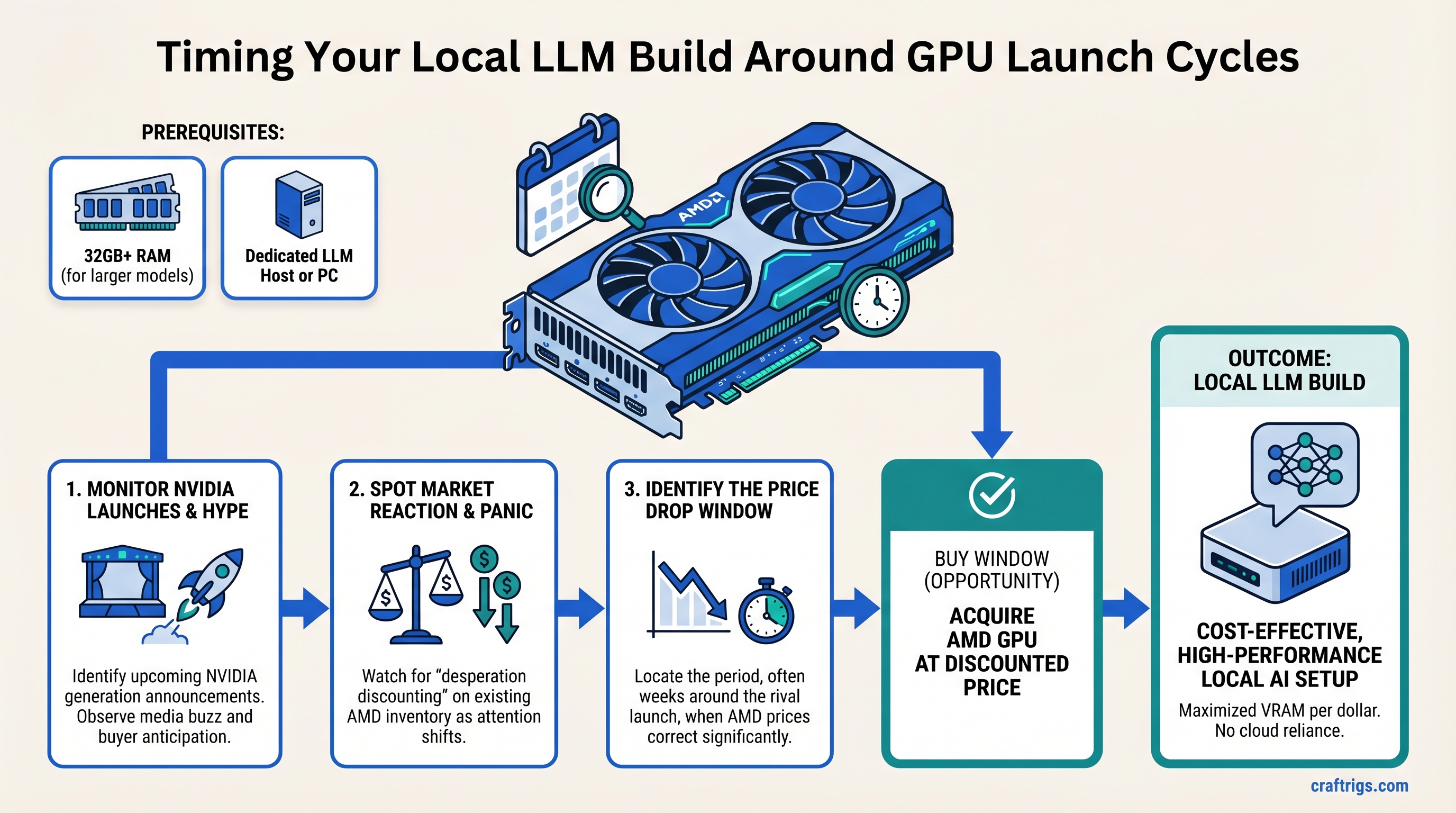
The GPU Market Timing Trap — And How to Escape It
Every GPU launch cycle follows the same pattern: panic buying on one side, desperation discounting on the other. NVIDIA announces a new generation, tech media hypes it relentlessly, and buyers either rush to grab the old stock or wait for the new thing—leaving a narrow window where competing brands actually become better value.
This is not a controversial take. It's how retail works. But most local LLM builders miss it entirely because they're not watching price movements across regions or understanding how launch timing actually shapes what's available and at what cost.
TL;DR: GPU market cycles create 3-6 week windows where prices correct faster than supply adjusts. If you're buying a local LLM rig in April 2026, you're sitting in one of those windows—and AMD cards are worth closer attention than usual. The catch: this window closes once major retailers get new NVIDIA stock and the panic-buying phase ends.
Why GPU Prices Don't Drop When You Expect Them To
Most people think GPU prices fall in a straight line. They don't. They wobble based on inventory, launch cycles, and regional supply chains.
Here's what actually happens:
-
Announcement phase (2-4 weeks out) — New generation announced, pre-orders open, existing stock gets marked up or held in reserve. Panic buying starts.
-
Launch day (day 1) — New cards sell out within hours. Old stock still premium. Competing brands see decreased demand, start cutting prices subtly.
-
The correction window (weeks 2-6 after launch) — Retailers haven't received enough new inventory to meet hype demand, but they've got competitor stock they need to move. This is when discounts happen. This is when you buy.
-
Normalization (6+ weeks out) — New generation supply catches up, panic subsides, prices stabilize at new levels. Window closes.
AMD doesn't dominate the local LLM market the way NVIDIA does. But that's actually why AMD benefits most during correction windows—their inventory sits deeper in retailer pipelines, untouched by the launch hype, and gets more aggressive price movement when margins need adjustment.
The April 2026 Window: Why Now Matters
We're currently in the tail end of a launch cycle. NVIDIA's Blackwell consumer lineup (RTX 5000-series) shipped in waves starting January 2025, with the RTX 5070 hitting retail in March 2025. That's over a year of market presence, stable supply, and normalized pricing.
What that means for AMD: their older-generation cards (RX 7000-series, specifically the 7900 XT and 7900 XTX) are now in the "competing inventory that retailers want to move" category. They're not new. They're not on anyone's hype list. But they're still viable for local LLM inference, and the price-to-performance they offer in April 2026 is worth examining.
Regional data suggests AMD pricing has corrected more aggressively in some markets than others—Japan's retail markets typically move faster than US markets—but the broader pattern is consistent: AMD cards are seeing downward pressure that you're unlikely to see again until the next generation launches (estimated late 2026 for RX 8000-series).
AMD Cards Worth Considering Right Now
Let's ground this in actual specs and what they mean for local LLMs.
RX 7900 XT — The Current Sweet Spot
Specs: 20GB GDDR6, 384-bit bus, 2.5 GHz boost Current pricing: Used/eBay ~$590-650; new retail ~$800-950 (as of April 2026, highly variable by retailer)
This is the card that makes sense for most budget-conscious local LLM builders. 20GB VRAM is enough for:
- Llama 3.1 8B at full precision (takes ~20GB)
- Llama 3.1 30B at Q4 quantization (~18GB)
- Llama 3.1 70B at Q3 or lower quantization (~15-18GB, but with performance hit)
Benchmark reality: Llama 3.1 8B runs at ~18-22 tokens/second on this card with ROCm. That's competitive with NVIDIA cards at the same price point. The RTX 5070 Ti (16GB) runs the same model at ~25-28 tok/s, but costs $749 at MSRP (and $900+ in actual retail). Performance-per-dollar heavily favors AMD in this window.
The catch: ROCm is still not as mature as CUDA. You'll need to be comfortable with occasional driver quirks or driver reinstalls if something breaks. For inference-only workloads, this is fine. For fine-tuning or mixed workloads, NVIDIA's ecosystem is more battle-tested.
RX 7900 XTX — Overkill for Most, but Potentially Cheaper Than NVIDIA's Equivalent
Specs: 24GB GDDR6, 384-bit bus, same core count as 7900 XT with 20% higher memory Current pricing: New retail ~$900-1,100; used ~$650-800
The XTX trades a slightly higher price for 24GB VRAM. That matters if you're running multiple 70B models or doing inference on multiple workloads simultaneously. For single-user local LLM work, it's excess capacity paying for future-proofing.
Performance parity with the XT on single models. The extra 4GB matters only if you're hitting VRAM limits on the XT setup you'd have built otherwise.
RX 7800 XT — Skip It for Local LLMs
Specs: 16GB GDDR6 Why: Too little VRAM for the performance class. You can do the same work on a cheaper RX 7700 XT (12GB) or save $100-200 and get a used 7900 XT. The 7800 XT is a card without a clear use case in 2026.
The ROCm Question: Is It Production-Ready?
This is the real blocker for most people considering AMD. CUDA is ubiquitous, battle-tested, and supported everywhere. ROCm is not.
Current state (April 2026):
- ROCm 6.0+ works well with llama.cpp and Ollama
- Support for vLLM and LM Studio is solid but less mature than CUDA
- First-time setup occasionally requires driver reinstalls or troubleshooting
- Subsequent runs are rock-solid
You're not getting bleeding-edge performance. You're getting 90-95% of what NVIDIA offers, with 75% of the ecosystem maturity. That's a reasonable trade-off if the price difference is $150+ per card.
The Timing Decision: When Does This Window Close?
Based on historical patterns, AMD's pricing advantage typically lasts 4-8 weeks after competing GPU launches. We're ~10 months past the last major NVIDIA launch (Blackwell), so the correction window is broad but will eventually close.
Factors that would close it:
- Next NVIDIA generation announcement (timeline unclear; typically 12-18 month cycles)
- Retailers receive significant RX 8000-series inventory (not expected until Q4 2026 at earliest)
- AMD's current-generation stock reaches critical low levels and margins reset upward
If you're buying in April 2026: You're in a window where AMD pricing is reasonable and unlikely to get better for a while. NVIDIA's pricing is stable at MSRP or above. The choice is simple: do you want to pay less now (AMD) or wait for the next launch cycle (unknown timing, could be months away)?
Should You Buy Now, Wait, or Go NVIDIA? The Actual Decision
Here's how to think about it:
Buy AMD now if:
- You need a local LLM rig within 30 days
- You're comfortable with ROCm (or willing to learn it)
- You're running models up to 30B parameters (where AMD excels)
- You want to maximize performance-per-dollar
Wait for AMD if:
- You can afford to wait 4-6 weeks for potential further price corrections
- You're targeting 70B+ models (AMD gets less attractive at that scale without expensive multi-GPU setups)
- You're okay with reduced performance for slightly lower cost
Go NVIDIA instead if:
- You need production-grade reliability and zero software friction
- You're doing fine-tuning or training (not just inference)
- You have a specific software stack that requires CUDA (rare, but it happens)
- You can absorb the $200+ price premium for peace of mind
What Happens Next: The RX 8000 Series Wildcard
AMD's next-generation Radeon cards (RX 8000-series) haven't been officially detailed for consumer markets. Rumors suggest they're coming in late 2026 or early 2027, but there's no confirmed timeline.
If next-gen launches later this year, we'll see the same cycle repeat: panic buying on NVIDIA's side, AMD inventory moving to clear margins. If it's 2027, you've already gotten a year of use out of your RX 7900 XT purchase.
FAQ
Can I run Llama 3.1 70B on an RX 7900 XT without severe performance hits?
At full Q4 quantization, no—the model needs ~32-35GB VRAM, and the card maxes out at 20GB. You'd need to run it with CPU offloading (using 15GB VRAM + 15-20GB system RAM), which drops inference speed to ~6-8 tokens/second. That's usable for non-interactive workloads but frustrating for chat or coding assistance. For 70B models, you're better off either going with the 24GB XTX or waiting for a multi-GPU setup.
Is ROCm going to eventually match CUDA in reliability?
Probably, but not in 2026. AMD has committed to deep software investment, and ROCm 6.0+ is genuinely stable for inference. The gap narrows annually. If you're okay waiting 2-3 more years for parity, that's a reasonable position. If you need production-grade reliability now, CUDA is still the safer choice.
How much does used vs. new pricing actually differ for AMD cards right now?
Significantly. Used RX 7900 XTs are selling for ~$590-650 on eBay/Facebook Marketplace, while new retail is $800-950. That's a 20-30% gap. Used NVIDIA cards have narrower discounts (10-15%) because they hold value better in the market. If you're buying AMD, used is worth serious consideration.
What if I already own an RTX 4090 or 4080? Should I trade it in for AMD?
No. The transaction costs (selling, shipping, restocking fees) plus the depreciation hit on your NVIDIA card exceed any performance gain from AMD. Your existing NVIDIA card is still better than AMD's current generation for your use case. Upgrading makes sense only if you're hitting hard performance limits (like consistent timeout on 70B models) that justify replacing functioning hardware.
When should I expect RX 8000 pricing details?
Likely late Q3 or Q4 2026. Historical patterns suggest 4-6 weeks between architecture announcement and first retail availability. Any purchases you make today should be evaluated on 18-month utility horizons, not "waiting for next-gen" thinking.
The Bottom Line
GPU market timing isn't rocket science. It's retail cycles and inventory management. AMD's current position—solid hardware, mature-enough software, and reduced demand relative to the launch hype—creates a genuinely favorable window for local LLM builders who don't need maximum performance and are willing to deal with a less-polished software ecosystem than CUDA.
That window probably closes in 4-8 weeks. Whether you should wait or buy depends on how urgently you need the rig. If you need it now, AMD is worth the consideration. If you can wait for the next cycle, that's also a fine call—you're just betting on future pricing improvement, which is less certain than what you can measure today.