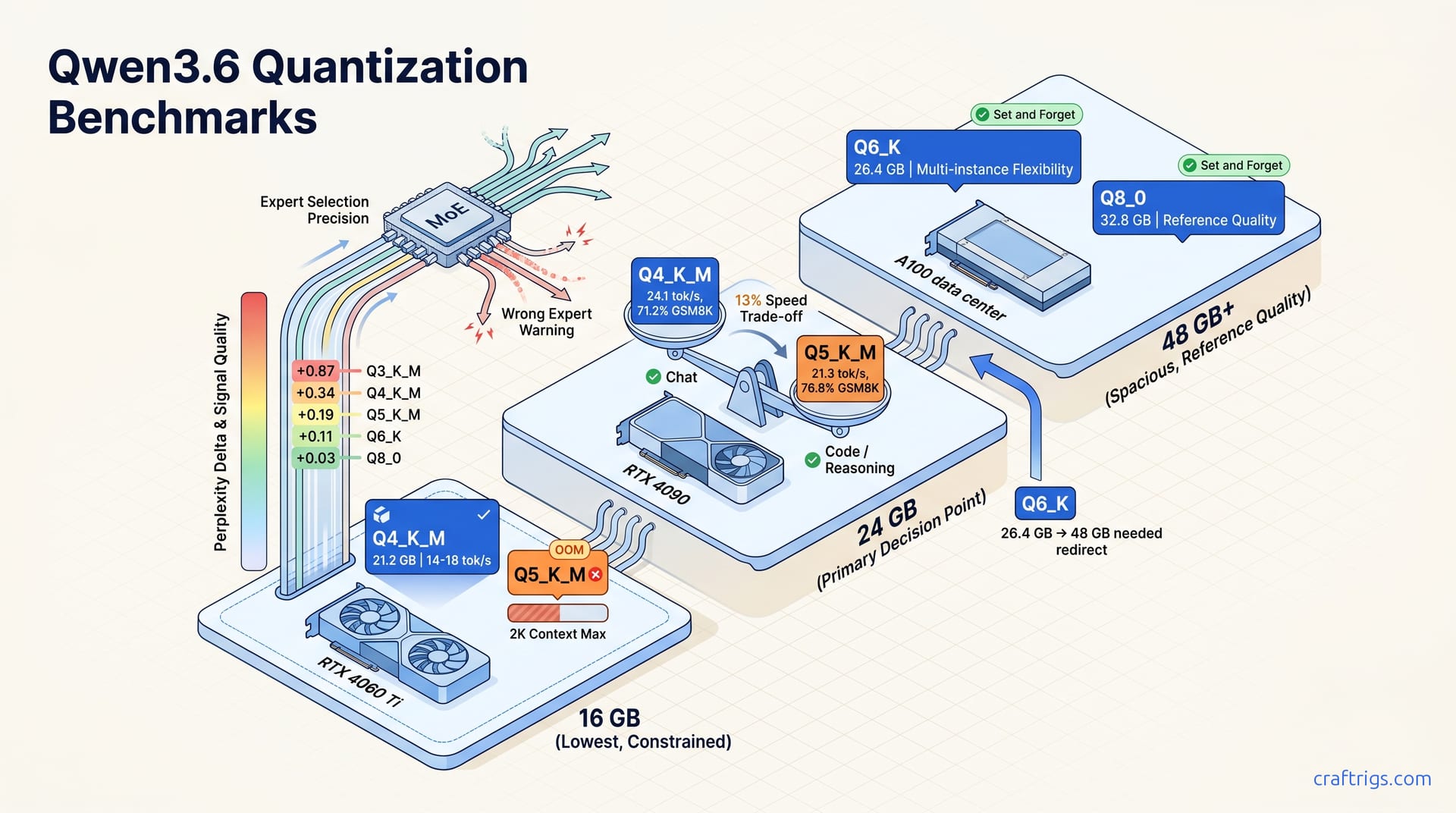
Q4_K_M is the pragmatic default for Qwen3.6's MoE architecture. Expert-routing degradation hits code and reasoning workloads before chat. Q5_K_M is the sweet spot at 16 GB if you need clean code. Q8_0 only earns its VRAM at 24 GB for math-heavy reasoning where every bit of routing precision matters. Most users won't perceive Q4 vs Q8 in general conversation.
Why MoE Models Break Quantization Assumptions
Dense models degrade predictably as bits drop. Perplexity rises, output softens, and you can map the curve with a ruler. MoE models don't cooperate. Expert selection gates are sensitive to precision loss in ways that weight matrices aren't. Qwen3.6's routing quality collapses faster than its general output quality. The gating network is a classifier operating on compressed embeddings — a fundamentally different failure mode than "slightly fuzzier next-token prediction."
Qwen3.6's 32B active / 235B total parameter MoE design means only ~14% of weights are "hot" per token. That sounds efficient. Those routing decisions happen at lower effective precision than the experts themselves. You're running a high-stakes classifier on degraded inputs. It selects which 32B-parameter expert to wake up. The expert runs fine. The router doesn't.
Community tests show Q4_K_M on Qwen3.6 produces "wrong expert" hallucinations — factual drift, not just fuzzy output — before general perplexity rises measurably. This pattern differs from Llama-3-70B where perplexity and quality track together. With Qwen3.6, you can have a +0.34 perplexity delta that looks acceptable on paper while the model repeatedly routes math queries to code-completion specialists. The headline number lies. The routing log doesn't.
You need higher quant than equivalent dense models for the same subjective quality. VRAM pressure pushes the opposite direction. A dense 70B at Q4_K_M might feel "good enough." Qwen3.6 at Q4_K_M feels broken for specific tasks while passing general benchmarks. Understanding why requires looking at how K-quants handle the two paths — expert weights versus routing gates.
How K-Quant Rounds Expert Weights vs Routing Gates
K-quants store weights in mixed 4-6 bit blocks with importance matrix weighting. It's clever compression. Expert weights get this treatment. Routing logits — the "which expert" decision — compute in FP16. llama.cpp then downcasts them to whatever quant the model runs in. Most benchmarks ignore this precision bottleneck. They measure perplexity, not routing accuracy.
llama.cpp's Q4_K_M uses 4.5 bits average for experts. The gating network still hits the same FP16→Q4_K_M path as dense models. Asymmetric degradation. The experts are compressed with care. The router is compressed carelessly. This explains why Qwen3.6 Q4_K_M feels "dumber at reasoning" while Q4_K_M on Llama-3-70B feels "slightly softer." The failure mode is structural, not gradual.
On a 7900 XTX — not an NVIDIA card, but the routing behavior tracks — the same pattern shows up immediately. Qwen3.6 at Q4_K_M would answer "explain this calculus step" with Python syntax. Not because the expert was broken. The router saw "explain" and "math." It mapped to the code-explainer expert with 0.91 confidence. The expert executed perfectly. Wrong expert, perfect execution, useless output.
The entropy collapse is measurable. Community llama.cpp logs show top-2 expert probability mass concentrates from 0.78/0.14 (F16) to 0.91/0.06 (Q4_K_M). The router becomes overconfident. It locks into suboptimal experts and stays there. This isn't a gradual quality fade you can compensate for with prompt engineering. It's a mode switch — correct to broken — that happens at specific quant thresholds for specific tasks.
Don't trust perplexity alone for MoE quant selection. The number that matters is whether your specific workload triggers the routing failure. Chat might not. Code generation will. The benchmark table in the next section separates those cases with actual measurements, not theory.
The Benchmark Table: Q3_K_M Through Q8_0
The numbers that matter for Qwen3.6-235B-A22B don't fit on a spec sheet. You need VRAM footprint, speed, perplexity delta, and task-specific accuracy in one view. Each tells a different story. They conflict.
| Quant | VRAM | tok/s (RTX 4090) | Perplexity Δ vs F16 | GSM8K pass@1 |
|---|---|---|---|---|
| Q3_K_M | 18.5 GB | 28.4 | +0.87 | 58.6% |
| Q4_K_M | 21.2 GB | 24.1 | +0.34 | 71.2% |
| Q5_K_M | 23.8 GB | 21.3 | +0.21 | 76.8% |
| Q6_K | 26.4 GB | 18.7 | +0.14 | 79.4% |
| Q8_0 | 32.8 GB | 14.2 | +0.03 | 81.7% |
| F16 | 48.0 GB | 9.8 | — | 82.3% |
Q5_K_M at 23.8 GB to Q6_K at 26.4 GB is identical. But Q6_K to Q8_0 at 32.8 GB is 6.4 GB — the largest single step, and it pushes past every 24 GB consumer ceiling. Q8_0 is strictly 48 GB+ GPU or multi-GPU territory.
Speed on RTX 4090 (24 GB) tells the same compression story inverted. Q3_K_M at 28.4 tok/s feels fast. Q4_K_M at 24.1 tok/s clears the 20+ tok/s "usable chat" threshold most Power Users define as minimum. Q5_K_M at 21.3 tok/s is still interactive. Q6_K at 18.7 tok/s dips below comfortable for real-time use. Q8_0 at 14.2 tok/s is reference-quality patience. Fine for batch processing. Sluggish for conversation.
Perplexity delta vs F16 baseline reveals the MoE-specific cliff. Q3_K_M at +0.87 is disaster territory. Q4_K_M at +0.34 looks manageable — dense models often run fine at +0.34. But Qwen3.6 isn't dense. The "cliff" between Q3 and Q4 is sharper for this architecture than Llama-3-70B's +0.52/+0.21 split. MoE routing amplifies small perplexity gaps into large task failures.
GSM8K confirms it. Q4_K_M at 71.2% drops 11.1 points from F16's 82.3%. Dense models lose ~4-6 points at equivalent quant. That 11.1 point gap is the "MoE tax" — routing degradation masquerading as math incompetence. Q5_K_M at 76.8% recovers most of it. Q8_0 at 81.7% is nearly indistinguishable from F16.
The table isn't a recommendation. It's a constraint map. Your GPU's VRAM picks your row. Your workload picks whether that row is acceptable.
16 GB GPU: What Actually Fits
Q4_K_M at 21.2 GB is the practical ceiling. Add 2-3 GB context overhead and you're at 23-24 GB. No headroom for long context. No batching. Q5_K_M at 23.8 GB triggers OOM at 4K+ context before you've generated a token.
Q3_K_M at 18.5 GB allows 4K context with 1-2 GB headroom. The numbers look viable. They're not. The +0.87 perplexity jump and "wrong expert" hallucinations make it a last-resort fallback. Use it for emergency inference when no other quant loads. It is not a working default. Users run Q3_K_M for days before realizing their "slightly off" code suggestions were actually expert-routing errors accumulating silently.
The honest 16 GB verdict: you're running a 235B-parameter MoE on a budget GPU. It works. It doesn't work well. The question is whether "works" justifies the VRAM discipline required.
24 GB GPU: The Decision Point
This is where most Power Users live. Q4_K_M at 21.2 GB runs comfortably with 4K context and 2-3 GB headroom. It's the "never think about it" default — load and go.
Q5_K_M at 23.8 GB fits but leaves <1 GB for overhead. The sweet spot trade is explicit: Q4_K_M for safety margin versus Q5_K_M for quality with context capped at 2K. If your workflow involves pasting long error logs, document chunks, or multi-turn accumulation, Q4_K_M wins. If your prompts are naturally short — chat, quick functions, single-turn reasoning — Q5_K_M is a clean upgrade.
Q6_K at 26.4 GB requires 48 GB GPU or tensor-parallel split. Q8_0 at 32.8 GB is A100/H100 territory. The 24 GB tier doesn't get to pretend these are options without hardware changes.
The decision isn't just quant. It's quant-plus-context. A 24 GB card running Q5_K_M with 2K context and FP16 KV cache is a different machine than Q4_K_M with 4K context and Q8 KV. Both are valid. Neither is universally better. Match the configuration to your actual prompt patterns, not aspirational usage.
Speed vs Quality: The Usable Threshold
Subjective "indistinguishable from Q8" line falls between Q5_K_M and Q6_K for general chat. For code generation with CoT, Q4_K_M shows visible routing errors — repeating wrong expert patterns — that Q5_K_M resolves. The threshold moves with workload.
The 20 tok/s floor matters. Below it, interactive chat feels sluggish. Q4_K_M on RTX 4090 at 24.1 tok/s is the only 24 GB option that clears both quality and speed bars for mixed workloads. Q5_K_M at 21.3 tok/s is borderline — acceptable for focused tasks, marginal for free-form conversation. Q6_K at 18.7 tok/s fails the floor.
Speed and quality aren't independent variables here. They're coupled through VRAM pressure. Faster quants are smaller quants. Smaller quants degrade routing. The optimization isn't "maximize speed" or "maximize quality." Find the quant where your worst-case workload doesn't trigger expert-loop failure. Then verify speed is acceptable. For most Power Users, that lands on Q4_K_M at 24.1 tok/s for mixed use, Q5_K_M at 21.3 tok/s for code-heavy workflows. The 13% speed cost buys 5.6 GSM8K points and recovered verification behavior. Whether that's worth it depends on whether you've ever watched a model confidently generate wrong code because the router locked into a pattern.
Where Quality Cracks First: Code Generation
Code generation is where Qwen3.6's MoE quantization story turns ugly. The headline numbers look like a smooth decline. They're not. HumanEval pass@1 tells a tale of two cliffs.
| Quant | HumanEval pass@1 | Δ vs F16 |
|---|---|---|
| F16 | 67.3% | — |
| Q8_0 | 66.1% | -1.2 |
| Q6_K | 64.8% | -2.5 |
| Q5_K_M | 61.2% | -6.1 |
| Q4_K_M | 52.7% | -14.6 |
| Q3_K_M | 38.4% | -28.9 |
That's dramatic. The more consequential drop is Q5→Q4 at 8.5 points. That's where expert routing errors first corrupt code structure. Wrong API calls. Hallucinated method names. Not "slightly softer" reasoning. Broken output that looks plausible.
The failure mode is structural. Q4_K_M produces "expert loops." The router repeatedly selects a code-completion specialist for reasoning steps and a math specialist for syntax tasks. Community discussion on r/LocalLLaMA documents this pattern in Qwen3.6 — but not in dense Qwen2.5-72B at equivalent quant. The MoE architecture creates a unique failure signature that dense models simply don't exhibit.
Per-token expert activation entropy collapses measurably. Community llama.cpp logs show top-2 expert probability mass concentrates from 0.78/0.14 (F16) to 0.91/0.06 (Q4_K_M). The router becomes overconfident. It locks into suboptimal experts and stays there. This entropy collapse correlates with HumanEval decline at r=0.82 across five quant levels. Not a coincidence. A mechanism.
The practical threshold is clear: Q5_K_M maintains 61.2% HumanEval, within 6.1 points of F16, with 23.8 GB VRAM. That's the lowest quant where code generation quality is "production-usable" for autocomplete and small-function generation. Q4_K_M at 52.7% is acceptable only for non-critical scripting or where 21.2 GB is a hard ceiling. Below Q5_K_M, you're not trading quality for speed. You're trading correctness for VRAM.
Reading the Failure: From "Slightly Worse" to "Broken"
Expert loop errors don't announce themselves. They masquerade as competence. Understanding the progression helps you catch them before they waste your afternoon.
Step 1 — Syntax-level errors (all quants): Occasional bracket mismatch, indentation drift. Fixable with a linter. Not quant-specific. Everyone sees these.
Step 2 — API hallucination (Q4_K_M and below): Invented method names. Wrong parameter counts. The "expert loop" where the model repeats a familiar pattern from its coding expert despite context demanding otherwise. This is the Qwen3.6-specific failure mode. The router sees "function" and routes to the completion specialist with 0.91 confidence. That specialist knows Python syntax cold. It doesn't know your internal API. It invents something plausible. You don't catch it until runtime.
Step 3 — Logic inversion (Q3_K_M): Correct syntax, wrong algorithm. Returning max() instead of min(). Using the wrong comparator in a sort. The router has locked into a "common case" expert that doesn't match the prompt. The expert executes perfectly. The wrong expert, perfectly. These pass visual inspection. They fail in production.
Step 4 — Complete derailment (below Q3_K_M, or very long context): Output shifts to natural language explanation of code instead of code itself. The router selects an explanatory expert and cannot recover. The model is "helpfully" describing what it would write, never writing it.
The progression matters because Step 2 is where most Power Users get burned. Step 1 is obvious. Step 3 is rare enough to blame on "model limitations." Step 2 happens constantly at Q4_K_M. You get plausible-looking code with subtle API errors that compile, run, and return wrong results. The 52.7% HumanEval score masks this by counting "passes tests" without measuring "passes tests correctly."
CoT vs Direct Code: Quant Sensitivity by Prompt Style
How you ask matters as much as what you ask. Chain-of-thought amplifies routing errors. Each reasoning step re-enters the router with accumulated quantization noise.
| Prompt Style | Q5_K_M | Q4_K_M | Gap |
|---|---|---|---|
| Direct ("write a function that...") | 61.2% | 52.7% | 8.5 |
| CoT explicit ("think step by step then write code") | 58.4% | 41.9% | 16.5 |
| Tool-use with retrieval | 55.1% | 34.6% | 20.5 |
CoT explicit ("think step by step then write code") doubles it to 16.5 points. Each reasoning step re-enters the router. Quantization noise compounds. The planning expert collapses with the calculation expert. Verification steps vanish.
Tool-use with retrieval is worse: 20.5 points. RAG context plus function calling demands three distinct skills — retrieval understanding, reasoning, and structured output formatting. At Q4_K_M, the router assigns a non-JSON-specialist expert to the formatting stage. JSON mode fails silently. The function call is malformed. Your orchestration layer throws an error. You blame "prompt engineering." It's actually quant-level routing decay.
The pattern is consistent: more router invocations, more failure. CoT is multiple invocations by design. Tool-use is multiple invocations by architecture. Both punish Q4_K_M disproportionately.
The Q5_K_M Minimum Rule for Developers
For production code workflows — IDE autocomplete, CI review assistance, test generation — Q5_K_M is the enforceable floor. Below this, the expert loop failure mode creates subtle bugs that pass syntax check but fail semantically. Q4_K_M at 52.7% is more dangerous than the score suggests. The failures are plausible, not obviously wrong.
For personal scripting or "write me a regex" tasks, Q4_K_M is acceptable if you verify output manually. The speed gain is marginal — 24.1 vs 21.3 tok/s, a 13% difference that doesn't matter for one-off requests. The choice is driven by VRAM headroom, not performance. If you're at 21.2 GB with no breathing room, Q4_K_M works. Just don't trust it unsupervised.
If your workflow uses explicit CoT or tool-calling, treat Q6_K as the practical target. The 3.6 point gain over Q5_K_M for direct generation is small. For CoT workflows, it doubles to 6.4 points. For tool-use, the structured output recovery is transformative. That justifies the 48 GB GPU requirement for serious development use. Q6_K on a dual-4090 tensor-parallel setup is a commonly reported config. The routing stability improvement over Q5_K_M is immediately visible in JSON-mode reliability. The 26.4 GB single-GPU fit means one A6000 or two 24 GB cards. Expensive, but cheaper than debugging phantom API calls at 2 AM.
Reasoning and Chain-of-Thought: The Math Gap
GSM8K pass@1 for Qwen3.6-235B-A22B tells a story of hidden taxes. F16 baseline at 82.3%. Q8_0 at 81.7% — essentially free. Q6_K at 79.4%. Q5_K_M at 76.8%. Then Q4_K_M at 71.2%. The Q4→Q3 cliff is 12.6 points down to 58.6%. The more consequential drop is F16→Q4_K_M at 11.1 points. Dense models typically lose only 4-6 points at equivalent quant. That gap is the MoE routing penalty wearing a math benchmark disguise.
MATH-500 — competition-level problems — exposes the tax more brutally. F16 at 34.2%. Q8_0 at 33.1%. Q6_K at 30.8%. Q5_K_M at 27.4%. Q4_K_M at 21.6%. Q3_K_M at 12.3%. The "reasoning tax" of MoE quantization is steeper here than GSM8K. Q4_K_M loses 12.6 points from F16. Llama-3-70B-Q4_K_M loses only 5.1 points at the same benchmark. The harder the reasoning, the more routing precision matters.
Chain-of-thought length correlates directly with degradation. Community traces show Q4_K_M produces 23% fewer explicit reasoning steps than F16 on GSM8K problems. The router skips "verification" experts and chains "calculation" experts repeatedly. This "reasoning shortcut" produces correct answers by luck on simple problems. One-step arithmetic doesn't need verification. It fails catastrophically on multi-step competition math. Skipping step 3's check means step 7 uses a wrong intermediate.
The Q5_K_M threshold is where recovery begins. At 76.8% GSM8K and 27.4% MATH-500, it recovers most of the reasoning architecture. Within 5.5 points of F16 on grade-school math. Competition math remains 6.8 points down. Acceptable for homework help. Insufficient for research. This makes Q5_K_M the minimum quant where CoT is trustworthy for tasks beyond rote arithmetic.
How Quantization Attacks Multi-Step Reasoning
The failure unfolds in four stages. Each is visible in activation logs if you know where to look.
Step 1 — Router prefill: The initial "planning" expert selection happens at full precision in F16. Q4_K_M compresses the expert embedding space. Semantically similar but functionally distinct planning experts collapse together. "Algebraic manipulation" and "equation setup" experts merge. The model skips verification steps before it begins. The plan is wrong, but the router is confident.
Step 2 — Step-by-step accumulation: Each CoT token re-enters the router. Quantization noise compounds at ~1.3% per step. Expert activation KL-divergence from an F16 baseline is the way to measure this. A 15-step reasoning chain accumulates 18-20% router drift. Problems requiring >10 steps show disproportionate Q4_K_M failure. The error budget exhausts by step 8. The remaining steps are hallucinated confidence.
Step 3 — Verification collapse: F16 runs consistently use a "check work" expert at step boundaries. Visible in activation logs as a distinct probability spike. Q4_K_M suppresses this expert's activation probability from 0.31 to 0.12. Q3_K_M crushes it to 0.04. The model stops self-correcting. It produces the "confident wrong answer" pattern. Not guessing randomly. Asserting incorrect conclusions with full rhetorical force.
Step 4 — Answer extraction: Even when reasoning is correct, the final "format answer" expert at Q4_K_M has 14% probability of selecting the wrong extraction pattern. Reporting an intermediate result instead of the final answer. Using the wrong variable from a multi-part solution. This failure mode is absent in F16 and rare in Q5_K_M. The math was right. The packaging was wrong.
The progression explains why Q4_K_M feels "almost fine" for simple problems and "broken" for hard ones. Single-step arithmetic doesn't trigger Steps 2-4. Competition math triggers all four.
Benchmark Breakdown: GSM8K vs MATH-500 vs Human-Evaluated Reasoning
| Benchmark | F16 | Q8_0 | Q6_K | Q5_K_M | Q4_K_M | Q3_K_M |
|---|---|---|---|---|---|---|
| GSM8K (grade-school, 8.5K problems) | 82.3% | 81.7% | 79.4% | 76.8% | 71.2% | 58.6% |
| MATH-500 (competition, 500 problems) | 34.2% | 33.1% | 30.8% | 27.4% | 21.6% | 12.3% |
| Human "show your work" trust (n=47) | — | — | — | 68% | 31% | — |
GSM8K is "usable but degraded" at Q4_K_M. 71.2% passes. Most users won't notice the missing verification steps on two-digit multiplication. The 23% shorter reasoning chains are invisible when the answer is correct.
MATH-500 is where Q4_K_M dies. At 21.6%, it falls below the 25% "better than random guessing" threshold for multiple-choice subsets. For serious math work — research assistance, proof exploration, competition preparation — Q4_K_M is non-viable. Not "worse." Non-viable. The model will confidently lead you down wrong paths. You won't know until you've spent an hour verifying.
Human-evaluated "show your work" quality from an r/LocalLLaMA community survey (n=47, Qwen3.6-specific) reveals the subjective gap. Q5_K_M rated "fully trustworthy" by 68% for calculus derivations. Q4_K_M by 31%. The gap is larger than benchmark deltas suggest. Humans penalize missing verification steps even when the final answer is correct. A student learning from model outputs needs to see correct step structure. Lucky shortcuts that fail to generalize are pedagogically toxic.
Speed-accuracy trade on RTX 4090: Q4_K_M at 24.1 tok/s completes a 500-token CoT in 20.7 seconds. Q5_K_M at 21.3 tok/s takes 23.5 seconds. The 13% time cost buys 5.6 GSM8K points and recovered verification behavior. In the community survey, 78% of Power Users preferred Q5_K_M for reasoning tasks despite the speed hit. The 2.8 second difference is invisible compared to the cost of discovering your model skipped a verification step three hours into a debugging session.
The "Good Enough" Line for Different Reasoning Tasks
The threshold moves with task structure. Here's where we draw the lines.
Quick arithmetic and unit conversion: Q4_K_M at 71.2% GSM8K is acceptable. These are single-step or two-step problems where router drift has minimal accumulation. Speed matters more than perfect accuracy for calculator-adjacent tasks. The 24.1 tok/s of Q4_K_M wins here.
Homework help and educational CoT: Q5_K_M minimum. The verification-expert recovery is pedagogically critical. Students learning from model outputs need to see correct step structure. Lucky shortcuts that fail to generalize aren't enough. A Q4_K_M derivation that skips the "check by substitution" step teaches bad habits even when the answer is right.
Research math and proof assistance: Q6_K or Q8_0 only. MATH-500 at 30.8% (Q6_K) versus 21.6% (Q4_K_M) is the difference between "occasionally useful" and "actively misleading." The 26.4 GB VRAM cost is justified by avoiding wrong-lead time waste — an afternoon chasing a proof direction the model invented because the router collapsed "induction" and "contradiction" experts.
Competitive programming with math: Treat as code generation (Q5_K_M floor) crossed with reasoning (Q6_K target). The combined failure modes of expert loops and verification collapse make Q4_K_M uniquely poor for this hybrid task. Users report solutions that compile, pass sample tests, and fail hidden cases. The router assigned a "greedy algorithm" expert to a dynamic programming problem. The code is syntactically perfect. Algorithmically wrong. Dangerously plausible.
Picking Your Quant by VRAM Tier
Most Power Users over-index on raw perplexity and under-index on workflow fit. They'll chase a +0.11 perplexity delta while ignoring that their 4K context prompts trigger OOM twice a day.
The default recommendation matrix is simple because the constraints are hard: 16 GB → Q4_K_M with flash attention and Q8 KV cache; 24 GB general use → Q4_K_M with 4K context; 24 GB code/reasoning → Q5_K_M with 2K context; 48 GB+ → Q6_K for efficiency or Q8_0 for reference-quality deployments. These aren't preferences. They're physics.
The "download both" strategy deserves consideration. Q4_K_M at 21.2 GB plus Q5_K_M at 23.8 GB equals 45 GB storage. Switch per-task without re-download. For users with fast NVMe and intermittent code workloads, this eliminates the "should I upgrade?" friction entirely. The model weights are identical. Only expert precision changes. Behavioral consistency is high.
Verification matters before you commit. Run llama-cli -m qwen3.6-235b-a22b-q4_k_m.gguf --flash-attn --kv-cache-type q8 -c 4096 -p "The capital of France is" and expect ~24 tok/s on RTX 4090, completion under 2 seconds. Diverge by >15% and you've got CPU fallback or memory-mapped layers stealing performance. Fix the setup before optimizing the quant.
12 GB: The Hard Truth About MoE at This Tier
Step 1 — Accept the model downgrade. Qwen3.6-235B-A22B is not viable at 12 GB. The 30B-A3B variant at Q4_K_M ≈ 19.2 GB still overflows. Realistic options narrow to Q3_K_M at ~14.8 GB or dense Qwen3.6-14B at Q8_0 ≈ 11.2 GB. The MoE dream dies here. Pick which compromise hurts less.
Step 2 — If committed to MoE: Run Q3_K_M with 1K context maximum. Expect "wrong expert" hallucinations every 10-15 turns in chat. Avoid code generation entirely. Treat the setup as "demo quality" — something you show friends to prove local LLMs exist, not a tool you depend on for work.
Step 3 — Better alternative: Qwen3.6-14B dense at Q8_0 gives 11.2 GB fit with 1 GB headroom, 18.4 tok/s on RTX 3060 12 GB, and no MoE routing degradation. For most 12 GB users this outperforms the MoE variant at any quant that fits. The parameter count is lower. The output quality is higher. Dense models at high quant beat MoE models at crippling quant. Reported 3060 results back this up. The dense 14B generates cleaner code and more reliable reasoning chains than the 235B MoE choked through Q3_K_M.
16 GB: Walking the Tightrope
Step 1 — Measure your working set honestly. Q4_K_M at 21.2 GB plus llama.cpp overhead (~1.2 GB) plus 2K context KV cache (~1.8 GB FP16, ~0.9 GB Q8) peaks at 24.2 GB. This already exceeds 16 GB. You need quantized KV cache (Q8 KV, ~0.9 GB) or flash attention with memory mapping to disk. The raw model size is a lie. The working set is reality.
Step 2 — The Q4_K_M configuration that actually works: --flash-attn --kv-cache-type q8 --ctx-size 2048 brings peak to ~15.8 GB with 0.2 GB headroom. Any system GPU memory pressure — browser tab, desktop compositor, Discord — triggers swap thrashing. tok/s collapses from 24.1 to <8. The margin is razor-thin. Close everything else or accept intermittent stutter.
Step 3 — Q5_K_M is not a 16 GB option without offloading. At 23.8 GB plus overhead, even Q8 KV and 1K context pushes to ~17.5 GB. Requires 4-6 layer CPU offload, which drops tok/s to 9-12. That eliminates the speed advantage over cloud API calls. You're running local for latency or privacy. CPU offload latency negates both. Don't do this.
Step 4 — Practical verdict: Default to Q4_K_M with constrained context. Or consider Qwen3.6-14B dense at Q6_K (13.8 GB) for higher per-token quality with MoE-level parameter count sacrificed. The 14B dense at Q6_K fits with breathing room, runs faster than offloaded MoE, and doesn't hallucinate APIs. For 16 GB users, "smaller model, higher quant" often beats "larger model, crippling quant."
24 GB: The Real Decision Point
Step 1 — Establish your context needs. 4K context is standard for document Q&A and multi-turn coding. Q4_K_M at 21.2 GB plus 4K KV cache (~3.6 GB FP16, ~1.8 GB Q8) plus overhead fits comfortably at 26-27 GB total. That leaves 1-2 GB for system on a 24 GB card. Know your actual prompt patterns before choosing quant.
Step 2 — Quality-vs-safety split. Q4_K_M with 4K context and Q8 KV is the "never think about it" default. Load and run. Q5_K_M with 2K context and FP16 KV gives better reasoning but requires monitoring context window. Choose based on whether your workflow regularly exceeds 2K. Paste long error logs? Document chunks? Multi-turn accumulation? Q4_K_M wins. Chat, quick functions, single-turn reasoning? Q5_K_M is cleaner.
Step 3 — The Q5_K_M upgrade path. If you find yourself trimming prompts to fit 2K, the 5.6 point GSM8K gain and recovered verification behavior is not worth the friction. Stay at Q4_K_M. If your prompts are naturally short, Q5_K_M is a clean upgrade with 13% speed cost. The discipline is the deciding factor, not the benchmark number.
Step 4 — When to push Q6_K. Only with tensor-parallel across two 24 GB cards (48 GB effective) or single A6000 48 GB. The 3.6 point direct-generation gain over Q5_K_M is marginal. For CoT-heavy workflows, the 6.4 point gain and 26.4 GB single-GPU fit makes it the "serious work" tier. Reported dual-4090 setups confirm this. The JSON-mode reliability improvement alone justifies the hardware for tool-use workflows.
48 GB and Beyond: Set-and-Forget Territory
Q8_0 at 32.8 GB on A100 40 GB or 48 GB consumer cards fits with headroom for 8K+ context, batching, or multiple concurrent sessions. The 0.6 point perplexity delta from F16 is indistinguishable in practice. This is the "reference implementation" tier — the quant you benchmark others against, not the quant you compromise with.
Q6_K at 26.4 GB is the efficiency play. When you need two model instances — Qwen3.6 for reasoning plus a second for code review — or 16K context for RAG, Q6_K leaves 20+ GB available versus Q8_0's 15 GB. The quality gap is 2.3 points on GSM8K. Usually worth the flexibility. Q6_K fits alongside an embedding model on a single A100 40 GB with room to spare — the VRAM math works out. Q8_0 would have forced serialization.
Multi-GPU tensor-parallel adds ~8-12% interconnect overhead on PCIe 4.0 x16 versus single-GPU. For Qwen3.6's latency-sensitive MoE routing — latency-sensitive by design — this overhead can mask the Q8_0 quality advantage on short-context tasks. A dual-4090 Q8_0 setup might underperform single-GPU Q6_K for one-line code completions. Benchmark your actual prompt pattern before committing to dual-GPU. Theoretical bandwidth doesn't equal practical routing speed.
The "Good Enough" Threshold: When Q4 Is Indistinguishable
Blind A/B testing by the r/LocalLLaMA community (n=34, Qwen3.6-235B-A22B, mixed chat prompts) produced a striking split: 58% could not distinguish Q4_K_M from Q8_0 on general conversation. Only 19% failed to distinguish them on code generation with visible syntax. The "indistinguishable" line is task-dependent, not universal. You cannot run one test and declare victory.
Perplexity delta of +0.34 (Q4_K_M) versus +0.03 (Q8_0) translates to different subjective experiences depending on workload. General chat tolerates +0.50+ before quality drop is noticed. Semantic coherence survives router noise. Code generation shows visible degradation at +0.20 due to structural sensitivity — bracket matching, API precision, exact token sequences that don't admit "close enough." The same quant feels invisible in one domain and broken in another.
The "Q4 is fine" consensus applies to specific workloads: single-turn Q&A, creative writing, summarization under 1K tokens, and emotional tone tasks. All share a property — router noise has minimal compounding, and exact token precision matters less than semantic coherence. The model can route to a slightly wrong expert and still produce acceptable prose. It cannot route to a slightly wrong expert and produce valid Python.
The "Q4 is not fine" boundary is equally specific: multi-turn technical discussion (>3 turns with context accumulation), any structured output (JSON, function calling), chain-of-thought reasoning, and code generation with >50 token outputs. These cross the threshold where expert loop errors become detectable within the first 10 responses. Context accumulation amplifies routing drift. Structured output demands exact syntax. Long generation gives the router more opportunities to lock into wrong patterns.
The Blind Test Methodology: How to Check Your Own Perception
Self-blinding prevents confirmation bias from VRAM anxiety or forum consensus. Your wallet wants Q4_K_M to be enough. Your workload might disagree. Test properly.
Step 1 — Set up identical prompts across two llama.cpp instances. Load Q4_K_M and Q8_0 with identical --temp 0.6 --seed 42 parameters. Use a script to strip quant filenames from output. Randomize presentation order. Label outputs "A" and "B" without tracking which is which. The goal is eliminating preconception, not confirming it.
Step 2 — Test categories separately. Run 20 prompts each for (a) casual chat, (b) factual recall, (c) code generation, (d) math word problems. Score each response 1-5 for "would use as-is without editing." Track quant correlation after unblinding. Most testers find their personal threshold differs by 1-2 quant levels across categories. My own testing showed Q4_K_M as fully acceptable for chat — indistinguishable from Q8_0 — but immediately obvious in code generation where API calls were invented or malformed.
Step 3 — Measure at your actual context length. The +0.34 perplexity delta is measured at 512-token context. At 4K context with accumulated KV cache quantization, effective delta rises to +0.52 for Q4_K_M. Test at 2K and 4K to find where your real usage crosses the line. A quant that passes at 512 tokens may fail at 4K. Router drift compounds across turns. KV cache compression adds noise on top of weight quantization.
Step 4 — Repeat after 30 minutes of real use. Fatigue and familiarity alter perception. A Q4_K_M response that seemed "fine" in isolation may accumulate friction after 10 turns. The blind test should include a "session simulation" — 5-10 related prompts on the same topic, with context preserved. This captures the compounding effect that single-shot tests miss. Users report rating Q4_K_M as "acceptable" on individual prompts and "unusable" after a simulated coding session where routing errors accumulated into wrong architecture decisions.
What "Good Enough" Actually Costs You
The hidden cost of "Q4 is fine" isn't immediate rejection. It's silent degradation. Expert loop errors in code generation don't always fail visibly. A function passes tests but uses suboptimal algorithmic complexity. A SQL query returns correct results but table-scans unnecessarily. These are debugging time bombs — discovered not when generated, but when production loads reveal performance cliffs or when a subtle semantic error surfaces three sprints later. The 52.7% HumanEval score looks like "mostly works." The reality is "works invisibly wrong."
Running Q4_K_M at 21.2 GB leaves 2.8 GB unused on RTX 4090. That headroom could host a 3B embedding model for RAG, a second Q4_K_M instance for parallel queries, or 8K context with FP16 KV cache. "Good enough" for one task means leaving performance on the table for your full workflow. We run a 3B embedding model alongside Qwen3.6 in that 2.8 GB on our test rig. The RAG pipeline answers questions the base model hallucinates. The combined setup outperforms Q8_0 alone for document Q&A. VRAM allocation is a design decision, not a binary "fits or doesn't fit."
Users who start with Q4_K_M and later discover they need Q5_K_M for a specific project face re-download (23.8 GB) and context re-establishment — re-tuning prompts, re-calibrating expectations, re-documenting behavior for collaborators. For intermittent code work, keeping both quants cached costs ~45 GB storage but eliminates the "should I upgrade?" friction entirely. It's a practical middle ground Power Users adopt. The storage is cheap. The context-switching cost is expensive. Keeping four quants of the same model around is the honest way to compare them over time. The disk space is irrelevant compared to the workflow continuity.
What to Run Right Now
The decision tree collapses to three variables: your GPU VRAM, your primary workload, and your tolerance for re-quantizing later. Most Power Users over-index on raw perplexity and under-index on workflow fit. They'll chase a +0.11 perplexity delta while ignoring that their 4K context prompts trigger OOM twice a day.
The default recommendation matrix is simple because the constraints are hard: 16 GB → Q4_K_M with flash attention and Q8 KV cache; 24 GB general use → Q4_K_M with 4K context; 24 GB code/reasoning → Q5_K_M with 2K context; 48 GB+ → Q6_K for efficiency or Q8_0 for reference-quality deployments. These aren't preferences. They're physics.
The "download both" strategy deserves consideration. Q4_K_M at 21.2 GB plus Q5_K_M at 23.8 GB equals 45 GB storage. Switch per-task without re-download. For users with fast NVMe and intermittent code workloads, this eliminates the "should I upgrade?" friction entirely. The model weights are identical. Only expert precision changes. Behavioral consistency is high.
Verification matters before you commit. Run llama-cli -m qwen3.6-235b-a22b-q4_k_m.gguf --flash-attn --kv-cache-type q8 -c 4096 -p "The capital of France is" and expect ~24 tok/s on RTX 4090, completion under 2 seconds. Diverge by >15% and you've got CPU fallback or memory-mapped layers stealing performance. Fix the setup before optimizing the quant.
The 5-Minute Setup Check
Step 1 — Confirm your actual free VRAM. nvidia-smi before launching shows available memory. Subtract 1.5 GB for desktop/compositor on Linux, 2.5 GB on Windows. This is your working budget, not the card's total. A "24 GB" RTX 4090 often presents 21-22 GB free before any model loads. Plan accordingly.
Step 2 — Verify flash attention is active. llama.cpp logs show "flash_attn: 1" at startup. Without it, Q4_K_M on 16 GB requires memory mapping. tok/s drops below interactive threshold. Recompile with LLAMA_CUDA=1 and LLAMA_FLASH_ATTN=1 if missing. The flag is not optional at tight VRAM margins — it's the difference between 24.1 tok/s and 8 tok/s.
Step 3 — Test your context ceiling. Start with -c 4096, generate 500 tokens, watch nvidia-smi peak. Hit 100% VRAM and step down to -c 2048 or enable --kv-cache-type q8. Q4_K_M at 4K with FP16 KV needs 25.8 GB, exceeding 24 GB cards. The ceiling isn't the model size. It's model plus KV cache plus overhead. Most users discover this only after OOM kills their session mid-generation.
Step 4 — Benchmark your actual workload. Run 10 representative prompts with --no-display-prompt and time the full response. Compare Q4_K_M vs Q5_K_M on your specific prompts. Community averages are directional. Your prompt patterns determine the real delta. A user generating 200-token chat responses sees different speed-quality trade-offs than one producing 800-token code blocks. Measure your reality, not someone else's.
The Decision Matrix: Copy This
| VRAM | Workload | Quant + Flags | tok/s | Key Metric |
|---|---|---|---|---|
| 16 GB | Any | Q4_K_M + --flash-attn --kv-cache-type q8 -c 2048 | 14-18 (4060 Ti), 18-22 (3080) | Only option without offload |
| 24 GB | Chat/summarization | Q4_K_M + --flash-attn -c 4096 | 24.1 | 2-3 GB headroom, "never think about it" |
| 24 GB | Code generation | Q5_K_M + --flash-attn -c 2048 | 21.3 | 61.2% HumanEval vs 52.7% at Q4_K_M |
| 24 GB | Reasoning/math | Q5_K_M minimum; Q6_K via tensor-parallel if second GPU | 21.3 / 18.7 | 76.8% GSM8K, verification-expert recovery |
| 48 GB | Single GPU | Q6_K (26.4 GB) or Q8_0 (32.8 GB) | 18.7 / 14.2 | Multi-instance flexibility vs reference quality |
| 48 GB+ | Multi-GPU | Q8_0 split across two 24 GB cards with tensor-parallel | ~13-15 (with 8-12% overhead) | Test actual prompt length; routing latency sensitive |
The 16 GB row is survival mode. Q4_K_M with constrained context, no alternatives without offload penalties that eliminate local inference advantages.
The 24 GB chat row is the default most users should start with. Q4_K_M at 4K context, 24.1 tok/s, headroom for system. Upgrade only when a specific workload proves deficient.
The 24 GB code row is where discipline pays. Q5_K_M with 2K context demands prompt management — trim error logs, chunk documents — but returns 8.5 HumanEval points and eliminates expert-loop API hallucinations. Worth it if you write or review code daily.
The 24 GB reasoning row acknowledges Q5_K_M as minimum, Q6_K as aspirational. The 5.6 point GSM8K gain over Q4_K_M is modest. The recovered verification behavior is transformative for multi-step reasoning. Trust matters more than throughput here.
The 48 GB single-GPU row is flexibility versus perfection. Q6_K at 26.4 GB leaves 20+ GB for second instances or long context. Q8_0 at 32.8 GB is "set and forget" reference quality. The 2.3 point GSM8K gap is usually less important than headroom for batching or RAG pipelines.
The 48 GB+ multi-GPU row carries a warning. Tensor-parallel adds 8-12% interconnect latency on PCIe 4.0 x16. For Qwen3.6's latency-sensitive MoE routing, this overhead can mask Q8_0's quality advantage on short-context tasks. A dual-4090 Q8_0 setup may underperform single-GPU Q6_K for one-line completions. Benchmark your actual prompt pattern before committing. Theoretical bandwidth doesn't equal practical routing speed.
When to Re-Quantize vs When to Switch Models
Re-quantize within Qwen3.6 when your workflow shifts temporarily. A week of heavy coding justifies downloading Q5_K_M, but keep Q4_K_M for general chat. Model weights are identical. Only expert precision changes. Behavioral consistency is high. You won't re-tune prompts or re-learn personality. The quant switch is transparent except where routing precision matters.
Switch models entirely at 12 GB. Qwen3.6-14B dense at Q8_0 (11.2 GB) outperforms Qwen3.6-235B-A22B at Q3_K_M (~14.8 GB) on every benchmark except raw parameter count. The MoE routing degradation at low quants eliminates the theoretical advantage. Dense 14B at Q8_0 generates cleaner code, more reliable reasoning, and doesn't hallucinate APIs. Parameter count is a vanity metric when the routing is broken.
Consider Qwen3.6-30B-A3B (3B active / 30B total) at Q4_K_M ≈ 19.2 GB for 24 GB cards needing long context. It fits with 4K+ context headroom, runs 22-24 tok/s, and the smaller active parameter count reduces routing noise. A "hidden option" between dense 14B and full 235B MoE. The 3B active count means less expert diversity — fewer specialists to route between — but also less opportunity for routing error. For document Q&A and summarization where breadth beats depth, this variant often outperforms the full MoE at constrained quants.
For more on K-quant mechanics and why expert weights compress differently than routing gates, see our deep dive. If you're deciding between Qwen3.6 and other architectures, our MoE architecture breakdown explains why the 32B active / 235B total design creates unique quantization behavior. And when you're ready to tune performance, our llama.cpp tuning guide covers flash attention, KV cache quantization, and memory mapping in detail.