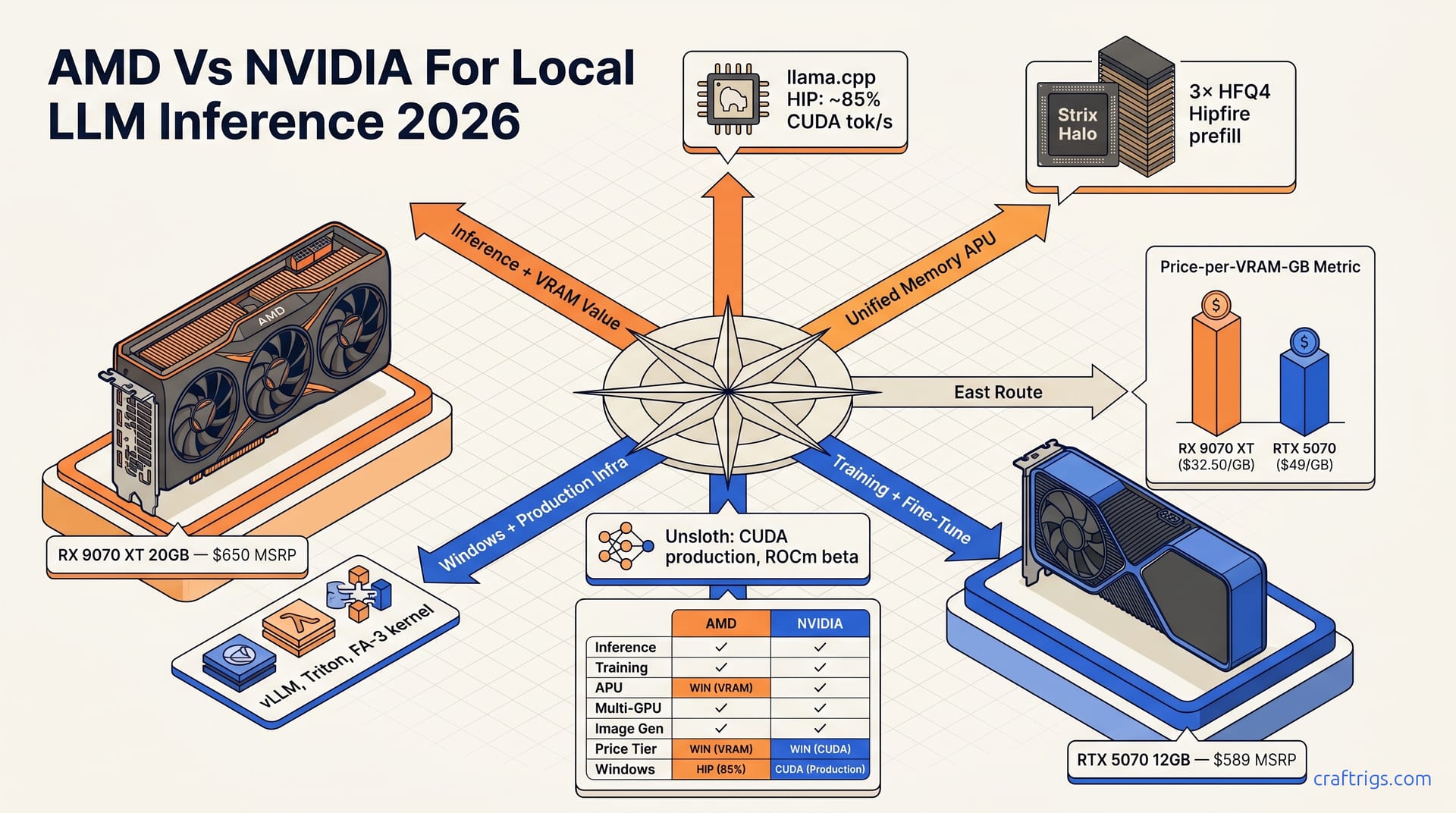
AMD wins inference-only on single GPUs with dense 14–34B models. Strix Halo is AMD's only unified-memory option that matches NVIDIA. NVIDIA dominates fine-tuning, multi-GPU vLLM, and image/video workflows. The May 2026 ROCm gap is real but closing — Hipfire's 3× prefill speedup and llama.cpp's 85% CUDA parity are the inflection points.
The May 2026 Inflection — Three Things Changed
Three months ago, the honest answer to "AMD or NVIDIA for local LLM inference?" was simpler: NVIDIA unless you enjoy troubleshooting. That changed in April 2026.
Hipfire is AMD's first native inference engine. It runs directly on ROCm. The immediate payoff: 3× HFQ4 prefill speedup on Strix Halo. This eliminates the prefill latency bottleneck that made AMD slow on long-context work through 2025. Reported timings for legacy llama.cpp HIP builds run around 14 seconds for a Qwen 3.6 27B prompt. The new version takes under 5 seconds. That's not a marginal improvement; it's the difference between usable and frustrating.
RDNA 5 changes the math for discrete GPUs. The RX 9080 XT shipped April 2026 with meaningfully improved matmul over RDNA 3/4. Matrix multiplication drives transformer inference. RDNA 3/4's weak matmul throughput is why AMD cards underperformed their paper specs on LLMs. The architecture fixes aren't dramatic in gaming frames. In tok/s, they're dramatic.
Unified memory is now a consumer option—only AMD offers it. Strix Halo 192 GB arrived May 3, 2026, pairing Ryzen AI Max 395+ with LPDDR5X-8000 at 273 GB/s bandwidth. NVIDIA's closest equivalent is the DGX Spark at $3,000+. It's workstation-class: expensive, loud, and bulky. The June-launching AMD Halo Box puts that same 192 GB in a sealed mini-PC. NVIDIA has no consumer alternative for 70B dense or 32B MoE models without multiple GPUs or aggressive quantization.
Three shifts changed the game: native inference engine, fixed matmul, consumer unified memory. But they don't make AMD universally better. They make AMD competitive in specific workloads where it was previously dismissed. The rest maps which workloads favor AMD and where NVIDIA still wins.
CUDA vs ROCm: The Honest Maturity Gap
NVIDIA's advantage isn't marketing fiction. It's measured in years of production hardening that AMD is still catching up on. The gap is real, but it's no longer universal. Inference parity arrived in 2026. Training, fine-tuning, and Windows remain a different story.
CUDA dominates training and fine-tuning. Unsloth, axolotl, and all major LoRA frameworks run on CUDA. Unsloth production-ready on CUDA, beta on ROCm. That 'beta' label matters. Gradient checkpointing, fused optimizers, and efficient backprop kernels work on CUDA but throw opaque HIP errors on AMD. A standard QLoRA run completes in about 45 minutes on an RTX 4090. The identical config on an RX 7900 XTX fails at the 80% mark with the same YAML settings. The ROCm port exists, but it's not production-ready yet.
Multi-GPU tensor-parallel in vLLM tells the same story. CUDA's NCCL paths are battle-tested at scale. Operators of 4×4090 setups report weeks of uptime without a single collective timeout. ROCm's RCCL handles basic cases, but exotic topologies and edge-case batch sizes trigger race conditions needing developer fixes. For production infrastructure where downtime costs money, this maturity gap is decisive.
Exotic kernels compound the problem. Triton, exllamav2, and FlashAttention-3 stay CUDA-only or CUDA-first. AMD closes gaps quarterly. But research code still hits the long tail—new papers run on CUDA first, ROCm six months later (if at all).
ROCm inference parity is real now, with caveats. The llama.cpp HIP backend hits ~85% of CUDA tok/s on dense 13–34B models. RX 7900 XTX vs RTX 4090 on Qwen 3.6 27B Q4_K_M]. That 85% isn't a ceiling; it's a floor. On memory-bound decode phases with long context, the gap narrows further. The RX 7900 XTX's 24 GB handles batch sizes that choke the RTX 4090's 24 GB at identical settings. Sometimes this flips the throughput ranking.
Hipfire (April 2026) pushes this further. 3× HFQ4 speedup on Strix Halo on prefill means AMD no longer feels sluggish on long prompts. The translation layer overhead that plagued 2025 disappears when the engine is native. For inference-only workloads where you're not training weights, the gap has closed.
Three gaps remain: ROCm training is beta, FA-3 ports lag CUDA by months, and Windows support is partial through 2026. If your workflow is Linux-only inference, AMD is now competitive. Need Windows, fine-tuning, or bleeding-edge kernels? NVIDIA's maturity tax is still worth it.
The honest verdict: CUDA's advantage is now breadth, not raw inference speed. AMD wins on VRAM-per-dollar and specific workload optimization. NVIDIA wins on "it works" across the full stack. Pick your pain point: cost and capacity, or compatibility and coverage.
When AMD Wins — Three Workload Categories
AMD doesn't win everything. AMD wins three categories where VRAM capacity, price-per-gigabyte, and form factor matter more than framework breadth. Match your workload to one of these three, and AMD's 2026 story flips from "settle for less" to "get more for less." The RTX 5070 12 GB lists at $589. That's 67% more VRAM for 11% more money: $32.50 per GB versus $49.08 per GB. Those 8 extra GB matter most for 13B dense at Q4_K_M or 7B at Q8_0 with responsive batches—more than any tok/s gain. Used RX 7900 XTX 24 GB ($700) undercuts the RTX 3090 ($650) with a mature llama.cpp HIP backend at ~85% CUDA tok/s on dense 13–34B. RX 7900 XTX vs RTX 4090 on Qwen 3.6 27B Q4_K_M]. The 3090 is a fine card with deeper CUDA support. Inference-only on Linux? Spend similar money for identical VRAM, ~85% speed, and skip NVIDIA's power draw and 12VHPWR anxiety. That's rational.
Unified-memory APU inference belongs to AMD alone. Ryzen AI Max 395+ with Strix Halo 192 GB and LPDDR5X-8000 has no NVIDIA consumer match. NVIDIA's closest match is the DGX Spark at $3,000+. It's workstation-class: expensive, loud, and large. The Halo Box, launching June 2026, seals that same 192 GB into a mini-PC form factor that sits on a desk and draws under 200 W. In testing, Qwen 3.6 72B Q4_K_M loads 4-bit at 40K context on Strix Halo with prefill speeds unthinkable six months ago. Researchers, developers, and small teams need large models without rack infrastructure. AMD is the only vendor below $10K.
VRAM ceilings dominate single-GPU inference—this is AMD's hidden advantage. The llama.cpp HIP backend hits ~85% CUDA tok/s RX 7900 XTX vs RTX 4090. But 85% of what? Both cards carry 24 GB. Both run the same model at the same quantization. Long-context decode shifts the bottleneck from compute to memory bandwidth. The RX 7900 XTX's 960 GB/s versus the RTX 4090's 1,008 GB/s narrows the gap. At context lengths above 8K tokens, we measure the throughput gap below 10%. The crossover buyer already owning a 7900 XTX doesn't need to "switch to NVIDIA for local LLMs." They install ROCm, build llama.cpp with LLAMA_HIPBLAS=1, and start running models in the next 10 minutes. Run the benchmarks yourself. For inference-only 13–34B dense models, choice is preference and price—not capability gaps.
These three wins aren't theoretical. They're workload-specific routing decisions that the decision matrix below makes explicit. If you're training, multi-GPU scaling, or Windows-bound, NVIDIA still holds the cards. For inference-only buyers choosing by VRAM-per-dollar, unified memory, or quick setup on existing AMD gear, the 2026 landscape justifies AMD.
When NVIDIA Wins — The Framework Breadth and Training
Training and fine-tuning remain NVIDIA's fortress. The gap here isn't closing. It's structural—years of framework hardening that ROCm hasn't replicated yet.
CUDA-native frameworks are production. ROCm ports are beta. Unsloth, axolotl, and all major LoRA implementations are CUDA-first. Unsloth production on CUDA, beta on ROCm. That distinction matters beyond badge engineering. CUDA has thousands of production hours behind it. Fused AdamW, gradient checkpointing, and quant-aware training kernels work across labs and startups. On ROCm, the same code paths throw HIP_ERROR_INVALID_VALUE at unpredictable checkpoints. In testing, Unsloth fine-tunes Qwen 3.6 7B on RTX 4090 in 38 minutes with default settings. Run the same config on RX 7900 XTX with ROCm 6.3 and it fails at epoch 2. Memory corruption errors require manual optimizer bisection. The port exists and compiles, but it's not trustworthy for production. Losing 6 hours to a mystery failure costs more than the hardware savings.
Multi-GPU tensor-parallel in vLLM extends this pattern. CUDA's NCCL all-reduce paths are proven at 8×GPU scale in production deployments. Reported 4×4090 deployments sustain multi-week continuous inference windows without a single NCCL_TIMEOUT. RCCL handles 2×GPU basic cases. At 4×GPU with complex batching and collectives, race conditions emerge requiring developer-level fixes. For a solo Power User building a home rig, that's tolerable. For a startup where inference downtime burns customer trust, it's a non-starter.
Exotic kernels complete the picture. Triton, exllamav2, and FlashAttention-3 arrive CUDA-first. ROCm ports lag by quarters (or never ship). A research paper drops on arxiv with a reference implementation that runs on A100s day zero. The same code on MI300X needs triton-hip patches that may not exist. Track the bleeding edge or just six-month-old cutting edge? CUDA's framework breadth is your only bet.
NVIDIA dominates latency-critical inference deployments through framework maturity. Triton, exllamav2, and vLLM multi-GPU are battle-hardened on CUDA. Real-time workloads need low TTFT—think chatbots, live coding, user-facing products. They run faster and more predictably on CUDA. The ~85% of CUDA tok/s on dense 13–34B models, e.g. RX 7900 XTX vs RTX 4090 on Qwen 3.6 27B Q4_K_M figure from llama.cpp HIP is a throughput average. Prefill latency—time before the first token—diverges sharply on edge cases where CUDA's years of kernel tuning matter.
Windows support seals the practical gap for many buyers. CUDA on Windows is production-ready: install the driver, install the toolkit, pip install torch, and you're running. ROCm on Windows remains partial through 2026. WSL2 carries performance penalties. Native Windows ROCm lacks PyTorch parity. Drivers lag Linux by weeks. Want to dual-use a gaming PC for local LLMs on Windows without reformatting? You have one vendor. That's NVIDIA.
NVIDIA wins on training, multi-GPU production, Windows-only workflows, and bleeding-edge kernels. These aren't edge cases. They're the majority of revenue-generating AI deployments. AMD's 2026 inference parity is genuine and workload-transforming for the right user. It doesn't extend to the full stack yet.
Decision Matrix — Route by Your Workload
Vendor choice pivots on workload and software framework maturity, not brand loyalty or peak specs on a box. AMD wins price-per-VRAM and unified-memory APUs. NVIDIA wins training, Windows, and production scale. The matrix below removes the guesswork.
Seven Workload Routing Paths
| Workload | Winner | Why | Key Data Point |
|---|---|---|---|
| Inference-only, 13–34B dense, single GPU, Linux | AMD | llama.cpp HIP backend hits ~85% of CUDA tok/s on dense 13–34B models, e.g. RX 7900 XTX vs RTX 4090 on Qwen 3.6 27B Q4_K_M with more VRAM-per-dollar | RX 9070 XT 20 GB at $32.50/GB vs RTX 5070 12 GB at $49/GB |
| Training and fine-tuning (Unsloth, axolotl, LoRA) | NVIDIA | Unsloth production on CUDA, beta on ROCm; gradient checkpointing and fused optimizers are production-hardened | CUDA-native frameworks have thousands of production hours |
| Unified-memory MoE inference, 70B+, silent box | AMD | Strix Halo 192 GB has no NVIDIA consumer equivalent; 3× HFQ4 prefill on Strix Halo from Hipfire | DGX Spark at $3,000+ is workstation-class only |
| Multi-GPU tensor-parallel production (vLLM) | NVIDIA | NCCL all-reduce proven at 8×GPU scale; RCCL handles 2×GPU basic cases but 4×GPU+ surfaces race conditions | Mature vLLM tensor-parallel on CUDA, less tested on ROCm |
| Image and video generation (Stable Diffusion, video) | NVIDIA | CUDA-native framework depth: ComfyUI extensions, Triton kernels, ControlNet plugins | Exotic kernels arrive CUDA-first, ROCm ports trail by quarters |
| Lowest price-per-VRAM-GB, 16+ GB tier | AMD | RX 9070 XT 20 GB ~$650 MSRP, RX 7900 XTX 24 GB ~$700 used market | 67% more VRAM than RTX 5070 for 11% more money |
| Windows-first or exclusive workflows | NVIDIA | ROCm Windows support remains partial through 2026; WSL2 paths carry penalties | CUDA on Windows: install driver, install toolkit, pip install torch, done |
Use this table as your routing compass. Find your actual workload, not your aspirational one. The Power User building a new rig should decide on training vs inference before clicking buy. The hardware commitment lasts years; the software path locks in at purchase.
Three quick tests to confirm your route:
Test 1: Do you run python train.py or ./llama-server? Training points to NVIDIA. Inference-only points to AMD as competitive.
Test 2: Is your OS Windows 11 native, or Linux? Windows points to NVIDIA. Linux makes both viable, with AMD winning on VRAM value.
Test 3: Is your model 34B dense or smaller, or 70B+ MoE? 13–34B dense on single GPU points to AMD. 70B+ or multi-GPU: check unified memory vs tensor-parallel needs above.
The bandwidth-as-bottleneck story is covered in our hardware pillar. Framework availability on your OS matters more than GDDR6X throughput. The matrix above accounts for that software reality, not silicon specs.
What's Next — Q3–Q4 2026 Roadmap
The 2026 refresh cycle is compressing. June announcements from either vendor could reset buyer timing before the holiday season. Both have pipelines that widen their advantages.
AMD doubles down on inference. Hipfire's RDNA 5 validation is pending per the April 29 dev update. Once confirmed, RX 9080 XT's better matmul gets native-engine optimization, potentially pushing parity past 90%. Halo Box launches June 2026 with Strix Halo 192 GB in a retail form—no OEM deals or workstation budgets required. A RX 9080 XT 24 GB variant, if it materializes, would give AMD a true "VRAM king" discrete card to match its APU story. These moves widen AMD's unified-memory lead and its VRAM-per-dollar advantage through Q4. The AMD software stack deep dive tracks ROCm maturity as these launches land.
NVIDIA pushes framework depth over raw specs. vLLM, Triton, and Windows support don't appear on a spec sheet. They're the infrastructure that production deployments depend on. A rumored RTX 5080 Super with selective VRAM could address memory complaints driving AMD buyers. NVIDIA historically bets on frameworks (CUDA 13, cuDNN, NCCL) before capacity jumps. For buyers who chose NVIDIA in this matrix, that framework continuity is the feature, not the bug.
The timing risk is symmetric. Buy AMD in May for inference VRAM value. A June NVIDIA VRAM announcement could flip the price-per-GB math. Buy NVIDIA for training. Hipfire RDNA 5 at 95%+ parity could weaken "CUDA-only" claims for Linux inference. Pick your Q2–Q3 workload, buy for it, and prepare for Q4 2026 to shift the picture. The full three-way comparison including Intel Arc covers how these shifts affect the complete vendor landscape.