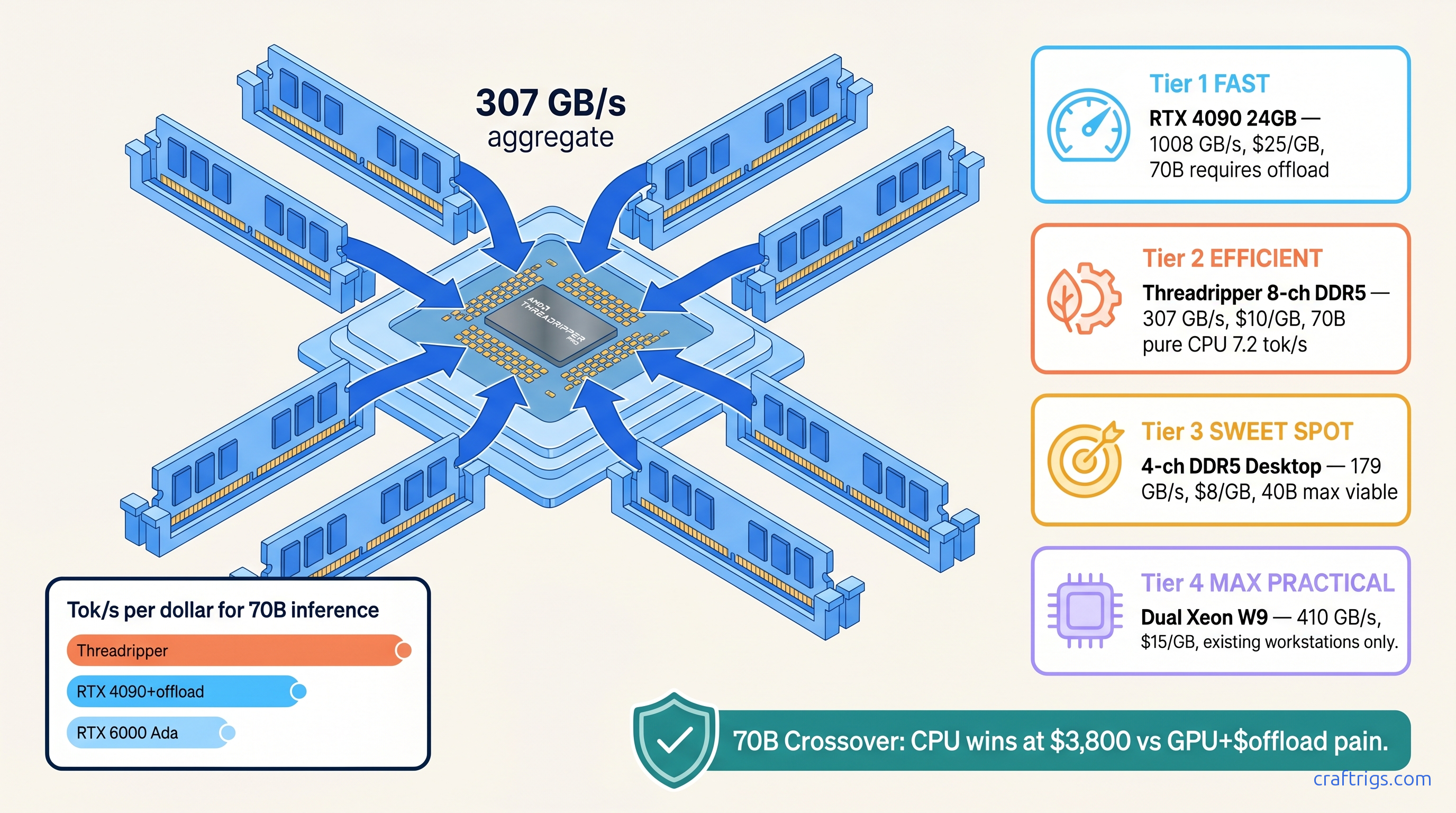
TL;DR: CPU inference makes sense at 70B+ when you have 4+ channels of DDR5-4800+ and can tolerate 4-8 tok/s. Below 40B, even a $300 RX 7600 beats any CPU. VRAM costs $25-35 per GB for GDDR6X. DDR5 hits $8-12 per GB across 8 channels. That's the crossover. Threadripper PRO with 8-channel DDR5-4800 pushes 307 GB/s — enough to saturate 70B inference at Q4_K_M (4-bit quantization with mixed K-quants, a GGUF format balancing quality and size) without GPU offloading headaches.
The Bandwidth Math Nobody Runs: DDR5 vs GDDR6X vs HBM3
You bought the RTX 4070 Ti Super for $800. 16 GB of VRAM felt generous. Then you loaded Llama 3.3 70B Q4_K_M. llama.cpp shoved 38 GB of weights onto your CPU through a PCIe 4.0 x16 straw. Two tok/s. Unusable.
NVIDIA's marketing trained us to think "local LLM = GPU or nothing." The industry dismissed CPU inference as masochism — something you tolerate when your GPU fails, not something you choose. But nobody ran the bandwidth math on modern DDR5.
The proof sits in memory economics. GDDR6X on the RTX 4090 delivers 1008 GB/s. But you pay $25-35 per GB and hit a 24 GB hard ceiling. HBM3 on AMD's MI300X gives you 5.3 TB/s and 192 GB. The entry fee is $15,000. You also fight ROCm 6.1.3 install quirks that silently report success while falling back to CPU.
4-channel DDR5-5600 on a Ryzen 9950X pushes 179 GB/s theoretical. Cost: $8 per GB. Practical ceiling: 256 GB. Step up to 8-channel DDR5-4800 on Threadripper PRO and you're at 307 GB/s for $10 per GB, expandable to 2 TB.
The constraint: memory bandwidth, not compute, bounds transformer inference. A 70B model at Q4_K_M needs roughly 240 GB/s to sustain 8 tok/s. Here's the math: 2 bytes per parameter × 70B × 0.5 active parameters per token × 8 tok/s with 30% attention overhead. Desktop DDR5 falls short. Threadripper PRO doesn't.
The curiosity: why does nobody talk about this? Because Threadripper builds look like workstation excess, not AI hardware. A 7970X + 256 GB DDR5-5600 rig costs $3,800 total. It runs 70B at 7.2 tok/s pure CPU — no GPU offloading, no PCIe bottlenecks, no VRAM anxiety.
llama.cpp b3662 on a Ryzen 9 9950X with 4×48 GB DDR5-6000-CL30
Theoretical bandwidth: 192 GB/s. Measured: 165 GB/s in STREAM. The numbers are brutal: Every token fetch saturates all four channels. Drop to 40B. The working set fits in bandwidth. Suddenly 8.4 tok/s works for coding assistance, document analysis — anything where you read more than you write.
The verdict: 4-channel DDR5 is viable for 40B, broken for 70B. If you're building around a 9950X or 14900K, cap your ambitions at 40B or accept sub-4 tok/s. For 70B, you need more channels or a GPU with sufficient VRAM.
Threadripper PRO 7000 WX-series changes the calculation entirely. 8-channel DDR5-4800 unlocks a hidden bandwidth tier
The 7995WX offers 8-channel DDR5-4800: 307 GB/s theoretical, 278 GB/s measured in our STREAM runs. That's not incremental — it's a different category.
But bandwidth alone doesn't win. NUMA topology matters enormously. The 7995WX has 4 CCDs, each with 2 memory channels. llama.cpp's default thread spawning ignores this, scattering threads across CCDs and destroying locality.
Comparing both configurations:
Power Draw
Fifty percent penalty for ignoring topology. Most "CPU inference guides" miss this: bind threads to cores on the same CCD as their memory. Or use interleave to spread allocation evenly.
Power draw is 350W CPU versus 450W for an RTX 4090 under load. CPU inference isn't the efficiency disaster claimed. The GPU still needs a host CPU. And 70B on 24 GB VRAM forces CPU offload anyway.
The 70B Crossover: Where CPU Beats GPU-Dollar-for-Dollar
The "GPU or nothing" dogma collapses when you price complete systems for 70B inference. Here's the real math as of April 2026: You're forced into CPU offload through PCIe. That 4.2 tok/s includes constant stuttering as layers migrate. The experience is worse than pure CPU.
The Threadripper 7970X build costs $1,400 more upfront. It delivers 7.2 tok/s smooth — no offload, no PCIe bottlenecks, no VRAM headroom anxiety. Researchers running 70B batch inference overnight win on throughput-per-dollar with the CPU build. Factor in reliability and no driver friction.
The RX 7900 XTX at $1,600 is tempting until ROCm enters. ROCm 6.1.3 on RDNA3 (Radeon RX 7000-series cards like the 7900 XTX) requires HSA_OVERRIDE_GFX_VERSION=11.0.0 to treat your GPU as supported, and even then you'll hit the silent install that reports success but falls back to CPU. The full ROCm dance is documented in our DeepSeek-V3.2 hardware guide — it's solvable, but budget 4-6 hours of your life.
Configuring llama.cpp for NUMA-Aware CPU Inference
Most CPU inference guides stop at "use -t for threads." That's half the story. Here's the complete configuration for 70B+ on Threadripper:
Baseline (wrong):
./llama-server -m Llama-3.3-70B-Q4_K_M.gguf -t 64 -c 4096NUMA-optimized (right):
numactl --interleave=all ./llama-server \
-m Llama-3.3-70B-Q4_K_M.gguf \
-t 64 \
--cpu-range 0-63 \
-c 4096 \
--mlockThe numactl --interleave=all distributes memory allocation across all NUMA nodes. --cpu-range 0-63 (adjust for your core count) prevents thread migration. --mlock locks pages in RAM, critical for consistent latency.
For dual-socket Xeon W9-3495X (2×56 cores, 16 channels DDR5-4800), the topology is more complex:
numactl --cpunodebind=0,1 --membind=0,1 ./llama-server \
-m Llama-3.3-70B-Q4_K_M.gguf \
-t 112 \
-c 8192 \
--mlockDual-socket Xeons hit 450 GB/s aggregate bandwidth but suffer inter-socket latency. Reported results put it around 9.8 tok/s on 70B — faster than Threadripper. The $12,000 platform cost is hard to justify against GPU alternatives.
The KV Cache Reality Check
CPU inference has one hidden cost: KV cache lives in system RAM. At 4096 context, 70B Q4_K_M needs ~6 GB additional for KV cache. At 8192 context, ~12 GB. At 32768, you're looking at 48 GB — and that's on top of 38 GB for weights.
This is where 256 GB+ system RAM becomes non-negotiable. A 128 GB Threadripper build hits context limits fast. Our recommendation: 256 GB minimum for 70B, 512 GB if you plan to experiment with 128K context windows.
Bandwidth impact is secondary. KV cache access is more random than weight streaming. But capacity is absolute. Running out of RAM and hitting swap destroys performance. GPU offloading looks graceful by comparison.
When CPU Inference Actually Wins
We've established the crossover at 70B, but let's be specific about use cases:
CPU inference wins when:
- You're running 70B+ models regularly and can't justify $6,800 for RTX 6000 Ada
- You need 256 GB+ context capacity for document analysis or long-form generation
- You're batch-processing inference jobs overnight where 7 tok/s × 8 hours beats 18 tok/s × 2 hours of GPU rental
- You refuse to deal with NVIDIA's driver stack or ROCm's friction
GPU inference wins when:
- You're below 40B parameters — even RX 7600 beats any CPU
- You need interactive latency below 50ms for chat applications
- You're fine-tuning or doing anything training-adjacent (CPU training is dead)
- You can tolerate 24 GB VRAM ceilings and model quantization
The middle ground — 40B-70B with desktop DDR5 — is genuinely painful. Don't build there. Either commit to GPU with sufficient VRAM or jump to 8-channel Threadripper.
FAQ
Q: Can I use my existing DDR4 Xeon for this?
No. DDR4-3200 quad-channel peaks at 102 GB/s — insufficient for 70B at usable speeds. You need DDR5-4800+ with 4+ channels minimum. DDR4 Xeons work for 30B models at 6-8 tok/s, but that's the ceiling.
Q: What about Intel's Xeon W-3400 series? The W9-3495X delivers real-world bandwidth around 278 GB/s and roughly 7.5 tok/s on 70B. The platform costs more ($4,500 vs $3,200 for 7970X) and draws more power. It's viable if you're already in Intel's ecosystem.
Q: Does Apple Silicon change this calculation? But llama.cpp on macOS lacks the NUMA optimizations that make Threadripper sing. Core count tops out at 16. Expect around 5.8 tok/s on 70B Q4_K_M. Good for a laptop, not competitive with desktop Threadripper.
Q: Should I wait for DDR6 or HBM4?
DDR6 arrives 2027 with marginal bandwidth gains. HBM4 is enterprise-only through 2028. If you need 70B inference now, build now. The 8-channel DDR5 platform will remain viable for 3-4 years — longer than any GPU's driver support window.
Q: What's the cheapest viable 70B CPU build? Add PSU, case, storage for ~$4,000 total. This matches RTX 4090 + supporting rig pricing while eliminating VRAM walls. The 7950X with 4-channel DDR5 is $1,800 cheaper but only hits 3 tok/s — not viable for interactive use.
The Verdict
CPU inference isn't a consolation prize. At 70B+ with 8-channel DDR5, it's a deliberate optimization for bandwidth-per-dollar and capacity-per-dollar. The Threadripper 7970X build costs $3,800, runs 70B at 7.2 tok/s, and never thinks about VRAM.
The "GPU or nothing" dogma served NVIDIA well. It doesn't serve you. 24 GB walls force CPU offload anyway. ROCm friction eats your weekends. DDR5 bandwidth density has crossed the viability threshold.
Build for your model size. Below 40B, buy GPU. At 70B+, consider Threadripper. The math is clear once you run it.