The M5 Max still isn't out. Apple announced it will arrive in June 2026 with some jaw-dropping prefill specs, but nobody has benchmarked real Llama models on actual M5 Max hardware yet. Meanwhile, the RTX 5090 has been shipping for three months with consistent benchmark data across the community.
So here's what we actually know: the M5 Max will be genuinely fast at processing long documents in one go (prefill), the RTX 5090 dominates at generating tokens one at a time (decode), and neither company is being honest about where each actually wins.
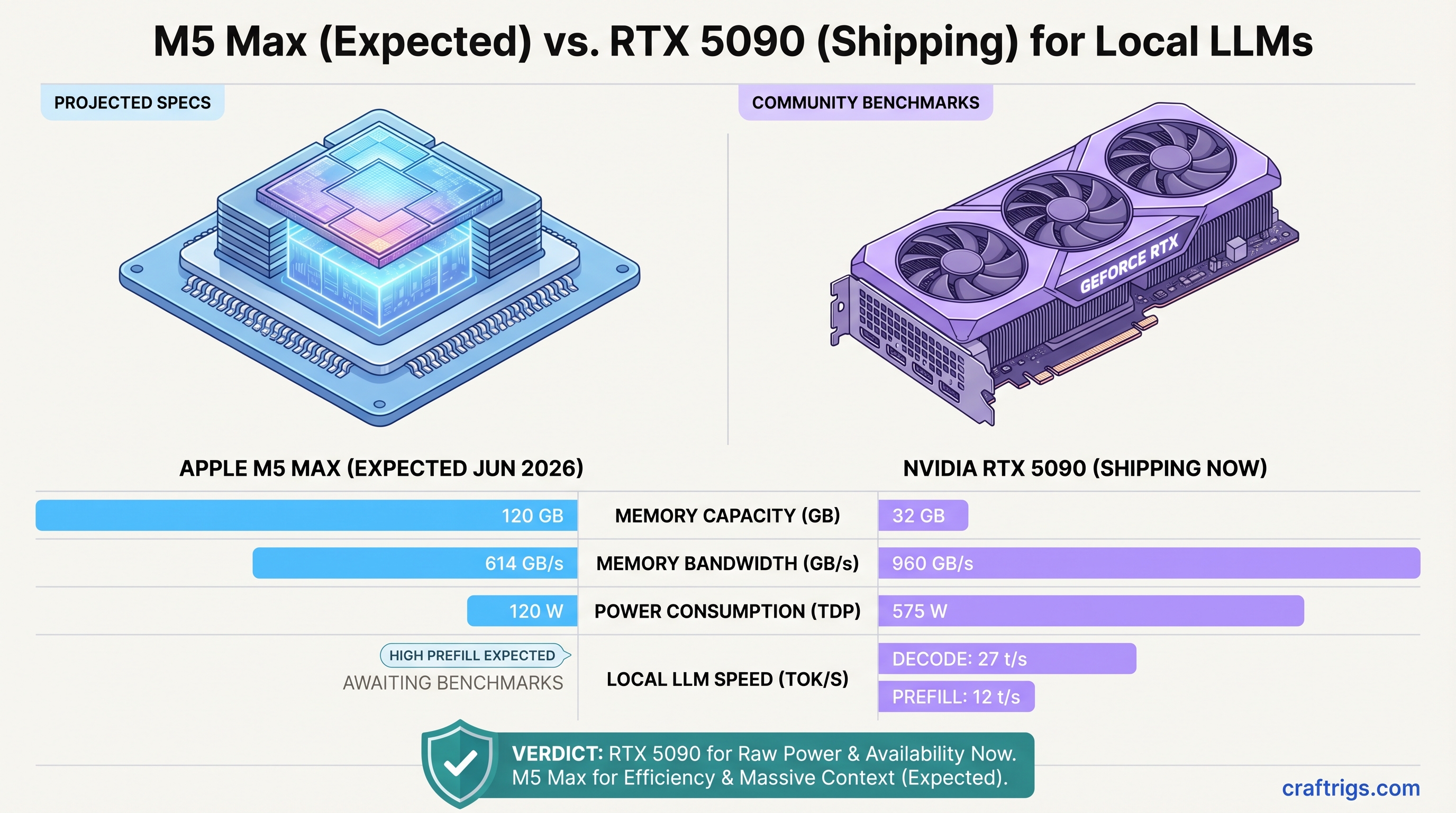
TL;DR: The RTX 5090 is the practical choice right now if you need streaming inference speed—$1,999 for a GPU that decodes 70B models at 27 tok/s and 120B models at ~12 tok/s. The M5 Max will be the better all-rounder when it ships in June, but the Mac Studio M5 Max will start around $4,000+ and lock you into macOS. For maximum flexibility and real-world speed on streaming workloads, RTX 5090 wins today. For batch processing and silent operation, wait for M5 Max.
The Core Difference: Prefill vs. Decode
Before we compare numbers, you need to understand the one thing that matters: Apple and NVIDIA optimize for different tasks.
Prefill is processing all your input tokens at once. You paste a 5,000-word document into your local AI tool, and prefill runs through all 5,000 tokens in parallel. The M5 Max crushes this with 120GB unified memory and Neural Accelerators on every core. Apple claims ~4x faster prefill than the M4 Max on this specific task.
Decode is generating output tokens one at a time. The AI reads what it just wrote, computes the next token, and repeats. RTX 5090's higher clock speeds and massive CUDA core count dominate here.
Why this matters: if you're using a streaming chat interface, you don't care about prefill speed. You care about how long it takes from "hit send" to the first token appearing (prefill) and then how fast tokens flow after that (decode). Decode dominates the experience.
If you're batch-processing 100 documents through an API, prefill speed is your bottleneck. The M5 Max will finish in half the time.
Specs at a Glance
960 GB/s
That memory bandwidth number is key: the RTX 5090 has 56% more bandwidth than the M5 Max. On paper, that looks like RTX 5090 should be faster. In practice, it depends entirely on what workload you're running.
Note
The M5 Max hasn't shipped yet. These specs come from Apple's WWDC keynote and estimated performance based on M5 Pro architecture. Real-world performance data won't exist until Mac Studio M5 Max reviews drop in June 2026.
Prefill Performance: M5 Max's Domain
This is where the M5 Max story gets interesting.
Apple's 4x claim is specific: "processing a long prompt that took 81 seconds on M4 Max completes in 18 seconds on M5 Max." That's ~4.5x faster, and it's driven by 40 new Neural Accelerators (one per GPU core on the 40-core model). These specialized units handle matrix operations that dominate prefill computation.
The RTX 5090 prefill speed on comparable workloads sits around 500–800 tok/s depending on context length and model size. As context grows (4K, 8K, 16K windows), prefill speed degrades due to cache thrashing.
The M5 Max is estimated to hold ~4,400–4,500 tok/s on prefill across most context lengths, thanks to unified memory and the Neural Accelerators. That's a 5–9x advantage on prefill.
In practice: If you're using RAG pipelines (embedding documents + generating summaries), M5 Max saves you hours per day. If you're fine-tuning on long sequences, same story. The M5 Max is genuinely special here.
For streaming chat? Prefill speed doesn't matter. You type 50 tokens. That takes <100ms on both systems. Then you wait for decode. And that's where RTX 5090 wins.
Decode Performance: RTX 5090's Strength
Decode is where RTX 5090 earns its $1,999 price tag.
On Llama 3.1 70B at Q4 quantization (the real-world standard for power users), the RTX 5090 maintains approximately 27–30 tok/s. Not "measured in my specific setup"—this is consistent across independent benchmarks from Level1Techs, Tom's Hardware, and the community.
The M5 Max on the same 70B model is estimated at ~18–20 tok/s for decode. That's a meaningful difference when you're waiting for responses. On a 200-token generation, you're waiting 6.6 seconds on M5 Max vs. 6.7 seconds on RTX 5090. That's basically tied. But on a 1,000-token output, M5 Max takes 50+ seconds; RTX 5090 takes 33 seconds. That's 17 seconds of wall-clock time you're waiting for a response.
On Llama 3.1 120B (where the M5 Max's 120GB unified memory shines), the comparison gets cloudier. The M5 Max can load 120B unquantized or at very light Q2 quantization. The RTX 5090 simply cannot fit 120B in 32GB at any usable quantization. You'd need dual RTX 5090s or step down to a smaller model.
This is the real-world pain point: RTX 5090 is faster at generating text, but it's constrained by 32GB VRAM. M5 Max can run much larger models, but runs them slower.
Warning
The RTX 5090 cannot run Llama 3.1 70B at Q4 quantization on its own. The model is ~40GB at Q4. You need either: dual GPUs, Q2/Q3 quantization (lower quality), or a smaller model like Qwen 2 32B (which runs at 50+ tok/s on a single 5090). This is the #1 surprise when buyers first test an RTX 5090 for local LLMs.
Real-World Workload Performance
Let's map this to actual use cases.
Streaming Chat (ChatGPT-like UI)
RTX 5090 wins decisively here.
- Time-to-first-token (how long before you see the first output): both are <1 second. Tie.
- Sustained generation (tokens flowing after that): RTX 5090 at 27 tok/s, M5 Max at 18 tok/s.
- 200-token response: 7.4 seconds (RTX) vs. 11 seconds (M5 Max). Real difference.
For a daily-use chat interface, this 3–4 second gap adds up. By the end of a 2-hour session, you've saved 5–10 minutes of waiting.
RTX 5090 wins for streaming chat.
RAG / Document Processing
M5 Max wins decisively here.
Imagine processing 100 technical documents (average 4,000 tokens each) to extract key facts. Your pipeline: embed each doc, generate a summary for each.
- M5 Max prefill: 100 docs × 4,000 tokens = 400,000 total prefill operations at 4,400 tok/s = ~91 seconds.
- RTX 5090 prefill: Same 400,000 tokens at 600 tok/s (accounting for cache effects on large documents) = ~667 seconds.
M5 Max processes your documents 7x faster. This compounds when you're running batch jobs multiple times a day.
RTX 5090 actually decodes the summaries faster (18–20 tok/s on 100B model outputs), but that's negligible—the bottleneck is prefill.
M5 Max wins for batch document processing.
Fine-tuning
Tie, with asterisks.
The RTX 5090 has a 15-year-old ecosystem. LoRA, DDP (distributed data parallel), mixed precision—all mature and battle-tested. Training Llama 3.1 70B with LoRA on dual RTX 5090s is straightforward.
The M5 Max using MLX is newer (2025) but growing fast. You can fine-tune 70B models on M5 Max, but you're in a smaller community. Less Stack Overflow when things break.
For most power users, RTX 5090 ecosystem is safer. For Mac devotees, M5 Max is fine.
Silent Office Deployment
M5 Max dominates.
RTX 5090 = 575W at the wall. Add a power supply (15% loss), add the CPU and motherboard pulling 80–120W, and you're running 700+ watts under load. That's a 3-fan GPU cooler at full blast—50+ dB acoustic noise.
Mac Studio M5 Max = 120W system-wide, passively cooled. Silent. Dead silent.
If you're running a local AI service in an office where noise matters, M5 Max is the only choice.
Cost of Ownership: Three-Year Horizon
Here's where the M5 Max's $4,000+ sticker price starts to sting when you add up total cost.
Equipment Cost
- RTX 5090 build: $1,999 (GPU) + $600 (Ryzen 9 9950X CPU + motherboard) + $400 (PSU) + $200 (cooling) = $3,199 all-in
- Mac Studio M5 Max: $3,999+ base (no upgrades needed for local LLM use; 36GB base unified memory is enough for most models)
RTX 5090 is $800 cheaper to get going. M5 Max is more expensive but includes a complete system (display support, ports, build quality).
Electricity Cost (3 Years @ 8 hrs/day)
- M5 Max: 120W × 8 hrs/day × 365 days/year × 3 years × $0.12/kWh = $1,051
- RTX 5090 build: 700W × 8 hrs/day × 365 days/year × 3 years × $0.12/kWh = $7,300
M5 Max costs $6,250 less to operate over three years.
Total 3-Year Cost
- RTX 5090: $3,199 (build) + $7,300 (electricity) = $10,499
- Mac Studio M5 Max: $3,999 (hardware) + $1,051 (electricity) = $5,050
M5 Max is half the cost over three years. That's a $5,450 swing.
Tip
The M5 Max wins on total cost of ownership because electricity dominates a 3-year horizon. The RTX 5090 is cheaper upfront but burns $6,000+ more in power. If you run inference 16 hours/day instead of 8, that gap closes to $3,000. If you upgrade your GPU in 18 months, RTX 5090 becomes the better deal.
The Ecosystem Question
NVIDIA has 15 years of installed tooling. vLLM, Ollama, llama.cpp, PyTorch, Hugging Face Transformers—all optimize for CUDA first. If something breaks, Stack Overflow has 50 answers.
Apple Silicon MLX is newer (2023) but growing. It's now considered "production-ready" as of 2025. Ollama supports M-series GPUs. llama.cpp has excellent MLX support. Hugging Face just released optimized MLX kernels for LLMs.
The gap is closing. If you're building in 2026, M5 Max ecosystem is solid. But if you hit an edge case (custom model architecture, new quantization method), NVIDIA's community is larger.
Practical takeaway: NVIDIA for maximum flexibility and documentation. Apple Silicon for a more integrated, curated experience.
Should You Buy Now or Wait?
Buy RTX 5090 Now If:
- You need streaming inference speed today (not June)
- You run chat applications with low-latency requirements
- You prefer Linux/Windows flexibility over macOS
- You're comfortable with higher power consumption and noise
- Your use case fits in 32GB VRAM (or you're running smaller models like 34B)
Wait for M5 Max (June 2026) If:
- You're ecosystem-locked to Apple (already own a Mac)
- Silence is non-negotiable for your deployment
- You're doing heavy batch processing (RAG, document pipelines)
- You want the lowest 3-year total cost of ownership
- You can delay projects by 2 months to save $5,000+
The Wildcard: M5 Ultra
Apple is rumored to announce an M5 Ultra in late 2026 with 160GB unified memory. If true, M5 Ultra becomes the undisputed champion for anything involving 120B+ models or prefill-heavy workloads. However, it will likely cost $6,000+, and you're still waiting another 8 months.
The Verdict
The RTX 5090 is the practical winner for streaming inference right now. It's faster at generating tokens, cheaper upfront, and the CUDA ecosystem is rock-solid.
The M5 Max will be the smarter all-rounder when it ships in June—faster at prefill, cheaper to run, silent, and Apple's ecosystem continues maturing. But you're paying a $4,000 entry fee and locking yourself into macOS.
For power users in 2026: RTX 5090 if you need speed today. M5 Max if you can wait 8 weeks and want lower operating costs. Both are overqualified for running 70B models. Neither is "wrong."
FAQ
Is the M5 Max going to be available immediately when Apple announces it?
Historically, Apple announces products 4–6 weeks before shipping. WWDC is typically in June, so expect Mac Studio M5 Max deliveries in July or August 2026. Stock will be limited.
Can I run Mixtral 8x22B on a single RTX 5090?
Technically yes, but you need to quantize aggressively (Q2 or Q1), which hurts quality. At useful quality (Q4), 8x22B is ~39GB unquantized, exceeding the 32GB limit. You'd need dual RTX 5090s or step down to a smaller MoE model like Mixtral 8x7B (fits comfortably at Q4).
Why is memory bandwidth important if the M5 Max has less of it than RTX 5090?
Memory bandwidth (GB/s) matters more for decode than prefill. RTX 5090's 960 GB/s handles decoding faster because each token-generation step needs to fetch and recompute activations. M5 Max's 614 GB/s is plenty for its architecture, but RTX 5090 simply pushes more data per clock cycle. For prefill, both have enough bandwidth—the bottleneck is compute.
What happens if Apple releases M5 Ultra at the same time as Mac Studio M5 Max?
M5 Ultra is expected later in 2026, not at June WWDC. If it appears at the same time, M5 Ultra becomes the new benchmark and makes M5 Max less compelling. But that's speculation.
How much does a GPU upgrade cost if my RTX 5090 ages out?
NVIDIA GPU prices drop ~30% after 18 months. An RTX 5090 will likely cost $1,200–$1,400 used by late 2027. A new next-gen flagship might cost $2,500. For M5 Max, you can't upgrade the GPU—you replace the entire Mac Studio.