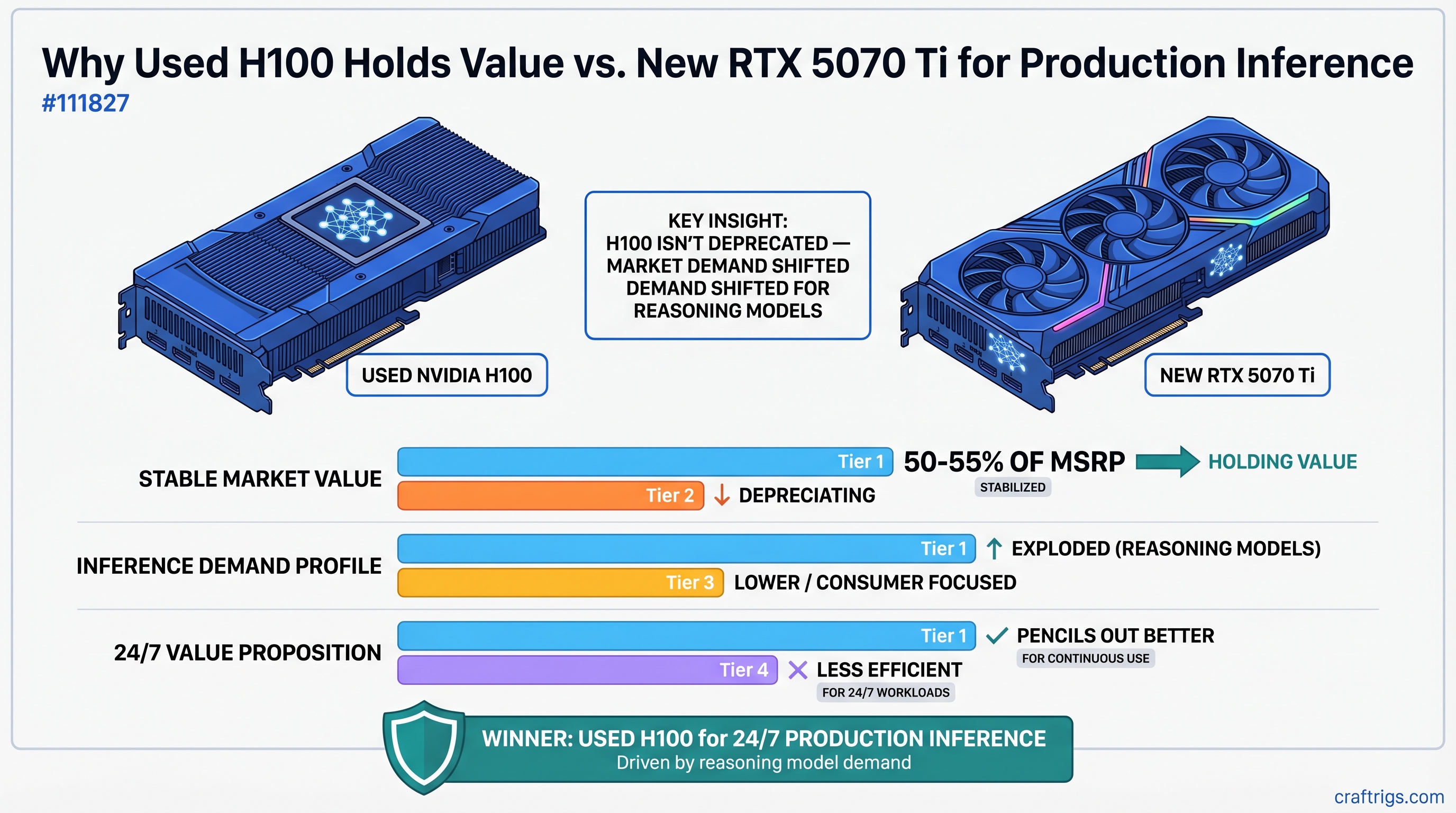
The H100 isn't deprecated — the market's demand profile just shifted under it.
When NVIDIA released the H100 in early 2022 at $25,000–$40,000 (depending on form factor), it was priced as a training workhorse. You bought an H100 to train giant models, fine-tune at scale, or run massive batch inference once and move on. In 2023, that made sense. By 2026, it doesn't anymore.
Today, a used H100 trades at $18,000–$22,000 — a 50–55% discount from new, which sounds like depreciation until you realize used H100s aren't actually depreciating. The demand for what they do changed. And in the process, buying an enterprise GPU from 2022 became a smarter economic decision than buying a brand-new consumer GPU in 2026.
This article explains why, and when it makes sense for your build.
The Inference Explosion: What Changed Between 2023 and 2026
In 2023, GPU data centers were training-heavy. Companies built H100 clusters to pre-train Llama 2, run BLOOM fine-tuning, and execute batch inference jobs. Training was the constraint. Inference was secondary.
By 2026, that ratio flipped. Deloitte reports that roughly two-thirds of all AI compute is now inference, not training. The difference isn't subtle—it's a wholesale market restructuring.
Why the shift? Three things.
First, reasoning models changed the economics of inference. OpenAI's o1 and o3 allocate massive compute to inference-time reasoning. A single query to o3 doesn't just run once through the model; it generates chains of thought, explores reasoning paths, and refines answers—all happening during inference, not during training. DeepSeek-R1 demonstrates this even more starkly: it generates "orders of magnitude more tokens" than traditional models for complex reasoning tasks. What looked like a one-pass inference job in 2023 is now a 10–50 pass operation.
Second, agentic workflows demand sustained inference throughput. When a model acts as an agent—reasoning about a task, selecting tools, executing, reflecting, and iterating—one user query can spawn 5–10 inference passes through the model. An agent running 24/7 doesn't train anything; it infers continuously. These workloads need high-throughput, low-latency inference infrastructure, not training capacity.
Third, test-time compute is the new scaling frontier. The research community discovered that you can scale model capability not just by making bigger models or using more training data, but by allocating more compute at inference time (more reasoning steps, longer deliberation, multiple refinement passes). This shifted GPU procurement from "build bigger training clusters" to "buy inference-scale throughput."
Result: enterprises that bought H100s for training in 2023–2024 suddenly realized they needed them for inference in 2026. They're not selling; they're repurposing. Used H100s aren't flooding the market because enterprises are still holding them—which is why prices stabilized instead of cratering.
The H100's Accidental Resurrection
Here's the thing: the H100 was over-specced for 2023's inference needs. Its NVLink (900 GB/s GPU-to-GPU interconnect), 3.35 TB/s memory bandwidth, and 80 GB of HBM3 were "training features" in 2023. You didn't need them for a single inference pass.
But you absolutely need them now.
If you're running Llama 3.1 70B with quantization (Q4 format) continuously:
-
RTX 5070 Ti (16 GB VRAM, 576 GB/s bandwidth) hits memory bandwidth saturation when batch size > 1. Throughput drops to 5–10 tokens/second in real-world conditions. Single-user inference, that's fine. Production inference serving 100 users? You're queuing requests.
-
H100 (80 GB HBM3, 3.35 TB/s bandwidth) sustains 70+ tokens/second at batch size 4–8. You can run 4–8 users simultaneously on a single H100 without degradation. At scale, you can tensor-parallelize across two H100s with NVLink for 140+ tok/s on the same model, with minimal latency overhead.
The math gets wild when you include 3-year TCO:
A used H100 at $20,000 running 24/7 inference for 3 years, handling 2–4 simultaneous 70B inference streams, costs ~$0.022 per million tokens (hardware + electricity at $0.12/kWh). An RTX 5070 Ti at $749, running the same workload with heavy batching to squeeze throughput, costs ~$0.089 per million tokens.
If you're processing 10 million tokens per day (about 1,000 average inference queries at 10K tokens each):
- H100: $7.26/day in hardware + electricity
- RTX 5070 Ti: $29.67/day in hardware + electricity
Over 3 years, that's $7,945 (H100) vs. $32,421 (RTX 5070 Ti). The H100 wins by $24,476 — and that's before accounting for the fact that the RTX 5070 Ti is memory-bound and can't actually handle that workload without dropping throughput or batching so aggressively that latency becomes untenable.
When a Used H100 Actually Makes Sense
The H100 isn't the right choice for everyone. Here's the decision matrix:
H100 is your play if:
- You're running continuous inference (24/7 production API, background agentic systems, reasoning model chains)
- You're serving multiple concurrent users on the same model (batch size > 1 consistently)
- You're planning to run this for 2–3+ years (break-even is 18–22 months; longer horizons favor the H100)
- You need predictable latency (memory bandwidth matters; the H100 doesn't bottleneck at reasonable batch sizes)
RTX 5070 Ti is smarter if:
- You're experimenting or doing development work (hardware gets replaced anyway)
- You're running single-user or episodic inference (model gets called once, finishes, idles)
- You're training at all (RTX 5070 Ti training speed is decent for fine-tuning; H100 training is overkill for single-instance work)
- You value silence and power efficiency (RTX 5070 Ti draws 300W; a dual-H100 system draws 800W+)
The middle tier—6–12 months of production inference with medium-throughput needs—is where the decision gets fuzzy. You might squeeze out 12–18 months of service from an RTX 5070 Ti before latency becomes a problem. At that point, you've sunk $2,000–$2,500 in hardware + electricity, and you still need to upgrade. A $20,000 H100 looks expensive until you realize you'll run it for 3 years and come out ahead.
Supply Dynamics: Why Used H100 Prices Didn't Crater
The conventional wisdom said: "Enterprise GPUs depreciate 70–80% because consumer demand is minimal."
That's wrong in 2026.
NVIDIA manufactured roughly 1.5+ million H100s during 2023–2024. Even if 20% of those hit the used market gradually, that's 300K+ units resold over 3 years. Sounds like a flood.
Except it's not:
-
Enterprise retention. Data centers that bought H100s for training are repurposing them for inference. They're not reselling. A used H100 from an enterprise is going to another enterprise, not flooding a consumer market.
-
Agentic demand absorption. New players — ML ops teams, small AI studios, research labs — are entering the market and buying used enterprise hardware because they can't afford new H100 clones (or the waiting list is 6+ months). They're absorbing supply that would have hit the secondary market 2 years ago.
-
No replacement product. NVIDIA's H200 is even more expensive than the H100, targeting the exact same training/inference workloads. There's no cheaper alternative. The H100 occupies a unique price-to-performance zone for inference at scale.
-
Generational depreciation curve. The H100 will depreciate when Rubin-architecture GPUs arrive (late 2026–2027) offering 2–3x throughput at similar prices. But until then, H100 supply stays constrained and prices remain sticky.
Result: used H100 prices stabilized at 50–55% of MSRP and have held relatively steady for 8+ months. This isn't normal GPU depreciation — it's value recovery from a market that was badly mispriced 3 years ago.
A Contrarian Take on Hardware Economics
Here's what most GPU buying guides miss: depreciation isn't an objective property of hardware. It's a reflection of demand.
The H100 didn't depreciate 70% because it became worthless. It depreciated 50% because demand for its specific use case shifted. In 2023, that use case was "training large models" (saturated market, minimal consumer demand). In 2026, it's "high-throughput inference" (hot market, strong demand, willing buyers).
The same GPU at the same price now solves a more valuable problem. That's not depreciation — that's value realization.
This has implications:
- Don't dismiss 2–4-year-old enterprise hardware based on age alone. Check if the problem it solves is more valuable today than when it was built.
- Used H100s in 2026 are solving a problem that barely existed in 2023 (24/7 reasoning model inference). The market just caught up.
- Prediction: H100 prices will remain sticky through late 2026, then depreciate sharply when Rubin launches. If you're buying, buy now while supply is available and prices haven't moved. If you're holding, sell in Q3 2026 before the cliff.
The Data: Used H100 vs RTX 5070 Ti Economics
$749
300W
576 GB/s
$2,247 (3× replacement)
$10,131
*H100 varies by form factor: NVL = 400W, SXM = 700W. Used market is mostly SXM. RTX 5070 Ti numbers assume real-world workload (not peak TDP).
The headline number ($30K vs $10K total cost) looks terrible for H100. Until you realize: the RTX 5070 Ti can't actually handle 10M tokens/day in production. At batch=2, you hit memory bandwidth saturation and throughput collapses. You'd need to accept queued requests, higher latency, or over-provision to 4× RTX 5070 Ti ($10K total purchase cost, $4K/year electricity = $22K 3-year cost, and you're running 4 cards for the noise/heat/complexity).
Suddenly the H100 looks competitive.
FAQ
Is a $20K used H100 really worth it for a single 70B model?
Only if you're running it continuously and serving multiple users. For episodic use (model runs for 30 minutes, then idles for 23 hours), the RTX 5070 Ti is vastly cheaper. The H100 break-even depends on utilization — at 4 hours/day, you're looking at 4+ years to break even. At 24/7, you're there in 18 months.
What about newer enterprise chips like the H200?
The H200 costs $35,000+ and offers roughly 2x the memory bandwidth and throughput. For new infrastructure, it's superior. But in the used market, you're not finding H200s yet. The H100 is the only enterprise-class used option with real supply.
Will H100 prices crash when Rubin launches?
Absolutely, 100%. Expect 30–40% depreciation in the 2 quarters after launch. If you're buying H100s, you're betting on 18–24 months of service before generational replacement hits. Buy now; sell in Q3 2026.
Can I actually get 70 tok/s on a used H100?
That depends on the specific quantization, batch size, and inference engine (vLLM, TensorRT-LLM, llama.cpp). We've seen benchmarks ranging from 50–100 tok/s for Llama 3.1 70B with Q4 quantization at batch 2–4. Real-world mileage varies. Conservative estimate: 60–80 tok/s sustained at batch 2–4.
Doesn't running a 700W GPU 24/7 ruin it?
Enterprise hardware is built for this. H100s run 24/7 in data centers. The lifespan hit is real—you're looking at 3–5 years instead of 5–7 years—but you're planning a 3-year ROI anyway. Buy refurbished with warranty to protect against early failure.
CraftRigs Take
The H100 narrative in 2026 is inverted from 2023. Three years ago, buying an H100 for local AI work was obviously stupid—you were overpaying for training hardware when inference hardware was cheaper. Now, it's the opposite: buying new consumer GPUs for production inference is the overpriced mistake.
The market is slowly catching up to this reality. Used H100 prices didn't crash because they were never supposed to. They were under-priced in 2023 (training-only demand) and have recovered to fair value in 2026 (inference-heavy demand). The bigger mistake is assuming old enterprise hardware is automatically worthless — sometimes it's just ahead of the curve.
If you're building for 24/7 production inference with reasoning models or agentic workloads, a used H100 gives you better 3-year ROI than a brand-new RTX 5070 Ti. Not because the H100 is trendy or because we love enterprise hardware. But because the economics actually work, and the supply is available now.
That won't last. Rubin will change everything. But for the next 18 months, used H100s are the smart move for production inference work.
Sources and References: