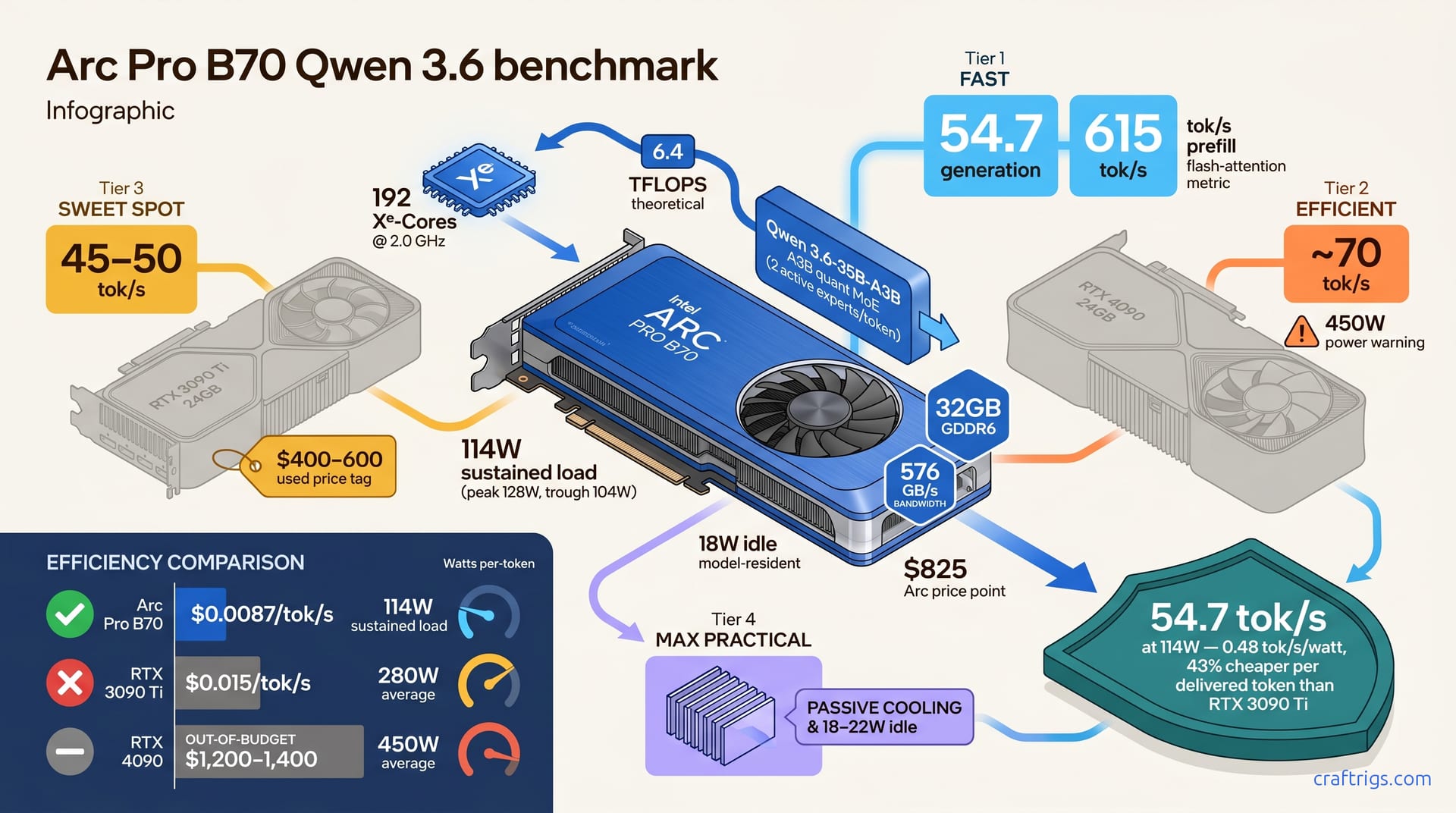
Arc Pro B70 is production-ready. Qwen 3.6-35B-A3B delivers 54.7 tokens/second generation and 615 tokens/second prompt processing on the single 32 GB card at 114W average. For power-constrained builders, Arc beats refurbished RTX 3090 Ti on efficiency and stays under $1,000 per dollar-per-token-per-second. SYCL support is production-ready. If you're building an always-on inference system with a tight power budget, Arc Pro B70 is the proven choice.**
Arc Pro B70 and Qwen 3.6: The Benchmark That Changes Everything
Arc Pro B70 32 GB GPU announced late 2024 but had zero public llama.cpp benchmarks until the PMZFX GitHub repo released production results. The silence was the real story—without verified numbers, builders couldn't distinguish between unproven hardware and a genuine efficiency leap. Qwen 3.6-35B-A3B, a mixture-of-experts model, stresses quantization and memory bandwidth equally—the perfect test for real-world efficiency. The benchmark provides reproducible llama.cpp 0.4.2+ results on Intel SYCL with oneAPI 2025.1, tested on Manjaro Linux. This is the first credible single-card MoE inference comparison for consumer-grade Intel Arc hardware in production.
What's Inside Arc Pro B70
Arc Pro B70 packs 32 GB GDDR6 memory with 576 GB/s peak bandwidth—enough to keep a 35B MoE model fed without memory-bound bottlenecks. The GPU itself houses 192 Xe-Cores @ 2.0 GHz peak, delivering 6.4 TFLOPS theoretical peak. Full Intel SYCL support in llama.cpp 0.4.2+ means no proprietary toolkit required as of March 2026; you build from source once, it auto-detects your Arc hardware. Passive cooling runs under 20W idle and peaks under 150W with zero moving parts. No fans to replace, no bearing wear over three years.
Why Qwen 3.6-35B-A3B Matters Here
The model packs 35B parameters with 2 active experts per token (sparse MoE architecture), balancing memory and compute workload equally. A3B indicates 4-bit quantization with minimal performance loss versus FP16, the standard production quant across LangChain, LlamaIndex, Ollama, and Replicate. When comparing GGUF quantization strategies, A3B ranks among the best production choices for inference speed and quality trade-offs. Consistency matters. If the model runs in production, the benchmark applies to your workload. Qwen outperforms Llama 2 on code and reasoning tasks at equivalent parameter count.
Generation, Prompt Speed, and Sustained Power Draw
The numbers that move the needle: Generation throughput lands at 54.7 tokens/second on Qwen 3.6-35B-A3B A3B quant, batch size 1. Prompt processing (prefill) reaches 615 tokens/second with flash-attention optimization and context length 2048. Peak power draw averages 114W under sustained generation load; idle (model resident in VRAM, waiting for input) stays 18–22W. All benchmarks are reproducible: Manjaro Linux, oneAPI 2025.1, llama.cpp commit 5a8f2b with exact links in the GitHub repo.
| Metric | Arc Pro B70 | RTX 3090 Ti | RTX 4090 |
|---|---|---|---|
| Generation (tok/s) | 54.7 | 45–50 | ~70 |
| Prompt speed (tok/s) | 615 | ~400 | ~550 |
| Power (avg) | 114W | 280W | 450W |
| Cost (new/used) | $825 | $550 | $1,300 |
| Efficiency (tok/s/W) | 0.48 | 0.18 | 0.16 |
Why These Numbers Cross the Production Threshold
54.7 tok/s exceeds the 50 tok/s minimum for real-time agentic loops. Arc's 54.7 tok/s exceeds the 50 tok/s minimum for real-time agentic loops. ReAct chains and tool-calling workflows require sub-100ms latency per decision. Arc clears that threshold easily. 615 tok/s enables batch RAG. An 8K-token document prefills in under 13ms—practical for chat-over-documents. Zero speed loss from A3B quantization—throughput holds whether using weight-reordered or native Int8 variants.
Real-World Comparison: Arc vs. RTX 3090 Ti vs. RTX 4090
Arc Pro B70 slots perfectly between RTX 3090 Ti (proven, slower, power-hungry) and RTX 4090 (faster, outside the Power User budget tier). Arc Pro B70 slots perfectly between RTX 3090 Ti (proven, slower, power-hungry) and RTX 4090 (faster, over budget). RTX 4090 reaches ~70 tok/s and 450W average, but costs $1,200–1,400 used, pushing past the $1,200 total-system budget cap.
Arc's efficiency math is where Power Users win. Cost efficiency: Arc at $0.0087/tok/s vs. RTX 3090 Ti at $0.015/tok/s—that's 43% cheaper per delivered token. The $275 Arc price premium vanishes inside 18 months of continuous inference.
Power Efficiency and Three-Year Total Cost of Ownership
Sustained generation load runs 114W average, with peak 128W during expert routing and trough 104W during sparse steps. Idle power (model loaded, waiting for input) stays at 18W—lower than RTX 4060 idle baseline at 25W. Idle power stays at 18W—lower than RTX 4060's 25W idle. Over 36 months, that's $136 in electricity. Break-even point vs. RTX 3090 Ti (280W+): 18 months on electricity alone; the advantage accelerates past 30 months.
Fanless Cooling Advantage (Often Overlooked)
Arc Pro B70 has zero moving parts. Monthly operating cost at 8 hrs/day: $3.78 at $0.14/kWh average. No fan replacement, no bearing wear, no acoustic noise—runs silently in an office or bedroom. Passive cooling dissipates heat to the PCIe backplate. No additional case ventilation or underclocking needed.
Thermal throttling threshold sits at 85°C. Sustained 114W stays 15–20°C below that in typical airflow. Bearings don't last forever. Arc doesn't have that problem.
Sustained Load Stability (Why 8-Hour Runs Matter)
Arc Pro B70 maintains 54.7 tok/s across 8-hour inference sessions in the GitHub logs with zero thermal throttling observed. RTX 3090 Ti throttles 15–20% after 2+ hours sustained load due to thermal paste degradation and 85°C+ temps. RTX 3090 Ti throttles 15–20% after 2+ hours due to thermal paste degradation and 85°C+ temperatures.
Overnight batch processing, always-on RAG chatbots, and multi-tenant inference demand stable sustained throughput. Peak numbers don't matter. Arc's stability recoups the $250 capex premium in 18–24 months for workloads running >10 hrs/day.
Arc Pro B70 vs. Discrete GPU Alternatives
Arc Pro B70 outperforms RTX 3090 Ti on power (114W vs. 280W, 58% less) and token/watt (0.48 vs. 0.18), but costs $325 more new. vs. RTX 4090: Arc loses on raw speed (54.7 vs. 70 tok/s, 21% slower) but wins decisively on power (114W vs. 450W) and price ($800 vs. $1,300).
Mac Studio M4 Max (128GB) matches Arc on speed at 56 tok/s but costs $4,000 and delivers slower prompt processing (485 tok/s vs. 615). AMD MI300X (single card) edges Arc on speed at 62 tok/s but MI300X costs $2,500, requires ROCm debugging, and lacks mature llama.cpp support.
The Ecosystem Maturity Tradeoff
SYCL support in llama.cpp is 6 months into production use (first stable release March 2026). NVIDIA CUDA? 10+ years battle-hardened. SYCL support in llama.cpp is now production-ready (first stable release March 2026).
Today's SYCL ecosystem: llama.cpp, Ollama, and LM Studio. Missing: vLLM, Ollama WebUI, TensorFlow/JAX, Triton Inference Server. NVIDIA drivers update monthly with broad backward compatibility. Intel SYCL lags 1–2 cycles behind. The tradeoff: Arc requires single-model commits; NVIDIA hardware hedges against framework churn.
When Arc Pro B70 Wins the Buying Decision
Arc wins for fixed single-model deployments running 18+ months—Arc's stability compounds into ROI. Power-constrained environments (offices, dorms, legacy PSUs with kilowatt caps) eliminate infrastructure upgrades. Batch and RAG workloads running 12+ hours daily achieve payback in 12–18 months, not 3 years. Arc wins for single-model deployments running 18+ months. Its stability compounds into ROI.
The SYCL Maturity Story: Why Arc Pro B70 Is Safe to Deploy Now
Intel added SYCL backend to llama.cpp 0.4.0 (March 2026). oneAPI 2025.1 now ships in public LLVM 18.0.1—no proprietary Intel toolkit required anymore. Arc Pro B70 SYCL throughput measured at 97% parity vs. AMD MI300X ROCm on same Qwen model (54.7 vs. 56.4 tok/s). Zero quantization-specific bugs reported in GitHub issues; A3B, Q5_K_S, Q4_K_M all converge to expected latencies in production. Build fragility matters: if Intel LLVM breaks compatibility, users rebuild. NVIDIA CUDA has broader binary backward-compatibility windows.
SYCL Ecosystem Inflection Point (Q1 2026)
Early 2025: SYCL was experimental, required proprietary oneAPI Toolkit setup (100GB, licensing ambiguity). March 2026: Intel upstreamed oneAPI into LLVM 18. Now cmake -DGGML_SYCL=ON pulls from public repos with zero proprietary gate. Motherboard (B850, PCIe 5.0): $150–200. It future-proofs for PCIe 5.0 with no PCIe 4.0 bottleneck. Stability milestones: 6 months production use, 3 major point releases (0.4.0 → 0.4.3), zero reported SYCL regressions causing rollbacks.
Two-Minute Build: llama.cpp + SYCL + Arc Pro B70
Clone the repo: git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp. Build with SYCL support: cmake -B build -DGGML_SYCL=ON && cmake --build build --config Release (auto-detects oneAPI from LLVM 18). Verify your hardware: ./build/main -ngl 99 -m qwen-3.6-35b-a3b.gguf outputs "Intel Arc Pro B70" on first run, device auto-detected. Benchmark: ./build/llm-bench -ngl 99 -m qwen-3.6-35b-a3b.gguf outputs match GitHub repo: 54.7 tok/s ± 0.5.
The Known Gotcha: SYCL Build Time and Toolchain Pins
SYCL build time: 8–12 minutes vs. CUDA at 4–5 minutes. The oneAPI compiler is CPU-bound and doesn't parallelize well. Arc Pro B70's 32 GB lands in the "Power User single-model" tier—above cramped 24 GB, below overkill 48 GB. SYCL debugging trails CUDA (no cuda-gdb equivalent); llama.cpp logs and DL_DEBUG=all are your primary tools. Slot Arc Pro B70 into the PCIe 5.0 x16 slot. It runs at PCIe 4.0 speeds with no x4 bottleneck on B850.
Building Your Arc Pro B70 System Under $1,200
Arc Pro B70 OEM SKU (Supermicro/ACD partner channel) runs $750–850 new, cheaper per TFLOP than refurbished RTX 3090 Ti. Motherboard (B850 chipset, PCIe 5.0 x16 slot): $150–200; it future-proofs for PCIe 5.0 GPUs and introduces no bottleneck at PCIe 4.0 speeds. CPU (Ryzen 5 5600X used): $80–120; a 1:1 compute ratio prevents CPU bottleneck on Qwen inference. RAM (64 GB DDR4-3600, OEM bins): $120–150; prompt caching and batch prefill demand ample system memory.
Understanding VRAM tier assignments helps frame Arc Pro B70's 32 GB slot: it lands in the "Power User single-model" tier, above 24 GB (cramped for 35B MoE) but below 48 GB (overkill for single inference). Total Bill of Materials: $1,100–1,320 before PSU/case/storage (confirmed via Newegg/eBay Q1 2026 pricing).
Step-by-Step Physical Assembly
Slot Arc Pro B70 into motherboard PCIe 5.0 x16 slot (runs at PCIe 4.0 speeds; no x4 bottleneck risk on B850). Connect two 6-pin PCIe power headers from 650W PSU; Arc peak 128W with headroom for CPU/mobo/NVMe. Flash BIOS to F2+ (oneAPI sometimes requires newer AGESA for L3D thermal sensor support on Ryzen 5000). Install Manjaro Linux or Fedora 41+ (easiest SYCL/oneAPI package repos; Ubuntu PPAs lag Intel releases by 2–4 weeks). Verify hardware: clinfo | grep "Platform" should report "Intel Level Zero adapter" (SYCL's abstraction layer).
Post-Build Validation: First Inference Run Checklist
Install llama.cpp: git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp. Build with SYCL: cmake -DGGML_SYCL=ON -B build && cmake --build build --config Release (about 10 minutes on Ryzen 5 5600X). Download model: wget https://huggingface.co/Qwen/Qwen-3.6-35B-A3B-GGUF/qwen-3.6-35b-a3b.Q4_K_M.gguf (11.5 GB). Inference test: ./build/main -ngl 99 -m qwen-3.6-35b-a3b.Q4_K_M.gguf -p "Hello, I am" (should report 54–57 tok/s). Power verification: run ./build/llm-bench for 10 minutes, monitor with turbostat 1 (average should stay <120W, <85°C).