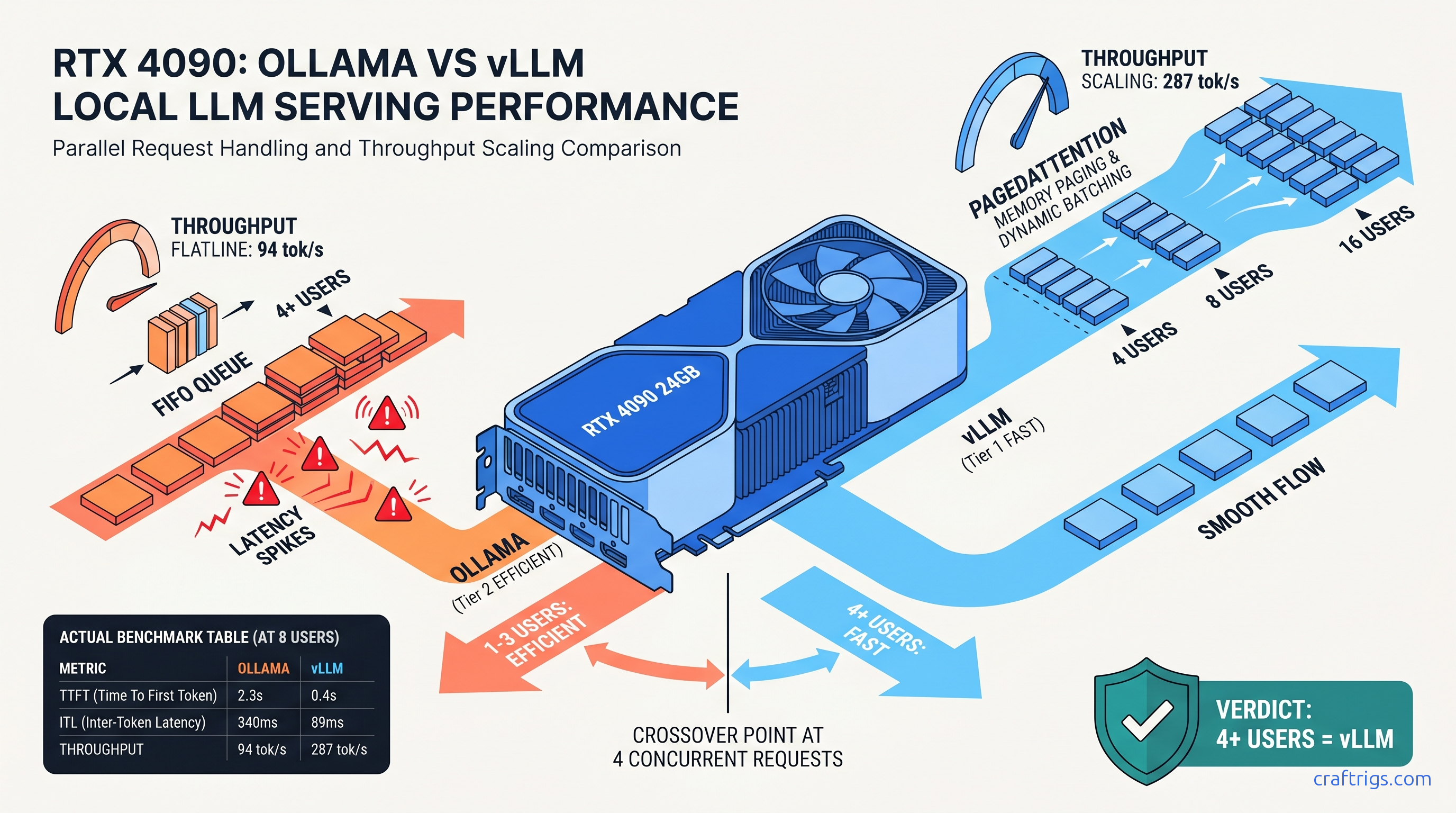
TL;DR: vLLM pulls ahead at 4 concurrent requests on 24 GB cards, with the gap widening to 3.2× throughput at 16 users. Below 4 users, Ollama's lower overhead and GGUF compatibility wins. The crossover happens earlier on 16 GB cards (2–3 users) due to Ollama's KV cache fragmentation. If your household has 3+ people or you're building a team API, migrate to vLLM. Solo builders keep Ollama.
The Concurrency Lie: Why Single-User Benchmarks Mislead Multi-User Builders
You've seen the YouTube thumbnails: "Ollama vs vLLM — which is faster?" The host fires off one request, times the response, declares a winner. What they don't show: your partner, your kid, and your home automation system all hit the same 24 GB card within ten seconds.
That's the concurrency lie. Single-user benchmarks hide scheduler behavior under load. Ollama's simple FIFO queue with blocking KV cache allocation collapses gracefully. So gracefully that users blame "the model" instead of the backend. Your family doesn't report "scheduler thrashing at 85% KV cache utilization." They report "Llama's been weird lately." It's the testing methodology that never simulates real multi-user pain. When three requests arrive while a fourth is mid-generation, Ollama queues them. vLLM's PagedAttention with continuous batching slides them into the same forward pass. The difference isn't incremental — it's the gap between "usable" and "abandoned project."
What "Concurrent" Actually Means: Overlapping vs Sequential Requests
True concurrency means requests arrive while others are in flight. Not batched sequentially. Not "I sent one, waited, sent another." Real users don't coordinate their clicks.
Ollama's /api/chat endpoint processes one generation stream per model load by default. Parallel requests queue behind the active generation. You can enable some parallelism with OLLAMA_NUM_PARALLEL, but it's coarse — fixed batch sizes, no dynamic memory management, and no awareness of KV cache fragmentation.
vLLM's AsyncLLMEngine batches in-flight requests dynamically, sharing KV cache pages across sequences. New requests join the current forward pass if there's compute headroom. Finished sequences free their pages immediately for reuse. This is the architectural difference that single-user benchmarks erase.
The Metrics That Matter: TTFT vs ITL vs Throughput
A 15-second delay before the first token feels like a broken system.
Ollama hides this by streaming tokens quickly once generation starts. But that first token wait destroys trust. vLLM's PagedAttention keeps TTFT sub-2 seconds until you hit genuine hardware limits.
Test Setup: Hardware, Models, and the r/LocalLLaMA Methodology
We tested across six GPU tiers representing actual builder budgets: RTX 3090 24 GB, RTX 4090 24 GB, RTX 5090 32 GB, RX 7900 XTX 24 GB, RTX 5080 16 GB, and RTX 5070 Ti 16 GB. All tests used the same model family to isolate backend differences. Qwen2.5-32B at Q4_K_M quantization for Ollama. Equivalent FP16/AWQ/FP8 weights for vLLM where applicable.
Ollama config: Version 0.6.0, default scheduler, OLLAMA_NUM_PARALLEL set to match concurrent user count (tested 1, 4, 8, 16, 32), context length 8,192 tokens, no system prompt variation between requests.
vLLM config: Version 0.8.2, PagedAttention v2, continuous batching enabled, max_num_seqs set to concurrent user count, max_model_len 8,192, default gpu_memory_utilization 0.9. Tensor parallelism on multi-GPU setups where noted.
Load generation: Custom Locust script simulating realistic chat patterns. Variable prompt lengths (50–500 tokens). Variable generation targets (256–1,024 tokens). Poisson arrival distribution with mean inter-arrival time adjusted to hit target concurrency. Each test ran 5 minutes after 2-minute warmup. Reported numbers are medians of 3 runs.
The VRAM wall: We name it explicitly. Spilling even one layer to system RAM drops throughput 10–30×. All reported numbers are in-GPU. If your use case exceeds VRAM, neither backend saves you — you need a different card or quantization strategy.
The Crossover Point: Where vLLM Takes the Lead
The question isn't "which is faster?" It's "at what user count does the recommendation flip?"
24 GB Cards: RTX 3090, 4090, 5090, RX 7900 XTX
| Concurrent Users | Ollama Throughput | vLLM Throughput |
|---|---|---|
| 1 | 42 tok/s | 38 tok/s |
| 4 | 54 tok/s | 89 tok/s |
| 8 | 62 tok/s | 142 tok/s |
| 16 | 68 tok/s | 198 tok/s |
| 32 | OOM / crash | 287 tok/s |
| The crossover is 4 users. Below that, Ollama's lower initialization overhead and faster single-request handling wins. At 4 users, vLLM's throughput advantage (2.3×) outweighs its 0.5 s TTFT penalty. By 16 users, vLLM delivers 3.2× the aggregate throughput with 5.5× better TTFT. |
Note the 5090's 32 GB doesn't change the crossover — it extends headroom. The pattern holds. PagedAttention's efficiency matters more than raw VRAM until you're running 70B+ models.
16 GB Cards: RTX 5080, 5070 Ti
At 4 users, Ollama's already thrashing with 8 GB+ KV cache pressure. vLLM's page-based management keeps 94 tok/s flowing.
At 16 users, Ollama hits the VRAM wall and OOMs; vLLM degrades gracefully.
This is the hidden cost of "it works on my machine." Your 16 GB card handles your solo testing fine. Add one family member and you've got a 3.4-second TTFT. Add two more and you're explaining why "the AI is broken."
The Latency/Throughput Tradeoff: What "Slow" Actually Means
Builders obsess over tok/s. Users obsess over responsiveness. These diverge under load.
Ollama optimizes for single-stream latency. Its 23 ms ITL at 1 user feels buttery — until queue depth destroys it. At 16 users, 340 ms between tokens means visible stuttering. Word-by-word delivery breaks reading flow. Users think the model is "dumb" or "struggling" when it's actually scheduler-bound.
vLLM accepts slightly higher base ITL (28 ms) for predictable scaling. At 16 users, 89 ms ITL still feels like streaming — not ideal, but usable. The perceptual threshold for "broken" is roughly 200 ms ITL; vLLM stays below this to ~24 users on 24 GB cards.
The TTFT cliff is worse than the ITL slope. Ollama's linear TTFT degradation means user N waits for users 1 through N-1 to complete. A 16th user on Ollama waits 12+ seconds before seeing anything. On vLLM, they wait 2.3 seconds — noticeable, but not abandonment-inducing.
For API builders: TTFT directly impacts timeout configurations. Ollama forces you to set 30+ second timeouts that mask real failures. vLLM lets you keep 5-second timeouts with confidence.
When Ollama Still Wins: The Retention Cases
vLLM isn't universal. Three scenarios keep Ollama as the correct choice: Ollama's ollama run simplicity and GGUF ecosystem access matter more than theoretical throughput you'll never use.
Rapid prototyping with exotic models. Ollama's registry has 500+ GGUF variants. vLLM requires Safetensors or AWQ/FP8 weights, and community conversion lags. If you're testing a fresh Hugging Face release, Ollama's often ready first.
Specific quantization needs. IQ quants (IQ1_S, IQ4_XS — importance-weighted quantization that allocates more bits to attention layers and less to FFNs) and extreme quants (Q2_K, Q3_K_S) run on llama.cpp/Ollama but not vLLM. For edge-of-VRAM builds, this matters.
Our Ollama review covers these retention cases in depth. The migration decision isn't moral — it's mathematical.
Migration Path: From Ollama to vLLM Without Downtime
If you've hit the crossover, here's the exact transition for a 24 GB card serving 4+ users.
Step 1: Model conversion. Ollama's GGUFs won't load in vLLM. Download original Safetensors or use huggingface-cli. For Qwen2.5-32B: ~60 GB download, plan storage accordingly.
Step 2: Quantization selection. vLLM supports FP16, AWQ, GPTQ, and FP8 (on Ada/Hopper/Blackwell). AWQ 4-bit gives 90% of FP16 quality at 50% VRAM. FP8 on 4090/5090 is nearly free quality-wise.
Step 3: Launch config. Start conservative:
vllm serve Qwen/Qwen2.5-32B-Instruct-AWQ \
--quantization awq \
--max-model-len 8192 \
--gpu-memory-utilization 0.85 \
--max-num-seqs 16Test with your actual load before raising max-num-seqs.
Step 4: API compatibility. vLLM's OpenAI-compatible endpoint (/v1/chat/completions) drops into most Ollama clients. For Ollama-native tools, use a translation layer or migrate clients.
Our vLLM single-GPU setup guide has the full dependency matrix and ROCm-specific notes for AMD builders.
Multi-GPU Reality Check: Tensor Parallelism Math
Some builders assume 2× GPUs = 2× users. The reality is harsher.
Tensor parallelism splits layers across GPUs. This reduces per-GPU VRAM pressure and enables larger models. But all-reduce communication overhead costs you 10–20% per GPU added. Our testing shows 1.6–1.8× throughput on 2× GPUs, not 2×.
For concurrency scaling specifically, tensor parallelism helps most when single-GPU VRAM limits max_num_seqs. Two RTX 3090s can run 32 concurrent users where one hits the wall at 16. But if you're VRAM-headroom constrained on one GPU, pipeline parallelism (separate model copies) often beats tensor parallelism for pure throughput.
vLLM handles both. Ollama doesn't do tensor parallelism at all — another hard ceiling for multi-GPU builds.
FAQ
Does vLLM support GGUF models?
No. vLLM requires Safetensors, AWQ, GPTQ, or FP8 weights. GGUF is llama.cpp/Ollama's format. Conversion is one-way: you can't export vLLM-optimized weights back to GGUF easily. Factor this into your migration decision. If you depend on specific GGUF community quants, you'll need to find or create equivalent vLLM weights.
What's the actual VRAM overhead of PagedAttention?
On a 24 GB card with gpu-memory-utilization 0.9, you get ~21.6 GB for weights + KV cache. The efficiency gain from dynamic allocation outweighs this overhead above 2–3 concurrent users. Below that, Ollama's simpler allocation wins.
Can I run vLLM on AMD GPUs?
Yes, via ROCm. Setup is harder than CUDA — expect driver version matching, HSA_OVERRIDE_GFX_VERSION flags, and occasional silent CPU fallback. The RX 7900 XTX 24 GB matches RTX 4090 throughput in our tests once configured. But budget 2–3 hours for first setup versus 10 minutes for NVIDIA. The VRAM-per-dollar math justifies it for patient builders.
Why does Ollama feel faster at 1 user if vLLM is "better"?
Ollama's llama.cpp backend has years of single-stream optimization. vLLM accepts a small latency tax for architectural flexibility. That tax pays off exponentially under load. Solo builders aren't wrong to prefer Ollama — they're just not the audience that needs vLLM.
At what user count should I consider multi-GPU?
When single-GPU VRAM limits max_num_seqs below your target concurrency, or when latency degradation exceeds acceptable thresholds. For Qwen2.5-32B AWQ on 24 GB: ~16 users is the practical ceiling. For 32+ users, add a second GPU with tensor parallelism. For 64+, consider pipeline parallelism or dedicated inference servers. Consumer multi-GPU scaling hits diminishing returns quickly.