Eight days apart. That's the gap between NVIDIA shipping Nemotron 3 Super (March 11) and Mistral dropping Small 4 (March 17). Both sit in the 119-120B parameter MoE class. Both claim to be built for agentic workloads. Both are open weights. And they make completely different architectural bets — which means the right pick for your hardware isn't obvious at all.
What These Models Actually Are
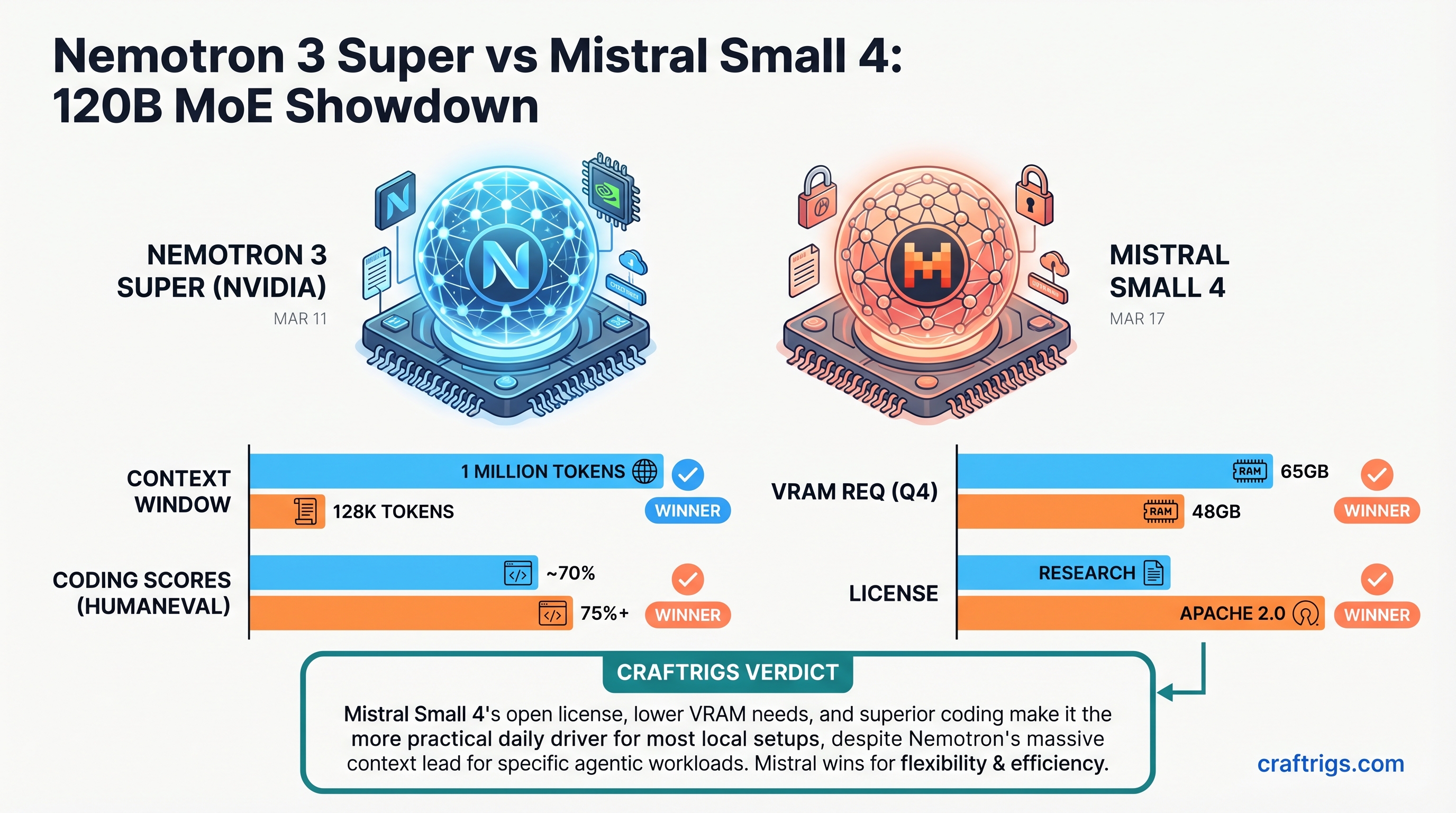
Start with Nemotron 3 Super. It's 120B total parameters, 12B active per token. That's nearly twice the active parameter density of Mistral Small 4's 6.5B per token — which means more computation per forward pass and, in theory, richer reasoning on each token. NVIDIA built it on a hybrid Mamba-Transformer stack, layering recurrent Mamba-2 state-space blocks alongside standard attention layers. The Mamba layers process long sequences in O(1) memory, which is the structural reason this model can hold a 1 million token context window without the KV cache growing into something unusable.
The expert routing is unusual too. NVIDIA calls it LatentMoE — instead of routing tokens from the full hidden dimension like every other MoE model, it compresses them into a latent space first, then routes to experts. This lets 22 experts fire per token at the compute cost of only one standard expert. 512 total experts in the pool.
Mistral Small 4 takes a different path entirely. 119B total, 6.5B active, 128 experts with 4 active per token. Standard transformer architecture — no Mamba, no latent routing. What it adds instead is breadth: configurable reasoning depth, multimodal input (text and images), and a single model that replaces three separate Mistral deployments. Previously you needed Magistral for reasoning, Pixtral for vision, and Devstral for agentic coding. Now there's one model card.
Both ship with configurable thinking modes you can toggle per request.
Note
Quick spec comparison
| Nemotron 3 Super | Mistral Small 4 | |
|---|---|---|
| Total params | 120B | 119B |
| Active params | 12B | 6.5B |
| Experts | 512 total / 22 active | 128 total / 4 active |
| Context | 1M tokens | 256K tokens |
| Architecture | Hybrid Mamba-Transformer MoE | Transformer MoE |
| License | NVIDIA Nemotron Open License | Apache 2.0 |
| Multimodal | No | Yes (text + image) |
| Release | March 11, 2026 | March 17, 2026 |
VRAM Reality Check
Here's where people tend to get confused with large MoE models. The active parameter count determines compute — but the total parameter count determines how much memory you need to hold the weights. Both models are roughly 120B parameters total, so their memory footprints at the same quantization level are nearly identical.
Q4 quantization (GGUF): About 65GB for weights plus overhead. A single H100 80GB handles this comfortably. If you're on consumer hardware, a dual RTX 4090 (48GB combined VRAM) can technically run Q4 with roughly 17GB offloaded to CPU — but you'll pay for it in speed, dropping to around 8-12 tokens per second versus 30+ on a properly-sized GPU. Unsloth confirms Nemotron 3 Super runs on "a device with 64GB of RAM, VRAM, or unified memory," and the same calculus holds for Mistral Small 4.
Mac users have it easier. Mac Studio Ultra (192GB unified memory) or any Apple Silicon machine with 64GB+ unified memory runs Q4 of either model without trouble.
Q8 quantization: Roughly 125-130GB of storage needed. You need 2x H100 80GB (160GB combined) or a Mac Studio Ultra to stay in-VRAM. Four RTX 4090s at 96GB total VRAM theoretically get you there, but the CPU offload situation becomes punishing.
Caution
Neither model runs acceptably on a single consumer GPU. Anyone claiming to run Nemotron 3 Super or Mistral Small 4 "on an RTX 4090" without heavy offloading is either running a Q2 quant that's degraded beyond usefulness or isn't being honest about token speeds. Plan for at minimum a single H100 80GB, or a Mac with 64GB+ unified memory, before committing to either model locally.
For a full breakdown of what single-GPU 24GB hardware can actually do with Mistral Small 4, see the Mistral Small 4 setup guide.
Benchmark Comparison
There's a meaningful gap on coding. Mistral Small 4 in reasoning mode scores 63.6% on LiveCodeBench. Nemotron 3 Super scores around 38%. That's not noise — it's 25 points. For pipelines that generate production-grade code, Mistral has a clear edge.
Flip to agentic task benchmarks and the picture shifts. Nemotron 3 Super was specifically trained across 21 RL environments for terminal and browser-based workflows. It scores 56% on Terminal-Bench 2.0, 61% on BrowseComp, 54% on OSWorld-Verified, and 44% on SWE-bench Verified. Comparable Mistral Small 4 scores on those same agentic benchmarks aren't widely published yet — the model shipped six days ago.
For reasoning quality, Mistral Small 4 hits 71.2% on GPQA Diamond in reasoning mode, with 78.0% on MMLU Pro. NVIDIA claims leading scores on AIME 2025 for Nemotron but independent community verification is still coming in as of today. That'll settle within a couple of weeks.
Instruction following is closer than the headline numbers suggest. Mistral scores 48% on IFBench in reasoning mode. Nemotron also lists IFBench among its leading benchmarks but hasn't published a clean third-party number — the BFCL tool-calling leaderboard doesn't yet include the Super model specifically, though Nemotron 3 Nano sat at 41.6% there, suggesting Super should score higher.
One thing worth flagging: Mistral Small 4's multimodal capability sounds like a real differentiator on paper. One model with vision, reasoning, and coding? Great story. But community testing of the vision side has not gone well. Multiple builders on r/LocalLLaMA found image understanding genuinely poor — both via the official Mistral API and local inference. For a model that was supposed to replace Pixtral entirely, that's a rough first week. Treat vision as a beta feature for now.
Which Hardware Runs Each Model Practically
Nemotron 3 Super has tighter hardware dependencies. The Mamba SSM layers and LatentMoE routing require CUDA-specific backends: TensorRT-LLM, vLLM with Triton attention, or SGLang. Getting peak throughput out of the NVFP4 checkpoint (the native training precision) requires Hopper or Blackwell GPUs — H100s or H200s. On Apple Silicon, you're limited to GGUF via llama.cpp, which works but misses the Mamba efficiency gains that make this model interesting in the first place.
Mistral Small 4 runs on more things with less friction. Standard transformer architecture means vLLM, llama.cpp, Transformers, and Ollama all work without special configuration. For Apple Silicon or mixed-hardware environments, Mistral is the less painful choice. The NVFP4 checkpoint is available if you have Hopper hardware, but you don't need it to get reasonable throughput.
Tip
Running Nemotron 3 Super on vLLM? You need --attention-backend TRITON_ATTN and --async-scheduling both set. Missing either causes silent performance degradation in the Mamba SSM cache — the model runs, looks normal, but is 30-40% slower than it should be. NVIDIA's own serving guide shows both flags as required.
Head-to-Head: Use Case Winners
Long-horizon autonomous agents: Nemotron wins, and it's not particularly close. The 1M context window against Mistral's 256K is the structural difference between an agent that can hold a complete multi-session research trace in context and one that constantly needs to compress or summarize. In multi-agent systems — where several sub-agents share and re-send history every turn — 256K runs out surprisingly fast. NVIDIA also specifically designed Nemotron's RL training for exactly this scenario.
Coding and software development agents: Mistral Small 4 wins. A 25-point gap on LiveCodeBench is hard to argue away. The Devstral lineage shows up in the output quality. If your pipeline involves generating real code, go Mistral.
Instruction following and structured output: Close. Probably a slight edge to Nemotron for tool-calling reliability based on architecture and training focus, but this is genuinely unsettled given how recently both models shipped.
Creative writing and multimodal inputs: Mistral by default — it accepts images, Nemotron doesn't. Just don't expect the vision side to be ready for production use based on current reports.
Commercial deployment and fine-tuning: Mistral wins outright. Apache 2.0 means you can fine-tune, redistribute, and build commercial products without restriction. The NVIDIA Nemotron Open Model License is permissive but explicitly limits use in competing AI platforms — worth reading carefully before productionizing.
Final Recommendation
Nemotron 3 Super is the pick if you're running multi-step autonomous agents on long tasks — code analysis pipelines, cybersecurity triaging, document retrieval agents. The 1M context window and purpose-built agentic RL training make it the more capable orchestration model. Budget for NVIDIA hardware; plan around the CUDA toolchain.
Mistral Small 4 is the pick if you're building a coding assistant, an agent that handles both code and images, or anything that needs Apache 2.0 clean-room freedom. It's also the more practical choice on Apple Silicon or heterogeneous hardware environments.
And if you're genuinely undecided: both models will have two more weeks of community benchmarking by the time you actually finish standing up your infrastructure. The independent agentic evals that exist right now barely scratch the surface of what either model can do. Check back around April 1 before locking in.
For environment setup and model configuration, see the Mistral Small 4 local setup guide.
See Also
- Mistral Small 4 Local Setup Guide — hardware tiers, llama.cpp config, and real performance numbers
- Gemma 4 GPU Sweet Spot — similar VRAM planning exercise for Google's next open model
- Hardware for a Local RAG System — if agentic workloads with document retrieval are your target