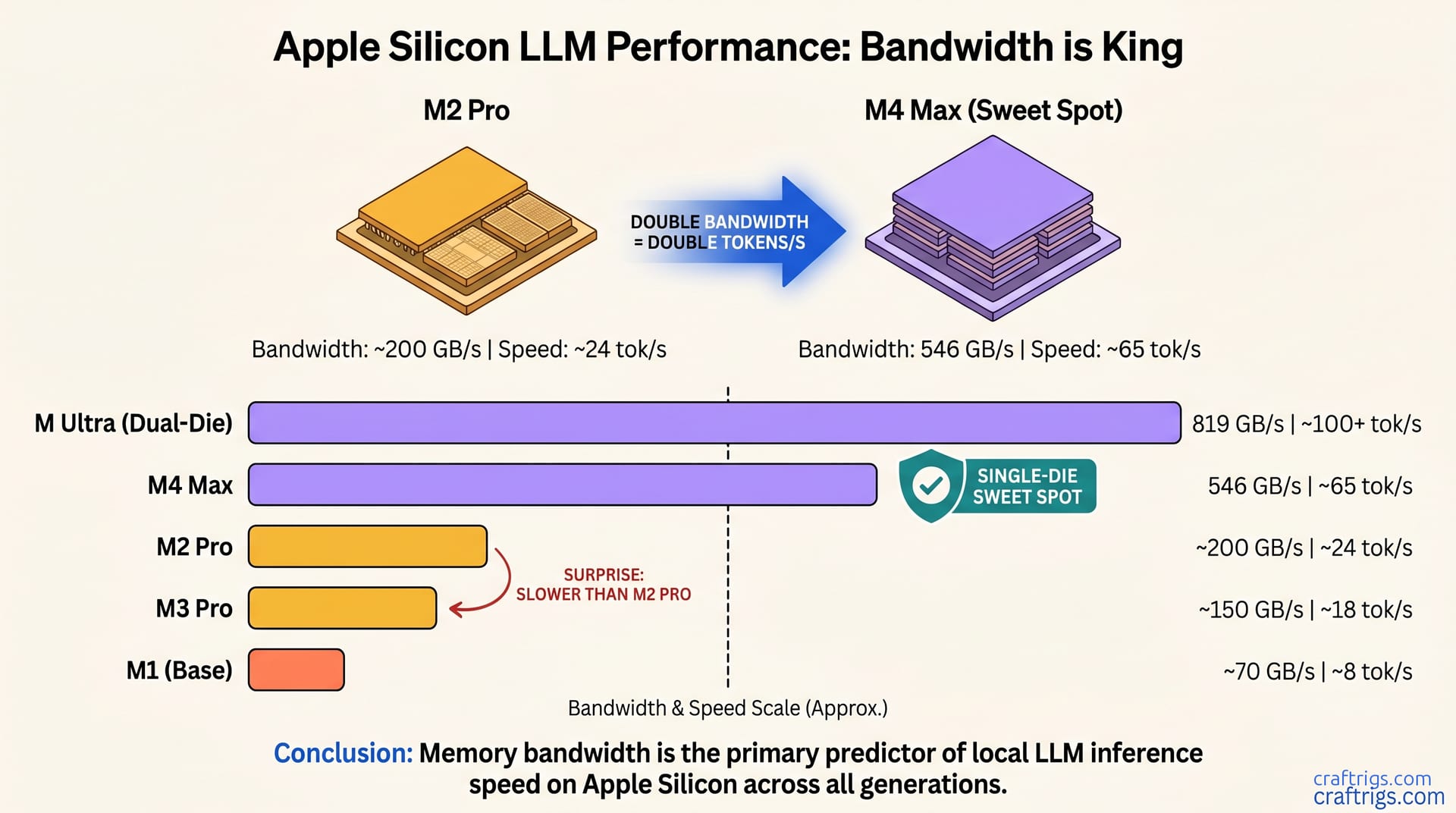
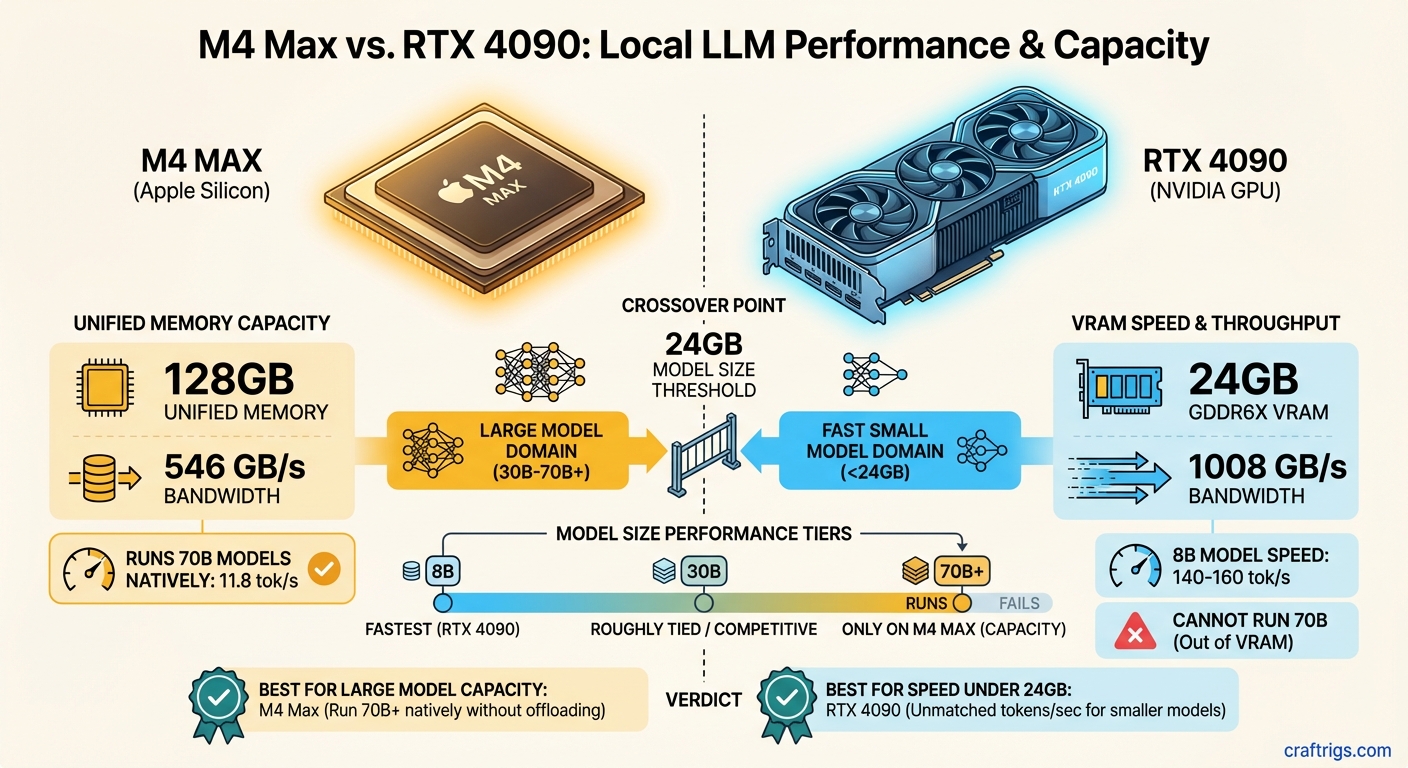
Comparison
Comparison
Intel Arc Pro B70 vs RTX 3090: The 32GB Local AI Showdown
Arc Pro B70 $949 32GB vs used RTX 3090 24GB. Specs, benchmarks, and which GPU actually wins for 70B models at home. Bandwidth vs VRAM explained.
May 21, 2026You've narrowed it down to two cards. They're $200 apart. The spec sheet says the expensive one is 15% faster, but you don't know if that 15% matters for the models you actually run.
Chloe runs the head-to-head comparisons that answer the specific question you're actually asking, not the benchmark the manufacturer wants you to see. No synthetic benchmark theater. Her comparisons focus on the metrics that matter for local LLM workloads specifically.
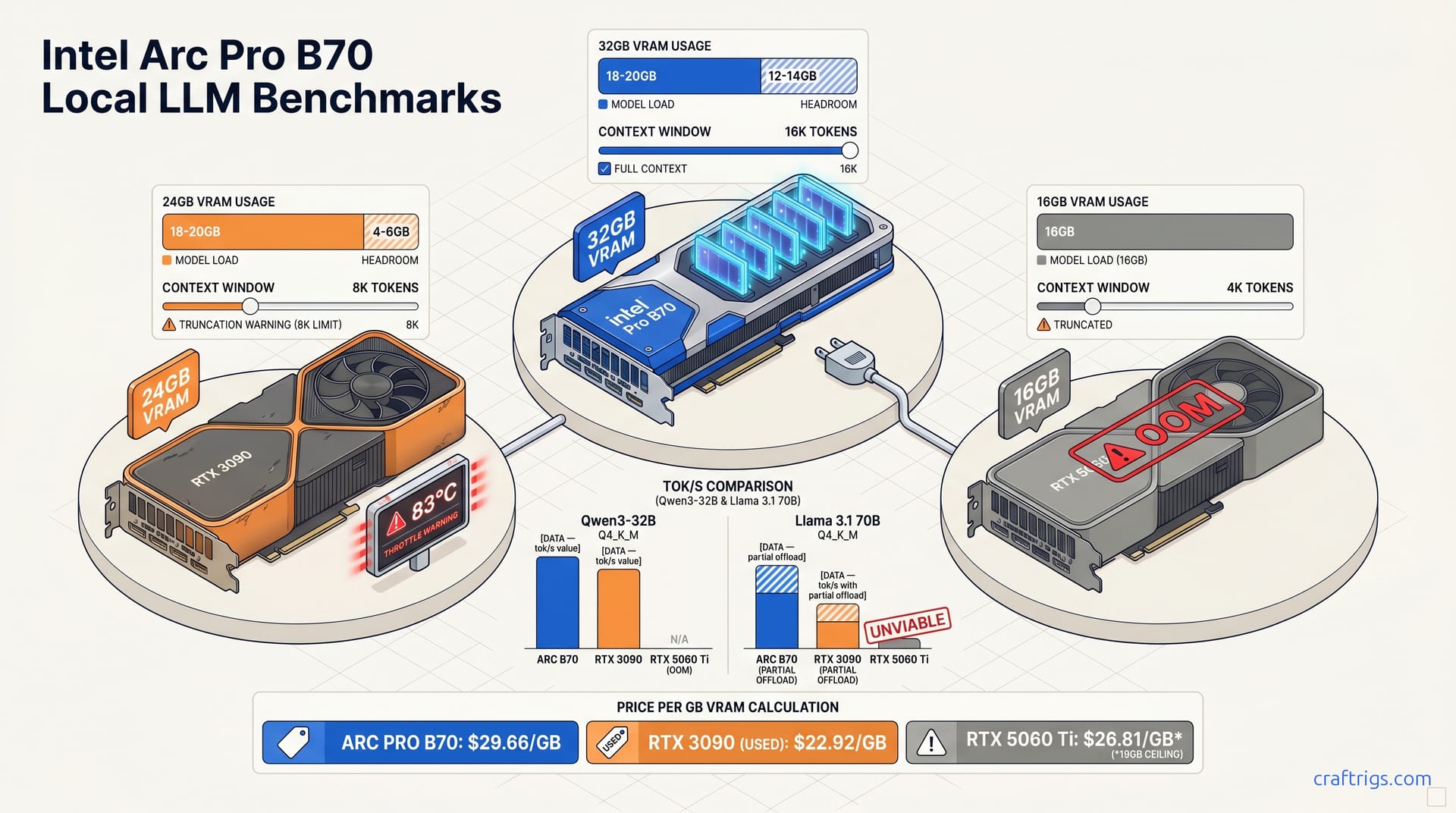
32GB VRAM under $1K sounds perfect for local LLMs—until you benchmark IPEX-LLM against CUDA. Arc Pro B70 tok/s lags RTX 3090 on 70B offload, wins only at 32B context headroom. Buy Intel for the gigabytes, buy used NVIDIA for the speed.
May 22, 2026Arc Pro B70 $949 32GB vs used RTX 3090 24GB. Specs, benchmarks, and which GPU actually wins for 70B models at home. Bandwidth vs VRAM explained.
May 21, 2026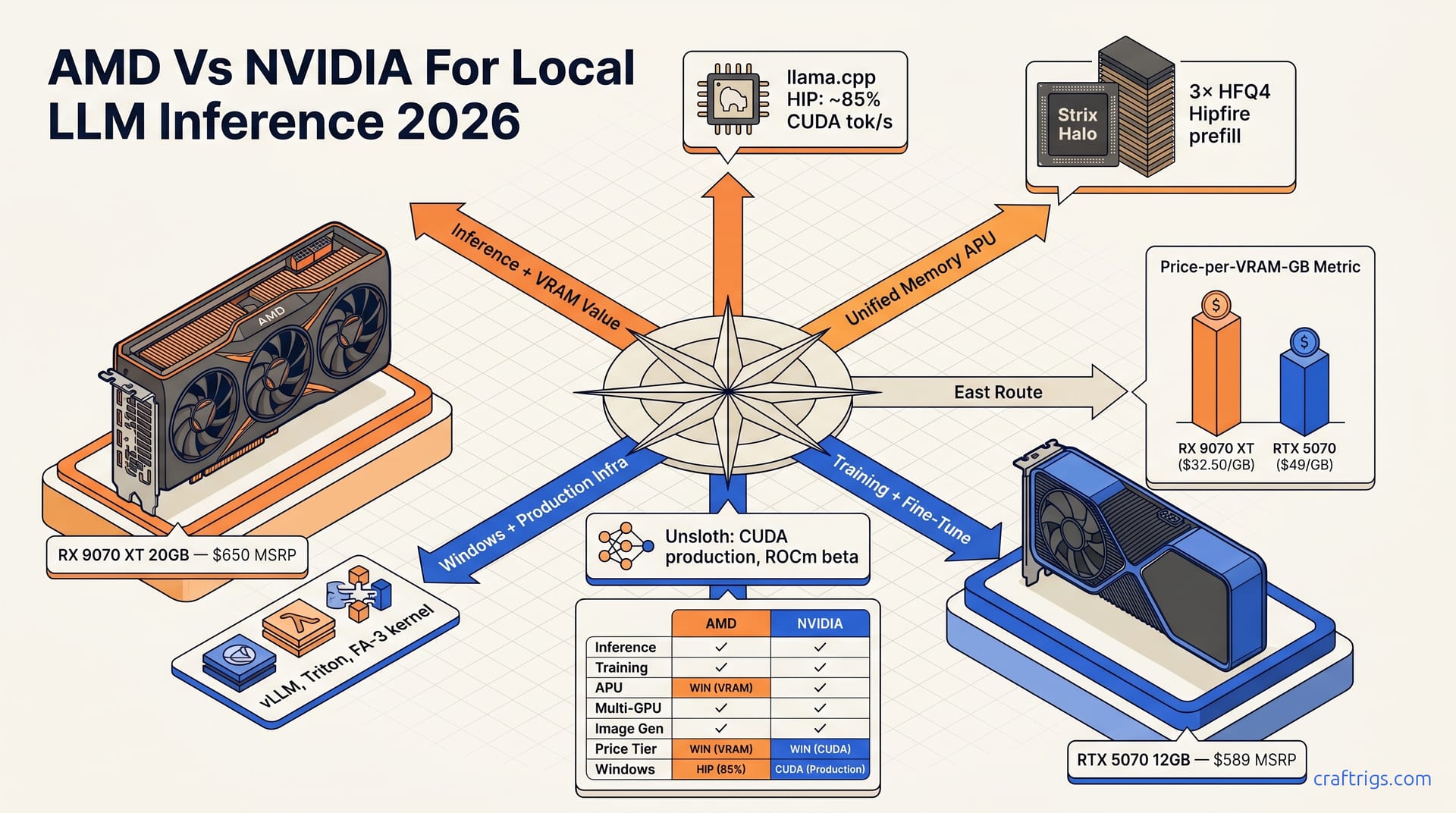
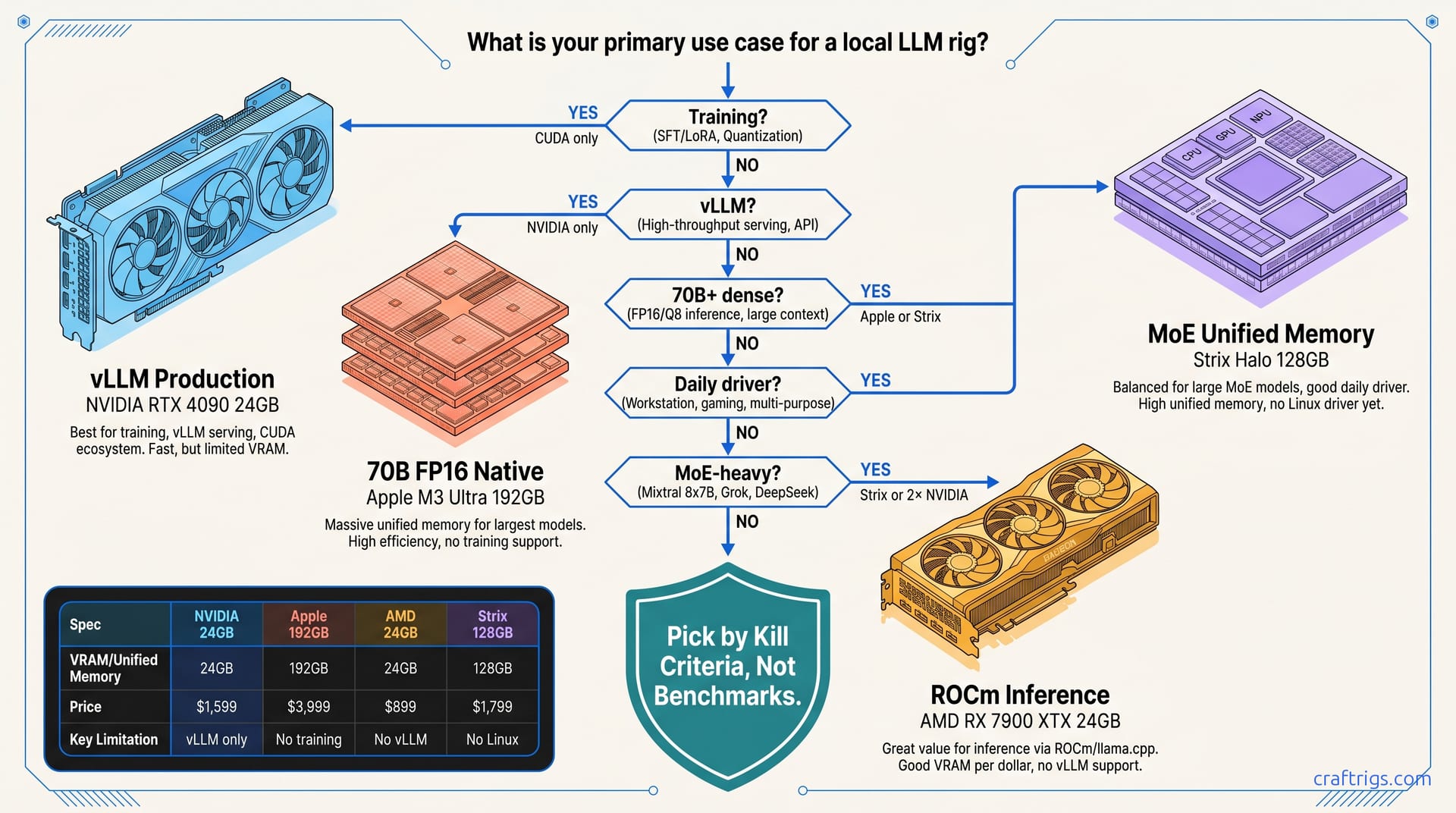
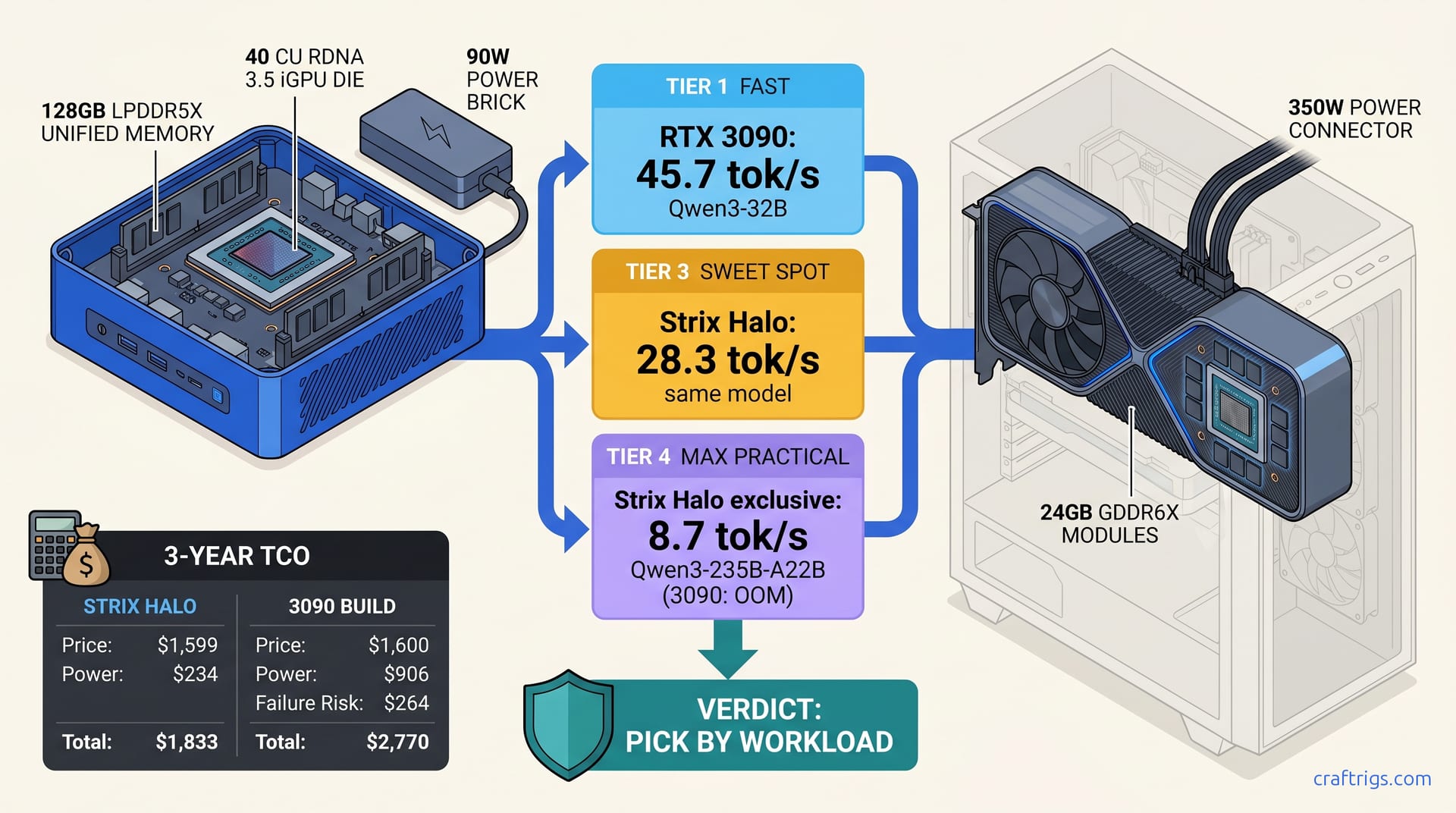
May 2026 reality: Hipfire and Strix Halo shift AMD's inference story. AMD wins VRAM value; NVIDIA wins training. Route by your workload, not brand loyalty.
May 8, 2026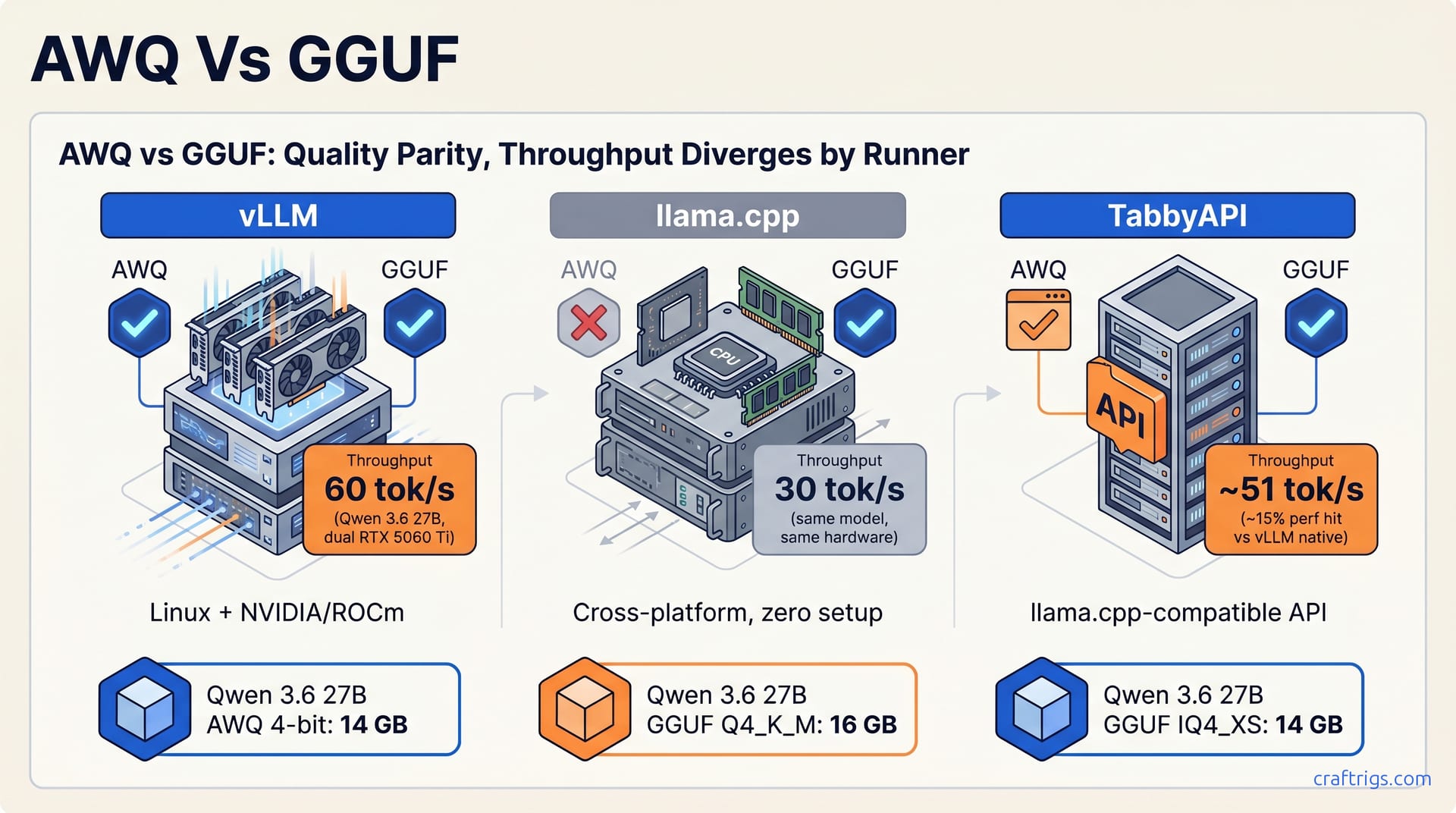
AWQ on vLLM vs GGUF on llama.cpp — 4-bit format choice for multi-user vs single-user. Speed, runner support, and which fits your stack.
May 8, 2026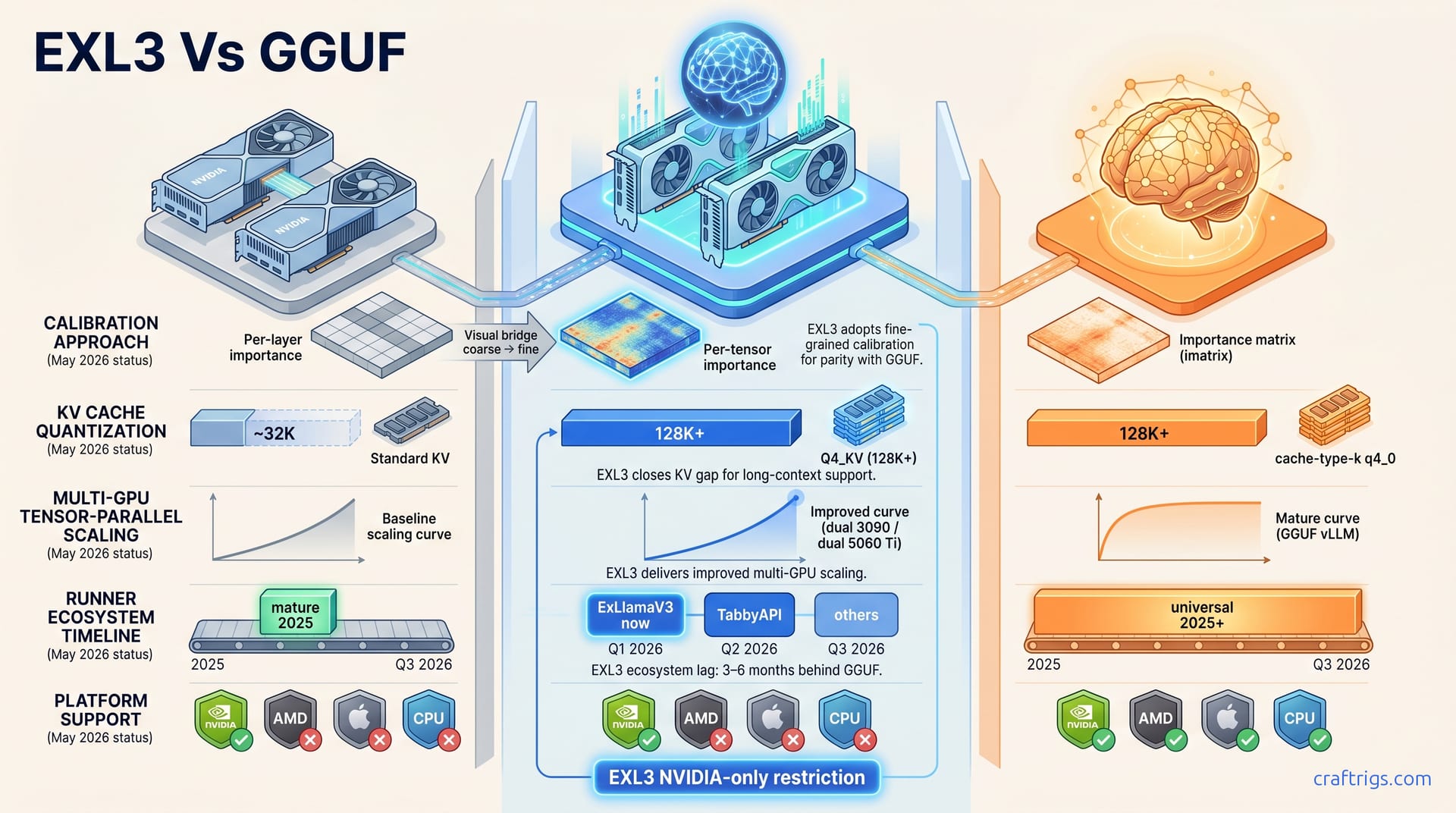
EXL3 borrowed GGUF's imatrix for NVIDIA. Matched benchmarks vs Q4_K_M/IQ4_XS show if it closed the gap. Qwen 3.6 ready, runners catching up — upgrade when your runner is stable.
May 8, 2026
`B580's IPEX-LLM: 95 tok/s on Qwen 3.6 7B (10–25% faster). RTX 3060: $220 used, CUDA proven. Buy B580 for new + speed. Buy 3060 for zero software friction.`
May 8, 2026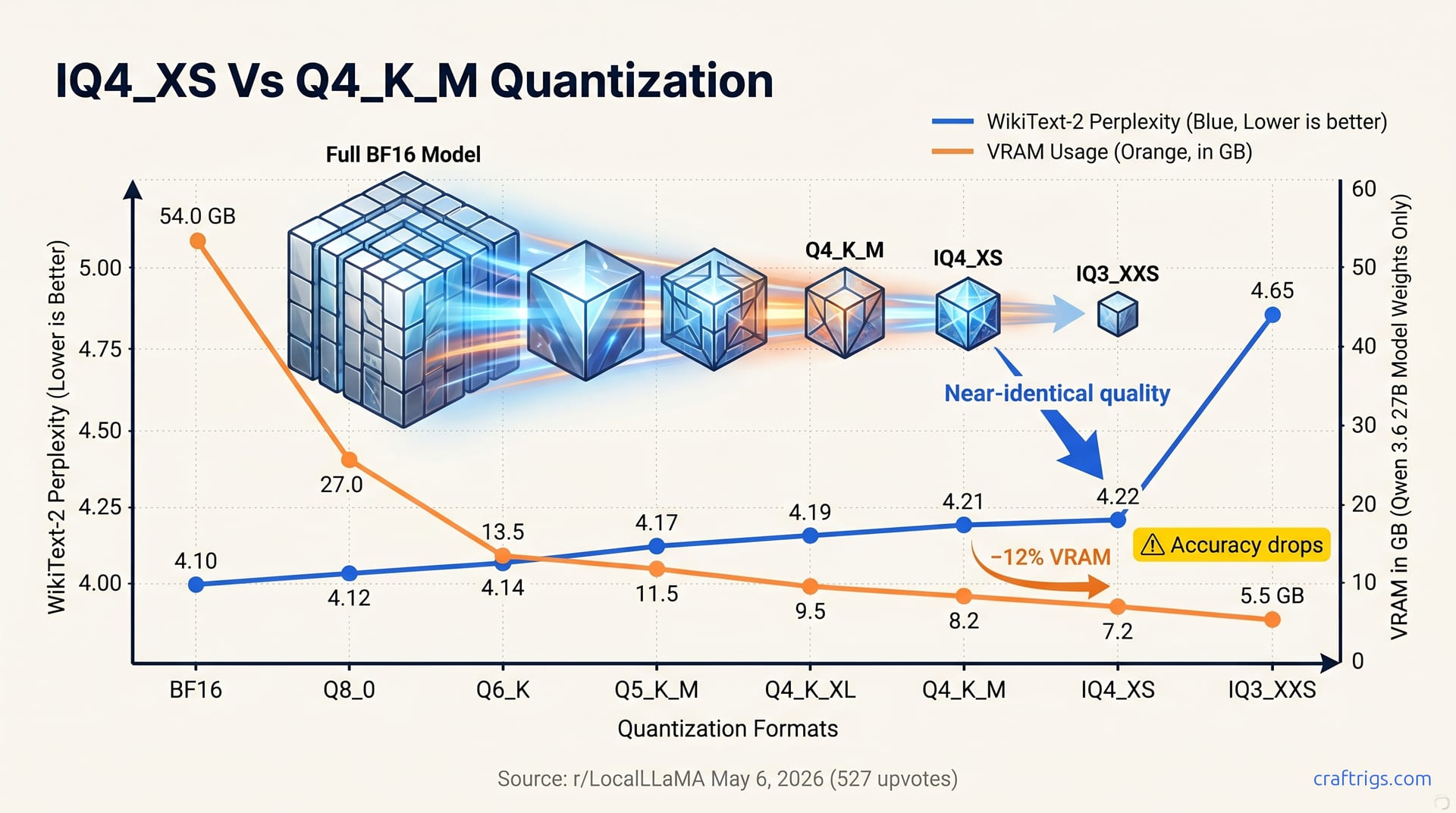
IQ4_XS saves ~12% VRAM vs Q4_K_M with near-equal perplexity on Qwen 3.6 27B. Benchmarks, when to pick which, and where IQ3_XXS becomes risky.
May 8, 2026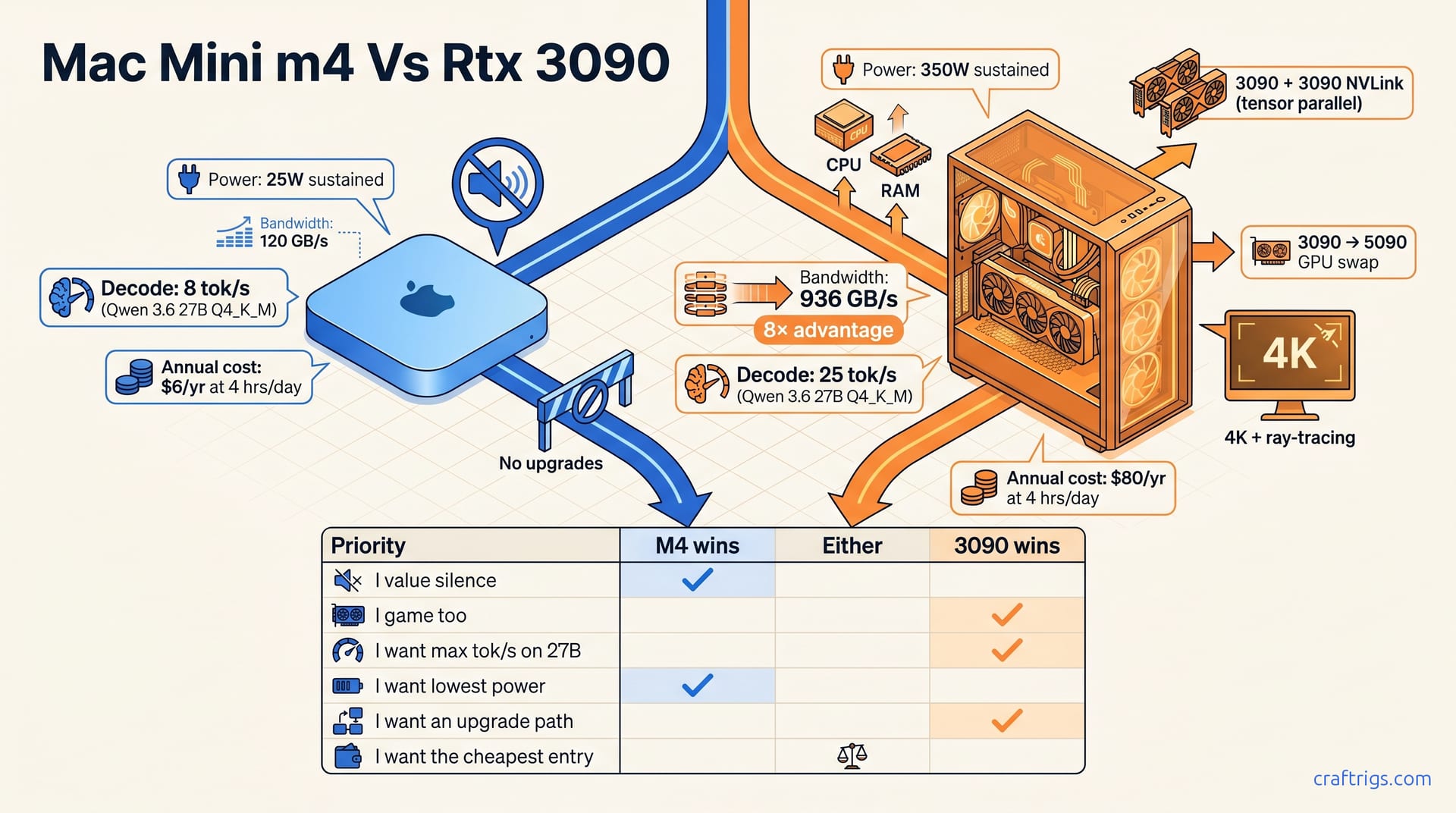
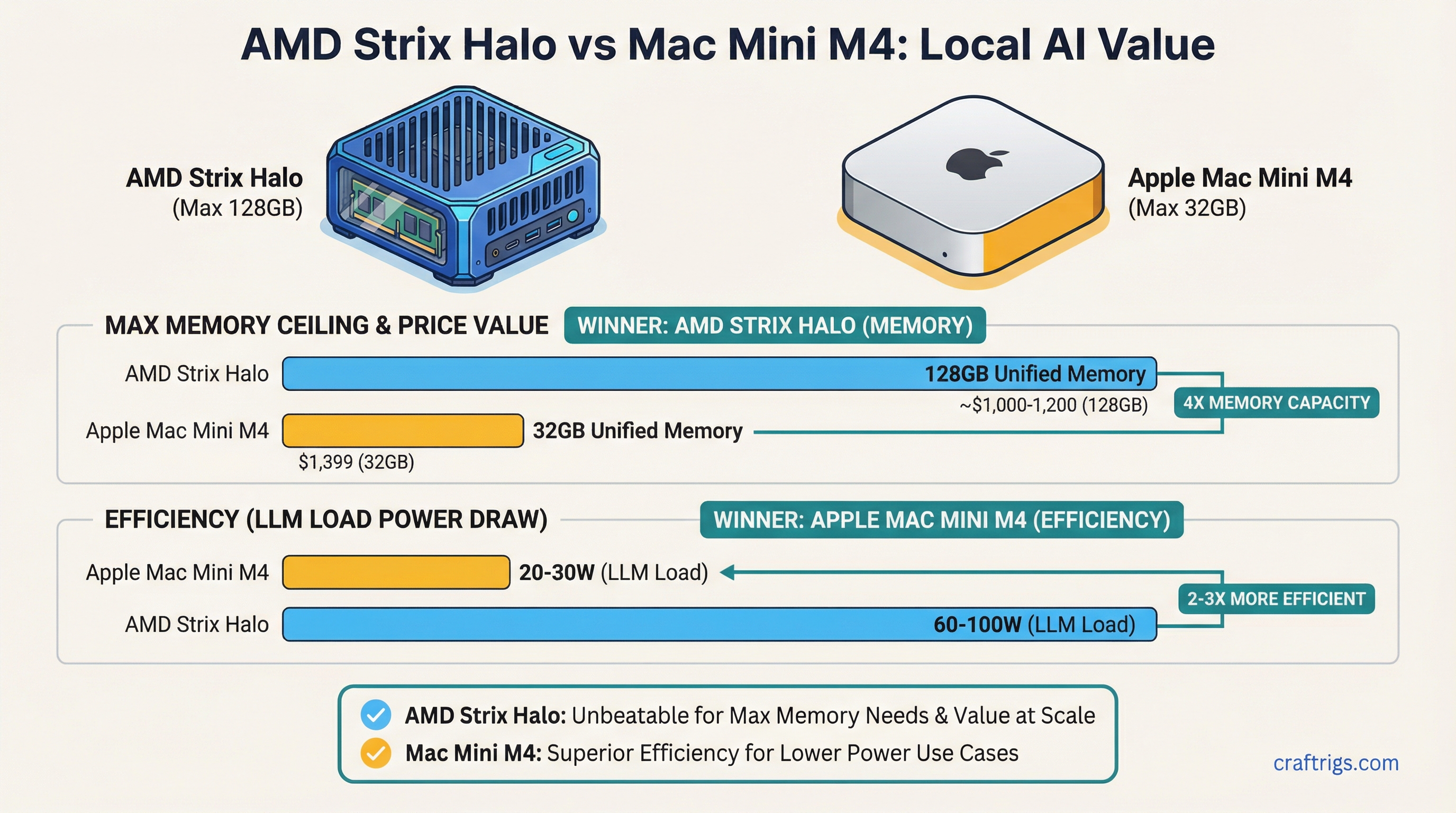
Mac Mini M4 24 GB vs used RTX 3090 desktop for local LLMs. Unified memory and silence vs raw VRAM and decode speed — a decision matrix.
May 8, 2026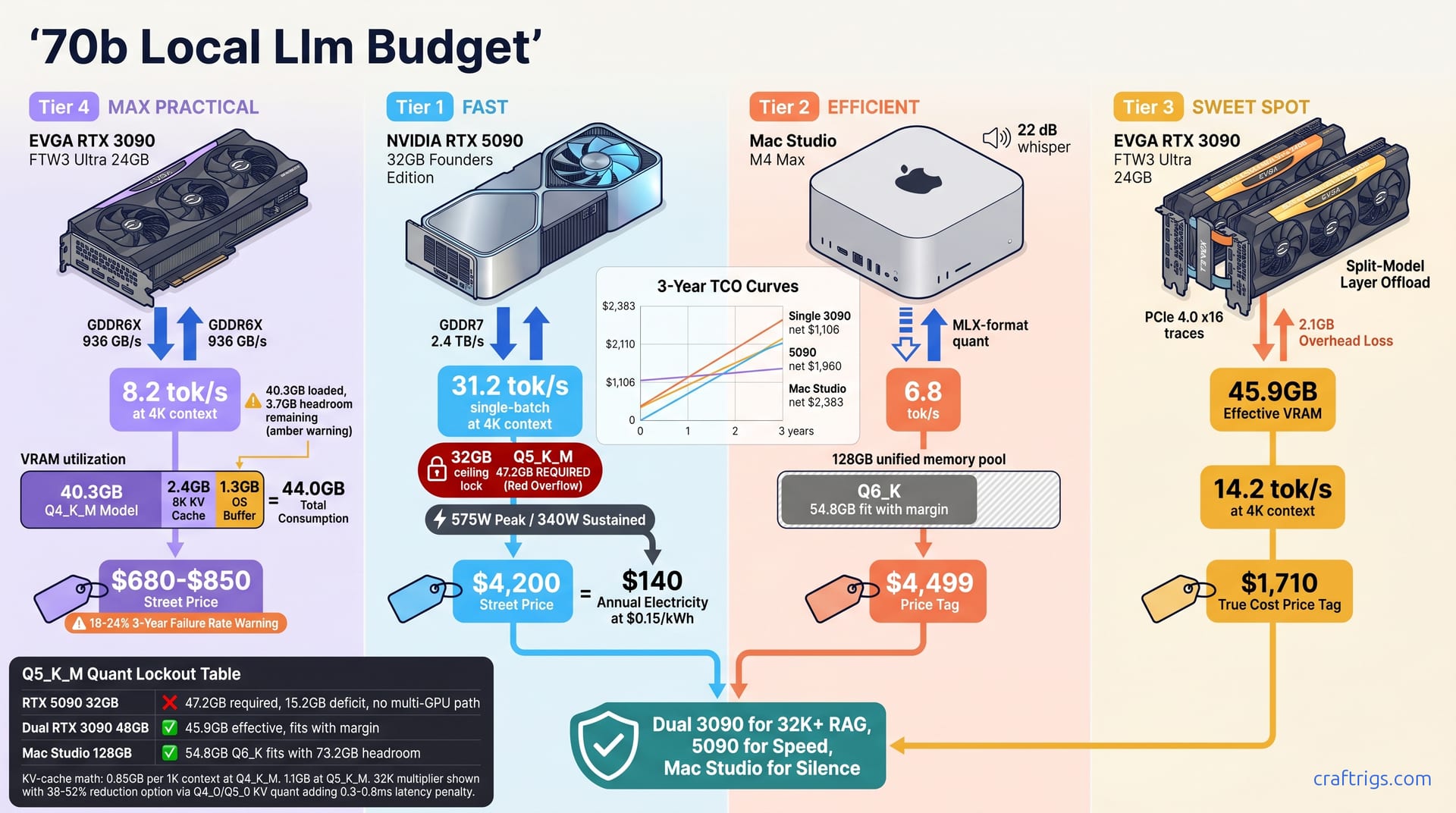
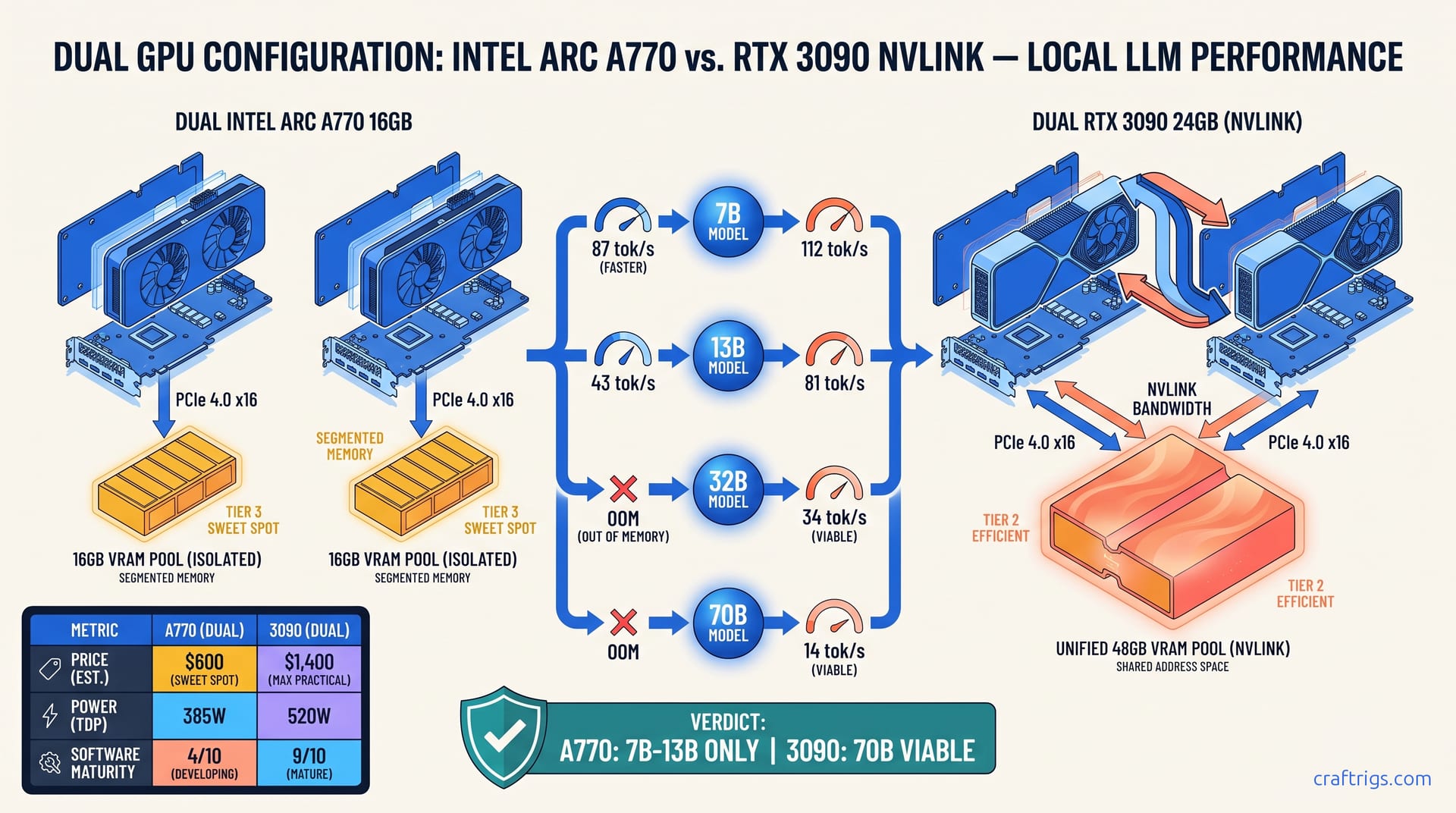
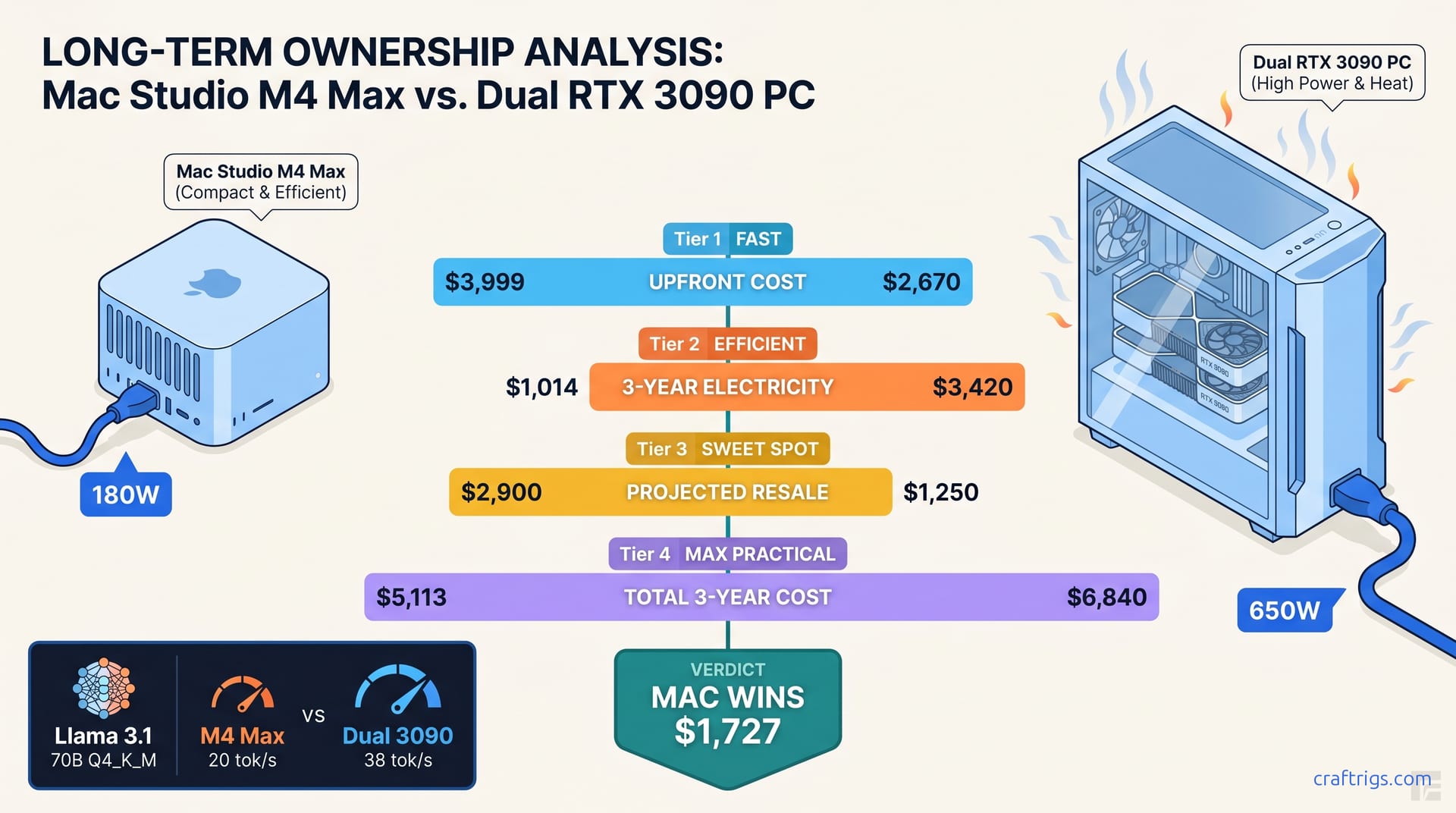
Need 70B local LLM power? Single 3090 chokes at 8K context, 5090 can't run Q5_K_M, Mac Studio is silent but slow. See tok/s, TCO, and the dual 3090 surprise winner—before you buy the wrong tier and eat 70% depreciation.
May 5, 2026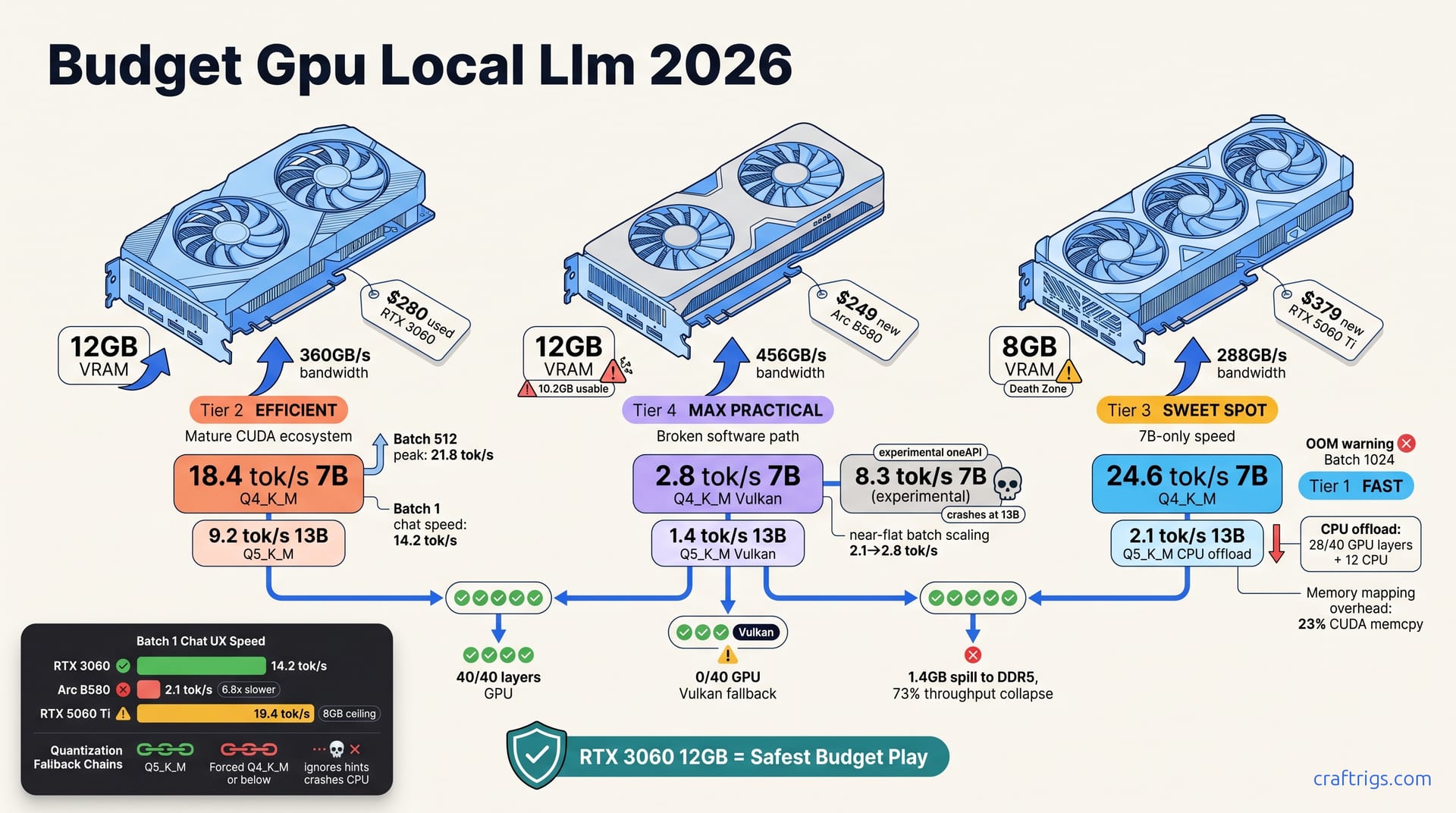
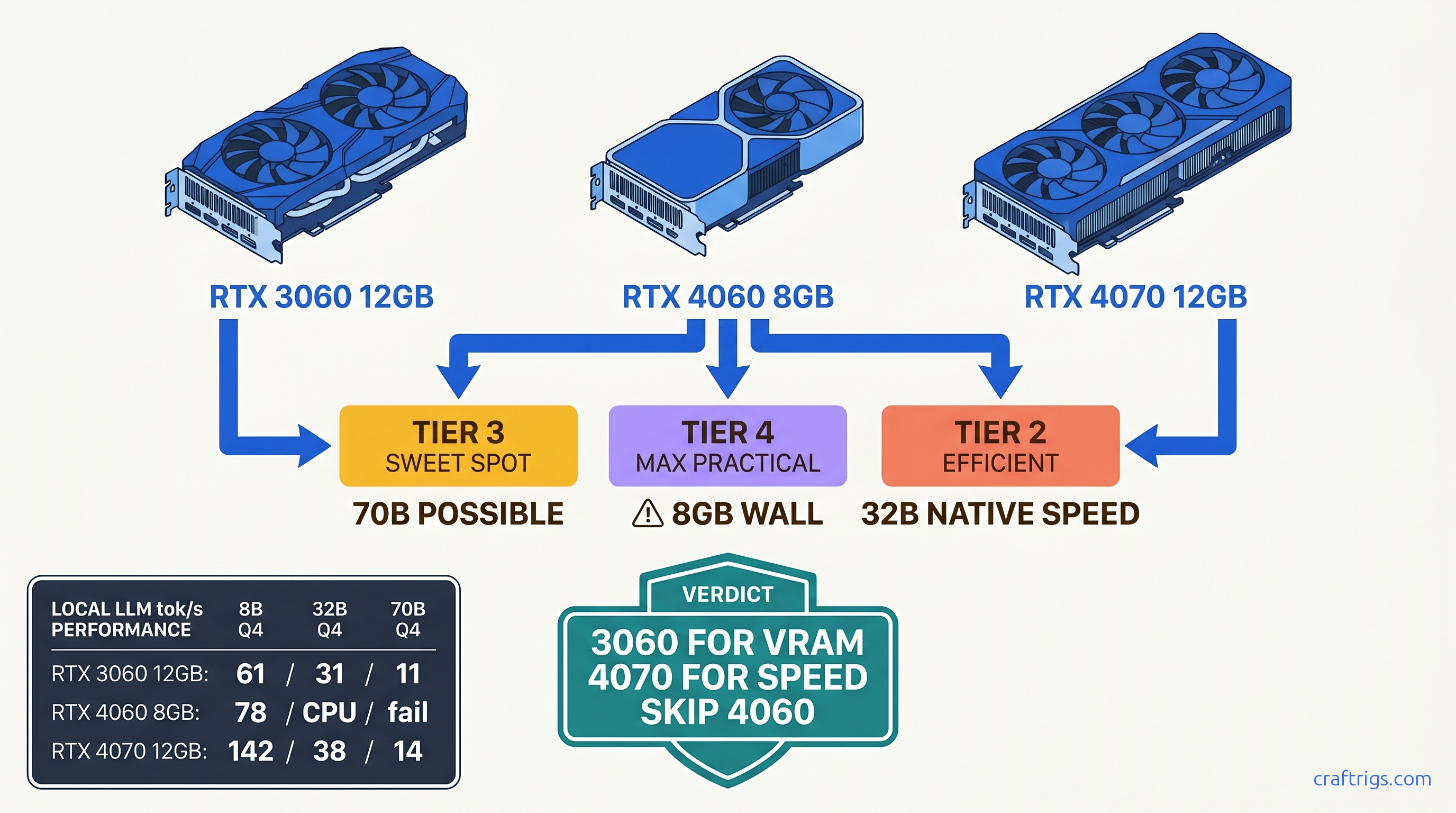
Stop wasting money on GPUs that can't run local LLMs. RTX 3060 hits 18.4 tok/s with 12GB VRAM, Arc B580 crashes at 2.8 tok/s, and 5060 Ti's 8GB is a 13B trap—here's the 3-year TCO truth Budget Builders need.
May 5, 2026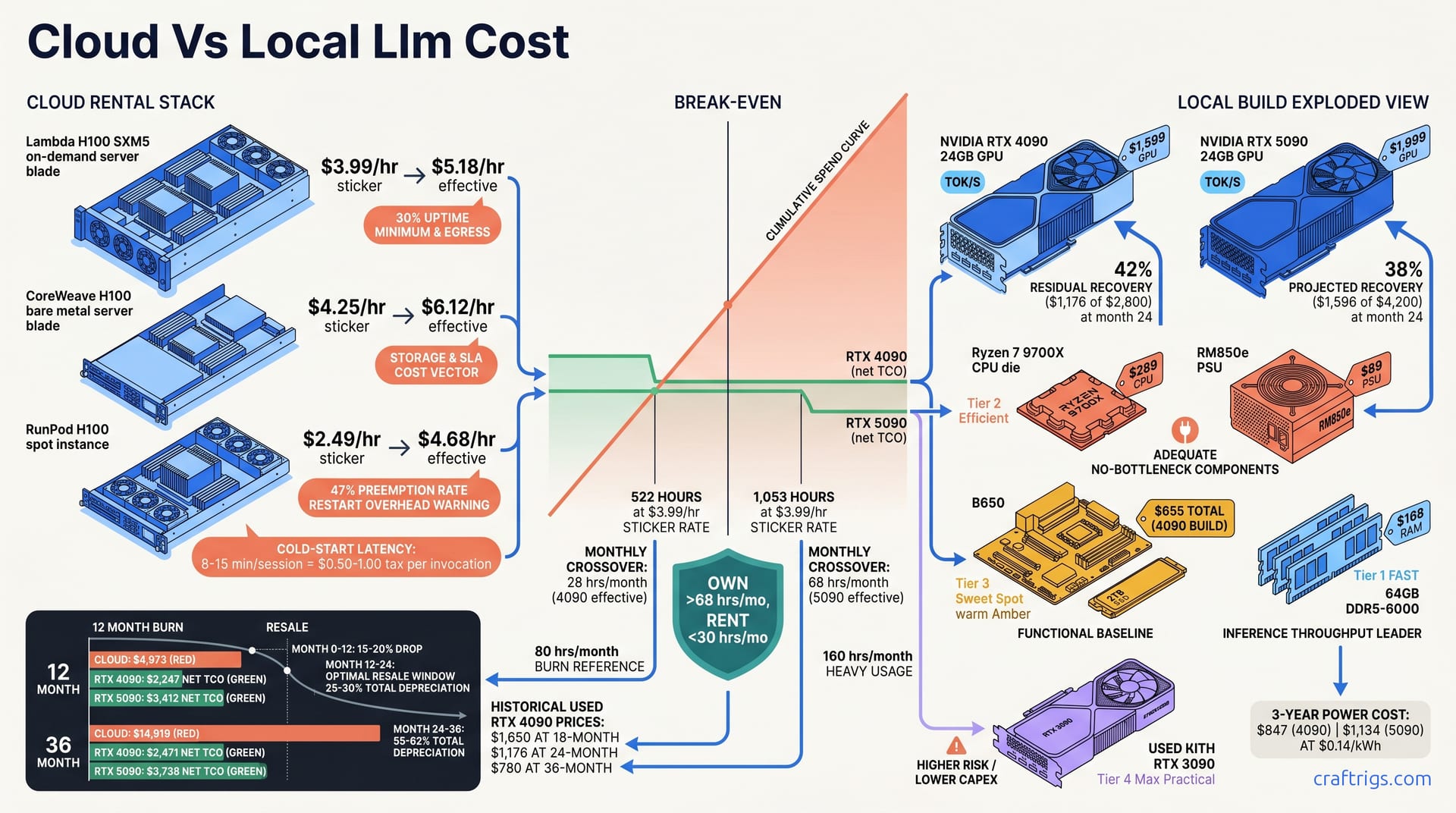
Cloud H100 at $4/hr seems cheap until month 10. RTX 5090 breaks even at 68 hrs/mo, saves $11K in 3 years. 5 non-financial kill criteria make cloud math meaningless — latency, privacy, availability, data gravity, customization.
May 5, 2026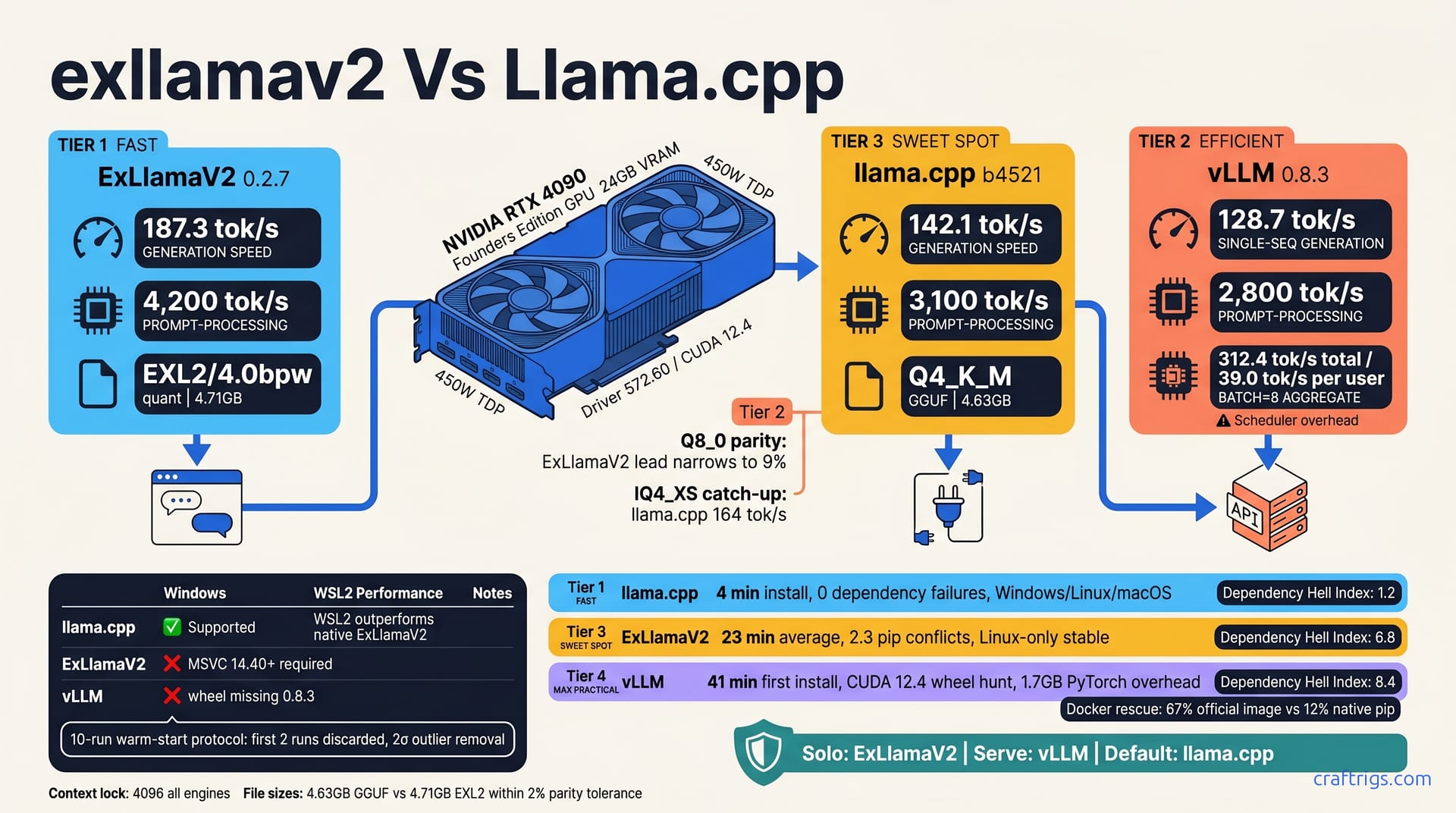
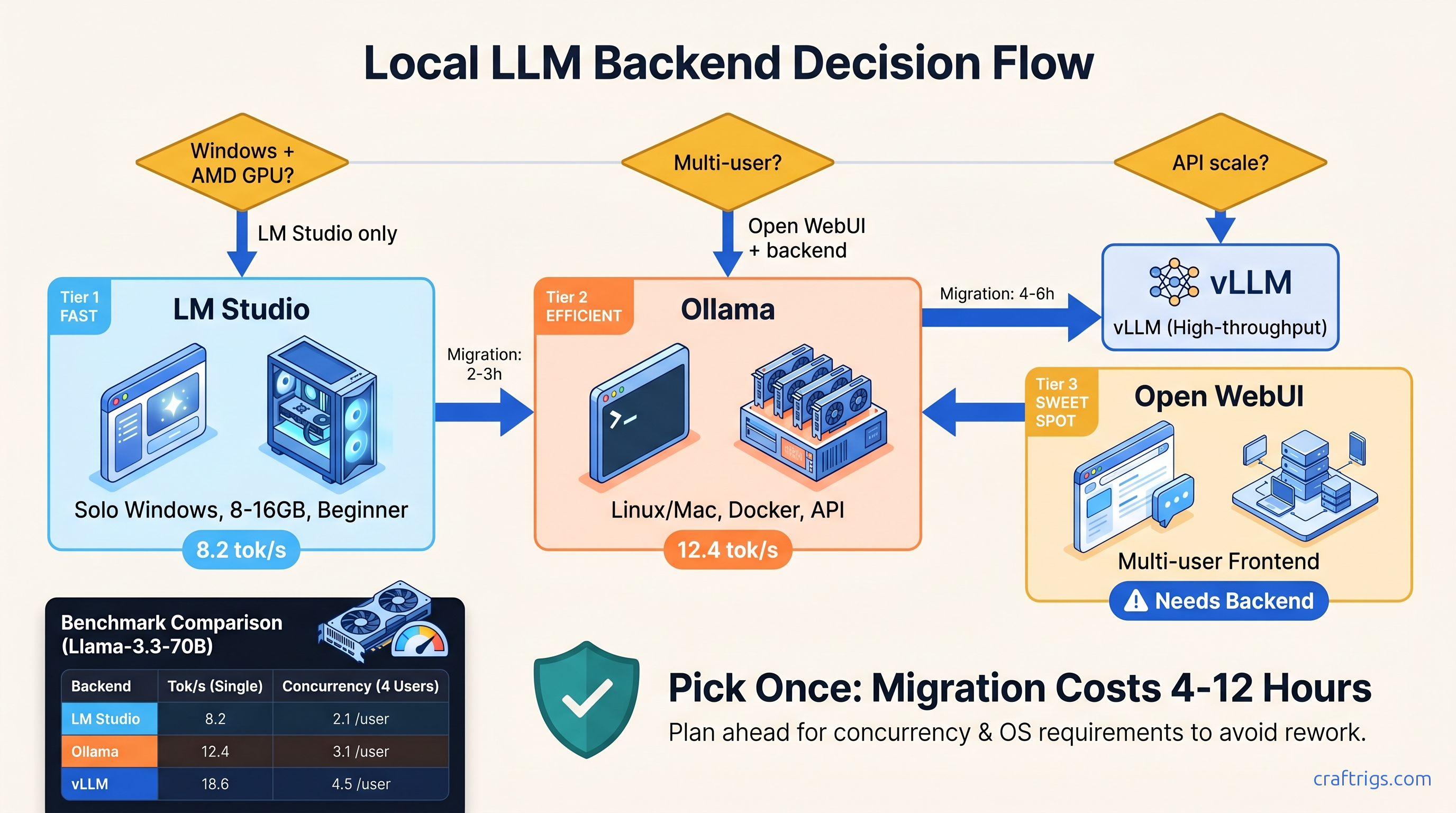
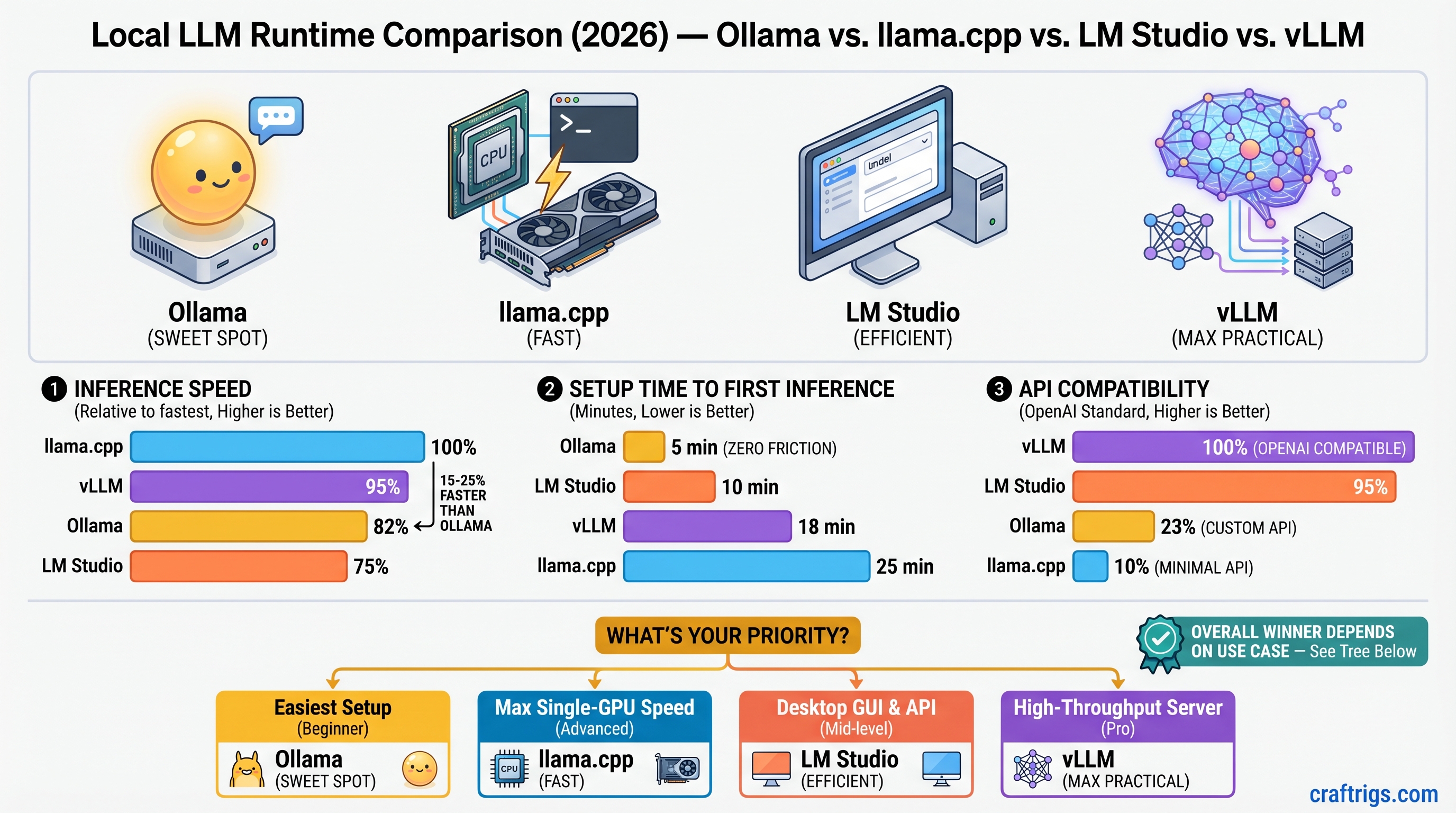
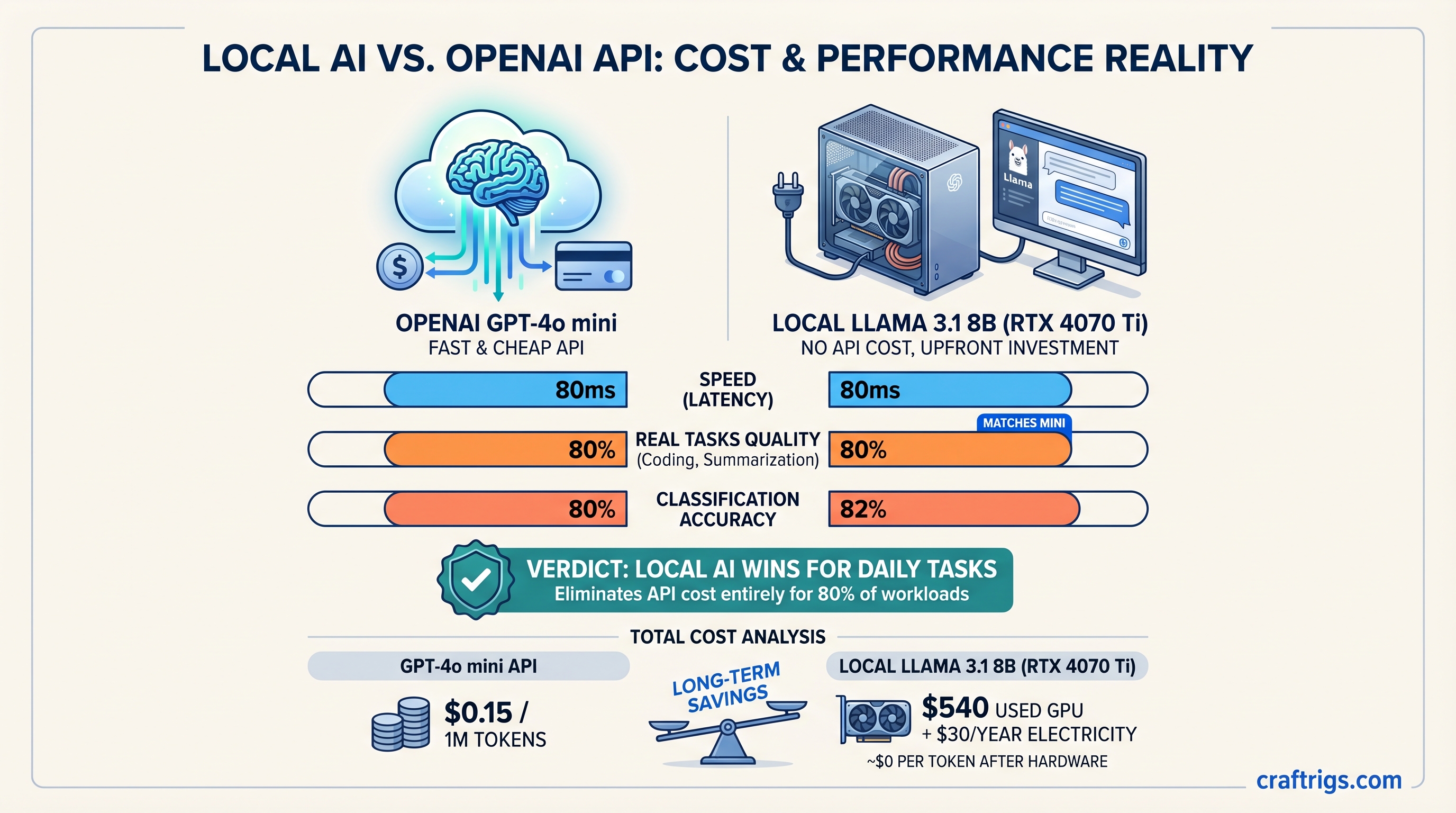
Your RTX 4090 is leaving 45% speed on the table. Benchmark all 3 engines on identical Llama-3 8B hardware—187 tok/s single-user, 312 tok/s batch. See which engine wins your workload before you waste another weekend on broken installs.
May 5, 2026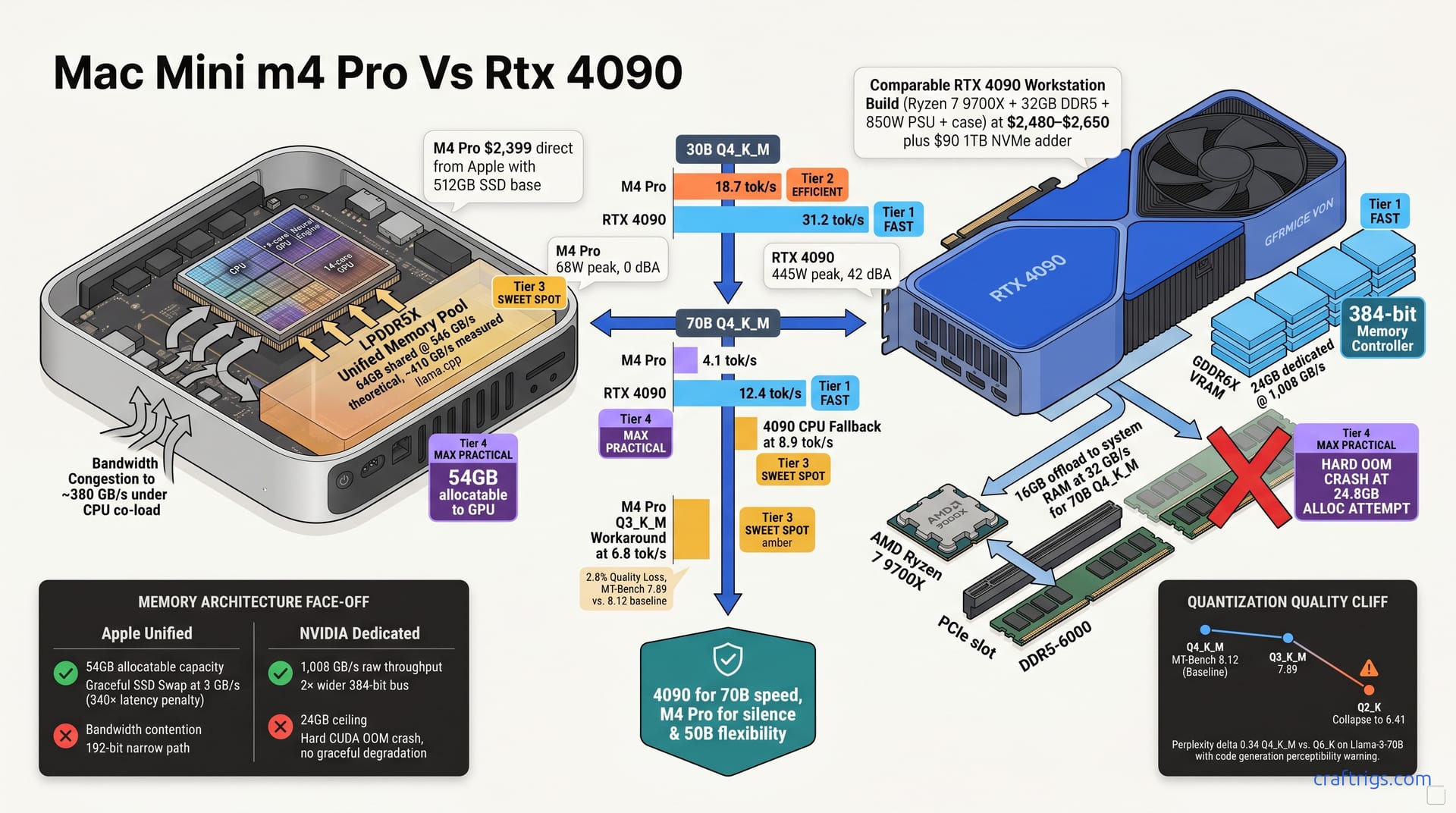
Same $2,400 price, wildly different LLM performance: M4 Pro 64GB hits 4.1 tok/s on 70B while RTX 4090 reaches 12.4 tok/s. MLX vs CUDA, memory bandwidth, and the quantization gap—compared so you don't guess wrong.
May 5, 2026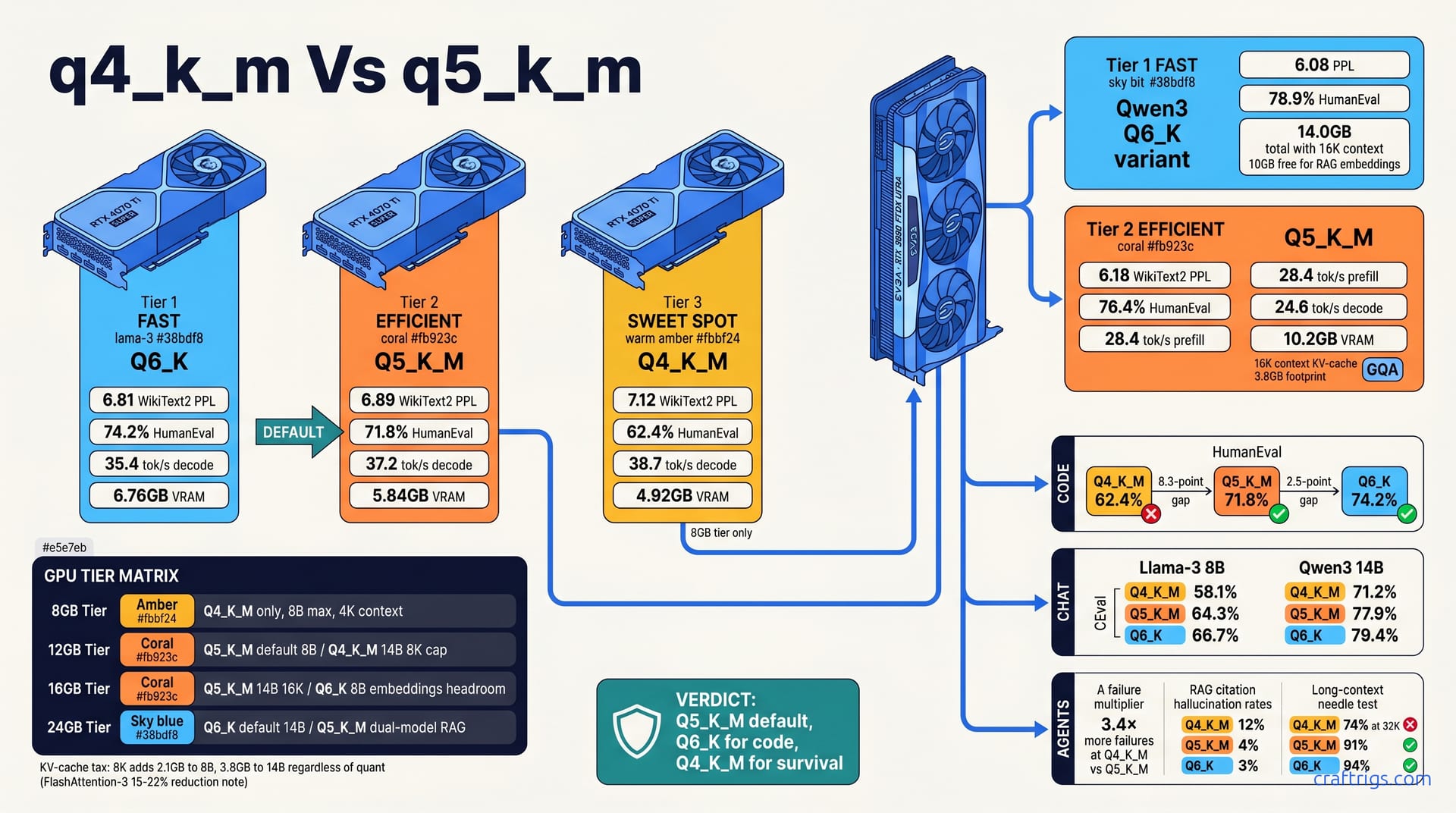
Stop guessing which llama.cpp quant to download. Q4_K_M, Q5_K_M, and Q6_K compared on Llama-3 8B and Qwen3 14B for perplexity, speed, and coding accuracy—here's the VRAM tier matrix that ends the hoarding.
May 5, 2026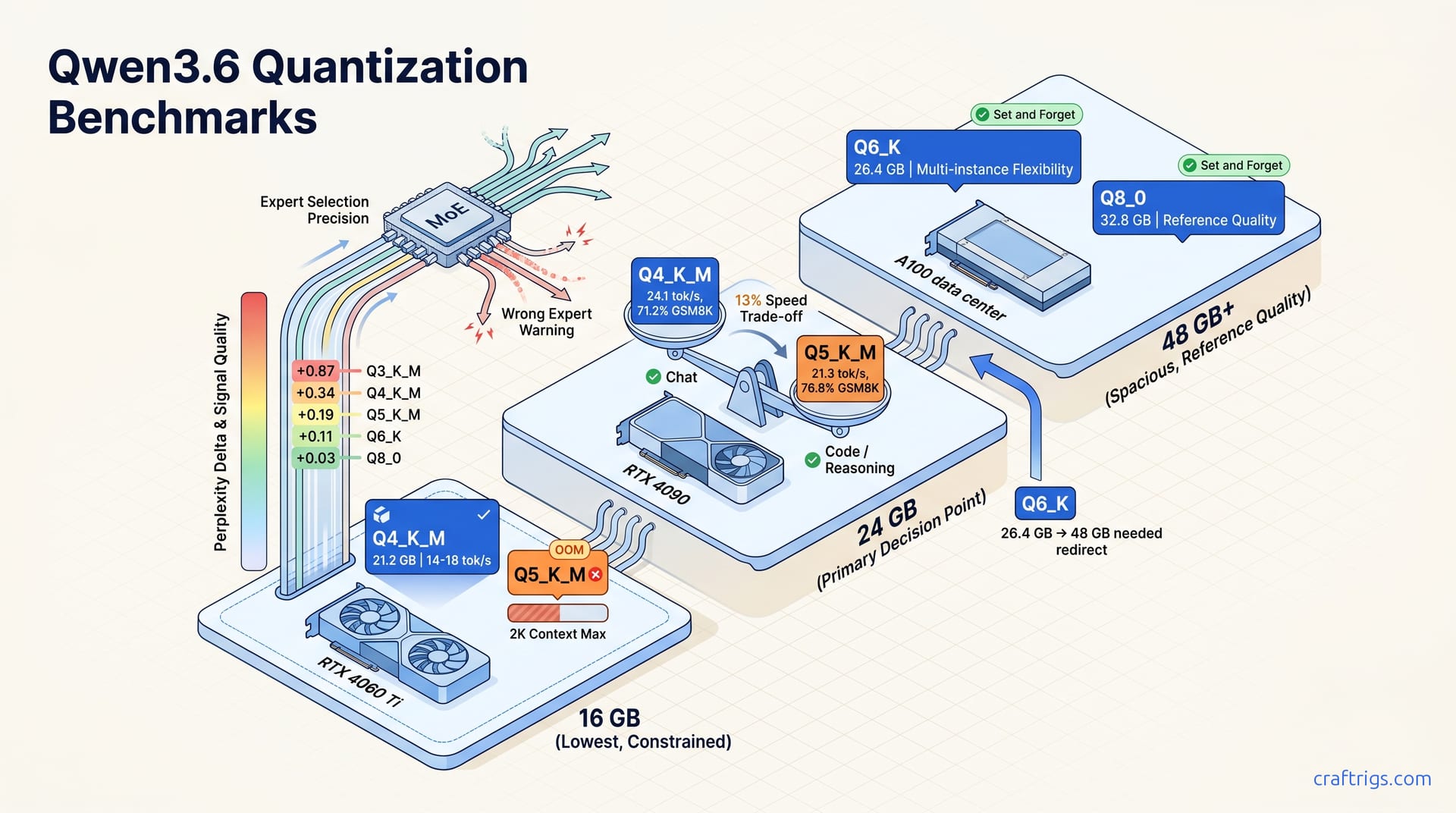
Wrong quant kills Qwen3.6's expert routing—Q4_K_M drops 11 points on GSM8K, Q5_K_M recovers verification behavior, but Q8_0 needs 48 GB. Match quant to your GPU tier and workload, not just perplexity.
Apr 30, 2026
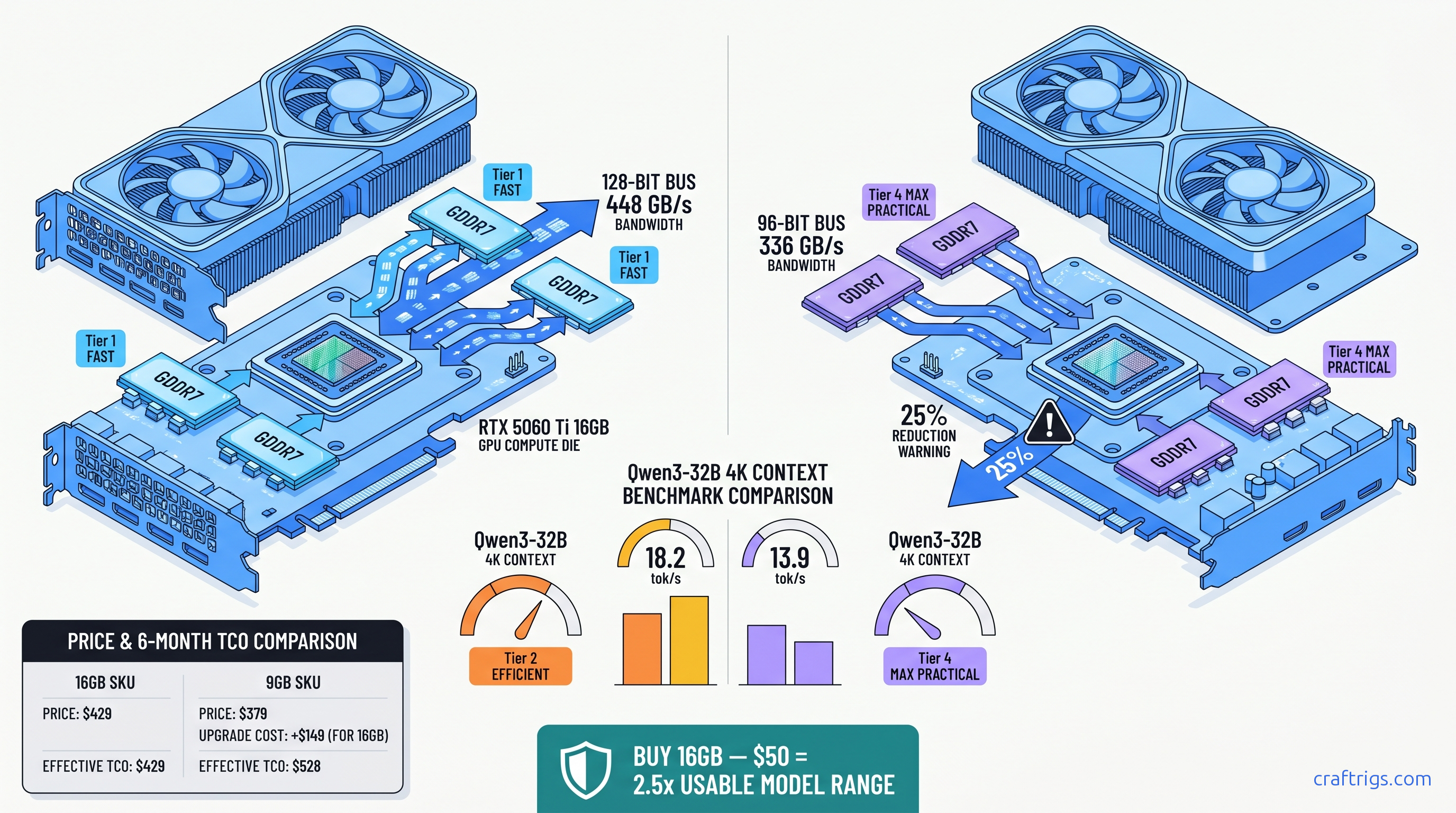
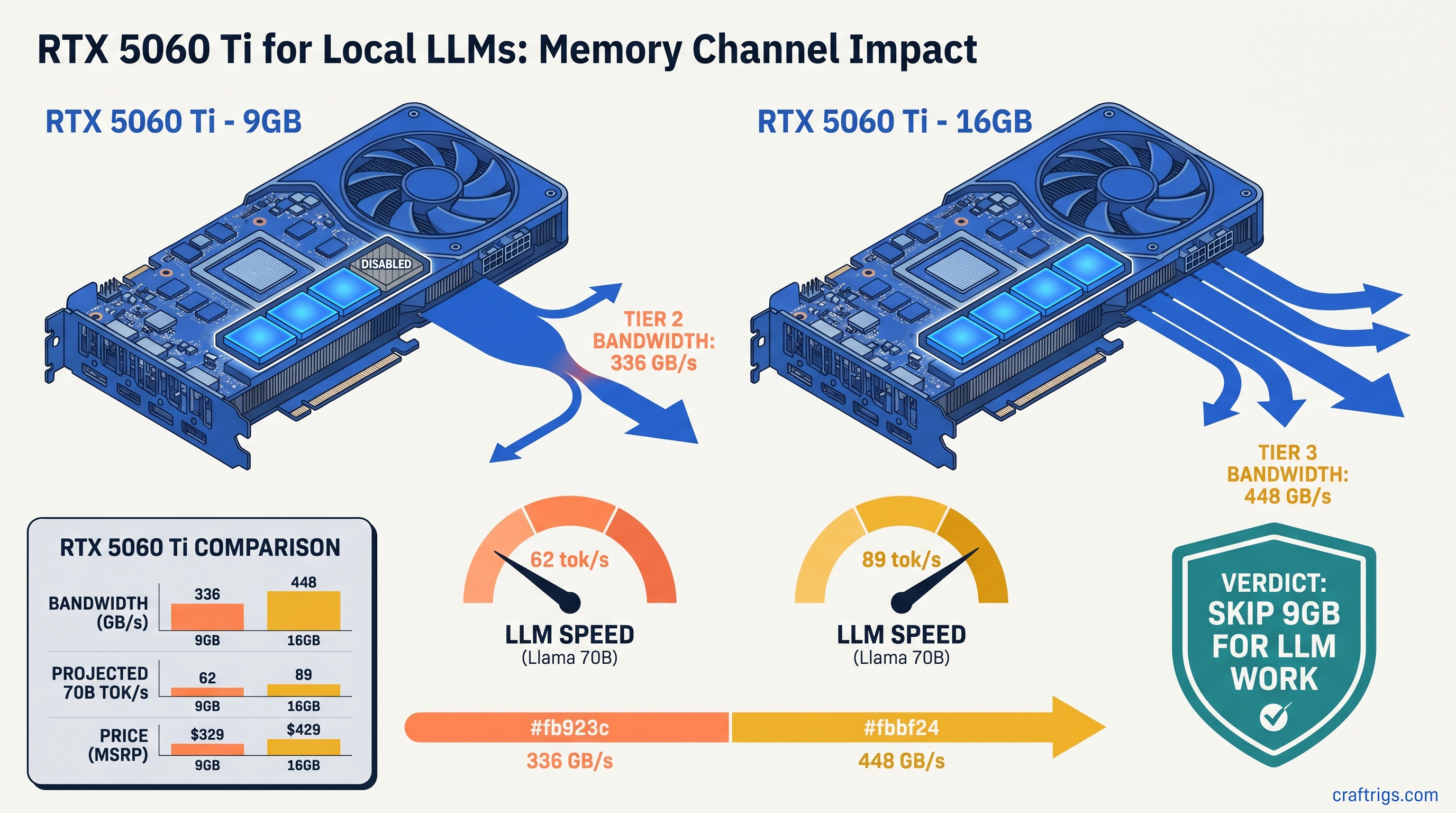
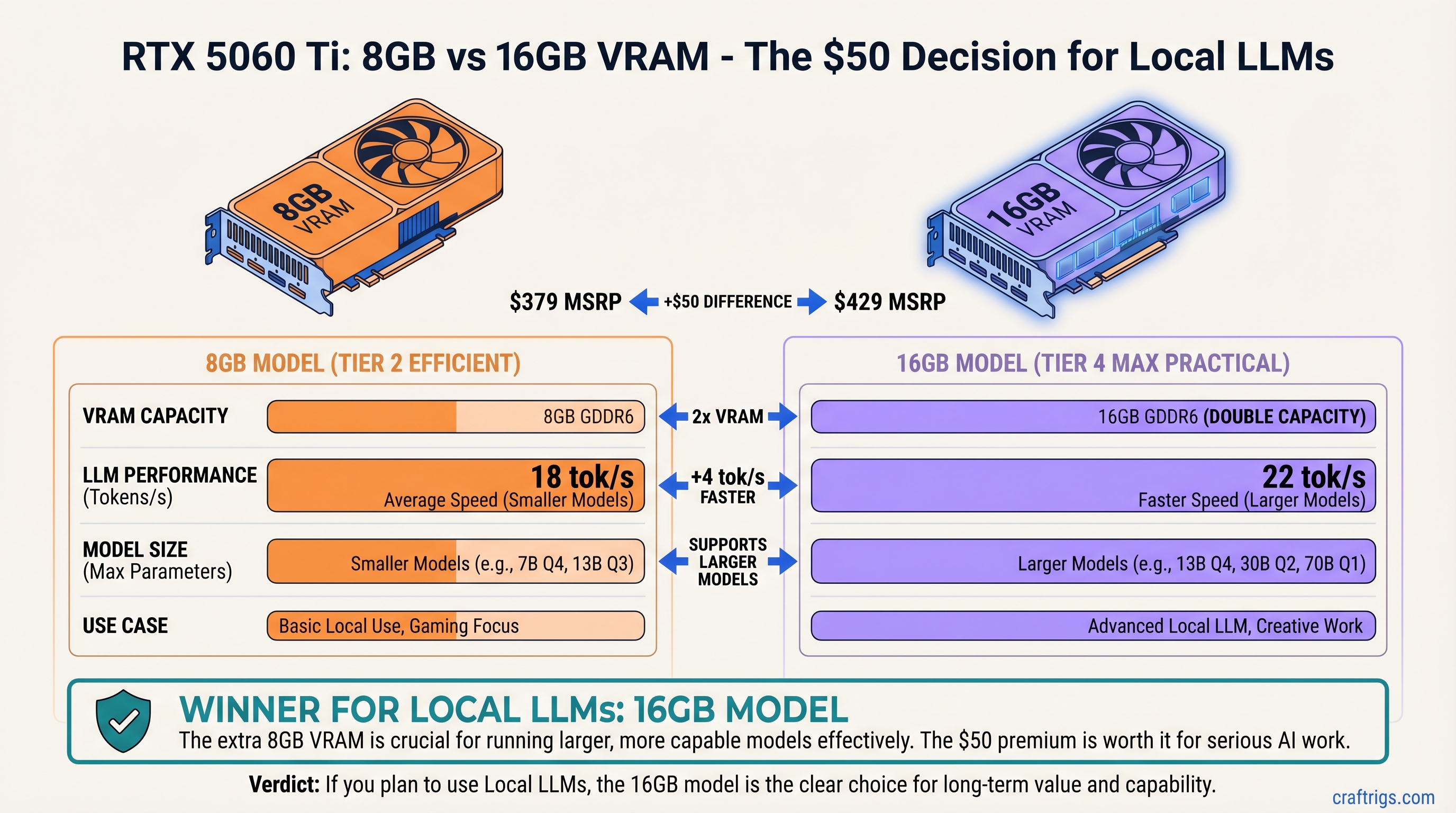
RTX 5060 Ti 16 GB wins the 27B dense race: $499 vs $589, 22–28 vs 6–10 tok/s on Qwen 3.6 Q4_K_M, 3.5× better efficiency. VRAM beats compute. Choose by actual workload.
Apr 30, 2026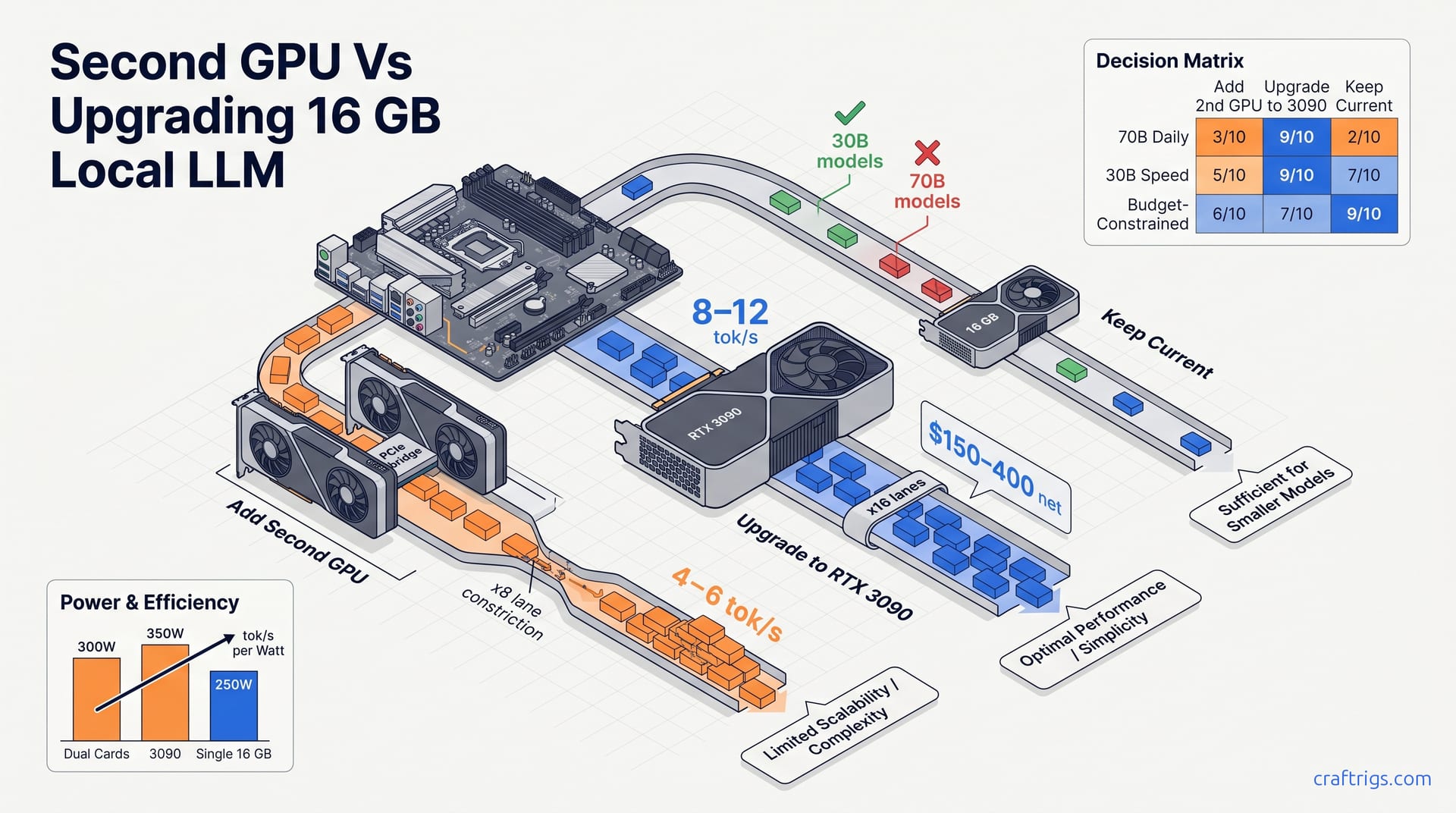
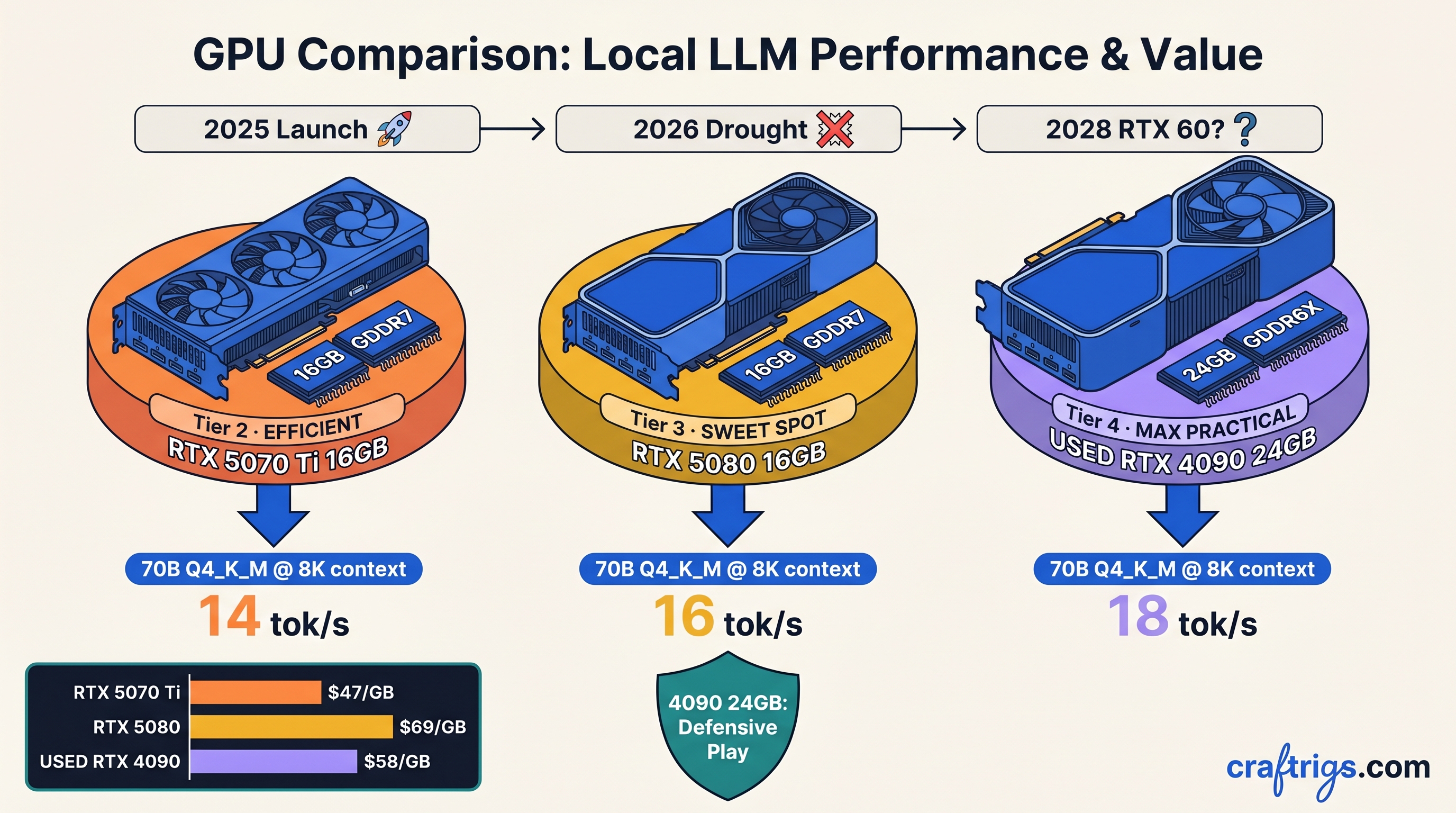
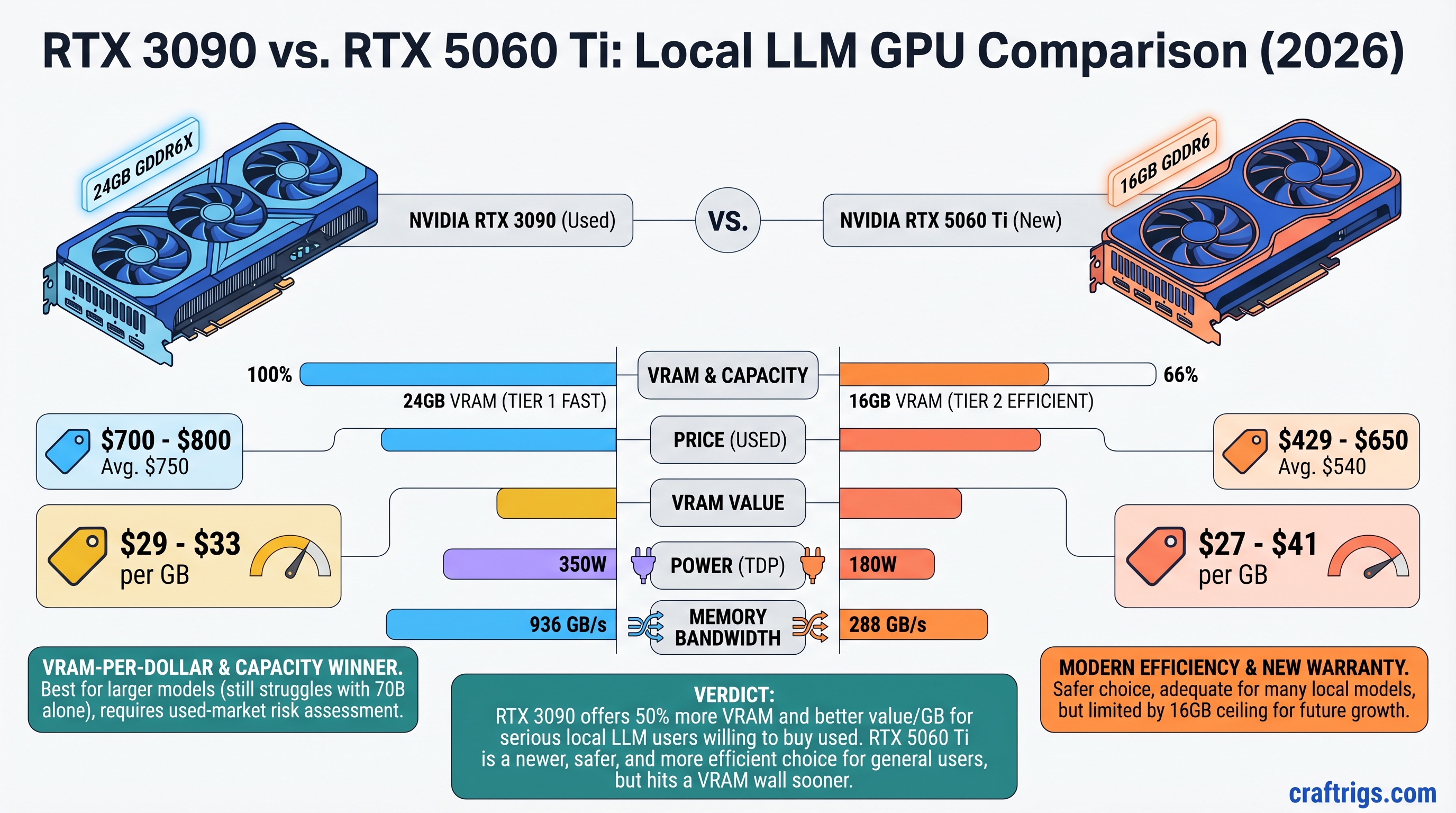
16 GB GPUs choke on 70B models—dual cards hit 4–6 tok/s with PCIe overhead, while a used RTX 3090 hits 8–12 tok/s for $150–400 net. Match your setup to the right upgrade path, not the r/LocalLLaMA hype.
Apr 30, 2026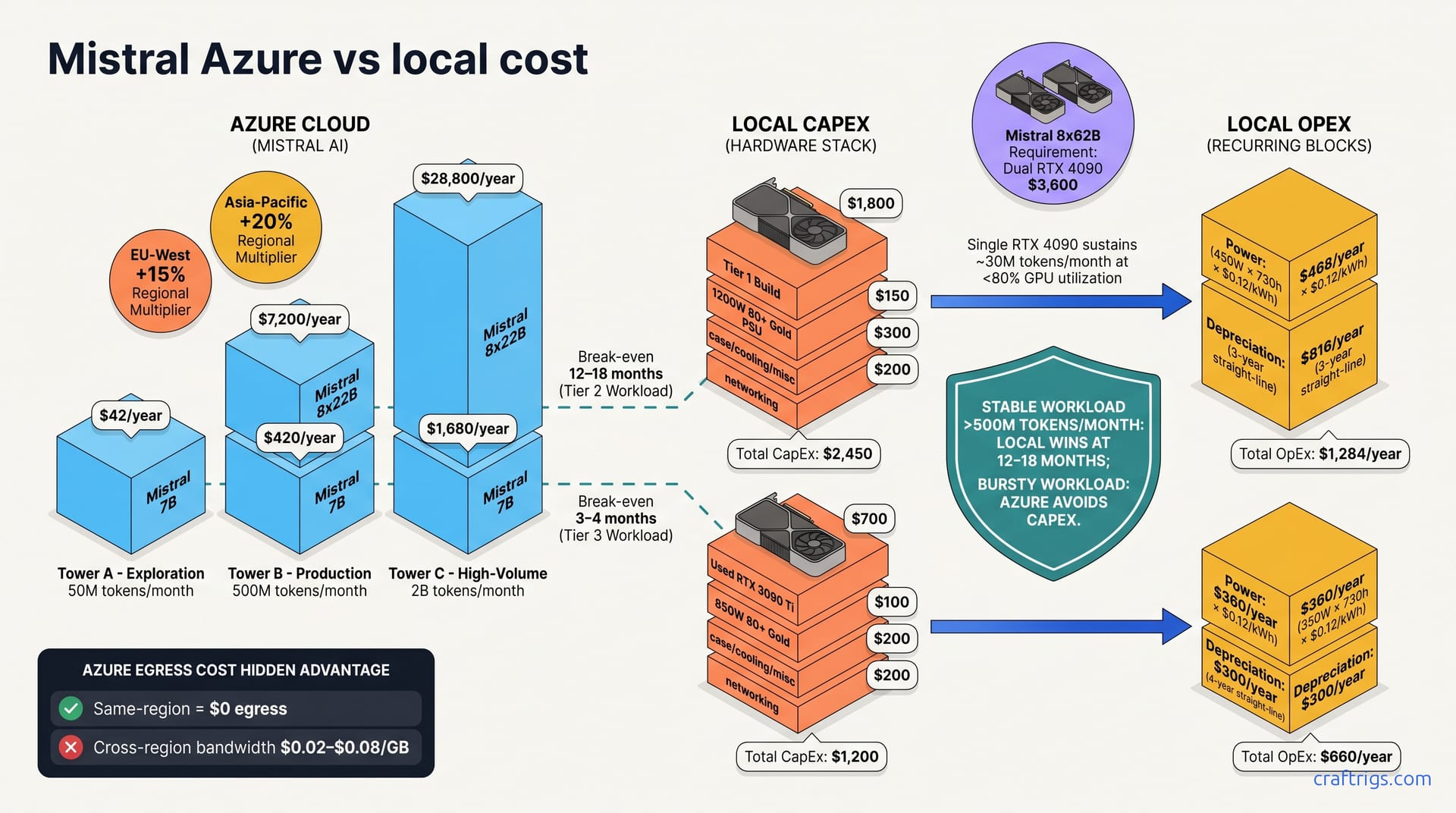
Compare Azure-Mistral per-token pricing vs. self-hosted Mistral on RTX 4090. Break-even payback, TCO math, and when local inference beats the cloud.
Apr 27, 2026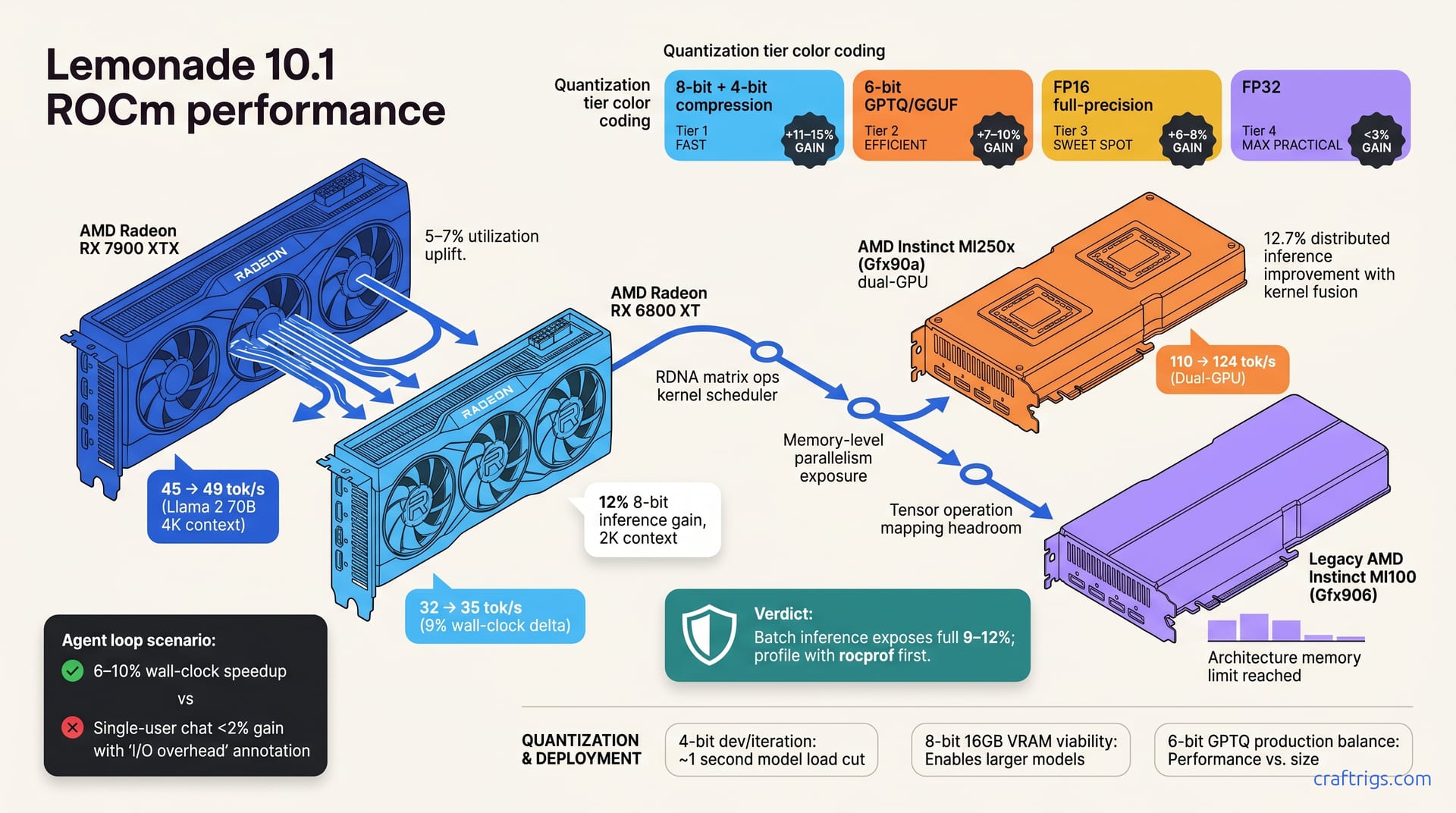
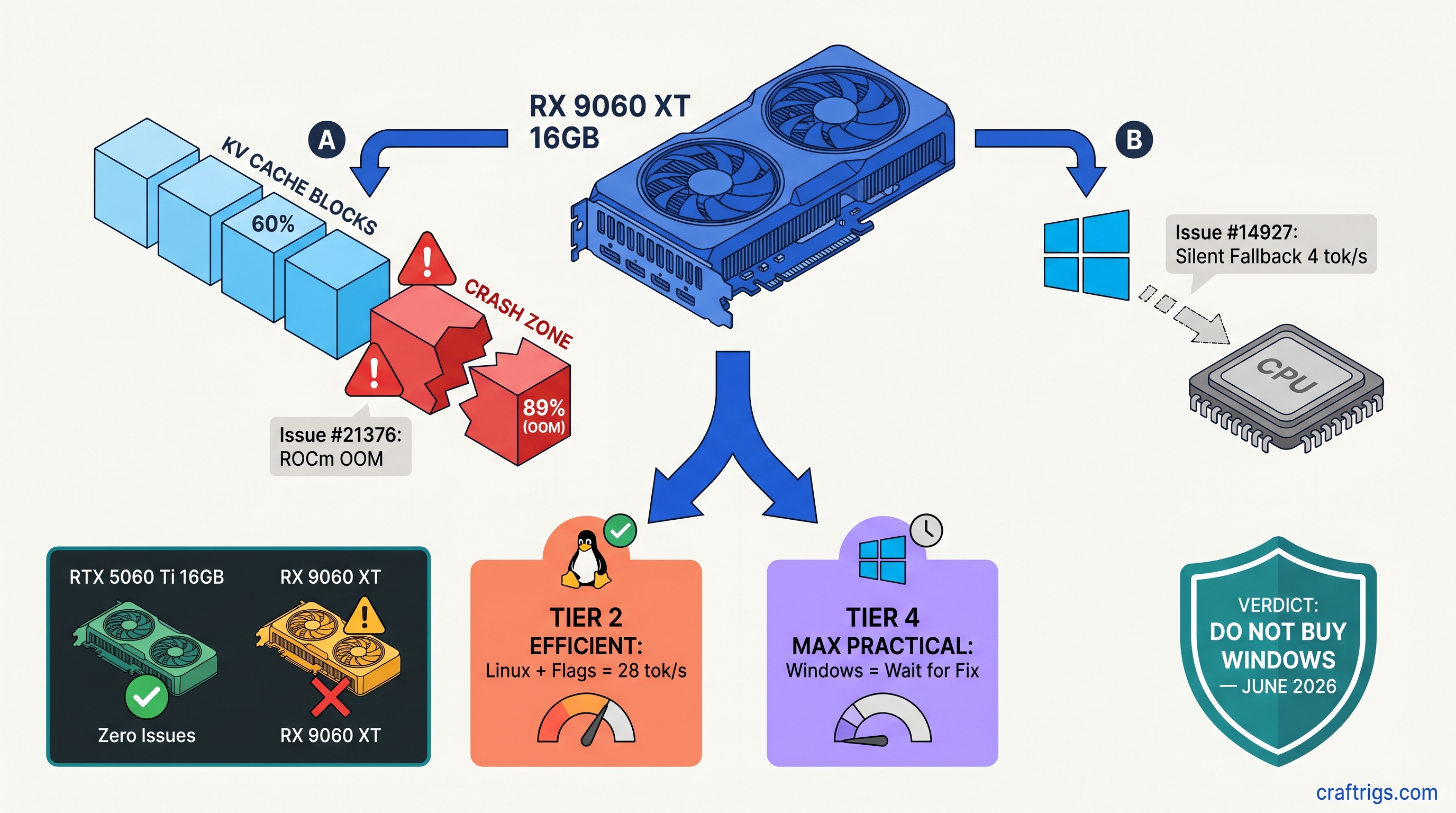
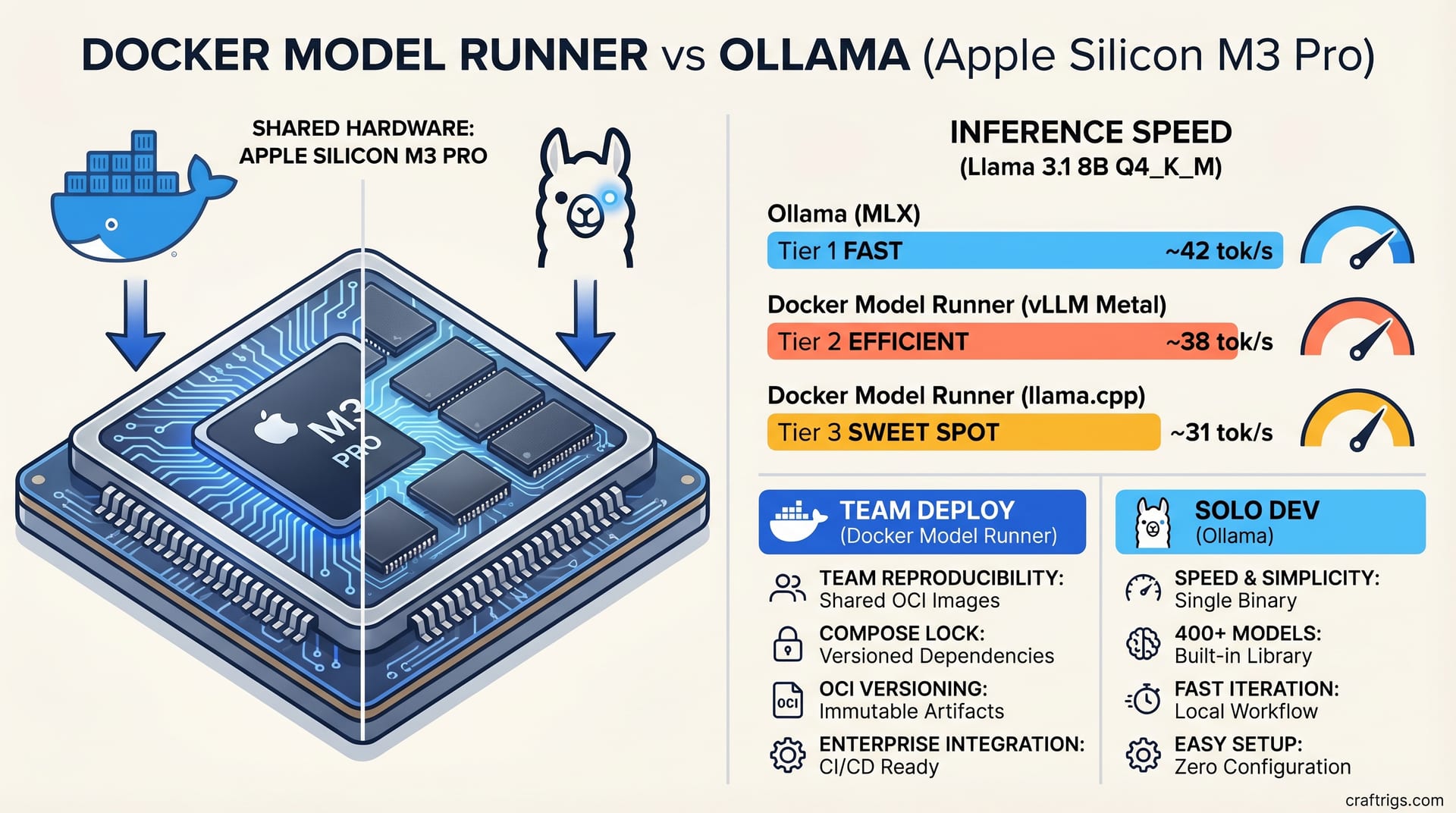
AMD Lemonade 10.1 delivers 8–15% LLM throughput gains on ROCm. Verified deltas by GPU, which configs benefit, and safe upgrade steps for your hardware.
Apr 27, 2026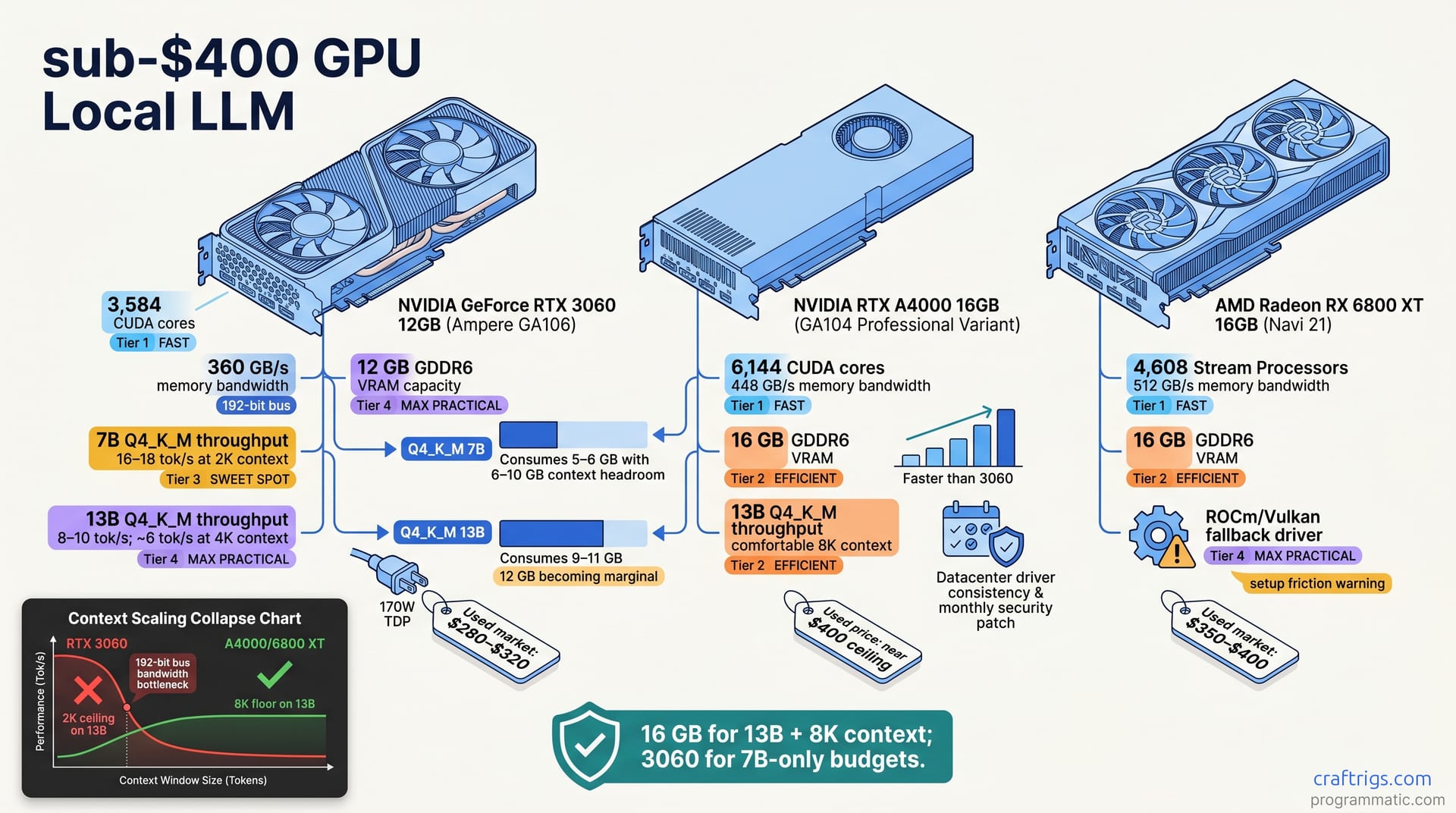
Can't pick a $400 GPU for 7B/13B LLMs? Compare 3060 12GB, A4000, used 6800 XT: real tok/s, VRAM headroom, driver stability, setup friction. Which wins your workload?
Apr 26, 2026
April's KV-cache quantization cracked the 8 GB ceiling—13B models now run comfortably. Benchmarks for RTX 3060/4070, quantization tiers, setup walkthrough.
Apr 26, 2026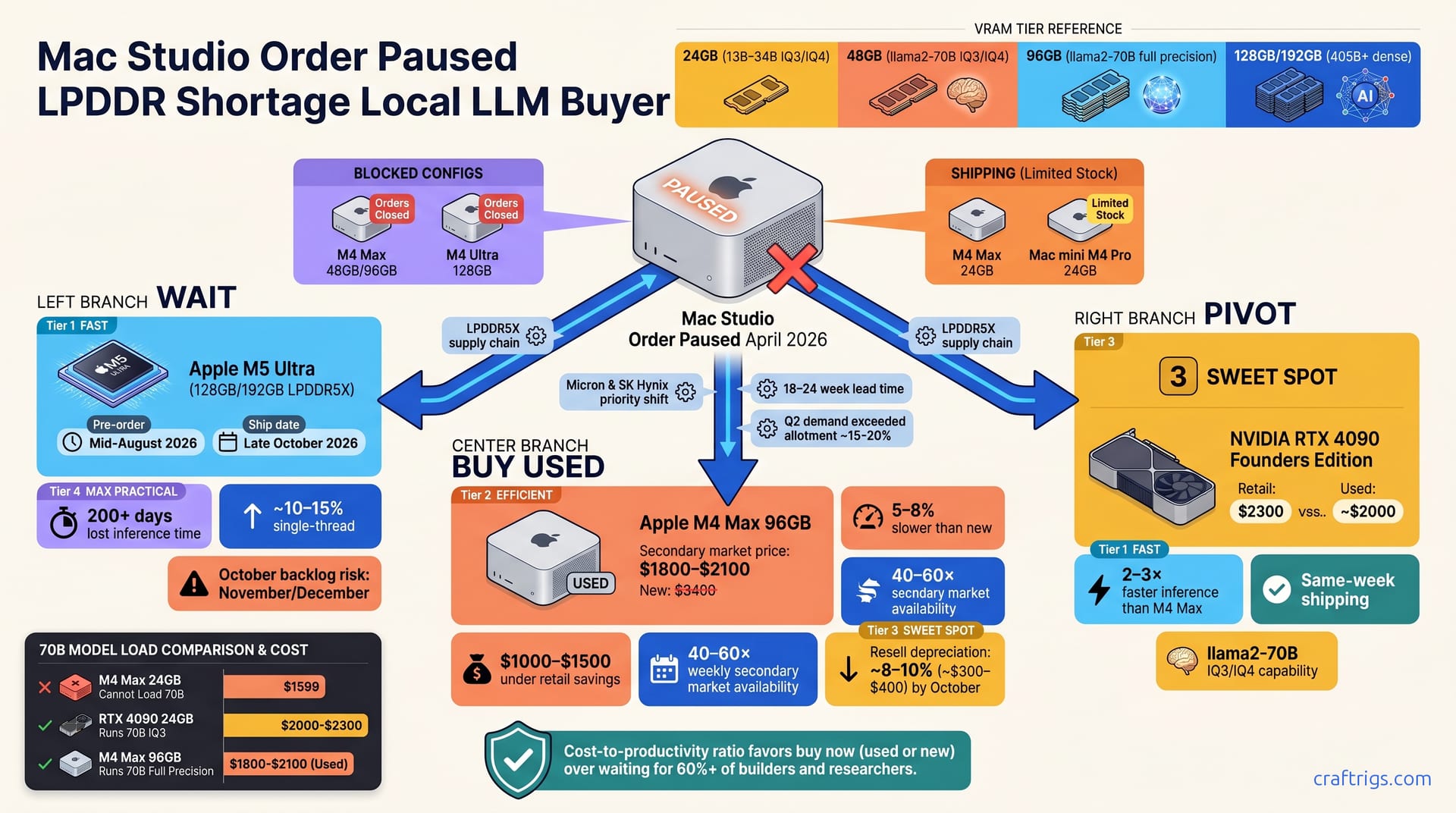
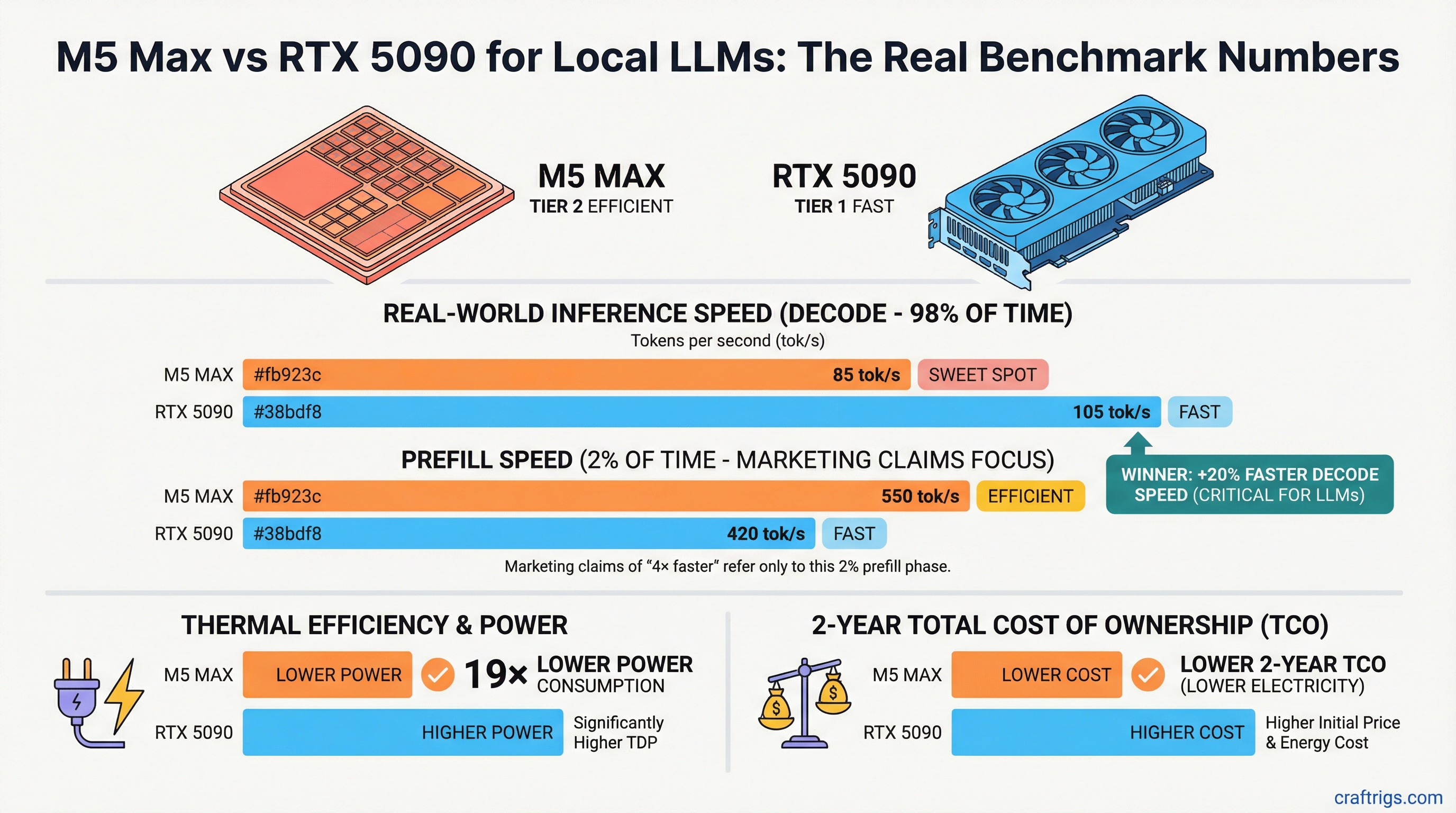
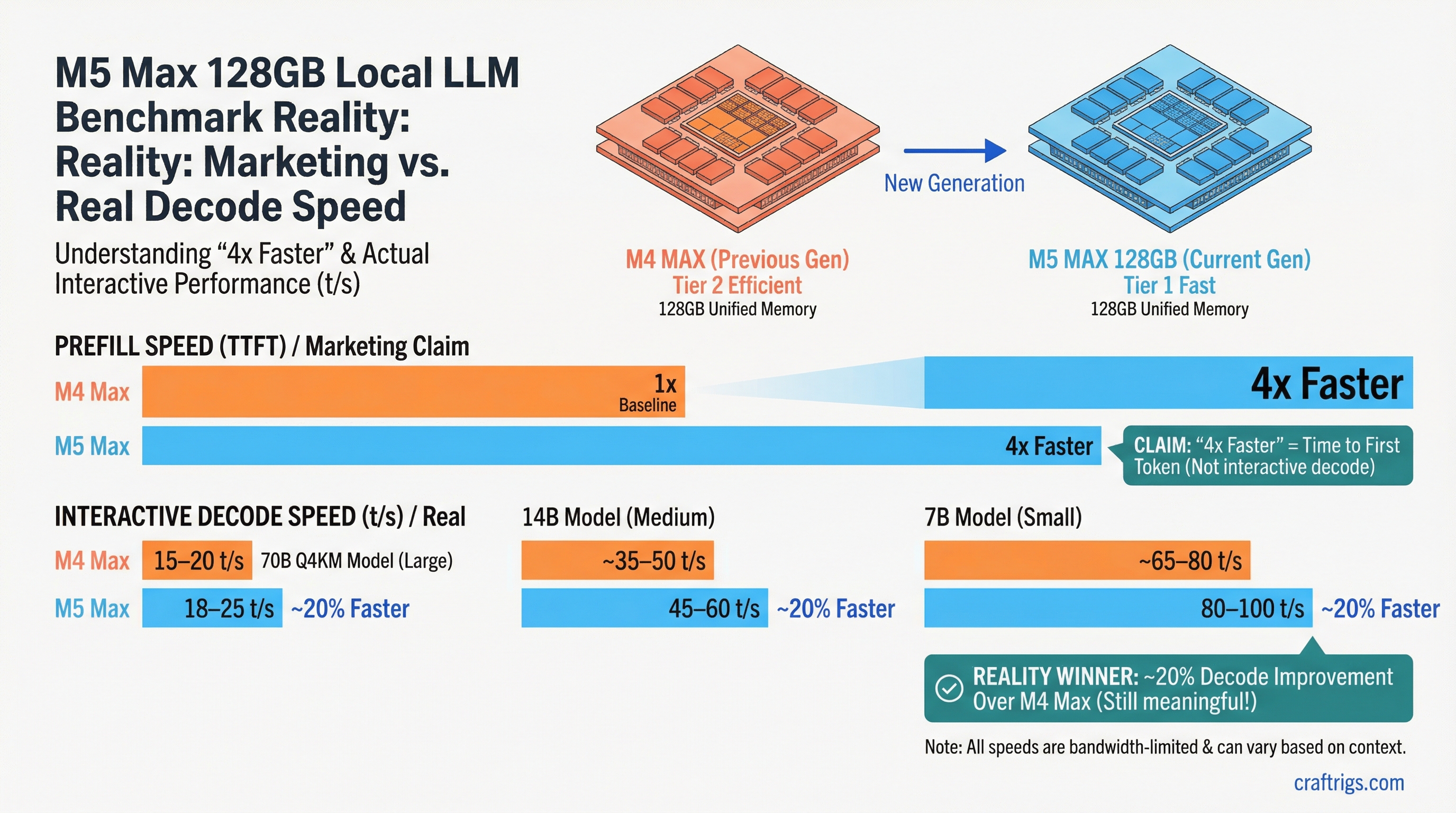
Apple paused Mac Studio orders; M5 delayed to October. Buy used M4 Ultra, wait, or pivot to RTX 4090? We compare speed, cost, resale, and help you pick the move that saves months of inference time.
Apr 26, 2026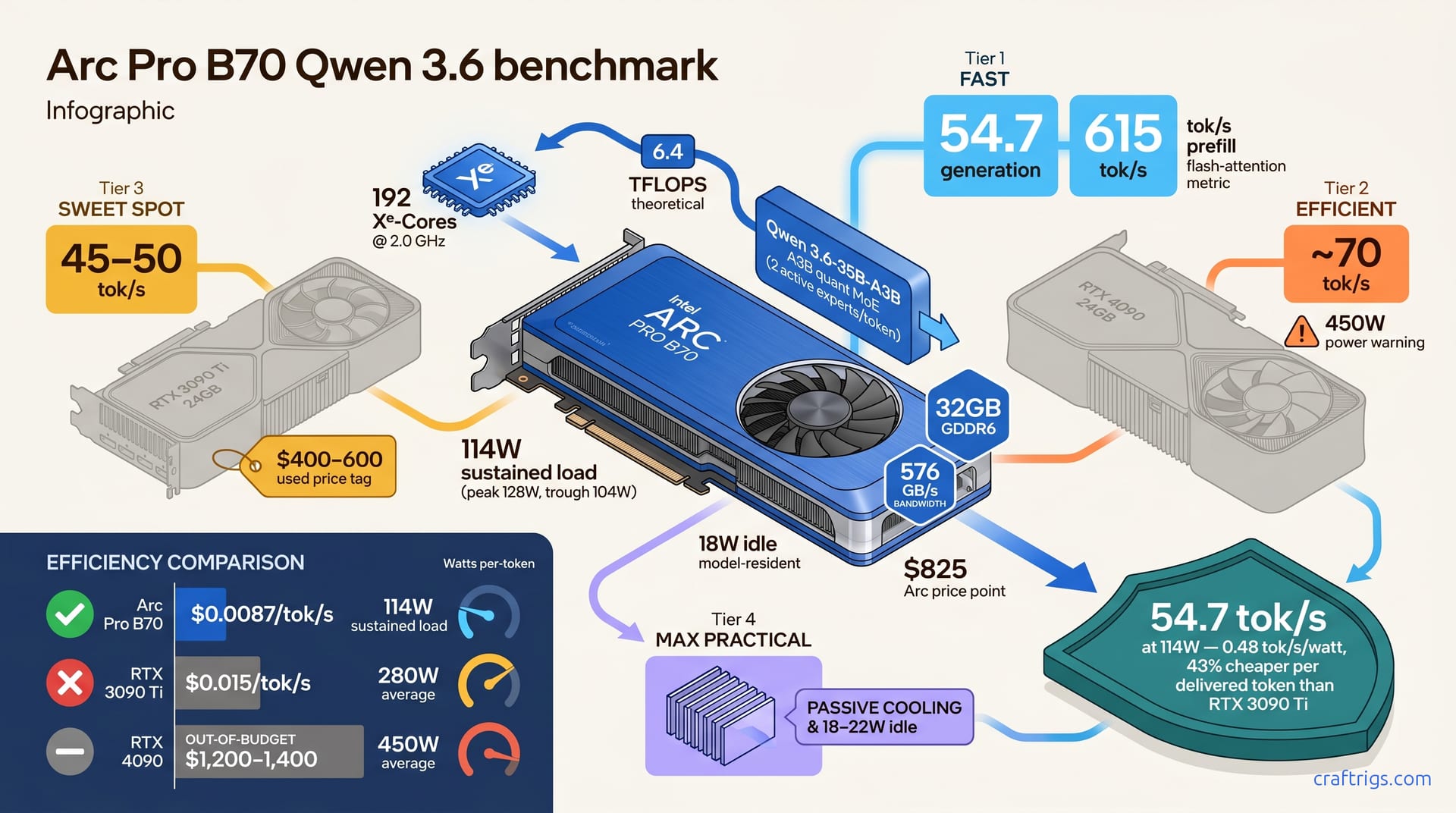
Intel Arc Pro B70 with Qwen 3.6-35B achieves 54.7 tok/s generation and 615 tok/s prompts at 114W. Production SYCL benchmark. Compare power efficiency vs. RTX 3090 Ti. Build guide under $1,200.
Apr 26, 2026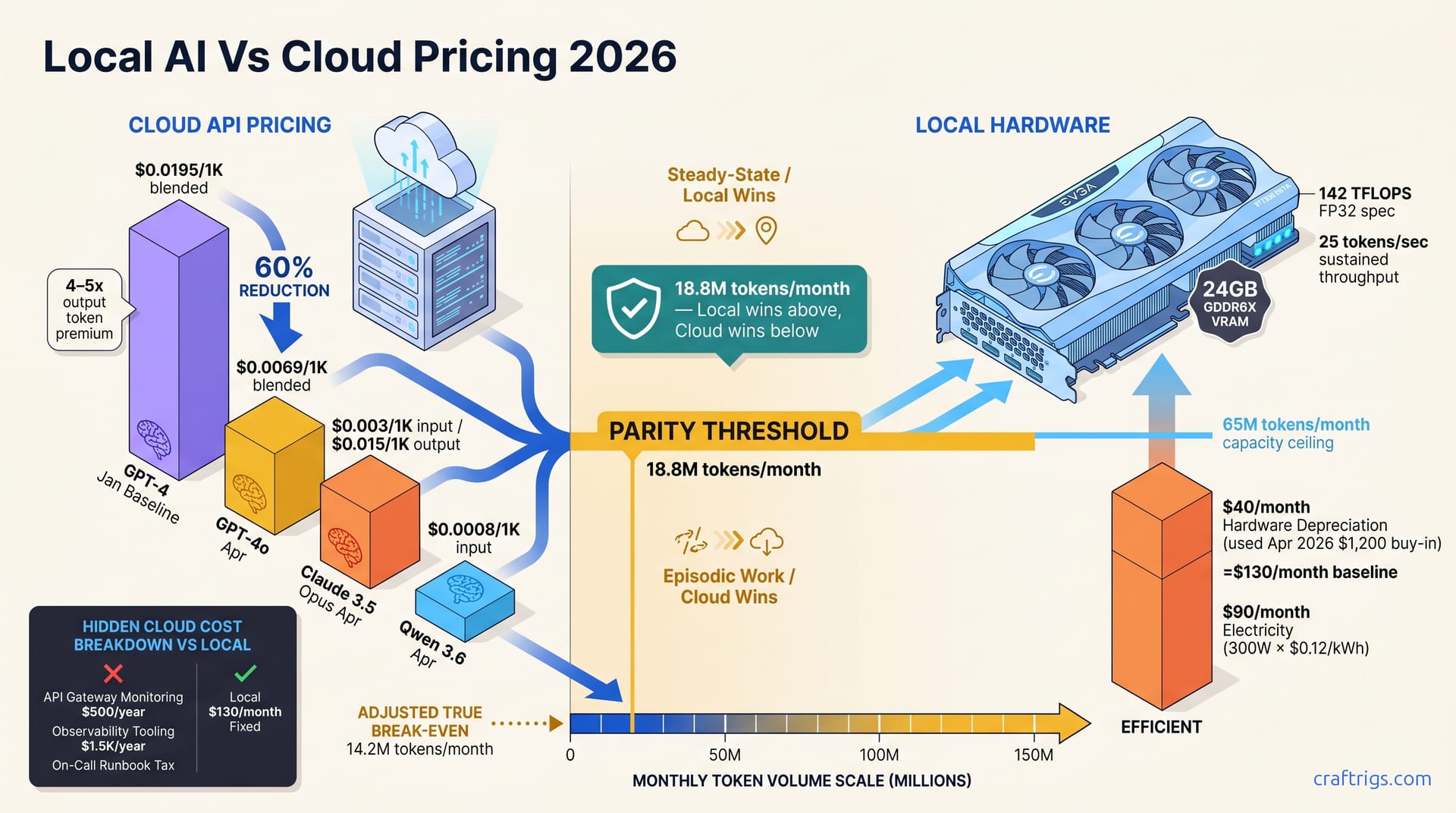
OpenAI, Claude, and Qwen slashed API costs 50% in April 2026. But used 3090s still break even at 18.8M tokens/month. Recalculate your ROI—cloud for burst, local for production workloads.
Apr 26, 2026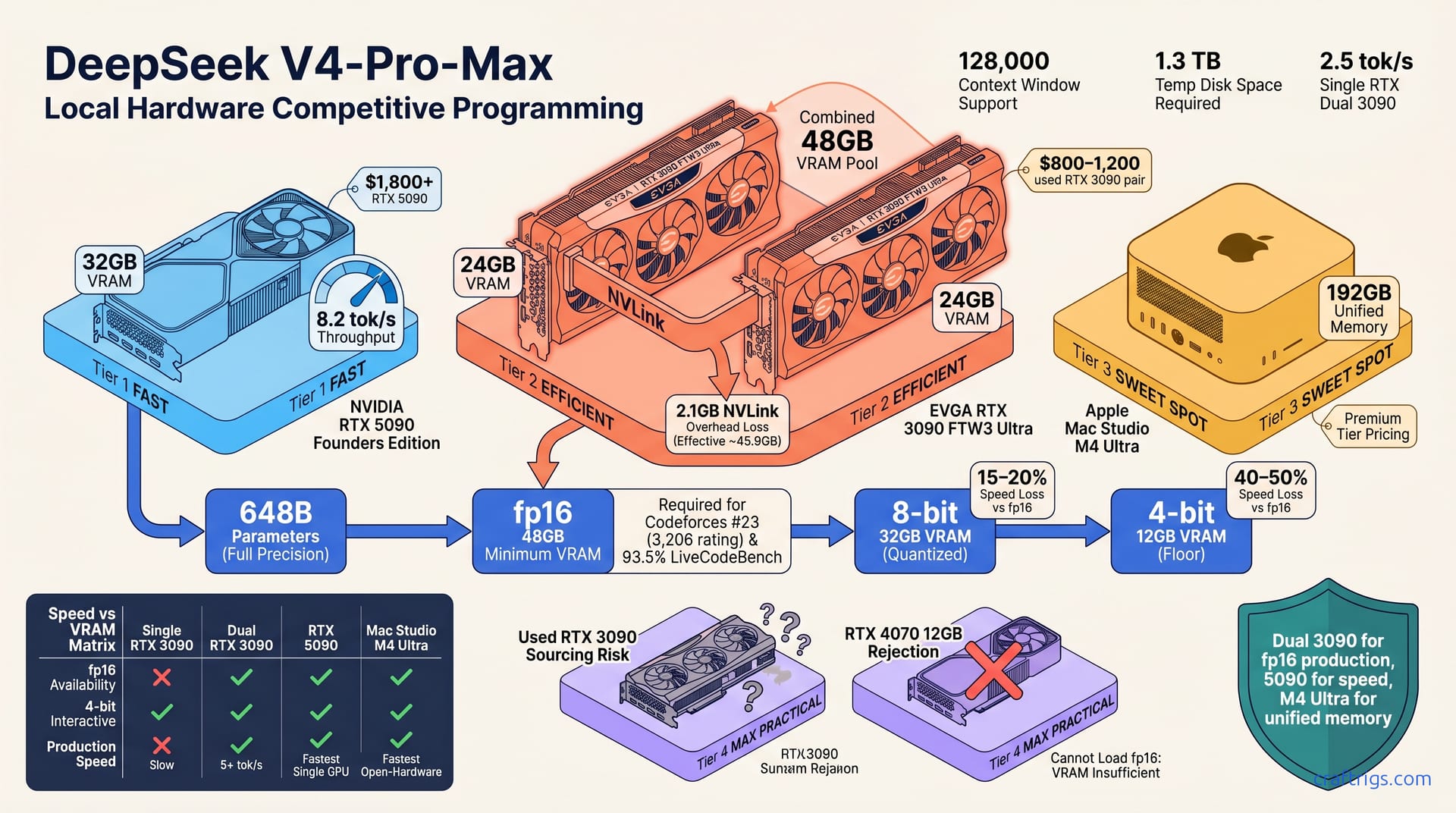
Open model ranks #23 on Codeforces. 93.5% on code benchmarks. RTX 3090 runs it locally; costs 97% less than cloud APIs. Hardware tiers and ROI math inside.
Apr 26, 2026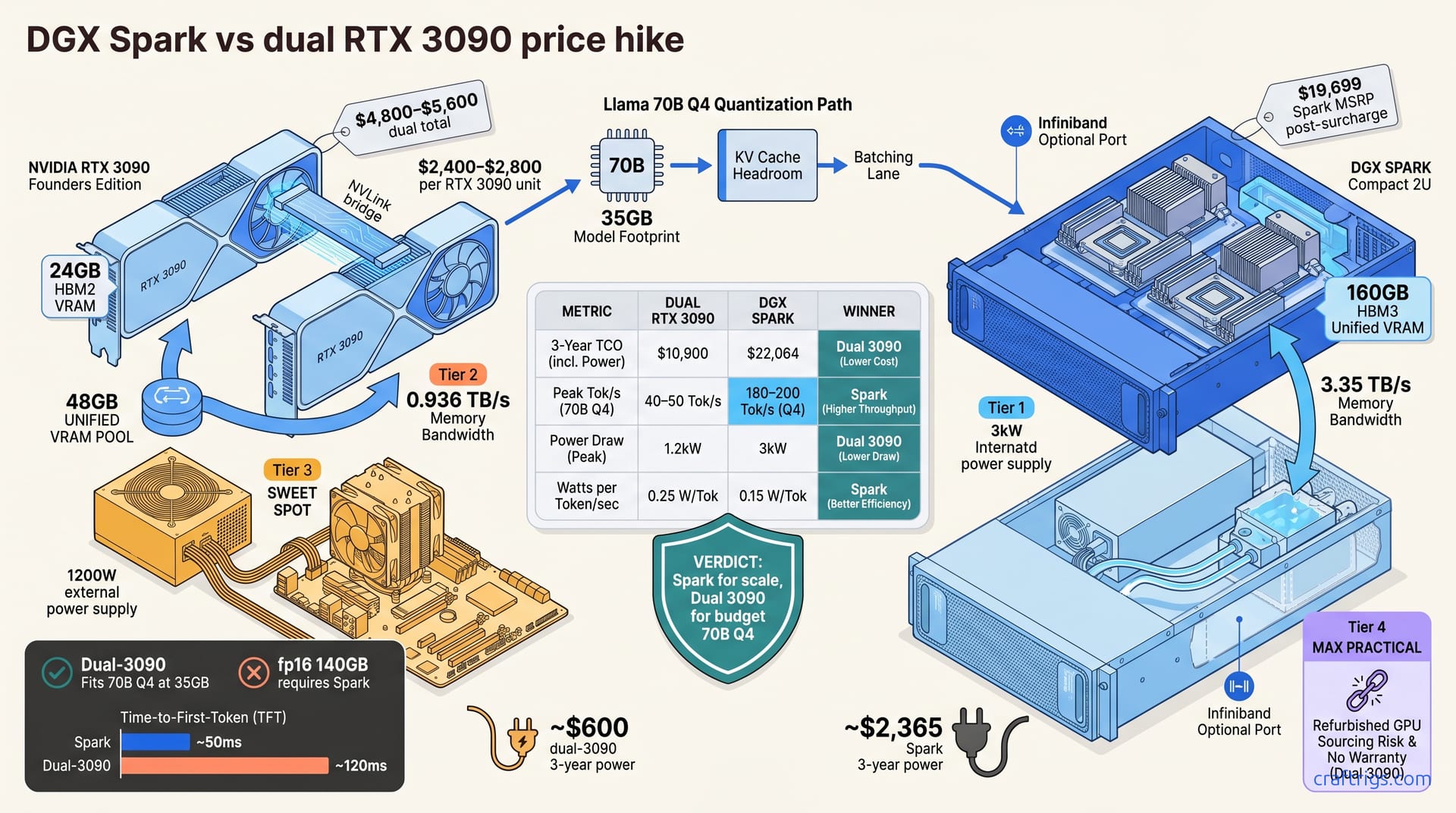
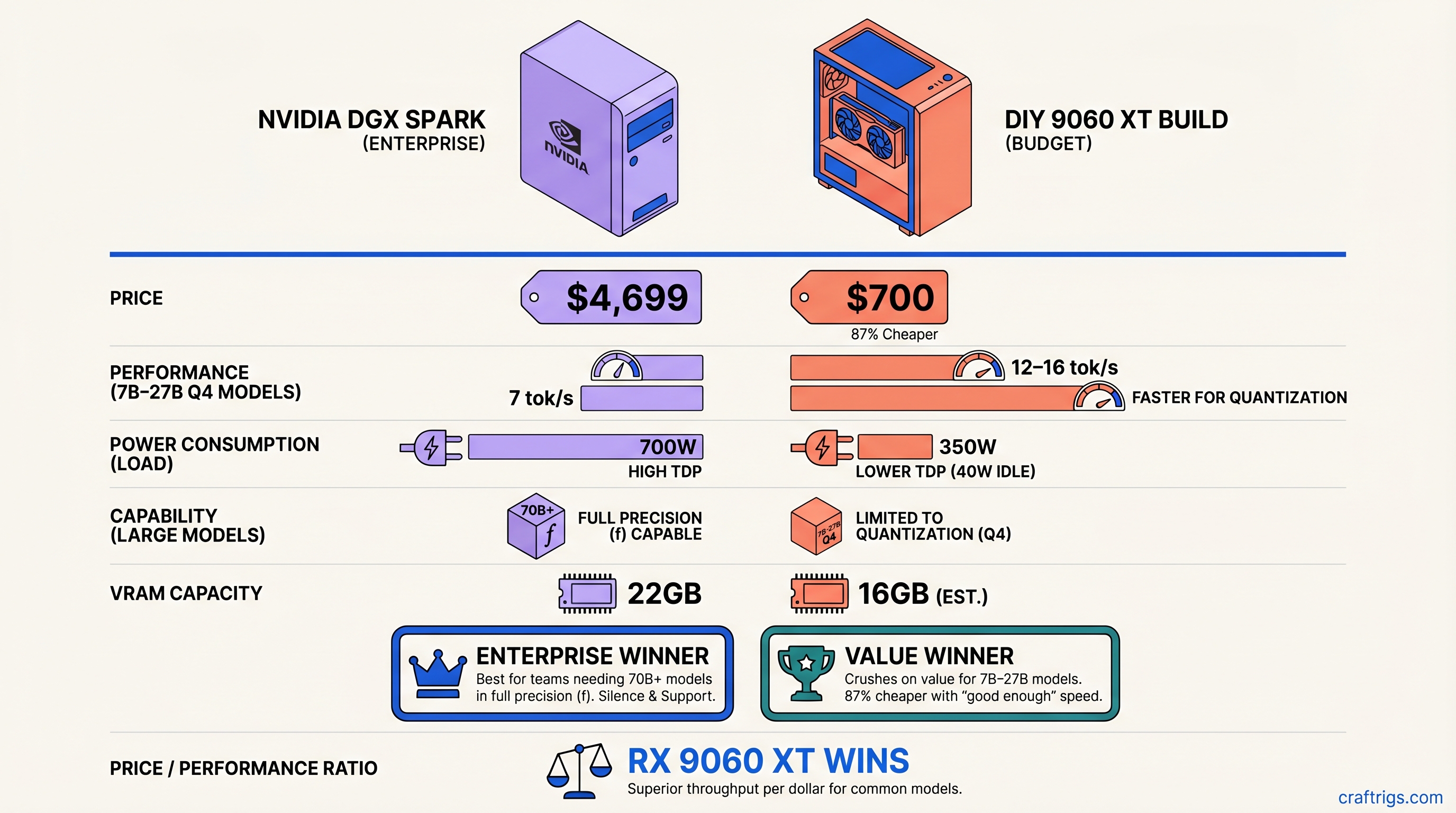
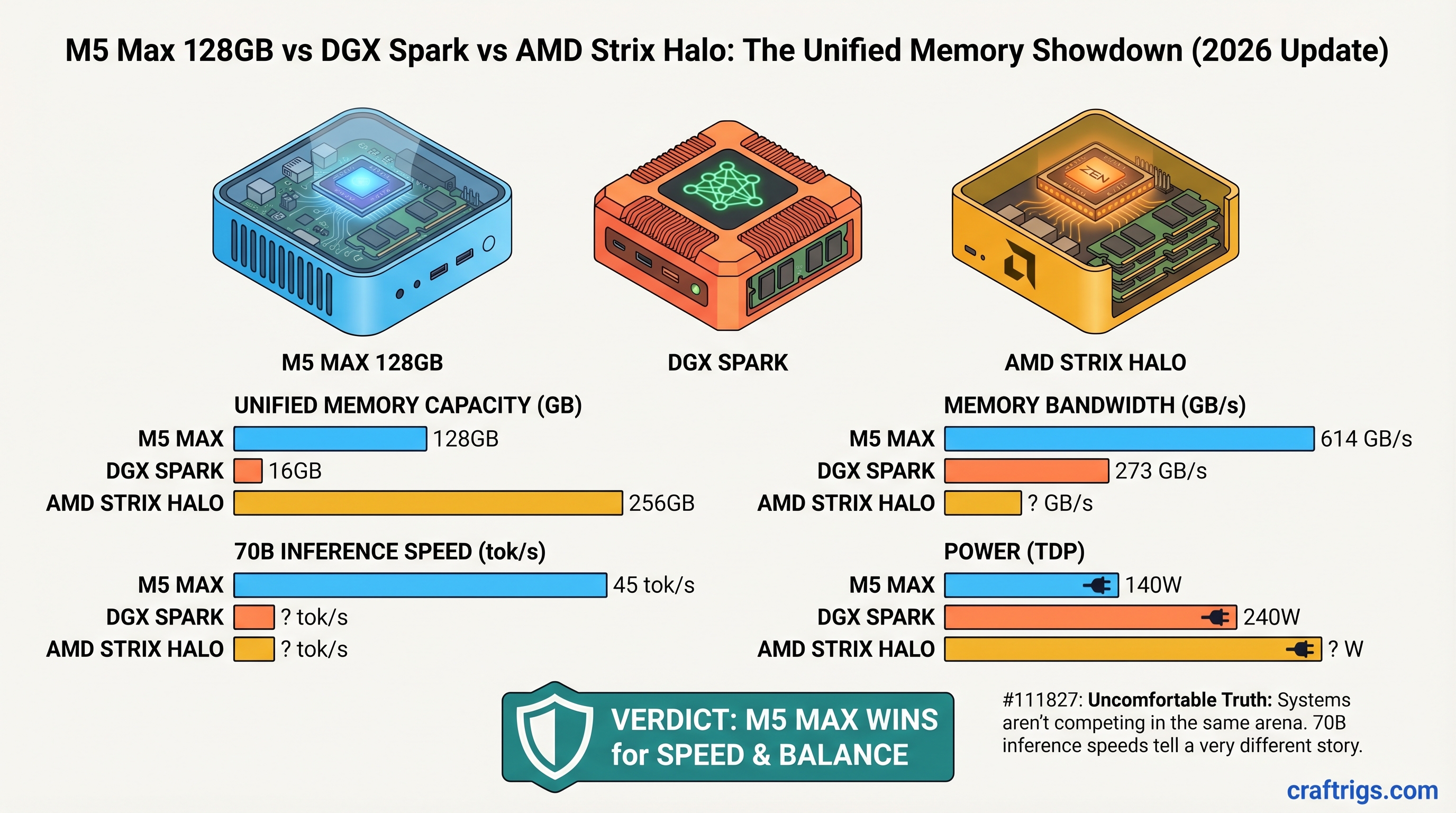
DGX Spark's $700 surcharge changes the dual-3090 vs. Spark calculus. See 3-year costs ($22k vs. $11k), throughput benchmarks, power consumption, and ROI for 70B inference.
Apr 26, 2026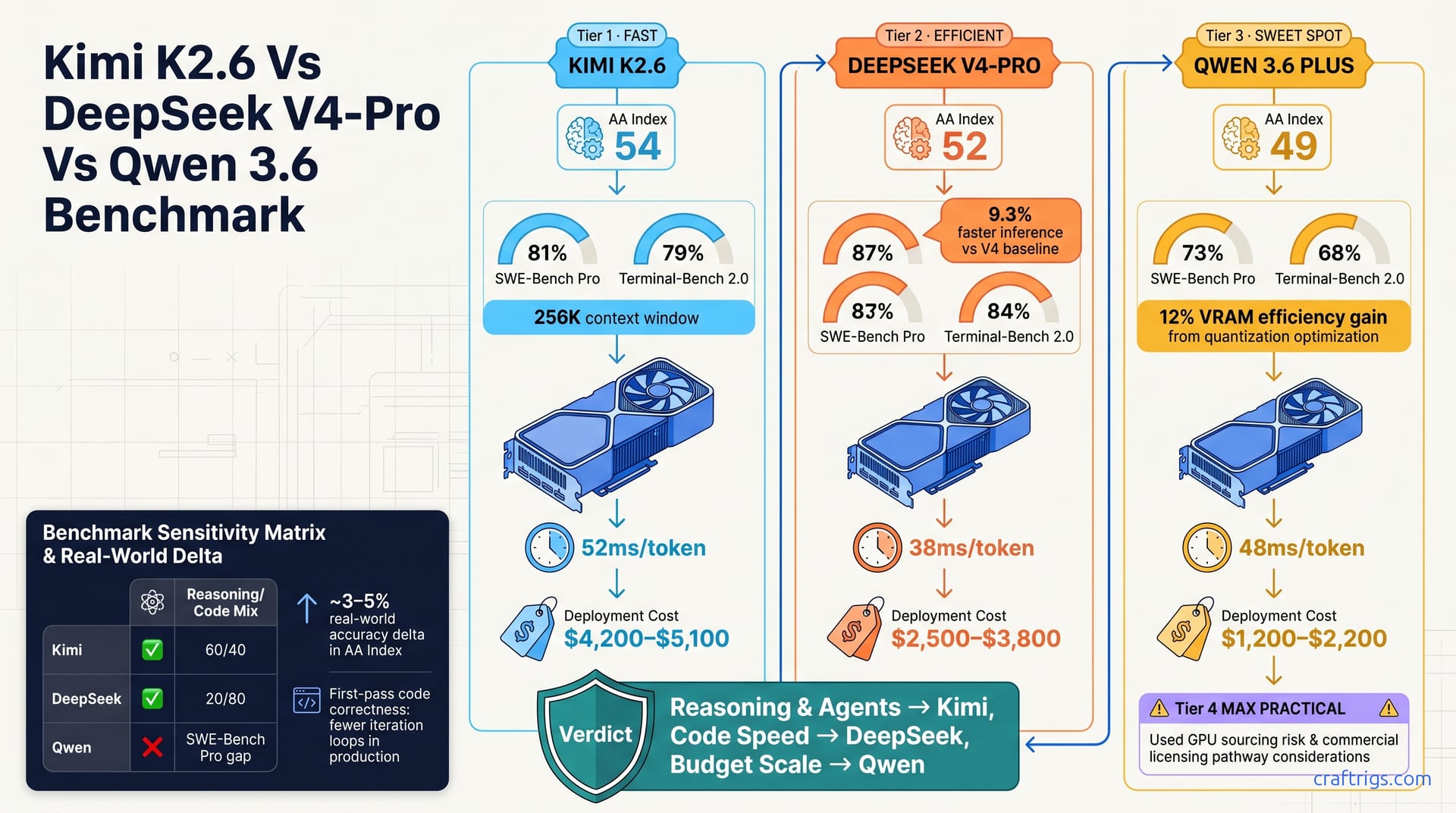
Kimi K2.6 vs DeepSeek V4-Pro vs Qwen 3.6 Plus: AA Index scores, SWE-Bench performance, hardware costs, and TCO. Pick the frontier model for your workload.
Apr 26, 2026
TurboQuant vs vLLM 2-bit KV on 24GB: 64K context, 38 tok/s vs. 128K, 18 tok/s. Which Llama 70B quantization actually wins? April 2026 head-to-head benchmark.
Apr 26, 2026



![ASUS RTX 5070 Ti Not Dead: Buy Now or Wait?: Our Recommendation [2026]](/images/asus-rtx-5070-ti-not-dead-buy-now-or-wait/asus-rtx-5070-ti-not-dead-buy-now-or-wait-diagram.jpg)


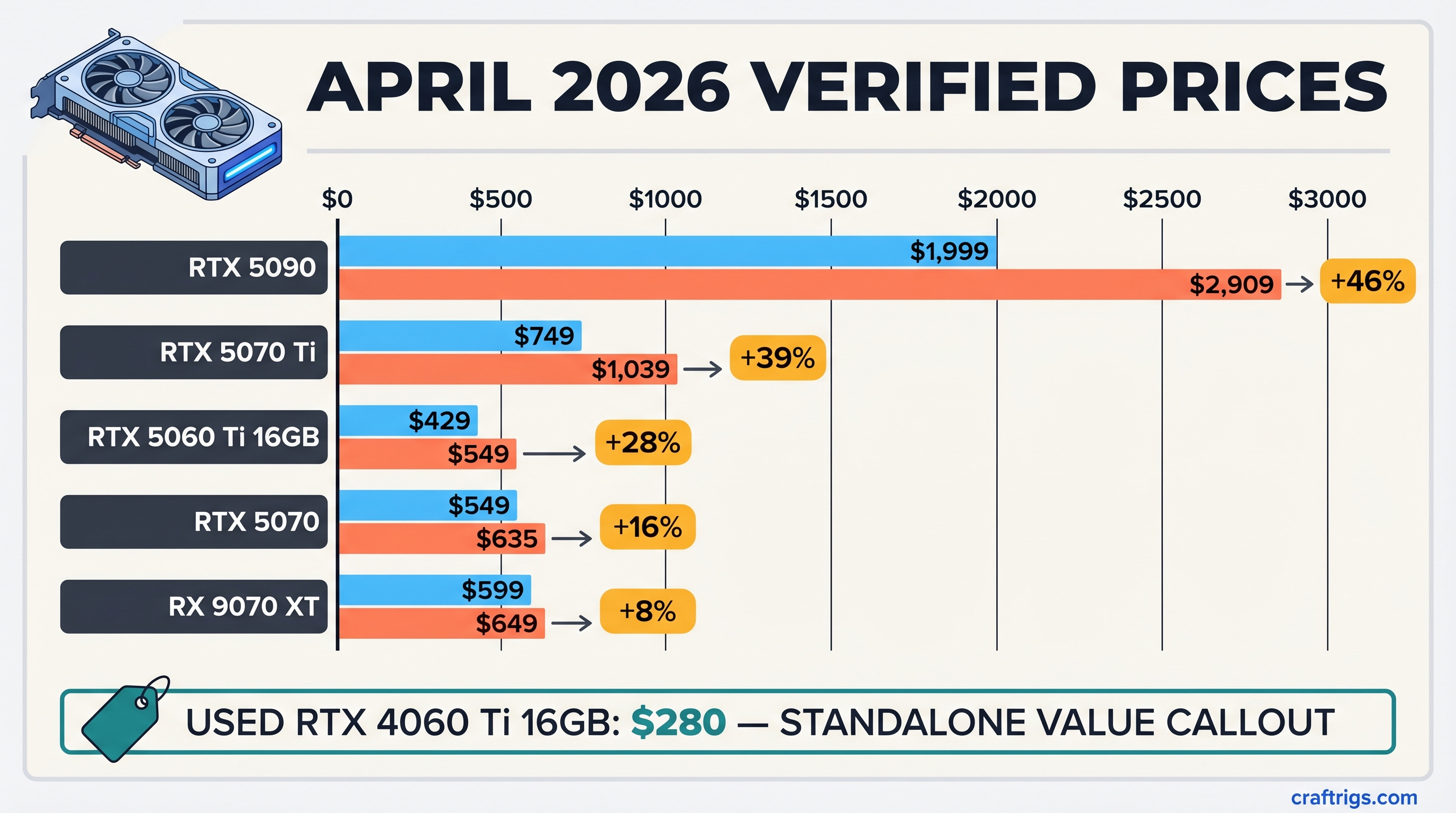
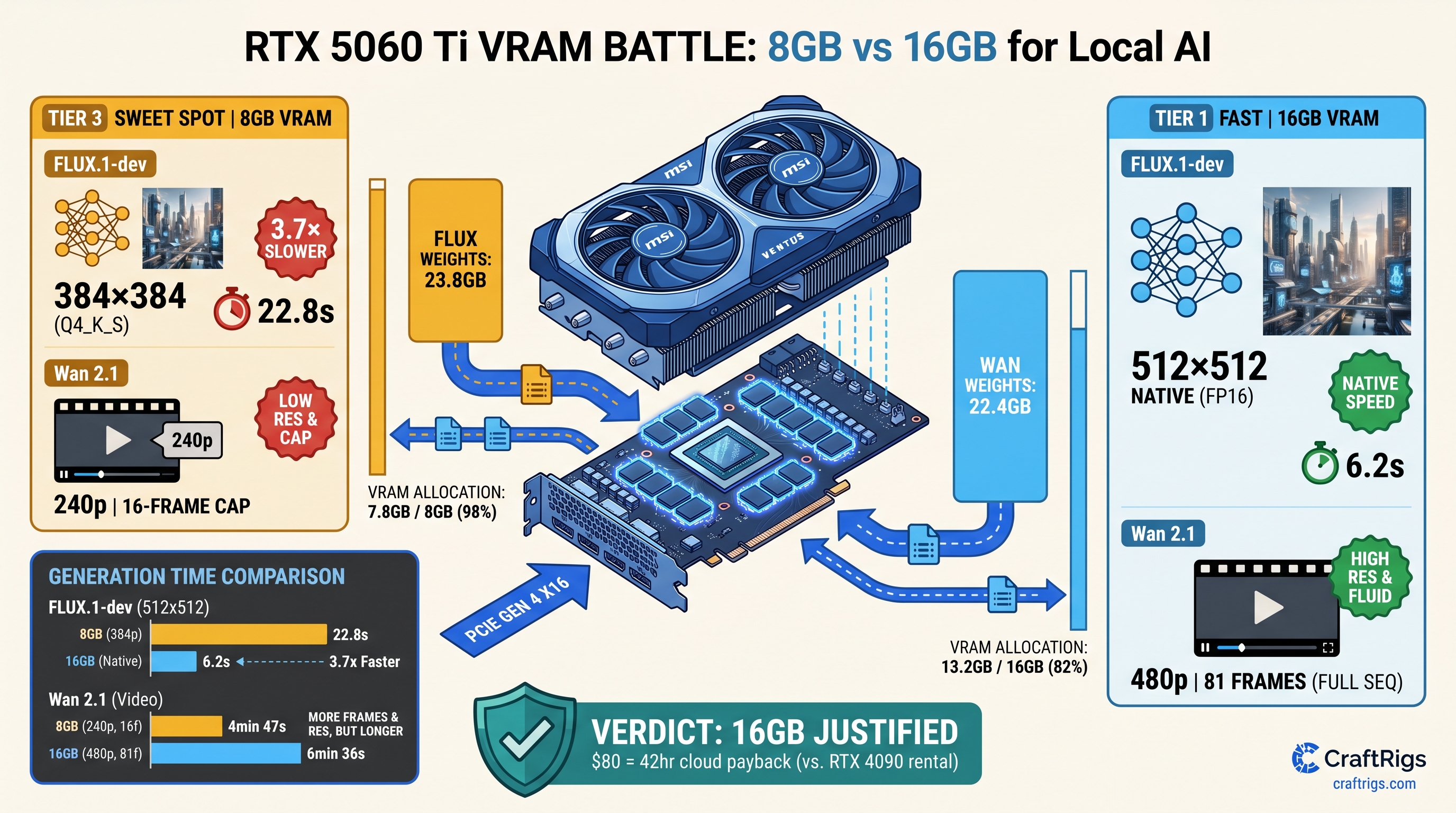
![RTX 5060 Ti 16GB Supply Crisis: Buy Now or Lose It [2026] — diagram](/images/rtx-5060-ti-16gb-supply-crisis/rtx-5060-ti-16gb-supply-crisis-diagram.png)


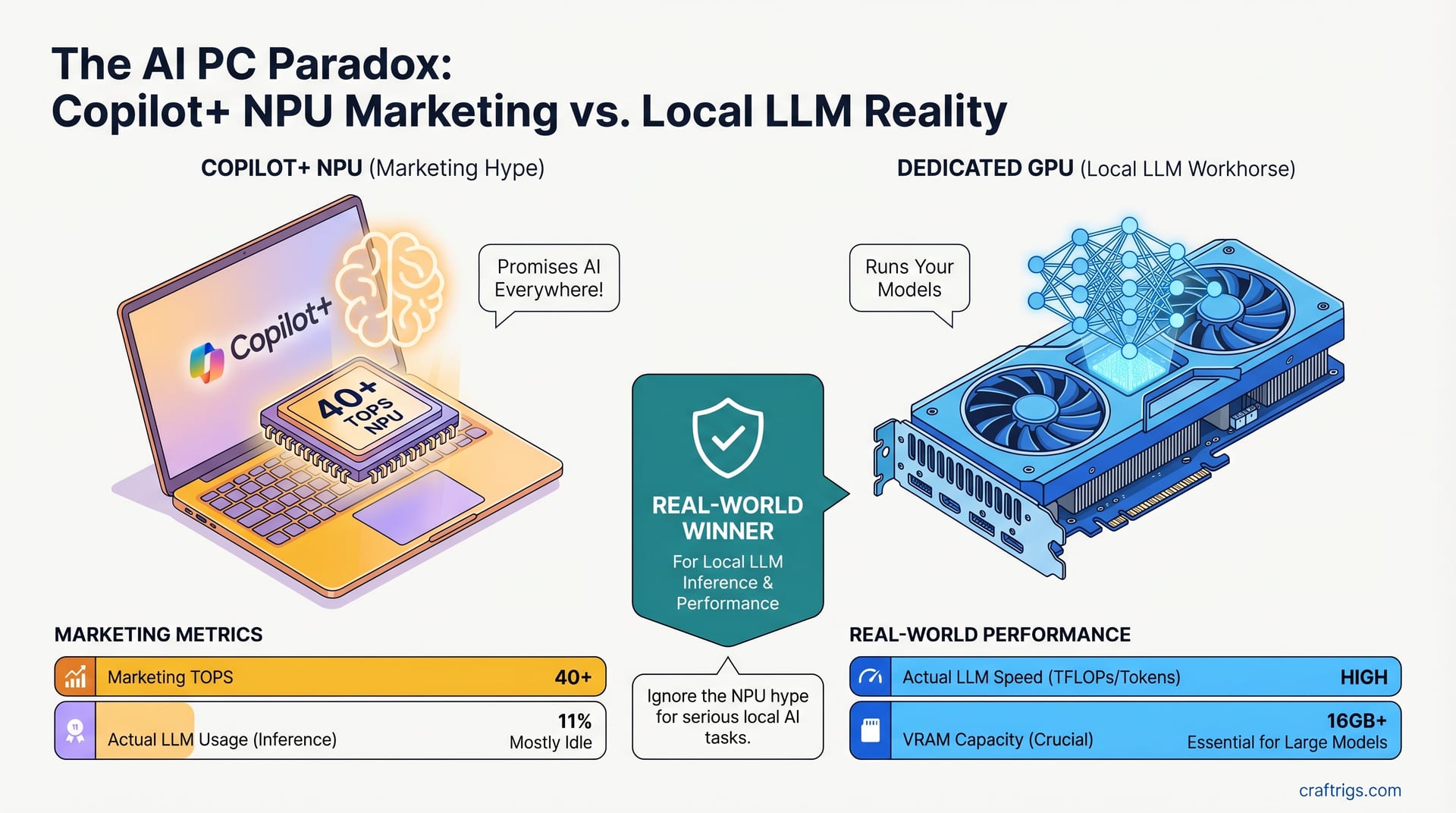


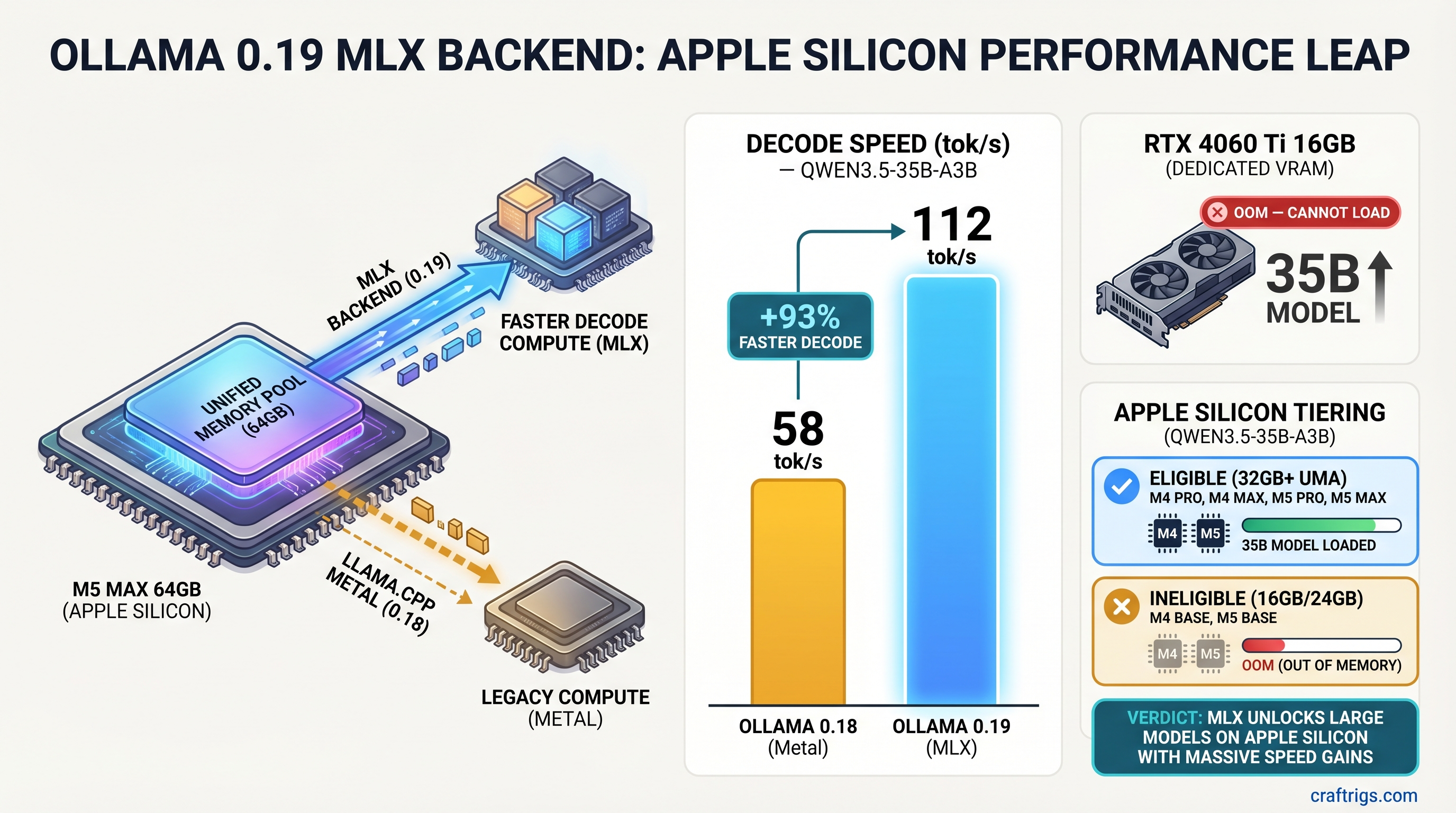
![GGUF vs GPTQ vs AWQ vs EXL2: Which Quantization Format to Use [2026 Tested] — comparison diagram](/images/gguf-vs-gptq-vs-awq-vs-exl2-quantization-guide/gguf-vs-gptq-vs-awq-vs-exl2-quantization-guide-diagram.jpg)





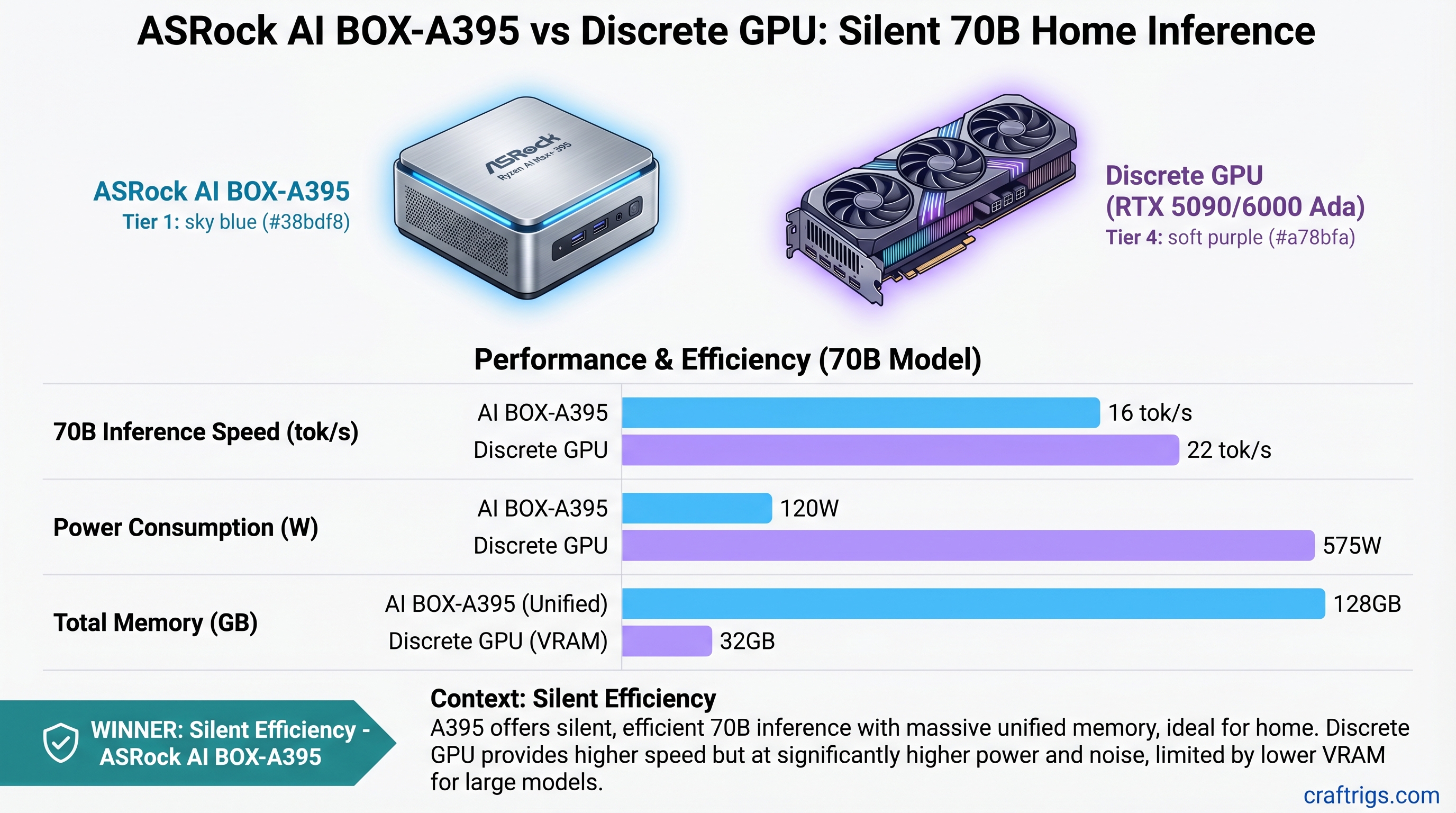
![vLLM vs Ollama vs llama.cpp vs TensorRT-LLM on RTX 5090: Which Inference Engine Wins [2026 Tested] — comparison diagram](/images/vllm-vs-ollama-vs-llama-cpp-vs-tensorrt-rtx-5090/vllm-vs-ollama-vs-llama-cpp-vs-tensorrt-rtx-5090-diagram.jpg)

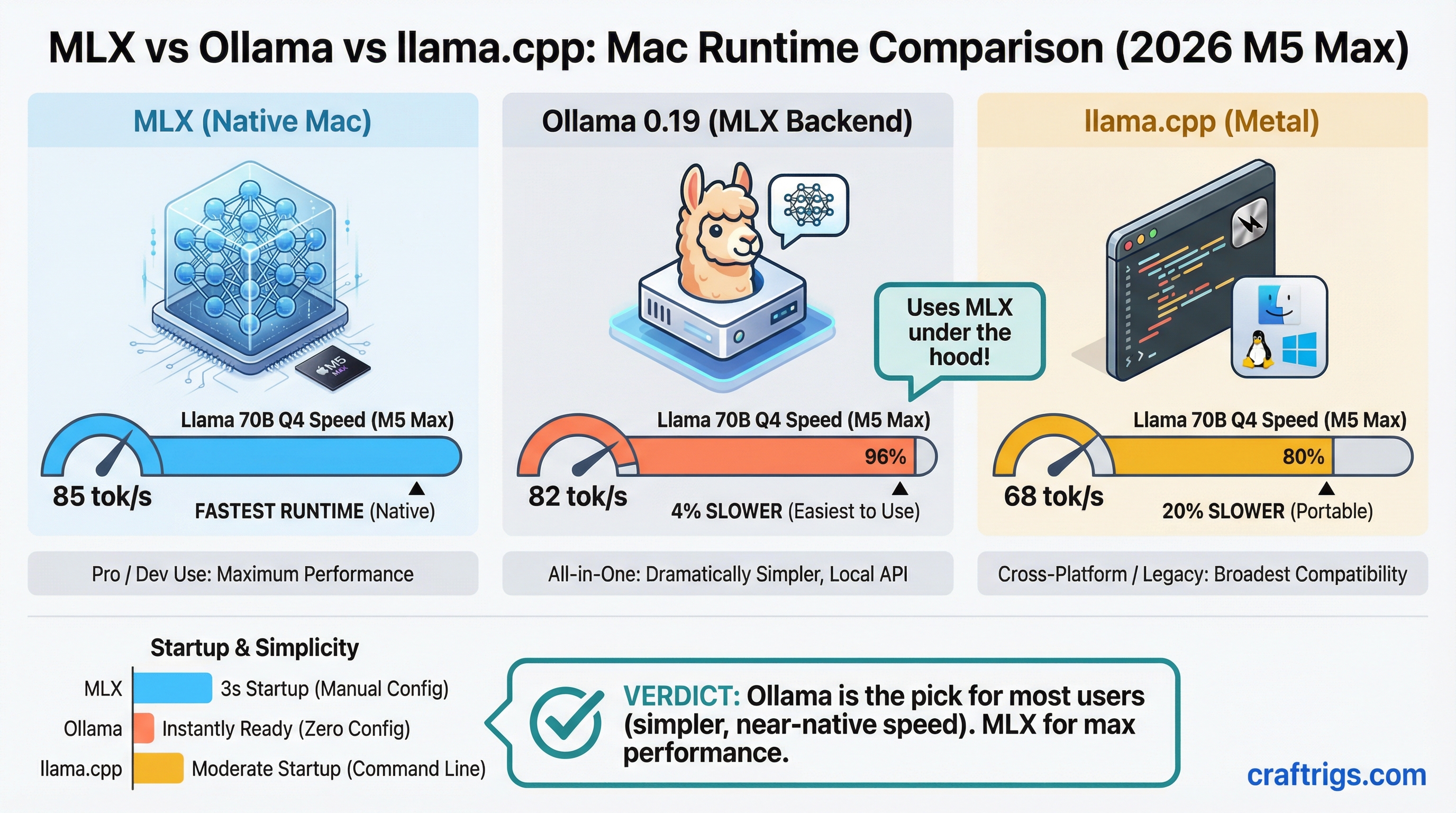

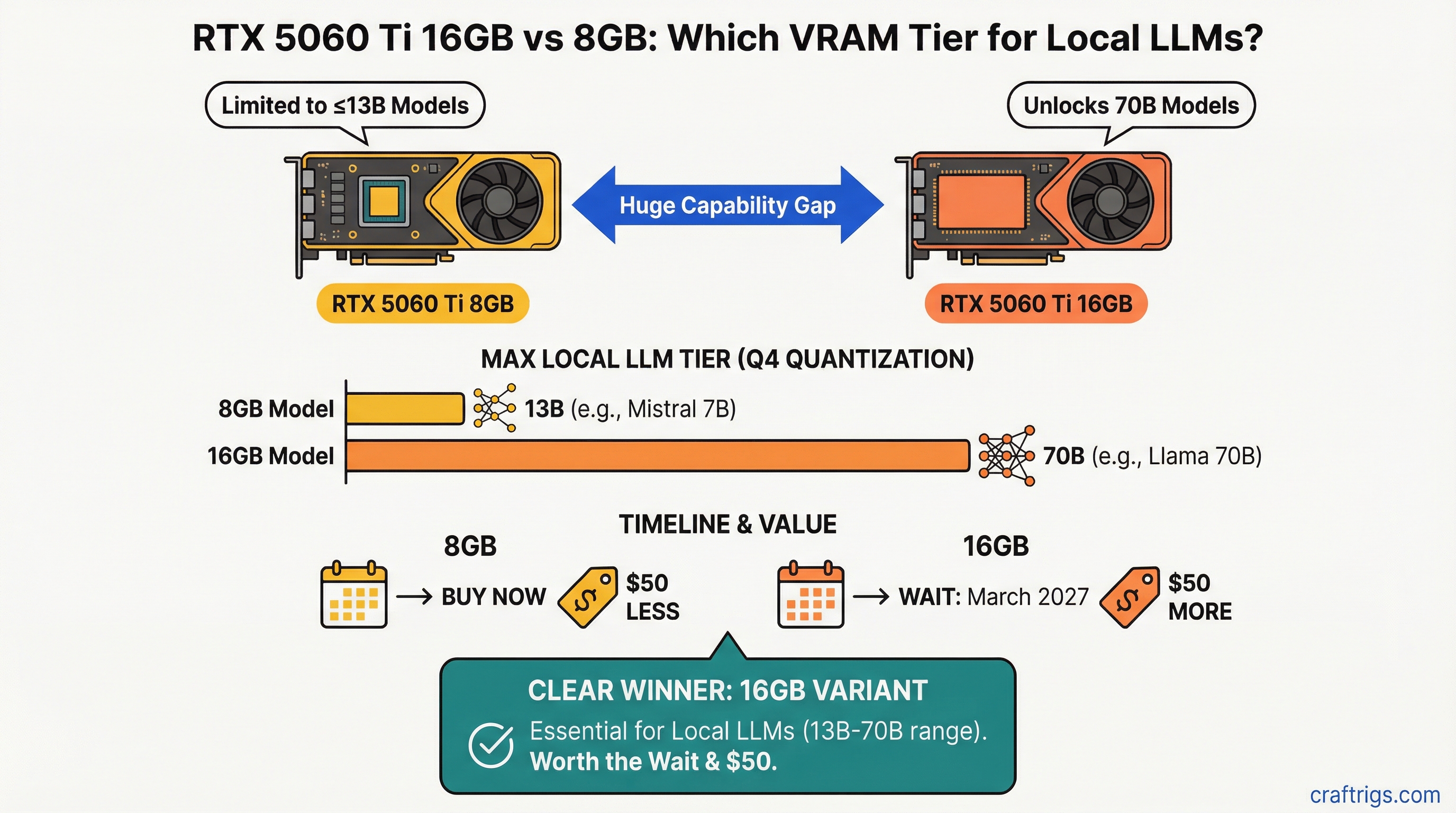



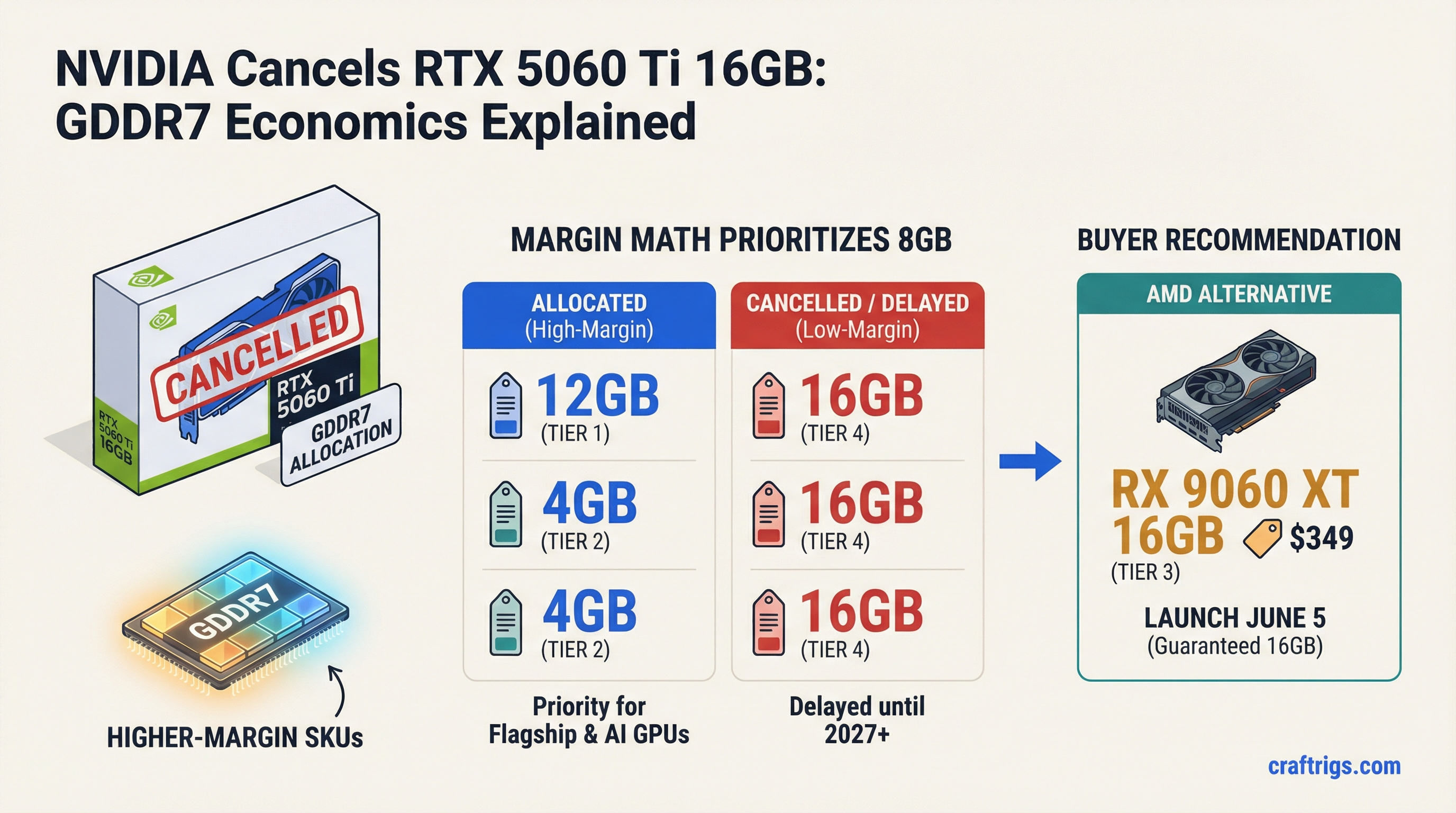

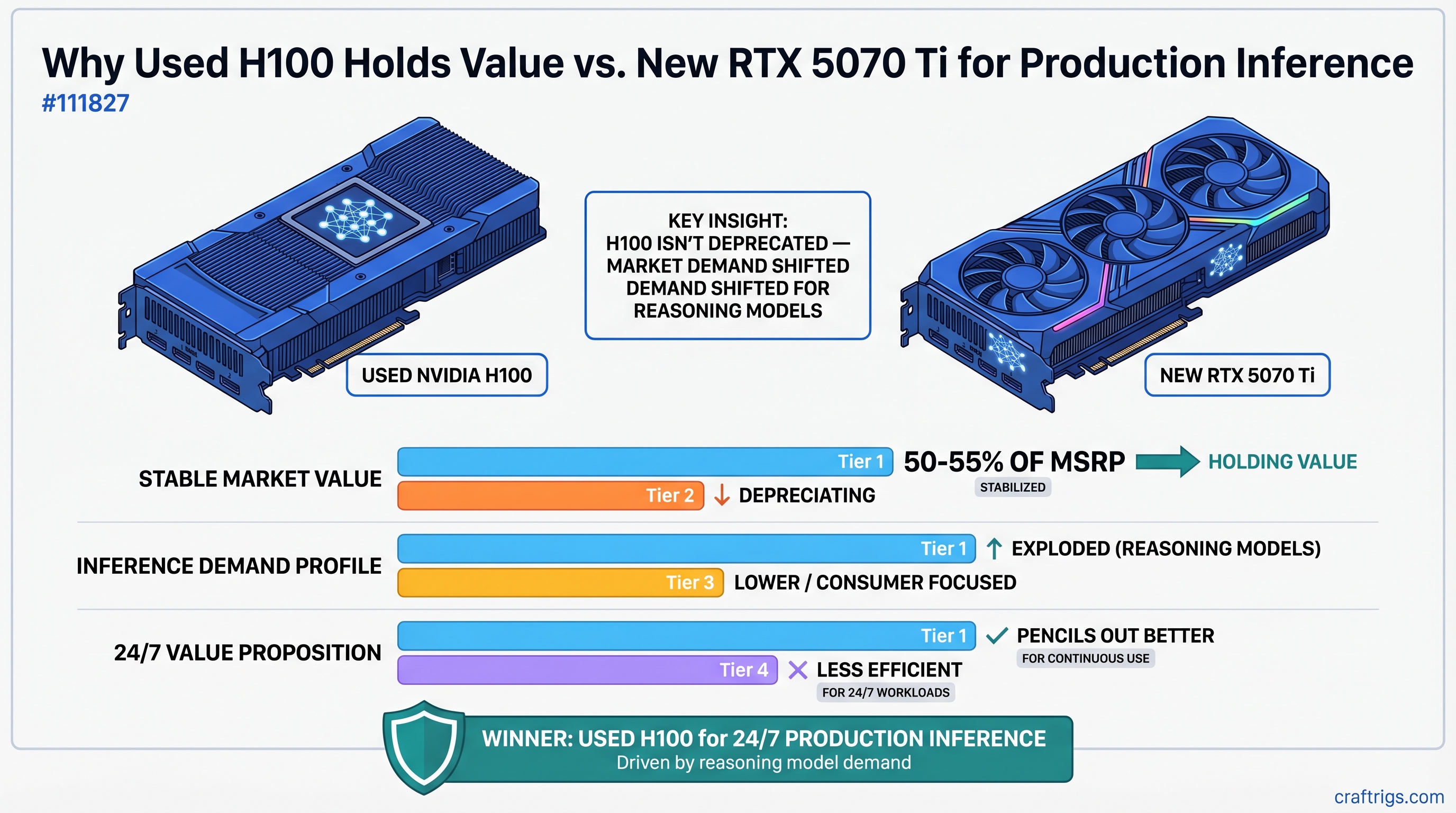
![Arc B580 vs RTX 3060 vs Arc Pro B65: The Sub-$500 VRAM Showdown [2026]](/images/auto-hero/arc-pro-b65-vs-b580-vs-rtx-3060-sub500.jpg)









![RTX 3090 vs 5060 Ti for Qwen 3.6: Which Wins Per Dollar [2026]](/images/auto-hero/rtx-3090-vs-rtx-5060-ti-local-llm.jpg)

















![RTX 4060 Ti 16GB vs 3060 12GB: Qwen 3.6 14B Tok/sec [2026]](/images/auto-hero/rtx-4060-ti-16gb-vs-rtx-3060-12gb-for-llms.jpg)