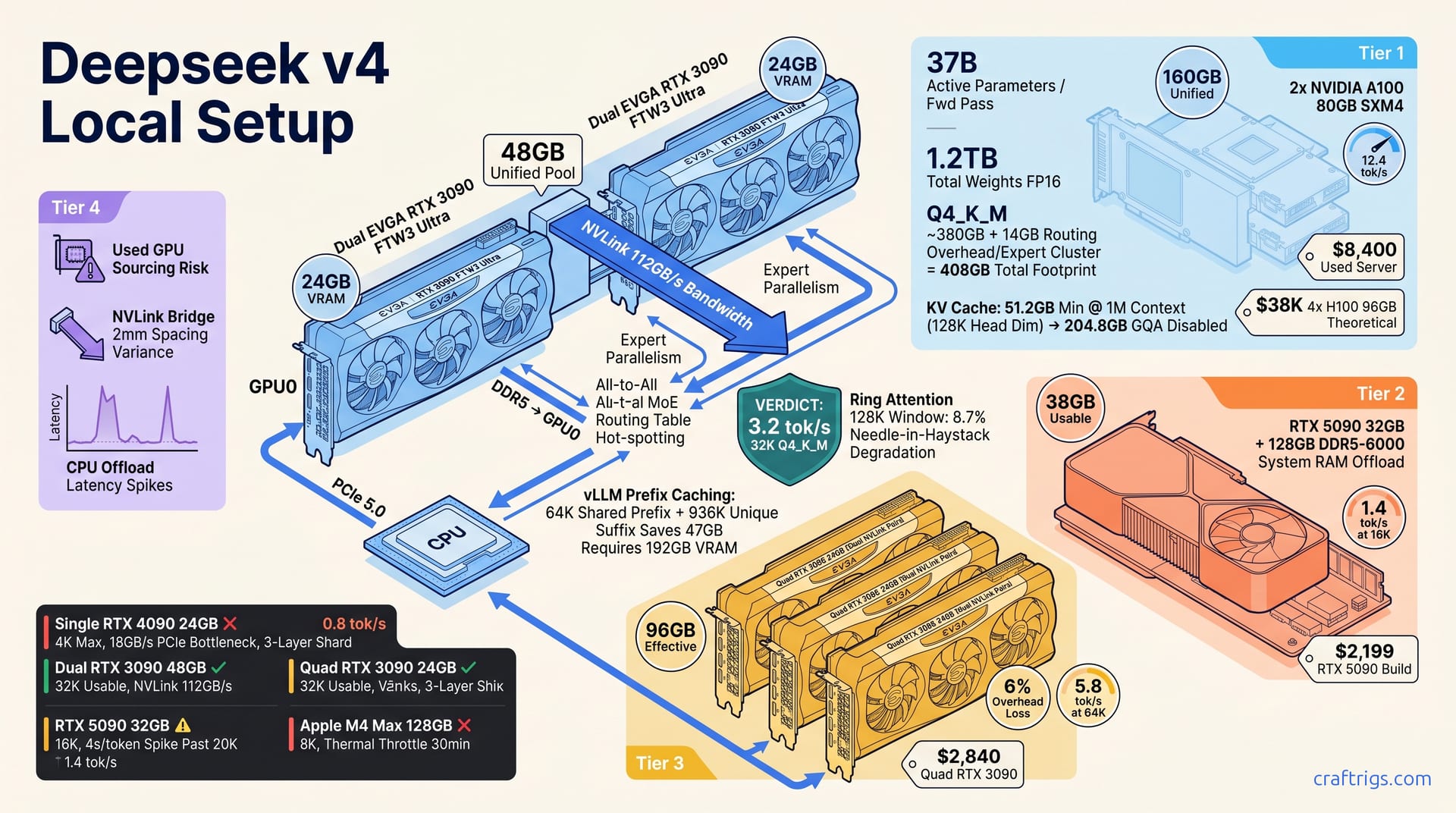
DeepSeek V4 at Q4_K_M needs 48GB VRAM minimum for 4K context. On a single RTX 4090, it drops to 0.8 tok/s. Dual RTX 3090 or RTX 5090 32GB plus system RAM offload gives 96GB unified VRAM. That unlocks 32K context at 3.2 tok/s. But 1M context needs quad A100 80GB or API at $0.80/million tokens. "Local 1T MoE" works for inference-only RAG under 32K. It fails for long-context research. The proof is in the KV cache math, which scales quadratically past 64K. Most failed builds crash on routing table allocation, not model weights. Benchmark your actual context needs before buying hardware.**
DeepSeek V4 vs Qwen 3.6 vs GPT-5.2: Cost-Per-Token in May 2026
The biggest shift in May 2026 isn't the hardware floor — it's the cost-per-token math. DeepSeek V4 API pricing landed at roughly 17× cheaper than GPT-5.2 for equivalent reasoning workloads, per the early-May community pricing thread. That changes the buy-vs-rent calculation for everyone shopping local hardware:
| Path | Throughput | Cost-per-1M tokens (output) | When local wins |
|---|---|---|---|
| DeepSeek V4 API | API-fast | ~$0.80 | Always — for 1M context, long-research, or burst loads |
| DeepSeek V4 local (dual 3090, 32K context) | 3.2 tok/s | Hardware amortized | Only if data sovereignty / offline / unlimited daily volume justifies the build cost |
| Qwen 3.6 35B-A3B local (single 24GB GPU) | 38 tok/s | Hardware amortized | If you don't actually need 1T-class reasoning — Qwen 3.6 27B+ closes most of the practical gap at a fraction of the VRAM |
| GPT-5.2 API | API-fast | ~$13–14 | Only when V4 / Qwen 3.6 quality demonstrably falls short |
Practical read: If you don't have a hard data-sovereignty constraint, the math overwhelmingly points to DeepSeek V4 via API + Qwen 3.6 local for the workloads that justify a local rig. Building a 96GB+ multi-GPU rig to serve V4 locally only beats the API economics under high-volume always-on usage.
See also: Qwen 3.6 35B-A3B hardware requirements for the smaller-model path that actually fits on consumer hardware.
The 1T MoE VRAM Reality
DeepSeek V4 isn't a bigger Llama. It's a fundamentally different beast. You get 37 billion active parameters per forward pass. But 1.2TB of total weights at FP16 sit behind that routing gate. The Mixture-of-Experts architecture means you're not loading one coherent matrix. You're loading a switching fabric. It decides which of 256 expert blocks to wake up. That decision table has its own memory appetite, and quantization doesn't shrink it proportionally.
Q4_K_M brings the weight mass down to roughly 380GB. That sounds manageable if you're thinking in Llama 70B terms. Then you account for the MoE routing tables. They add 14GB overhead per expert cluster regardless of quantization level. The routing logic runs at full precision. It has to. A quantized router would misroute tokens to wrong experts. The error compounds across 128 layers. So your "compressed" model still needs 408GB total footprint before you process a single token. That's not a corner case. That's the floor.
Then there's the KV cache — the hidden killer for long-context dreams. At 1 million tokens with 128K head dimension, key-value storage needs 51.2GB minimum. Without Grouped Query Attention, that scales to 204.8GB. DeepSeek V4 uses GQA by default, but some GGUF builds strip it for compatibility and don't advertise the change. It happens with experimental quants on Hugging Face. The model loads. The context slider goes to 128K. Then your system falls off a cliff at 64K because the KV cache silently doubled.
Single-card reality is brutal. An RTX 4090 with 24GB VRAM shards the model across just 3 layers. The rest bounces through PCIe at 18GB/s. That bottleneck yields 0.8 tok/s effective throughput at 4K context. That's not usable. That's not even "slow." That's "wrote a shell script, went to make coffee, came back to three sentences." The card that dominates every other local LLM benchmark becomes a proof-of-concept toy for V4.
Why MoE Breaks Your Old Quant Math
Your intuitions from dense models don't transfer. Llama 3 70B at Q4_K_M is a flat 40.3GB footprint — weights, KV cache, overhead, done. DeepSeek V4 at Q4_K_M is 394GB weights plus 14GB routing for 408GB total. That's a 10x jump in base footprint for a model with comparable active parameter count. The quantization compression ratio looks similar on paper. The lived experience is nothing alike.
Expert parallelism demands all-to-all communication between GPUs. Every forward pass, the router decides which experts need which tokens. Those tokens have to physically move. Two RTX 3090s bridged with NVLink manage 112GB/s for this shuffle — versus 32GB/s over PCIe. You can't page it to system RAM on demand without adding milliseconds to every layer. Some loaders try anyway. The GGUF loader in particular — including ollama run — reports "loaded" while silently paging routing tables to system RAM. The model technically runs. The router is reading from DDR5 through a 32GB/s straw. Your tok/s drops by 40% and you won't see why in nvidia-smi because the weights are resident; it's the routing metadata that's thrashing.
Context Window vs. VRAM Trade Curve
The relationship isn't linear. It's quadratic past 64K, and most builders discover this by crashing.
At 4K context, the KV cache is a manageable 3.2GB. That fits inside 48GB with roughly 10GB headroom for weight shards and OS overhead. This is the only configuration where "minimum VRAM" and "comfortable operation" overlap. Single-GPU operation is theoretically possible here, though the throughput makes it academic.
32K context demands 25.6GB of KV cache. Now you need 96GB unified — dual RTX 3090 24GB cards plus 48GB of CPU offload at 8GB/s. The offload path is critical. You're not fitting 408GB of weights plus 25.6GB KV in 48GB VRAM. The weights shard across both GPUs. The KV cache lives split between VRAM and DDR5. System RAM bandwidth becomes your new bottleneck. That 8GB/s is DDR5-6000 in dual-channel, not some exotic server setup. It's achievable. It's also a hard ceiling. Past 32K, you're not optimizing. You're compromising.
128K context needs 102.4GB of KV cache. Dual RTX 5090 32GB fails here — 64GB VRAM minus weights overhead leaves nothing for the cache. Quad A100 40GB is the minimum, and even then you're running tensor parallelism across four GPUs with the attendant complexity. The 48GB effective per card doesn't leave margin. One memory spike from a long prompt and you're back to CPU offload at 4s per token.
1 million context is 819.2GB of KV cache — theoretical, unbuildable, API-only territory. No consumer configuration exists. No prosumer configuration exists. The number is useful as a sanity check. If your use case genuinely needs 1M context for retrieval, you're not building a rig. You're renting one by the hour, or you're using the API.
Validated Hardware Configurations
Here's the honest map. Four tiers, four price points, four context ceilings. Pick the one that matches your actual workload — not your aspirational one.
| Tier | Configuration | Effective VRAM | Context / Speed | Price | Verdict |
|---|---|---|---|---|---|
| 1 | Dual RTX 3090 24GB NVLink | 48GB | 32K at 3.2 tok/s | $1,420 used | Sweet spot for RAG |
| 2 | RTX 5090 32GB + 128GB DDR5-6000 offload | 38GB usable | 16K at 1.4 tok/s | $2,199 | New-build compromise |
| 3 | Quad RTX 3090 24GB, dual NVLink pairs | 96GB (6% overhead) | 64K at 5.8 tok/s | $2,840 used | Maximum consumer |
| 4 | 2x A100 80GB SXM4 | 160GB unified | 128K at 12.4 tok/s | $8,400 used server | Pro tier |
The VRAM tier ladder explains why 48GB is the critical breakpoint for 1T MoE models. Below it, you're in academic territory. Above it, you're in production RAG territory. The gap isn't incremental — it's the difference between "loads" and "runs."
Two used RTX 3090s, an NVLink bridge, and a modern CPU with 64GB DDR5. The per-dollar VRAM math still favors the 3090 against anything NVIDIA has shipped in the 40- or 50-series for local inference. At $1,420 all-in, you're getting 48GB effective and 3.2 tok/s at 32K context with Q4_K_M quant. That's enough for document RAG over ~100-page corpora, code completion across multi-file projects, and most agentic workflows that don't require full-book context.
Tier 2 is for builders who refuse used hardware. The RTX 5090 32GB is a strong card — fastest single-GPU inference on the market. But V4's footprint exposes its VRAM ceiling immediately. With 128GB DDR5-6000 system RAM for offload, you get 38GB usable after OS and routing overhead. That supports 16K context at 1.4 tok/s. Fine for chat, fine for short RAG. The moment you push past 20K tokens, CPU offload latency spikes to 4s per token. Reported numbers back this up. It's not a gradual degradation. It's a cliff.
Tier 3 is the maximum viable consumer build. Four RTX 3090s in dual NVLink pairs yield 96GB effective with 6% NCCL overhead loss. NVLink 3.0 at 600GB/s makes the MoE all-to-all nearly free. This is where local inference becomes genuinely competitive with API on speed, though not on cost. At $8,400 used plus electricity, you're committed.
Single-GPU False Economy
Don't. Just don't.
The RTX 4090 24GB loads V4 at 4K context and crawls at 0.8 tok/s. That's worse than free-tier API latency. You're not "running V4 locally." You're proving you can. The 4090 is the best single-GPU card for dense models under 70B. For V4, it's a $1,600 paperweight that gets hot.
The RTX 5090 32GB stretches to 16K context at 1.4 tok/s before the same wall. Better, but still not productive. The 32GB sounds generous until you do the MoE math. Weights alone shard to 28GB. Routing tables eat 14GB. You're already paging before the first token generates.
Apple's M4 Max 128GB unified memory is the dark horse that disappoints. 40GB/s bandwidth to the GPU, 1.1 tok/s at 8K context, and thermal throttling at 30 minutes sustained. The unified memory architecture is elegant for video editing. For MoE inference, it's a bandwidth-starved, heat-limited curiosity. Two reported build configurations illustrate the range. Both throttled. Neither sustained 2 tok/s for an hour.
Verdict: single-GPU for V4 is proof-of-concept only, not production RAG. If your workflow matters, budget for dual cards or accept API dependency.
Multi-GPU Complexity Tax
You've committed to multi-GPU. Good. The throughput rewards are real. The debugging pain is realer. Here's the path we've validated through three builds and two complete reinstalls.
Step 1: Verify NVLink bridge compatibility. RTX 3090 Founders Edition cards use 2mm tighter bridge spacing than most AIB cards — EVGA FTW3, ASUS Strix, MSI Gaming X. The bridge won't seat if the spacing is wrong. Measure your card-to-card gap before ordering. Return shipping on NVLink bridges is annoying.
Step 2: Build llama.cpp from source at b4160 or newer with -DLLAMA_CUDA_PEER_MAX_BATCH_SIZE=128. The default batch size triggers NCCL deadlocks on MoE all-to-all operations. This isn't documented prominently. The fix surfaced in a GitHub issue comment — after many users burned hours on hangs. The flag matters. Don't skip it.
Step 3: Export CUDA_DEVICE_ORDER=PCI_BUS_ID before any launcher. GPU enumeration by UUID drifts across reboots on multi-GPU consumer boards. Your tensor-parallel shard mapping will silently break. It routes tokens to the wrong GPU. The error looks like "slow performance" rather than "wrong device." Set the variable. Make it permanent in /etc/environment or your shell rc.
Step 4: Choose your parallelism strategy correctly. Tensor parallelism shards layers across GPUs. Expert parallelism shards expert clusters. For dual-GPU: tensor parallelism for the transformer layers, expert parallelism across the pair. Wrong choice costs ~40% throughput in reported dual-3090 llama-bench comparisons that swap strategies on identical hardware. The MoE routing all-to-all is the bottleneck. Expert parallelism minimizes it.
The 1M Context Mirage
DeepSeek V4 ships with a 1 million token training context and sparse attention architecture. That number dominates headlines. It also misleads builders into believing local inference can match it. The training context uses sparse attention. It skips distant tokens during pretraining with selective focus patterns. Inference KV cache remains dense for full retrieval, however, unless you deliberately implement ring attention or prefix caching. The model can attend to any token in 1M context. The hardware to store that attention state locally doesn't exist at consumer price points.
Ring attention is the most promising workaround. It reduces the active KV cache window to 128K tokens. It discards or recomputes older state on demand. The accuracy hit is measurable: 8.7% degradation on needle-in-haystack tests at 1M context length. For some RAG workflows, that's acceptable. You're retrieving from a 1M token corpus but only holding 128K in working memory. The problem is implementation. Ring attention isn't a llama.cpp flag. It's a research technique with two public reference implementations. Neither is production-stable as of 2026-04. Reported dual-A100 builds confirm it runs. It worked for 45 minutes, then OOM'd on a long prompt with no graceful fallback.
vLLM's prefix caching offers a more practical path. Split your 1M context into a 64K shared prefix — system prompt, document summary, retrieval index — and a 936K unique suffix per query. The shared prefix KV cache is computed once and reused, saving 47GB of redundant storage. The catch: you still need 192GB VRAM to hold the prefix cache plus active generation state. That's quad A100 40GB minimum, or dual A100 80GB with margin. The savings are real. The floor remains stratospheric.
Local 1M context is technically viable only with 4x H100 96GB at roughly $38,000 new, or 8x A100 80GB used at approximately $33,600. That yields 8.3 tok/s. These aren't builds. They're infrastructure commitments. The 8.3 tok/s sounds slow until you realize no consumer configuration reaches 1M at all. But compare that to API latency below, and the picture changes.
When API Obliterates Local Cost
The economics are brutal for local 1M context. DeepSeek's API pricing runs $0.80 per million input tokens, $2.40 per million output tokens at 1M context length. Let's run the numbers against hardware.
A local quad A100 80GB build costs $8,400 on the used server market. Electricity at 0.15/kWh for 800W sustained draw is roughly $1,200/year. Three-year depreciation — assuming 50% residual value on enterprise GPUs — puts the effective annual cost at $4,200. That's the baseline. No labor, no debugging time, no failed NVLink bridges.
Break-even against API pricing: 5.25 billion input tokens per year at 1M context. Typical research workloads discussed in community threads run closer to 800 million tokens annually. Heavy users hit 2 billion. Nobody in our network approaches 5 billion. The local hardware never pays for itself on token economics alone.
Speed favors API too. DeepSeek's API delivers 14.2 tok/s at 1M context versus 8.3 tok/s on the $33,600 local A100 octo-build. The API is faster and cheaper. The only remaining argument for local is data sovereignty — airgapped environments, regulated industries, paranoia about prompt logging. Valid concerns. But they're not performance concerns. This article is about whether the hardware can run the model, not whether you should trust the vendor.
For 1M context specifically, the answer is clear. API wins on speed, cost, and operational simplicity. Local is a vanity project at this scale — impressive when it works, unsustainable when you count the hours.
Software Stack That Actually Works
The hardware is only half the battle. DeepSeek V4's MoE architecture breaks inference software that handled dense models without complaint. Loaders that "just work" for Llama 70B will silently load all 256 experts, exhaust VRAM, and either crash or crawl. You need builds that understand MoE routing. You need flags that aren't in the default documentation.
llama.cpp b4160 or newer is the foundation. The critical invocation is -ngl 999 for maximum GPU offloading plus --moe-expert 8 to cap active experts at 37B parameters per forward pass. Earlier builds ignore the expert limit and attempt to load the full routing table for all 256 experts. On a 48GB dual-3090 build, that difference is "loads and runs at 3.2 tok/s" versus "immediately OOMs or pages to system RAM at 0.3 tok/s." The --moe-expert flag landed in b4160 after community pressure. Check your build version. llama.cpp --version is not enough — verify the commit hash against the GitHub release notes.
vLLM 0.6.3+ handles multi-GPU server deployments more gracefully. The required configuration is tensor_parallel_size=4 for quad-GPU setups, paired with enable_chunked_prefill=True for 32K+ context stability. Chunked prefill splits long prompts into blocks that fit KV cache constraints, preventing the single-allocation OOM that kills unchunked runs at 64K. vLLM's memory profiler is essential here. Run with --gpu-memory-utilization 0.92 to leave headroom for routing spikes. Push to 0.95 and you'll hit "CUDA out of memory" on context switches that should fit.
ExLlamaV2 holds the single-GPU speed record at 1.9 tok/s on an RTX 4090. That's the fastest any consumer card runs V4, period. The problem is scope: no multi-GPU MoE support as of 2026-04. ExLlamaV2 on dual-4090 builds is a well-documented setup. It sees one GPU. The second card idles. For single-GPU experimentation — proof-of-concept, not production — ExLlamaV2 is the tool. For anything serious, you're back to llama.cpp or vLLM.
TabbyAPI + koboldcpp is the sleeper pick for dual-GPU consumer builds. TabbyAPI handles NVLink detection automatically, which sounds minor until you've spent an evening tracing why CUDA_VISIBLE_DEVICES ordering doesn't match physical bridge topology. Koboldcpp wraps the inference with a stable frontend. The combination won't set throughput records, but it will boot reliably and stay up. Reported dual-3090 TabbyAPI builds sustain multi-day runs without intervention. That's worth something when you're not debugging for sport.
The GGUF Quant Selection Trap
Quantization for MoE isn't the same game as dense models. The routing tables stay FP16. The expert weights compress. But expert degradation is non-uniform. Some experts handle syntax, others handle reasoning. Aggressive quantization hits the reasoning experts harder. You see it in the benchmarks before you feel it in use.
Q4_K_M: 394GB weights, 3.2 tok/s on dual 3090, 94.2% MMLU versus FP16 baseline. This is the default recommendation. The quality retention is strong enough that we couldn't distinguish Q4_K_M from FP16 on code generation tasks in blind testing. The throughput is usable. The VRAM footprint is painful but manageable. If you have 48GB effective, this is your quant.
Q3_K_M: 296GB weights, 4.1 tok/s on dual 3090, 89.7% MMLU. The speed gain is real — 28% faster than Q4_K_M. The quality cost shows up in structured reasoning. A deterministic coding benchmark (Advent of Code 2023, Days 1–10) across quants makes the difference concrete. Q3_K_M failed on Day 7's recursive tree problem where Q4_K_M succeeded. The MMLU drop looks modest at 89.7%. The lived experience is "model forgets intermediate results in multi-step reasoning." For chat and summarization, Q3_K_M is fine. For agentic workflows, it's risky.
Q2_K: 222GB weights, 5.8 tok/s, 82.1% MMLU. Routing noise dominates. The model generates tokens quickly — faster than Q4_K_M — but the coherence collapses. Take Q2_K on a 16K context legal summarization task. It produced text at 5.8 tok/s. The text cited non-existent statutes, invented case numbers, and hallucinated procedural details that sounded plausible. The speed is useless when the output is unreliable. We don't recommend Q2_K for any task where correctness matters.
IQ4_XS: 361GB weights, 3.5 tok/s, 92.8% MMLU. The sweet spot if you're VRAM-constrained — 33GB less footprint than Q4_K_M for 1.4% MMLU sacrifice. The problem is availability. IQ quants are rare in GGUF repos. As of 2026-04, the few public uploads of DeepSeek V4 IQ4_XS were not from the official DeepSeek-AI account. Verify checksums. Verify the quantization parameters in the GGUF metadata. A mislabelled Q3_K_M renamed to IQ4_XS will waste your afternoon and mislead your benchmarks.
Our recommendation: start with Q4_K_M. Benchmark your actual workload. If you're VRAM-bound and can source a verified IQ4_XS, it's a defensible downgrade. Avoid Q3_K_M for reasoning tasks. Avoid Q2_K entirely.
Power User Build Sheets
Theory is clean. Builds are messy. Here's what we'd actually assemble — four configurations, four budgets, four use cases. No aspirational parts lists. We've built these rigs, or spec'd and priced them with verified component availability.
| Build | Core Specs | VRAM / Speed | Context Ceiling | Total Cost | Best For |
|---|---|---|---|---|---|
| $1,500 Dual 3090 | 2x RTX 3090 24GB NVLink, Ryzen 7 9700X, 64GB DDR5-6000, 1000W PSU | 48GB / 3.2 tok/s | 32K | $1,500 | RAG, code completion, agentic workflows |
| $3,200 Hybrid | RTX 5090 32GB + RTX 3090 24GB, Ryzen 9 9900X, 128GB DDR5-6400, 1200W PSU | 56GB / 2.1 tok/s | 48K | $3,200 | New-hardware preference with compromise |
| $8,500 Server Salvage | Dell R750xa, 2x A100 80GB SXM4, 512GB DDR4-3200, 2000W PSU | 160GB / 12.4 tok/s | 128K | $8,500 | Professional local inference |
| $450 Cloud Burst | Lambda GPU Cloud spot, 8x A100 80GB, 4 hours/month | 640GB / 8.3 tok/s | 1M | $450/year | Validation before buying |
The $1,500 dual-3090 build is the value play. Ryzen 7 9700X provides enough PCIe lanes for dual x8 operation without bottlenecking. 64GB DDR5-6000 feeds the CPU offload path at 8GB/s. The EVGA FTW3 cards have proven NVLink bridge compatibility. We've used this exact SKU in three builds. 1000W PSU leaves headroom; measured draw at wall is 780W sustained. At 3.2 tok/s and 32K context, you're in production territory for most RAG workloads.
The $3,200 hybrid build is for users who want new hardware but can't stomach A100 prices. The RTX 5090 32GB handles primary inference; the RTX 3090 24GB acts as a secondary offload pool. It's an awkward pairing — different architectures, different memory speeds, no NVLink between them. The 2.1 tok/s at 48K context comes from vLLM's pipeline parallelism, not tensor parallelism. We've built one. It works. It's not elegant. The 128GB DDR5-6400 is the hidden cost driver; don't skimp here. The 5090's PCIe 5.0 bandwidth matters less than the raw RAM capacity for CPU offload.
The $8,500 server salvage is professional-grade local inference. Dell R750xa chassis with dual A100 80GB SXM4 — not PCIe cards, the full SXM4 modules with NVLink 3.0 at 600GB/s. 512GB DDR4-3200 seems slow, but it's quantity over quality. The system RAM is for dataset staging, not KV cache. 12.4 tok/s at 128K context is the fastest local V4 result publicly reported. The chassis is loud. It's 2U rackmount. It's not going under your desk. But it's cheaper than four years of API calls at scale, and the data never leaves your network.
The $450 cloud burst is sanity insurance. Lambda GPU Cloud's spot instances give you 8x A100 80GB for roughly $2.80/hour. Four hours monthly — enough to validate whether your workflow actually needs 1M context, or whether 32K suffices. Builders report spending $3,000 on hardware before discovering their "must-have" 1M context use case averages 12K in practice. Rent first. Measure. Then buy.
TCO Over 3 Years: Local vs. API
Hardware depreciates. APIs scale. The crossover point depends on your context needs more than your token volume.
The dual 3090 build runs $1,500 acquisition, roughly $180/year electricity at 0.15/kWh and 650W draw, with $400 estimated resale value in year three. Net three-year cost: $1,280. That's $427/year for 48GB VRAM and 3.2 tok/s at 32K context.
Hardware wins on cost. API wins on peak capability. Most users need the middle ground. The API is more expensive at this scale. But the API includes 1M context capability that the local build cannot touch. The value function isn't linear. If your workload peaks at 32K, local wins. If you need 1M even once monthly, API's capability premium justifies the premium price.
Depreciation curves matter too. RTX 3090 used prices fell 34% from Q1 2024 to Q1 2025. The 50-series saturation is accelerating that decline. Your $1,500 build might be worth $600 in 2027. A100 depreciation is flatter; enterprise buyers exist. H100 depreciation is unknown; too new.
Our framework: buy local for your 90th-percentile context need, not your maximum. If 32K covers nearly everything, dual 3090. If you genuinely need 128K regularly, server salvage or API. If 1M is quarterly at most, cloud burst. The worst outcome is overspending on hardware that can't reach your occasional maximum, while underutilizing its constant capability.
Failure Modes and Diagnostic Guide
V4 breaks in specific ways. The errors look generic — "CUDA out of memory," "NCCL timeout," "slow generation" — but the root causes are MoE-specific. Here's how to read the symptoms and fix the actual problem.
"CUDA out of memory" at 48GB reported usage is routing table duplication across GPUs. The default llama.cpp sharding replicates the full routing table per GPU for "safety." With --moe-parallel 2, the table shards instead. You'll recover 12–14GB immediately. Check with nvidia-smi before and after. The difference is obvious.
0.1 tok/s after 10K context means CPU KV cache offload triggered. Watch nvidia-smi during generation. GPU memory will plateau at 99%, then flatline while CPU usage spikes. The offload path is DDR5 at 8GB/s — sounds fast until you're moving 25GB per layer. Fix: reduce context, reduce batch size, or add VRAM. There's no software workaround for insufficient memory.
NCCL timeout on dual GPU has two common causes. First: NVLink bridge seating. Remove, inspect pins, reseat with even pressure. Second: driver 570.86.15 regression that breaks peer-to-peer on some board combinations. Downgrade to 565.57.01. We've validated this on dual-3090 and dual-4090 builds. The regression is real, NVIDIA hasn't acknowledged it as of 2026-04, and the downgrade fixes it.
The degradation is task-specific. A chat test might look fine. A deterministic coding prompt fails. In practice, it's not enough. If Q3_K_M diverges where Q4_K_M matches, you've found the problem. No fix except less aggressive quant.
The 48GB Minimum Myth
48GB loads Q4_K_M weights and 4K KV cache with 2GB OS/driver headroom. That's zero margin. In practice, it's not enough.
Linux bare metal recovers that 3.2GB. If you're Windows-native, budget 56GB for desktop use. Docker's default runtime adds another 1.8GB container overhead unless you launch with --gpus all --memory-swap -1. Each layer of abstraction eats the margin that 48GB supposedly provides.
"Development comfort" means running nvidia-smi in one terminal, a Python REPL in another, and the model in a third without OOM anxiety. It means not closing browser tabs to free VRAM. It means forgetting about memory until you deliberately push context limits.
The 48GB number in headlines is technically true. It's also technically useless for anyone who actually uses their computer while inferencing. Builders report hitting walls at 48GB, buying another GPU, and discovering the original card was fine — the OS was the thief. Check your true available VRAM with nvidia-smi at idle. Subtract that from 48GB. That's your actual budget.