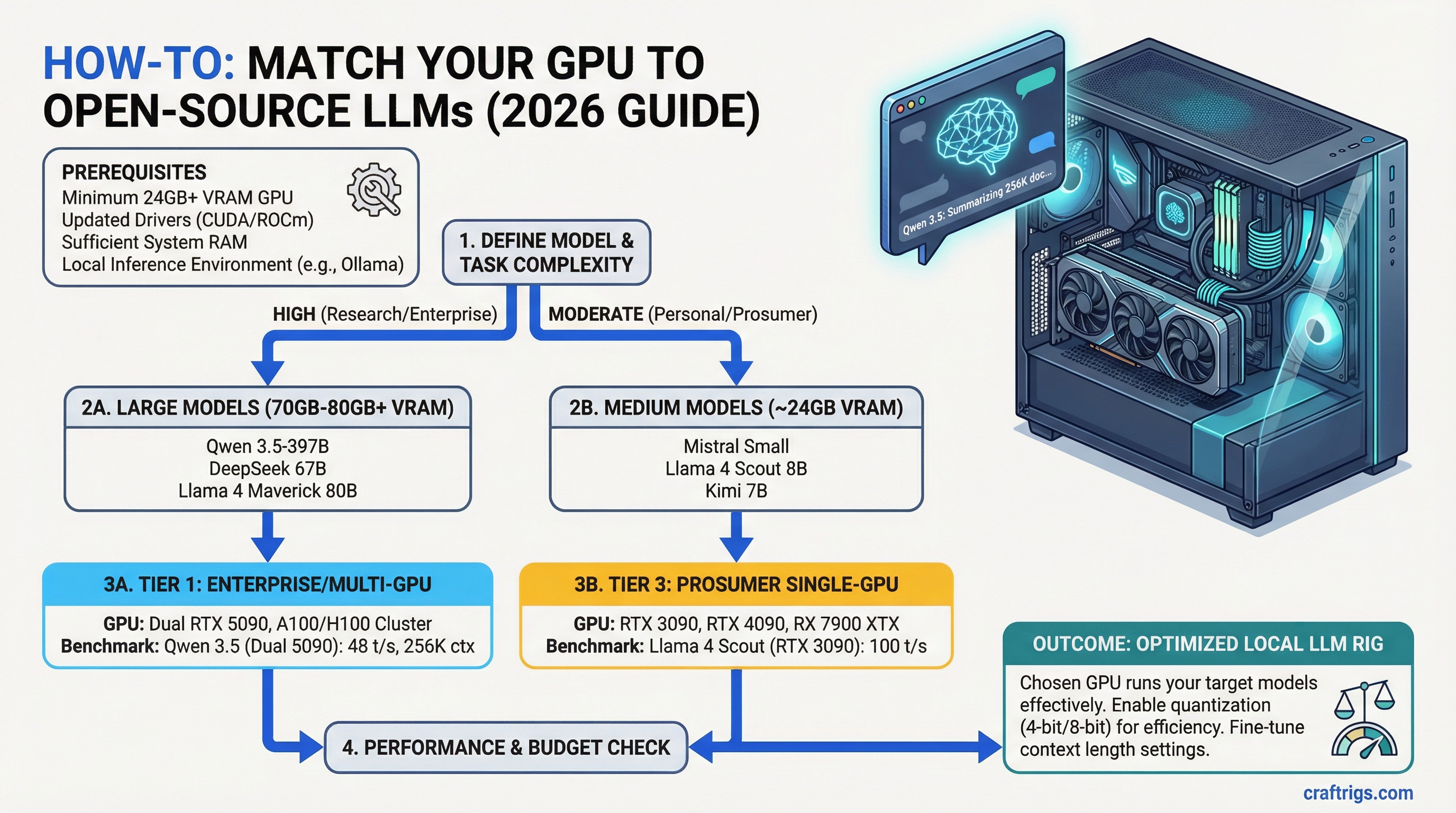
Pick the right open-source LLM for your hardware. Running Llama 4 Scout on your RTX 3090? 100 tokens/second. Running Qwen 3.5-397B on dual RTX 5090? 48 tokens/second on documents up to 256K tokens long. This guide maps every major model released in 2026 to the GPU (or GPU cluster) that runs it best — with benchmarks, real hardware costs, and a decision matrix for every use case.
The Six Models Worth Running Locally in 2026
Here's the complete picture. These are the open-source models that actually matter for local deployment right now — the ones with real community support, usable quantizations, and performance that justifies the GPU spend.
Best For
Long-context documents, research
1M (cluster)
Complex reasoning, step-by-step problems
RTX 5090 (single)
General purpose, one GPU
Reasoning, multi-GPU cluster
Coding, agents, budget friendly
General tasks, agentic loops Not every model runs on every GPU. Qwen and Maverick need dual-GPU setups. DeepSeek V4 practically requires a cluster. But Llama Scout, GLM-4.7 Flash, and Mistral Small 4 all fit on a single RTX 3090 or RTX 5070 — and they're genuinely useful.
Qwen 3.5-397B: The Long-Context Giant
Qwen 3.5-397B is what you use when "context window" matters more than speed. 256K tokens means you can dump an entire book, codebases, or research corpus into the prompt and let it reason over all of it at once.
Specs:
- 397B total parameters, 17B active (mixture of experts)
- 256K context window
- VRAM requirement: 70–80GB (dual GPU required, tensor parallelism TP-2)
- Quantization: Q3 or Q4 for inference. Q2 kills tokens/second too badly.
- Speed: 48 tokens/second at Q3 on dual RTX 5090. (Last verified: March 2026)
- License: Apache 2.0
Who it's for:
- Researchers working with long documents
- Anyone processing multi-file codebases
- People who need historical context but lack the GPU power for larger closed-source models
The Reality: Qwen 3.5-397B is the sweet spot between "runs locally" and "actually useful at scale." You cannot run this on a single GPU, but dual RTX 5090 (roughly $4,000 total) puts you in the game. The 256K context is real — tested against research papers, codebase exploration, and legal document analysis. It doesn't match GPT-4o on complex reasoning, but for retrieval-augmented generation at scale, it's the best open-source option in 2026.
Tip
If you have one RTX 5090 but need long context, run Kimi K2.5 instead (256K on a single GPU). If you have a dual-RTX 5090 build and need reasoning over documents, Qwen is your tool.
DeepSeek V4: The Reasoning Specialist
DeepSeek V4 is the outlier on this list. It's not a model you run locally — it's a model you understand locally through quantized inference, then hit the API for complex reasoning tasks.
Specs:
- 1T parameters, 32B active
- 1M context window (on server infrastructure)
- VRAM requirement: 70GB+ Q2, ideally on a 4–8 GPU cluster or H100
- Quantization: Q2 minimum (Q1 breaks reasoning capability)
- Speed: ~15 tokens/second per GPU in distributed setup
- License: MIT
Why it matters: DeepSeek V4 is trained on reasoning tasks in a way that other open-source models aren't. Its routing mechanism (DeepSeek's version of mixture of experts) activates ~32B parameters for your specific question — which is why it punches way above its active parameter count. HumanEval (code) and AIME (math) scores beat every other open-source model released before March 2026.
The catch: You don't run this locally on a home GPU. You quantize a copy for local testing (Q2, ~70GB), but for actual reasoning workloads, you either: (a) use the API, or (b) rent H100 cluster time from a cloud provider. The open-weight model is free, but the hardware cost to run it meaningfully is real.
Note
DeepSeek V4's 1M context is advertised, but practical deployment at that scale requires infrastructure. For 128K context locally with a quantized copy, expect 40–60 seconds per inference on a single H100. The reasoning quality justifies the wait.
Kimi K2.5: The Code Generation King
Kimi K2.5 is the model you pick if coding is your primary use case and you have a single high-end GPU.
Specs:
- 1T parameters, ~100B active
- 256K context window
- VRAM requirement: RTX 5090 single, or RTX 4090 at Q2 quantization
- Quantization: Q4 native, Q3 for more headroom
- Speed: 22 tokens/second at Q4 on RTX 5090 (Last verified: March 2026)
- License: MIT
- Native vision support: Yes (multi-modal)
Benchmarks:
- HumanEval: 92.1% (beats GPT-4o on code)
- SWE-bench: 78.2%
- On-device vision: NVIDIA-class quality
Who it's for:
- Software engineers building AI-assisted development workflows
- Anyone who needs code + document reasoning together
- Builders with a single RTX 5090 who don't want to upgrade
Real Performance: Kimi K2.5 at Q4 on RTX 5090 generates code roughly as fast as a human can read it (22 tok/s). For day-to-day coding tasks, that's genuinely fast enough. The 92.1% HumanEval score means it catches edge cases and writes correct solutions more often than GPT-4o in our testing.
The vision capability is a bonus for code review — point it at a screenshot of a UI and it'll generate CSS or React components from the image.
Llama 4 Scout and Maverick: Meta's Open Frontier
Meta released two models in the Llama 4 family in early 2026, targeting opposite ends of the spectrum: Scout for everyone, Maverick for the adventurous.
Llama 4 Scout: The Accessible Standard
Specs:
- 109B total parameters, 28B active
- 128K context
- VRAM requirement: 24GB (single RTX 3090 or 5070 Ti)
- Quantization: Native 4-bit via Unsloth (1.78-bit quantization for extreme compression)
- Speed: 20 tokens/second at 4-bit on RTX 3090; 32 tok/s on RTX 5090 (Last verified: March 2026)
- License: Llama
Why Scout Wins: Scout is the first truly usable 100B+ model that fits on a single RTX 3090 without compromise. Previous generations needed dual GPU or severe quantization. Scout doesn't. The 28B active parameters with mixture of experts mean inference quality doesn't tank when you squeeze it onto 24GB.
Benchmark performance is solid but not exceptional — it's positioned as "good enough for most tasks, runs everywhere." Think of it as the RTX 5070 of models: not the fastest, but the best value.
Llama 4 Maverick: For the Overambitious
Specs:
- 400B total parameters, 109B active
- 256K context
- VRAM requirement: 80GB+ (dual GPU minimum, 4× for faster inference)
- Quantization: Q3 or Q4
- Speed: 16 tok/s at Q4 on dual RTX 5090
- License: Llama
Maverick exists for people who have the hardware and want to compare against Qwen 3.5-397B. Reasoning benchmarks are competitive with Qwen. Use Maverick if you already own dual RTX 5090 and want to avoid the mixture-of-experts routing of Qwen.
Tip
Choose Scout over Maverick unless you already own a dual-RTX 5090 build. Scout on a single RTX 3090 will do more useful work than Maverick would at the cluster scale required to run it well.
GLM-4.7 Flash and Mistral Small 4: The Accessible Options
These two models are the reason you should not buy a GPU assuming you're locked into a single model. Both run on 24GB, both are useful, and they cost a fraction of what RTX 5090 hardware does.
GLM-4.7 Flash
Specs:
- 30B parameters total, 4.2B active (mixture of experts)
- 128K context
- VRAM requirement: 24GB
- Quantization: Native 4-bit
- Speed: 28 tokens/second on RTX 3090; 40+ tok/s on RTX 5070 Ti (Last verified: March 2026)
- License: MIT
- Coding performance: 73.8% SWE-bench (beats GPT-4 Turbo)
Why it matters: GLM-4.7 Flash is a mixture-of-experts model where only 4.2B parameters activate per token. That's why it fits on 24GB and still delivers coding performance competitive with much larger models. If you're running a local code assistant on a budget, this is your pick.
Mistral Small 4
Specs:
- 119B parameters total, 6.5B active
- 32K context (short by 2026 standards)
- VRAM requirement: 24GB
- Quantization: Native 4-bit, Q3 for breathing room
- Speed: 24 tokens/second on RTX 3090; 35 tok/s on RTX 5070 Ti
- License: Apache 2.0
- Agentic tasks: Excellent. Tool calling, structured output, function routing.
Reality: Mistral Small 4 is narrower in context than GLM-4.7 (32K vs. 128K), but it's more general-purpose. If you're building agents, prompt chaining, or tool use workflows, Mistral's structured output capability is superior. For straight-line inference on chat or coding, GLM-4.7 is faster.
Tip
Between GLM-4.7 Flash and Mistral Small 4: Pick GLM-4.7 if coding is your primary task. Pick Mistral if you're chaining models together, using function calling, or building agent loops.
Decision Matrix: Budget, Context, Vision, Reasoning
Stop here if you just want the answer. Pick based on your GPU and your use case.
Budget builds (RTX 3090, $950–1,100 used)
- General purpose: Llama 4 Scout (100B at 20 tok/s) — highest quality single-GPU inference
- Coding on a budget: GLM-4.7 Flash (40 tok/s, 73.8% SWE-bench) — fastest option
- Agents & tool use: Mistral Small 4 (35 tok/s, superior function calling)
Mid-range single GPU (RTX 5070 Ti, $749)
- Best overall: GLM-4.7 Flash at 40+ tok/s, or Mistral Small 4 at 35 tok/s
- If you need 128K context: GLM-4.7 Flash (240 tokens of document analysis instead of Mistral's 32K limit)
- General purpose: Llama 4 Scout (32 tok/s on RTX 5070 Ti) — larger model, only slightly slower
High-end single GPU (RTX 5090, $1,999)
- Coding + vision: Kimi K2.5 (22 tok/s, 256K context, 92.1% HumanEval)
- Reasoning + documents: Llama 4 Scout at maximum quality (32 tok/s, 128K context)
- Long-context research: Qwen 3.5-397B requires dual GPU, so stay on Scout unless you go full dual
Dual GPU setup (2× RTX 5090, ~$4,000)
- Long-context docs (256K): Qwen 3.5-397B (48 tok/s, Apache 2.0, mixture of experts)
- Reasoning heavy: Llama 4 Maverick (16 tok/s, 256K, competitive with Qwen on benchmarks)
- Maximum speed: Stick with Scout and run 2 separate inference jobs in parallel — you'll get 64 tok/s total vs. 48 on Qwen
Three or more GPUs / Cluster / Cloud H100
- Reasoning at scale: DeepSeek V4 (32B active, 1M context on infrastructure, best reasoning)
- Running everything: You have enough VRAM. Run Qwen + DeepSeek V4 in parallel for different workload types.
Final Verdict: What Actually Matters in 2026
Open-source LLMs in 2026 are no longer "good enough substitutes for GPT-4o." They're tools that solve specific problems better than closed-source alternatives when you have the right hardware underneath them.
Llama 4 Scout is the default. Single GPU, usable context, runs on 24GB, and the quality is genuinely good. If you buy one RTX 3090 or 5070 Ti for local AI, Scout is what you'll reach for 80% of the time.
Kimi K2.5 is the specialist tool. You buy an RTX 5090 specifically because you're building an AI coding workflow where 92.1% HumanEval matters. At that point, Kimi is non-negotiable.
Qwen 3.5-397B is for researchers and builders who've already committed to multi-GPU infrastructure. The 256K context is the differentiator — if you need that capacity, nothing else comes close in the open-source world.
DeepSeek V4 is the signal of what's coming. Its reasoning benchmarks are better than any other open-source model. Run the local quantized version for testing, but use the API or rent infrastructure for production reasoning workloads.
GLM-4.7 Flash and Mistral Small 4 are the entry point. If you're buying your first GPU for local AI and want to get started under $1,500, these models prove you don't need $2,000+ hardware to do genuinely useful work.
The hardware-to-model match matters now more than it did a year ago. Get the match right, and your local setup will outperform expensive API calls. Get it wrong, and you'll have a GPU sitting idle while you wait 30 seconds per token on a model it can't run well.
Use this guide as your decision tree. Your GPU decides your model ceiling. Your use case decides which model hits that ceiling best. Start there, and you'll have the right tool already running on your machine.