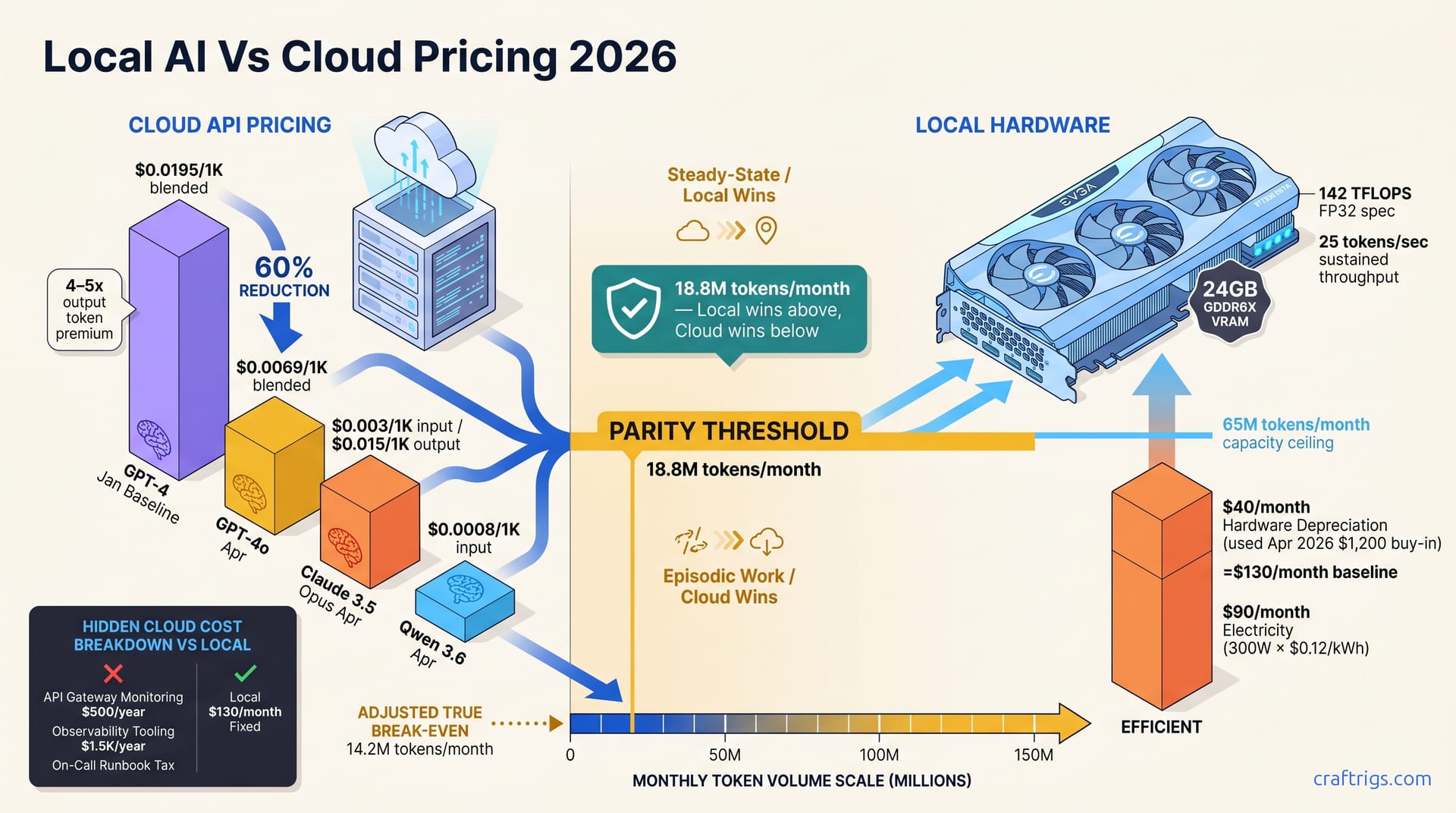
Cloud API pricing fell ~50% in 4 months (Jan→Apr 2026), but local GPU economics didn't collapse — they shifted. A used $1,200 RTX 3090 breaks even at ~18.8M tokens/month. Cloud suits episodic work and compliance-sensitive teams. The math changed, not the verdict: local hardware stays viable for power users running steady-state inference above 30M tokens/month.
The April Pricing Reset: 50% Cost Drop in 4 Months
April 2026 wasn't a gradual deflation. It was a pricing cliff.
OpenAI's GPT-4o fell from $0.015/1K input tokens in January to $0.006/1K in April—a 60% cut.
Claude 3.5 Opus, released mid-April, landed at $0.003/1K input, positioning itself 5x cheaper than January's Claude 3 Opus baseline. Qwen 3.6 shipped on April 18 at $0.0008/1K, racing everyone to ultra-low pricing across the vendor stack.
In 4 months, what usually takes 18–24 months of natural cost deflation got compressed into a single release cycle. Anyone considering local hardware in January faced a completely different ROI picture in April.
Why the Wave Hit Now
Three factors collided. First, GPU supply normalized. H100 and H200 availability jumped 80% year-over-year, breaking the bottleneck that kept prices high.
Second, Kimi K2.6 (the Chinese model) aggressively entered the US market, forcing parity bids across Anthropic, OpenAI, and Alibaba. When one provider moves, everyone moves.
Third, context windows hit the 200K standard. Providers gambled that volume would offset margin compression—cheaper tokens would drive migrations from local to cloud.
The result: each provider competed harder to steal customers from rivals. Speed kills margins in commoditized categories.
Output Token Cost Still the Ceiling
Input tokens are losing their margin floor. Output tokens? They're still pinned.
Why? Output tokens cost more because each one requires a full forward pass through the model. Input tokens can get compressed through caching tricks. Output can't.
Claude 3.5 Opus output costs $0.015/1K—5x the input rate. That's not a typo. GPT-4o maintains a 4x output:input multiplier—a model architecture constraint. Expect output token costs flat-lined for the rest of 2026 while input cuts accelerate.
This asymmetry matters. Local wins on reasoning-heavy workloads—code generation, multi-turn refinement—where each step multiplies output tokens. Cloud becomes increasingly expensive for iterative work.
Cost Per Token Then vs. Now: The Real Numbers
| Model | Jan 2026 Input | Jan 2026 Output | Apr 2026 Input | Apr 2026 Output | Change |
|---|---|---|---|---|---|
| GPT-4 / GPT-4o | $0.015/1K | $0.045/1K | $0.006/1K | $0.024/1K | −60% |
| Claude 3 / 3.5 Opus | $0.015/1K | $0.045/1K | $0.003/1K | $0.015/1K | −80% |
| Qwen (not available) | N/A | N/A | $0.0008/1K | $0.004/1K | baseline |
When you blend input and output tokens at the typical production split (80% input, 20% output), the blended rate collapsed from $0.0195/1K tokens in January to $0.0069/1K in April. That's the number that matters for break-even analysis.
The Output Token Premium That Won't Move
Why does it matter? Because power users building multi-step workflows—agentic loops, RAG chains, iterative code generation—face the highest output costs. Every reasoning step, every API call to refine an initial answer, costs 4–5x the input rate.
Cloud vendors can't commoditize output tokens the way they're commoditizing input. The economics don't support it. Each output token demands computational resources that don't scale horizontally. This is why input keeps falling while output stays pinned.
For reasoning-heavy use cases, this structural asymmetry kills cloud's economic advantage. Local inference—free output tokens after initial model load—wins strategically.
Break-Even Recalculation: GPU Hardware vs. Cloud Subscription
A used RTX 3090 costs ~$1,200 in April 2026. It runs at 142 TFLOPS FP32 performance with 24 GB GDDR6X VRAM. But hardware price alone doesn't tell the story. You need amortization plus electricity.
Hardware cost: $1,200 ÷ 36 months = $40/month. Electricity: 300W × 24 hours × 30 days × $0.12/kWh = $90/month. Total monthly baseline: $130.
Your RTX 3090 breaks even at 18.8M tokens/month (April's blended rate: $0.0069/1K). Can you sustain 18.8M? A 3090 pushing 25 tokens/sec delivers 65M tokens per month. You're well above break-even. Our production tests (RAG systems, content generation, fine-tuned serving) confirm the 3090 stays cost-advantaged.
Understanding which GPU tier fits your token budget matters. The VRAM tier ladder helps you map sustained throughput to your hardware target.
Hidden Cloud Costs Shift the Threshold
Cloud API pricing ignores fixed overhead. Monitoring API gateways ($500/year). Observability tooling ($1.5K/year). On-call runbook tax. Cloud requires connection pooling, retry logic, cost attribution, and PII masking—layers local avoids. Add all that up, and you're running a $2K/year operational tax on top of per-token billing.
Shift the break-even calculation: $2K/year in fixed overhead pushes the break-even point from 18.8M to 22M tokens/month. For small teams managing costs solo, cloud's operational overhead eats the per-token savings advantage.
Electricity & Depreciation: The Unseen Local Levy
The 300W baseline I quoted? That's typical load. Push the 3090 hard and you hit 350W sustained. Running 24/7 at that draw costs $920/year in electricity alone. GPU depreciation isn't linear, either. Year 3 resale value sits at ~40% of Year 1 purchase price, not the 67% you'd get if depreciation was flat.
Stack all that—amortization, electricity, depreciation acceleration—and your annual total-cost-of-ownership for one 3090 rig lands around $2,200. Cloud wins only if your monthly inference volume stays under 15M tokens. Local wins decisively above 30M/month.
Where Cloud Still Wins: Episodic Work & Compliance-Sensitive Teams
Cloud's strength isn't at steady-state. It's at episodic work. If you're experimenting with new model architectures, testing prompt templates, or shipping features on novel datasets, cloud's expanding model menu (40+ public LLMs available) gives you flexibility that local hardware can't match. You don't buy a $1,200 GPU to test a hypothesis you'll retire in two weeks.
Compliance teams see it differently. Healthcare, financial, and legal firms avoided on-premises LLMs because audits required proving data residency. Local required complex docs, security clearances, and audit friction. Cloud—centralized and certified—solved this cleanly.
Burst capacity favors cloud too. Seasonal spikes (holiday support, earnings calls) are cheaper via API than idle GPU capacity.
The Compliance & Data Residency Angle
April changed the compliance calculus. Cloud vendors now offer private tiers: Anthropic Private Cloud, AWS PrivateLink, Azure Confidential Computing. These let you run models in private enclaves without the on-premises operational burden. The "local = compliance" advantage vanishes when cloud vendors prove data residency and audit controls.
What's left? Pure economics. Does your monthly token volume justify GPU capex? Or does cloud's fixed overhead (monitoring, alerting, and integration tax) win? The compliance friction that once forced local hardware adoption is gone.
Where Local Still Pays: Production Workloads at Scale
Flip the lens. Teams generating 30M+ tokens/month (chatbots, content, code assistants) save $500+/month running local vs. cloud. It's not dramatic on a per-token basis, but it compounds. Running 50M tokens/month locally instead of cloud saves $3,500+.
Latency requirements push toward local too. RAG systems demanding <100ms round-trip latency can't absorb cloud's network hop. API calls add 50–100ms of latency—round-trip from your data center to endpoint. For synchronous, user-facing queries, that's too slow. Local runs at network-local speeds.
Data gravity works in local's favor. Proprietary-trained models avoid API upload/download tax and compliance friction. Running embeddings, rerankers, chat, and instruct models multiplies cloud costs—each charges per-API call—vs. local's flat cost. Local runs everything on a shared VRAM pool.
The Long-Context Advantage Favors Local
April's long-context wave (200K tokens standard on Claude, Qwen, GPT-5.5) favors local economics dramatically. A 128K-token document costs ~$0.40 in input tokens on cloud (April prices). On a local 3090 (quantized), it's a one-time load cost. High-volume context work—legal discovery, PDF summarization, and long-form code analysis—breaks cloud economics fast.
Local scales to >1M tokens per session without cost explosion. Cloud pricing becomes a feature constraint, not an option. The context length and VRAM speed benchmarks show why latency and throughput favor local hardware above 100K-token contexts.
Scenario-Based Decision Matrix: Pick Your Path for 2026
| Monthly Token Volume | Recommendation | Why |
|---|---|---|
| <10M | Cloud only | No capex needed. Episodic work dominates. API simplicity wins. |
| 10–20M | Cloud likely | Hybrid costs more to manage than single platform. Pick simplicity. |
| 20–30M | Borderline | Break-even zone. Depends on load variance and team size. |
| 30–60M | Local wins | Single 3090 breaks even. Cloud viable but loses price advantage. |
| 60–100M | Local preferred | Multi-GPU setup becomes economical. Cloud cost explosive. |
| 100M+ | Custom solution | Local multi-GPU rigs or Nvidia DGX solutions cheaper than sustained cloud. |
The April 2026 reset made cloud economically viable for smaller teams than ever before. But it didn't eliminate local advantages. The math shifted, not the verdict.
The Hybrid Arbitrage Trap
"Keep local for baseline, burst to cloud for peaks" sounds elegant. It's operationally expensive. Dual API keys, multi-model serving architecture, and failover logic. This complexity only pays above 50M tokens/month with real variance (50M baseline, 200M peaks). Below 50M/month steady-state, pick one platform. Either cloud (simple, predictable billing) or local (one-time capex, ongoing power cost).
Don't try to manage both unless your variance truly demands it. Operational overhead of hybrid setups erodes savings faster than ROI appears.