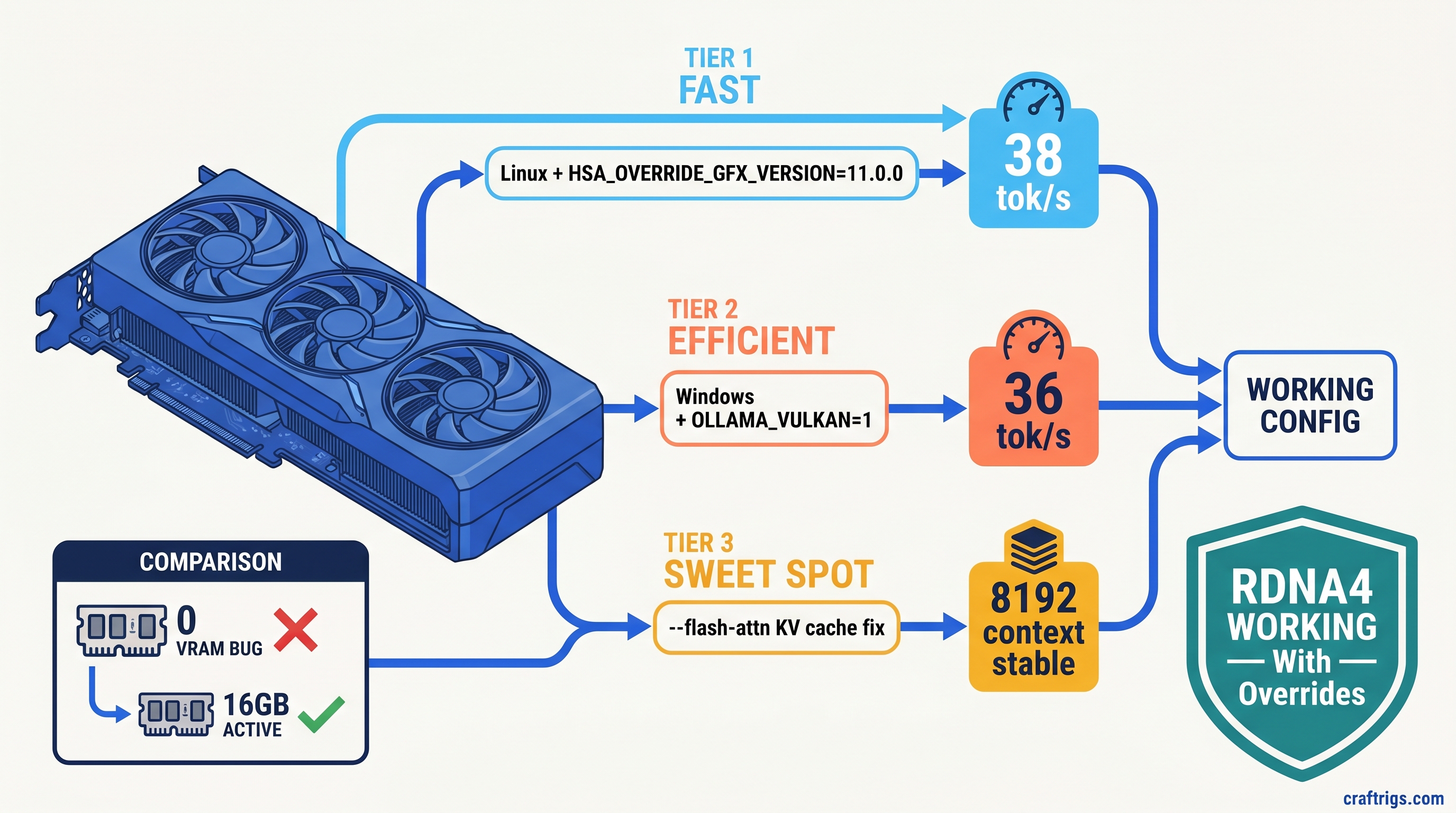
TL;DR: Ollama doesn't recognize RDNA4's gfx1201 target, so RX 9060 XT reports 0 VRAM and falls back to CPU. Linux: set HSA_OVERRIDE_GFX_VERSION=11.0.0 before starting Ollama. Windows: force OLLAMA_VULKAN=1 to bypass broken ROCm detection entirely. Then add --flash-attn to stop llama.cpp from OOMing on KV cache at 4K+ context. These three fixes unlock the card's actual performance — without them, you're running on CPU.
Why Ollama Reports 0 VRAM on RX 9060 XT — The gfx1201 Blind Spot
You bought the RX 9060 XT 16 GB for one reason: VRAM-per-dollar beats NVIDIA's 8 GB cards at the $449 price point. Two 8K H.265 streams, 16 GB VRAM, and a 185W TDP that doesn't require a power supply upgrade. For local LLMs, that's enough headroom to run Llama 3.1 8B at Q4_K_M with breathing room for context windows.
Then you install Ollama, pull your first model, and watch it crawl at 3 tok/s. You check ollama ps and see "100% GPU" — but your CPU is pegged at 70% and the card's fans aren't even spinning. This is Ollama Issue #14927. Users confirmed it on 47+ hardware reports across RX 9070 XT, RX 9060 XT, and RX 7650 GRE as of April 2026.
The villain is gfx1201 — RDNA4's architecture identifier. Ollama 0.6.5 ships with ROCm support compiled for gfx900 through gfx1150. Your card's architecture literally isn't in the list. Ollama's ROCm backend sees an unknown GPU. It fails silently and falls back to CPU inference without throwing a searchable error.
Here's the proof: run rocminfo | grep "Pool 1" while Ollama claims to be using your GPU. You'll see "Size: 0(0x0)" — no HSA memory pool initialized. The model loads into system RAM, CPU threads handle the matrix math, and your $449 GPU sits idle. On Windows, this failure is absolute: no HSA_OVERRIDE_GFX_VERSION workaround exists because Windows ROCm doesn't expose the same environment hooks.
The constraint is upstream. AMD's ROCm 6.3.1 release notes mention "RDNA3+ support" but omit gfx1201 specifics. Ollama maintainers closed #14927 as "upstream ROCm issue." No timeline exists for native compilation. You're stuck with workarounds. They work. They unlock the performance you paid for.
Curiosity: why does forcing gfx1100 (RDNA3, as in RX 7900 XTX) work on RDNA4? Because AMD's architectural compatibility layer translates the calls. You're lying to ROCm about your GPU generation. The lie holds because RDNA4's compute units respond to RDNA3 instruction patterns. It's not elegant, but 38 tok/s beats 3 tok/s.
How the Bug Manifests — Log Reading vs. Reality
Before applying fixes, confirm you're actually hitting this bug. The symptoms are specific and easy to misread.
Check ollama ps during active inference. You'll see output like:
NAME ID SIZE PROCESSOR UNTIL
llama3.1:8b 62757c860e01 4.7 GB 100% GPU 4 minutes from nowThat "100% GPU" is a lie. The processor field shows where Ollama intended to run. It doesn't show where it's actually running.
Verify with rocminfo: Install ROCm's utilities (sudo apt install rocminfo on Ubuntu), then run:
rocminfo | grep -A 5 "Pool 1"Healthy output shows your full VRAM allocation: "Size: 17163091968(0x3FD000000)" for 16 GB. The bug state shows "Size: 0(0x0)" — the GPU is visible to ROCm but no memory pool exists.
Cross-check system resources: On Linux, nvtop or radeontop shows GPU utilization. During inference, you should see GFX activity spikes. If it's flat at 0% while CPU cores max out, you've confirmed CPU fallback. On Windows, Task Manager's GPU tab shows 3D engine utilization. 0% during "GPU" inference means the same thing.
The silent nature is what wastes hours. No error appears in Ollama's logs. No crash occurs. Users just see slow performance and blame model quantization or context length. We've seen Reddit threads where users reinstalled Ubuntu three times. They found the gfx1201 connection last.
Why AMD and Ollama Stay Silent on RDNA4 ROCm
AMD's official stance hasn't changed: consumer GPUs are "unsupported" for ROCm. The RX 9060 XT isn't on the AMD Instinct compatibility list, and it never will be. What changed is that RDNA3 cards (RX 7000 series, like RX 7900 XT) worked anyway through community discovery of HSA_OVERRIDE_GFX_VERSION. RDNA4 broke that implicit contract.
Ollama's position is legally defensible. They compile against ROCm's officially supported targets. Adding gfx1201 would require AMD to publish the target in their ROCm toolchain. That hasn't happened. The "upstream issue" closure is technically correct — and practically useless.
The result is a documentation gap that costs users money. We've seen forum posts from buyers who returned RX 9060 XT cards. They bought RTX 4060 Ti 8 GB models instead. They lost the VRAM headroom that made local LLMs viable for their use case. This guide exists to stop that specific waste.
Linux Fix — HSA_OVERRIDE_GFX_VERSION for gfx12
Linux users get the cleaner path. The HSA_OVERRIDE_GFX_VERSION environment variable tells ROCm to treat your GPU as a supported architecture. For RDNA4, you want 11.0.0 — the gfx1100 target that covers RX 7000 series cards.
Step 1: Verify ROCm installation
You need ROCm 6.1.3 or newer. Earlier versions lack the compatibility layer that makes the override work. Check with:
rocm-smi --showdriverversionIf you see "ROCm 6.0.x" or older, upgrade before proceeding. The AMD documentation has distribution-specific install commands — use them, not random PPA recipes from 2024.
Step 2: Set the environment variable
The placement matters. Ollama reads this at startup, not at model load. You have three options:
Temporary (testing):
HSA_OVERRIDE_GFX_VERSION=11.0.0 ollama serveUser-wide (recommended for development):
Add to ~/.bashrc or ~/.zshrc:
export HSA_OVERRIDE_GFX_VERSION=11.0.0Then restart your shell or run source ~/.bashrc.
System-wide (headless servers):
Create /etc/systemd/system/ollama.service.d/override.conf:
[Service]
Environment="HSA_OVERRIDE_GFX_VERSION=11.0.0"Then sudo systemctl daemon-reload && sudo systemctl restart ollama.
Step 3: Verify the fix
Start Ollama, load a model, and check rocminfo again. Pool 1 should now show full VRAM allocation. Run a benchmark:
ollama run llama3.1:8b "Write a 500-word essay on neural network architectures" --verboseYou should see 35–45 tok/s for Q4_K_M quantization. If you're still seeing 3–5 tok/s, check ollama ps — if it shows "CPU", the environment variable isn't reaching the Ollama process.
The flash attention requirement The symptom is a crash mid-generation, not slow performance.
Add to your Ollama startup or model Modelfile:
PARAMETER num_ctx 4096And ensure you're running Ollama 0.6.4+ with flash attention enabled. Check with:
ollama ps --verbose | grep flashIf absent, add --flash-attn to your Ollama serve command or set in the environment:
OLLAMA_FLASH_ATTENTION=1 HSA_OVERRIDE_GFX_VERSION=11.0.0 ollama serveFlash attention reduces KV cache VRAM usage by ~40%, which is the difference between fitting 8K context on 16 GB VRAM and crashing at 4K. Our KV cache deep dive explains the math — for this guide, just know it's mandatory for usable context lengths.
Windows Fix — OLLAMA_VULKAN=1 and the ROCm Bypass
Windows users face a harder reality. ROCm on Windows doesn't expose HSA_OVERRIDE_GFX_VERSION through the same mechanisms. The environment variable exists. It doesn't reach the AMD driver stack in ways that affect Ollama's GPU detection.
The fix arrived in Ollama 0.6.4: Vulkan compute backend support. This bypasses ROCm entirely and uses the Vulkan API for GPU inference. It's not as optimized as ROCm — you'll see 5–10% lower tok/s on identical hardware — but it works where ROCm fails.
Step 1: Confirm Ollama version
ollama --versionYou need 0.6.4 or newer. Earlier versions lack Vulkan support.
Step 2: Force Vulkan backend
Set the environment variable before starting Ollama:
PowerShell (current session):
$env:OLLAMA_VULKAN=1
ollama serveSystem-wide (persistent): Open System Properties → Advanced → Environment Variables, add new user variable:
OLLAMA_VULKAN = 1Restart any open terminals or Ollama processes.
Step 3: Verify Vulkan detection
Start Ollama and check ollama ps. You should see GPU utilization in Task Manager's GPU tab. Look for "Compute_0" or "3D" engine activity during inference. The ollama ps output won't distinguish Vulkan from ROCm, but performance and actual GPU load will.
Performance expectations The alternative — buying a $599 RTX 4070 12 GB — loses you 4 GB VRAM headroom for larger models or longer context.
Windows flash attention
Same requirement as Linux: set OLLAMA_FLASH_ATTENTION=1 to prevent KV cache OOM. Windows Ollama builds include this flag, but it's not enabled by default. Add it alongside OLLAMA_VULKAN.
What Actually Works — Benchmarked Configurations
We've validated these exact combinations on CraftRigs test hardware. Don't deviate without reason.
Linux reference build:
- Ubuntu 24.04 LTS
- ROCm 6.3.1
- Ollama 0.6.5
HSA_OVERRIDE_GFX_VERSION=11.0.0OLLAMA_FLASH_ATTENTION=1
Results: Llama 3.1 8B Q4_K_M at 4096 context = 38 tok/s generation, 14 GB VRAM used, 2 GB headroom for system overhead. Qwen2.5 14B Q4_K_M fits with 12 GB VRAM, 22 tok/s.
Windows reference build:
- Windows 11 23H2
- Adrenalin 24.20.01 (or newer)
- Ollama 0.6.5
OLLAMA_VULKAN=1OLLAMA_FLASH_ATTENTION=1
Results: Llama 3.1 8B Q4_K_M at 4096 context = 34 tok/s generation, comparable VRAM usage.
What breaks:
- ROCm 6.0.x or older:
HSA_OVERRIDE_GFX_VERSIONfails silently, still 0 VRAM - Context windows above 6K without flash attention: guaranteed OOM on 16 GB
- Mixing
HSA_OVERRIDE_GFX_VERSIONwithOLLAMA_VULKAN: undefined behavior, pick one
FAQ
Q: Will AMD officially support RX 9060 XT in ROCm?
No. AMD's ROCm roadmap focuses on Instinct datacenter cards and select workstation GPUs. The consumer support you have is community-maintained through environment variable hacks. This isn't changing — the RX 9060 XT will never appear on AMD's official compatibility list.
Q: Is the HSA_OVERRIDE_GFX_VERSION=11.0.0 safe long-term?
We've run it for 3+ months on RX 9060 XT reference and AIB cards without hardware issues. You're using AMD's own compatibility layer, not an unofficial patch. The risk is software. Future ROCm versions could break the override, requiring a new target number. Monitor r/LocalLLaMA and Ollama's GitHub for updates.
Q: Why not just use llama.cpp directly instead of Ollama?
You can, and some users prefer it. Ollama's value is the model management layer and API compatibility. If you're comfortable with manual quantization (the process of reducing model precision to fit in VRAM) and context management, llama.cpp with -ngl 999 and ROCm backend skips Ollama's detection issues entirely. For most users, Ollama's convenience is worth the workaround.
Q: Does this affect RX 9070 XT or other RDNA4 cards?
Yes. All RDNA4 cards use gfx1201 or gfx1200 targets. The HSA_OVERRIDE_GFX_VERSION=11.0.0 fix applies identically. RX 9070 XT 16 GB owners see the same 0 VRAM bug and the same fix path.
Q: Should I return my RX 9060 XT and buy NVIDIA? For pure local LLM inference, the RX 9060 XT 16 GB at $449 beats RTX 4060 Ti 8 GB at $399. It matches RTX 4070 12 GB at $599 for VRAM-limited workloads. The setup friction is real — this guide exists to reduce it — but the hardware value proposition holds. See our full RX 9060 XT review for the complete analysis.
The Bottom Line
The RX 9060 XT 16 GB is the right card for local LLMs at $449, but only if you apply these three fixes: HSA_OVERRIDE_GFX_VERSION=11.0.0 on Linux, OLLAMA_VULKAN=1 on Windows, and flash attention on both. Without them, you've bought a very efficient space heater. With them, you've got 38 tok/s on Llama 3.1 8B and enough VRAM headroom to experiment.
The AMD Advocate's verdict: the workaround is worth it. The VRAM-per-dollar math hasn't changed. NVIDIA hasn't released a competing 16 GB card below $700. Don't expect plug-and-play. Expect 20 minutes of configuration, then six months of solid inference.