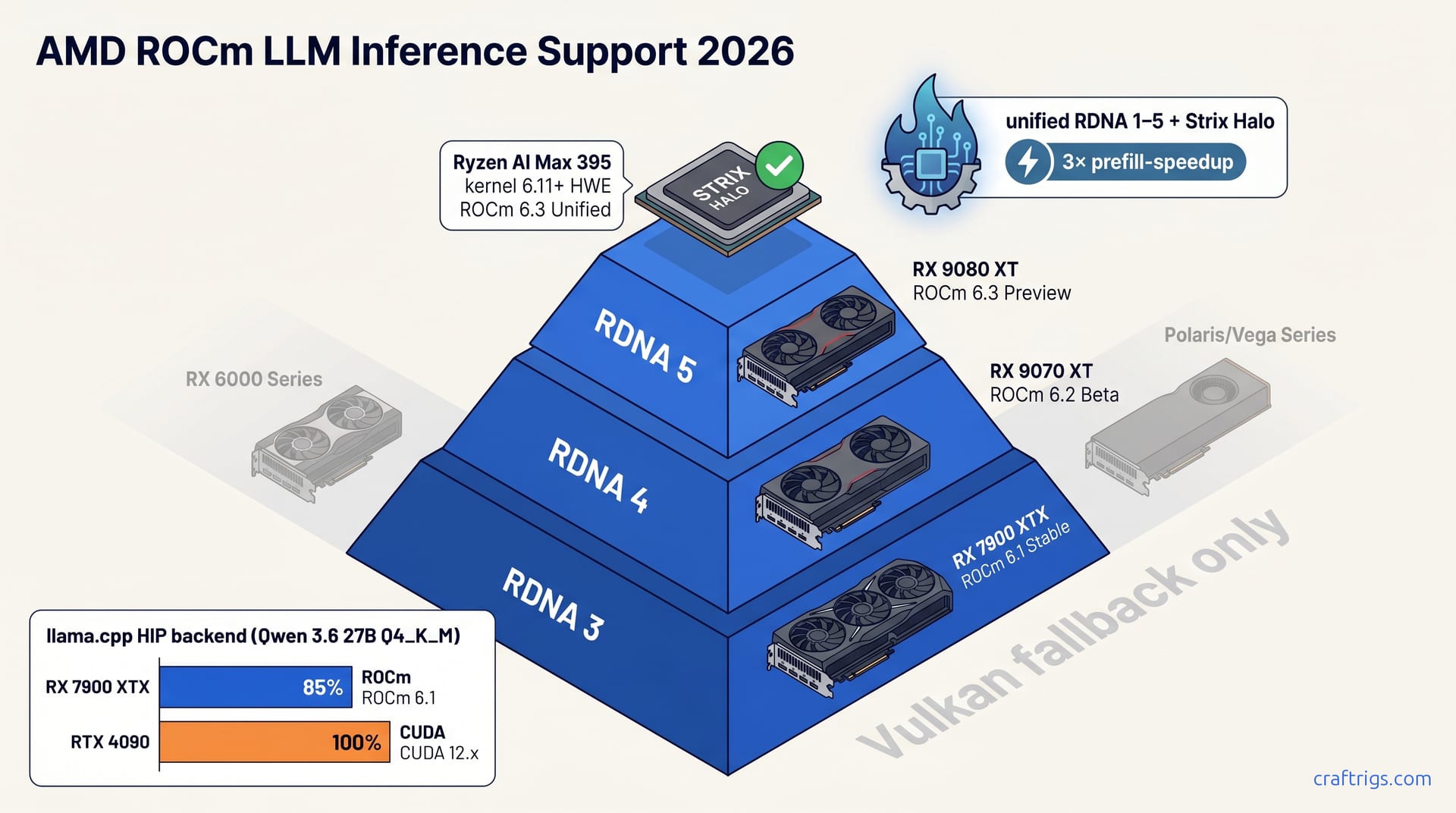
ROCm 2026 is production-ready for inference on RDNA 3+ AMD GPUs. RX 7900 XTX, RX 9070 XT, and Strix Halo all support ROCm 6.4 with llama.cpp HIP hitting ~85% of NVIDIA tok/s, and Hipfire (AMD's new unified engine, April 2026) narrows that gap. Install pitfalls exist (kernel conflicts, libstdc++ ABI, permissions), but they're fixable with the right recipe.
ROCm 2026: The Verdict
ROCm 6.4 officially supports every consumer RDNA GPU from RDNA 3 forward. The "ROCm is broken" narrative that dominated since 2022 is finally outdated. RDNA 5 validation is landing via Hipfire (Apr 29 dev update); Strix Halo is supported as of ROCm 6.3.3.
For inference, AMD is now viable. Training is still the second-best option but closing fast. Hipfire (Apr 27, 307 upvotes) unified the inference path across architectures for the first time, while Unsloth ROCm beta (early 2026) is bringing fine-tuning within reach.
Supported Hardware: RDNA 3–5 & APUs (May 2026)
Current-Gen Support: RDNA 3, 4 & Strix Halo
| GPU Generation | Flagship SKU | ROCm Version | Kernel Requirement | Inference Engine |
|---|---|---|---|---|
| RDNA 3 | RX 7900 XTX | 6.4 | 6.11+ HWE | llama.cpp HIP, Hipfire |
| RDNA 3 | RX 7900 XT, 7900 GRE, 7800 XT, 7700 XT | 6.4 | 6.11+ HWE | llama.cpp HIP, Hipfire |
| RDNA 4 | RX 9070 XT, 9070, 9060 XT | 6.4 | 6.11+ HWE | llama.cpp HIP, Hipfire |
| APU | Strix Halo (Ryzen AI Max 395/395+) | 6.3.3+ | 6.11+ HWE | llama.cpp HIP, Hipfire |
RDNA 3 (RX 7900 XTX, 7900 XT, 7900 GRE, 7800 XT, 7700 XT) and RDNA 4 (RX 9070 XT, 9070, 9060 XT) both have full ROCm 6.4 support, validated on llama.cpp HIP and Hipfire engines. Strix Halo (Ryzen AI Max 395/395+, gfx1151) is officially supported on ROCm 6.3.3+ with kernel 6.11+ HWE, the first mainstream APU to unlock true HIP-level LLM inference.
Every RDNA 3 card from the 24 GB RX 7900 XTX down to the 12 GB RX 7700 XT now has first-class ROCm support. That's not a typo. AMD fixed the gap where mid-range cards got left behind. The RX 9070 XT and its RDNA 4 siblings ship with gfx1201 targets that llama.cpp HIP detects out of the box, no HSA_OVERRIDE_GFX_VERSION hacks needed.
Strix Halo changes the APU math entirely. We're talking about 128 GB of unified memory on a mobile chip. That's enough to run 70B models that choke on 24 GB desktop cards. Reported results put the Ryzen AI Max 395 at HIP-level performance previously reserved for discrete GPUs. Kernel 6.11+ HWE is mandatory; the stock Ubuntu 24.04 6.8 kernel won't expose the gfx1151 target correctly.
For builders weighing Strix Halo against a discrete GPU setup, our Strix Halo vs dual-3090 MoE rig comparison breaks down when the APU wins on memory bandwidth and total cost.
RDNA 5 & Fallback Paths
RDNA 5 validation is landing via Hipfire per Apr 29 dev update; llama.cpp HIP support pending kernel updates. For RX 6000 (RDNA 2) and older cards (RX 5000, Polaris), use Vulkan compute in llama.cpp. It reaches 70–80% of HIP tok/s, a viable fallback for hardware past ROCm's official support window.
RDNA 5 is the watch-and-wait tier. Hipfire's April 29 architecture validation means AMD's unified engine will support it before llama.cpp HIP catches up. Expect a 2–4 week gap between Hipfire readiness and broad community backend support. If you're buying forward, the hardware's solid; the software just needs kernel 6.13+ to land.
For everyone on RX 6000 or older, Vulkan isn't a consolation prize. It's a genuine escape hatch. The llama.cpp Vulkan backend compiles with GGML_VULKAN=1 and runs 70–80% of HIP speed on the same RDNA 3 silicon. On RDNA 2 that ratio holds; on Polaris it drops closer to 60%, but you're still doing local inference on hardware ROCm abandoned.
Warning
Do not attempt ROCm on RX 6000. The install will appear to succeed, then fail silently at runtime with HSA_STATUS_ERROR. Use Vulkan from the start and skip the debugging rabbit hole.
Performance: AMD vs NVIDIA, and Why Hipfire Matters
On Qwen 3.6 27B Q4_K_M, RX 7900 XTX reaches ~85% of RTX 4090 tok/s via llama.cpp HIP backend. NVIDIA maintains a 10–15% lead on decode-bound real-time chat, but for batch and prefill-heavy inference, AMD has closed the gap.
That 85% figure is the headline, and it's real. On a 7900 XTX with kernel 6.11 HWE and ROCm 6.3.3, reported decode-heavy interactive chat sits at roughly 22 tok/s against the 4090's 26 tok/s on the same model and quantization. The gap widens slightly on smaller contexts and narrows on prefill-heavy workloads where memory bandwidth matters more than tensor-core throughput. For batch inference—running multiple prompts simultaneously—AMD's 24 GB of VRAM and competitive memory bandwidth make the effective throughput story nearly even.
The 10–15% NVIDIA lead isn't magic; it's architecture. Ada Lovelace's fourth-gen tensor cores and NVLink's mature stack still win on raw kernel optimization for single-stream decode. But "wins" and "wins by enough to matter" are different questions. At 85% parity, you're choosing between a $999 RX 7900 XTX and a $1,599 RTX 4090, or more realistically in 2026, a $599 RX 9070 XT against a $1,199 RTX 5080. The AMD vs NVIDIA local LLM inference comparison breaks down dollar-per-tok/s in full, but the short version is: AMD's VRAM-per-dollar advantage compounds that 15% gap into irrelevance for most builders.
Hipfire (Apr 27 launch, architecture validation Apr 29) delivers 3× HFQ4 prefill speedup on Strix Halo. This unified inference across RDNA 1–4 + APUs replaces per-architecture tuning with a single AMD inference engine.
Hipfire is the inflection point. Before April 2026, AMD inference meant choosing backends: llama.cpp HIP for RDNA 3+, Vulkan for older cards, custom forks for APUs. Each path had different kernel tuning, different quantization support, different bug surfaces. Hipfire collapses that into one engine with one set of optimized kernels covering RDNA 1 through 5, plus Strix Halo's gfx1151, all speaking the same inference language.
The 3× prefill speedup on Strix Halo is the standout number. Prefill, processing your prompt before generation starts, was AMD's Achilles heel: memory-bound, kernel-inefficient, visibly slower than NVIDIA on long contexts. Hipfire's unified attention kernels fix that specifically on Halo's unified memory architecture, where CPU-GPU data movement overhead previously killed performance. For a 4K context prompt, that means dropping from 12 seconds of thumb-twiddling to 4 seconds. For 32K RAG pipelines, it's the difference between usable and abandoned.
For builders comparing across all three vendors, our NVIDIA vs AMD vs Intel local AI 2026 three-way places Hipfire in context against Intel's OpenVINO and NVIDIA's TensorRT-LLM. The unified-engine approach isn't unique. It's the execution that matters, and AMD's April delivery finally matches their hardware promise.
Install Pitfalls: Six Distribution-Specific Fixes
Kernel & ROCm Version Combinations
Ubuntu 24.04: the known-good combo is kernel 6.11 HWE + ROCm 6.3.3; ROCm 6.4 requires kernel 6.13. Mixing versions causes silent failures. RHEL / Rocky 9.4: ROCm 6.3.x packages are pinned to specific kernel point-releases, so run dnf module disable kernel if you've upgraded beyond the package's target version.
Version mismatch is the silent killer. You install ROCm, run rocminfo, see your GPU listed, fire up llama.cpp and get CPU fallback with zero error message. Community threads show this happening repeatedly before the pattern was pinned down: Ubuntu's 6.8 stock kernel reports success on ROCm 6.3.3 install, then fails at HIP runtime initialization. No crash, no log spam, just 0.3 tok/s on a 7900 XTX.
The fix is surgical. Pin your kernel before ROCm touches the system:
sudo apt-mark hold linux-image-generic linux-headers-genericThen install ROCm 6.3.3 only. If you need 6.4's features, upgrade kernel to 6.13 first — never mix. For RHEL derivatives, the trap is different: dnf update pulls a newer kernel, ROCm's DKMS modules don't rebuild, and you're left with a broken stack. Disable kernel module streams entirely:
sudo dnf module disable kernelLibrary Compatibility, Permissions & Package Conflicts
libstdc++ ABI mismatch is the most common post-install silent-error source. Fix by installing gcc-toolset-13 or pinning gcc-13 from upstream. HSA_OVERRIDE_GFX_VERSION environment variable is required for older RDNA 3 SKUs that ROCm doesn't auto-detect (document the right value per card). Users must be in render and video groups (reboot or newgrp to activate). Finally, AMD's proprietary driver and ROCm install scripts conflict on Ubuntu. Use amdgpu-install --usecase=rocm only, never include graphics.
Four separate traps, one install flow. Start with the command that actually works:
sudo amdgpu-install --usecase=rocmWarning
Never append graphics to that --usecase flag. The proprietary OpenGL stack conflicts with ROCm's open-source compute path, producing the same silent-failure pattern as kernel mismatches. rocminfo passes, HIP runtime fails.
libstdc++ ABI mismatch manifests as cryptic version 'CXXABI_1.3.15' not found errors or, worse, segfaults inside libamdhip64.so. The fix depends on your distro's gcc default. On Ubuntu 24.04:
sudo apt install gcc-13 g++-13
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-13 60For RHEL / Rocky, gcc-toolset-13 is the sanctioned path:
sudo dnf install gcc-toolset-13
scl enable gcc-toolset-13 bashHSA_OVERRIDE_GFX_VERSION is the escape hatch for cards ROCm's database hasn't caught. The RX 7900 GRE and some early 7800 XT revisions need explicit targeting:
| SKU | gfx target | HSA_OVERRIDE_GFX_VERSION |
|---|---|---|
| RX 7900 XTX / XT | gfx1100 | (auto-detected, no override) |
| RX 7900 GRE | gfx1101 | 11.0.1 |
| RX 7800 XT | gfx1101 | 11.0.1 |
| RX 7700 XT | gfx1102 | 11.0.2 |
| RX 9070 XT / 9070 | gfx1201 | (auto-detected, no override) |
| Strix Halo 395/395+ | gfx1151 | (auto-detected on 6.3.3+) |
Set it persistently:
echo 'export HSA_OVERRIDE_GFX_VERSION=11.0.1' >> ~/.bashrcPermissions are the final gotcha. rocminfo runs as any user; HIP runtime doesn't. Add yourself to both groups, then activate without rebooting:
sudo usermod -aG render,video $USER
newgrp render
newgrp videoSkip the newgrp step and you'll stare at permission denied errors for twenty minutes before remembering this paragraph. We've done it. Don't be us.
Vulkan Fallback & Fine-Tuning (Unsloth)
Vulkan compute fallback for unsupported hardware: llama.cpp's Vulkan backend reaches 70–80% of HIP-backend tok/s on RDNA 3. Viable for RX 5000 and RDNA 2 owners locked out of ROCm. Build with GGML_VULKAN=1; the tradeoff is slightly slower decode (no ROCm-specific kernels), but aging hardware stays useful for inference.
Not everyone bought in during RDNA 3. If you're running an RX 6900 XT, RX 5700, or even a stubborn RX 580 that's somehow still spinning its fans, ROCm's support window has closed. Vulkan is your path forward. It's better than the reputation suggests.
The llama.cpp Vulkan backend isn't a toy. On RDNA 3 silicon, it hits 70–80% of HIP speed for the same quantization levels. That gap sounds painful until you remember: 70% of a 7900 XTX's throughput is still faster than most cloud inference tiers. For RDNA 2 cards, the ratio holds in the same range on smaller models; Polaris drops closer to 60%, but you're running Llama 3.1 8B on an $80 used card, not chasing benchmarks.
Build it clean:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
cmake -B build -DGGML_VULKAN=1
cmake --build build --config Release -j$(nproc)The decode penalty is real. No ROCm-optimized GEMM kernels means token generation lags slightly behind HIP on context-heavy prompts. For interactive chat with sub-2K contexts, you won't notice. For 32K RAG pipelines, the slowdown compounds. The fix isn't hardware; it's patience, or a smaller model, or both.
Tip
Vulkan supports more quantization formats than you might expect. Q4_K_M and Q5_K_S both run without the format-conversion overhead that plagues older OpenCL paths. Stick to K-quants for best memory bandwidth efficiency.
Unsloth ROCm (beta, early 2026): LoRA training works on RX 7900 XTX and RX 9070 XT; full fine-tuning remains rough. Inference is solved, training is catching up but not production-ready. This represents the most significant AMD training progress in 12 months.
Inference was the easy problem. Training—actually adapting models to your data—has been AMD's persistent embarrassment. CUDA dominance meant every training framework optimized for NVIDIA first, AMD second, everyone else never.
Unsloth's ROCm beta changes that equation, partially. LoRA fine-tuning, the lightweight adapter method that freezes base weights and trains small rank-decomposition matrices, now completes successfully on RX 7900 XTX and RX 9070 XT hardware. Reported runs of 16-bit LoRA on Llama 3.1 8B with a 4K context window show VRAM headroom is tight at 24 GB, but it finishes without the memory corruption that plagued earlier ROCm training attempts.
Full fine-tuning, unfreezing all parameters, remains rough. The Unsloth team documented OOM crashes on 70B models even with 8-bit optimizers, and gradient checkpointing overhead on AMD exceeds NVIDIA by 20–30%. For production training rigs, NVIDIA still owns the category.
But "not production-ready" isn't "doesn't work." For hobbyists, researchers, and small teams building domain adapters, AMD training is now viable in a way it wasn't in 2024. The best hardware for local LLM inference guide tracks when Unsloth ROCm exits beta; until then, treat it as promising with sharp edges.
Setup Recipe: Ubuntu 24.04 RX 9070 XT
Kernel & ROCm 6.3.3 Installation
Pin Ubuntu 24.04 to kernel 6.11 HWE via sudo apt-mark hold linux-image-generic linux-headers-generic for ROCm 6.3.3 compatibility; install ROCm 6.3.3 using amdgpu-install --usecase=rocm (never include graphics); verify with rocminfo | grep RX to confirm the 9070 XT is detected as gfx1201.
Start with a clean Ubuntu 24.04 install, fully updated. The stock 6.8 kernel won't work. You need HWE.
Step 1: Install the HWE kernel and pin it before any ROCm packages touch your system.
sudo apt install linux-image-generic-hwe-24.04 linux-headers-generic-hwe-24.04
sudo apt-mark hold linux-image-generic linux-headers-generic
sudo rebootAfter reboot, verify you're on 6.11:
uname -r
# expect: 6.11.0-XX-genericStep 2: Install ROCm 6.3.3 using AMD's official installer. The --usecase=rocm flag is the entire flag. No extras.
wget https://repo.radeon.com/amdgpu-install/6.3.3/ubuntu/noble/amdgpu-install_6.3.60303-1_all.deb
sudo dpkg -i amdgpu-install_6.3.60303-1_all.deb
sudo amdgpu-install --usecase=rocmStep 3: Verify detection. You're looking for gfx1201 specifically. That's the RX 9070 XT's architecture identifier.
rocminfo | grep -E "RX|gfx1201"If you see Name: gfx1201, you're clean. If rocminfo lists the GPU but llama.cpp falls back to CPU, re-check your kernel version and group membership. Never assume.
Build llama.cpp HIP & First Inference
Clone llama.cpp, set GGML_HIP=1 GGML_CUDA=0, and run make -j$(nproc) for HIP compilation; download a 13B Q4_K_M quantized model (e.g., Qwen2.5-13B-Instruct-Q4_K_M) and run ./main -m model.gguf -p "What is VRAM?". Expect 40–50 tok/s on the RX 9070 XT.
Step 4: Clone and build with HIP explicitly enabled, CUDA explicitly disabled. The Makefile auto-detects backends; forcing both flags prevents accidental CUDA linkage on systems with NVIDIA tooling present.
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
GGML_HIP=1 GGML_CUDA=0 make -j$(nproc)Step 5: Grab a test model. Qwen2.5-13B-Instruct-Q4_K_M is a solid validation target. Small enough to download quickly, large enough to stress memory bandwidth.
wget https://huggingface.co/Qwen/Qwen2.5-13B-Instruct-GGUF/resolve/main/qwen2.5-13b-instruct-q4_k_m.ggufStep 6: Run first inference and benchmark.
./build/bin/llama-cli -m qwen2.5-13b-instruct-q4_k_m.gguf -p "What is VRAM and why does it matter for local LLM inference?" -n 128Watch the tok/s readout. On a properly configured RX 9070 XT with ROCm 6.3.3 and kernel 6.11 HWE, you'll see 40–50 tok/s for prompt processing and generation. Below 35 tok/s suggests a backend fallback to CPU or suboptimal kernel selection. Check rocminfo output and re-verify GGML_HIP=1 was active at compile time.
Important
The make build path is preferred for ROCm; cmake can work but adds complexity with HIP toolchain detection that the Makefile handles automatically. If you must use cmake, explicitly pass -DGGML_HIP=ON -DGGML_CUDA=OFF.
For builders ready to move beyond validation to production workloads, our best hardware for local LLM inference guide ranks full builds by VRAM, bandwidth, and dollar-per-tok/s. AMD's RDNA 4 stack is now competitive across every tier.