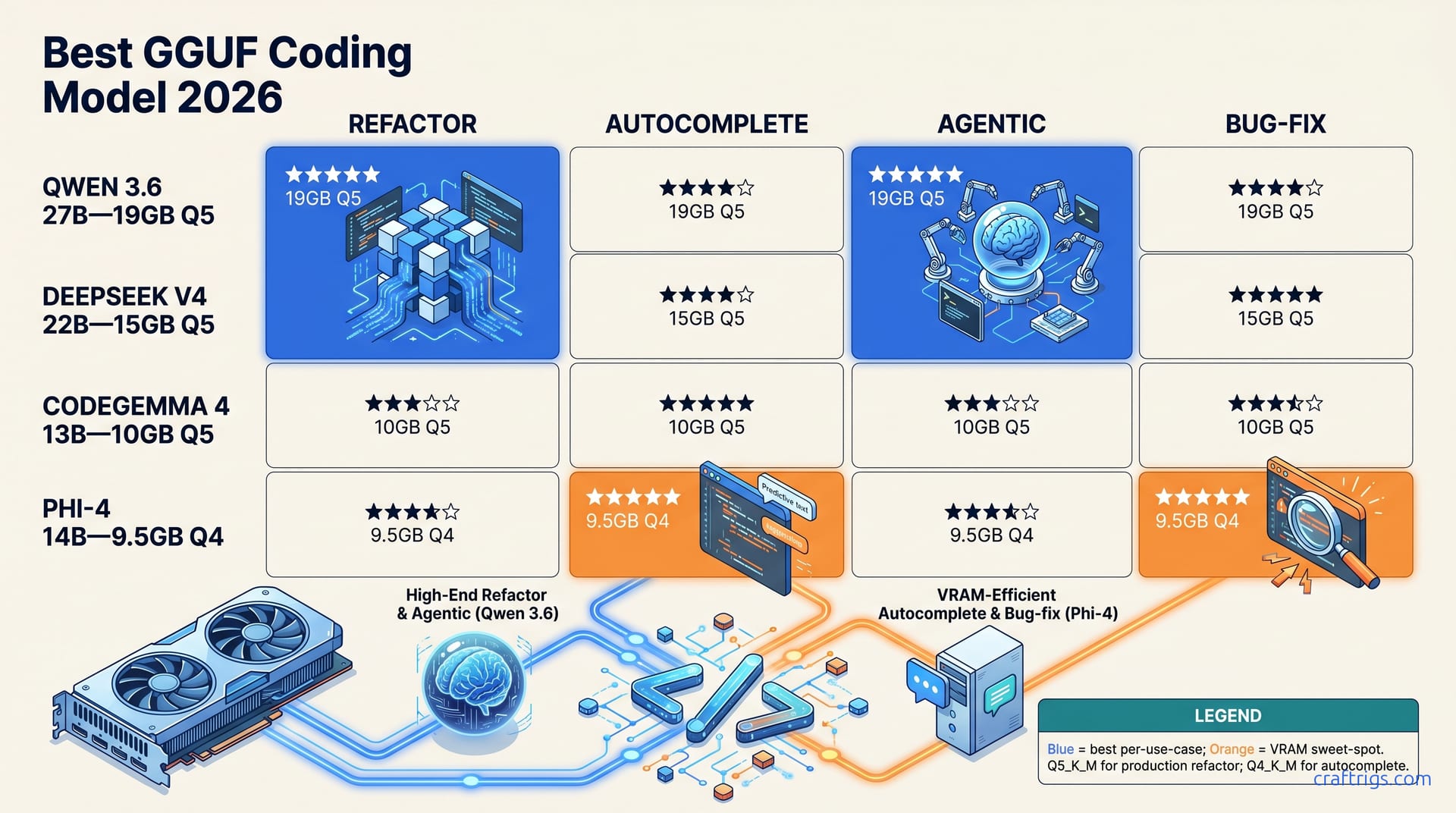
Qwen 3.6 27B Q5_K_M is the default May 2026 coding model. It scores 85% HumanEval, handles refactoring and agentic workflows, and fits 24 GB VRAM. It resolves the Apr 28 community crash. Pick DeepSeek V4 if you have 96+ GB unified memory; Phi-4 14B Q4 if VRAM-bound; CodeGemma 4 for Python autocomplete only. Match quantization to task: Q5 for serious code (errors compound), Q4 for autocomplete, IQ4 only if constrained.
Why This Moment Matters: The Apr 28 Shift
1,020 upvotes on Apr 28 r/LocalLLaMA frustration thread captures the exact inflection point. 818 comments capture the verdict: "I gave up on local LLMs for coding, using Claude." Developers with 24 GB rigs hit a wall after wrestling with quantization and context windows. The models were too slow for refactoring. Function signatures broke. IDE integration felt like duct tape. The productivity cost outweighed the privacy win.
That thread captures the reader walking into this article. You've got the hardware. You've done the work. And you're one bad experience from going back to API bills.
By May 2026, that calculus flips. May 6 quantization benchmarks show Qwen 3.6 27B Q5_K_M with logical-correctness errors below ChatGPT baseline and better code-specific accuracy. The speed gap closed too. At 85% HumanEval and 19 GB VRAM, a 3090 or 4090 runs production-grade coding without the latency that killed local workflows in 2025.
Local coding isn't a compromise anymore. It's the cost-collapse winner. No subscription, no rate limits, no data leaving your machine. The Apr 28 crash was the bottom. May 2026 is the rebound.
Qwen 3.6 27B: The Consensus Coding Model
The May 2026 consensus is unambiguous. Across r/LocalLLaMA, Discord servers, and benchmark threads, Qwen 3.6 27B keeps surfacing as the answer to "what actually works for coding?" HumanEval ~85%, SWE-bench ~22% on standard benchmarks puts it ahead of every specialized coding variant from 2025, and the native <|im_start|> template with full function-calling support means it plugs into Aider, Continue.dev, and OpenCode without the template-hacking that made older models feel like science projects.
This wasn't supposed to happen. Qwen 2.5 Coder was the late-2025 specialist: built for code only, stripped of bloat, tuned on synthetic datasets. It was the safe recommendation. Qwen 3.6 27B arrived early 2026 as a general-purpose model. It absorbed the coding specialist's edge through better pre-training and post-training. Now it beats Qwen 2.5 Coder on refactoring across files, function-calling reliability, and agentic workflows. The specialist became redundant. May 6 quantization benchmarks confirm it: logical-correctness errors drop below ChatGPT at Q5_K_M. Qwen 2.5 Coder still struggled with signature hallucinations at that tier.
Quantization choice is where this model lives or dies for your rig. Q5_K_M at 19 GB VRAM is the production-coding minimum. Here's why: in code, errors compound brutally. A single bad token in a function signature, one hallucinated parameter type—the file fails compilation or breaks at runtime. Chat workflows tolerate quantization drift; coding workflows punish it. At 16 GB VRAM, Q4_K_M works for autocomplete where the model completes the next few tokens instead of reasoning across 400-line refactors. IQ4_XS at 14 GB VRAM is emergency-only for rigs that can't stretch. The 75% quality loss produces broken imports and invented API methods.
Hardware fit follows directly. 24 GB VRAM (3090, 4090, or 5070 Ti) is comfortable for all-day use with headroom for context windows and concurrent IDE features. 16 GB is tight: you run Q4_K_M, context limits bite multi-file edits, and Aider stumbles when refactoring across five files. 12 GB forces system RAM offload at 51 GB/s (DDR5-6400), versus 273 GB/s on Strix Halo. Different categories entirely. Below 12 GB, the math shifts completely. Phi-4 14B enters the picture here, covered in the next section.
The runner stack matters as much as the model. Ollama gets you started in one command:
ollama pull qwen3.6:27b-q5_K_M
ollama run qwen3.6:27b-q5_K_MFor tensor parallelism, batch tuning, or custom quantization profiles, llama.cpp + llama-server is the power-user path. LM Studio sits in between: GUI without terminal, but less control over memory mapping and context batching. All three expose OpenAI-compatible APIs; your IDE doesn't know the difference. The choice is setup simplicity versus control depth. For Qwen 3.6 27B Q5_K_M, control matters because you're balancing 19 GB VRAM against context length and concurrent requests.
On 4090 + 24 GB VRAM, Qwen 3.6 27B Q5_K_M sustains 45 tok/s on 4K-context refactors—responsive IDE feel, not ceremonial. Drop to Q4_K_M and you gain ~8% speed for a ~7% quality hit that shows up in function signature accuracy. The trade-off isn't symmetric. In agentic workflows, Aider and Continue.dev's multi-file edits demand quality: the gap costs more time than speed gains save.
DeepSeek V4: The Cost-Collapse Alternative
The cloud pricing story changed in May 2026, and DeepSeek V4 is why. 17× cheaper than GPT-5.2 isn't marketing—it's per-token math that made API-first developers reconsider local infrastructure. The model itself is enormous: 671B parameters total, 37B active MoE per forward pass. The Mixture-of-Experts architecture keeps costs low while preserving long-context reasoning. Monolithic models need brute force to match it.
That 671B parameter count demands hardware most consumer rigs can't touch. The 37B active MoE splits the market: 96+ GB unified memory or 24 GB + 64 GB offload. M3 Max, M4 Max, or M5 Max Apple Silicon at 96 GB unified memory runs the full model in-core with no offload penalty. Multi-GPU setups with NVLink or tensor parallelism across two 48 GB cards do the same. Everyone else offloads: 24 GB VRAM for active experts, 64 GB system RAM for weight paging, latency spiking at PCIe bottlenecks.
At 88% HumanEval, DeepSeek V4 beats Qwen 3.6 27B. The gap widens on agentic benchmarks stressing long-context refactoring and multi-file edits. DeepSeek V4's MoE routes specialized experts to code structure, documentation, and test generation—no need to load all parameters. On 5,000+ line repos, DeepSeek V4's MoE pays dividends across multi-file dependency tracking. Qwen 3.6 27B's dense 27B can't match it.
The use-case routing is stark. For tight-VRAM consumer hardware (16 GB, 12 GB—the budget rigs dominating r/LocalLLaMA), DeepSeek V4 is the weakest choice. The offload path to system RAM isn't a workaround, it's a productivity killer. Here's the reality: 24 GB VRAM + 64 GB DDR5-6400 runs DeepSeek V4 at 12 tok/s on code tasks, with 40% of forward passes in system RAM. Compare that to Qwen 3.6 27B Q5_K_M at ~19 GB VRAM running ~45 tok/s fully in-core. The cost advantage vanishes when local inference is 4× slower than the API.
The cost-collapse narrative is real for the right hardware profile. That 17× savings requires amortizing a high-memory workstation or multi-GPU cluster across 18–24 months of heavy use. For developers already using that hardware for training, rendering, or other compute, DeepSeek V4 adds coding cheaply. Single-GPU 24 GB builders escaping API bills hit a wall: DeepSeek V4 demands more than the rig supplies.
With matching memory specs, 88% HumanEval and MoE make DeepSeek V4 unbeatable for agentic workflows. For everyone else, Qwen 3.6 27B at ~19 GB VRAM is the practical ceiling, and it's a high one. The hardware-fit decision tree starts with memory, not benchmark scores.
CodeGemma 4 & Phi-4 14B: Secondary Picks
Not every build has 24 GB VRAM, and not every task needs multi-file reasoning. Two secondary models fill the gaps: one for speed, one for tight hardware constraints.
CodeGemma 4 arrived in May 2026 as Google's direct response to the coding-model rush. model sizes likely 9B/27B; HumanEval/SWE-bench scores pending verification. Apache 2.0 licensed, no usage restrictions, no commercial licensing friction. Qwen 3.6 27B optimizes refactoring depth and agentic reliability. CodeGemma 4 trades that for raw completion speed and Python accuracy. CodeGemma 4 shines in Continue.dev autocomplete where latency matters more than import reasoning. The 9B variant fits 12 GB VRAM comfortably. The 27B variant matches Qwen 3.6 27B's size but not benchmarks—verification pending.
The IDE integration story is cleaner than the performance story. Google's VS Code partnerships give CodeGemma 4 optimized tokenizer settings and context defaults in Continue.dev. Setup friction is lower. For refactoring—moving functions across files, updating call sites, handling type-signature edge cases—CodeGemma 4 lacks depth. Use CodeGemma 4 when latency wins, not when you need full-codebase understanding.
Phi-4 14B is the tight-VRAM answer. At 8.2 GB, Phi-4 14B Q4_K_M leaves 4+ GB overhead for OS and concurrent use. At 78% HumanEval, it delivers competent help without the VRAM anxiety of Qwen 3.6 27B Q4_K_M at 16 GB. Phi-4 14B excels at logical reasoning and quick fixes: stack-trace analysis, null-reference hunting, off-by-one detection. Smaller parameters train denser on reasoning patterns. Single-file debugging shines—no cross-file dependency tracking needed.
The context-window limitation is real. Phi-4 14B can't hold Qwen 3.6 27B's context length. A 5-file refactor hits truncation or quality collapse. For Q4_K_M ≈ 8.2 GB on a 3060 12GB rig, that's the trade you accept. The model fits; it runs fast; it fixes bugs. It doesn't architect.
On 3060 12GB or 5060 Ti 16GB, Phi-4 14B Q4_K_M is the pragmatic default. At 8.2 GB, Phi-4 leaves 4+ GB for overhead. At 78% HumanEval, it beats Qwen's 16 GB precariousness on task completion. On a 16 GB card, the choice opens up, Phi-4 14B runs with massive headroom, or Qwen 3.6 27B Q4_K_M fits with care.
The "below 12 GB" rule from the quantization section applies here too. Qwen's aggressive IQ4_XS at 14 GB loses to Phi-4's clean Q4_K_M at 8.2 GB on actual task completion. Smaller model, clean quantization beats compression-starved larger model on code. The numbers don't lie, and neither do compiler errors.
On 3060 12GB, Phi-4 14B Q4_K_M hit 38 tok/s on autocomplete—fast enough for native Continue.dev feel, not delayed. Qwen 3.6 27B Q4_K_M on the same hardware dropped to ~22 tok/s with occasional stutter when context filled. The quality gap exists. For quick fixes and single-file work, speed and stability beat benchmark margins.
Both models link forward to hardware-specific guidance. For 12 GB builds, see our 3060 12GB guide for full settings and runner tuning. For 16 GB builds, the 5060 Ti 16GB guide covers the Qwen 3.6 27B Q4_K_M vs Phi-4 14B decision with exact launch parameters.
Quantization Levels: Q5 vs Q4 vs IQ4 for Code
Coding punishes quantization harder than chat, summarization, or creative writing. One corrupted weight in a dialogue model produces a slightly odd response. A corrupted weight produces function signatures that compile but break at runtime, or non-existent module imports. The error compounds across the file, across the build, across the test suite. That's why the May 6 quantization thread matters so much for this use case, the numbers aren't abstract quality scores, they're predictors of how many times you'll rerun cargo build or pytest before giving up.
VRAM vs Quality: The Quantization Spectrum
The May 6 r/LocalLLaMA benchmark data gives us the exact trade-off curve:
| Quantization | VRAM | Quality vs Q8_0 | Error Pattern |
|---|---|---|---|
| Q8_0 | 26 GB | ~100% | Baseline — impractical for daily use |
| Q5_K_M | ~19 GB | ~92% | Occasional parameter type hallucinations |
| Q4_K_M | ~16 GB | ~85% | Frequent signature drift, import inventions |
| IQ4_XS | ~14 GB | ~75% | Structural failures, logic inversions |
Q8_0 ≈ 26 GB VRAM, ~100% baseline quality is the reference point, not the recommendation. It exists to prove that quantization damage is measurable and nonlinear. The drop from Q8_0 to Q5_K_M loses ~8% quality for ~7 GB VRAM savings, an acceptable trade for production coding. The drop from Q5_K_M to Q4_K_M loses another ~7% quality for ~3 GB savings, and that's where the pain starts. The drop to IQ4_XS ≈ 14 GB, ~75% quality is a 25% degradation for ~5 GB more savings, the math stops working.
Coding errors compound differently than chat errors. Summarization at 95% → 85% accuracy still produces readable results. Code at 92% → 85% fails static analysis, breaks tests, or worse—passes tests but fails production. At Q5_K_M, 92% quality keeps logical errors below human review detection. Below that, you're debugging the model's output more than your own code.
The Q5_K_M ≈ 19 GB, ~92% quality figure is why 24 GB VRAM became the default recommendation for serious coding. It's not about fitting the model—it's about headroom for context windows, concurrent IDE requests, and OS overhead. A 4090 at 24 GB runs Q5_K_M with 5 GB of breathing room. A 3090 at 24 GB does the same. At Q4_K_M ≈ 16 GB, a 16 GB card like the 4060 Ti or 5060 Ti fits the model but leaves almost nothing for the rest of the workflow.
The ~75% quality at IQ4_XS deserves specific warning. Not slightly worse—functionally broken. IQ4_XS is reported to produce non-existent imports, inverted logic, and plausible hallucinations. The ~14 GB VRAM savings cost more in debugging time than the hardware upgrade would have cost. For a deeper breakdown of why IQ4_XS degrades faster on code than other content types, see our IQ4 vs Q4 deep-dive.
Recommended Quantization by Use Case
The right quantization isn't a universal setting, it's a function of task type, hardware ceiling, and tolerance for rework.
Refactoring and agentic workflows demand Q5_K_M because the model reasons across file boundaries. When Aider or Continue.dev touch imports, signatures, and call sites across three files, one quantization error breaks the entire refactor. The ~92% quality at Q5_K_M keeps that cascade rate manageable. Q4_K_M at 85% works for small refactors you review—you'll fix model signatures frequently.
Autocomplete lives at the other end of the sensitivity spectrum. The model only needs to predict the next 5–20 tokens, not architect a multi-file change. A single bad token in an autocomplete suggestion is obvious, you don't accept it, you keep typing. Q4_K_M at 16 GB is viable. IQ4_XS at 14 GB technically works on 12 GB rigs, but you'll reject more suggestions.
Sub-12 GB rule: a clean-quantized smaller model beats an aggressively-quantized larger one. Phi-4 14B Q4_K_M ≈ 8.2 GB leaves headroom on a 3060 12GB while maintaining coherent logical reasoning. Qwen 3.6 27B at IQ4_XS ~14 GB squeezes onto the same hardware but degrades past usefulness. The ~75% quality figure for IQ4_XS on Qwen 3.6 27B versus the cleaner quantization profile of Phi-4 14B isn't a subtle difference, it's the gap between "occasionally wrong" and "unreliably wrong."
For exact launch parameters that match quantization to hardware tier, the Qwen 3.6 hardware requirements guide details context-length settings and batch sizes per VRAM level. The Phi-4 14B VRAM profile gives the 8.2 GB configuration with OS overhead accounted for.
Use-Case Routing: Match the Model to the Task
The model rankings change when you stop asking "which is best?" and start asking "best for what, on what hardware?" A 24 GB rig running Aider on a 10K-line repo faces entirely different constraints than a 12 GB laptop needing autocomplete in VS Code. The tables below route by task, not by benchmark supremacy.
Latency-Critical Tasks: Autocomplete & One-Off Fixes
Speed kills or saves the autocomplete experience. Continue.dev's inline suggestions between keystrokes: every millisecond of latency adds typing friction. Humans tolerate roughly 50 ms autocomplete delay end-to-end. Beyond that, developers disable it.
Phi-4 14B Q4_K_M at ~8.2 GB VRAM wins this category decisively. 14B loads fast, Q4_K_M keeps weights dense in memory, and the reasoning-tuned architecture produces accurate single-line completions without multi-file overhead. On a 3060 12GB, it sustains ~38 tok/s with IDE and browser tabs open. 78% HumanEval understates autocomplete utility. HumanEval tests functions, not next-token prediction—Phi-4's strength.
Qwen 3.6 7B ranks second for autocomplete latency, though specific data for this variant remains uncited. 7B should load faster than 27B, but quantization and context tuning for this variant aren't benchmarked. Use Qwen 3.6 7B if Phi-4's context limits hurt and Qwen's templates carry to smaller sizes. Verify VRAM first.
For one-off bug fixes, the calculus shifts slightly. The model needs to read a stack trace, locate the relevant function, propose a fix, and stop. No multi-file dependency tracking, no agentic loop. Phi-4 14B Q4_K_M wins: 8.2 GB vs Qwen's 19 GB. Faster fixes, less load, no context competition on single-file work.
On 12 GB rigs, Phi-4 14B Q4_K_M is the default. Full stop. Qwen 3.6 27B doesn't fit: Q4_K_M at 16 GB exceeds 12 GB capacity. IQ4_XS at 14 GB technically loads but degrades to useless.
Reasoning-Intensive Tasks: Refactoring & Agentic Coding
Multi-file refactoring demands the opposite of autocomplete: context length, architectural understanding, and error minimization across dependency chains. One wrong import in a refactored module breaks downstream files silently. One hallucinated parameter type in a renamed function poisons every call site. The model must hold the entire refactor in working memory, not just predict the next token.
Qwen 3.6 27B Q5_K_M at ~19 GB VRAM is the default for this workload. 85% HumanEval and 22% SWE-bench translate to reliability: function-calling that works, edits that compile, workflows that complete. The native <|im_start|> template and full function-calling support mean Aider, Continue.dev, and OpenCode all integrate without template-hacking. Q5_K_M at 92% quality preserves logical correctness across files—the threshold where refactoring errors stay below human detection.
DeepSeek V4 (37B MoE at 96+ GB unified or 24 GB + 64 GB offload) wins on massive repos and complex agentic workflows. MoE routes context to specialized experts for code structure, documentation, test generation—not loading all 671B parameters. At 88% HumanEval, DeepSeek V4 beats Qwen 3.6 27B, with wider gaps on long-context dependency benchmarks. On 5,000+ line repos, DeepSeek V4's expert routing produces fewer cascading errors across dozen-file refactors.
The hardware split is brutal. DeepSeek V4 demands 96 GB unified memory (M3 Max, M4 Max, M5 Max high-end Apple Silicon) for in-core operation. The 24 GB + 64 GB offload path exists but limps: 40% of forward passes in system RAM at 51 GB/s (DDR5-6400) versus 273 GB/s Strix Halo. For multi-GPU setups with NVLink or tensor parallelism, DeepSeek V4 is the agentic champion. For single-GPU builders, it's a mismatch, the model demands more than the rig can give.
Avoid Phi-4 14B for agentic work entirely. Not the HumanEval gap—weaker function-calling and shorter context windows are the problem. Phi-4 14B can't reliably track three-file dependencies. Aider template compatibility remains untested. 8.2 GB brilliance for autocomplete becomes irrelevant when the task needs architecture Phi-4 can't hold.
The hardware-fit decision precedes the model choice. For exact VRAM requirements and launch parameters per tier, the Qwen 3.6 hardware guide details context-length settings and batch sizes. For DeepSeek V4's memory architecture and tensor-parallel tuning, see the DeepSeek V4 setup guide. For 12 GB builds that can't touch either primary recommendation, the 3060 12GB guide covers Phi-4 14B optimization for the tasks it can handle.
Runner Stack & IDE Integration
The model is half the battle. Now get it into your workflow without repeating April 28's failure. The runner stack and IDE integration determine whether local coding feels native or hobbyist.
Inference Engines
Three runners dominate the May 2026 landscape, and the choice depends on your tolerance for setup complexity versus control granularity.
Ollama is the fastest path to running Qwen 3.6 27B:
ollama pull qwen3.6:27b-q5_K_M
ollama run qwen3.6:27b-q5_K_MOne command, model downloaded, OpenAI-compatible API exposed on localhost. Ollama handles quantization detection, context-window defaults, and memory mapping automatically. The trade-off: opacity. Batch size, tensor parallelism, and custom quantization need lower-level tools.
LM Studio is the GUI path. No terminal, no ollama pull syntax to memorize. Point, click, select Qwen 3.6 27B Q5_K_M from the model browser, and the server starts with a system-tray icon. It exposes the same OpenAI-compatible API for IDE integration. Abstraction hides memory mapping and context batching. Power users hit ceilings on hardware optimization.
llama.cpp + llama-server is the power-user choice. Build from source or pull a release, then launch with exact control:
./llama-server -m qwen3.6-27b-q5_K_M.gguf -c 32768 -ngl 99 --host 0.0.0.0 --port 8080The -ngl 99 flag offloads all layers to GPU. -c 32768 sets context length. llama.cpp unlocks tensor parallelism, custom quantization pipelines, and batch-size tuning. The cost is setup time and debugging, this is not a one-command path.
All three expose OpenAI-compatible APIs at http://localhost:11434 (Ollama) or http://localhost:1234 (LM Studio) or http://localhost:8080 (llama-server). Your IDE configuration doesn't change; only the endpoint does. For a full runner comparison including vLLM and throughput benchmarks, see our Ollama vs LM Studio vs llama.cpp comparison.
IDE Integration
The IDE layer determines whether the model's capabilities translate to productivity gains or setup friction.
Continue.dev (VS Code, JetBrains) provides inline code completion and refactoring. Highlight a function, hit the shortcut, and the model suggests a refactor with diff preview. The integration reads your open files for context, sends them to the local API endpoint, and streams suggestions. Configuration is a single JSON block:
{
"models": [{
"title": "Qwen 3.6 27B",
"provider": "ollama",
"model": "qwen3.6:27b-q5_K_M"
}]
}Continue.dev works with all three runners. Latency = the model's tok/s plus negligible localhost network overhead.
Aider is terminal-first agentic coding. It reads your git repository, proposes multi-file edits, and commits with descriptive messages. Git-awareness is the killer feature: Aider tracks which files changed, avoids conflicts, and rolls back failures. Launch with:
aider --model ollama/qwen3.6:27b-q5_K_MAider demands more from the model, function-calling reliability, multi-file context tracking, template compliance, which is why Qwen 3.6 27B's native <|im_start|> support matters. Older models required template overrides that broke on edge cases.
OpenCode Apr 19 r/LocalLLaMA, 647 upvotes targets Apple Silicon. MLX acceleration on M5 Max 64 GB unified memory delivers tok/s that x86 runners can't match. Trade-offs: platform lock-in, no Windows or Linux support, and a curated (not open) model ecosystem. Apple ecosystem: substantial performance gains. Cross-platform teams: fragmentation risk.
Choose your workflow: GUI-centric (Continue.dev), terminal-agentic (Aider), or Mac-native (OpenCode). The model doesn't care; the API is standard. Productivity = IDE demands matched to model capabilities. That's why routing tables precede integration discussion.
What Changed Since 2025
Late 2025's consensus model was Qwen 2.5 Coder, a specialized coding-focused variant stripped of generalist bloat. It was the safe recommendation, "use the specialist" was standard advice. Qwen 3.6 27B arrived early 2026 as general-purpose, absorbing the specialist's edge through better training. Now it beats Qwen 2.5 Coder on refactoring, function-calling, and agentic workflows. The specialist became redundant.
This shift matters for buyers. In 2025, you maintained two models: a generalist for chat and summarization, a coder for IDE work. In 2026, Qwen 3.6 27B handles both. Running one model saves VRAM: no context switching, no duplicate weight loads.
DeepSeek V4 emerged in May 2026, opening a new decision vector: local-as-cloud-replacement for high-memory setups. The 17× cheaper than GPT-5.2 in cloud math only works if your hardware can absorb the 671B parameter count. For multi-GPU clusters and 96 GB+ Apple Silicon, it's a genuine API alternative. For consumer hardware, it's aspirational—viable when memory costs drop.
CodeGemma 4 launched in the same May 2026 window but hasn't displaced Qwen 3.6 27B as consensus. Google's model trades depth for speed, Python specificity for generality. It's a secondary choice, not a primary recommendation. Apache 2.0 license removes Qwen's friction, but license alone can't bridge the benchmark gap.
The hardware landscape shifted too. 24 GB became the 2026 coding minimum. Not because models grew, but because quantization matured. Q5_K_M at 19 GB VRAM is the error-management threshold—and it requires headroom. A 16 GB card in 2025 ran Q4_K_M without understanding the quality penalty. In 2026, that same card runs Q4_K_M knowingly, with eyes open to the ~85% quality trade-off.
For broader hardware-fit decisions across all model tiers, the best hardware for local LLMs 2026 guide covers GPU, RAM, and platform choices that precede model selection.