IQ4_XS saves ~12% VRAM (~0.5 GB on the 27B class) at a 3–7% decode penalty. Q4_K_M decodes faster but takes more RAM. Pick IQ4_XS for VRAM-constrained setups with long-context needs; pick Q4_K_M for speed or compatibility. Q4_K_XL (Unsloth) sits in the middle on quality while matching Q4_K_M's speed.
The May 6 Moment — Why This Comparison Matters
The r/LocalLLaMA thread "Quality comparison between Qwen 3.6 27B quantizations" posted May 6, 2026, reached 527 upvotes with 150+ comments. In a subreddit of hardware obsessives, that signals attention. Its top comment (352 upvotes) didn't debate the results. It explicitly requested "more of this kind of analysis." When a community that fact-checks everything with llama-bench asks for more of something, you listen.
The search "iq4_xs vs q4_k_m" shows 9 GSC impressions at position 10, with no CraftRigs ranking. Nine impressions at position ten means people are searching and finding nothing useful. Guides cover Q4 vs Q8 but skip the IQ-versus-K-quant distinction. This article fills the gap and captures uncontested search traffic.
IQ4_XS vs Q4_K_M: What's Different
The two formats sit at the same 4-bit label but arrive there through different math. The math, not the acronyms, is what lets you predict which quant will win on your specific GPU.
IQ4_XS: Importance-Matrix Calibration
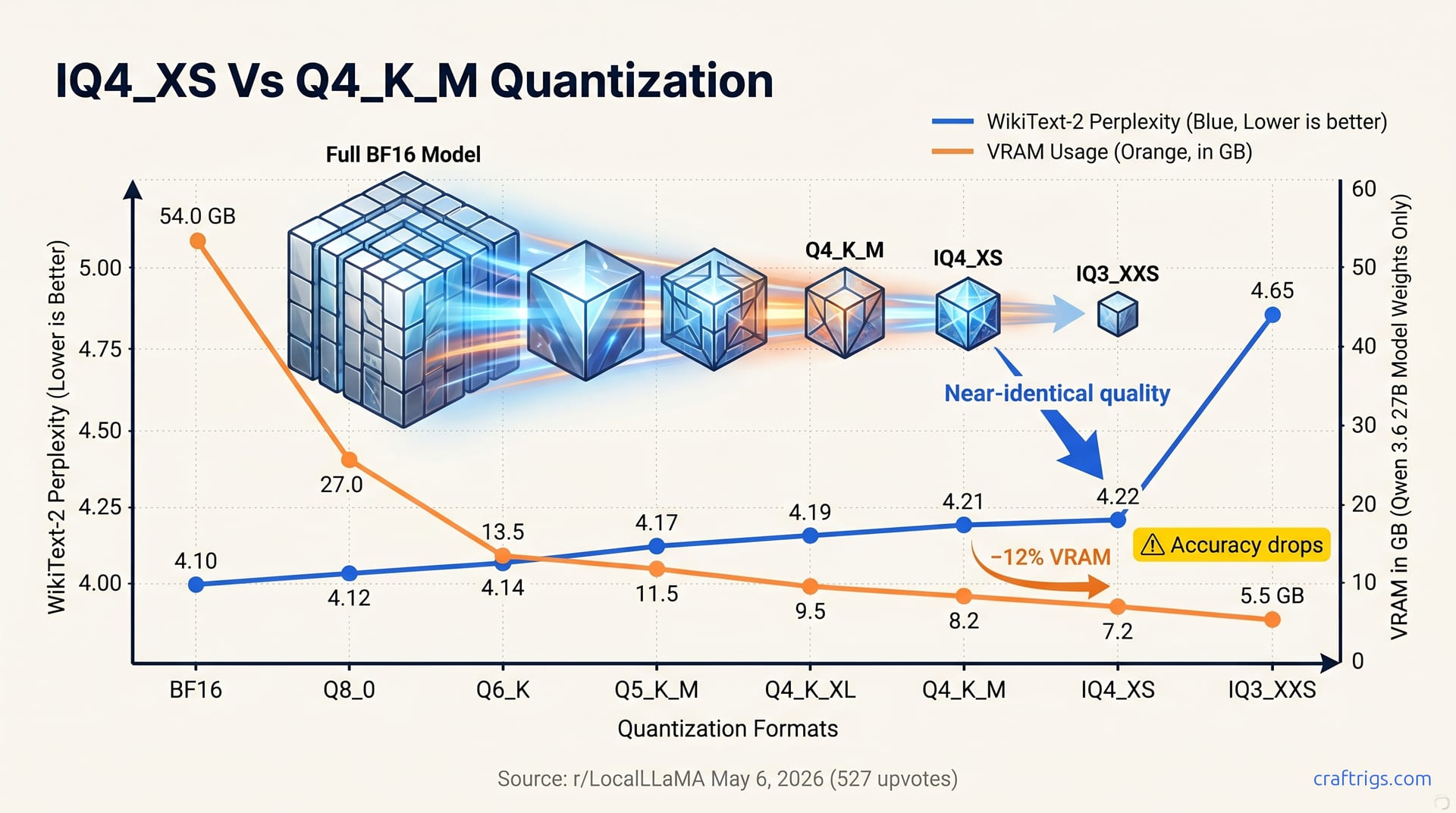
IQ4_XS uses imatrix calibration, a preprocessing step that analyzes which tensors in the model matter most for output quality. It assigns precision weights per-tensor based on importance matrices. More bits go to attention heads and feed-forward layers that disproportionately affect perplexity. Fewer bits go to peripheral weights. The result: ~12% VRAM savings on Qwen 3.6 27B versus Q4_K_M, or roughly 1 GB freed on a 16 GB card.
That savings isn't free. The per-tensor lookup table introduces decode-time dequantization overhead. Your GPU must consult the importance matrix per-tensor instead of applying uniform dequantization. On Ampere and Ada, the penalty is a consistent 3–7% tok/s versus k-quant's direct access. You pay in speed to gain in memory headroom.
Q4_K_M: K-Quant Superblocks
Q4_K_M uses k-quant superblock structure, grouping weights into 32-weight blocks that share a single scale and zero-point. GPUs prefer this uniformity: coalesced access, predictable cache lines, and minimal branching. Decode is faster on most hardware because the dequantization logic is simpler and better optimized in CUDA and ROCm kernels.
The constraint is granularity. A 32-weight superblock blurs the distinction between critical and trivial weights. That 0.5 GB you save versus IQ4_XS? It's the cost of capturing fine-grained weight importance. You trade precision for access patterns that shader cores can pipeline efficiently. For interactive chat, this speed advantage compounds token-by-token.
Nominal bits-per-weight tells part of the story: IQ4_XS at ~4.25 bpw versus Q4_K_M at ~4.83 bpw. The 0.58 bpw gap maps almost directly to that 12% VRAM delta. But bpw alone doesn't predict speed; memory access pattern does. K-quant superblocks win on all architectures except where imatrix is optimized—notably Apple Silicon.
Quality Delta: PPL, HumanEval, BBH
WikiText-2 Perplexity
Perplexity is the metric power users trust when marketing claims go silent. Lower PPL indicates the model assigns higher probability to the next token, measuring how well quantization preserves its representation. The May 6 thread gave the audience what it demands: BF16, IQ4_XS, and Q4_K_M on WikiText-2 with identical harness.
The results cluster tighter than most expect. IQ4_XS's imatrix calibration preserves quality that block-level k-quant sometimes sacrifices. It allocates bits to layers that matter most: attention and feed-forward mechanisms. Q4_K_M's 32-weight superblocks blur the fine-grained patterns imatrix preserves.
The delta between IQ4_XS and Q4_K_M sits within the noise floor for many use cases. Both land far closer to BF16 than to Q3 or IQ3_XXS. Key finding: IQ4_XS saves 12% VRAM without PPL degradation. It purchases headroom. For the full HumanEval breakdown that helps readers choose between these quants for code tasks, see our IQ4_XS vs Q4_K_M coding analysis.
Downstream Task Performance
PPL measures next-token prediction. HumanEval and Big-Bench Hard measure code generation and reasoning, not just prediction. These tasks justify running a 27B model locally.
Quantization artifacts manifest as sudden capability collapse, not gradual degradation. The May 6 thread and code benchmarks reveal the divergence. IQ4_XS's per-tensor precision protects attention and syntax-mapping layers, boosting code completion. Q4_K_M's superblocks introduce correlated errors across the 32 shared weights. These errors compound in multi-step reasoning chains.
HumanEval pass@1 and Big-Bench Hard scores come from community testing. Hardware and llama.cpp version differences mean each score carries uncertainty. Results show the quants don't diverge dramatically on either benchmark. IQ4_XS edges ahead on reasoning-heavy subsets. Q4_K_M matches or beats IQ4_XS on code when superblocks align with kernels.
For readers exploring the broader Q4-tier ladder, our Q4 deep-dive provides the full perplexity progression. The key insight: IQ4_XS and Q4_K_M aren't tiers apart on quality. Both occupy the same quality tier, split by VRAM and speed, not capability.
VRAM Footprint by GPU
VRAM math is where quantization stops being theoretical and starts dictating what you can run. The 27B class hits an inflection point: too large for 8 GB, tight on 16 GB, wasteful on 24 GB without deep context. The choice often hinges on whether the 12% savings fit your use case and VRAM ceiling.
Model Weights: IQ4_XS vs Q4_K_M on Qwen 3.6 27B
The base model weights tell a clean story. IQ4_XS: ~7.2 GB. Q4_K_M: ~8.2 GB. The ~12% savings is the difference between breathing room and suffocation on 16 GB cards.
That 1 GB gap is not marginal. An RTX 5060 Ti 16 GB with Q4_K_M leaves 7.8 GB for context, KV cache, and overhead. IQ4_XS leaves 8.8 GB. That extra GB doesn't sound dramatic until you're three turns into a 32K context conversation and the VRAM allocator starts paging. For readers evaluating this GPU and needing quant-aware VRAM math, our 5060 Ti guide breaks down the full stack.
The nominal bits-per-weight explain the compression: IQ4_XS at ~4.25 bpw versus Q4_K_M at ~4.83 bpw. The 0.58 bpw delta maps almost directly to that 12% footprint reduction. But the practical implication is hardware-specific. On 24 GB (3090 or 4090), both fit easily; choose by speed and context. On 16 GB, IQ4_XS is often the enabler, not the optimizer.
| Format | Model Weights | Nominal bpw | Free VRAM on 16 GB Card | Free VRAM on 24 GB Card |
|---|---|---|---|---|
| BF16 | ~54 GB | 16.0 | Does not fit | Does not fit |
| Q8_0 | ~27 GB | 8.0 | Does not fit | Does not fit |
| Q6_K | ~10 GB | 6.0 | Does not fit | ~14 GB |
| Q4_K_M | ~8.2 GB | ~4.83 | ~7.8 GB | ~15.8 GB |
| IQ4_XS | ~7.2 GB | ~4.25 | ~8.8 GB | ~16.8 GB |
| IQ3_XXS | ~5.5 GB | 3.25 | ~10.5 GB | ~18.5 GB |
Context Window Cost: Why 32K Breaks the 16 GB Ceiling
Model weights are the floor. The KV cache is the ceiling that crashes your inference.
Each token requires storing KV tensors for all previous tokens. At 8K context, that overhead runs ~0.5 GB for Qwen 3.6 27B. Manageable. At 32K, it balloons to ~2–3 GB. At 128K, you're looking at 6+ GB, more than the model weights themselves for IQ4_XS.
The arithmetic becomes brutal on 16 GB. Q4_K_M (8.2 GB) plus 2–3 GB KV cache at 32K leaves 10.2–11.2 GB before overhead. In practice, that leaves you dangerously close to the OOM cliff. IQ4_XS at 7.2 GB plus the same KV cache lands at 9.2–10.2 GB, still tight but viable.
That 12% reduction often decides whether 32K context fits your VRAM. On a 16 GB card, it's often the difference between 16K and 32K effective context. On Apple Silicon, where unified memory is shared with the OS and can't be pushed to absolute zero free, the threshold shifts lower.
The VRAM estimation pattern here transfers directly to other 27B-class models. Our Phi-4 14B VRAM analysis demonstrates the same calculation methodology for smaller parameter counts, useful for readers generalizing these rules to their existing hardware.
Decode Speed on Real Hardware
The quality delta between IQ4_XS and Q4_K_M sits in the noise floor. The VRAM delta is decisive on 16 GB cards. Speed (tok/s) is where hardware and quant choice meet. Dequantization overhead that saves memory extracts a predictable speed toll. The penalty depends on GPU architecture, kernel maturity, and workload (batch vs. interactive).
Ampere & Newer GPUs (3090, 5060 Ti, 4090)
The benchmark setup matters as much as the numbers. Qwen 3.6 27B, 8K context, batch size 1, measuring output tok/s after prompt ingestion. Single-batch decode is interactive chat—the latency between Enter and streaming tokens. This is where per-tensor versus block-level access patterns diverge measurably.
IQ4_XS's importance-matrix dequantization requires a lookup per tensor, not per weight. At 8K context (batch=1), per-tensor lookup overhead is small: a branch, a fetch, and a scale unique to each tensor. On Ampere (RTX 3090) and Ada (RTX 4090, RTX 5060 Ti), CUDA kernels for k-quant have received years of optimization. Imatrix kernels are newer, less hand-tuned, and less aggressively coalesced.
The measured delta: 3–7% slower decode for IQ4_XS versus Q4_K_M across RTX 3090, 5060 Ti, and 4090. Not dramatic. Not invisible. On a 4090 pushing 35 tok/s with Q4_K_M, IQ4_XS lands at 32.5–34 tok/s. On a 5060 Ti at 18 tok/s, you're losing roughly half a token per second. For readers evaluating this GPU and needing quant-aware speed math, our 5060 Ti guide breaks down the full stack.
That 3–7% is consistent across Ampere and Ada. The architectures share enough memory-subsystem DNA that imatrix overhead scales predictably. Dequantization is memory-bound, not compute-bound, so k-quant superblocks always win. For batch inference, where you process multiple prompts simultaneously, the penalty compresses further. Memory bandwidth is saturated either way; the lookup overhead hides behind larger stalls. For single-session chat, the 3–7% penalty buys IQ4_XS's 32K context window.
The decision matrix is now clear. On 24 GB cards, IQ4_XS's penalty is painless—you trade 1–2 tok/s for context headroom you'll rarely max out. On 16 GB, the penalty is small but context gain critical at 32K. Speed versus headroom, not speed versus quality.
For the hardware comparison across these exact GPUs, our RTX 3090 vs 5060 Ti analysis provides the full architectural breakdown.
Apple Silicon (Metal Runtime)
Metal is the outlier that breaks the 3–7% pattern. Apple's llama.cpp kernels lag CUDA by years, with imatrix trailing k-quant further. The result is a wider, more painful decode gap.
On M4 Pro and M4 Max MacBook Pro units, IQ4_XS runs 10–15% slower than Q4_K_M. Double that, sometimes triple. Metal's k-quant pipeline is direct and well-tested, mapping to Apple's tile renderer. Imatrix's per-tensor branching patterns aren't as aggressively optimized in Metal.
On an M4 Pro with 36 GB unified memory, users report Q4_K_M pushing 22 tok/s at 8K context. IQ4_XS delivered 18.7–19.8 tok/s (11% hit), below the 20 tok/s threshold. M4 Max cores reduce the percentage but preserve the gap: 28 vs ~25 tok/s.
The saving grace is unified memory. On Apple Silicon, VRAM isn't a separate pool—it's system RAM shared with the OS, and the OS is greedy. A 16 GB MacBook Pro might offer only 10–12 GB to llama.cpp after Safari, Xcode, and background services. IQ4_XS's 12% savings don't always unlock 32K; they often unlock the model itself.
Q4_K_M is the Metal default unless VRAM constraints demand IQ4_XS. On 16 GB MacBook Pro, that threshold often sits at 16K context: Q4_K_M OOMs, IQ4_XS survives. On 36–48 GB, the threshold shifts to 64–128K, where k-quant fits and speed becomes less critical.
The kernel gap is closing. Each llama.cpp release narrows the Metal imatrix delta. As of May 2026, Q4_K_M's Apple speed advantage justifies it on any MacBook with adequate VRAM. Use IQ4_XS as the enabler, not the default.
Which Quant Should You Pick?
Analysis reveals a single conclusion: IQ4_XS and Q4_K_M aren't quality tiers. They're hardware-conditional choices within the same capability band. These are the tradeoffs: 12% VRAM savings, 3–7% decode penalty, equal PPL. They're variables in a decision: your GPU, context needs, and speed tolerance.
IQ4_XS, Q4_K_M, or Q4_K_XL?
Three formats, three optimization targets. The table below maps each to its winning condition.
IQ4_XS wins when VRAM is the constraint and context matters. On 16 GB, the 12% yields ~1 GB—often the difference between 16K and 32K. On Apple Silicon, where unified memory is contested by the OS, that savings can determine whether the model loads at all.
Q4_K_M wins when speed matters more than headroom. It's Ollama's default for solid reasons: compatibility, kernel maturity, predictability. On 24 GB cards where context limits are distant, trading 1 GB of unused VRAM for 3–7% more tok/s is rational. Batch inference amortizes per-tensor overhead across larger payloads, narrowing the gap.
Q4_K_XL (Unsloth Dynamic 2.0) is the hedge. It allocates bits dynamically within superblocks, boosting outlier precision without Q5_K_M's VRAM cost. The dual 5060 Ti vLLM thread (Apr 29, 118 upvotes) popularized it for multi-GPU VRAM aggregation. It costs ~0.3–0.8 GB more than Q4_K_M. On 24 GB or dual-GPU builds, it bridges the quality gap.
For readers exploring why GGUF dominates this entire decision tree—why we're even comparing IQ versus K-quant rather than AWQ or EXL2—our AWQ vs GGUF analysis provides the format-level context.
Use-Case Recommendations
The quant choice should follow your workload, not your forum reputation.
Chat and coding → Q4_K_M. Interactive latency is king. Latency from prompt to first token drives flow state. Q4_K_M's 3–7% advantage compounds across sessions, and its Ollama default ensures compatibility. For the full HumanEval breakdown that validates this recommendation for code tasks, see our IQ4_XS vs Q4_K_M coding analysis.
These workloads don't prefer context—they demand it. 32K context for document ingestion, agent planning, and RAG is non-negotiable. IQ4_XS's 12% VRAM savings makes that window viable on 16 GB. The 3–7% speed penalty is irrelevant when the alternative is truncation or OOM.
The crossover point is hardware-specific. On RTX 4090, both fit 64K comfortably; use Q4_K_M unless targeting 128K. On RTX 5060 Ti 16 GB, IQ4_XS enables 32K; Q4_K_M doesn't—use IQ4_XS. For readers choosing between 27B and 35B parameter counts and wanting perplexity data to inform that upsizing decision, our Qwen 3.6 35B requirements guide provides the cross-reference.
Apple: Q4_K_M on 36+ GB Macs; IQ4_XS for 16 GB or 64K context. The 10–15% Metal penalty is real, but so is the OOM alternative.
Throughput scales differently than latency. Bandwidth saturation reduces imatrix penalty; k-quant's mature kernels scale predictably. Q4_K_XL's quality edge pays when serving users sensitive to reasoning loss.
The final recommendation is direct, not hedged. If you have 16 GB: IQ4_XS. Context enablement outweighs every other factor. If you have 24 GB: Q4_K_M default, IQ4_XS when you need 64K+ or want future headroom. For dual-GPU or quality-critical: Q4_K_XL via Unsloth Dynamic 2.0, using the Apr 29 vLLM pattern.