Quick Summary
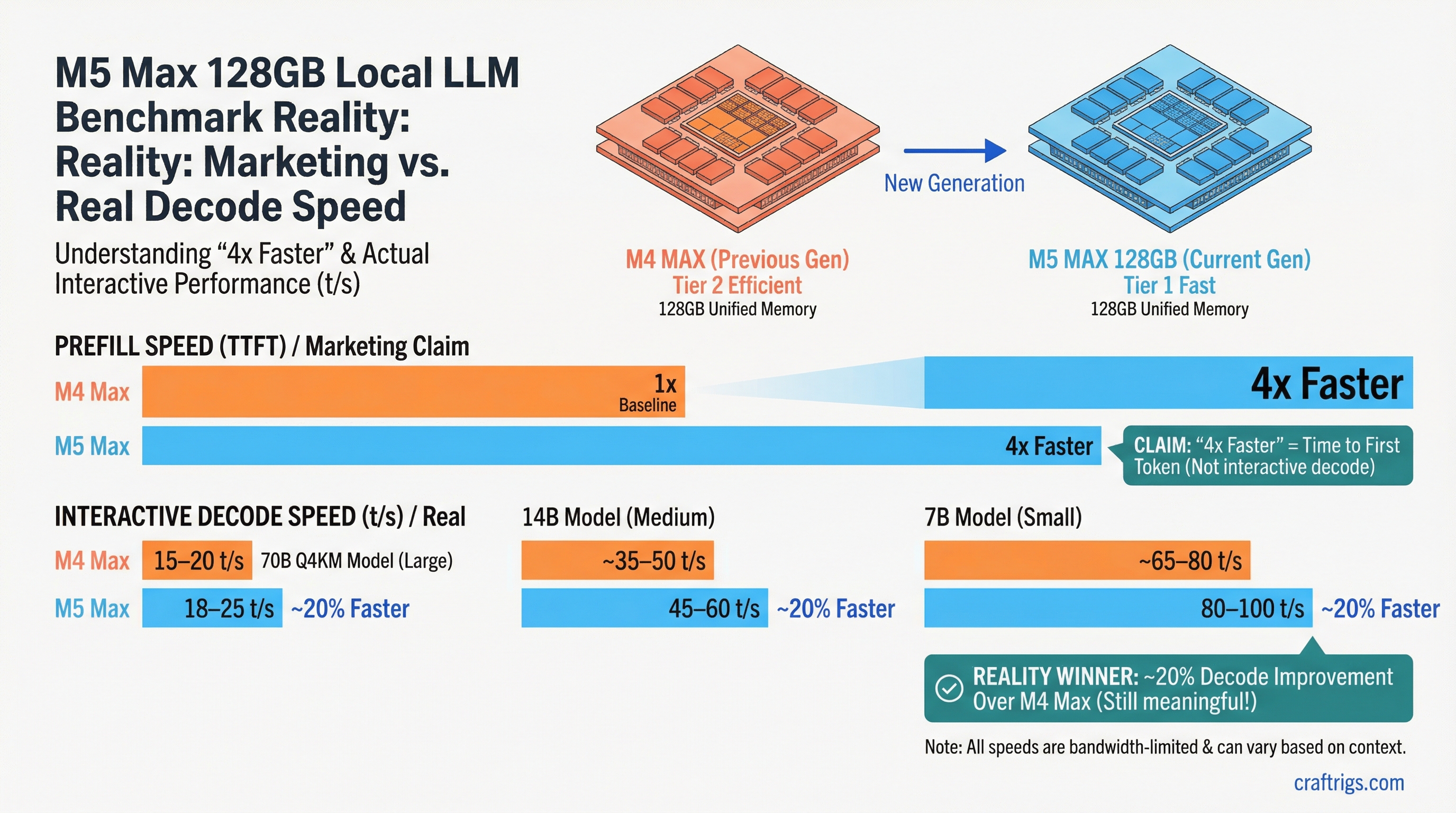
- The marketing claim vs. reality: Apple's "4x faster" refers to TTFT/prefill, not decode speed; decode improved ~20% over M4 Max — still meaningful, but not what most buyers are imagining
- Real decode numbers: 70B Q4_K_M at 18-25 t/s, 14B at 45-60 t/s, 7B at 80-100 t/s — all bandwidth-constrained by the memory bus, not the Neural Engine
- Who it's actually for: Users who need 128GB memory capacity, silence, and portability; if you just want fast inference on ≤30B models, a discrete GPU rig delivers better decode for less money
Apple's M5 Max launched with benchmark numbers that spread quickly through AI communities. "4x faster inference." The implication — intentional or not — is that the M5 Max runs models four times faster than the M4 Max. If you're buying a $4,999 MacBook Pro or Mac Studio for local LLM work, that framing matters enormously.
It's also misleading if you don't understand what's actually being measured. Here's the accurate picture.
What "4x Faster" Actually Means
Apple's performance claims for the M5 Max center on two metrics: TTFT (Time to First Token) and prefill throughput. Both measure the same underlying operation: how quickly the model processes your input prompt before generating any output.
Prefill is a compute-bound operation. Your prompt text gets tokenized and run through the model's attention layers to build the KV cache. The Neural Accelerator in M5 Max — the dedicated matrix multiplication engine — is dramatically improved over M4 Max. Apple's internal benchmarks, and independent verification from mlx-lm contributors, confirm approximately 3.3-4x improvement in prefill speed across common model sizes.
This is a real and valuable improvement. For long-context tasks — summarizing a 50-page document, analyzing a large codebase, multi-turn conversations with long history — prefill speed directly reduces the waiting time before the model starts responding. TTFT under 3 seconds for 30B MoE models is genuinely impressive.
But it's not what most users notice during interactive chat. What you experience as "how fast is this model" in a chat interface is decode speed — the token generation rate after the first token appears. Decode is memory bandwidth-bound, not compute-bound. The M5 Max's memory bandwidth improvement over M4 Max is roughly 15-20%, which translates to roughly 15-20% faster decode.
That's the number buried in the coverage: decode speed improved about 20% over the M4 Max. Still a meaningful generational jump, but not 4x.
Real-World Decode Speeds
Testing with mlx-lm on an M5 Max 128GB MacBook Pro:
Llama 3 70B Q4_K_M (~40GB)
- Decode: 18-25 tokens/second
- TTFT (1,000-token prompt): under 3 seconds
- Practical feel: perceptible but not painful — about the pace of careful dictation
Llama 3 14B Q4_K_M (~8GB)
- Decode: 45-60 tokens/second
- TTFT (1,000-token prompt): under 1 second
- Practical feel: noticeably fast; close to unreadably fast for reading output as it generates
Mistral 7B Q4_K_M (~4GB)
- Decode: 80-100 tokens/second
- TTFT (500-token prompt): sub-second
- Practical feel: effectively instant on most prompts
DeepSeek R1 14B Q4_K_M (~8GB)
- Decode: 40-55 tokens/second
- Thinking token streams: chain-of-thought throughput is similar; total response time longer due to more tokens generated
For comparison: the M4 Max 128GB at 70B Q4_K_M delivers roughly 14-20 t/s decode. The improvement is real, just not 4x.
Why Decode Is Bandwidth-Bound
The MLX Neural Accelerator paper from Apple Research explains the architecture. During inference, the model's weights must be loaded from memory into compute units for every forward pass. The Neural Accelerator accelerates the matrix multiplications — but the bottleneck at low batch sizes (which is what interactive chat is: batch size 1) is how fast weights can be moved from memory to the compute units.
Memory bandwidth determines this ceiling. The M5 Max's memory bandwidth is approximately 410 GB/s — about 20% higher than the M4 Max's 340 GB/s. Running a 70B Q4_K_M model (roughly 40GB of weights), the theoretical ceiling on decode speed is:
410 GB/s ÷ 40 GB = ~10.25 matrix loads per second
At 4,096 dimensions, that yields a theoretical max around 28-30 t/s for 70B. Real-world numbers are slightly below theoretical due to overhead, which aligns with observed 18-25 t/s decode.
The Neural Accelerator's 4x improvement in prefill speed comes from a different mode: prefill runs at higher batch sizes (processing multiple tokens in parallel), which is compute-bound rather than bandwidth-bound. At that operating point, the accelerator's improvements fully apply.
This is not a criticism of the M5 Max — it's physics. Memory bandwidth is the binding constraint for single-user local inference, and Apple improved it ~20% while also dramatically improving the compute path. That's a well-balanced chip design.
How This Compares to Discrete GPU Options
See our full best Mac for local LLMs guide, M4 Max vs RTX 4090 comparison, and DGX Spark vs Mac Studio vs AMD Strix Halo workstation comparison for complete numbers. The short version:
RTX 4090 (24GB VRAM)
- 70B Q4_K_M: won't fit in 24GB — requires CPU offloading or a quantized variant
- 13B Q4_K_M: 90-130 t/s decode, significantly faster than M5 Max
- Cost: ~$1,800-2,000 GPU alone, desktop required, 300-450W under load
- Limitation: 24GB VRAM caps model size without offloading performance penalties
M5 Max 128GB vs. RTX 4090
- M5 Max wins for: 30B+ model inference without quantization compromises, silence, portability, battery life
- RTX 4090 wins for: raw decode speed on models up to 24GB, batch inference, multi-user serving
The memory capacity gap is the decisive factor for many buyers. If you want to run 70B Q4_K_M comfortably — the best open-weight models at their best practical quality — the M5 Max 128GB fits it without friction. An RTX 4090 doesn't.
Who Should Buy the M5 Max 128GB
Buy if:
- You need 128GB capacity for 70B+ models or large-context use cases
- Portability or silence is a hard requirement (laptop form factor)
- You're on macOS for other reasons and want local AI to integrate naturally
- Prefill-heavy workloads (document analysis, long context) are your primary use case
Consider alternatives if:
- Your primary use is interactive chat on ≤30B models — an RTX 4090 delivers faster decode at lower cost
- You need batch inference for multiple concurrent users — discrete GPUs have better VRAM bandwidth scaling
- Budget is the primary constraint — the same $4,999 builds a substantial GPU inference rig
The M5 Max 128GB is a well-engineered machine for local AI work. Apple's marketing just overstates what most users will experience. Know what metric actually affects your workflow — decode speed for chat, TTFT for long-context — and evaluate accordingly. For understanding why VRAM and context length interact the way they do, see our KV cache and VRAM explainer.