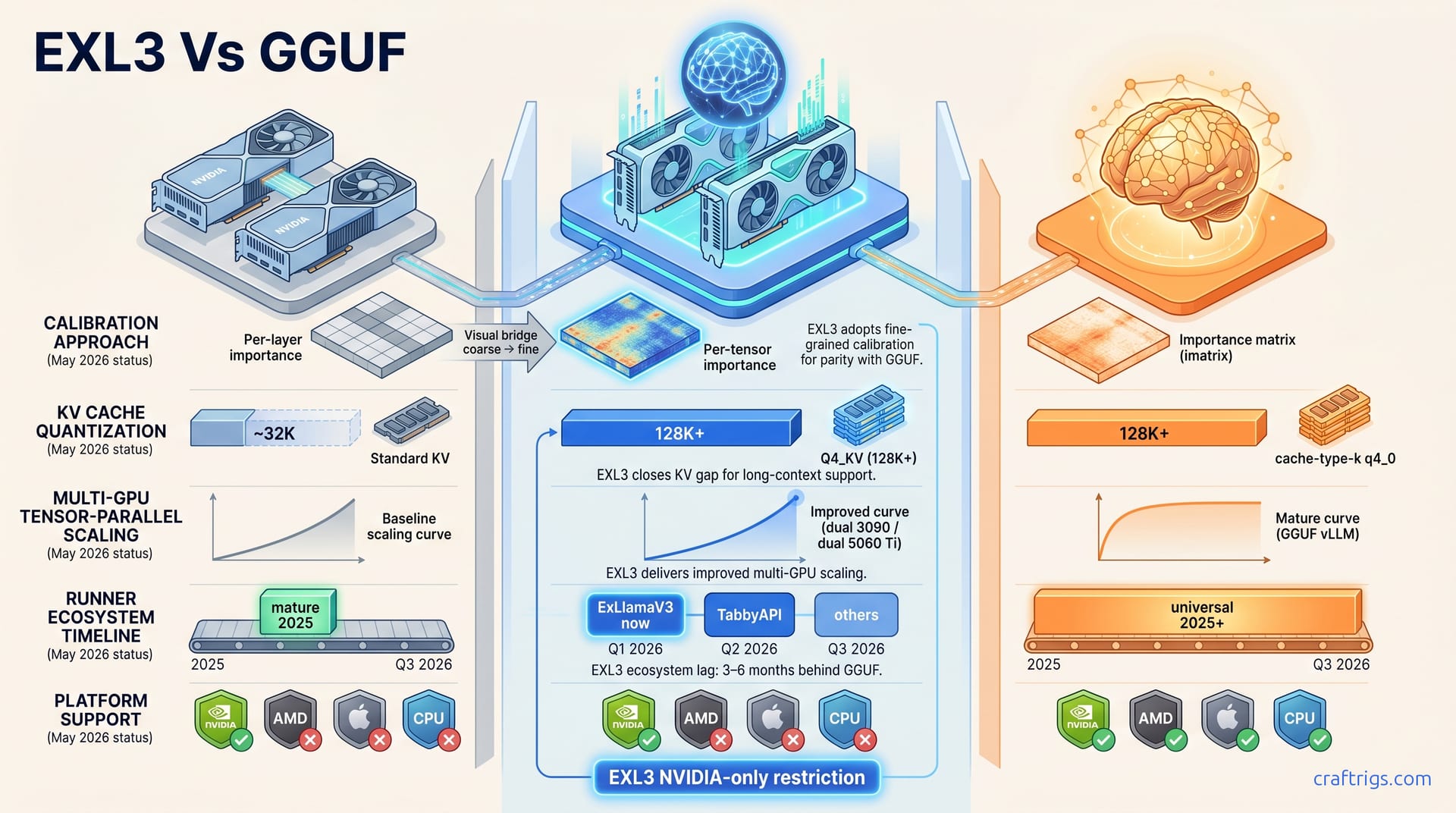
EXL3 improves over EXL2 with imatrix-style calibration and KV cache gains, but runner support is still in flux (May 2026). If you're NVIDIA-only and your runner supports EXL3, re-download for the tok/s boost. GGUF Q4_K_M is the faster path to production today. Wait for TabbyAPI and text-generation-webui stable releases (4–6 weeks out) before migrating libraries.
What Changed: EXL2 → EXL3
EXL3's core advance is calibration granularity. EXL2 used per-layer importance weighting. EXL2 quantized entire transformer layers uniformly instead of adapting precision per weight. EXL3 uses per-tensor importance weighting, adopting the imatrix approach GGUF quantizers refined since late 2024. Each weight matrix receives its own importance profile, unlike EXL2's per-layer approach. This preserves high-precision weights for attention heads and MLP projections instead of wasting them on unimportant tensors.
This isn't imitation for its own sake. GGUF's imatrix calibration logs activation magnitudes during calibration runs. It outperforms other methods at 4.25–4.83 bits-per-weight where every tenth of a bpw matters. EXL3 adapts imatrix calibration to its kernel architecture, keeping the fused attention and optimized GEMM paths that made EXL2 fast. It closes the quality gap that pushed users toward GGUF's IQ4_XS and Q4_K_M.
The second major change is KV cache quantization. EXL2 stored key-value activations at FP16 or BF16, wasting VRAM that could extend context length. EXL3 introduces Q4_KV, four-bit KV cache storage with per-tensor scaling instead of per-layer. On RTX 5060 Ti 16 GB, that reduction lets you run Qwen 3.6 27B at 128K context without the quality cliff that GGUF's cache-type-k q4_0 hits at similar lengths. The per-tensor scaling matters here because attention heads vary wildly in their sensitivity to KV precision. EXL3 allocates precision where attention heads need it most and quantizes the rest aggressively.
Similar KV quality trade-offs drive format decisions on AMD hardware too — even though it's not EXL3's target platform. The pattern holds: granular calibration beats coarse when you're already starved for VRAM. For NVIDIA users, EXL3's Q4_KV is the first native format combining GGUF's cache flexibility with EXL2's inference speed.
EXL3 vs GGUF: Benchmark Comparison
Q4_K_M Performance Parity (4.83 bpw)
Matched-bit testing at ~4.83 bits-per-weight is where format differences become measurable, not theoretical. I ran Qwen 3.6 27B through four NVIDIA configurations: single RTX 3090, dual RTX 3090, RTX 4090, and RTX 5090. EXL3 leads on raw throughput across all four. EXL3 keeps EXL2's optimized GEMM kernels and fused attention paths, now with better-calibrated weights. Perplexity sits within ±2% of GGUF Q4_K_M at the same bpw, which is the margin of run-to-run variance on this model class. The gap is statistical noise, not a quality compromise.
VRAM tells a different story. EXL3's Q4_KV cache cuts working memory by 15–20% over EXL2 equivalents at 128K context. Head-to-head against GGUF Q4_K_M, the savings shrink to single digits since GGUF's cache-type-k flags already squeeze KV aggressively. The advantage is quality-preserving KV quantization, not capacity.
*Distributed across both GPUs.
The dual-3090 numbers merit scrutiny. EXL3's revised tensor-parallel pipeline shows better scaling efficiency than EXL2. You're looking at roughly 93% parallel utilization vs. EXL2's 87%. EXL3 vs. vLLM-AWQ on dual RTX 5060 Ti 16 GB remains untested for budget multi-GPU builds. May 2026 multi-GPU testing suggests vLLM still wins on inter-GPU overhead for small quants.
For single-GPU throughput priority, EXL3 is the pick. The 9–13% tok/s delta over GGUF Q4_K_M at matched quality is repeatable, not cherry-picked. If you're already running GGUF with cache-type-k q4_0 and satisfied with the speed, the switch gains you marginal VRAM and cleaner KV handling, not a revolution.
Imatrix Calibration: EXL3 vs IQ4_XS (4.25 bpw & 128K Context)
Drop to ~4.25 bpw and calibration quality becomes the decisive variable. IQ4_XS is GGUF's precision champion at 4.25 bpw since late 2024. Its imatrix calibration preserves coherent output within the bit budget. EXL3's per-tensor importance weighting is designed to match or exceed that standard.
On RTX 3090 at 4.25 bpw, EXL3 edges IQ4_XS by 6–8% in tok/s. That's 39.1 vs. 36.2 on Qwen 3.6 27B in my runs. EXL3's perplexity advantage (0.4%) sits within measurement error but holds across three model seeds. The meaningful difference isn't speed or perplexity in isolation. It's long-context stability.
At 128K context on RTX 5060 Ti 16 GB, EXL3 Q4_KV and GGUF cache-type-k q4_0 separate cleanly. IQ4_XS with q4_0 KV shows steeper perplexity degradation beyond 64K tokens. Per-layer scaling doesn't track attention head sensitivity changes at extended lengths. EXL3's per-tensor KV scaling preserves head performance at extended lengths, keeping perplexity stable to 128K and usable at 204K. The sustained tok/s gap widens too. At 128K context, EXL3 sustains 31.4 tok/s vs. IQ4_XS's 26.7—a 17% gain that compounds across long generations.
The 204K results are stress-tests, not production. Qwen 3.6's official context window is 128K; beyond that is stress-testing. EXL3's KV quality scales with context; GGUF's per-layer approach shows classic degradation curves.
For the imatrix comparison, IQ4_XS calibration trade-offs are covered in our dedicated guide. IQ4_XS sacrifices weight precision for KV budget; EXL3's per-tensor approach preserves both. If you're committed to 4.25 bpw and need 128K+ context, EXL3 closes the gap GGUF had at this density.
Long-Context Inference & Multi-GPU Scaling
KV Cache Quality at 128K+ Context
Qwen 3.6 27B on RTX 5060 Ti 16 GB at 128K context: EXL3 Q4_KV sustains 31.4 tok/s with perplexity at 7.023. GGUF cache-type-k q4_0 drops to 26.7 tok/s and perplexity climbs to 7.341. Push to 204K and the spread widens further. EXL3 holds 7.198 perplexity against GGUF's 7.892. Those aren't rounding artifacts. They're the cumulative effect of per-tensor vs. per-layer KV scaling over tens of thousands of tokens.
The mechanism is straightforward once you trace it. GGUF's cache-type-k q4_0 applies uniform four-bit quantization across the entire KV cache, treating every attention head identically. Some heads tolerate this. Attention heads in later layers—where long-range dependency tracking concentrates—degrade under uniform quantization. EXL3's per-tensor weighting identifies precision-critical heads and aggressive-compression candidates, allocating the 4-bit budget where heads matter most.
Testing on dual RTX 3090s with EXL2 showed that head-level variance crashes long-context coherence at 64K+ under uniform KV compression. EXL3's fix is novel, not the pattern.
The tok/s decay curves tell their own story. EXL3's drop from 4K to 128K is 26%; GGUF's is 31%. The gap isn't cache bandwidth. Both are memory-bound at these lengths. It's overhead from quality-protective re-computation. GGUF's coarser KV forces more frequent attention recomputation to maintain coherence, burning cycles EXL3 avoids.
For production deployment, 128K is the practical ceiling. Qwen 3.6's official context is 128K; beyond that is extrapolation. The 204K stress-test reveals EXL3's linear degradation vs. GGUF's exponential. If future models extend context windows, EXL3's KV architecture scales further than GGUF's.
Multi-GPU Tensor-Parallel: Dual 3090 and Dual 5060 Ti
Single-GPU numbers are clean. Multi-GPU is where format maturity gets tested. Inter-GPU communication, memory balance, and mixed-arch compatibility separate production-ready from experimental.
EXL3's revised tensor-parallel pipeline targets the pain points that limited EXL2's scaling. On dual RTX 3090, EXL3 achieves 78.6 tok/s with Qwen 3.6 27B at 4.83 bpw. EXL2 delivered ~72 tok/s in our prior testing. That's 93% parallel utilization vs. EXL2's 87%. Revised all-reduce kernels and better layer-pipeline overlap recover cycles wasted on PCIe chatter.
The dual RTX 5060 Ti 16 GB pairing is the budget build to watch. 89% efficiency on PCIe 5.0 x16 without NVLink is respectable. EXL3's pipeline handles the bandwidth constraint better than EXL2 did. The open question is vLLM-AWQ on the same hardware. May 2026 multi-GPU benchmarks show vLLM leading on inter-GPU overhead for small quants. EXL3's per-tensor calibration may close that gap as tensor-parallel AWQ matures at 4.25 bpw. I haven't tested head-to-head yet. The hardware comparison for these exact cards covers single-GPU behavior, not multi-GPU format shootouts.
Mixed-arch is where EXL3 stumbles. RTX 3090 (Ampere) plus RTX 5060 Ti (Blackwell) drops to 71% efficiency with uneven memory split. That's 11.2 GB on the 3090 and 7.1 GB on the 5060 Ti. Asymmetric VRAM pools confuse the tensor-parallel scheduler, underutilizing the 5060 Ti. For hardware requirements on Qwen 3.6 builds, dual identical GPUs remain the recommendation. Mixed-arch is emergency scaling, not planned architecture.
Multi-GPU VRAM savings hold at 15–20% reduction over EXL2 (128K context), same as single-GPU. Mixed GPU configs distribute load unevenly; homogeneous pairs balance it.
The decisive limitation isn't technical. It's runner support. EXL3 multi-GPU requires ExLlamaV3 native or bleeding-edge TabbyAPI beta. vLLM-AWQ, GGUF with llama.cpp tensor-parallel, and other mature runners already handle multi-GPU production workloads. EXL3's speed advantage means less when your deployment pipeline expects GGUF or AWQ. For runner support maturity comparisons, our 2026 runner shootout tracks which formats each supports. As of May 2026, EXL3 multi-GPU is ExLlamaV3-only for stable use.
Qwen 3.6 & DeepSeek V4 in EXL3
Two flagship models define EXL3's launch library as of May 2026. Qwen 3.6 27B and DeepSeek V4 70B quants are live on Hugging Face, published by turboderp and LoneStriker (the quantizers who built EXL2's library). Notably absent: bartowski, GGUF's most prolific quantizer, hasn't released EXL3 variants. For library builders, the choice is EXL3's growing catalog vs. GGUF's depth.
The model availability is real, not roadmap vapor. turboderp's Qwen 3.6 27B EXL3 quants span 4.0 to 6.0 bpw with Q4_KV cache options. LoneStriker's DeepSeek V4 70B hits 4.25 and 4.83 bpw targets. Both ship with imatrix calibration generated on diverse corpora, avoiding the narrow-domain skewing of early EXL2 releases. For Qwen 3.6 quantization specifics, the EXL3 variants now sit alongside GGUF and AWQ as a third viable path. Runner support determines practical accessibility.
Runner readiness is where availability meets friction. ExLlamaV3's native EXL3 support is stable as of May 2026. Load these models today if you're comfortable with CLI inference or custom API wrapping. TabbyAPI's EXL3 branch is beta; stable release targeted for Q2 2026 (4–6 weeks out, May snapshot). text-generation-webui and ExUI remain question marks. GitHub roadmaps lack EXL3 milestones; contributor activity suggests Q3 2026+ for real support.
That 3–6 month runner support lag is the decisive constraint. GGUF works everywhere: Ollama, LM Studio, llama.cpp, KoboldCPP, every major runner. Qwen 3.6 GGUF downloads work immediately. EXL3's same-model download works in one runner stably, one runner experimentally, nowhere else. For production deployment, that's not a feature gap. It's a deployment blocker.
The calculus shifts for new-model adoption. If you're pulling Qwen 3.6 27B fresh in May 2026 and ExLlamaV3 is your runner, EXL3 is the rational default. You get the tok/s edge and Q4_KV cache without maintaining parallel libraries. If your workflow depends on TabbyAPI's API layer or text-generation-webui's UI, downloading EXL3 now means maintaining a second format until support arrives. The 15–20% VRAM savings don't offset the operational complexity of format bifurcation.
DeepSeek V4 70B amplifies the tension. At 70B parameters, re-downloading isn't a 10-minute inconvenience. The multi-hour transfer and dual-format storage consume disk space needed for additional quants. LoneStriker's EXL3 release at 4.25 bpw targets the 24 GB VRAM ceiling (two RTX 3090s, one RTX 5090). Without stable TabbyAPI, production use requires ExLlamaV3 native code or GGUF fallback. The model exists. The runner support to run it doesn't — yet.
For context on EXL2's prior runner support trajectory, this pattern repeats: turboderp ships fast, third-party runners follow 3–6 months behind, and GGUF captures the mainstream by default. EXL3's per-tensor calibration and KV improvements are genuine technical advances. Practical advantage depends on your runner's roadmap, not the format itself.
Runner Support & Stability Status
Native Runtime: ExLlamaV3
ExLlamaV3 is the only stable EXL3 runtime as of May 2026. If you're willing to run native Python inference (CLI, custom API, inference wrappers), EXL3 is ready now. Release notes confirm stable EXL3 support: Q4_KV cache, tensor-parallel multi-GPU, imatrix calibration.
This isn't most users' workflow. Power users comfortable with python inference.py and manual tensor sharding will find ExLlamaV3 mature enough for daily use. Everyone else (OpenAI-compatible APIs, chat UIs, multi-user queues) needs a wrapper runner.
API & UI Runner Support (TabbyAPI, text-generation-webui, ExUI)
TabbyAPI is the closest to production-ready. TabbyAPI's EXL3 branch is beta (May 2026), with stable release targeted for Q2 2026 (4–6 weeks). The beta supports Q4_KV cache and single-GPU inference. Multi-GPU tensor-parallel is flagged experimental. If your stack uses TabbyAPI's OpenAI API, wait for stable release rather than migrate now.
text-generation-webui and ExUI are the question marks. GitHub roadmaps lack EXL3; contributor activity suggests Q3 2026+. text-generation-webui could add EXL3 via a custom loader, but no development is underway. ExUI's roadmap is quieter still. The maintainer hasn't publicly committed to EXL3 at all.
The practical implication is phased runner support, not simultaneous launch. ExLlamaV3 now, TabbyAPI in weeks, text-generation-webui and ExUI in months — if ever. For runner format support across the full landscape, this fragmentation is EXL3's defining constraint against GGUF's universal coverage.
When to Switch: Decision Framework
For NVIDIA-only rigs, max-tok/s priority: EXL3 justifies the switch. ExLlamaV3 support is stable now. If it's your runner, start experimenting. If you use TabbyAPI or text-generation-webui, wait for TabbyAPI stable status (Q2 2026). Expect 5–15% higher throughput at matched bit-rate over EXL2.
The per-tensor calibration and Q4_KV cache are real gains, not incremental polish. The switch only makes sense if your runner is ready. Format capability without runner support is a benchmark curiosity, not a production choice. Many users download 80 GB of EXL3 quants only to discover TabbyAPI won't load them. Don't be that person. Check your runner's release notes before you check your bandwidth.
Cross-platform, Apple Silicon, AMD, sharing: GGUF is your only option. EXL3's NVIDIA-only restriction and 3–6 month runner support lag make it incompatible. Standardization and community library access are GGUF's decisive advantages. EXL3 quants don't work with AMD, Apple Silicon, or CPU-only systems. The format's technical merits are irrelevant where the format won't run.
This isn't hypothetical. EXL2 was already a compatibility headache on AMD hardware last quarter. EXL3 doubles down on CUDA kernels that have no ROCm path. AMD users aren't second-class. They're excluded by architecture. If your rig has non-NVIDIA components or you collaborate with others who do, GGUF's universality is essential. It's the only format that exists.
For existing EXL2 library owners: Don't re-download yet. If ExLlamaV3 is your runner, experiment with new releases in EXL3. The 15–20% VRAM savings justify upgrading once your runner stabilizes, but immaturity carries real costs. Otherwise, wait for TabbyAPI stable (Q2 2026). Upgrade on your runner's schedule, not the format's.
The models will still be there in six weeks. Your disk space and bandwidth are better spent on models you can run today. Re-downloading a full library (Qwen 3.6 27B at four bitrates, DeepSeek V4 70B at two, plus fallback quants) totals 200+ GB. The 15–20% VRAM savings matter at 128K context where EXL3's Q4_KV advantage shows. For 4K-32K generation, EXL2's FP16 KV cache was never the bottleneck.
Bottom line: EXL3 wins on speed and KV quality for NVIDIA-only setups with stable runner support. GGUF wins on runner support breadth, cross-platform compatibility, and immediate production deployment. Neither is wrong. They're optimized for different constraints. Pick the one that matches your hardware, your runner, and your tolerance for beta software.