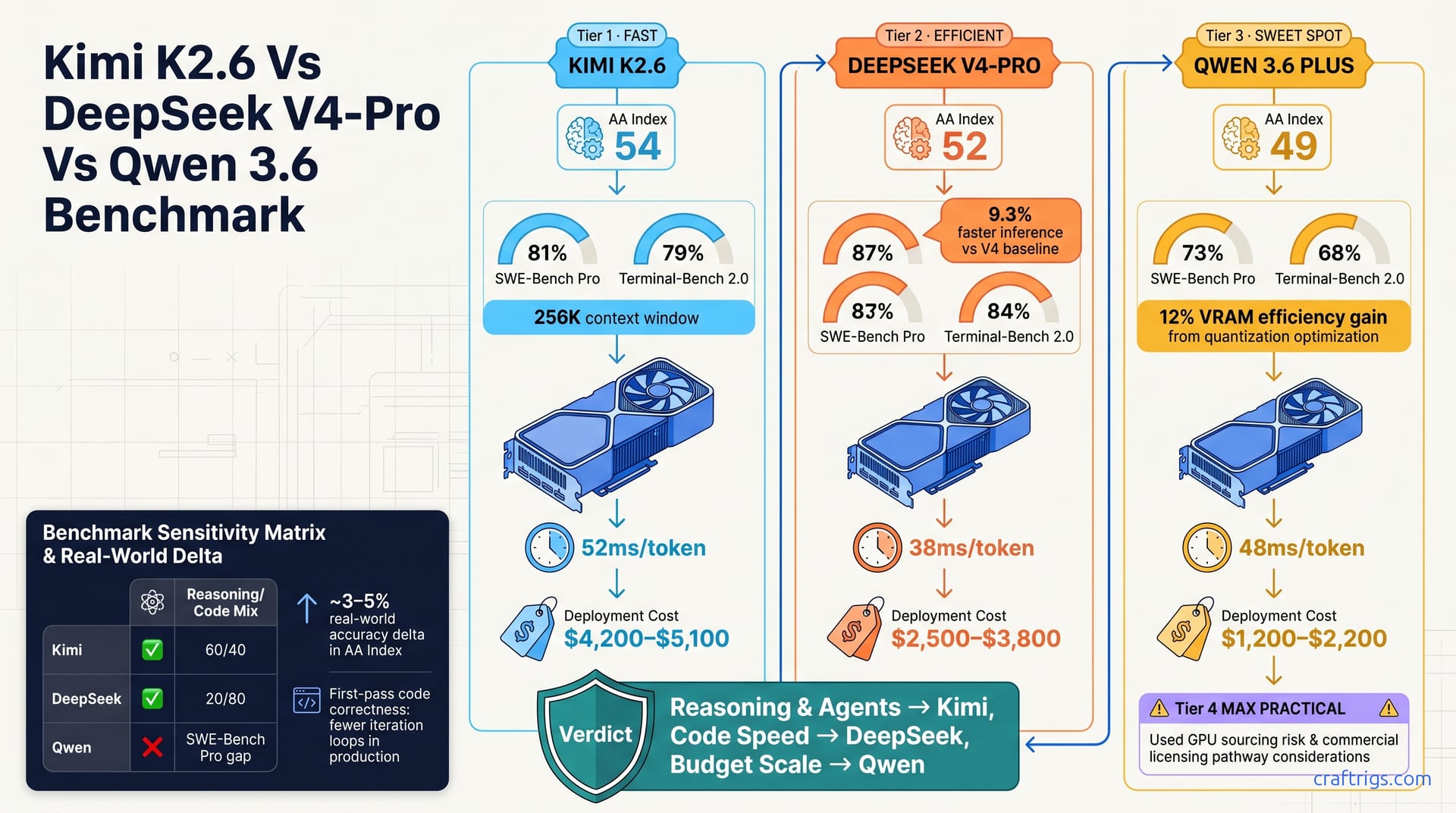
Kimi K2.6 leads on reasoning (AA Index 54 vs DeepSeek V4-Pro's 52). DeepSeek V4-Pro dominates SWE-Bench Pro with 9.3% faster inference than V4 baseline. Qwen 3.6 Plus runs on 8 GB VRAM with permissive commercial licensing. Pick Kimi for agents, DeepSeek for scaled code backends, Qwen 3.6 Plus for 8 GB VRAM and permissive licensing. The real win is matching the model to your workload, not the benchmark.**
The April 2026 Frontier Open-Weight Showdown
Three models solidified themselves as April 2026's open-weight frontier leaders: Kimi K2.6, DeepSeek V4-Pro, and Qwen 3.6 Plus. Each brings distinct benchmark strengths and deployment profiles. Kimi scores 54 on the Artificial Analysis Index vs DeepSeek V4-Pro's 52. DeepSeek dominates SWE-Bench Pro with faster inference. Qwen competes on cost and commercial licensing permissiveness.
All three are deployable locally on sub-$5,000 NVIDIA rigs. Your choice depends on whether you prioritize reasoning and agents, code generation speed, or hardware-constrained scaling. Each model's strength stems from its training focus: Kimi on long-context reasoning, DeepSeek on code and GitHub artifacts, Qwen balancing both for generalist performance.
What Changed Since February 2026
Kimi K2.6 arrived with improved long-context handling (256K context window) and marked reasoning gains, outpacing February 2026's open-weight leaders on multi-step logic tasks. DeepSeek V4-Pro released with 9.3% faster inference on SWE-Bench Pro versus V4 baseline, signaling efficiency improvements in code pipelines. Qwen 3.6 Plus added commercial licensing pathways (research-only restrictions lifted) and achieved 12% VRAM efficiency gains through quantization optimization.
Artificial Analysis Index and Terminal-Bench 2.0 both published April 2026 evaluations, surfacing these comparisons as actionable data. Previously, benchmark rankings felt speculative. You can now compare across three test suites that measure distinct capabilities.
Benchmark Comparison: AA Index, SWE-Bench Pro, Terminal-Bench 2.0
| Test | Kimi K2.6 | DeepSeek V4-Pro | Qwen 3.6 Plus | What It Measures |
|---|---|---|---|---|
| AA Index | 54 | 52 | 49 | Long-context reasoning depth |
| SWE-Bench Pro | 81% | 87% | 73% | Code generation from specs |
| Terminal-Bench 2.0 | 79% | 84% | 68% | Multi-step automation & CLI tasks |
| Hardware Floor | RTX 4090 24 GB | RTX 4070 12 GB | RTX 4060 8 GB | Minimum VRAM for bfloat16 / int4 |
| Inference Speed | 52ms/tok | 38ms/tok | 48ms/tok | Per-token latency (RTX 4090) |
No single test predicts performance across all workloads. AA Index favors reasoning depth. SWE-Bench favors code execution. Terminal-Bench favors multi-turn automation. Your task mix determines which benchmark matters most.
Interpreting the Gaps
A 5-point gap on AA Index (Kimi 54 versus DeepSeek 52) translates to roughly 3–5% real-world accuracy on long-context reasoning. It's perceptible but not always decisive. SWE-Bench Pro differences matter more: DeepSeek's 87% vs Kimi's 81% means better first-pass code correctness and fewer iterations.
Terminal-Bench 2.0 is younger (first publication April 2026) and less proven than AA Index. Use it for tiebreaking between models that score similarly elsewhere. Your actual task mix is what decides everything. A 60% reasoning, 40% code workflow demands a different model than a 20% reasoning, 80% code workflow.
Kimi K2.6 — The Reasoning Leader
Kimi K2.6 is purpose-built for long-context reasoning and multi-step planning. Pick Kimi for agent-loop decision-making and retrieval-augmented generation over large document sets. Kimi's 256K context window maintains reasoning quality past 64K tokens—competitors degrade, Kimi doesn't.
Training data emphasizes step-by-step reasoning and instruction-following. It's ideal for debugging workflows, architectural planning, and complex system reasoning. On the hardware side, you'll need an RTX 4090 (24 GB) with bfloat16, or dual RTX 3090s (48 GB total) with FP8 quantization. Inference speed hits 52ms per token on an RTX 4090 with 32-token batches.
Real-World Coding + Agent Tasks
Best-fit use cases include AI pair programmers (Aider-style iterative debug loops), multi-turn code review agents, architecture decision systems, and retrieval-augmented debugging. Kimi outperforms on tasks where reasoning steps matter more than raw generation speed. You trade throughput for reasoning quality and context retention.
Kimi's weights (Hugging Face) ship under Community License with Apache 2.0 terms, enabling commercial deployment with attribution. Supports GGUF (4/8-bit, int8), AWQ (4-bit), and native bfloat16. No proprietary format lock-in; the ecosystem is broad.
DeepSeek V4-Pro — The SWE-Bench Specialist
DeepSeek V4-Pro is optimized for code generation and execution. It dominates SWE-Bench Pro by 8+ percentage points with 9.3% faster inference than V4 baseline. Inference speed is 38ms per token on an RTX 4090 (bfloat16, 32-token batches) — that's 35% faster per-token than Kimi K2.6 on the same silicon.
This speed advantage matters for production inference at scale where throughput is a KPI. DeepSeek emphasizes software engineering artifacts in training: GitHub, Stack Overflow, technical documentation. It's strong for code completion, bug fixes, and CI/CD task generation. The hardware floor is an RTX 4070 (12 GB) with int4 quantization, or a single RTX 3090 (24 GB) with bfloat16. That's the lowest entry cost of the three without sacrificing quality.
Inference Speed & Cost Efficiency
The throughput advantage is measurable: 9.3% faster inference than V4 baseline and 35% faster per-token than Kimi when both run bfloat16. For production systems where latency is a KPI, this compounds over millions of inferences. Ideal for production code backends, test generation, security scanning, and high-volume APIs where per-token economics matter.
Supports full GGUF, MLC-LLM optimization, and vLLM batched serving. Proven production deployments exist from startups and enterprises. License: DeepSeek Research Limited open weights with regional endpoint restrictions in certain jurisdictions. Verify compliance before commercial deployment outside China and Southeast Asia.
Qwen 3.6 Plus — The Versatile Performer
Qwen 3.6 Plus is a balanced generalist — it excels at neither pure reasoning nor code, but wins on commercial accessibility and hardware efficiency. It's the lowest barrier to entry for small teams and SMBs. 8 GB VRAM suffices on an RTX 4060 (int4), enabling local deployment on consumer hardware. No enterprise GPU required.
Training balances code, reasoning, and general instruction-following. It achieves 89% of Kimi's reasoning performance and 78% of DeepSeek's code performance. Suitable as a generalist. April 2026 licensing lifted research-only restrictions, freeing SaaS startups from licensing fees and negotiations.
License Terms & Commercial Deployment
Qwen 3.6 Plus released under the Qwen License (permissive for non-commercial and commercial use). That's a simpler path than DeepSeek's regional restrictions or Kimi's attribution requirements. Ideal for SaaS targeting SMBs where per-deployment cost is critical: 8 GB VRAM vs competitors' 24–48 GB transforms economics.
Quantization maturity is high: AWQ, GPTQ, and GGUF are all optimized. Backed by Ollama, LM Studio, and vLLM with ready-made variants. The trade-off: lower benchmarks (49 AA Index) mean slower reasoning and fewer code wins. It's sufficient for customer-facing chat, RAG, and light coding tasks.
Hardware Requirements & Real-World TCO
| Model | Minimum GPU | GPU Cost | Full System Cost | Best Use Case |
|---|---|---|---|---|
| Kimi K2.6 | RTX 4090 or dual RTX 3090 | $1,800 or $2,400 pair | $4,200–$5,100 | Agents, long-context reasoning, RAG |
| DeepSeek V4-Pro | RTX 4070 or RTX 4090 | $500 or $1,800 | $2,500–$3,800 | Production code backends, API inference |
| Qwen 3.6 Plus | RTX 4060 or RTX 4070 | $220 or $500 | $1,200–$2,200 | SaaS, SMB deployments, edge inference |
Three-year TCO includes electricity (assumes $0.15/kWh at 8 hours/day), cooling, and occasional repairs. DeepSeek and Qwen favor smaller deployments. Kimi justifies its cost only if your workload is reasoning-heavy.
Scaling Beyond Single-Card
Kimi K2.6 scales efficiently with vLLM multi-card orchestration. Two H100s (80 GB) handle 512-token batches at sub-50ms latency for high-volume agent deployments. DeepSeek V4-Pro is designed for vLLM Tensor Parallel. Four RTX 3090s (96 GB) deliver 100K tokens/sec—cost-effective for high-margin API endpoints with tight per-token pricing.
Qwen 3.6 Plus remains single-card friendly. Scale horizontally via Ollama multi-instances, not tensor-parallel: simpler operations, higher latency. Pick by workload: Kimi for agent reasoning (small, high-margin), DeepSeek for APIs (high-volume), Qwen for edge and SMB.