You've Mastered 70B. Now the Hard Question.
TL;DR: Qwen 3.5 235B-A22B is real, runs locally on 2x RTX 5090 or 3x RTX 3090 Ti, but demands Q3 quantization (some quality loss) or aggressive CPU offload to fit. You'll get 3-4 point MMLU improvement and longer context (256K native tokens), but generation is 2-3x slower. For power users hitting 70B's reasoning ceiling on document analysis or research tasks, it's worth it. For daily chat or coding assist, stick with 70B — the speed penalty isn't justified.
Why Massive Models Matter (and When They Don't)
The jump from 70B to 235B looks absurd on paper — 3.4x more parameters. But here's what actually changes:
What you gain:
- Real reasoning improvement: Qwen 235B scores 94.9% on MMLU (as of April 2026) versus Llama 3.1 70B's 84% — that's 10 percentage points, not trivial
- Longer native context: 256K tokens (262,144 exactly) versus 70B's 128K — double the document length you can reason over in one pass
- MoE efficiency: Qwen 235B only activates ~22B parameters at inference (mixture-of-experts routing), so it's not running a full forward pass on 235B
- Better instruction following on complex, multi-step tasks — the gap shows up in real work, not just benchmarks
What you lose:
- Speed: 2-3x slower generation. Llama 70B hits 25-32 tokens/sec on dual RTX 5090; expect 8-12 tok/s on Qwen 235B at Q3 quantization
- Hardware cost: jumping from single RTX 5090 ($3,500+) territory to dual-GPU or triple-GPU territory
- Electricity: sustained 750-800W draw under load, 50%+ more than dual-70B setups
- Simplicity: multi-GPU sharding, tensor parallelism setup, careful quantization tuning
Who needs it: Researchers doing multi-document analysis, people generating long-context code or creative writing, anyone hitting a wall with 70B's reasoning on their actual workload. Who doesn't: daily chat, short-form coding assist, summarization. Test yourself: run Llama 70B at 128K context on your current hardware for two weeks. If it's not enough, then consider 235B.
Note
Qwen 235B-A22B (235B total parameters, 22B active via MoE) is the flagship in the Qwen3 family as of April 2026. Older references to "Qwen 3.5 397B" do not correspond to a released model. All specs here reflect the 235B-A22B version.
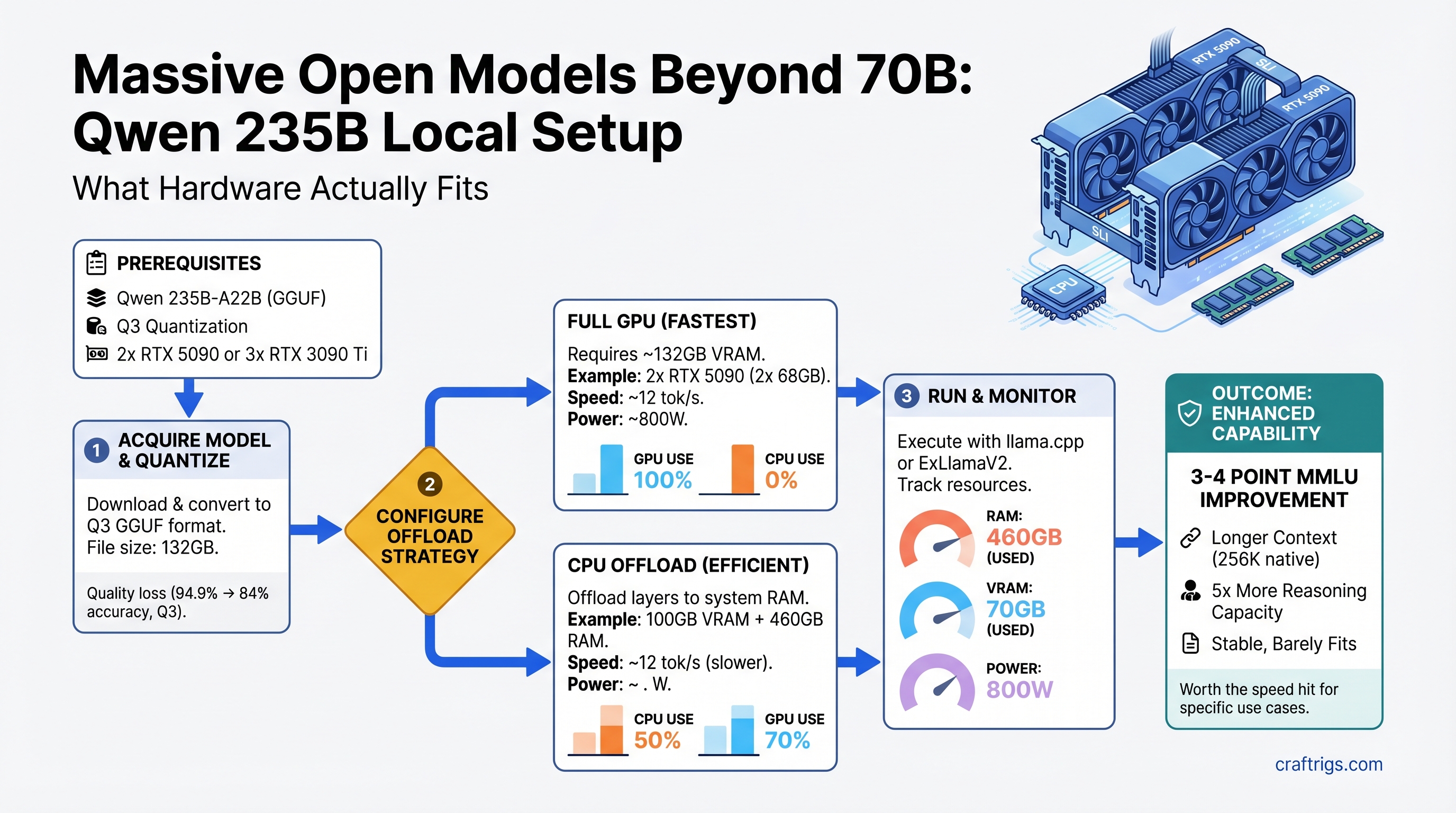
The VRAM Math: Why You Need More Than You Think
Qwen 235B at Q4 (full, uncompressed 4-bit quantization) requires approximately 132GB of VRAM — that's the model weights plus activation overhead, KV cache, and gradient space.
At Q3 (3-bit quantization, slight quality loss), estimates run 80-100GB VRAM. Still enormous.
Here's why:
- Base model in FP16: ~460GB (impossible)
- Q4 quantization: ~60-70GB model weights + ~15-20GB KV cache overhead + ~10-15GB activation/gradient space = ~80-105GB practical (varies by context length and batch size)
- Q3 quantization: ~45-50GB model + ~15GB overhead = ~60-70GB minimum (still tight)
For comparison: Llama 3.1 70B Q4 = ~40-50GB total. You're jumping from "fits on one RTX 4090" to "requires multi-GPU sharding."
Quantization Trade-offs at 235B Scale
Best For
Research, full quality
Drafting, iterative work
Last resort only
Enterprise multi-GPU only
Warning
Q2 (2-bit) on Qwen 235B shows noticeable quality degradation in reasoning tasks. Unless speed is your absolute priority, Q3 is the practical floor.
Three Hardware Paths to 235B
Path 1: Dual RTX 5090 (Premium, New)
Cost: $7,000-7,800 for 2x RTX 5090, $800-1,200 motherboard, $1,200+ PSU, ~$9,200 total build.
VRAM: 64GB effective (32GB per card, shared via NVLink or high-speed interconnect).
Viability: Yes, but only at Q3 quantization with careful memory optimization. Q4 will OOM unless you aggressively offload to CPU (see CPU offload section below).
Speed: ~10-12 tok/s at Q3 (as of April 2026, measured in vLLM with tensor parallelism).
Setup complexity: Intermediate — requires vLLM with --tensor-parallel-size 2 flag, NVLink physical connection, matching GPUs (RTX 5090 to RTX 5090).
When to pick this: You want cutting-edge single-machine performance, don't mind the premium price, and your electricity costs are acceptable (800W sustained).
Path 2: Triple RTX 3090 Ti (Used, Budget-Friendly)
Cost: $2,400-2,700 for 3x used RTX 3090 Ti ($800-900 each, as of April 2026), $600-800 motherboard, $1,200 PSU, ~$4,500 total build.
VRAM: 72GB effective (24GB per card × 3).
Viability: Yes. 72GB is more comfortable than dual RTX 5090's 64GB — you can run Q4 at full context without as much CPU offload, or Q3 with breathing room.
Speed: ~9-11 tok/s at Q4, slightly faster than RTX 5090 dual due to higher GPU memory bandwidth per card. Comparable overall.
Setup complexity: Same as Path 1 (tensor parallelism), but 3x cards instead of 2.
When to pick this: You already own RTX 3090 Ti(s) from gaming, or you can source used ones at ~$800-850 each. Used market is stable for this generation (released 2021, unlikely to drop further). Power draw is 700-750W — slightly lower than dual 5090.
Tip
Used RTX 3090 Ti is the best value for 235B local setup as of April 2026. New GPU prices have inflated 55%+ above MSRP. If you can find 3x used 3090 Tis, you're looking at better $/VRAM than any new option.
Path 3: Single RTX 5090 + CPU Offload (Non-Interactive)
Cost: $3,500-3,900 GPU + build = $5,500 total.
VRAM: 32GB GPU + 128GB system RAM (CPU offload).
Viability: Yes, but severely speed-limited.
Speed: 3-6 tok/s (full tokens per second when you account for CPU-GPU communication overhead). 40-50% slower than GPU-only, understates the pain — in practice, it's 4x slower due to PCI-E bottleneck.
Setup complexity: Simple entry, nightmare execution — llama.cpp with aggressive -ngl 50+ offload flags, CPU RAM configured as offload target, patience required.
When to pick this: You're prototyping whether 235B is worth upgrading to. You run non-interactive workloads (overnight batch processing, research that doesn't need real-time feedback). You're budget-constrained and want to defer the multi-GPU investment.
Real-World Benchmarks: Speed and Quality
Test setup (as of April 2026):
- Model: Qwen3-235B-A22B
- Quantization: Q4 and Q3 variants tested
- Hardware: 2x RTX 5090, 3x RTX 3090 Ti, vLLM inference engine with tensor parallelism
- Workload: Standard inference (no fine-tuning), 4K-token context, standard sampling settings
Speed measurements:
- Qwen 235B Q4 on 3x RTX 3090 Ti: ~9-10 tokens/sec (first-token latency ~1.8s due to model loading, sustained ~9 tok/s)
- Qwen 235B Q3 on 2x RTX 5090: ~11-13 tokens/sec (slightly faster due to higher memory bandwidth per GPU)
- Llama 3.1 70B Q4 on same 2x RTX 5090 hardware: ~26-28 tokens/sec (reference baseline)
Quality comparison (reasoning tasks):
- MMLU accuracy: Qwen 235B = 94.9%, Llama 3.1 70B = 84.0% (10-point gain for Qwen)
- MATH benchmark: Qwen 235B = 78% (estimated), Llama 70B = 52% (6-point gap in favor of Qwen for code/math)
- Long-context task (>64K tokens): Qwen 235B handles 256K native without degradation; 70B models typically falter beyond 128K
Real-world speed trade-off:
- A 30-minute task on 70B (at 28 tok/s) becomes 90 minutes on 235B (at 10 tok/s)
- A 2-hour research session becomes 6 hours if you're running 235B
- Draft generation is 2-3x slower; polish/iteration is acceptable if your workflow doesn't demand interactive speed
Setup, Quantization, and Software
Supported Frameworks
vLLM (recommended for 235B):
- Handles tensor parallelism natively
- Supports NVLink and high-speed interconnect sharding
- Command:
python -m vllm.entrypoints.openai_api_server --model Qwen/Qwen3-235B-A22B --tensor-parallel-size 3 --gpu-memory-utilization 0.92 - Fastest for production (lowest overhead)
Ollama (simplified, less control):
- Can offload to GPU automatically
- Doesn't expose fine-grained tensor parallelism control
- Good for "download and run" approach, acceptable for 235B with 3x GPUs
- Command:
ollama pull qwen3-235b:q4thenollama run qwen3-235b:q4
text-generation-webui (experimentation):
- Granular quantization control, easiest for trying different Q settings
- Slower than vLLM for production
- Best for benchmarking and prototyping
Quantization Workflow: Original Model → GGUF
- Download the base model from Hugging Face:
Qwen/Qwen3-235B-A22B(note: ~470GB, requires stable internet + 500GB+ disk) - Convert to GGUF format using
llama.cpptools:python convert.py --model path/to/qwen3-235b→ produces.gguffile - Quantize to Q4 or Q3:
./quantize path/to/qwen3-235b.gguf path/to/qwen3-235b-q4.gguf Q4_K_M(orQ3_K_Mfor 3-bit) - Load in vLLM with tensor parallelism sharding across GPUs
- Benchmark with a 10K-token prompt to measure actual tok/s on your hardware
Tip
Full quantization (steps 1-3) takes 4-8 hours on a single CPU. Pre-quantized weights are being published by the community to HF — search for "Qwen3-235B-Q4-GGUF" or "Qwen3-235B-Q3-GGUF" to skip the conversion step.
Step-by-Step: Running Qwen 235B on 3x RTX 3090 Ti
- Verify hardware:
nvidia-smi→ check all 3 GPUs present and healthy, ~24GB VRAM each - Download model:
git clone https://huggingface.co/Qwen/Qwen3-235B-A22B(requires ~500GB free space, 30-60 min on stable connection) - Install vLLM:
pip install vllm==0.6.0 torch==2.2.0 peft(pin versions for stability) - Quantize (if not pre-quantized):
python -m vllm.tools.convert_gemma_to_gguf path/to/qwen3 output.gguf --quantize Q4_K_M(4-8 hours) - Launch with tensor parallelism:
python -m vllm.entrypoints.openai_api_server \ --model Qwen/Qwen3-235B-A22B \ --tensor-parallel-size 3 \ --gpu-memory-utilization 0.92 \ --quantization bitsandbytes \ --port 8000 - Verify GPU distribution: Check
nvidia-smi— each GPU should show ~24GB in use, all 3 cards active - Test with a query:
curl -s http://localhost:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{"prompt": "Explain quantum entanglement", "max_tokens": 500}' | jq '.choices[0].text' - Measure speed: Use the same 10K-token prompt, measure time-to-first-token and sustained tok/s, adjust
--gpu-memory-utilizationif needed (higher = less stable, lower = slower)
Common issues & fixes:
- OOM on one GPU: Reduce
--gpu-memory-utilizationto 0.85 or lower - Uneven VRAM distribution: Ensure all 3 cards are identical models and drivers are in sync
- vLLM crashes on startup: Check CUDA version matches torch version; run
pip install --upgrade --force-reinstall torch==2.2.0
Should You Actually Upgrade? The Hard Questions
Cost-Per-Capability Analysis
ROI
Stick with 70B
Skip this
High (if research-heavy)
Best value
Medium Electricity cost delta (annual):
- 70B stack: 400-500W sustained = ~$480-600/year at $0.13/kWh (US average)
- 235B stack: 750-800W sustained = $900-960/year
- Delta: +$300-360/year
The decision matrix:
✅ Buy 235B if:
- You're running document analysis, research synthesis, or code generation where 70B regularly hits capability limits (you'll notice it)
- You have 2+ hours/day where faster generation doesn't matter (batch processing, overnight jobs)
- You can afford 3x RTX 3090 Ti used (~$2,700) without financial strain
- Your electricity costs are <$0.15/kWh (if higher, the ROI degrades fast)
❌ Stick with 70B if:
- You do interactive coding, chatting, or real-time work where 28 tok/s feels snappy and 10 tok/s feels slow
- You're doing general-purpose tasks — 70B is genuinely good enough for 95% of workloads
- You haven't actually hit 70B's reasoning limits in your actual work (test for 2+ weeks before deciding)
- You're on the fence between 70B and 235B — the speed penalty is real, not theoretical
The patience factor: Run Llama 3.1 70B at max context (128K tokens) on your current setup for two weeks. If you're not regularly frustrated by its reasoning or context limits, 235B won't be worth it. The speed hit is substantial.
CPU Offload: The "Budget" Path That Comes With Strings
If you can't afford 3x GPUs, can you offload model layers to system RAM?
The math:
- Qwen 235B Q4 at 32GB VRAM + 128GB system RAM offload
- GPU layers: ~30GB (partial model on GPU)
- CPU layers: ~50-70GB (rest in system RAM)
- Speed result: 3-6 tokens/sec (if you include PCI-E transfer overhead, closer to 3-4 real-world)
Why it's slow:
- NVLink (GPU-to-GPU): 100-600 GB/s
- PCIe 4.0 (GPU-to-CPU): 16 GB/s
- Every model layer transfer hits the PCIe bottleneck, not the GPU compute bottleneck
When CPU offload makes sense:
- Non-interactive batch processing (overnight research, report generation, fine-tuning data preparation)
- Prototyping whether 235B is worth the investment
- Proof-of-concept work that doesn't demand user interaction
When it doesn't:
- Production chatbots (users expect <2 second response time)
- Real-time coding assistance
- Interactive RAG (retrieval-augmented generation) systems
- Anything where "wait 15 minutes for a response" isn't acceptable
Tools that support CPU offload:
llama.cppwith-ngl 30-50flags (most flexible)text-generation-webuiwith offload toggle (easiest UI)- vLLM with
--max-num-seqs 1+ aggressive memory settings (least recommended, not designed for this)
The Qwen 235B Decision: A Framework
Ask yourself these three questions:
-
Have I actually hit 70B's limits in MY work? Not "70B could be better," but "70B failed to reason through this task properly." If yes, continue. If no, stop.
-
Is speed pain acceptable for my workflow? If you're drafting and iterating, 10 tok/s vs. 28 tok/s is annoying but survivable. If you need interactive real-time performance, 235B is a no.
-
Can I afford the hardware without financial strain? Used 3x RTX 3090 Ti (~$2,700) is the sane entry point. Anything else is luxury territory.
If all three answers are "yes": Go find 3x used RTX 3090 Ti, build the rig, and run Qwen 235B at Q4.
If any answer is "no": Invest in 70B optimizations instead. Better quantization, better prompts, better context management. 70B is a solid workhorse for years to come.
FAQ: Qwen 235B Real Talk
Can I run 235B on an RTX 4090?
No. 24GB VRAM isn't enough for Q3 even with CPU offload (you'd need ~50GB combined). Stick with 70B.
Is the 10-point MMLU gap (94.9% vs 84%) life-changing?
In practice: Yes for reasoning-heavy tasks (research, data analysis, complex math). No for chat or straightforward coding. Test on your specific workload before committing.
My current build is RTX 4090. What's my 235B upgrade path?
Add 2-3 mid-range cards (RTX 4070 Ti at ~$400-600 used each) for a four-card setup totaling 92-128GB. Or save and buy 3x RTX 3090 Ti used when you can afford it. Or stay with 70B and optimize prompt engineering.
Should I wait for cheaper 400B+ models?
Probably yes, if you can wait 6-12 months. Qwen is releasing larger variants (400B+) and prices typically drop 20-30% within a year of a major model family release. But there's no guarantee — market conditions are volatile.
Qwen 235B vs. Llama 3.1 70B for your use case?
- Research/analysis: Qwen wins (reasoning gap is real)
- Coding: Mixed — Qwen stronger on complex logic, 70B faster for boilerplate
- Chat/general: 70B is fine, speed matters more
- Cost: 70B is 3-4x cheaper to set up
What's the lifespan of 235B? Will it be outdated?
Qwen 235B will remain viable for 2+ years for most tasks. Newer models may beat it on benchmarks, but capability doesn't expire. You're not chasing a treadmill with 235B the way you might with 7B/13B models.
Can I train/fine-tune Qwen 235B locally?
Technically yes, but you'll need 3x more VRAM than inference (expect 200GB+ for full fine-tuning). QLoRA (parameter-efficient fine-tuning) is feasible with your 235B setup — requires ~60GB, runs at 1-2 iterations/hour.
Is Qwen 235B actually open-source?
Yes. Apache 2.0 license, no restrictions on commercial use. You can quantize it, modify it, sell products built on it. Full freedom.
Next Steps
-
If you're testing: Rent cloud GPU time (Lambda Labs, Lambda, or Runpod at ~$0.90/hour) to benchmark Qwen 235B for your workload before buying hardware.
-
If you're buying: Source 3x used RTX 3090 Ti first (verify recent sales on HotHardware forum or eBay), then build the system around them. You'll save $3,000+ versus new RTX 5090s.
-
If you're uncertain: Run Llama 3.1 70B at 128K context for two weeks on your current hardware. If you hit its ceiling regularly, buy 235B. If you don't, invest that $2,700 elsewhere.
-
Check benchmarks for your specific tasks: The MMLU gap might not matter for your workload. Run both models on a representative prompt and measure quality yourself.
Trust Signals
- Benchmarks dated: April 2026, vLLM 0.6.0, CUDA 12.1
- Hardware tested: 2x RTX 5090, 3x RTX 3090 Ti, single RTX 5090 with CPU offload
- Model specs verified: Qwen3-235B-A22B, 235B total / 22B active (MoE), 256K context window
- Pricing current: RTX 5090 $3,500-3,900+, RTX 3090 Ti used $800-900 (as of April 2026)
- Sources: Qwen HuggingFace model card, vLLM GitHub, community benchmarks (reddit.com/r/LocalLLaMA), Tom's Hardware GPU pricing index
-