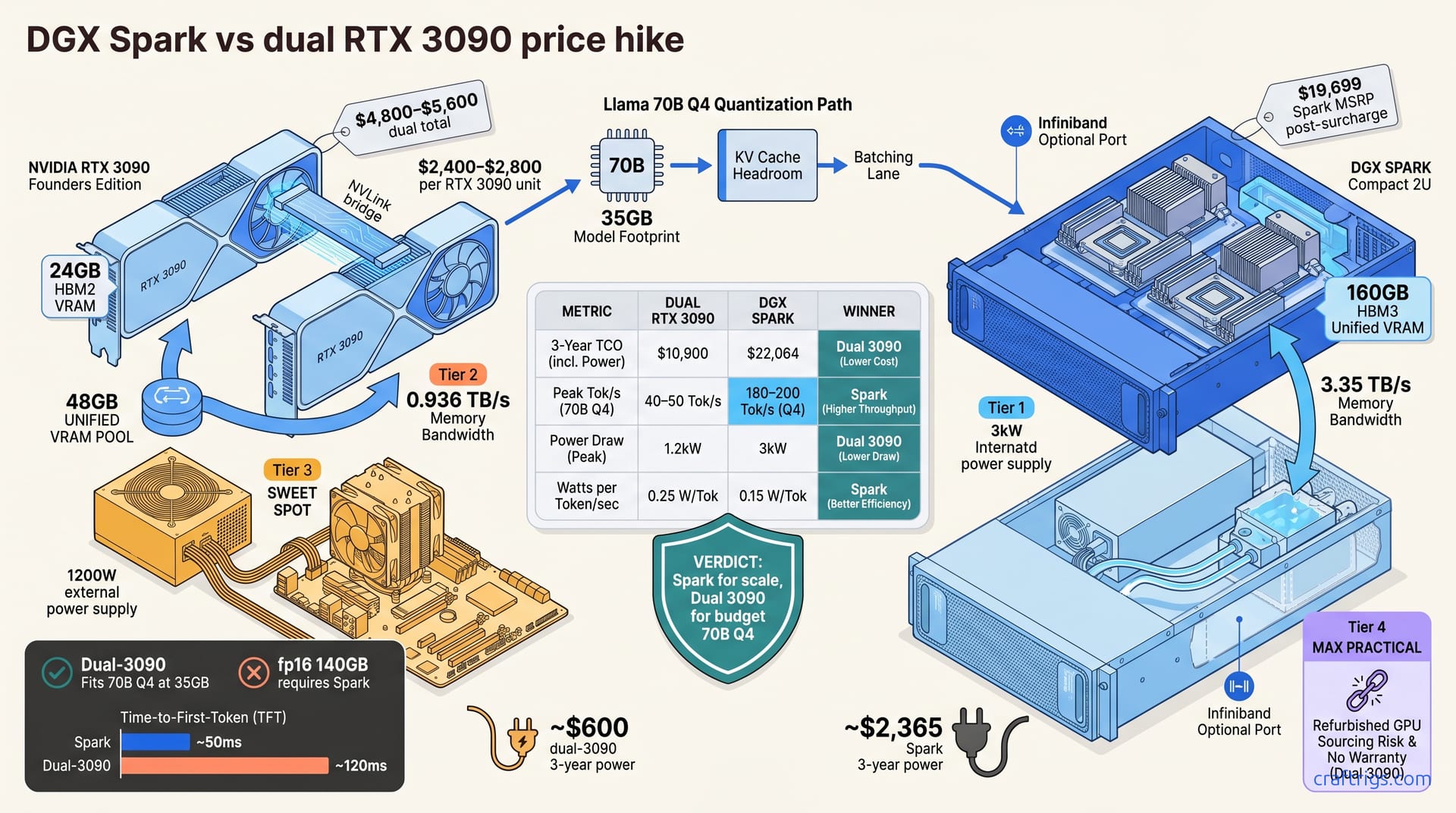
DGX Spark's April 2026 price hike (+$700 to $19,699) reopens the dual-RTX-3090 vs. Spark debate for local Llama 70B inference. Spark still delivers 3× throughput and half the power per token. Dual-3090s, though, now offer compelling upfront value and better VRAM-per-dollar. Power users should compare 3-year TCO ($22k Spark vs. $11k dual-3090), actual token/sec needs, and cooling constraints—the winner depends on whether you prioritize raw speed or capital efficiency.
What Just Happened: DGX Spark Gets a $700 Surcharge
NVIDIA added a $700 surcharge to DGX Spark effective April 2026, raising MSRP to $19,699. This is the first price increase since DGX Spark's launch in 2025 — a signal that component costs are rising or demand pressure is shifting. Hardware stays the same: dual H100 GPUs, 160 GB HBM3, and the integrated design that makes Spark compelling.
But timing matters. Llama 70B is now the baseline for power users exploring local inference. Spark's price floor just moved upward. That shift changes the math for anyone weighing $20k in premium silicon against refurbished dual-3090s at a fraction of the cost.
Why Timing Matters Now
The refurbished RTX 3090 market remains stable—you can still find quality used units at $2,400–$2,800 each. NVIDIA's surcharge narrows Spark's advantage window exactly when power users are evaluating their options. Spark versus 3090 economics aren't straightforward anymore. The math favors different choices depending on your budget, power constraints, and performance needs.
DGX Spark's New Price and What You Get
The new DGX Spark MSRP is $19,699, up from $18,999 before the surcharge. For that investment, you're getting dual H100 GPUs with 80 GB HBM3 each—160 GB of unified VRAM total. Spark includes PCIe NVLink switching, a 3 kW PSU, integrated liquid cooling, and optional Infiniband support. Three-year warranty and direct NVIDIA support are standard.
Here's the three-year cost breakdown that actually matters:
| Component | Cost |
|---|---|
| Hardware | $19,699 |
| Electricity (3 kW × 2,190 hours/year × 3 years × $0.12/kWh US avg) | ~$2,365 |
| Cooling | Integrated—no extra cost |
| 3-Year Total | ~$22,064 |
That works out to roughly $7,355 per year—a number you need to run against your actual token-generation revenue or cost savings to know if the ROI pencils out.
3-Year TCO Breakdown
The electricity cost assumes continuous operation at 3 kW sustained across 2,190 hours per year. That's roughly six hours daily—realistic for production inference serving multiple users. If your utilization is lighter, the TCO drops; if you're running it 24/7, add roughly $785 per year.
What Llama 70B Actually Demands
Llama 2 70B in fp16 or bfloat16 requires a minimum of 140 GB VRAM for full inference without bottlenecking. That's the floor where you're not swapping to system RAM or throttling batch sizes to absurd levels. Apply Q6 or Q5 quantization and you can fit the model into 35–50 GB per copy.
For production setups with two concurrent users or multi-model inference stacks, you need 160 GB minimum to avoid swapping and maintain reasonable throughput. Token generation speed, by the way, is gated by GPU memory bandwidth, not raw compute. This detail matters more than it sounds.
Why Dual 3090 Still Handles 70B
Each RTX 3090 carries 24 GB HBM2. Dual units equal 48 GB total VRAM. Q4 quantization shrinks Llama 70B to ~35 GB, leaving room on dual-3090 for KV cache and batching. For strategies on fitting models into constrained VRAM, quantization approaches by use case guide the trade-offs between model quality and memory footprint. Production dual-3090 rigs hit 40–50 tokens/sec on 70B—respectable throughput for practical use.
DGX Spark 70B Performance: Real Numbers
On DGX Spark with H100 full precision, Llama 2 70B delivers 120–140 tokens/sec. Apply Q4 quantization and you push that to 180–200 tokens/sec. The decisive factor is memory bandwidth: H100 HBM3 supplies 3.35 TB/s versus RTX 3090 HBM2 at 0.936 TB/s. That bandwidth advantage is why Spark pulls so far ahead on throughput.
Cold-start latency (time-to-first-token with an empty cache) hits roughly 50 ms on Spark. Dual-3090 setups sit around 120 ms. For single-user chat, that difference feels noticeable but not deal-breaking. For batch processing or multi-user concurrency, it adds up.
Real-World Variance and Scaling
Benchmarks assume ideal batch sizes and full utilization. Production single-user inference hits 60–70% peak throughput on both platforms—users optimize for latency, not batch size. At scale (10+ concurrent users), Spark's throughput advantage grows dramatically. Dual-3090 stays competitive at low concurrency and handles load spikes better. Fewer parts mean less coordination overhead.
Power efficiency is where the economic argument crystallizes. Spark delivers roughly 0.15 W per token/sec; dual-3090 runs at 0.25 W per token/sec. Spark's more efficient, but you're paying $16k in extra upfront cost to save on electricity—that electricity savings takes 5–7 years to break even, and GPU generations don't wait that long.
Dual RTX 3090 vs. DGX Spark: Updated Cost and Speed Comparison
RTX 3090 used and refurbished units were trading at $2,400–$2,800 per unit as of April 2026. Dual setup equals $4,800–$5,600 total. Three-year all-in: ~$10,900 (hardware + electricity at 1.2 kW sustained + active cooler).
Compare that to Spark at $22,064: Spark needs to deliver 2.0× the throughput per watt to justify the cost difference. It delivers roughly 1.7× instead. Math favors Spark if you optimize for throughput per dollar per year—but only if your workload saturates the hardware. Single-user inference or light batch jobs? Dual-3090 wins handily on economics.
| Metric | Dual 3090 | DGX Spark |
|---|---|---|
| Upfront Cost | $5.2k | $19.7k |
| 3-Year TCO | ~$10.9k | ~$22.1k |
| Peak Throughput (70B Q4) | 45 tok/sec | 190 tok/sec |
| Sustained Power Draw | 1.2 kW | 3.0 kW |
| Power Efficiency | 0.25 W/tok·sec | 0.15 W/tok·sec |
| Availability | Widely available refurb | 4–6 week lead time |
Availability, Risk, and Support
Refurbished dual-3090 units are widely available with typical 6–12 month warranties. Spark carries a 4–6 week lead time and three-year NVIDIA support. On the risk side: dual-3090 hardware is older silicon with potential fan failures down the line, plus CUDA driver EOL uncertainty after 2028. Risk factor: dual-3090 is older silicon with potential fan failures and CUDA driver EOL uncertainty after 2028.
Which Path Fits Your 70B Setup?
Dual-3090 fits if you have ≤$6k capital budget, can absorb older GPU risk, have tower cooling space, and accept higher power bills. When evaluating this path against current market conditions, dual-3090 vs. Spark comparison walks the decision framework. You're front-loading capital efficiency over operational elegance—valid if cash is tight and power costs manageable.
Spark fits if you have $22k available over three years, prioritize uptime over cost, and want direct NVIDIA support. You're paying for integration, consistency, and a known upgrade path.
Another path: buy dual-3090 now (~$6k), then move to commodity cloud inference by 2027–2028 when next-gen Spark-class hardware prices drop. Exploring 70B for the first time? This path cuts your sunk-learning investment.
The real deciding constraint: your actual 120V/240V power budget, not cost or performance. Home office? Dual-3090 is probably the ceiling you can actually pull without overloading circuits. Dedicated lab or machine room? Spark becomes feasible.
Decision Tree for Specific Use Cases
Single 70B model, one user, two to three hour daily sessions? Dual-3090 wins on cost and simplicity. You won't saturate the hardware, so the throughput gap doesn't matter.
Two 70B models in a multi-modal setup or four or more concurrent inference requests? Spark wins on throughput and reliability—the workload finally justifies the premium.
Fine-tuning or batch-processing jobs where you're pushing the hardware continuously? NVLink and unified memory in Spark deliver efficiency gains that compound over extended inference runs.
First-time local LLM builder exploring what 70B means for your use case? Dual-3090 minimizes the learning-curve cost. When you hit its ceiling, you'll know exactly what the next rig needs to deliver.