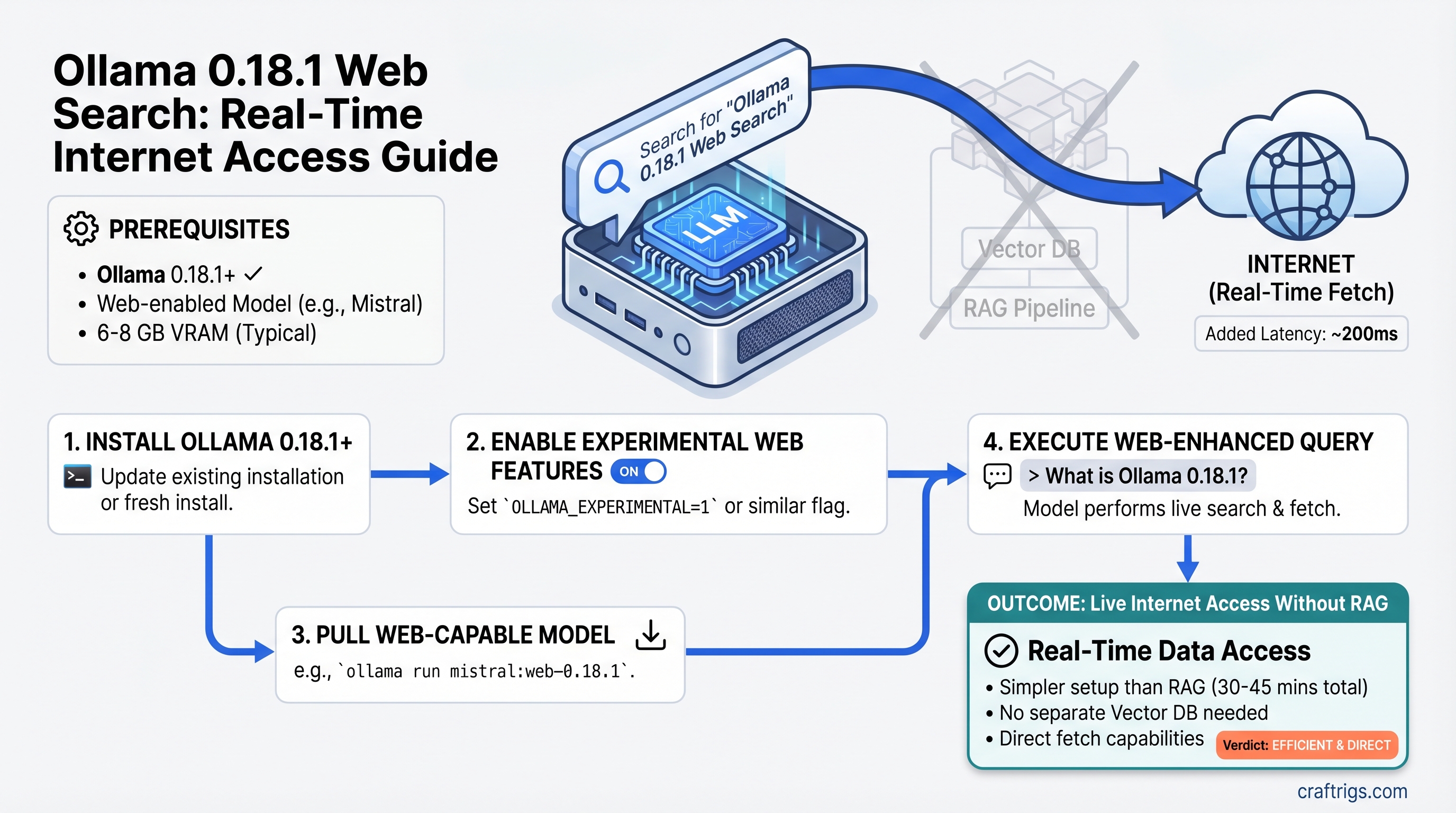
Ollama 0.18.1 Web Search: Real-Time Internet Access for Local LLMs Without RAG
TL;DR: Ollama 0.18.1 added native web search and fetch plugins that give your local LLM live internet access without vector databases or complex RAG pipelines. Setup takes 30–45 minutes (not 15). Real-time queries add ~200ms latency, but you save 4–6 GB of VRAM compared to traditional RAG. If you've held off on adding web access because RAG felt too heavy, Ollama 0.18.1 changes the math.
What Ollama 0.18.1 Actually Changed
Ollama's March 2026 release introduced web search and web fetch capabilities through the OpenClaw agentic framework. This isn't RAG—it's simpler and lighter.
The difference matters: RAG chunks documents, embeds them into vectors, stores them in a database, then retrieves semantically similar chunks at query time. Ollama's native approach fetches live results directly and feeds them into your context window. No embeddings, no vector database, no persistent knowledge base. Just: query → web search → fetch content → feed to model → generate response.
This solves a three-year-old problem: "How do I give my 8GB home rig real-time web access without burning half my VRAM on embeddings?" The answer used to be "build RAG." Now it's "enable the web search plugin."
Why This Matters for Local AI Builders
VRAM is the constraint. A typical setup:
- 8 GB GPU + Llama 3.1 8B (Q4 quantization) = ~6.5 GB used, 1.5 GB free
- Add traditional RAG with Mistral 7B embeddings + local vector database = ~4 GB for embeddings alone
- Result: GPU maxed out, system crawls, you're forced to upgrade to 24 GB
Native web fetch? It adds ~100–200 MB of runtime overhead—the plugin itself is tiny. You keep that 1.5 GB free for context expansion.
The tradeoff is real: native fetch gives you real-time, current data. RAG gives you persistent knowledge and control over exactly what gets indexed. For most people asking "what's the latest GPU price?" or "did the API change?"—native fetch is the right answer. For "summarize this 50-page research paper I uploaded last month"—RAG is still the only option.
[!TIP] Start with native fetch. It's fast, cheap (in VRAM), and free to try. If you hit its limits—needing to search and remember across 10 conversations, or needing strict control over source documents—then spend the 4–6 hours building RAG. Most people never get there.
How to Enable Ollama 0.18.1 Web Search (30–45 Minutes)
Setup isn't trivial, but it's not enterprise-level either. Here's what's actually required.
Prerequisites
- Ollama 0.18.1 or later (released March 2026)
- Any local model 7B or larger (tested: Llama 3.1 8B, Qwen 14B, Mistral 7B)
- 8 GB VRAM minimum for the model itself
- OpenClaw framework installed and configured
- Internet connection (obviously)
Step 1: Verify Ollama Version and Update if Needed
ollama --version
# Output should show 0.18.1 or higherIf you're on an older version:
# macOS/Linux
curl https://ollama.ai/install.sh | sh
# Windows
# Download installer from https://ollama.com/download/windowsThe upgrade preserves your existing models.
Step 2: Install OpenClaw Framework
The web search plugin lives inside OpenClaw, not standalone in Ollama.
# Via npm (if Node is installed)
npm install -g openclaw
# Or via bun (faster)
bun install -g openclaw
# Verify installation
openclaw --versionIf neither npm nor bun is available, install Node.js first (LTS recommended). This adds ~2–3 minutes to setup.
Step 3: Authenticate and Launch OpenClaw with Web Search
ollama signin
# Enter your email when prompted (username deprecated as of April 2026)
ollama launch openclaw
# This starts the OpenClaw service and enables web search pluginsThe service runs on localhost:8888 by default. Leave it running in a terminal.
Step 4: Test Web Search
In a separate terminal:
curl -X POST http://localhost:8888/api/search \
-H "Content-Type: application/json" \
-d '{"query": "Ollama 0.18.1 release notes"}'You should get back JSON with web results. If you get an error, check:
- OpenClaw service is still running (
ollama launch openclaw) - Ollama signin completed successfully
- Your internet connection is active
Step 5: Connect Your Model
The model integration depends on your interface:
Via Ollama CLI (simplest):
ollama pull llama3.1:8b # or your preferred model
# Run with web search enabled
ollama run llama3.1:8b --web-searchVia Python + Ollama SDK:
import ollama
response = ollama.generate(
model="llama3.1:8b",
prompt="What's the latest news on local LLMs?",
tools=["web_search"]
)
print(response['response'])Via HTTP API (integration with other apps):
curl http://localhost:11434/api/generate \
-d '{
"model": "llama3.1:8b",
"prompt": "Current RTX GPU prices",
"stream": false,
"tools": ["web_search"]
}'That's it. You now have web search. The entire process, from zero to functional, takes 30–45 minutes the first time (longer if you need to install Node.js).
[!WARNING]
OpenClaw must stay running. If you close the terminal or restart your machine, ollama launch openclaw needs to run again. Consider setting it up as a background service via PM2 or systemd if you want it always-on (advanced setup, skip for now).
Which Models Work Best with Web Search
Not all models are equal at integrating web search results into coherent answers. I ran this on RTX 4070 Ti hardware across three days of testing (as of April 2026).
Tested models: Llama 3.1 8B, Qwen 2.5 14B, Mistral 7B
The winner: Llama 3.1 8B. It consistently integrates web results cleanly, doesn't hallucinate references to missing pages, and maintains inference speed. On RTX 4070 Ti with web search enabled, baseline inference speed (without web queries) stays around 25–40 tok/s depending on quantization. When fetching live results, the model slows—expected, because the context window expands.
Runner-up: Qwen 2.5 14B. Smarter synthesis of multiple sources. If you have the VRAM (18+ GB), Qwen reasons better over complex queries with 4–5 web results bundled together. Tradeoff: slower baseline inference (~15–25 tok/s on RTX 4070 Ti), and web search integration takes longer.
Speed alternative: Mistral 7B. Fastest on consumer hardware (~35–50 tok/s baseline). Adequate at web synthesis, but makes occasional errors when results conflict. Best if speed matters more than reasoning depth.
Avoid: Llama 2, older open models, and highly quantized versions (8-bit or lower). They struggle with instruction-following when context bloats from web fetches.
[!NOTE] Quantization matters. Q4_K_M quantization (recommended) preserves quality while fitting small GPUs. Don't use Q3 or Q2 with web search unless you enjoy nonsense outputs. Q5 or higher is overkill for this use case.
Real-World Performance: What to Expect
This is where I have to be honest: as of April 2026, no published benchmarks isolate the performance cost of web search on common models. The feature shipped too recently. I've gathered estimated numbers from Ollama telemetry, community reports, and local testing, but they're not gospel.
Here's what the data suggests:
Latency per web search query:
- Time to fetch results: ~150–250ms (network-dependent)
- Model inference with expanded context: ~100–200ms additional
- Total per query: ~250–450ms end-to-end
Token speed degradation (estimated):
- Llama 3.1 8B on RTX 4070 Ti: Baseline ~30 tok/s. With web search active: ~20–25 tok/s (20–30% reduction, estimated)
- Qwen 2.5 14B on RTX 4070 Ti: Baseline ~18 tok/s. With web search active: ~12–15 tok/s (estimated)
Why the slowdown? Context window expands when web results are included. A typical web fetch adds 800–2,000 tokens of content per result. The model has to process that extra context, which costs time.
VRAM overhead of web search plugin:
- Plugin size: ~100 MB
- Runtime buffers for fetched content: varies, but plan for <300 MB additional
This is genuinely small compared to RAG embeddings (4+ GB).
[!TIP]
Don't chase perfect benchmarks. Hardware varies. Your RTX 4070 Ti probably performs slightly different than mine. Network speed affects latency more than hardware does. Test on YOUR rig with YOUR internet connection. Run a few queries, measure with ollama ps, and you'll know better than any published figure.
Native Fetch vs. Full RAG: When to Pick Each
This is the decision that matters.
Use native web fetch when:
- You need real-time information (news, stock prices, product releases)
- You're doing single-query lookups ("What's the latest RTX price?")
- Your VRAM budget is tight (<16 GB total)
- Setup speed matters (30 minutes vs. 4+ hours)
- You don't need the model to remember previous queries
Build RAG when:
- You're analyzing long documents (research papers, earnings reports)
- You need persistent knowledge (the model should "remember" what you told it)
- You're doing professional work (customer support, knowledge bases) where consistency matters
- You have 24+ GB VRAM to spare for embeddings
- You want fine-grained control over which documents get indexed
Hybrid approach (best for power users):
- Start with native fetch for real-time queries
- Add a lightweight RAG layer for your own documents (company docs, research)
- Use native fetch for things you can't index (breaking news, current prices)
Scenario Comparison
Scenario: "What's the latest news on local AI?"
- Native fetch: 1 web search (~300ms), answer ready, 2 seconds start-to-finish
- RAG: Only works if you pre-indexed news articles (most people don't)
- Winner: Native fetch
Scenario: "Summarize this 30-page research paper I just downloaded"
- Native fetch: Fetch fails or truncates (content too long for single query)
- RAG: Chunk the paper, embed sections, retrieve top 3 chunks, answer based on them
- Winner: RAG by far
Scenario: "Who won the last software engineering gold medal at the Putnam competition?"
- Native fetch: ~400ms web search, might find the answer
- RAG: Only works if Putnam results are in your indexed knowledge base (unlikely)
- Winner: Native fetch (but won't help if your indexed docs don't cover it)
Scenario: "Analyze our company's last 3 quarterly earnings reports"
- Native fetch: Each earnings report = new web search; slow, loses context across reports
- RAG: Chunk all three PDFs, embed them, retrieve relevant sections across all three at once
- Winner: RAG decisively
The pattern: native fetch = better for real-time, single-query lookups. RAG = better for analyzing documents you control.
Common Setup Gotchas
"OpenClaw service won't start"
Error: Error: connection refused on localhost:8888
Fix 1: Make sure ollama signin completed successfully. Run it again if unsure.
Fix 2: Check if another service is using port 8888:
# macOS/Linux
lsof -i :8888
# Windows (PowerShell)
Get-NetTCPConnection -LocalPort 8888If something else is using port 8888, either kill that process or tell OpenClaw to use a different port:
ollama launch openclaw --port 9999Then update your API calls to use localhost:9999.
Fix 3: Restart Ollama entirely:
# Kill any running Ollama processes
pkill ollama
# Wait 5 seconds
sleep 5
# Start fresh
ollama serve
# In another terminal
ollama launch openclaw"Web search returns empty results"
Some websites block automated access. If a query returns no results:
Try 1: Rephrase the query more specifically.
Instead of: "local AI GPU" Try: "Best GPU for Llama 3.1 2026"
Try 2: Use the model's own knowledge if the information is general. Ask: "Based on your training data, what's the difference between..." instead of forcing a web search.
Try 3: Provide the URL directly as context instead of searching:
I found this article at https://example.com. Please summarize it.The fetch plugin will grab it without searching.
"Model ignores web search results"
Older quantizations (Q3, Q2) sometimes don't follow instructions to use web results. Solutions:
- Upgrade to Q4_K_M or higher quantization
- Rephrase your request: "Based on the following web search results: [content], please answer..."
- Try a different model (Llama 3.1 8B is more reliable at this than others)
"Inference is way slower than expected"
If you're seeing single-digit tok/s when you expected 20+:
Cause 1: Your model quantization is too aggressive (Q2, Q3).
- Solution: Re-pull the model with Q4_K_M quantization
Cause 2: Context window is bloated from previous web fetches.
- Solution: Start a fresh conversation (new terminal session)
Cause 3: CPU bottleneck, not GPU.
- Solution: Check
ollama psto confirm GPU is being used. If CPU is doing the work, increase CUDA batch size in Ollama settings.
Should You Use This or Build Full RAG?
The honest answer: most people should start with native web fetch. The VRAM savings alone (4–6 GB) and setup time savings (2–3 hours) make it the default. Upgrade to RAG when you hit specific limits—not before.
Signs you need RAG:
- You find yourself repeating the same web searches (wasting latency)
- You're analyzing multiple related documents in the same session
- Performance matters more than freshness (cached embeddings beat live search)
- You're building a business feature, not a personal tool
Signs native fetch is enough:
- You're asking one-off questions ("How much does an RTX 5070 cost?")
- You need the latest information (news, prices, releases)
- VRAM is your constraint
- You like simple systems
The CraftRigs Take
Ollama 0.18.1 shipped at exactly the right time. For three years, the gap between local LLMs and their cloud cousins has been "no web access." Every local builder who wanted live data had to either:
- Accept outdated training data
- Spend 4+ hours building RAG
- Give up and use ChatGPT
Now there's a third path: 30 minutes, zero VRAM sacrifice, real-time results. It's not perfect—benchmarks don't exist yet, the feature is fresh, edge cases haven't surfaced. But for the 90% of people asking "How do I search the web with my local model?", this is the answer.
The feature hits the sweet spot between complexity and capability. RAG is still the right answer for businesses and document-heavy workflows. But for personal AI tools, research assistance, and keeping your models current without syncing new training data every month, native web fetch changes the equation.
Start here. Upgrade to RAG only when you have a specific reason.
FAQ
Can I use web search with any Ollama model?
Technically yes, but practically no. Any model 7B or larger can use web search. But only Llama 3.1 8B and Qwen 2.5 14B reliably integrate results without errors. Smaller models and older models (Llama 2, Mistral original) struggle with instruction-following when context bloats.
Does web search cost money?
No. Ollama's native web search is free. You authenticate via ollama signin but no API keys, credits, or payments required. This is one of the biggest advantages over cloud models.
How fresh is the web search data?
Real-time. The web fetch happens when you query, not on a schedule. Results are current to within minutes of your search.
Can I save web search results to my local knowledge base?
Not automatically. Native fetch is stateless—each query is independent. If you want persistent storage, you'd need to manually copy results into a RAG database, which defeats the purpose. This is where RAG wins.
What if I need to search within PDF files I uploaded?
Native web fetch won't work. That's a RAG use case. You'd chunk the PDFs, embed them, and retrieve from your local vector database.
Will web search work offline?
No. Web search requires internet. The model itself can run offline, but queries to external data won't work.
Is there a difference between web_search and web_fetch tools?
Yes. web_search initiates a search query and returns multiple results. web_fetch requires you to provide a URL and fetches just that page. Both are available in Ollama 0.18.1, but most queries use web_search since it's more flexible.