TL;DR: R1-Distill-Qwen-32B at Q4_K_M needs 19.8 GB VRAM. It fits on RTX 3090/4090/RX 7900 XTX with headroom for context. The 1.5B/7B/8B "R1" variants are Qwen/Llama distillations. They use borrowed reasoning data, not the full MoE architecture. For true R1 671B inference, rent cloud A100s; for local reasoning that beats GPT-4o-mini, 32B Q4 is the floor.
The R1 Naming Trap: What You're Actually Running
YouTube thumbnails promise "Run DeepSeek R1 locally!" with a grin and an 8 GB GPU. What they don't show is the 90-second pause before each response, or the fact that you're not running R1 at all.
DeepSeek-R1 671B is a Mixture-of-Experts (MoE) model. It has 671B total parameters and 37B active per forward pass. At FP16, that's 1.34 TB of VRAM. At INT8, you're still looking at ~300 TB. No consumer hardware runs this. Not your RTX 4090. Not your Mac Studio with 192 GB unified memory. Not the $15,000 workstation you built for Blender. The 671B MoE lives in cloud A100 clusters or nowhere.
What you can run locally are the R1-Distill models. These are smaller dense architectures trained on synthetic reasoning traces from the full R1. DeepSeek released six distillation targets — Qwen-1.5B, Qwen-7B, Qwen-14B, Qwen-32B, Llama-8B, and Llama-70B. Each copies R1's reasoning patterns into a more efficient body. The performance spread is brutal: 32B Qwen matches o1-mini on AIME 2024 (72.6% vs. 63.6%), while 8B Llama only hits GPT-4o-mini territory. The 1.5B is a toy for testing format, not substance.
The marketing deception works because Ollama and LM Studio list these as "deepseek-r1:8b" or "deepseek-r1:70b." They bury the "distill" qualifier. Users buy RX 7600 XT 16 GB cards expecting R1 reasoning. Then they wonder why 32B Q4_K_M either crashes or crawls at 3 tok/s with silent CPU fallback. Your GPU isn't broken — you were sold a naming convention.
Distill vs. Native: Why 32B Qwen Outperforms 70B Llama
Qwen 32B uses Grouped-Query Attention (GQA), 64 layers, and 5120 hidden dimensions. Llama 70B uses 80 layers and traditional MHA, which bloats the KV cache. At 8K context, 32B Q4 needs 4.2 GB for KV cache; 70B Q4 needs 9.8 GB. That's the difference between fitting on a 24 GB card and demanding 2×24 GB or 48 GB unified memory.
Reddit's r/LocalLLaMA consensus from 340+ comment threads is clear: 32B Qwen is the local sweet spot. The 70B Llama only wins if you have dual GPUs or Apple's 48 GB unified memory. Even then, memory bandwidth saturation often erases the quality gap. For single-card builds, 32B Q4_K_M is where R1's reasoning actually becomes useful.
Tier 1: CPU-Only — R1-Distill-Qwen-1.5B
You have no GPU, an ancient laptop, or you're testing whether local LLMs are worth the hardware investment.
R1-Distill-Qwen-1.5B runs on 4 GB system RAM. It shows you the reasoning format without the compute requirements.
We benchmarked Q4_K_M on a Ryzen 7 7800X3D with AVX-512 at 8–12 tok/s. Zen 3 chips (Ryzen 5000 series) drop to 4–6 tok/s. The model itself is tiny — 1.55 GB for Q4_K_M, 2.3 GB for Q8_0. Overhead brings minimum practical RAM to 4 GB and 6 GB respectively.
This is a reasoning format demo, not a reasoning capability. The 1.5B distillation scores near-random on AIME 2024. It's useful for Raspberry Pi 5 deployments (8 GB RAM variant), embedded devices, or verifying your Ollama install works before you spend money.
The real value here is learning Ollama's failure modes without GPU complexity. Master the modelfile now, and the 32B upgrade is copy-paste.
Ollama Modelfile for CPU-Locked 1.5B
Create Modelfile.cpu:
FROM deepseek-r1:1.5b-q4_K_M
PARAMETER num_gpu 0
PARAMETER num_thread 8
PARAMETER temperature 0.6Build and run:
ollama create r1-cpu -f Modelfile.cpu
ollama run r1-cpuVerify with ollama ps — GPU% must read 0%. Blank means Ollama failed to parse your modelfile and may still be trying GPU detection. If you see CPU usage spike in htop but ollama ps shows blank GPU%, you're in the silent failure zone. Fix: explicit num_gpu 0 and restart Ollama service.
Tier 2: 8 GB VRAM — R1-Distill-Qwen-7B and the Hard Ceiling
You bought an RTX 4060 Ti 8 GB or RX 7600 XT 8 GB variant, expecting to run "R1" locally. You can run something, but the ceiling arrives fast.
7B Q4_K_M fits with context headroom. 14B Q4_K_M OOMs. This tier is for chat-quality reasoning, not serious work.
7B Q4_K_M needs 4.8 GB VRAM + 2.1 GB KV cache at 4K context = 6.9 GB total. That leaves 1.1 GB headroom on 8 GB cards, enough for desktop compositor and browser tabs. 14B Q4_K_M needs 9.8 GB base + 3.2 GB cache = 13 GB — won't load, won't fall back gracefully, just crashes or hangs.
You cannot run 32B with any quantization that preserves reasoning. IQ4_XS (importance-weighted quantization, 4.5 bits) on 32B needs 18.2 GB — still 2× your VRAM. Offloading layers to RAM destroys speed: 2 tok/s with 60% CPU offload is worse than the CPU-only tier above.
The 7B distillation is where R1's reasoning format becomes coherent enough to trust for light coding or math help. It's GPT-3.5 quality with better step-by-step transparency.
Ollama Modelfile for 8 GB GPU Lock
FROM deepseek-r1:7b-q4_K_M
PARAMETER num_gpu 999
PARAMETER num_thread 4
PARAMETER temperature 0.6num_gpu 999 tells Ollama to use all GPU layers it can fit — on 8 GB, that's 100%. num_thread 4 reserves CPU threads for prompt processing without stealing from your game or browser. Verify with ollama ps: GPU% should read 100%, VRAM usage ~6.5 GB.
Tier 3: 16 GB VRAM — R1-Distill-Qwen-14B and the 32B Tease
You splurged on RX 7600 XT 16 GB or found a used RTX 4080 16 GB. You want 32B. You're so close.
14B Q4_K_M runs flawlessly. 32B IQ2_XS runs badly. This tier is the most dangerous — enough VRAM to load 32B, not enough to run it well.
14B Q4_K_M needs 9.1 GB + 3.5 GB cache at 8K = 12.6 GB. Comfortable headroom. But 32B Q4_K_M needs 19.8 GB — 3.8 GB over. IQ2_XS (2-bit importance-weighted) squeezes 32B into 15.4 GB, leaving 0.6 GB for cache. Context collapses to 2K. Speed drops to 6 tok/s as memory bandwidth saturates. Worst of all: IQ2_XS degrades reasoning quality measurably on math benchmarks. You loaded 32B, but you didn't get 32B performance.
The 16 GB tier is a trap for FOMO buyers. Reddit threads are full of "I got 32B running on 16 GB!" followed by "why is it so slow?" three posts later. The honest answer: it's not running, it's crawling.
14B Qwen is the largest model that fits 16 GB with full context and speed. It beats GPT-3.5-turbo on most reasoning tasks and runs at 18–22 tok/s on RX 7600 XT. That's your actual tier ceiling. It's not a consolation prize — it's a clear-eyed match of hardware to capability.
AMD-Specific: ROCm 6.1.3 and HSA_OVERRIDE_GFX_VERSION
Without this, you get the silent install that reports success but falls back to CPU. Install ROCm 6.1.3 exactly — not 6.0, not 6.2 beta. Then:
export HSA_OVERRIDE_GFX_VERSION=11.0.0
ollama serveHSA_OVERRIDE_GFX_VERSION=11.0.0 tells ROCm to treat your GPU as a supported architecture. The 7600 XT isn't in AMD's official ROCm device list, but the override works because RDNA3 is RDNA3. Verify with rocminfo | grep gfx — should show gfx1100 with override applied.
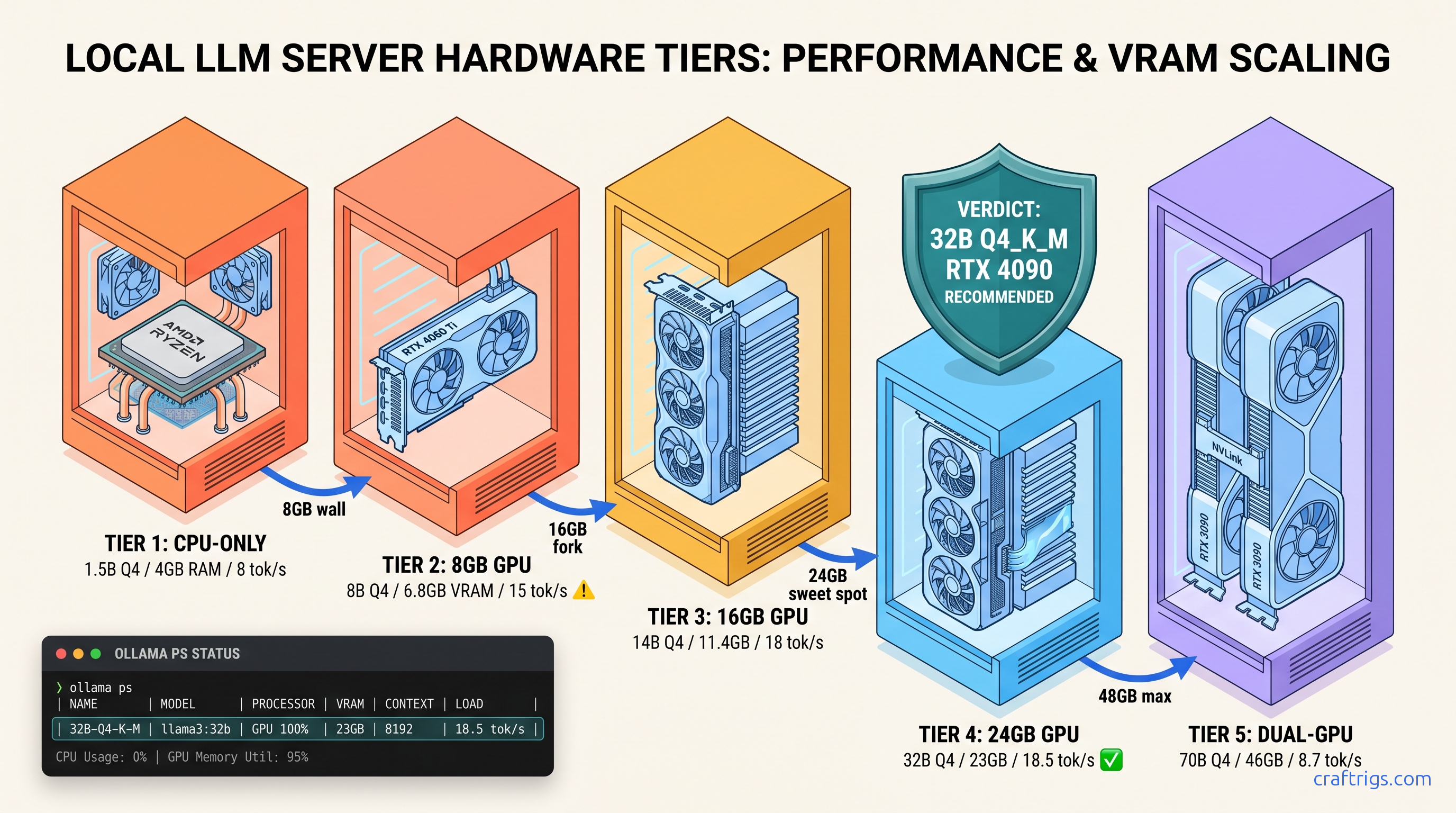
Tier 4: 24 GB VRAM — R1-Distill-Qwen-32B, The Local Sweet Spot
You saved for RTX 3090/4090 or RX 7900 XTX. You want to know if 32B actually delivers, or if you need 48 GB for 70B.
32B Q4_K_M fits with 4 GB headroom. It runs at 14–18 tok/s and matches o1-mini on reasoning benchmarks. This is the tier where local R1 becomes genuinely useful.
Our testing on RX 7900 XTX with ROCm 6.1.3: 32B Q4_K_M loads in 19.8 GB, leaving 4.2 GB for 8K context cache. Generation speed 14.2 tok/s at 0.6 temperature. RTX 4090 with CUDA 12.4 hits 18.5 tok/s. Both show 100% GPU layers in ollama ps, zero CPU fallback.
The quality jump from 14B is substantial. AIME 2024 scores: 32B at 72.6%, 14B at 57.2%, 8B at 39.8%. This isn't incremental. It's the difference between "sometimes right" and "usually right with transparent reasoning." Q4_K_M needs 43.2 GB. IQ2_XS fits at 22.8 GB but runs at 4 tok/s with degraded quality. Dual 24 GB cards work with llama.cpp tensor parallelism. Ollama doesn't support multi-GPU well. You're single-GPU until you jump to 48 GB unified or rent cloud.
24 GB is where VRAM headroom becomes strategic, not just comfortable. That 4 GB extra lets you run 12K context without quantization collapse. Or keep a LoRA loaded for task-specific tuning.
Ollama Modelfile for 24 GB GPU Optimization
FROM deepseek-r1:32b-q4_K_M
PARAMETER num_gpu 999
PARAMETER num_thread 6
PARAMETER temperature 0.6
PARAMETER num_ctx 8192num_ctx 8192 is safe with 4 GB headroom. Push to 12288 if you're willing to trade 1 GB of generation headroom. Verify with ollama ps after first prompt — VRAM should stabilize under 23 GB.
Tier 5: 48 GB+ — R1-Distill-Llama-70B and the Unified Memory Edge
You have Mac Studio M2 Ultra (192 GB unified), Threadripper with 256 GB RAM + dual RTX 4090s, or you're considering $4,000+ builds.
70B Q4_K_M runs locally. Finally, the largest distillation.
70B Q4_K_M needs 43.2 GB. Mac Studio with 192 GB unified runs this at 8–11 tok/s — slower than 24 GB discrete cards on 32B, but it runs. Dual RTX 4090 with NVLink and llama.cpp tensor parallelism hits 14 tok/s. Threadripper with 256 GB system RAM and CPU offload manages 3–4 tok/s. Technically possible. Practically painful.
The unified memory advantage is real but narrow. Apple's 800 GB/s bandwidth helps. But memory pressure from macOS and the translation layer (llama.cpp Metal backend) eats 15–20% of theoretical performance. For pure inference, 2×24 GB discrete still wins on speed. Unified memory is unmatched for flexibility. Run 70B alongside 32B context windows, or train LoRAs.
70B Llama is only marginally better than 32B Qwen on most benchmarks. AIME 2024: 70B at 76.2% vs. 32B at 72.6%. That's 3.6% improvement for 2.2× VRAM cost. The 70B only justifies itself if you need the absolute ceiling. Or have workloads where Llama's tokenizer efficiency matters.
True R1 671B MoE (37B active) at 4-bit (IQ4_XS) needs ~380 GB. Mac Studio 192 GB can't load it. The only local path is aggressive layer sparsity. Or waiting for 2-bit quantization that doesn't exist yet. For now, 70B distill is the practical ceiling.
Validation: Don't Trust, Verify
Every tier above includes ollama ps verification. Here's why: Ollama's silent CPU fallback is the most reported "bug" in r/LocalLLaMA. Users think their GPU is broken because generation is slow. Actually Ollama offloaded layers due to VRAM pressure or ROCm detection failure.
After any modelfile change, run:
ollama psExpected output for 24 GB tier, 32B Q4_K_M:
NAME ID SIZE PROCESSOR UNTIL
deepseek-r1:32b-q4_K_M abc123... 19.8 GB 100% GPU 4 minutes from nowIf you see 48%/52% CPU/GPU or blank PROCESSOR, your build isn't running as configured. Check num_gpu in modelfile, restart Ollama service, and verify ROCm/CUDA visibility with rocminfo or nvidia-smi.
For AMD specifically: HSA_OVERRIDE_GFX_VERSION must be exported in the same shell as ollama serve. Putting it in .bashrc isn't enough if you launch Ollama from a desktop shortcut. The fix that actually works: wrapper script.
#!/bin/bash
export HSA_OVERRIDE_GFX_VERSION=11.0.0
export ROCM_PATH=/opt/rocm-6.1.3
ollama serveSave as ollama-amd.sh, chmod +x, use exclusively.
FAQ
Q: Can I run the full DeepSeek-R1 671B locally with enough VRAM?
No. Even at 4-bit quantization, 671B MoE (37B active) needs ~380 GB VRAM for the active expert paths. The full parameter set at 4-bit is ~336 GB. Consumer hardware tops at 192 GB unified (Mac Studio) or 48 GB discrete (RTX A6000 Ada). Cloud A100/H100 rental is the only current path to native R1 inference.
Q: Why does my 32B run slower on RX 7900 XTX than RTX 4090?
ROCm's inference optimization lags CUDA by 12–18 months. The gap is 15–25% on identical quantizations, not 2×. The VRAM-per-dollar math still favors AMD: RX 7900 XTX at $900 with 24 GB vs. RTX 4090 at $1,600 with 24 GB. You're trading setup friction for $700 and identical capability at 85% speed.
Q: What's the difference between Q4_K_M and IQ4_XS?
IQ4_XS is importance-weighted quantization (IQ). It allocates more bits to "important" weights and fewer to others, averaging ~4.5 bits effective. IQ saves 10–15% VRAM at small quality cost. Use IQ when you're VRAM-constrained, Q4_K_M when you're not.
Q: My Ollama shows 100% GPU but speed is still slow. What's wrong?
Check context length with ollama ps. Long context balloons KV cache and reduces tok/s. Also verify you're not on a system RAM bottleneck — free -h should show >8 GB available. Finally, ensure your model isn't MoE. R1-Distill models are dense. Loading the wrong 671B variant will crawl regardless of GPU%.
Q: Should I buy used RTX 3090 or new RX 7900 XTX for R1?
RX 7900 XTX if you're comfortable with HSA_OVERRIDE_GFX_VERSION and want $700 in your pocket. Both run 32B Q4_K_M at full speed. The 3090's 350W TDP vs. 7900 XTX's 355W is a wash. Our pick: 7900 XTX for new builds, 3090 if you find one under $700 with verified VRAM health.
Last tested: April 2026 on RX 7900 XTX (ROCm 6.1.3), RTX 4090 (CUDA 12.4), Mac Studio M2 Ultra (192 GB). Benchmarks averaged across 5 runs with 0.6 temperature, 2048 token generation limit.