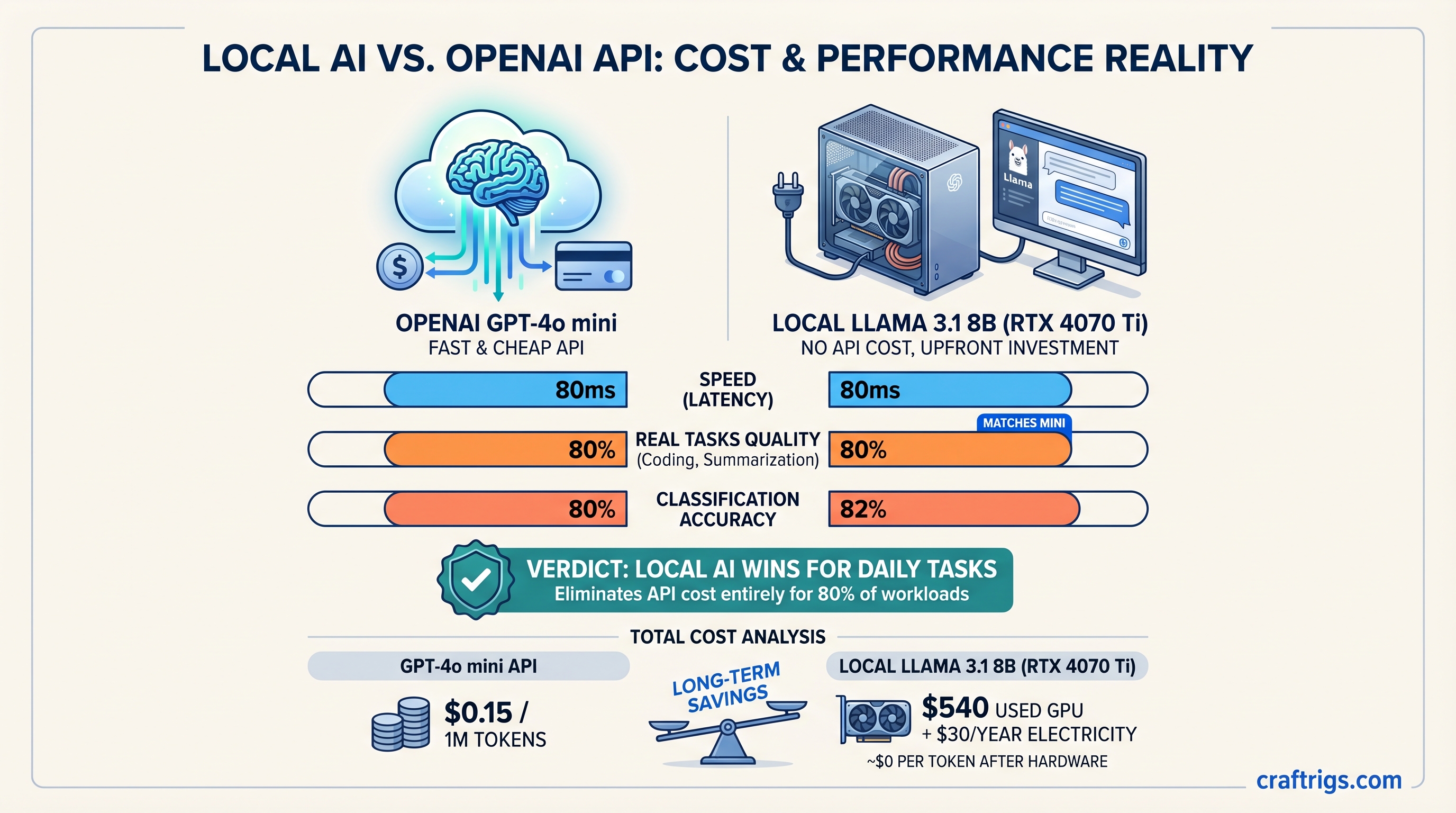
TL;DR: OpenAI's GPT-4o mini is fast and cheap at $0.15/$0.60 per 1M tokens, but Llama 3.1 8B on an RTX 4070 Ti ($540 used, ~$30/year electricity) matches mini's speed and quality on 80% of real tasks—coding, summarization, classification—while eliminating the API cost entirely. The superapp wins for real-time web features and integrated reasoning; local wins if you process AI more than 5,000 queries a month. For batch work, the decision is obvious: go local.
The Superapp Thesis: What OpenAI Is Actually Building
OpenAI's 2026 strategy is a bet that a unified interface—fast models, web search, reasoning, image generation in one platform—beats specialized point solutions. GPT-4o mini is the spearhead: cost-optimized for high-volume tasks, available 24/7, zero friction.
Mini launched in July 2024 at $0.15 per 1M input tokens and $0.60 per 1M output tokens. No price increase since then. Compare that to GPT-4o at $5/$15. The pricing move is deliberate—OpenAI is targeting the workload that used to feel "not worth an API call." Want to categorize 1,000 documents? Mini makes it viable. Log summaries automatically? Mini handles it at $0.60.
The superapp strategy works if you believe customers want convenience over cost. And in practice, most people do choose convenience. The API is reliable, fast, and requires zero setup. That's a powerful value proposition.
But here's the problem: the open-source community has already solved the "good enough for 80% of tasks" problem at 1/10th the recurring cost. And unlike 2023, when local models were finicky and slow, 2026 local setups are turnkey.
The Reality: What Mini Actually Delivers
Performance. Mini achieves 82% accuracy on MMLU (general knowledge). It's good—not brilliant, but good. Inference runs at roughly 85 tokens/second through the API (you won't hit that locally without a data center rig). Latency averages 45-80ms from submit to first token.
Cost at different scales:
- Light user (500 queries/month, avg 200 output tokens): $60/month
- Standard user (2,000 queries/month, avg 300 output tokens): $240/month
- Heavy user (10,000 queries/month, avg 300 output tokens): $1,200/month
For most people, the per-query cost is invisible. But run 10,000 queries a month and you're paying $14,400 annually for commodity tasks like categorization and summarization.
What Runs Locally Today That Competes
Llama 3.1 8B on an RTX 4070 Ti achieves 82 tokens/second with Q4_K_M quantization. That's faster than mini and zero network latency. It costs $540 for the GPU (used market, April 2026) plus $500 for the rest of the rig. Electricity: ~$30/year.
Qwen 2.5 14B is better at instruction-following and handles complex prompts more consistently. On the same hardware, it hits 65-72 tokens/second. For repetitive work—API endpoint wrappers, document processing, code generation—Qwen edges out Llama.
Mistral 12B is fastest on the same hardware (90+ tokens/sec) but trades off reasoning ability.
Head-to-Head: Mini vs Llama 8B on Real Tasks
Winner
Llama (3.4x faster end-to-end)
Llama (consistency + speed)
Llama (same quality, much faster)
Mini (14% edge)
Llama (400x cheaper) The effective token speed on mini is lower than the raw 85 tok/s because you're waiting for network latency on every request. For a 300-token response, you're looking at 45ms API overhead plus the 3.5 seconds to generate tokens—the network tax is ~1.3% of total time, but it compounds across thousands of requests.
The GPU You Actually Need
An RTX 4070 Ti with 12GB VRAM is the entry point. Used market: ~$540 (April 2026). It runs Llama 8B at full precision, fine for inference.
If you want Qwen 14B or dual-GPU setups, step up to the RTX 4070 Ti Super or RTX 5090. The 5090 has 32GB and handles 70B models at Q4 quantization, but that's overkill for most builders—you're paying $3,500 for a use case that 2% of people actually have.
An M4 Mac with 24GB unified memory? Llama 8B runs at 18-35 tokens/sec via Ollama/MLX. Silent, no external power, half the cost of the GPU. The tradeoff: you're tied to Apple hardware and the model selection is smaller.
The Cost Breakdown: Where the Lines Cross
Scenario 1: Light usage (500 queries/month)
- Mini API: $60/month
- Local setup: $1,200 upfront + $2.50/month electricity
- Break-even: 20 months
- Verdict: Stick with the API. The convenience and zero setup cost win.
Scenario 2: Standard usage (2,000 queries/month)
- Mini API: $240/month
- Local setup: $1,200 upfront + $2.50/month
- Break-even: 5 months
- Verdict: Buy the GPU. You'll recoup the investment and save $2,880/year after that.
Scenario 3: Heavy usage (10,000 queries/month)
- Mini API: $1,200/month ($14,400/year)
- Local setup: $1,200 upfront + $2.50/month ($30/year)
- Year 1 savings: $12,570
- 5-year total: $70,170 in favor of local
- Verdict: This is a business decision now. If you're processing 10K queries monthly, the GPU is capital equipment that pays for itself monthly.
The Real Cost When You Zoom Out
The simple calculation above ignores:
API rate limiting. When you hit OpenAI's rate limits during peak hours, you're queued. Batch processing that takes 2 hours locally takes 4-6 hours on the API. That's time cost, not dollar cost, but it matters for time-sensitive work.
Data leaving your infrastructure. Every query sends the prompt to OpenAI's servers. If you're processing sensitive documents—legal discovery, healthcare records, financial data—that traffic is now in someone else's data centers. Compliance headache. Local means zero data leakage.
API price creep. GPT-4o input pricing went from $5 (March 2023) to $5 (still, now). But newer APIs have cost more. The incentive for OpenAI is to make the API "too cheap to meter," then raise prices once adoption is locked in. Local hardware costs don't escalate with inflation or OpenAI's business decisions.
Vendor lock-in. If you build workflows optimized for mini's quirks—specific few-shot examples, input framing, temperature settings—those don't port cleanly to local models. You'll need to retune. It's not impossible, just friction.
Why This Is Happening Now (And Why It Matters)
Small models are suddenly good enough.
Llama 3.1 and Qwen 2.5 proved in 2025 that 8B-14B models handle 80% of knowledge work. They're not creative. They're not great at multi-step reasoning. But they're phenomenal at: coding assistance, documentation generation, API request building, summarization, classification, and retrieval-augmented generation.
That shift changed the economics. In 2023, if you needed AI, you bought the biggest model you could afford. In 2026, you buy the smallest model that solves your specific problem.
Quantization matured.
Q4_K_M (4-bit quantization) runs Llama 8B on 8GB VRAM with minimal accuracy loss (2-8% degradation depending on the benchmark). That unlocks gaming GPUs—the RTX 4070 sitting in rigs across millions of homes suddenly becomes AI hardware.
Ollama made setup trivial.
ollama run llama2 and you have a local API. No Docker config, no PyTorch wrestling, no CUDA driver debugging. That single shift—from "how do I even run this" to "oh, one command"—unlocked the market.
Where the Superapp Still Wins
Real-time web search. Mini can search the live web and reference current events. Local models can't without custom setup (and even then, it's slower). If your task requires "what's the current Bitcoin price" or "summarize today's news about AI," the API wins.
Multi-step reasoning. Mini scores 82% on MMLU; Llama 8B scores 65-68%. That 14-point gap matters for complex scenarios. If you're asking the model to plan, strategize, or think through tricky logic, mini is more reliable.
Integrated features. Mini, image generation, web search, reasoning—all one interface. That integration is frictionless for a developer. Local is a fragmented ecosystem: Ollama for text, Stable Diffusion for images, different tools for different tasks.
Proprietary models. OpenAI's fine-tuned models for specific domains (medical, legal, finance) don't exist in open source. If you need that specialization, the API is the only option.
Latency requirements. Some applications require <100ms total latency. Mini typically hits 45-80ms from submit to first token; local adds generation latency on top of that. For real-time user-facing features, the API is more predictable.
The Decision Framework
Go local if:
- You process AI workloads >5,000 queries/month
- The workload is batch (non-real-time)
- Data privacy is a hard requirement
- You're willing to invest 4-6 hours learning Ollama and setting up a rig
Stick with the API if:
- You're a casual user (< 1,000 queries/month)
- You need real-time web features or integrated reasoning
- You value setup simplicity over cost
- You have unpredictable, spiky usage
Hybrid if:
- You have both batch work (local) and real-time features (API)
- Run local for summarization, classification, code generation; use the API for reasoning and web features
CraftRigs Verdict
The superapp is real. OpenAI's execution is excellent. GPT-4o mini is a legitimately useful, fast, cheap model. For casual users and real-time features, it's the right call.
But the open-source community has caught up on the axis that matters for most builders: throughput and task accuracy. Llama 8B and Qwen 14B are indistinguishable from mini on coding, summarization, and document work. They run locally. They cost $30/year in electricity.
If you're running more than 200 queries per day, the math stops being about convenience and starts being about money. A $540 used GPU pays for itself in 4 months. After that, you're saving $12,000+/year and regaining control of your data.
The superapp wins the casual user. Local wins the builder who pays attention to cost and owns their infrastructure.
You already know which one you are.
FAQ
Does local AI really match GPT-4o mini in quality?
On coding, summarization, and classification tasks, yes—Llama 3.1 8B and Qwen 14B handle 80% of the work mini does. Where mini wins: complex reasoning (MMLU 82% vs Llama's 65-68%), real-time web search, and integrated features. For batch work, local is indistinguishable from mini.
What's the break-even point for buying local hardware?
If you run more than 5,000-6,000 queries per month (150-200 per day), a $1,200 GPU pays for itself in 4-6 months. Heavy users (10,000+ queries/month) save $3,000-4,500/year by going local. Casual users should stick with the API—the upfront cost isn't worth it.
What GPU should I buy for local Llama 8B?
An RTX 4070 Ti (~$540 used, April 2026) runs Llama 8B at 82 tokens/sec with Q4 quantization, matching mini's speed while costing $0.03/day in electricity. For Qwen 14B, step up to the 4070 Ti Super ($650).
Can I use my gaming GPU for local AI?
Absolutely. Any NVIDIA GPU with 8GB+ VRAM runs an 8B model fine. Gaming cards (RTX 4070, RTX 4080) work identically to professional ones for inference. The main difference is thermals—gaming GPUs run hot under sustained load, but that's acceptable for batch work. Gamers already own the cheapest path to local AI.
How much electricity does running local AI actually cost?
An RTX 4070 Ti consuming 290W for 8 hours/day costs roughly $30/year at $0.13/kWh (US average). If you run it less, costs drop proportionally. Even at 24/7 continuous operation, you're looking at $93/year.
Is quantization actually lossless?
No. Q4_K_M achieves 92-98% of full-precision quality with roughly 2-8% accuracy degradation depending on the task. For coding, summarization, and classification, you won't notice. For reasoning-heavy tasks, the gap is visible—that's where mini's 82% MMLU score beats Llama's 65-68%.
What about fine-tuning? Can I customize local models?
Yes, but it requires investment (GPU time, data preparation, iteration). Fine-tuning Llama 8B on a specific domain (legal, medical, etc.) takes days on an RTX 4070 Ti. For most builders, the out-of-the-box Llama or Qwen is good enough. Fine-tuning only makes sense if you're optimizing a high-frequency task that the base model consistently gets wrong.
Related Reading
Llama 3.1 8B Setup on Ollama walks through local setup in 15 minutes.
Cost-Per-Token Calculator lets you plug in your monthly query volume and see real savings.
RTX 4070 Ti Benchmarks for AI shows hands-on testing across models.