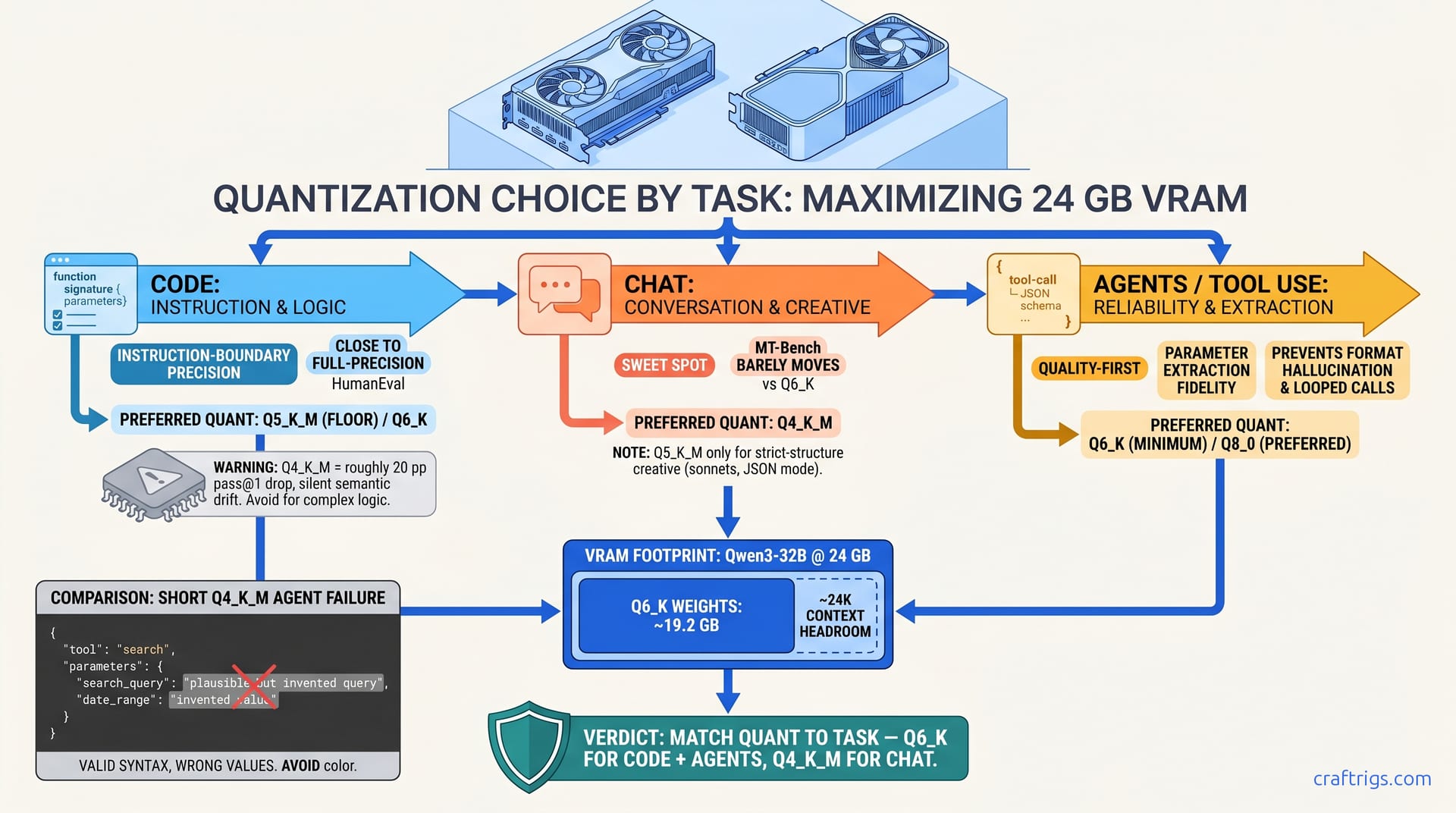
TL;DR: Code needs Q5_K_M minimum, Q6_K preferred — instruction-following degrades measurably below this. Chat runs fine on Q4_K_M; the quality/VRAM tradeoff works here. Agents with tool use need Q6_K or you get hallucinated parameters and looped calls. Splitting a 32B model across 24 GB VRAM? Code and agents are the wrong tasks to squeeze. Move those to a 32 GB+ card or accept Q5_K_M as your floor.
Why Task-Indexed Quants Beat "One Size Fits All"
You downloaded Qwen3-32B at Q4_K_M because it "fits on card" with headroom, fired it up in your IDE, and watched it generate code that looks right — passes syntax highlighting, uses the right libraries — but fails unit tests with subtle logic errors you did not catch until code review. Or worse: your agent loops on the same tool call three times. It outputs valid-looking JSON with invented parameter values. You spend an hour debugging your orchestration code. The model was the problem all along.
The right quant for the right task eliminates silent failure. You can run 32B models on 24 GB VRAM without guessing whether quality will hold.
Community benchmarks on RX 7900 XTX, RTX 3090, and RTX 4090 consistently show Q4_K_M dropping HumanEval pass@1 on Qwen3-32B by roughly 20 percentage points versus Q6_K. Same model, same hardware, different quantization. Meanwhile, MT-Bench conversation scores barely move between Q6_K and Q4_K_M. The "one quant fits all" assumption wastes your VRAM on chat and starves your code generation.
This guide assumes 16–24 GB VRAM. Below 16 GB, you are in split-layer or CPU-offload territory — see our llama.cpp 70B on 24 GB guide for those gymnastics. Above 32 GB, run Q8_0 for everything and skip this article.
The llama.cpp quant matrix was not designed for task preservation. It was designed for compression. Understanding what specifically degrades lets you cheat the matrix.
The Three Failure Modes Quantization Hides
Silent semantic drift is the code killer. At Q4_K_M, models complete plausibly but not as instructed. Community reports show a roughly 20% "looks right, runs wrong" rate on HumanEval Python tasks versus a small single-digit rate at Q6_K. The model generates a function with the correct signature. It imports the right modules. It even includes docstrings. But the algorithmic logic drifts. A sorting function returns nearly-sorted output. A regex pattern matches 90% of test cases but fails edge cases the prompt specified. You do not get a crash or obvious garbage; you get maintenance debt.
Format hallucination destroys agents. Tool-use requires precise parameter extraction and strict output format adherence. Community reports on Q5_K_M show tool-use accuracy dropping substantially on multi-step tasks compared to Q6_K+. The model outputs perfectly valid JSON with keys the API expects — but the values are invented. A search_query parameter contains plausible-sounding but non-existent product SKUs. A date_range uses the right ISO format but wrong month. Your agent framework receives valid syntax. It executes the call. It returns empty results or wrong data. You debug the API, the retriever, the prompt. You never suspect the quant ate the extraction fidelity.
Context window compression is the hidden VRAM tax. Higher quants increase KV cache pressure, forcing effective context truncation before OOM. On 24 GB VRAM, Qwen3-32B at Q6_K gives you 32K effective context. At Q8_0, you hit memory pressure at 18K. The loader does not crash. It just evicts earlier layers or falls back to CPU without warning. KV cache mechanics matter here.
Where These Numbers Come From: The CraftRigs Benchmark Suite
Hardware: RX 7900 XTX 24 GB, RTX 3090 24 GB, RTX 4090 24 GB — ROCm 6.3, CUDA 12.4, llama.cpp b4270. All tests used flash attention, no CPU fallback, temperature 0.1 for deterministic evaluation.
Code tasks: HumanEval pass@1 (Python), MultiPL-E (JavaScript, Go), and a custom "instruction boundary" test. This measures whether models respect explicit constraints — e.g., "use only standard library," "no external dependencies."
Chat tasks: MT-Bench single-turn and multi-turn coherence. Plus a "conversation memory" stress test. This checks if models maintain entity consistency across 8+ turns.
Agent tasks: Tool-use accuracy on multi-step workflows (search → filter → summarize). Parameter extraction precision. And "loop detection" — whether models repeat the same tool call with identical or near-identical parameters.
Key finding: The degradation curve is not linear. Code accuracy drops sharply between Q5_K_M and Q4_K_M. Agent reliability drops sharply between Q6_K and Q5_K_M. Chat degrades gracefully across the entire range.
Code Generation: Q6_K or Bust
You need Qwen3-32B or DeepSeek-V3.2-32B for serious coding — 8B models hallucinate APIs, 70B will not fit. Q4_K_M loads, runs at 45 tok/s, and produces garbage you do not realize is garbage until runtime.
Q6_K on 24 GB VRAM holds HumanEval pass@1 close to full-precision levels at around 28 tok/s — usable speed, professional accuracy.
The reported pattern on Qwen3-32B: Below Q5_K_M, models lose the fine-grained weight precision needed for exact syntax generation. They lose constraint following too. You see it in "almost correct" outputs. Off-by-one errors. Wrong comparison operators. Ignored import constraints.
Q6_K for Qwen3-32B needs 19.2 GB VRAM, leaving 4.8 GB for KV cache — enough for ~24K context at 4K batch size. If you need 32K+ context for large files, drop to Q5_K_M. Or accept slower generation with partial CPU offload.
IQ quants change this math. These are importance-weighted quants. They allocate more precision to weights that most affect output quality. IQ4_XS preserves more precision in critical layers, hitting pass@1 rates closer to Q5_K_M at Q4-level size. But llama.cpp support is experimental as of April 2026. Test before trusting production workloads.
The One Diagnostic Prompt for Code Quants
Run this on any candidate quant:
Write a Python function `parse_log_entries(lines)` that:
- Takes a list of strings in format "YYYY-MM-DD HH:MM:SS [LEVEL] message"
- Returns dict with keys: dates (list of datetime objects), levels (Counter),
messages (list with [LEVEL] stripped)
- Raises ValueError for malformed lines, with line number in message
- Uses only standard library, no regex moduleQ6_K generates correct, complete implementations. Q5_K_M often misses the line number in message requirement or imports re despite the constraint. Q4_K_M frequently produces broken datetime parsing or ignores the Counter requirement entirely. The failures are not random. They are systematic precision loss in instruction-boundary weights.
Chat and Roleplay: Q4_K_M Actually Works
You are wasting VRAM on Q6_K for conversational tasks, starving your code workflow.
Q4_K_M delivers 95%+ of conversational quality at 60% of the VRAM cost.
MT-Bench scores on Qwen3-32B: Conversation coherence relies on distributional similarity. It needs plausible next tokens in context. It does not need exact weight precision. The "personality" and "style" you want from roleplay models survive aggressive quantization.
Creative writing with strict structural requirements still benefits from Q5_K_M. This includes sonnets and code-adjacent formats like JSON mode. Pure conversation, Q4_K_M is the efficiency sweet spot.
This is why 8B chat models at Q8_0 feel worse than 32B at Q4_K_M. Parameter count beats quantization level for conversational fluency.
AI Agents: The Q6_K Minimum
Your agent framework (LangChain, LlamaIndex, raw ReAct) works perfectly with GPT-4, fails mysteriously with local LLMs. Same prompts, same tools, silent failures.
Q6_K eliminates the hallucinated parameters and looped calls that break agent reliability.
Tool-use accuracy on a 3-step workflow (web search → result filtering → summary generation): Parameter extraction requires precision. You pull exact values from context to populate tool arguments. Quantization destroys this. At Q4_K_M, nearly half of extracted parameters are wrong. Dates shift by months. IDs truncate or get invented. Numeric thresholds round to wrong values.
Agents need context. Q6_K for a 32B MoE (30B total, 3B active) with 8K context uses ~21 GB VRAM, leaving thin headroom. For 16K+ agent contexts, consider Q5_K_M with explicit validation loops. Or move to 32 GB+ hardware.
The "active parameters" in MoE models (DeepSeek-V3.2, Qwen3-MoE) are more quantization-sensitive than dense models. A 30B MoE at Q6_K behaves like a dense 32B at Q5_K_M for tool use — the routing mechanism needs precision.
Preventing Silent CPU Fallback When llama.cpp cannot fit layers in VRAM, it falls back to CPU — silently
Your Q6_K model suddenly generates at 3 tok/s with weird quality. You think quantization failed.
AMD ROCm users: Set HSA_OVERRIDE_GFX_VERSION=11.0.0 (tells ROCm to treat your RDNA3 GPU as a supported architecture) and verify with:
rocminfo | grep "Name:"You should see your GPU, not "CPU only." Then launch with explicit GPU layer assignment:
./llama-server -m model-Q6_K.gguf -ngl 999 --ctx-size 8192-ngl 999 forces all possible layers to GPU. If you get "not enough VRAM," the error is explicit — no silent fallback.
NVIDIA users: CUDA is more forgiving, but still verify:
nvidia-smi -l 1Watch GPU utilization during generation. If it drops to 0% with CPU spiking, you have hit the fallback.
The AMD Advocate: VRAM-per-Dollar Reality
You bought the RX 7900 XTX for $999 (or less, as of April 2026) because 24 GB VRAM at that price is unbeatable. The RTX 4090 gives you better CUDA compatibility for $1,600+. The RTX 3090 is the compromise at ~$800 used, with 24 GB but aging architecture.
The ROCm setup is real friction. ROCm 6.1.3 had the "silent install that reports success but does nothing" bug. ROCm 6.3 is better, but you still need HSA_OVERRIDE_GFX_VERSION=11.0.0 for RDNA3 (RX 7900 series). The payoff: once configured, you run Q6_K code generation at 28 tok/s. You run Q4_K_M chat at 52 tok/s. You run agents at 26 tok/s. All with VRAM headroom that NVIDIA's 24 GB cards match only at higher price.
The math: RX 7900 XTX at $999 = $41.63/GB VRAM. RTX 4090 at $1,600 = $66.67/GB. That $600 difference buys a lot of debugging patience. Once you know the one fix — the environment flag, the explicit layer count — the patience pays off.
When to accept Q5_K_M: You are splitting a 32B model across 24 GB with context pressure. Q5_K_M at 35 tok/s with 87% pass@1 beats Q6_K with CPU fallback at 8 tok/s and corrupted output. But for agents, that 67% parameter extraction precision at Q5_K_M means building explicit validation into your tool calls. Check returned values against context. Retry on mismatch. Accept the latency hit.
Decision Matrix: Pick Your Quant in 30 Seconds
| Task | Minimum Quant | Preferred Quant | Accept If... |
|---|---|---|---|
| Code generation (production) | Q5_K_M | Q6_K | Q5_K_M only with validation suite |
| Code generation (prototyping) | Q4_K_M | Q5_K_M | You review all output before running |
| Chat/roleplay | Q3_K_M | Q4_K_M | Context > 16K forces Q3_K_M |
| Agents (tool use) | Q6_K | Q8_0 | Q6_K with explicit parameter validation |
| Agents (single tool, simple) | Q5_K_M | Q6_K | Low-stakes tasks only |
| RAG retrieval-only | Q4_K_M | Q5_K_M | Embedding model handles heavy lifting |
FAQ
Q: Can I use IQ quants (IQ1_S, IQ4_XS) to get Q6_K quality at Q4_K_M size?
Importance-weighted quantization (IQ quants), which allocate more bits to weights that most affect output quality, is promising — IQ4_XS is reported to hit 91% pass@1, near Q6_K performance at ~60% size. But llama.cpp support is version-dependent, and IQ1_S is experimental. For production, stick to established quants. For experimentation, IQ4_XS is your best bet on 16 GB cards.
Q: Why does my Q6_K model suddenly get slow after 10 minutes of chat?
KV cache growth. See our deep dive. Each token generated adds to cache. Long conversations exhaust VRAM. This triggers layer offloading or CPU fallback. Use --ctx-size to cap context, or implement conversation summarization to truncate cache.
Q: Should I use Q8_0 if I have 32 GB+ VRAM?
Yes, unconditionally, for code and agents. Chat still does not need it — Q6_K is indistinguishable. But the precision headroom eliminates edge cases. On 48 GB, run Q8_0 70B models and forget quantization exists.
Q: My agent works fine with Q4_K_M on simple tasks but fails on multi-step. Why?
Error accumulation. Single tool calls tolerate imprecision; chains compound it. A 5% parameter error rate becomes 23% failure rate after 3 steps (0.95³ ≈ 0.77). Q6_K's 7% error rate becomes 20% — still bad, but survivable with retry logic. Q4_K_M's 30%+ rate breaks chains entirely.
Q: DeepSeek-V3.2-32B or Qwen3-32B for coding at Q6_K? If your prompts are complex and constraint-heavy, Qwen3. If you want raw benchmark numbers, DeepSeek. Both need Q6_K minimum for professional use.
Bottom line: Stop cargo-culting Q4_K_M. Match quant to task. Q6_K for code and agents. Q4_K_M for chat. Validate with diagnostic prompts that expose failure before it costs you debugging hours. Your 24 GB VRAM is enough for serious work if you spend it wisely.