AWQ matches Q4_K_M quality at 4-bit. Only vLLM, TGI, and SGLang run it natively—Ollama and llama.cpp don't. Pick AWQ + vLLM for multi-user Linux serving (NVIDIA/AMD). Pick GGUF for universal runner support or single-user chat. Converting between them is lossy. Download the native format you need instead of trying to convert.
What is AWQ?
AWQ selects per-group scale factors to preserve the most information-dense activation channels in model weights. Unlike uniform approaches that treat every weight identically, AWQ recognizes that some activation channels carry disproportionately more information. It protects those channels with finer-grained scaling while compressing the rest aggressively.
AWQ uses representative data to optimize scales (calibration-aware), similar to GGUF's imatrix. This calibration step is what separates AWQ from older methods that blindly chop precision. The model sees representative data during quantization, learning which weights suffer most when rounded down. This awareness delivers measurably lower perplexity on downstream tasks than non-calibrated 4-bit schemes.
AWQ enforces 4-bit (group-size 128) with no 3-bit or 5-bit variants, unlike GGUF. This rigidity is both a feature and a limitation. On the plus side, every AWQ file behaves predictably. You don't guess whether your runner supports some exotic group-size hybrid. The trade-off is that you can't trade quality for VRAM the way IQ4_XS lets you with GGUF, and you can't squeeze into tighter budgets with 3-bit the way Q3_K_M might allow.
AWQ vs GGUF: Quality, Size, and Speed
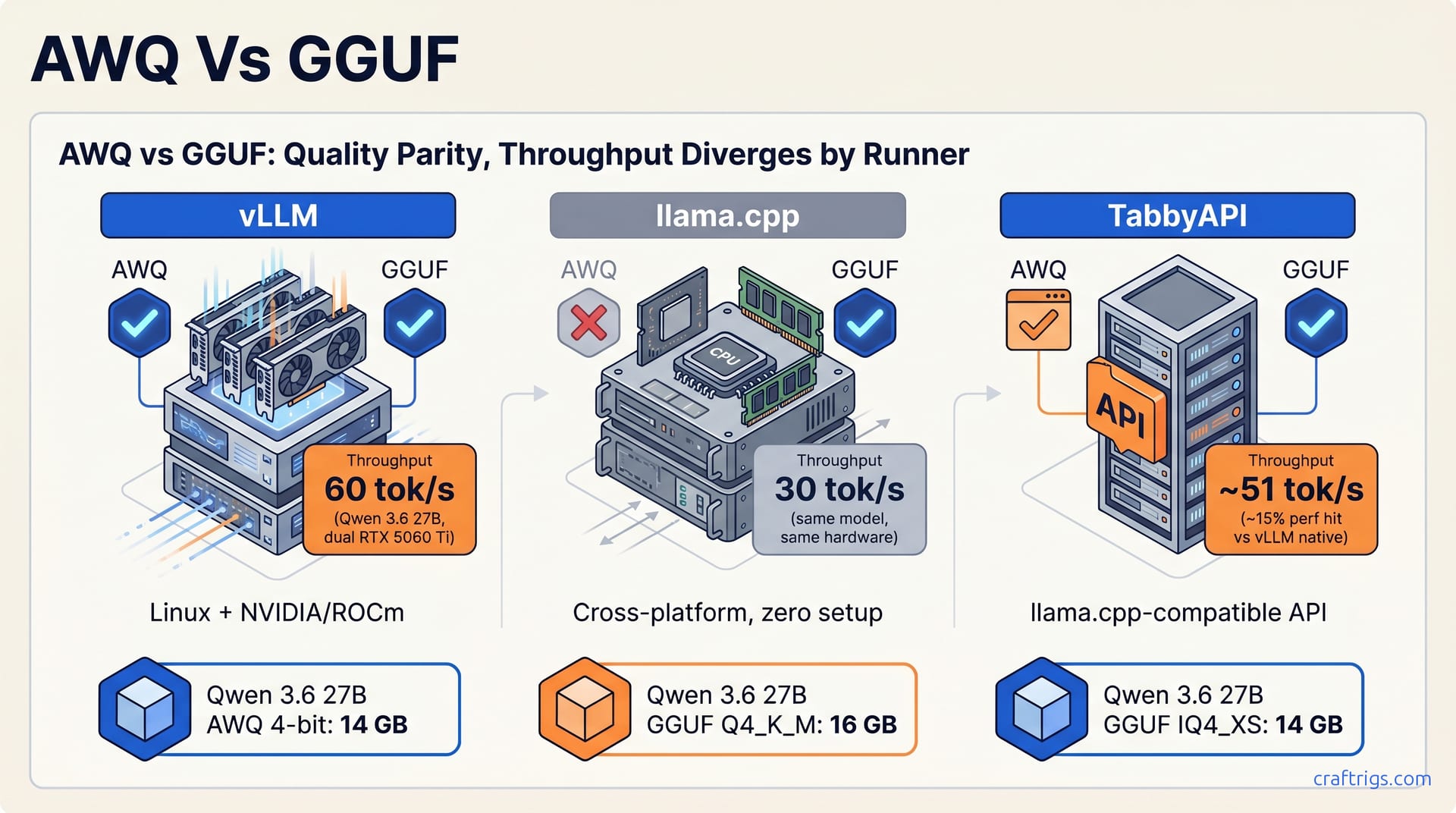
AWQ and GGUF Q4_K_M sit in a statistical dead heat on perplexity benchmarks for the same model at the same nominal bit-width. IQ4_XS, GGUF's own calibration-aware format, narrows the gap further. Quality isn't the differentiator. AWQ matches top GGUF variants but lives in a narrower runner ecosystem.
VRAM footprints tell the same story of rough equivalence. Qwen 3.6 27B loads at 14 GB in AWQ, 16 GB in GGUF Q4_K_M, and 14 GB in GGUF IQ4_XS. The 2 GB delta between AWQ and Q4_K_M matters on a single 16 GB card. It's not the dramatic compression win that drives adoption. The real separation is throughput, not size: vLLM + Qwen 3.6 27B AWQ on dual RTX 5060 Ti hits 60+ tok/s; llama.cpp + GGUF Q4_K_M hits ~30 tok/s.
The 2x multiplier reflects vLLM's continuous batching, PagedAttention, and optimized CUDA kernels, not AWQ's quantization approach. Run AWQ through a naive runner and you don't get 60 tok/s; run GGUF through vLLM and the gap compresses. The format choice unlocks the runner, and the runner delivers the speed.
Three variables drive the decision. Need universal runner support? GGUF is your choice. Serving multiple users through vLLM? AWQ's throughput advantage justifies the format lock-in. VRAM-bound on a single 16 GB card? IQ4_XS matches AWQ's footprint with broader runner compatibility—the pragmatic middle path.
Runner Support Matrix (The Deciding Factor)
AWQ native support is confined to four Linux-first serving frameworks: vLLM (the primary production home), Hugging Face's TGI, SGLang for structured generation, and TabbyAPI's wrapper layer. All support NVIDIA CUDA; vLLM adds AMD ROCm and Intel XPU. llama.cpp, Ollama, LM Studio, KoboldCpp, and Jan don't support AWQ natively. This is an architectural boundary, not a temporary gap. AWQ's kernel fusion and GEMM optimizations require dedicated CUDA/ROCm kernels consumer runners haven't built.
GGUF works across every runner: llama.cpp, Ollama, LM Studio, KoboldCpp, Jan, vLLM, and TGI. One GGUF file runs on your gaming PC, headless server, MacBook, and API endpoints—no conversion. This universality explains why GGUF dominates Hugging Face despite AWQ's quality parity.
Home builders run into a hard constraint here. Ollama and LM Studio don't support AWQ, locking out 90%+ of desktop users without a toolchain switch. This friction—installing vLLM, managing Python, configuring tensor parallelism—explains GGUF's dominance more than any benchmark gap. Builders choose formats based on runner support, not perplexity charts. It's decided by whether ollama run recognizes your file.
Runners That Support AWQ (and Don't)
The runner gap matters more than any quality difference between formats. AWQ splits the ecosystem: production serving frameworks on one side, consumer runners on the other, with no overlap.
AWQ support is confined to four Linux-first frameworks: vLLM (primary), TGI, SGLang, TabbyAPI. llama.cpp, Ollama, LM Studio, KoboldCpp, and Jan don't support AWQ natively. This is structural, not a licensing quirk or pending pull request. AWQ's kernel-fused GEMM and activation-aware dequantization need specialized CUDA/ROCm kernels consumer runners haven't built. The format lives in datacenter-optimized codepaths, not desktop convenience layers.
vLLM is the AWQ production home: it achieves 60+ tok/s on dual RTX 5060 Ti 16 GB with Qwen 3.6 27B AWQ (Apr 29 thread, 118up). That throughput advantage only becomes economical at multi-user scale. Single-user chat doesn't justify the complexity of Linux, Python, and tensor-parallel setup. GGUF's universal runner support stays the default. You trade theoretical throughput for "it runs everywhere."
AWQ-Native Runners
Four frameworks run AWQ natively. Each serves a distinct production niche, and none target the casual desktop user.
vLLM (primary): NVIDIA CUDA, AMD ROCm, Intel XPU support. Multi-user batched serving via continuous batching and PagedAttention. The 60+ tok/s comes from vLLM keeping both RTX 5060 Ti cards saturated with interleaved requests—not quantization.
TGI (Hugging Face): Production inference server, ~40 tok/s (slower than vLLM), fully containerized. Best for teams running Kubernetes pipelines who want Hugging Face ecosystem integration. The throughput cost is real. Operational simplicity for existing TGI deployments may offset it.
SGLang: Structured generation with JSON schemas, regex constraints, and constrained decoding. Need reliably formatted outputs? SGLang + AWQ combines speed with guarantees llama.cpp's grammar engine can't match at scale.
TabbyAPI: AWQ-through-vLLM wrapper with llama.cpp-compatible API (~15% slower). The bridge for users who want vLLM's speed without rewriting client code. That 15% penalty (51 tok/s vs 60 tok/s) buys llama.cpp-compatible API support for existing frontends.
GGUF-Universal Runners and the AWQ Lock-Out
The consumer side of the runner ecosystem is an AWQ desert.
llama.cpp, Ollama, LM Studio, KoboldCpp, Jan: zero native AWQ support. vLLM is the only bridge runner that loads both AWQ and GGUF. For the home-lab builder who wants to double-click a model in LM Studio or type ollama run qwen3.6:27b, AWQ isn't an option. The file won't load and the runner doesn't recognize the format. No GUI workaround exists.
90%+ of CraftRigs readers have zero AWQ options in their toolchain, making GGUF the practical default despite theoretical parity. This is the market reality that perplexity benchmarks miss. A format can match Q4_K_M on every eval and still lose because ollama pull doesn't speak its language.
Forum threads repeat the same specific frustration. A user downloads an AWQ file, drops it in their Ollama directory, and gets silence. Or they see fast AWQ benchmarks, buy hardware, then discover LM Studio doesn't support it. That discovery cost—lost time, wrong hardware buys, forum troubleshooting—is format fragmentation's hidden tax. GGUF's universality eliminates it. One file, every runner, no surprises.
For a deeper look at how this runner landscape breaks down across use cases, see our full runner comparison. If you're building around dual RTX 5060 Ti cards, our hardware guide maps the vLLM + AWQ throughput path to that VRAM tier.
When to Pick AWQ: Multi-User Serving
vLLM + AWQ on dual RTX 5060 Ti 16 GB achieves ~60 tok/s with Qwen 3.6 27B (Apr 29 thread, 118up). That's roughly double the throughput of llama.cpp + GGUF Q4_K_M on identical hardware. That 2x multiplier looks compelling on paper. It only justifies the complexity when you're serving 5+ concurrent users or running batched API calls. Single-user chat? GGUF's universal simplicity wins every time.
Understand what that 60 tok/s means: not 60 tok/s for you. That's 60 tok/s aggregated across batches—PagedAttention slices KV cache across interleaved requests. One user typing alone sees latency, not throughput. The magic happens when request N+1 arrives while request N is still generating. vLLM slips the new prompt into gaps the single-user runner would leave idle. You're buying scheduling efficiency across concurrent users, not per-token speed for single conversations.
VRAM footprints are equivalent: Qwen 3.6 27B AWQ ≈ 14 GB model + KV cache vs Q4_K_M ≈ 16 GB model + KV. AWQ's advantage is pure throughput—the natural pick for multi-user serving (household APIs, small business, batch loops) where latency compounds across concurrent requests.
The decision matrix is clear. The format is excellent. The runner ecosystem is narrow. The 30 tok/s of llama.cpp + GGUF feels slow only in comparison. It's instant for human typing. Throughput gains only help when requests queue up.
For the builder with dual RTX 5060 Ti cards weighing this decision, our hardware guide maps both paths to that VRAM tier. The vLLM + AWQ route is there if your use case fits. Most won't.
Converting AWQ to GGUF (or Not)
Don't convert between these formats. Conversion is lossy in both directions—your file underperforms native releases on either side.
The de-quantize-then-requantize pipeline strips away format-specific intelligence at every step. Decompressing AWQ to full precision destroys the activation-aware scaling knowledge—those calibrated per-group factors that made it worth using. Re-quantizing to GGUF applies GGUF optimizations (imatrix, k-quant, importance weighting) that assume different distributions than your dequantized weights present. Result: a Frankenstein file with neither format's native optimizations, both formats' assumptions broken. These conversions underperform native releases by measurable perplexity margins.
Simpler path: download a native GGUF from Hugging Face instead. Most models (Qwen 3.6, DeepSeek, Mistral) ship both AWQ and GGUF variants, each optimized natively by their maintainers. The AWQ release carries the calibration dataset and scale factors that make it sing in vLLM. The GGUF version carries imatrix and k-quant mixtures for universal runner compatibility. These are parallel builds from the same base weights, not sequential conversions. Treat them as separate artifacts.
Train-merge-export GGUF, not convert—if you've fine-tuned in AWQ and need distribution. See the fine-tuning section below.
Fine-Tuning: GGUF as Distribution Target
Unsloth and Axolotl support AWQ-aware LoRA training (Unsloth with explicit AWQ output). After fine-tuning, merge the LoRA + base model, then export as GGUF for distribution. Keep AWQ for vLLM production serving. Export GGUF for community sharing. The workflow looks like this:
-
Train in AWQ. Use Unsloth or Axolotl. Adapters learn against the calibrated quantization structure.
-
Merge LoRA + base. Create a full-precision checkpoint for maximum flexibility. This is your master copy — store it, version it, never distribute it raw.
-
Export to AWQ. Generate an optimized serving copy for your vLLM endpoint. Same group-size 128, new scale factors tuned to your fine-tuned distribution.
-
Export to GGUF. Create a community distribution copy for universal runner compatibility. Not a conversion — a parallel build from the same merged source.
Neither export is a degraded version of the other. Both get format-appropriate optimization passes. The AWQ copy serves fast to your vLLM endpoint. Your GGUF copy travels to Ollama, LM Studio, llama.cpp users—anyone wanting your weights without your infrastructure.
For builders weighing Unsloth's CLI-native workflow against GUI alternatives, our Unsloth vs LM Studio comparison maps the practical differences. The AWQ-aware training path demands Linux comfort and terminal fluency. The payoff: export flexibility GUI pipelines can't match—train once, serve anywhere.
Fine-Tuning Workflows: Train Strategically, Ship Carefully
The modern fine-tuning stack has evolved alongside AWQ rather than resisting it. You don't need full-precision base weights to train a useful LoRA. You need a framework that updates adapters without destroying calibrated quantization.
Unsloth and Axolotl both support AWQ-aware LoRA fine-tuning. Unsloth supports explicit AWQ output—train adapters directly on quantized weights, export in the same calibrated structure. Don't train against dequantized AWQ weights (or full-precision then re-quantize)—you strip the activation-aware scaling that makes it worthwhile. The adapter learns against the wrong statistical distribution, and the merged result underperforms.
Axolotl is more conventional: load AWQ, train adapters in mixed precision, merge to full precision. Calibration is preserved through frozen base weights, which don't get explicitly optimized during training. Both work. Unsloth's native AWQ pipeline is tighter for builders staying quantized end-to-end.
The strategic split comes after training, not during. Keep trained models in AWQ for serving through vLLM. That's where the format's throughput advantage lives. Export as GGUF for distribution. That's where universality wins. One trained model, two serialized artifacts, each optimized for its destination runner ecosystem. No conversion penalty—both export from the same merged checkpoint with fresh calibration.