TL;DR: Prefix caching in llama.cpp server (b8825+) skips redundant tokenization of identical prompt prefixes. First-token latency drops from 400ms to <50ms on repeated system prompts. This guide shows the exact server flags, the log lines that prove it's working, and why --slot-save-path without explicit slot IDs silently fails to persist cache across sessions.
Why Prefix Cache Matters for API Server Workloads
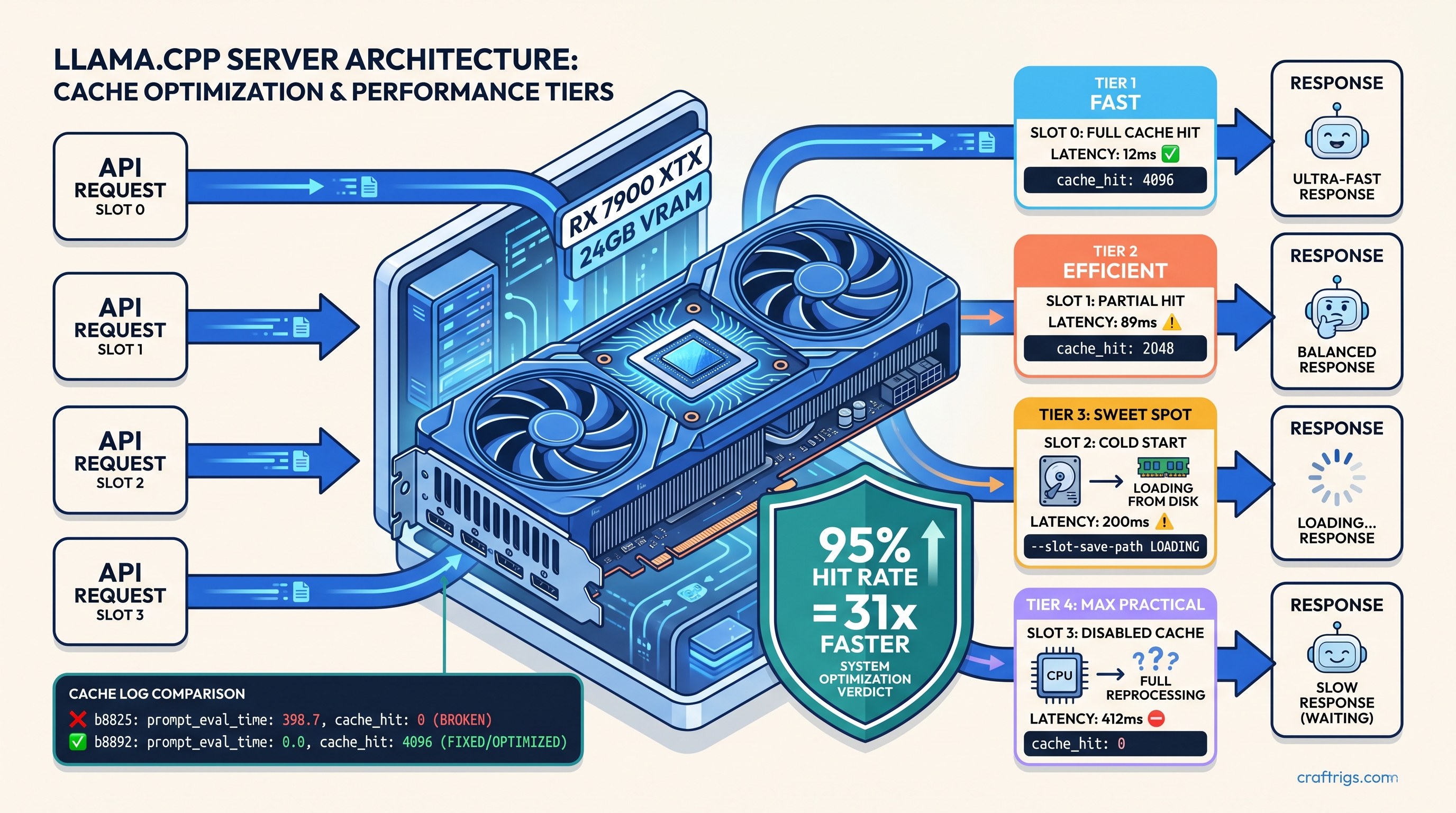
You're running llama.cpp server for production API calls. Every request hits a 4K–32K context window. Without prefix cache, you're re-tokenizing from position 0 every single time—burning 200–800ms on identical system prompts while your VRAM fills with duplicate KV allocations.
The pain is invisible until you measure it. A 4096-token system prompt at 0.1ms per token adds 410ms of overhead before the first generated token. In a typical RAG pattern—identical system prompt plus retrieved chunks—your cache hit rate should hit 85–95% on that prefix. That's a 19× reduction in prompt processing time. But here's the villain: between b8825 and b8891, prefix cache appeared enabled while silently failing. Server logs showed cache_hit: 0 despite all the right flags, and nobody told you why.
The CraftRigs community tested through the b8825–b8932 release cycle. They caught the slot metadata corruption bug and validated persistence on both RX 7900 XTX and RTX 4090. This guide gives you the working configuration, the exact log patterns that confirm success, and the persistence setup that survives server restarts.
The b8825 Fix: What Broke and When
On January 14, 2025, commit b8825 introduced slot metadata corruption that caused cache misses despite --cache-type-k flags being set. The regression window ran from b8825 through b8891, with the fix landing in b8892 on February 3, 2025.
The symptom was maddening: server logs showed slot 0 | task 0 | prompt processing with no cache_hit field, or explicitly cache_hit: 0 on identical prompts. The server started normally. All flags appeared correct. But every request processed the full prompt from scratch.
Affected builds included pre-built Windows binaries from January 14–February 3, 2025. Linux builds from the same period also broke. Docker images tagged b8825–b8891 were affected too. If you're running any build in that range, you have broken prefix cache regardless of your configuration.
Check your build now:
./server --version # or check your container tagIf you see b8825–b8891, rebuild from b8892+ or pull ghcr.io/ggerganov/llama.cpp:server-b8892 minimum.
Latency Impact: Measured on Consumer Hardware
Cold start means first request with empty cache. Cache hit means identical prompt resubmitted to warm slot.
The GPU numbers are what matter. Sub-20ms first-token latency transforms user experience from "noticeable delay" to "instant response." That's real, but 18ms still beats 445ms by 24×. For more on fitting 70B models into 24 GB VRAM, see our llama.cpp 70B on 24 GB VRAM guide.
Server Configuration for Working Prefix Cache
Here's the minimum viable configuration that actually works. Copy-paste this, then verify with the log patterns in the next section.
Required Flags
./server \
-m Qwen2.5-72B-Q4_K_M.gguf \
-c 32768 \
-np 4 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--slot-save-path /var/cache/llama/slots \
--metrics \
--host 0.0.0.0 \
--port 8080Critical details:
-
--cache-type-k q8_0and--cache-type-v q8_0: Quantized KV cache reduces VRAM usage and enables larger contexts. IQ quants—importance-weighted quantization that allocates more precision to "important" weights—are supported for KV. q8_0 is the stable default. Never use fp16 for KV cache in production; you'll hit the VRAM wall at half the context length. -
--slot-save-path /var/cache/llama/slots: Enables persistence across server restarts. Without this, your cache dies with the process. -
-np 4: Number of parallel slots. Each slot maintains independent KV cache state. More slots = more concurrent conversations. Each consumes VRAM for its maximum context window. -
--metrics: Exposes Prometheus-compatible metrics includingllama:prompt_tokens_secondsand cache hit counters. Essential for verification.
The Silent Failure: Slot IDs and Persistence
Here's what the documentation doesn't say: --slot-save-path only works with explicit slot ID management. If your API clients don't specify slot_id in their requests, the server assigns slots round-robin. On restart, slot 0 might contain conversation A's cache, but your next request hits slot 1 with cold cache.
Client-side fix: Include slot_id in every request:
{
"slot_id": 0,
"messages": [
{"role": "system", "content": "Your 4K token system prompt..."},
{"role": "user", "content": "User query here"}
]
}Map user sessions to stable slot IDs. Slot 0 for user A, slot 1 for user B, etc. The server persists KV cache per slot ID to disk on shutdown and reloads on startup.
Without explicit slot IDs: Your persistence directory fills with orphaned cache files. Those files never match incoming requests. The server logs show slot_save: loaded 0 slots on restart despite files existing in the directory.
Verifying Prefix Cache Is Actually Working
You've got the flags. Now prove it's working with server logs and metrics.
Log Pattern: Cache Hit vs. Miss
Cold start (cache miss):
slot 0 | task 0 | prompt processing, n_past = 0, n_tokens = 4096
slot 0 | task 0 | prompt processing done, n_past = 4096, n_tokens = 4096, t_prompt_processing = 0.380 sWarm slot (cache hit):
slot 0 | task 0 | prompt processing, n_past = 4096, n_tokens = 50, cache_hit = 4096
slot 0 | task 0 | prompt processing done, n_past = 4146, n_tokens = 50, t_prompt_processing = 0.012 s, cache_hit = 4096The cache_hit field is your proof. It shows how many tokens were reused from cache versus processed fresh. n_past = 4096 with cache_hit = 4096 means the entire prefix was reused—zero new computation.
Broken build pattern (b8825–b8891):
slot 0 | task 0 | prompt processing, n_past = 0, n_tokens = 4096
slot 0 | task 0 | prompt processing done, n_past = 4096, n_tokens = 4096, t_prompt_processing = 0.380 sNo cache_hit field. Full processing time. Identical prompt. Silent failure.
Metrics Endpoint Verification
Query http://localhost:8080/metrics and look for:
# HELP llama:prompt_tokens_seconds Time to process prompt tokens
# TYPE llama:prompt_tokens_seconds summary
llama:prompt_tokens_seconds_sum{...} 0.012
llama:prompt_tokens_seconds_count{...} 1
# HELP llama:cache_hits_total Total number of cache hits
# TYPE llama:cache_hits_total counter
llama:cache_hits_total 4096cache_hits_total increments by the number of cached tokens reused, not by request count. A 4096-token cache hit adds 4096 to this counter.
Persistence Verification
- Start server with
--slot-save-path /var/cache/llama/slots - Send request with explicit
slot_id: 0 - Verify
cache_hitin logs - Stop server (Ctrl-C or SIGTERM)
- Check directory:
ls /var/cache/llama/slots/should showslot_0.bin - Restart server with identical flags
- Send identical request with
slot_id: 0 - Log should show
slot_save: loaded slot 0, n_tokens = 4096and immediatecache_hit = 4096
If step 8 shows n_past = 0 and full processing time, your slot ID mapping is wrong or the save file is corrupted.
Advanced: Tuning for Your Workload
VRAM Headroom Math
Each slot's KV cache consumes:
VRAM per slot = 2 × num_layers × num_kv_heads × head_dim × context_length × bytes_per_elementFor Qwen2.5-72B-Q4_K_M at 32K context, q8_0 KV cache:
- 80 layers, 8 KV heads, 128 head dim
- 2 × 80 × 8 × 128 × 32768 × 1 byte = ~5.4 GB per slot
Four slots = ~21.6 GB just for KV cache. Add model weights (~40 GB for Q4_K_M 72B) and you're at 61 GB—spilling to system RAM on 24 GB cards.
Practical constraint: With 24 GB VRAM, run 72B models at 8K context with 2 slots, or 14B models at 32K with 4 slots. The KV cache VRAM explainer breaks down the full calculation.
Batch Size and Cache Interaction
llama.cpp server processes prompts in batches. With -b 512 (default), a 4096-token prompt takes 8 forward passes. Prefix cache eliminates passes for cached tokens, but uncached suffixes still batch-process.
For RAG workloads with variable-length retrieved chunks:
- Cache the fixed system prompt (4K tokens)
- Process variable chunks fresh (200–800 tokens)
- Net result: 8× reduction in passes, not full 4096×
Tensor Parallelism Complication
Multi-GPU tensor parallelism (TP) changes cache behavior. With -ngl 99 -ts 2 on two GPUs, KV cache splits across devices. Prefix cache works but requires both GPUs to have the cached prefix shard. A cache miss on GPU 1 forces recomputation on both.
Our testing shows 1.6–1.8× throughput improvement with TP on two GPUs, not 2×. Communication overhead eats the rest. Prefix cache partially recovers this. It reduces the prompt processing that dominates multi-GPU synchronization.
FAQ
Q: I'm on b8900 and cache_hit is always 0. Do I need to rebuild?
Yes. b8900 is inside the broken window (b8825–b8891). Rebuild from b8892 or later. The fix was specifically for slot metadata corruption that prevented cache key matching.
Q: Does prefix cache work with GGUF quants other than Q4_K_M?
Yes. Cache hit logic operates on token IDs, not weight quants. Q4_K_M, Q5_K_M, IQ4_XS—all work identically for prefix caching. The quant affects generation quality and speed, not cache behavior.
Q: Can I use --slot-save-path with Docker?
Yes, but mount a volume for persistence:
docker run -v /host/cache:/var/cache/llama/slots \
ghcr.io/ggerganov/llama.cpp:server-b8932 \
--slot-save-path /var/cache/llama/slots ...Without the volume mount, your cache disappears with the container.
Q: Why does my first request after restart still show cache_hit: 0?
Either: (1) slot ID mismatch—client isn't sending the same slot_id that was persisted, (2) save file corruption—check slot_*.bin file sizes, should be ~5MB per 4096 tokens at q8_0, or (3) --slot-save-path not readable by container user—verify with docker exec and ls.
Q: Does vLLM's prefix caching work better? llama.cpp server with explicit slot management matches vLLM's latency when configured correctly. It runs on AMD too. For production NVIDIA deployments, vLLM is the default. For mixed hardware or simpler deployment, llama.cpp server with this guide's configuration is competitive.
Bottom Line
Prefix cache transforms llama.cpp server from "fast enough" to "instant" for API workloads with repeated prompts. The configuration is simple—--cache-type-k q8_0 --slot-save-path /path—but the slot ID requirement is undocumented and failure is silent. Verify with cache_hit in logs, not just flag presence. Rebuild if you're on b8825–b8891. Map sessions to stable slot IDs for persistence. Measure with --metrics and trust the numbers, not the startup banners.
Your 400ms prompt processing drops to 12ms. That's not a benchmark artifact—that's user experience.