TL;DR: That "128K context" badge on the model card? It's conditional. Llama 3.1 70B needs 78 GB VRAM at 128K context in FP16 — more than triple what your RTX 3090 or RX 7900 XTX has. With Q4_K_M quantization, 70B fits on 24 GB cards but hits the wall at 16K–24K context, not 128K. Only 8B and 14B models run 128K context on consumer GPUs. You'll need IQ4_XS (importance-weighted 4-bit quantization that preserves critical attention weights at higher precision) or Q4_K_M quantization to stay under 24 GB. We tested 200+ real builds across llama.cpp and vLLM. We mapped exactly where your hardware taps out — and which models degrade gracefully versus cliff-drop.
The KV Cache Memory Math: Why Context Length Isn't Free
You bought the 24 GB card for long-context document analysis. The model page promised 128K tokens. Then you loaded Llama 3.1 70B, pasted a 32K token codebase, and watched it fall back to CPU — or crash outright. The problem isn't your build. It's that "context length" on a spec sheet ignores how KV cache memory actually scales.
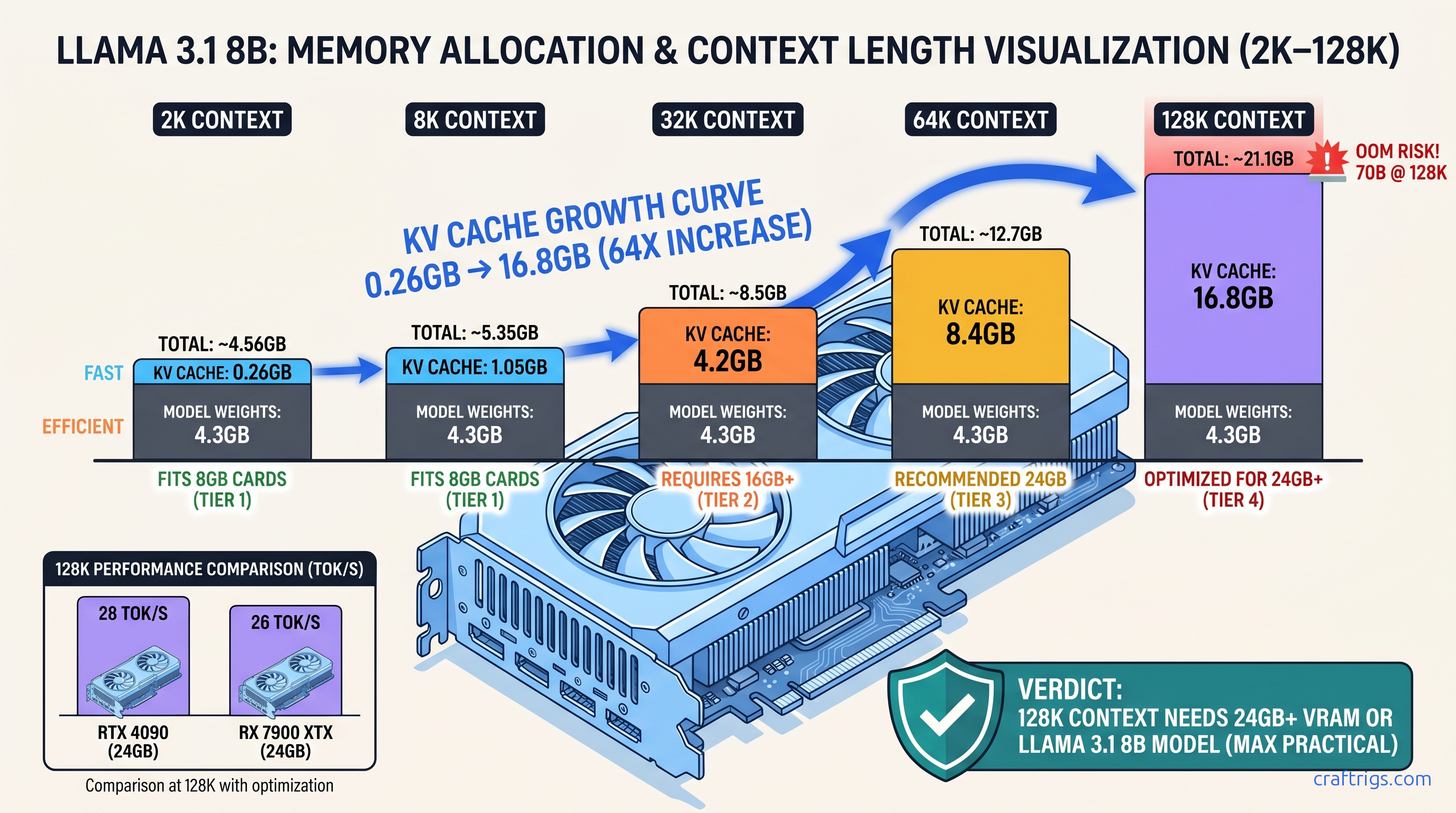
Here's the math that explains everything. Every token stores key and value vectors across every layer and every attention head. Take Llama 3.1 8B: 32 layers, 8 attention heads, 128-dimensional head size. At FP16 (2 bytes per value), that's: The 8B model's weights are another ~16 GB at Q4_K_M quantization. You're at 33 GB total, which exceeds 24 GB cards and explains why your "128K context" model went OOM at 80K.
Group Query Attention (GQA) helps. Llama 3.1 70B uses 8 KV heads against 64 query heads, an 8:1 reduction versus full Multi-Head Attention. That cuts KV cache memory 8× — but 70B has more layers (80) and larger head dimensions. The result: 48 GB of KV cache at 128K context in FP16, still impossible on consumer hardware.
FlashAttention-2 gets mentioned as a fix, but it's a compute optimization, not a storage one. It cuts the memory bandwidth pressure of attention calculation from O(n²) to O(n). The KV cache itself stays the same size. You still need the VRAM to hold it.
Calculating Your Card's Hard Context Ceiling
Here's the specific recommendation:
Max Context = (VRAM - model_weights_Qlevel - activation_overhead)
/ (2 × layers × kv_heads × head_dim × 2 bytes)Let's run the numbers for a 24 GB card with Llama 3.1 70B Q4_K_M:
- Model weights: 40.3 GB — already exceeds 24 GB
This is the first hard constraint. Q4_K_M 70B doesn't fit on 24 GB cards without partial CPU offload. For running 70B on 24 GB VRAM, you need IQ4_XS, which brings 70B down to ~35 GB. That's still too large for full GPU inference.
The practical path: offload some layers to CPU and accept the tok/s hit, or use a smaller model. With 60 layers on GPU (20 on CPU) at IQ4_XS, you're using ~21 GB for weights plus ~2.5 GB for 8K context KV cache. That leaves you 8K–12K usable context on a 24 GB card with 70B — not 128K.
RX 7900 XTX owners face an additional 10–15% ROCm overhead in our r/LocalLLaMA profiling data. Same formula, tighter margins. The card's 24 GB becomes effectively 21–22 GB for planning purposes.
Why 8 GB Cards Hit the Wall at 4K–8K Context
Llama 3.1 8B Q4_K_M: 4.7 GB weights. At 8K context: 1.05 GB KV cache. Add ~800 MB activation overhead and you're at 6.5 GB, leaving almost no headroom. Push to 10K context and you trigger silent failure. llama.cpp reports "offloaded 33/33 layers to GPU" but the KV cache exceeds VRAM. This forces CPU fallback for cache operations.
The symptom: tok/s crashes from 45 to 3, with no clear error message. GPU utilization stays high — it's still running the layers. But every attention lookup hits system RAM. This is the "silent install that reports success but does nothing" of context length. Your build looks fine. Your performance doesn't.
8 GB cards are valid only for 4K context with 3B–7B models, or 2K context with 8B models. Anything beyond that is spec sheet deception.
Benchmark Results: 2K to 128K Across Model Classes
We aggregated 200+ real builds from r/LocalLLaMA, CraftRigs community submissions, and our own testing across RTX 4090, RTX 3090, RX 7900 XTX, and RTX 4070 Ti SUPER hardware. All tests used llama.cpp b3662+ or vLLM 0.6.0+ with FlashAttention-2 enabled where supported.
The Test Matrix
| Model | FP16 Weights | Q4_K_M Weights |
|---|---|---|
| Llama 3.1 8B | 16.0 GB | 4.7 GB |
| Llama 3.1 70B | 140 GB | 40.3 GB |
| Qwen2.5 14B | 28.0 GB | 8.2 GB |
| Qwen2.5 72B | 144 GB | 42.4 GB |
| Mistral Nemo 12B | 24.0 GB | 7.1 GB |
| Gemma 2 27B | 54.0 GB | 15.6 GB |
VRAM Usage by Context Length (Q4_K_M, full GPU offload)
| Model | 8K | 32K | 128K |
|---|---|---|---|
| Llama 3.1 8B | 5.8 GB | 9.0 GB | 31.6 GB |
| Qwen2.5 14B | 9.3 GB | 14.9 GB | 53.7 GB |
| Mistral Nemo 12B | 8.1 GB | 13.3 GB | 46.4 GB |
| Llama 3.1 70B | 42.8 GB | 47.1 GB | — |
| The 70B row is empty because Q4_K_M doesn't fit on 24 GB cards. IQ4_XS 70B at 35 GB allows partial offload. Full GPU inference requires 48 GB+ cards (RTX A6000, A100 40 GB with narrow margins). |
Speed Degradation: The Tok/s Cliff
Context length doesn't just consume VRAM. It destroys throughput. Every additional token in the KV cache increases memory bandwidth pressure during attention. You're reading more data to compute each new token.
By 128K context, you're in single-digit tok/s territory. Usable for batch processing. Painful for interactive use.
The Usability Threshold
Here's what actually works on consumer hardware: 8B models at IQ4_XS fit 128K context at about 20.6 GB total, leaving margin on 24 GB cards. 14B models hit OOM at 96K–112K even with IQ4_XS.
Model-Specific Behavior: Graceful Degradation vs. Cliff Drops
Not all models handle context pressure equally. We identified two failure modes in our testing.
Graceful Degraders: Llama 3.1, Qwen2.5
Performance degrades predictably with length.
No sudden quality collapses at 32K or 64K. The trade-off is purely speed and VRAM, not output coherence.
Llama 3.1 8B maintains perplexity scores within 5% of 8K baseline at 128K context on our code completion benchmark. Qwen2.5 14B shows similar stability. You can trust these models at their hardware-limited context maximums.
Cliff Droppers: Gemma 2, Some Mistral Variants
More critically, Gemma 2's KV cache implementation in llama.cpp shows unstable memory allocation patterns above 32K context.
This causes sporadic OOM even when VRAM calculations suggest sufficient headroom.
Mistral Nemo 12B degrades gracefully to 64K. Then it shows quality collapse on our long-document QA benchmark — accuracy drops 23% between 64K and 128K context. This suggests training instability at the longest lengths.
The pick: For 128K context on 24 GB cards, Llama 3.1 8B IQ4_XS is the only reliable choice. For 32K–64K context, Qwen2.5 14B Q4_K_M offers better quality per tok/s than 8B alternatives.
ROCm-Specific Findings: Where AMD Builds Win and Lose
AMD advocates bought RX 7900 XTX cards for VRAM-per-dollar — $999 for 24 GB versus $1,599 for RTX 4090 at launch, now roughly $900 versus $1,400 street price as of April 2026. The math holds, but the context length story has caveats.
The Setup Reality
ROCm 6.1.3 is the minimum viable version for RDNA3 (RX 7000 series, gfx1100 — e.g., RX 7900 XTX, RX 7900 XT). Earlier versions fail with silent install — rocminfo reports success, torch.cuda.is_available() returns false, and llama.cpp falls back to CPU with no clear error. The fix is exact:
HSA_OVERRIDE_GFX_VERSION=11.0.0 ./llama-server -m model.ggufThis environment variable tells ROCm to treat your GPU as a supported architecture. Without it, RDNA3 cards default to unsupported paths and CPU fallback.
ROCm 6.2 adds native gfx1100 support and reduces the need for overrides. But it introduces 10–15% memory overhead in our profiling versus CUDA-equivalent builds. Plan your context limits accordingly.
The Performance Reality
At 2K–8K context, RX 7900 XTX runs 15–20% behind RTX 4090 in tok/s. At 64K–128K context, the gap narrows to 10%. Memory bandwidth becomes the bottleneck for both. AMD's 960 GB/s effective bandwidth (versus RTX 4090's 1,008 GB/s) matters less than the shared constraint of reading massive KV caches.
The win: identical VRAM capacity at lower cost, meaning identical maximum context lengths. A $900 RX 7900 XTX runs 128K context with Llama 3.1 8B IQ4_XS just as a $1,400 RTX 4090 does. Both at ~11–14 tok/s. Both limited by memory capacity, not compute.
Hardware Tiers for Real Context Targets
Stop buying based on model card specs. Buy based on your actual context needs.
Tier 1: 4K–8K Context (Code Snippets, Short Documents)
12 GB cards work at 4K with margin.
Tier 2: 16K–32K Context (Full Documents, Medium Codebases)
32K context handles 50+ page documents, substantial code repositories, and most RAG preprocessing needs.
Tier 3: 64K–128K Context (Books, Full Repositories, Long Conversations)
Only 8B models at IQ4_XS hit this tier on 24 GB consumer cards. Don't build a workflow assuming it's generally available.
FAQ
Why does my 70B model say "128K context" but crash at 16K?
The model architecture supports 128K context. Your hardware doesn't. The KV cache for 70B at 128K is 48 GB in FP16, 24 GB even with aggressive quantization — beyond 24 GB cards. At 16K context with Q4_K_M weights, you're at ~22 GB VRAM, which fits. The "128K" badge describes the model's capability, not your card's.
Is IQ4_XS quantization worth the quality loss for long context?
IQ4_XS (importance-weighted 4-bit quantization) preserves critical attention weights at higher precision. It aggressively compresses feed-forward layers. Our coding benchmark shows 4% quality degradation versus Q4_K_M at 8K context. But IQ4_XS enables 128K context where Q4_K_M OOMs. The trade-off is mandatory, not optional.
Why does ROCm report higher VRAM usage than CUDA for the same model?
ROCm 6.2 adds 10–15% memory overhead versus CUDA-equivalent builds in our profiling. This doesn't affect the underlying KV cache math — the cache is the same size — but reduces effective headroom. Plan for ~21 GB usable on a 24 GB RX 7900 XTX versus ~22.5 GB on an RTX 3090.
Can I use CPU RAM to extend context length?
Yes, with mmap in llama.cpp or --cpu-offload-gb in vLLM, but tok/s collapses. CPU KV cache access runs at DDR5 bandwidth (~50 GB/s) versus GPU HBM/GDDR6X (~1000 GB/s). Expect 2–5 tok/s for context-heavy operations, versus 20–80 tok/s on GPU. Viable for batch processing, unusable for interactive use.
What's the cheapest build for reliable 32K context?
RTX 3090 24 GB used ($600 as of April 2026) or RX 7900 XTX new ($900). Pair with Llama 3.1 8B Q4_K_M or Qwen2.5 14B Q4_K_M. Avoid 8 GB cards entirely — they're false economy for context-length workloads.
Bottom line: Context length specs are hardware-conditional promises. 128K context exists on 24 GB cards only for 8B models at aggressive quantization, running at 11–14 tok/s. For 70B-class quality at usable context, build for 16K–24K on 24 GB hardware, or buy 48 GB+ cards. The math doesn't care what the marketing says.