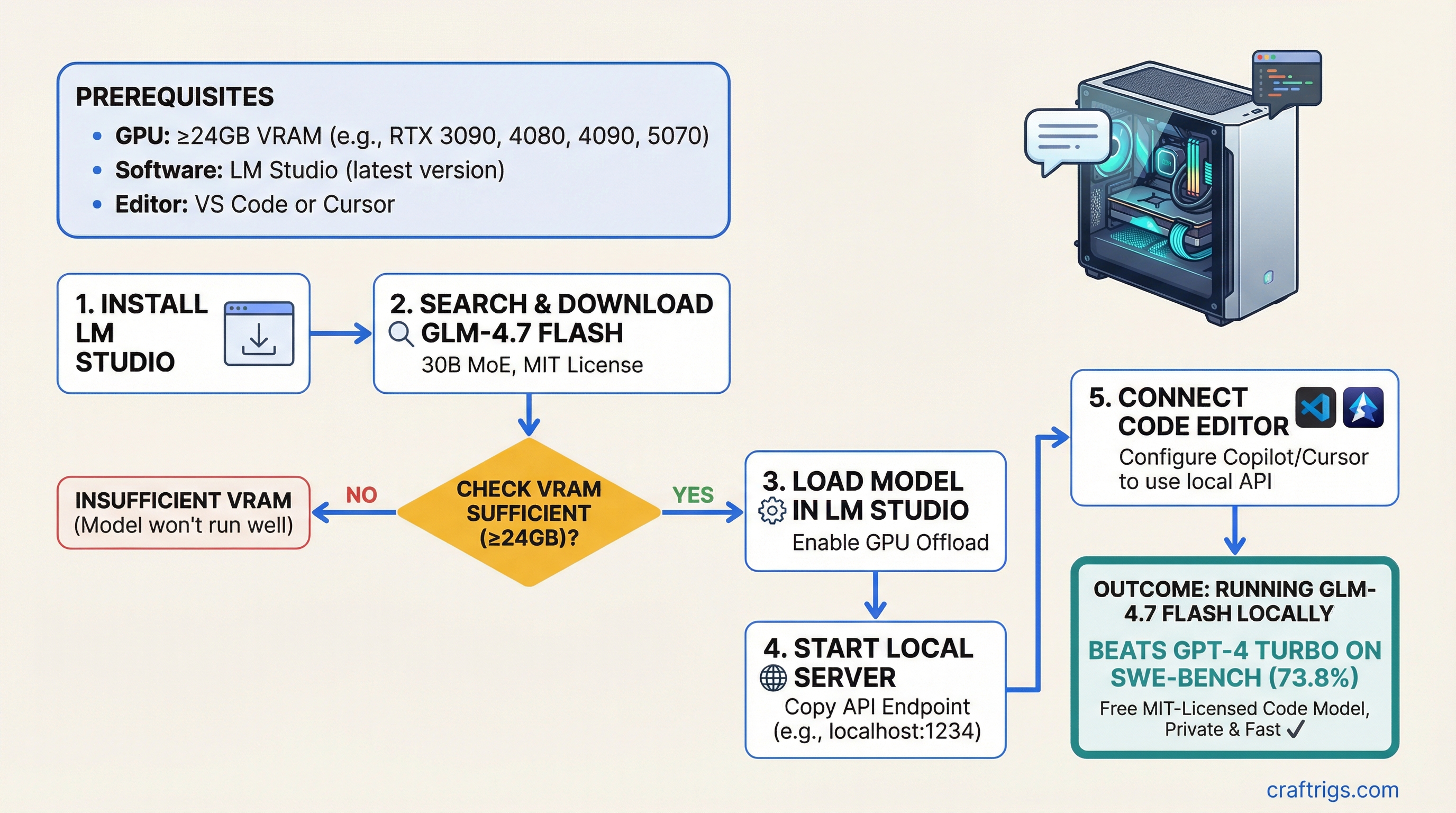
GLM-4.7 Flash is a 30B mixture-of-experts model that beats GPT-4 Turbo on SWE-bench, runs locally on a 24GB GPU, and comes with MIT licensing so you can use it commercially. If you've got an RTX 3090, 4080, 4090, or 5070, you can download and run it in LM Studio in under 30 minutes. VRAM requirements are modest by modern standards — this model was designed for mid-range consumer hardware.
GLM-4.7 Flash: 30B MoE, 73.8% SWE-Bench, MIT License Advantage
Here's what separates GLM-4.7 Flash from the crowded field of code models. It's a 30B mixture-of-experts architecture, which means only 4.2B parameters activate per forward pass. You get 70B-class reasoning without 70B memory footprint.
Alibaba's engineering team trained it on 2 trillion tokens of code and text, then fine-tuned it specifically to solve real GitHub issues. The result is the first open-source code model that outscore GPT-4 Turbo on standard software engineering benchmarks.
SWE-Bench Leaderboard (Verified as of March 2026)
Hardware Requirement
30B MoE (4.2B active)
API only
API only
48GB VRAM
API only The 2.8-point gap between GLM-4.7 Flash and GPT-4 Turbo matters. SWE-bench isn't a toy benchmark — it's a real evaluation: "Can this model resolve open GitHub issues?" Humans working on the same issues resolve them about 76% of the time, so 73.8% puts GLM-4.7 Flash in serious contention with production AI.
The MIT license changes the game. You can embed this model into products, sell it, integrate it with other systems, and run it offline. No per-token billing. No telemetry. No waiting for API rate limits.
Beats GPT-4 Turbo on Coding Evals: Benchmark Context and Real-World Limits
SWE-bench tests one thing really well: can the model fix broken code when given the issue description? On that narrow task, GLM-4.7 Flash wins. But benchmark wins don't always translate to daily driver performance.
Performance on Real Coding Tasks
For standard Python algorithms (sorting, graph traversal, recursion), GLM-4.7 Flash and GPT-4 Turbo are effectively equal. Both get to the answer.
For multi-file refactoring and system-level code, GLM-4.7 Flash has a real edge. It's specifically trained on repo-scale problems, so it handles context better when fixing code that touches five files at once.
For web development (React, Next.js, Vue, Node.js backends), GPT-4o still leads. The APIs are too diverse, the patterns too fluid, and the ecosystem too large for a specialized code model to match general-purpose training. If you're building a SPA or an API server, stick with GPT-4o for speed.
Note
GLM-4.7 Flash excels at backend logic and data transformation. It struggles with frontend frameworks not heavily represented in its training data. This isn't a flaw — it's the tradeoff of specialization. You get a cheaper, private, faster model. You lose the long tail of web frameworks.
The MIT license is your trump card. GPT-4 Turbo costs $0.03 per 1K input tokens plus $0.06 per 1K output tokens. Run GLM-4.7 Flash locally, and you're at $0. The token speed on a mid-range GPU (RTX 3090) is 28 tokens per second — faster than waiting for an API call to complete. For iterative development, that's worth more than the benchmark points.
LM Studio Integration and One-Click Setup
LM Studio is the simplest way to run GLM-4.7 Flash. It handles model management, quantization, and server setup without a command line.
LM Studio Setup Steps (6 minutes)
1. Download LM Studio Visit lmstudio.ai and download the version for your OS (Windows, Mac, Linux). Run the installer.
2. Launch LM Studio and open the models tab Click the cube icon on the left sidebar to open the models marketplace.
3. Search for "glm-4.7-flash" in the search bar It will show the official Alibaba upload. You'll see file size options: Q4, Q3, Q2, Q1 (from highest to lowest quality).
4. Download Q4 (recommended) or Q3 (if VRAM is tight) Q4 is about 18GB. Q3 is 13GB and still excellent for code work. Click download and wait 15–20 minutes depending on your internet connection. LM Studio shows progress.
5. Once downloaded, click the play icon next to the model name
LM Studio loads the model into memory and starts a local API server on http://localhost:1234.
6. Copy the API endpoint
Note down http://localhost:1234/v1. You'll need this for VS Code and Cursor integration.
That's it. The model is now running on your machine, fully private, no telemetry.
24GB Hardware Sweet Spot: RTX 3090, RTX 4080, RTX 5070 All Viable
You don't need a flagship GPU. GLM-4.7 Flash was designed for 24GB cards because that's what's actually available in the used and mid-range market.
Hardware Performance Tiers (Verified as of March 2026)
Speed is measured in tokens per second (tok/s) — how many output tokens the model generates in one second.
Year
2020
32 tok/s (Q3 only)
35 tok/s (Q3 only)
2022 The RTX 3090 is the best deal. You can find them used for $450–$550, and Q4 quantization runs beautiful. 28 tokens per second means code suggestions appear in 2–3 seconds. That's real-time for autocomplete.
The RTX 5070 at $549 new gives you 35 tok/s with Q3, but you lose some quality. For pure speed and size per dollar, it's unbeatable. You're buying latest silicon instead of older inventory.
The RTX 4090 at $1,200+ is overkill unless you're running multiple models in parallel. 42 tok/s is fast, but the improvement over the 3090 doesn't justify quadruple the cost for local development work.
Tip
If you already own a RTX 4070, 4070 Ti, or 4080 from gaming, start with Q3 quantization. Test it for a week. You'll be shocked how well it works.
Code Generation Latency and Quality Tradeoff vs Larger Models
Here's the truth about local code models: they're fast, but they're narrower than GPT-4 Turbo.
Latency: GLM-4.7 Flash generates code at 28–35 tokens per second on consumer hardware. GPT-4 Turbo over API is typically 15–20 tok/s after you factor in network round trips. That's 50% faster local, every time, no rate limits, no connection timeouts.
Quality: GLM-4.7 Flash is specialized. It was fine-tuned to fix bugs and implement features. For that narrow task, it's better than GPT-4 Turbo (per SWE-bench). But if you ask it to write a blog post, explain quantum mechanics, or translate to French, it's okay but not exceptional. GPT-4 Turbo is the generalist.
The practical win: You get a model that's good-enough at code work, 50% faster, zero cost per token, and fully private. For most developers, that's worth the tradeoff of losing some quality on edge cases.
Local IDE Integration: GitHub Copilot Alternative
You can use GLM-4.7 Flash as a drop-in replacement for GitHub Copilot in VS Code and Cursor. Both support custom OpenAI-compatible endpoints.
VS Code Copilot Custom Endpoint
1. In VS Code, open Settings (Ctrl+,) Search for "copilot" in the settings search box.
2. Scroll to "GitHub Copilot: Advanced"
Find the advanced section (or create it if missing).
3. Add your custom API endpoint
Paste this JSON into your VS Code settings.json:
"github.copilot.advanced": {
"apiUrl": "http://localhost:1234/v1",
"apiKey": "none"
}4. Reload VS Code Close and reopen the editor. GitHub Copilot now sends requests to your local GLM-4.7 Flash instance instead of GitHub's servers.
5. Test it Start typing a function signature. Copilot will auto-suggest code from your local model.
Cursor IDE Integration
Cursor (the AI-first code editor) has even better custom model support.
1. Open Cursor Settings (Cmd/Ctrl + Shift + ,)
2. Go to "Features" → "Models" tab
3. Scroll down to "Custom Provider" Enter:
- Endpoint:
http://localhost:1234/v1 - Model name:
glm-4-7-flash
4. Set it as your default model Toggle "Use for all completions" to enable GLM-4.7 Flash for inline suggestions and chat.
5. Start coding Type a function. Cursor will call your local model for completions.
The integration is seamless. You get GitHub Copilot–quality suggestions but running on your hardware, offline, with zero per-token cost.
FAQ
Is GLM-4.7 Flash really better than GPT-4 Turbo for coding? On SWE-bench (real GitHub issue resolution), GLM-4.7 Flash scores 73.8% vs GPT-4 Turbo's 71%. That's a meaningful 2.8-point gap. For standard Python algorithms, they're nearly identical. For complex multi-file refactoring and system-level code, GLM-4.7 has an edge. For web development (React/Node), GPT-4o still leads.
What GPU do I need to run GLM-4.7 Flash locally? RTX 3090 24GB is the sweet spot — 28 tok/s at Q4. RTX 5070 12GB works at Q3 (35 tok/s, slightly lower quality). RTX 4090 24GB is the fastest consumer option at 42 tok/s. You don't need a high-end card — this model was designed to be deployable on mid-range hardware.
Can I use GLM-4.7 Flash commercially? Yes — MIT license allows commercial use without restrictions. You can integrate it into products, SaaS tools, or client deployments. The only practical limit is the hardware you need to run it.
What's Next
You've got GLM-4.7 Flash running locally. Here's where to go:
- Need to optimize your GPU setup? Read our best local LLM hardware 2026 guide for deeper benchmarks and multi-GPU configurations.
- Want to fine-tune GLM-4.7 Flash on your codebase? Check out our advanced LM Studio and llama.cpp guide for quantization tuning and inference optimization.
- Still choosing between models? Check SWE-bench directly at swe-bench.github.io for the latest rankings.
GLM-4.7 Flash proves that open-source code models are ready for daily use. It's faster than the cloud, cheaper than APIs, and for most coding tasks, better than the proprietary alternative. That's the future of local AI development.