners and analysts have estimated the B65 at $700–800 per card.
Warning
The "4x B65 = $1,600" figure ($400/card) circulating in some previews is not supported by confirmed retailer pricing. At the industry-expected $700–800 range, four cards total approximately $2,800–$3,200. That's still competitive against a used A100 80GB PCIe at $4,800+, but verify current street prices before committing to any build math.
Arc Pro B65 vs B70 — What You Sacrifice for a Lower Per-Card Price
Both cards have identical VRAM and identical bandwidth. What you lose going B65 over B70: 37% of the compute cores, 46% of INT8 TOPS, and 14% of clock speed. Intel's own MLPerf v6.0 benchmark submission showed the B70 delivering 1.8× higher inference throughput than the Arc Pro B60. The B65 sits between those two on the compute stack, closer to B70 in memory terms, closer to B60 in throughput terms.
For workloads that are genuinely memory-bandwidth-bound — streaming weights from VRAM to feed attention layers in 70B inference — that compute gap shrinks. For batch serving with high concurrency, it shows.
Side-by-Side Specs — VRAM, Bandwidth, Compute
See the table above. The short version: memory is identical. Compute is not. The 608 GB/s bandwidth is the same on both cards — that's the number that determines how fast you can stream model weights during inference.
Per-Card vs Per-GB Cost: Which Scales Better at 4x?
At an estimated B65 price of $750 per card:
- Per GB of VRAM: $750 ÷ 32 = $23.44/GB
- 4× B65 total: ~$3,000 for 128 GB
- Per-GB cost scales linearly — memory config doesn't change with the die cut
At B70's confirmed $949:
- Per GB of VRAM: $949 ÷ 32 = $29.65/GB
- 4× B70 total: ~$3,796 for 128 GB
If B65 confirms at $750, a 4-card B65 rig delivers the same VRAM as 4× B70 for ~$800 less. The compute cores you sacrifice matter more at training time. For memory-bandwidth-bound 70B inference where you're saturating VRAM throughput, the B65 is the smarter scaling bet — assuming price lands where analysts expect.
4x B65 = 128GB — Does the Multi-Card Scaling Math Actually Hold Up?
128 GB of VRAM across four cards sounds like a clean win. It's not that simple. Those four cards connect via PCIe, not NVLink. Every all-reduce synchronization during tensor parallelism has to traverse that bus. And PCIe is slow.
Tensor Parallelism Overhead — The Number That Changes Everything
PCIe Gen 5 x16 provides approximately 64 GB/s of bidirectional bandwidth. NVLink 4.0 provides 900 GB/s. That's a 14× gap in inter-GPU communication speed. In practice, according to vLLM's distributed inference documentation, PCIe-based tensor parallel setups at TP=4 lose 40–50% of theoretical throughput to inter-card communication overhead.
The practical translation: a 4× B65 setup has 4× the memory capacity but realistically delivers 2×–2.5× the single-card inference throughput. You're paying for VRAM, not for 4× speed. Intel's 4-GPU benchmark submission with llm-scaler-vllm showed approximately 369 tok/s aggregate output throughput across 50 concurrent requests at 1,024-token context — that's a high-concurrency serving number, not single-user streaming latency.
Note
This isn't an Intel problem specifically. Four RTX 3090s in a PCIe-only chassis (no NVLink between card pairs 3 and 4) has identical overhead. The limitation is the interconnect, not the vendor. NVLink effectively requires datacenter hardware — H100 SXM, A100 SXM — to eliminate the bottleneck at TP=4.
What Models Fit at 128GB and How Fast Do They Actually Run?
Intel's MLPerf v6.0 submission (April 2026) validated a 4-card B70/B65 system running 120B-parameter models at high concurrency. Here's the practical model fit picture:
Fits 4× B65?
Yes
Yes
Yes
Yes (2 cards min)
Yes (2 cards min)
Yes
Yes
Yes (MLPerf-validated)
No For single-user 70B inference at Q4_K_M across 2× B65, expect 15–25 tok/s — functional for private inference or low-concurrency work, not for production serving at scale. Intel doesn't publish standalone B65 benchmarks for this config yet; numbers will sharpen as AIB cards reach reviewers.
Total Build Cost Breakdown — 4× B65 vs Every Real Alternative
Est. Cost (April 2026)
OneAPI / vLLM-XPU
CUDA
CUDA
CUDA All prices April 2026. B65 per-card price estimated; not confirmed by retailers at publication.
The B65 4× setup wins on VRAM at its price tier. The RTX 3090 4× wins on bandwidth and software maturity. The A100 single-card wins on effective throughput-per-dollar at sustained high concurrency — if you can absorb the upfront cost. The 2× RTX 3090 NVLink is still the best value play for anyone whose ceiling is 70B at Q4.
vLLM + Intel OneAPI — What Runs Today vs What's Still Broken
This is the section other Arc Pro B65 previews are quietly glossing over. The hardware ships with a real software gap. Not a fatal one — but a gap you need to understand before committing to a $3,000 build.
Intel's inference stack has matured significantly through 2025–2026. The vLLM blog post on Arc Pro B-Series GPUs from November 2025 and the llm-scaler-vllm 0.14.0-b8 release in March 2026 both confirm a working, actively maintained pipeline. But "works" and "painless" aren't the same thing.
Inference Stack Compatibility Matrix — April 2026 Status
Notes
Intel's modified Ollama with full Arc GPU acceleration
No native Arc support; must use IPEX-LLM fork
Intel-patched transformers with XPU backend
torch-xpu ships with OneAPI dependencies bundled
Less complete than GGUF support on Arc Status as of April 2026. Intel llm-scaler-vllm 0.14.0-b8, OneAPI 2025.3.2 LTS.
OneAPI vs CUDA — The Maturity Gap That Actually Matters
CUDA has 17 years of production deployment behind it. OneAPI has roughly 4. The gap isn't marketing spin — it shows up in concrete ways: fewer community examples, less StackOverflow coverage, and third-party libraries that quietly assume CUDA at the kernel level and haven't been ported.
The core inference path is solid. vLLM XPU works. IPEX-LLM Ollama works. Where you hit friction is at the edges: LoRA fine-tuning frameworks with hardcoded CUDA memory management, quantization workflows that haven't been adapted for XPU backends, and production deployment tooling built around NVIDIA all the way down.
If your workflow is pull a model → run vLLM → serve inference → repeat, you're functional today. If your workflow involves custom CUDA kernels, cutting-edge quantization formats, or fine-tuning pipelines that haven't been tested on Arc, budget time for debugging.
Arc Pro B65 vs Used RTX 3090 — Two Very Different Bets
At roughly the same per-card price (~$700–800), the RTX 3090 24 GB and Arc Pro B65 32 GB represent the two most interesting single-card options for builders working toward large VRAM pools. They make opposite trade-offs, and both are defensible depending on your situation.
Single-Card Comparison — 32 GB vs 24 GB at Comparable Price Points
The RTX 3090 has higher memory bandwidth (936 GB/s vs 608 GB/s), giving it faster weight streaming and lower time-to-first-token on large models. It has full CUDA support, meaning every inference tool in the r/LocalLLaMA ecosystem works without a fork or workaround. And at $670–800 used, it has known pricing — not estimates.
The B65 gives you 33% more VRAM per card. That's not nothing. A 32 GB card runs Qwen 2.5 32B at Q4_K_M without touching a second card. The RTX 3090 doesn't. For models in the 25–32 GB loaded range, B65 is the cleaner single-card solution. For everything smaller, the RTX 3090's bandwidth advantage and software maturity win.
Scaling Play — 4× B65 vs 4× RTX 3090 — What Each Setup Gets You
Four RTX 3090s at ~$3,000 get you 96 GB of VRAM, 3,744 GB/s aggregate bandwidth, and the full CUDA software stack. Note that RTX 3090 NVLink only works in pairs — a 4-card setup uses PCIe between the second card pair, giving you the same TP=4 communication overhead as the B65. You're not escaping PCIe bottlenecks with a 4× RTX 3090 build either.
Four B65s at ~$3,000 (estimated) get you 128 GB of VRAM — 32 GB more headroom — at lower aggregate bandwidth and with Intel's software ecosystem. The extra 32 GB is the entire argument. If your target models fit in 96 GB, there's no hardware case for B65 over RTX 3090 right now. If you specifically need 128 GB, there's no consumer alternative at this price point.
Tip
Two used RTX 3090s with a NVLink bridge (~$1,500 total) give you 48 GB, effective ~1,800 GB/s inter-GPU bandwidth, and solid CUDA support. That setup runs 70B at Q4_K_M today with no software roughness. If 48 GB is enough for your workload, it's the most practical path to large-model inference in 2026.
Should You Build a 4× B65 Inference Rig Today?
The hardware is real. The software works. The B65 pricing uncertainty is the wildcard, and the PCIe TP overhead is a known, unavoidable constraint. Here's the decision by workload:
If You're Running Llama 3.1 70B or Llama 4 Scout Today
Wait, or buy used RTX 3090s. Two RTX 3090s with NVLink gives you 48 GB at ~$1,500 — comfortably runs 70B at Q4_K_M, full CUDA ecosystem, no software surprises. That setup exists today with confirmed pricing and real-world benchmarks behind it. Unless you specifically need 70B at Q8_0 or are targeting 80B+ models, 4× B65 is overbuilt and adds software risk you don't need.
If You're Fine-Tuning or Need Reliable Batch Inference
Not yet. Fine-tuning is where OneAPI friction is highest. Axolotl, Unsloth, and PEFT all carry CUDA assumptions that require workarounds on Intel Arc. Production batch inference via vLLM XPU works, but you're further from the community support path than with CUDA — and when things break at 2am, that matters.
If You're Willing to Wait 6 Months for Better Driver Coverage
This is where the B65 gets genuinely interesting. Intel's software velocity has been real: llm-scaler-vllm jumped from B60-class performance to 1.49× gains on BMG-G31 silicon in a single release. If B65 street pricing confirms at or below $800, and six more months of OneAPI tooling maturity close the remaining gaps, a 4× B65 rig at ~$3,000 for 128 GB VRAM becomes a serious value play against anything else at that price tier.
The full 2026 GPU landscape — including where B65 sits against NVIDIA's current generation — is covered in our best hardware guide for local LLMs.